踪迹聚类下组织实体的重要度排序方法
2016-05-14徐涛孟野
徐涛 孟野

摘要:针对简单套用交接网络等社会网络分析方式不能很好地反映踪迹聚类生成的一系列流程的组织实体的重要度的问题,提出了一种踪迹聚类下组织实体的重要度排序方法。首先,对于参与踪迹聚类生成的一系列流程的组织实体构建踪迹聚类与组织实体关系网络;其次,定义基于踪迹聚类与组织实体关系网络的节点重要度评估方法;最后,对踪迹聚类下的各个组织实体节点计算其在关系网络中的重要度评分并排序。实验结果表明,所提方法构建的关系网络相比踪迹聚类下的交接网络能够更准确地反映组织实体的实际重要度;与基于拓扑势的网络社区节点重要度排序算法相比,所提方法的节点重要度排序结果更符合实际业务流程,能更好地区分关系网络中重要度不同的节点。
关键词:流程挖掘;组织挖掘;重要度排序;社会网络;复杂网络
中图分类号:TP391.4 文献标志码:A
Abstract: Aiming at the issue that the social network analysis method like handover network cannot express the importance of organizational entities precisely, a method to sort the quantified importance of organizational entities organized under the trace clusters was proposed. Firstly, a relation network was constructed to describe the relationship between trace clusters and organizational entities; secondly, a quantitative assessment of the nodes importance of this network was defined; finally, all these nodes were sorted respectively according to their quantified importance. The experimental results show that this relation network can express the actual importance of organizational entities more precisely than the handover network generated by trace clustering. Compared to the importance sorting algorithm of network community nodes based on topological potential, the proposed method is more suitable for the actual business processes, meanwhile it can distinguish distinct organizational entities better than the importancesorting algorithm based on topological potential.
Key words:process mining; organizational mining; importance sorting; social network; complex network
0 引言
业务流程运行数据往往来自于企业信息系统生成的业务流程日志,而流程挖掘(process mining)技术可以提取流程日志中的有用信息用于流程分析,并重现业务流程的真实过程,为管理者提供流程运行的知识[1-2]。流程挖掘通过分析流程日志中的任务、 参与者和时间等数据,结合工作流管理和数据挖掘等相关技术,从控制流、组织结构等角度提取流程运行的知识,利用这些知识可以发现业务执行与企业战略目标的偏差、流程瓶颈、组织之间的低效率协作等问题,从而对业务流程进行优化[3]。
业务流程日志包含了一系列业务流程实例(instance)。业务流程实例可以表示为业务流程开始到结束所调用的活动的序列,这种活动序列又被称作踪迹(trace),而组成踪迹的活动又对应着不同的组织实体[1,4]。组织实体根据不同级别可分为执行活动的企业部门、员工等,是企业组织结构的组成部分。因此,既可以通过流程挖掘算法挖掘踪迹所可能表示的流程模型,又可以采用社会网络分析方法挖掘踪迹中活动对应的组织实体的交接网络(handover network)等关系网络[1,5]。通常情况下,流程模型的发现与组织挖掘是各自独立的。
组织挖掘能够发现组织实体之间的协作关系和组织实体在流程中的重要性。文献[5]对某医疗流程中的医务人员进行模块化的社区挖掘,每次迭代都计算社区聚类结果的模块化程度,最后将模块化最高的聚类作为团体聚类结果,从而得到团体内部协作紧密,而团体之间的协作关系松散的社区。绘制此医疗流程的社交图谱,对同一社区的医务人员进行统一着色,通过人员节点间的连线体现医务人员、团体之间的协作程度,从而分析得出应适当增加对急救科的人员分配,以适应急救环节在社交图谱中所体现的中心地位,避免因人员不足影响整个流程的效率。
文献[6]使用聚类算法分析了知识维护业务中员工之间的知识层次结构。将交接网络中,入度为0的节点的知识层次视为最低,出度为0的节点的知识层次视为最高,具有相同前驱和后继节点的节点视为处于同一领域的同一知识层次。但该方法的挖掘结果与目标单位的组织结构对比往往存在较大不同,且该方法对普通员工在知识层次结构中的专业知识水平估计过高,与实际情况存在差异。文献[7]提出基于社会网络分析的员工自动组合方法,定义关键贡献者、影响者和协调者三种特殊的社交角色,并分别通过度中心性、向量中心性、中间中心性对员工的重要性进行度量。
企业实际业务流程日志往往表现出结构化程度低的特点。传统的流程挖掘算法在处理这类低结构化流程时易生成结构复杂且难于理解的流程模型,其原因在于这类流程挖掘算法难以为处于低抽象层次的流程日志指定合适的抽象层次,而踪迹聚类是解决这一问题的方式之一[8]。对踪迹聚类后,意味着各类踪迹所代表的实例之间具有相关性,因此可采用分治的策略将原始日志的流程模型表示为一系列结构复杂度较低且易于理解的流程模型。踪迹聚类解决了直接对原始日志进行流程挖掘时流程模型难以理解的问题,但同时,踪迹聚类也相应对组织实体生成的社会网络构成了一种新的社区划分,简单套用元日志的社会网络分析方法时,组织实体的实际重要度不能被准确地表示。
本文提出一种基于踪迹聚类的组织实体关系网络的组织实体重要度排序方法,依照踪迹聚类结果划分该关系网络的社区,并对组织实体在不同社区内的重要度进行度量。通过组织实体在不同社区中重要性的度量,对社区进行区分和理解,同时,通过社区内部组织实体的排序,体现社区内实体的差异性,为针对组织结构的真实情况开展流程优化提供帮助。
1 踪迹聚类方法
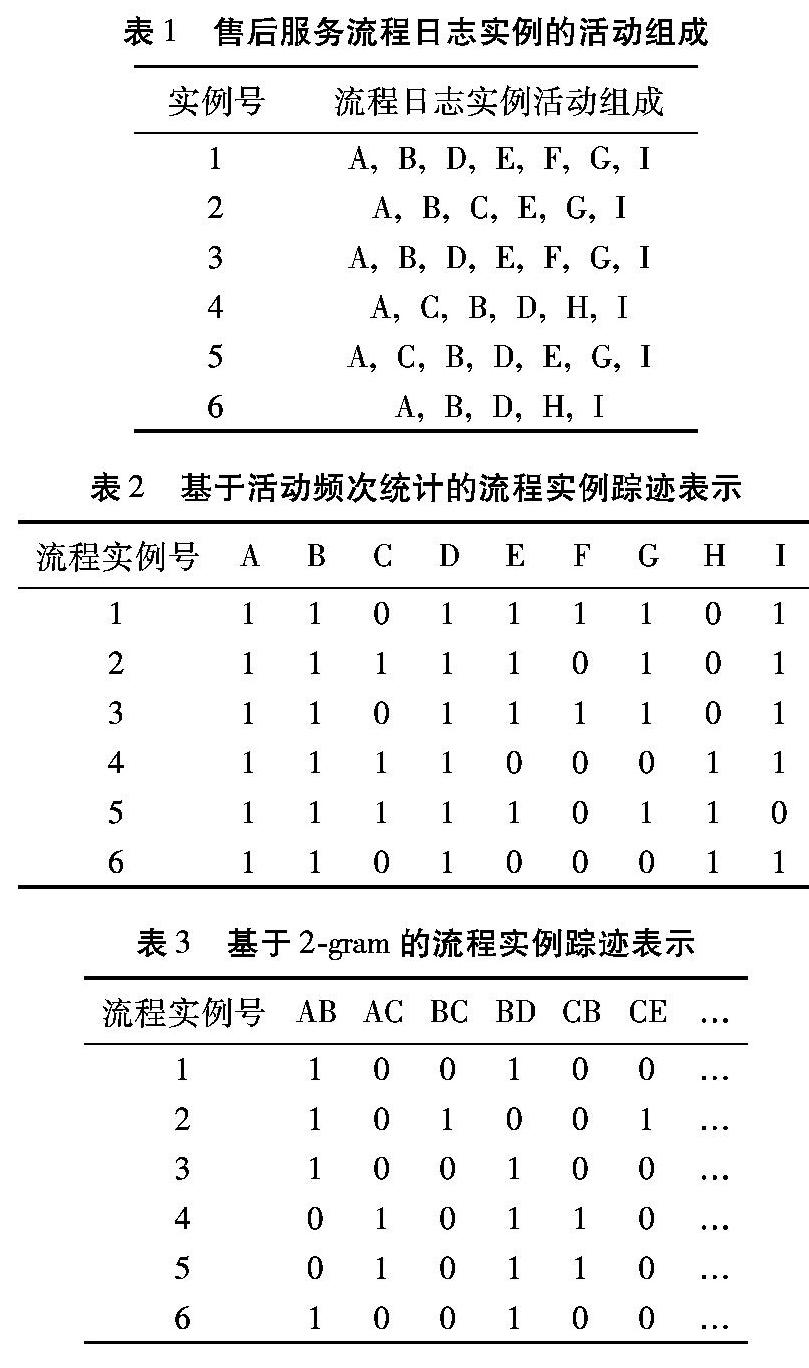
踪迹聚类结果通过对流程日志的踪迹进行聚类得到,为了得到有意义的踪迹聚类结果,需对踪迹进行量化表征,并确定不同踪迹间的相似性度量方式。以某产品售后服务流程为例,日志表1是某产品售后服务流程日志中流程实例的活动组成,表中组成流程实例的活动由大写字母表示,A代表收到返回产品与保修请求,B代表检查产品,C代表核对保单,D代表通知客户,E代表修理产品,F代表测试修理后的产品,G代表收取修理费,H代表发送取消保修请求,I代表返回该产品。文献[8]通过统计流程日志实例的活动频次,构建踪迹表示向量,并采用K均值、凝聚层次聚类(Agglomerative Hierarchical Clustering,AHC)、自组织映射(SelfOrganizing Map,SOM)等方法进行踪迹聚类。表2是对表1流程日志中踪迹进行活动频次统计后的踪迹表示结果,可以加入组织结构成员等统计信息进一步扩展踪迹表示向量。文献[9]基于上下文感知对踪迹进行距离,该文献引入ngram模型构建踪迹表示向量。表3是引入2gram模型后,售后服务流程日志的踪迹表示结果。文献[10]将踪迹表征为踪迹中最大重复集合(maximal repeat set)等特征集合出现频次的向量。
上述踪迹聚类方法的思路均为通过构建踪迹表示向量对踪迹进行量化,将踪迹聚类问题转化为一般性的聚类问题,并用成熟的聚类算法求解。本文引入文献[11-12]的混合概率模型估计踪迹属于各类簇的概率,用概率估计结果构建踪迹表示向量; 并采用文献[13]的球面K均值算法(spherical Kmeans)进行踪迹聚类,将踪迹聚类所得聚类结果应用于后续的组织实体重要度排序中。
2 复杂网络节点重要度评估方法
对业务流程应用组织挖掘得到社会网络后,可发现其节点多为流程日志中出现的各组织实体。因此复杂网络节点的重要度评估方法对组织实体的重要度评估有重要参考价值。复杂网络节点重要度评估方法主要有中心性指标、基于最短路径和基于凝聚度等。文献[14]定义一种基于复杂网络凝聚度的节点重要度评估方法,将网络凝聚度定义为节点数与平均路径长度乘积的倒数,但这种方法不适合用于加权网络。文献[15]定义一种基于拓扑势的网络社区节点重要度排序算法,该算法考虑到单纯计算拓扑势并不能真正说明节点在网络中的重要性,因此将社区中起不同作用的节点区分为内部节点和边界节点,计算各节点拓扑势后,再连接内部节点和边界节点排序结果。文献[16]提出了一种评估加权复杂网络节点重要度方法,该方法以最短路径为基础,综合考虑了节点的连接度和节点在网络中的位置,并重新定义了加权网络D=(V,E)的凝聚度(D)为:
3 踪迹聚类下的组织实体重要度排序
对踪迹聚类得到的子业务流程而言,负责流程关键环节组织实体,往往有较高的流程实例参与频次,并与其他个体有着更多交互与合作。所以可建模基于踪迹聚类与组织实体关系网络,将组织实体的流程实例参与频次量化为组织实体的重要度,并根据组织实体的实际情况,为组织实体设置合适的权重,从而综合地进行评估。
3.1 相关定义
传统社会网络分析方法较少利用组织实体在踪迹聚类得到的子业务流程中的参与度等信息,为此可建立定义如下:
4 实验验证与分析
本文选用国内某大型枢纽机场的流程日志数据集进行实验。对日志数据集进行预处理后结果如下:数据集共有流程实例记录2006条,踪迹540条;流程日志的组织实体分为部门、角色和资源三个级别,其中部门10个、角色20个、资源500人。进行踪迹聚类后,抽取其中的某一类簇对应的流程日志进行实验,该类簇的实际含义为机场的机位分配业务流程。
4.1 实验评价指标
为了验证本文方法的合理性,选择资源级别与角色级别的组织实体分别进行基于踪迹聚类与组织实体关系网络下组织实体重要度排序实验。选用节点度(node degree)直观观察节点在网络中的地位,并简明地对网络节点进行排序。同时,考虑到度中心性指标是衡量网络节点重要性最为广泛采用的方法 [17-18];且网络节点的重要度不仅和节点局部重要性有关,而且与其在网络中所处位置以及节点之间的相互依赖程度密切相关[19-20]。因此,选用度中心性指标中的接近中心性(closeness centrality)与中介中心性(betweeness centrality)对节点进行进一步的评估,并通过与重要度排序结果的对比验证方法的有效性。
4.2 组织实体重要度排序实验
4.2.1 实验1
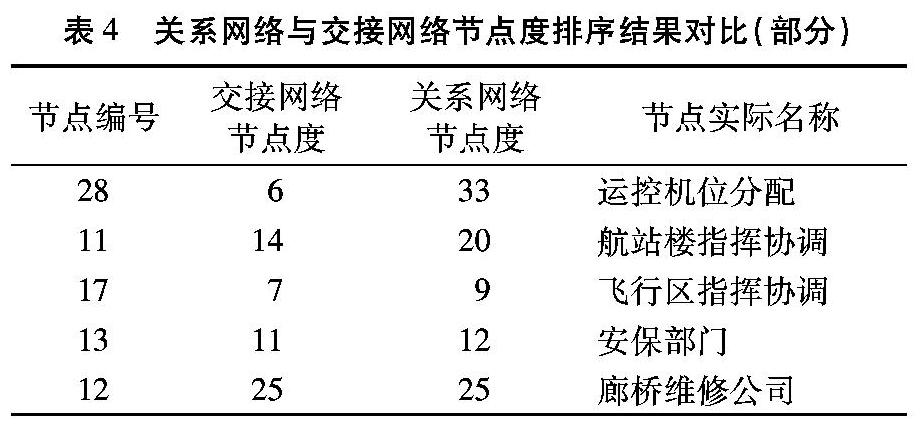
将角色级别的基于踪迹聚类与组织实体关系网络节点排序结果与踪迹聚类下交接网络节点的排序结果进行对比,选取具有代表性的五个节点的排序结果如表4所示。踪迹聚类下交接网络节点度最大的节点为12号节点,对应实际组织实体为驻场单位之一的廊桥维修公司。由于机位分配流程涉及到对廊桥的安排,因此廊桥维修会依照机场运行控制相关角色的指令,频繁进行维修、待命等活动,在本例的踪迹聚类下的交接网络中,廊桥维修公司的节点度为25,高于其他角色;运行控制中心下属的机位分配部门作为整个机位分配流程的中枢,需要对下属角色下达指令,这类活动不需要频繁进行,导致该节点度仅为6,其在交接网络中的地位与实际情况有较大偏差。而基于踪迹聚类与组织实体关系网络中,各节点的节点度排序与实际情况较为符合,说明基于踪迹聚类的组织实体关系网络能够比踪迹聚类下的交接网络更好地体现网络中组织实体的实际情况。
4.2.2 实验2
继续对角色级别的组织实体进行重要度排序实验,结果如表5所示。重要度评分较高的3个节点为28号节点、11号节点与17号节点,分别对应了机位分配流程中的运控机位分配、航站楼指挥协调、飞行区指挥协调角色。节点28、11在关系网络中的中心性指标与重要度评分相吻合,节点17的中心性指标较低。对流程日志统计发现,节点17参与的全部33个流程实例中,节点28或节点11也一同参与的实例个数达到了26个,且不存在其他频繁出现的节点。 因此,节点17在中心性指标较低的情况下得到了较高的重要度评分。
4.2.3 实验3
进一步对资源级别的组织实体进行重要度排序实验,结果如表6所示。可以看出重要度评分最高的155号节点的在度、接近中心性、中介中心性三项指标均有较高的值,证明该方法在推广到数量更多的资源级别关系网络时,也能较好地反映节点在关系网络中的重要度。
4.2.4 实验4
选用文献[15]基于拓扑势的网络节点重要度排序算法对角色级别组织实体进行重要度排序,其中算法的影响因子σ取优化值1.0203[21]。文献[15]算法所得重要度排序结果与本文算法排序结果的比较如表7所示。该算法所得排序结果中,重要度评分最高的节点与本文算法同为对应运控机位分配的28号节点,对应廊桥维修公司的12号节点的重要度评分为0.067639,高于对应航站楼指挥协调的11号节点的0.062033;对应安保部门的13号节点的重要度评分为0.053064,高于对应飞行区指挥协调的17号节点的0.049701。而廊桥维修公司与安保部门作为机场具体业务的实施角色,在实际的机位分配业务流程中,其重要程度不足以与负责指挥协调的航站楼指挥协调以及飞行区指挥协调两大指挥角色相提并论。此外,该算法计算得到的节点重要度评分结果中,评分值同为0.040732的有6个节点,评分值同为0.041853的有3个节点,造成一些重要度评分值相同节点的重要度难以区分。该算法在反映节点的重要度时强调网络中节点的局域连接密集程度的重要性,因此在空手道俱乐部网络以及海豚关系网络上实现了网络中社区内节点的有效区分,取得了较好的实验结果。但该算法不能很好地体现节点在整个网络或整个社区的地位,算法的组织实体排序结果虽然能够根据业务流程关系网络中节点的拓扑势找出业务流程中的最重要组织实体节点,但对于一些次重要的节点并不能很好地反映其实际重要度;同时,该算法在评价节点的重要度时,依赖于节点拓扑势的计算,因此当网络中存在局域连接密集程度相近的节点,易得到相同的节点重要度评分,此时相同评分节点的重要度便变得难以区分。而本文算法在构造关系网络后,通过踪迹聚类信息进行社区划分,得到的排序结果与实际业务流程更为一致;同时由于加入了踪迹聚类信息,对于局域连接密集程度相近节点的重要度也能够根据踪迹聚类的社区划分计算出不同的评分从而加以区分。
5 结语
本文针对传统社会网络分析方法对踪迹聚类得到的业务流程进行组织挖掘时表现不佳的问题,提出了一种基于踪迹聚类与组织实体关系网络的组织实体重要度排序方法,通过建模踪迹聚类与组织实体间的关系网络,对关系网络中的组织实体节点进行重要度评分的计算,从而对不同踪迹聚类下各级别的组织实体进行重要度排序。实验表明组织实体的重要度排序结果能够反映为关系网络在节点中的重要度排序,从而解决前述问题,并有助于对踪迹聚类结果的理解。
参考文献:
[1]van der AALST W M P. Process Mining: Discovery, Conformance and Enhancement of Business Processes[M]. Berlin: Springer Science & Business Media, 2011: 11-16.
[2]ROZINAT A, de JONG I S M, GUNTHER C W, et al. Process mining applied to the test process of wafer scanners in ASML[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews, 2009, 39(4): 474-479.
[3]van der AALST W M P, ADRIANSYAH A, de MEDEIROS A K A, et al. Process mining manifesto[C]// Proceedings of the 10th International Conference on Business Process Management. Berlin: Springer, 2012: 169-194.
[4]van der AALST W M P, DUSTDAR S. Process mining put into context[J]. IEEE Internet Computing, 2012, 16(1): 82-86.
[5]FERREIA D R, ALVES C. Discovering user communities in large event logs[C]// Proceedings of the 7th International Workshop on Business Process Intelligence. Berlin: Springer, 2012: 123 -134.
[6]LI M, LIU L,YIN L, et al. A process mining based approach to knowledge maintenance[J]. Information Systems Frontiers, 2011, 13(3): 371-380.
[7]LIU R, AGAWAL S, SINDHGATTA R R, et al. Accelerating collaboration in task assignment using a socially enhanced resource model[C]// Proceedings of the 11th International Conference of Business Process Management. Berlin: Springer, 2013, 8094: 251-258.
[8]SONG M, GUNTHER C W, van der AALST W M P. Trace clustering in process mining[C]// Proceedings of the 7th International Conference on Business Process Management. Berlin: Springer, 2009: 109-120.
[9]BOSE R P J C, van der AALST W M P. Context aware trace clustering: towards improving process mining results[C]// Proceedings of the 2009 SIAM Data Mining Conference. Philadelphia: SIAM, 2009: 401-412.
[10]BOSE R P J C, van der AALST W M P. Trace clustering based on conserved patterns: towards achieving better process models[C]// Proceedings of the 8th International Conference on Business Process Management. Berlin: Springer, 2010: 170-181.
[11]SUN Y, HAN J, ZHAO P, et al. RankClus: integrating clustering with ranking for heterogeneous information network analysis[C]// Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology. New York: ACM, 2009: 565-576.
[12]SUN Y, YU Y, HAN J. Rankingbased clustering of heterogeneous information networks with star network schema[C]// Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2009: 797-806.
[13]ZHONG S. Efficient online spherical kmeans clustering[C]// Proceedings of the 2005 IEEE International Joint Conference on Neural Networks. Piscataway, NJ: IEEE, 2005: 3180-3185.
[14]谭跃进,吴俊,邓宏钟.复杂网络中节点重要度评估的节点收缩方法[J].系统工程理论与实践,2006,26(11):79-83.(TAN Y J, WU J, DENG H Z. Evaluation method for node importance based on node contraction in complex networks[J]. Systems Engineering — Theory & Practice, 2006, 26(11): 79-83.)
[15]张健沛,李泓波,杨静,等.基于拓扑势的网络社区结点重要度排序算法[J].哈尔滨工程大学学报,2012,33(6):745-752.(ZHANG J P, LI H B, YANG J, et al. An importancesorting algorithm of network community nodes based on topological potential[J]. Journal of Harbin Engineering University, 2012, 33(6): 745-752.)
[16]朱涛,张水平,郭茂潇,等.改进的加权复杂网络节点重要度评估的收缩方法[J].系统工程与电子技术,2009,31(8):1902-1905.(ZHU T, ZHANG S P, GUO M X, et al. Improved evaluation for node importance based on node contraction in weighted complex networks[J]. Systems Engineering and Electronics, 2009, 31(8): 1902-1905.)
[17]CHEN D, LU L, SHANG M, et al. Identifying influential nodes in complex networks[J]. Physica A: Statistical Mechanics and its Applications, 2012, 391(4): 1777-1787.
[18]陈静,孙林夫.复杂网络中节点重要度评估[J].西南交通大学学报,2009,44(3):426-429.(CHEN J, SUN L F. Evaluation of node importance in complex networks[J]. Journal of Southwest Jiaotong University, 2009, 44(3): 426-429.)
[19]赵毅寰,王祖林,郑晶,等.利用重要性贡献矩阵确定通信网中最重要节点[J].北京航空航天大学学报,2009,35(9):1076-1079.(ZHAO Y H, WANG Z L, ZHENG J, et al. Finding most vital node by node importance contribution matrix in communication networks[J]. Journal of Beijing University of Aeronautics and Astronautics, 2009, 35(9): 1076-1079.)
[20]周漩,张凤鸣,李克武,等.利用重要度评价矩阵确定复杂网络关键节点[J].物理学报,2012,61(5):050201.(ZHOU X, ZHANG F M, LI K W, et al. Finding vital node by node importance evaluation matrix in complex networks[J]. Acta Physica Sinica, 2012, 61(5): 050201.)
[21]淦文燕,赫南,李德毅,等.一种基于拓扑势的网络社区发现方法[J].软件学报,2009,20(8):2241-2254.(GAN W Y, HE N, LI D Y, et al. Community discovery method in networks based on topological potential[J]. Journal of Software, 2009, 20(8): 2241-2254.)
