论训练样本集结构和稀疏表示分类算法的关系
2016-05-23向顺灵广西民族大学信息科学与工程学院广西南宁530006
向顺灵(广西民族大学信息科学与工程学院,广西南宁,530006)
论训练样本集结构和稀疏表示分类算法的关系
向顺灵
(广西民族大学信息科学与工程学院,广西南宁,530006)
摘要:近年来,基于表示法的人脸识别技术主要都集中在约束条件和字典学习。很少有研究用样本数据特征来确定基于表示分类算法的性能。本文定义了结构离散度,表示样本集的结构特征。实验结果表明,具有较高的结构离散度的集合能让一个分类算法获得更高的识别率。
关键词:模式识别;人脸识别
0 引言
1 SRC和训练样本集的结构关系
在基于标准的分类算法中,训练样本集的整除是影响分类结果的重要因素。标准也是衡量样本集可分性的重要指标。在不同的公共人脸数据库中,许多实验表明,标准在基于稀疏表示分类方法上不是有利的。事实上,样本集的过度聚集包含了高类内离散度(within-class scatter),因此,这个样本集的稀疏表示能力将严重减弱,低类内离散度中的一组样本向量集通常不能跨越高类内离散度中的更大向量空间。例如,两个样本集中的一个样本的离散度明显高于单个样本;那么两个样本的稀疏表示能力比单个样本强。这个事实就可以解释为什么当训练样本越多,基于稀疏表示的分类算法能获得较高的识别率。
因此,样本高类内离散度对基于稀疏表示的分类算法是有益的。设人脸图像的调整大小为,像素值为。人脸图像空间是有限距离。随着样本类内离散度(within-class scatter)的增加,样本类间离散度(between-class scatter)随之减少。最后,我们假设训练样本集,其中代表的是第类数据集,表示类的数量,是类样本的数量。定义如下:
总样本集的类内离散度的定义:

图1 结构离散的曲线和不同人脸数据的识别率
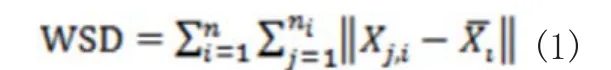
样本集的类间离散度的定义:
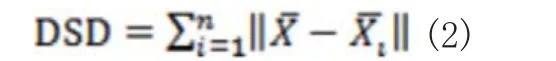
其中表示样本集中类的均值,是总样本集中所有训练样本的均值。而且,样本集的结构离散度定义为:
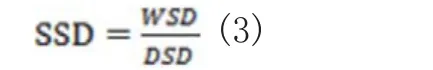
以上分析得出样本结构离散度中高类内离散度可能是影响SRC算法性能的原因。下面通过实验分析进一步验证这个结论。
2 实验结果及分析
为了进一步验证结构离散和基于稀疏表示分类算法之间的关系,我们选用AR;FERET;extended Yale B作为人脸基准数据集。实验表明训练样本集的增加超过某个固定值时,大多数基于稀疏表示分类的识别率不可能明显的提高。本文从人脸基准数据集中选择2到4个样本。
实验环境为:Window XP,随机存取存储器(Ramdom Access Memory,RAM)大小为:3.25GB;CPU频率为:3.16GHz,使用的软件为:MATLAB。结构离散作为水平轴,正确的识别率作为垂直轴。如图1所示:
图1中的直线是拟合线,对应的是有序对集的线性回归;曲线是训练样本集SSD的识别率变化,图1可看出结构离散越高,分类算法得到越高的正确识别率。因此,可以得到结论:训练样本集中的结构离散度越高对基本稀疏表示的识别算法越有利。
3 结束语
本文通过实验分析得到训练样本集中的结构离散越高,基于稀疏表示的分类算法的识别率越高。正确的识别率是人脸识别中重要的标准。选择合理的训练样本集数量和高结构离散可以有效地提高正确识别率。
参考文献
[1]D.Lowe.Distinctive image features from scale-invariant key-points.International Journal of Computer Vision.2004,60(2): 91-110.
[2]T.Ojala,M.Pietikainen,and D.Harwood. A comparative-study of texture measures with classi cation based on feature distributions.Pattern Recognition,1996,29(1):51-59.
[3] Wright,J.,Yang,A.,Ganesh,A.,Sastry,S.,Ma, Y.: Robust face recognition via sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2): 210-227.
[4] Martinez,A.:The ar face database.CVC Technical Report 24 (1998)
[5] A.P.J.Phillips,H.Moon,P.J.Rauss,S.Rizvi, The FERET evaluation methodology for face recognition algorithms,IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22 (10):1090-1104.
[6]L.Chen,H.Man,A.V.Nefian.Face recognition based on multiclass mapping of Fisher scores.Pattern Recognition 38(2005):799-811.
向顺灵(1989-),女,硕士研究生,研究方向为图像处理、视频处理;
Relationship between the representation-based classification algorithm and structure of the training sample set
Xiang Shunling
(School of information science and engineering, Guangxi University For Nationalities, Nanning, Guangxi 530006)
Abstract:In recent years,representation-based face-recognition techniques are focus mainly on constraint conditions and dictionary learning. Few researchers study which sample data features determine the performance of representation-based classification algorithms.we define the structure-scatter degree, which represents the structure features of training sample sets, said structure characteristics of sample set. Experimental results show that sets with a higher structure scatter more likely allows a classification algorithm to obtain a higher recognition rate.
Keywords:Pattern recognition;Face recognition
通讯作者:向舜然(1987-),男,讲师,重庆市城市管理职业学院
作者简介
中图分类号:TP319
文献标识码:A
人脸识别已经发展成为计算机视觉领域中一个活跃的研究课题,其中子空间方法(subspace method)主要是将高维数据向低维特征空间转变。在这个过程中,将原来样本中的信息嵌入到少量的特征向量中,这其中包括一些对分类有利和不利的信息。因此有了局部特征提取的方法,如尺度不变特征变换(Scale invariant feature transform,SIFT),局部二值特征(local binary pattern,LBP),基于稀疏表示的分类(Sparse Representation-based Classification, SRC)对人脸分类有较好的效果。但是经过实验分析,在同一人脸数据库中,不同的训练样本集可能会引起相同的算法,并得到完全不同的识别率。最直观的原因就是不同的训练样本集中的不同结构分布,从而影响算法性能。
