含语音增强模块的i-向量说话人识别性能分析
2016-05-27游寒旭
李 昕, 李 为, 游寒旭, 朱 杰
(上海交通大学 电子信息与电气工程学院,上海 200240)
含语音增强模块的i-向量说话人识别性能分析
李昕, 李为, 游寒旭, 朱杰
(上海交通大学 电子信息与电气工程学院,上海 200240)
摘要:为解决文本无关说话人识别中训练与识别环境不同导致模式失配的问题,提出了一种采用语音增强模块进行前端预处理的i-向量说话人识别系统,从而提高系统对于环境噪声的鲁棒性.为评估不同语音增强算法的性能,利用NIST08核心测试集进行仿真实验.采用IMCRA算法对语音进行噪声估计后,分别用维纳滤波法、MMSE-LSA、传统谱减法和多频带谱减法等4种方法进行语音增强前端处理,在基于i-向量的说话人识别系统下进行实验.实验结果表明采用了语音增强的系统具有一定抗噪声性能,并且在高信噪比条件下,基于多频带的谱减法在此系统下性能最佳,而低信噪比情况下MMSE-LSA算法更有优势.
关键词:说话人识别; i-向量; 语音增强; 维纳滤波; MMSE; 谱减法
0引言
说话人识别是一种生物识别技术,通过特定说话人的语音信号来对其身份进行识别,可以作为一种身份认证方式,应用于网络安全、电话侦听和司法鉴定等领域,具有广泛的应用前景,并且每两年美国国家标准技术署(NIST)通过举办NIST说话人识别评测,对当前国际上说话人识别的技术水平进行评估.该技术主要通过对语音信号进行分析、提取特征向量后进行数学建模来实现,早期的说话人识别模型有动态时间弯折(DTW)、矢量量化(VQ)[1]等,而近年来在评测中表现更好的则是以高斯混合模型(GMM)为基础的GMM-UBM(Universal Background Model)[2],以及利用GMM超向量进行估计建模的联合因子分析(JFA)[3]和i-向量[4]模型,并辅以类内协方差规整(WCCN)[5]、概率线性判别分析(PLDA)[6]等信道补偿方法,说话人识别系统的性能在一定的环境条件下,基本可以达到实际应用要求.
然而在实际应用环境中,由于外界的噪声干扰存在,语音质量大大降低,会导致识别准确率受到影响,尤其是在训练和识别的噪声环境不匹配的情况下,系统的性能更会显著降低.为了改善说话人识别系统对噪声的鲁棒性,可以通过语音增强方法消除语音中的噪声,还原被噪声破坏的特征向量从而改善说话人识别系统在噪声失配情况下的识别性能.
通常在说话人识别系统中并不采用语音增强模块,一方面由于实验用的测试语料都是干净语料,一般不包含有噪声,因而处理时无需考虑该问题.另一方面由于说话人识别技术的特性,其对语音处理带来的信号失真十分敏感,如果语音增强算法不能保持语音中说话人的个性特征,整体系统的性能反而会下降.为得到最佳的抗噪声说话人识别系统,对各种语音增强算法在识别系统中的应用效果进行评估,本文作者选择基于最小均方误差准则和谱减法的两种语音增强方法及其相应改进算法,在不同噪声强度下进行测试,得到其对系统识别准确率改善情况的分析和结论,为实际环境下的系统实现提供理论依据.
1系统组成
抗噪声说话人识别的整体系统框图如图1所示.
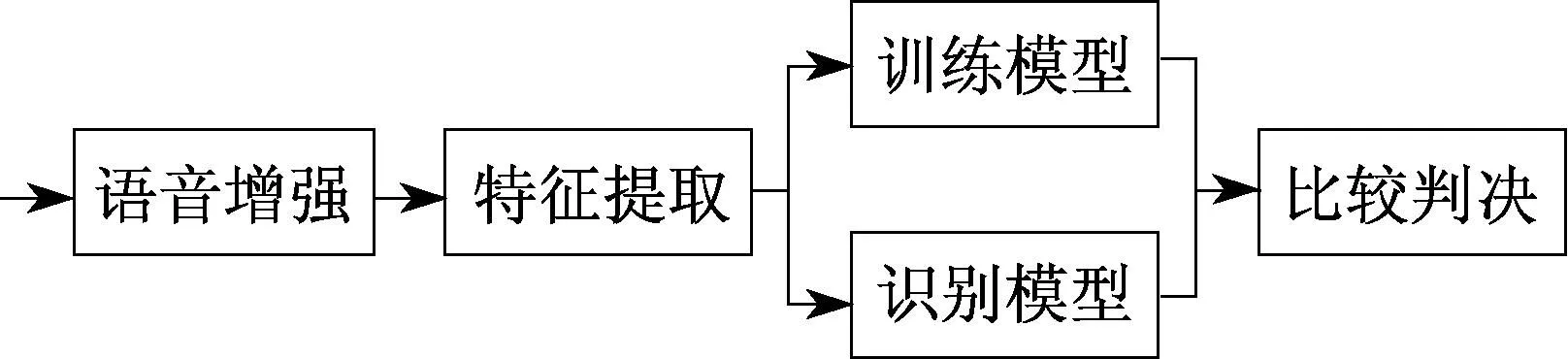
图1 说话人识别系统框图
在一般的说话人识别系统前端加入语音增强预处理模块后,进行Mel-scale Frequency Cepstral Coefficients(MFCC)特征提取,之后分别利用训练和识别语音的特征参数提取i-向量说话人模型,将两个模型比较计算得分,最终得到拒绝或接受的判决结果,下面主要就语音增强、i-向量说话人模型和判决模块进行阐述.
2语音增强
含噪声的语音信号y(t)可表示为:

(1)
其中s(t)为纯净语音信号,n(t)为加性噪声,语音增强的目的就是从带噪信号y(t)中恢复原信号s(t),算法由噪声估计和语音增强两个主要部分组成.由于假设语音为短时平稳信号,通常将语音分帧后在频域内对带噪信号幅度谱或功率谱进行恢复.
2.1噪声估计
单通道语音增强方法需要利用噪声特性参数,在没有先验知识的条件下,噪声的功率谱需要从带噪语音中获得,因而准确的噪声估计算法是提高语音增强效果的关键环节.传统的噪声估计通过语音活性检测(VAD)检测噪声段,对其功率谱进行最优平滑,得到最终噪声估计值,但其对非平稳噪声效果不佳,无法及时跟踪噪声能量的变化.因而采用Cohen[7]提出的改进最小控制递归平均算法(IMCRA)进行噪声估计,在计算语音出现概率的基础上,通过2次平滑和最小值统计来估计噪声功率谱.
2.2语音增强
根据估计的噪声结果,可以通过多种方式计算纯净语音的估计.为寻求最合适的语音增强方法,从维纳滤波法、最小均方误差(MMSE-LSA)、传统谱减法和多频带谱减法4种方法中进行选择,通过仿真实验分析各算法的优劣.
2.2.1维纳滤波法
维纳滤波算法是首先通过对先验信噪比进行估计,基于最小均方误差(MMSE)的判别方法得出谱增益函数后,最后根据式(2)得到纯净语音信号频谱的估计:
(2)
其中ξk,γk分别为先验和后验信噪比,Sk(ω)为纯净语音频谱,Yk(ω)为带噪语音频谱,Gk(ξk,γk)为谱增益函数,由先验信噪比计算得出:
(3)
估计先验信噪比可以通过Ephraim和Malah[8]提出的“直接判决法”(decision-directed)得到:
(4)

2.2.2MMSE-LSA
MMSE-LSA是维纳滤波的改进算法,在对数谱幅度域中进行最小均方误差估计,得到新的谱增益函数,其中v定义为v≜ξkγk/(1+ξk):
(5)
在此方法中,采用Cohen在2004年提出的无关联估计器对先验信噪比进行估计,此估计方法相比于直接判决法能更快速地跟踪噪声水平的突变,并且估计结果更为平滑,从而降低语音增强带来的音乐噪声,详细的估计算法参考文献[9].
2.2.3传统谱减法[10]
谱减法是通过对带噪语音功率谱减去估计的噪声功率谱来达到语音增强的效果,基本公式如下:
(6)
其中a是过减因子,b是谱减系数,过减因子a通过后验信噪比进行自适应的调整,实验中a的调整范围取1~3,b取0.002.谱减法的优势在于实现十分简单快速,适合实时语音增强,然而传统的谱减法缺少对语音频谱特性进行分析假设,因而处理后会对语音的可懂度损伤较大,并且由于频谱相减使处理后的语音中产生一种具有节奏感的残余噪声,称为音乐噪声,对语音的听觉效果影响很大,因而常采用非线性谱减法降低语音失真度并去除音乐噪声.
2.2.4多频带谱减法
考虑到噪声的频谱在整个频域上不均匀分布,多频带谱减法将频率划分为N个频带,对每个子频带计算后验信噪比SNRk,以此为基础调整过减因子a,并添加控制因子δ以调整不同频段的系数,算法公式如下:
(7)
过减因子和控制因子的自适应调整方法分别表示为:
(8)
(9)
频带的划分也有多种方式,经实验验证,按照Bark域进行频带划分的方法要优于线性划分方法[11],因而采用Bark带方式划分频带.
3i-向量说话人模型
i-向量是近年来主流的文本无关说话人建模方法,其基本思想源自JFA中对信道和说话人的子空间估计.Dehak提出的i-向量是利用一个全局变化子空间(Total Variability Space)来表征以上两种特征,其基本假设是将说话人的GMM超向量表示为:

(10)
其中m是与说话人和信道无关的超向量,通常使用UBM的超向量表示,而T是一个低秩的表征全局变化子空间的矩阵,ω是标准正态分布的向量,表征特定说话人在全局变化子空间内的全局因子,因其作为表征说话人身份的矢量(identityvector),所以简称为i-向量.由式(10)可以看出,该建模方式的关键在于对全局变化矩阵T的估计,该矩阵起到对GMM超向量进行降维,同时加强对不同说话人和信道之间的区分性的作用.
全局变化矩阵是通过大量不同说话人语料进行估计的,基本思想与JFA中对说话人子空间和信道子空间的估计相同,通过EM算法对矩阵参数进行迭代计算,但i-向量将说话人和信道特征作为整体,将同一说话人在不同信道下的语段分别估计,因而不需要对说话人进行标记.在得到了全局变化矩阵后,便可从语音特征向量中得到对应的i-向量.详细的T估计算法和i-向量提取方法可参考文献[4].
4判决模块
系统的判决方式采用余弦距离得分[12]的方式,通过计算分别从训练和识别语音中提取的i-向量之间的余弦距离,并与固定阈值θ进行比较得出拒绝或接受的判定结果.余弦距离由式(11)所示:
(11)
该判决方法是一种对称式的核函数分类器,通过归一化消除了矢量幅度变化的影响,实现快速简单,在此系统中能达到与SVM媲美的分类性能.
5测试实验与性能分析
采用NIST08的核心测试集short2-short3作为测试语料进行实验,仅取男性语料进行测试,由290段训练语料和344段识别语料组成共3256个测试.为仿真噪声失配环境,设计的系统在训练端采用原始语音,识别端分别加入不同信噪比的白噪声.说话人识别系统采用MFCC特征提取方式,语音分帧的参数为每帧长20ms,帧移10ms,提取20维倒谱系数,加上一阶和二阶差分共60维作为特征参数,之后用VAD去除非语音帧,用倒谱均值减(CMS)进行特征规整作为最终的特征参数.模型参数方面,GMM混合数为512,i-向量维数为400,UBM和T用NIST06和08剩余的语料进行训练得到.在此基线系统中加入语音增强算法,分别用上述4种语音增强算法对语音进行预处理后再进行说话人识别,得到各噪声条件下的系统等错误率(EER)如表1所示.从表1中可以看出,在无噪声的情况下,i-向量说话人识别系统的EER为2.63%,基本可以满足实际应用的要求.而在噪声失配的情况下,系统的识别性能显著降低,并且随着信噪比的降低,系统整体识别率也成比例地下降.随着语音增强前端处理算法的引入,系统的识别性能能够得到一定的改善,然而不同的语音增强算法带来的效果也不尽相同.在信噪比相对较高时,即5dB情况下,无增强的系统恶化到18.86%,而加了多频带谱减法增强模块后,可以达到15.32%,尽管还很不理想,但也改善了3.54%的EER.而随着噪声能量的不断增大,噪声估计的准确率下降,导致以谱减法为基础的语音增强算法效果愈发下降,而以最小均方误差准则的增强方法由于考虑到语音的分布情况,使得抗噪声效果愈发明显,在低信噪比为-5dB条件下,MMSE-LSA算法比起其他算法,有较显著的性能提升,与无增强系统相比,可以降低6.14%的EER.同时值得注意的是,传统谱减法由于在语音增强的同时引入了较强的残留音乐噪声,并且由于过减因子没有自适应变化而导致一定的语音失真,其识别率反而比不使用增强算法的系统更低,说明语音增强算法应谨慎选择,否则会使系统性能进一步退化.

表1 噪声环境下各语音增强算法识别结果
6结论
本文作者针对噪声失配环境下的说话人识别,利用语音增强模块结合i-向量说话人模型来改善系统整体性能,同时对常用的四种语音增强算法在系统中的表现进行实验评估,以求找到最佳的前端处理算法.从实验结果来看,合适的语音增强算法确实可以改善说话人识别系统的性能,但必需根据不同的信噪比情况有针对性地选择.实验结果表明,在多频带谱减法和MMSE-LSA两种算法中如果能根据具体环境合理使用,可以获得较佳的系统抗噪声性能.
参考文献:
[1]Zhang Q.Research on target speaker identification system under noise environment [D].Wuhan:Wuhan Textile University,2012.
[2]Togneri R,Pullella D.An overview of speaker identification:Accuracy and robustness issues [J].Circuits and Systems Magazine IEEE,2011,11(2):23-61.
[3]Kenny P.Joint factor analysis of speaker and session variability:Theory and algorithms [R].Montreal:CRIM,2005.
[4]Dehak N,Kenny P,Dehak R,et al.Front-end factor analysis for speaker verification [J].Audio,Speech,and Language Processing,IEEE Transactions on,2011,19(4):788-798.
[5]Hatch A O,Kajarekar S S,Stolcke A.Within-class covariance normalization for SVM-based speaker recognition [C]//DBLP.INTERSPEECH 2006 and 9th International Conference on Spoken Language Processing-ICSLP.Pittsburgh:DBLP,2006.
[6]Kenny P.Bayesian Speaker Verification with Heavy-Tailed Priors [C]//ISCA.Proceedings of the Odyssey Speaker and Language Recognition Workshop.Bruno:ISCA,2010.
[7]Cohen I.Noise spectrum estimation in adverse environments:Improved minima controlled recursive averaging [J].Speech and Audio Processing IEEE Transactions on,2003,11(5):466-475.
[8]Ephraim Y.A minimum mean square error approach for speech enhancement [C]//IEEE.Acoustics Speech and Signal Processing.Albuquerque:IEEE,1990.
[9]Cohen I.Speech enhancement using a noncausal a priori SNR estimator [J].Signal Processing Letters,IEEE,2004,11(9):725-728.
[10]Berouti M,Schwartz R,Makhoul J.Enhancement of speech corrupted by acoustic noise [C]//IEEE.Acoustics Speech and Signal Processing IEEE International Conference on ICASSP′79.Washington,D.C:IEEE,1979.
[11]Cheng Z,Zhao H M.Speech enhancement based on spectral subtraction of multi-band scale [J].Computer Engineering and Applications,2007,43(36):40-42.
[12]Dehak N,Dehak R,Glass J R,et al.Cosine Similarity Scoring without Score Normalization Techniques [C]//Deleon P,Pucher M,Yamagishi J.Proceedings of the Odyssey Speaker and Language Recognition Workshop,Brno:Odessey,2010.
(责任编辑:包震宇)
Speech enhancement ini-vector speaker verification system
LI Xin,LI Wei, YOU Hanxu, ZHU Jie
(School of Electronic Information and Electrical Engineering,Shanghai Jiao Tong University,Shanghai 200240,China)
Abstract:To solve the model-mismatch problem in text-independent speaker verification system when training environment differs from recognition environment,We propose a i-vector speaker verification system using speech enhancement in front-end preprocessing it can improve the system robustness to additive noise.To estimate the performance of different speech enhancement methods,we used NIST08 core test set in the experiment.Four speech enhancement methods,including wiener filtering,MMSE-LSA,traditional spectral subtraction and multi-band spectral subtraction,combining with IMCRA noise estimation,were evaluated in the speaker verification system based on i-vector.The result shows the proposed system with speech enhancement had some improvement in noise environment and that multi-band spectral subtraction method performed the best when SNR was relatively high and MMSE-LSA performed the best when SNR was low.
Key words:speaker verification; i-vector; speech enhancement; wiener filtering; MMSE; spectral subtraction method
中图分类号:TN 912.32
文献标志码:A
文章编号:1000-5137(2016)02-0237-06
通信作者:朱杰,中国上海市闵行区东川路800号,上海交通大学电子信息与电气工程学院,邮编:200240,E-mail:zhujie@sjtu.edu.cn
基金项目:国家自然科学基金(61271349,61371147,11433002);上海交通大学医工合作基金(YG2012ZD04)
收稿日期:2016-02-29
