基于用户兴趣和社交信任的聚类推荐算法
2016-05-14肖晓丽钱娅丽李旦江谭柳斌
肖晓丽 钱娅丽 李旦江 谭柳斌


摘要:个性化推荐系统中使用最广泛的算法是协同过滤算法,针对该算法存在的数据稀疏和扩展性差问题,提出了一种基于用户兴趣和社交信任的聚类推荐算法。该算法首先基于聚类技术根据用户评分信息将具有相同兴趣的用户聚为一类,并建立基于用户兴趣相近的邻居集合。为了提高兴趣相似度计算的准确性,采用了修正余弦计算公式来消除评分标准的差异问题。然后,引入信任机制,通过定义直接信任、间接信任、传递路径和计算方法来度量社交网络用户之间隐含的信任值,将社交网络转换为信任网络,依据信任程度来创建基于社交信任的邻居集合。通过加权的方式将基于两种邻居集合的预测值融合起来为用户产生项目的推荐。在Douban数据集上进行仿真实验,确定了最优的协调因子值和分类数值,并与基于用户的协同过滤算法和基于信任的推荐算法进行对比,实验结果表明,所提算法的平均绝对误差(MAE)减少了6.7%,准确率(precision)、覆盖(recall)和F1值分别增加了25%、40%和37%,有效提高了推荐系统的推荐质量。
关键词:协同过滤;数据稀疏;社交信任;聚类技术;信任网络
中图分类号:TP391.1 文献标志码:A
Abstract:Collaborative filtering algorithm is the most widely used algorithm in personalized recommendation system. Focusing on the problem of date sparseness and poor scalability, a new clustering recommendation algorithm based on user interest and social trust was proposed. Firstly, according to user rating information, the algorithm divided users into different categories by clustering technology, and set up a user neighbor set based on interest. In order to improve the accuracy of the calculation of interest similarity, the modified cosine formula was used to eliminate the difference of user scoring criteria. Then, the trust mechanism is introduced to measure implicit trust value among users by defining the direct trust calculation method and indirect trust calculation method, converted a social network to a trust network, and set up a user neighbor set based on trust. Finally, this algorithm combined the predictive value of two neighbor sets to generate recommendations for users by weighting method. The simulation experiment was carried out to test the performance on Douban dataset, found suitable value of α and k. Compared with collaborative filtering algorithm based on users and recommendation algorithm based on trust, the Mean Absolute Error (MAE) decreased by 6.7%, precision, recall and F1 increased by 25%,40% and 37%. The proposed algorithm can effectively improve the quality of recommendation system.
Key words:collaborative filtering; date sparseness; social trust; clustering technique; trust network
0 引言
随着Web 2.0时代的到来,互联网上的资源与信息迅速膨胀,用户很难在海量信息中获得对自己有用的信息[1]。解决这类问题最有效的工具就是个性化推荐系统,它通过分析用户的喜好,为用户推荐其感兴趣的信息,从而节省筛选信息的时间[2]。
个性化推荐系统中使用最广泛的算法是协同过滤算法,该算法需计算目标用户(或项目)与全体用户(或项目)之间的相似度,随着用户和项目的增加,数据稀疏和扩展性差问题成为影响推荐系统推荐质量的关键因素[3-4]。为了解决此问题,许多学者引入聚类技术对协同过滤算法进行优化,如尹航等[5]提出的采用聚类算法优化的k近邻协同过滤算法,王明佳等[6]提出的基于模糊聚类的协同过滤算法,孙辉等[7]提出的一种相似度改进的用户聚类协同过滤推荐算法,吴湖等[8]提出的两阶段联合聚类协同过滤算法,王雪蓉等[9]提出的用户行为关联聚类的协同过滤推荐算法。上述方法在一定程度上改善了数据稀疏问题对推荐精度的影响;然而传统的协同过滤算法及其改进算法都是利用用户评分信息计算用户之间的相似度[10],在用户评分信息不足的情况下不能够得到准确的推荐结果。
用户之间的信任关系作为社交网络中一个重要信息,为系统推荐提供了依据[11],许多学者在这个方面进行了研究,如邹本友等[12]提出的基于用户信任和张量分解的社会网络推荐,张富国[13]提出的用户多兴趣下基于信任的协同过滤算法,王兴茂等[14]提出的基于一跳信任模型的协同过滤推荐算法,杨兴耀等[15]提出的基于信任模型填充的协同过滤推荐模型。目前大多数基于信任的个性推荐算法中信任关系值是事前给定的,如冯勇等[16]提出的基于社会网络分析的协同推荐方法改进,将用户预填的家人朋友同事关系直接转换成信任度值,融入到用户相似度计算中;夏小伍等[17]提出的基于信任模型的协同过滤推荐算法,是根据共同评分过的项目得出信任值;周璐璐[18]提出的融合社会信任关系的改进推荐系统,信任值来自事先给定的社会信任图。然而大多数社交网络并没有提供用户之间的显式的信任关系值,如何挖掘用户之间的隐式信任关系,度量用户信任值是目前待解决的问题。
针对这些问题,本文提出一种基于用户兴趣和社交信任的协同过滤算法。该算法首先引入聚类技术根据用户评分信息将用户分为不同类别,在聚类的基础上建立基于用户兴趣的邻居集合。在用户兴趣相似度计算时,为了避免不同用户的评分标准不一样,本文采用了修正的余弦计算公式来消除评分标准的差异。同时,引入信任机制,度量社交网络中用户之间信任关系的强弱,通过定义直接信任、间接信任、传递路径将社交网络转换为信任网络,依据信任程度来创建基于社交信任的邻居集合。最后,通过加权的方式将基于两种邻居集合的预测值融合起来为用户产生推荐。在Douban数据集上进行实验,与基于用户的协同过滤算法和基于信任的推荐算法相比,本文不仅在平均绝对误差方面拥有优秀的表现,而且在查准率和查全率方面同样表现出色。
1 基于用户兴趣和社交信任的推荐算法
1.1 问题描述
本文主要利用用户历史评分信息和用户社会关系来对用户进行项目推荐,首先对这两大数据进行描述。定义m个用户的集合为U={u1,u2,…,um},n个项目的集合为V={v1,v2,…,vn}。建立用户及项目之间关系的模型,如图1所示。其中,圆形代表用户,三角形代表项目,实线箭头连接着两个用户,代表两个用户之间的关注关系,虚线箭头连接着用户和项目,代表用户的兴趣。
2 本文算法步骤及时间复杂度分析
2.1 算法步骤
输入 目标用户u0,用户评分信息,用户关注关系信息;
输出 评分最高的N个推荐项目。
步骤1 根据用户评分信息建立用户项目矩阵,根据用户关注关系信息建立用户关注关系矩阵。
步骤2 根据用户项目评分矩阵,使用k均值聚类方法将用户分类,得到k个类别的聚类中心。
步骤3 通过式(2)计算用户u0和每个聚类中心的相似度,并将用户u0加入到相似度最高的类。
步骤4 利用式(2)计算用户u0与簇内所有用户的相似度,得到基于用户兴趣的相似度sim_c(u0,u)值。
步骤5 根据用户关注关系矩阵,利用式(3)、(5)、(6)计算用户u0与集合U中用户基于信任的相似度sim_t(u0,u)的值。
步骤6 根据基于用户u0兴趣的相似度和基于用户信任的相似度,为用户u0选择基于用户兴趣的邻居集合TU和基于用户信任的邻居集合FU。
步骤7 提取出集合TU和FU中所有用户的评分项目,并去剔除用户u0已经评分过的项目,构成候选集P。
步骤8 对于集合P中每个候选项目v,通过式(7)计算预测评分值,根据预测的评分降序排序并向用户u0提供N个推荐项目。
2.2 时间复杂度分析
时间复杂度分析:在计算基于用户兴趣的相似度时,传统的协同过滤算法是直接计算目标用户u0与全体m个用户之间的相似度,同时需要对比n个项目以确定共同评分过的项目,因此,目标用户u0与所有用户相似性的时间复杂度为O(m×n)。本文的算法在计算用户兴趣的相似度时引入了聚类的方法,离线产生聚类中心,在线仅需计算目标用户与聚类中心之间的相似度,然后计算目标用户与类别内的p个用户的相似度, p是聚类后同类别中用户的个数,是一个远远小于m的常数。计算目标用户u0与聚类中心相似性的时间复杂度为O(k×n),计算目标用户u0与类别内用户相似性的时间复杂度为O(p×n),总的时间复杂度为O(k×n)+O(p×n)。因为k, p是远远小于m的数,所以新算法降低了时间复杂度。
3 实验和分析
3.1 数据集及预处理
本实验选用来源于豆瓣网的Douban数据集(http://www.datatang.com/data/13784)。该数据集是对电影部分评分的数据,评分的范围是1~5分。同时,用户还通过关注其他用户建立社交关系,从对方的动态和发布的内容中获取自己感兴趣的部分。该部分数据包含129490个用户对58541部电影的评分,并有1692952条关注关系信息。实验采用五折交叉验证的方法,按照4∶1的比例把数据集分成训练集和测试集,将5次实验结果的平均值作为对算法精度的估计。
3.2 实验评价标准
本文采用平均绝对误差(Mean Absolute Error, MAE)、 precision、recall和F1值四种常见的评价指标。MAE用来衡量预测评分与真实值之间的差异,MAE值越小,表示偏差越小,推荐效果越好,计算如式(8)所示; precision是查准率,用于衡量最后的推荐结果列表中有多少是用户真正喜欢的项; recall是查全率,用于衡量最后的推荐列表中包含了多少用户真正喜欢的东西; F1值是考察查全率与查准率的综合评价指数,计算公式如(9)~(11)所示。
3.3 α的选择
本文相似度计算由用户兴趣相似度和用户社交信任相似度两部分构成,α作为平衡因子调节这两部分权重。α的取值范围为[0,1],每次增加0.1。当α取0时,算法只根据基于用户兴趣的邻居预测值产生推荐;当α取1时,根据基于用户信任的邻居预测值产生推荐;当0<α<1时,算法综合考虑了基于用户信任的邻居和基于用户信任的邻居预测值产生推荐,且α越大基于用户信任预测值所占的比重越大。
从图3看出,通过实验得到,随着α的增大,MAE值先减小后增大,α在区间[0.5,0.7]有最小的平均绝对值误差;α在区间[0.6,0.7]有最好的查准率;α在区间[0.55,0.65]有最优的查全率。综上,α取0.6时,有最佳推荐效果。此外,实验结果表明,综合基于用户兴趣和基于信任两方面信息比只考虑其中一方面的信息有更好的推荐效果,同时也说明在此数据集上选择邻居用户时基于用户信任的相似度比基于用户兴趣的相似度贡献大,所以在预测评分时给基于用户信任相似度所选择的邻居用户赋予了更高的权重,也说明人们更愿意相信与自己有信任关系的朋友的推荐。
3.4 k均值聚类算法中分类数k的选择
k均值聚类方法受分类数k的影响,在不同问题下最佳分类数k的取值不同,需要确定最适合本文算法的分类数。本实验以聚类数k为变量,k的取值范围为[30,75],每次增加5。实验结果如图4所示,从图中可以看出并不是k越大效果就越好,随着k值增加,MAE值先减小再增加。在[30,45]区间内,MAE值逐渐减小,说明随着k的增加,分类更为准确,同类别的用户的相似度更大;在[45,75]的区间内,MAE值逐渐增大,此时随着聚类k的增大,某些类别内只存在很少的用户,分类数的增加并不能够很好地划分类别。分类数k=45时,MAE最小,表明推荐效果最佳。
3.5 几种算法的推荐效果比较
为了更好地评价算法的推荐质量,用本文提出的算法与传统的基于用户的协同过滤(userbased CF)算法、基于信任的推荐(trustbased)算法和本文算法(不含间接信任)4种算法进行比较分析。
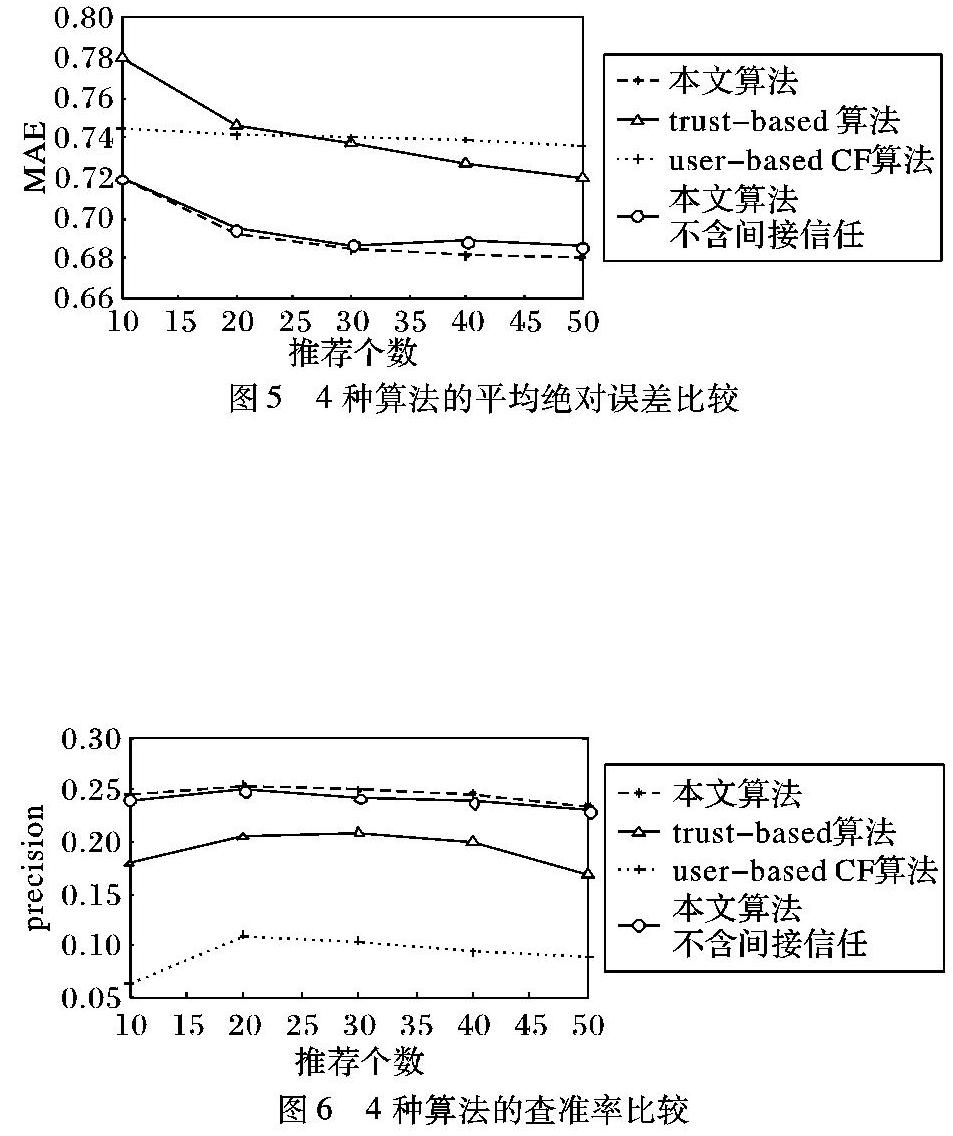
图5显示了4种算法在平均绝对误差上的比较,从实验结果中可以看出,当本文算法不考虑间接信任时,平均绝对值误差会比考虑间接信任时大,说明结合间接信任的算法有效的减少了误差。在推荐个数较少时,基于用户的协同过滤算法比基于信任的推荐算法预测平均误差要小,随着推荐个数的增大,基于信任的推荐算法要优于基于用户的协同过滤算法,然而本文算法在平均绝对误差上明显优于对比算法。
图6显示了4种算法在查准率上的比较,从实验结果中可以看出,本文算法查准率高于其他算法且处于相对稳定的状态,4种算法在推荐数为20时准确率最高,之后随着推荐数增加,引入了更多不准确的推荐,导致各个算法的准确率整体呈下降趋势,同时,结合间接信任关系的算法提升了查准率。
图7显示了4种算法在查全率上的比较,从实验结果中可以看出,开始时3种算法的查全率相差不大,当推荐数达到20时,本文算法和基于信任的推荐算法比基于用户的协同过滤算法的查全率要高。四种算法的查全率都是随着推荐个数增加而增加,然而本文算法在结合间接信任时始终处于最优状态。
图8显示了4种算法在F1值上的比较,F1是根据查准率和查全率得到的一项综合性评价指标。由于本文算法在查准率和查全率上都优于基于用户的协同过滤算法和基于信任的推荐算法,因此本文算法的F1值也优于对比算法。另外,本文算法和基于信任的推荐算法的F1值明显优于基于用户的协同过滤算法,本文算法综合用户兴趣、直接信任和间接信任有效提升了推荐系统的性能。
4 结语
传统的协同过滤推荐算法是在整个用户空间上根据用户项目评分来计算用户间的相似性,不仅计算量大,而且忽略了其他用户对目标用户兴趣的影响,这无疑会降低推荐的质量。本文利用聚类算法将用户分类,然后将信任机制引入到个性化推荐方法中,通过定义直接信任和间接信任来度量社交网络用户之间的隐含信任关系,将社交网络转换为信任网络。在基于用户评分矩阵和用户信任关系上分别选择邻居用户,加权为用户产生推荐。另外,在计算用户兴趣相似度时,本文采用了修正的余弦计算公式来消除评分标准的差异问题,提高了兴趣相似度计算的准确性。为了对本文算法进行评价,本文引进了两个实验,确定了合适的协调因子α值和分类数k值,然后再与基于用户的协同过滤算法和基于信任的推荐算法进行对比实验,实验结果表明本文算法在MAE、 precision、recall、F1值上优于传统的基于用户的协同过滤算法、基于信任的推荐算法和不含间接信任的本文算法,有效提高了推荐系统的推荐质量。
参考文献:
[1]CHOI K, SUH Y. A new similarity function for selecting neighbors for each target item in collaborative filtering [J]. KnowledgeBased Systems, 2013, 37: 146-153.
[2]KRZYWICKI A, WOBCKE W, KIM Y S, et al. Collaborative filtering for peopletopeople recommendation in online dating: data analysis and user trial [J]. International Journal of Human Computer Studies, 2015, 76: 50-66.
[3]施凤仙, 陈恩红.结合项目区分用户兴趣度的协同过滤算法[J].小型微型计算机系统, 2012, 33(7):1533-1536.(SHI F X, CHEN E H.Combining the items discriminabilities on user interests for collaborative filtering[J]. Journal of Chinese Computer Systems, 2012, 33(7): 1533-1536.)
[4]吴泓辰, 王新军, 成勇, 等.基于协同过滤与划分聚类的改进推荐算法[J].计算机研究与发展, 2011, 48(S3):205-212.(WU H C, WANG X J, CHENG Y, et al. Advanced recommendation based on collaborative filtering and partition clustering[J]. Journal of Computer Research and Development, 2011, 48(S3): 205-212.)
[5]尹航, 常桂然, 王兴伟.采用聚类算法优化的K近邻协同过滤算法[J].小型微型计算机系统, 2013, 34(4):806-809.(YIN H, CHANG G R, WANG X W. Effect of clustering algorithm in Knearestneighborhood based collaborative filtering[J]. Journal of Chinese Computer Systems, 2013, 34(4): 806-809.)
[6]王明佳, 韩景倜, 韩松乔.基于模糊聚类的协同过滤算法[J].计算机工程, 2012, 38(24):50-52.(WANG M J, HAN J T, HAN S Q. Collaborative filtering algorithm based on fuzzy clustering[J]. Computer Engineering, 2012, 38(24): 50-52.)
[7]孙辉, 马跃, 杨海波, 等.一种相似度改进的用户聚类协同过滤推荐算法[J].小型微型计算机系统, 2014, 35(9):1967-1970.(SUN H, MA Y, YANG H B, et al. Collaborative filtering recommendation algorithm by optimizing similarity and clustering user[J]. Journal of Chinese Computer Systems, 2014, 35(9): 1967-1970.)
[8]吴湖, 王永吉, 王哲, 等.两阶段联合聚类协同过滤算法[J].软件学报, 2010, 21(5):1042-1054.(WU H, WANG Y J, WANG Z, et al. Twophase collaborative filtering algorithm based on coclustering[J]. Journal of Software, 2010, 21(5): 1042-1054.)
[9]王雪蓉, 万年红.云模式用户行为关联聚类的协同过滤推荐算法[J].计算机应用, 2011, 31(9):2421-2425.(WANG X R, WANG N H. Cloud pattern collaborative filtering recommender algorithm using user behavior correlation clustering[J]. Journal of Computer Applications, 2011, 31(9): 2421-2425.)
[10]荣辉桂, 火生旭, 胡春华, 等.基于用户相似度的协同过滤推荐算法[J].通信学报, 2014, 35(2):16-24.(RONG H G, HONG S X, HU C H, et al. User similaritybased collaborative filtering recommendation algorithm[J]. Journal on Communications, 2014, 35(2): 16-24.)
[11]REAFEE W, SALIM N. the social network role in improving recommendation performance of collaborative filtering[C]// Proceedings of the 1st International Conference on Advanced Data and Information Engineering. Berlin: Springer, 2014: 231-240.
[12]邹本友, 李翠平, 谭力文, 等.基于用户信任和张量分解的社会网络推荐[J].软件学报, 2014, 25(12): 2852-2864.(ZOU B Y, LI C P, TAN L W, et al. Social recommendations based on user trust and tensor factorization[J]. Journal of Software, 2014, 25(12): 2852-2864.)
[13]张富国.用户多兴趣下基于信任的协同过滤算法研究[J].小型微型计算机系统, 2008, 29(8):1415-1419.(ZHANG F G. Research on trust based collaborative filtering algorithm for users multiple interests[J]. Journal of Chinese Computer Systems, 2008, 29(8): 1415-1419.)
[14]王兴茂, 张兴明, 邬江兴.基于一跳信任模型的协同过滤推荐算法[J].通信学报, 2015, 36(6):193-200.(WANG X M, ZHANG X M, WU J X. Collaborative filtering recommendation algorithm based on onejump trust model[J]. Journal on Communications, 2015, 36(6):193-200.)
[15]杨兴耀, 于炯, 吐尔根·依布拉音, 等.基于信任模型填充的协同过滤推荐模型[J].计算机工程, 2015, 41(5):6-13.(YANG X Y, YU J, IBRAHIM T, et al. Collaborative filtering recommendation model based on trust model filling[J]. Computer Engineering, 2015, 41(5):6-13.)
[16]冯勇, 李军平, 徐红艳, 等.基于社会网络分析的协同推荐方法改进[J].计算机应用, 2013, 33(3):841-844.(FENG Y, LI J P, XU H Y, et al. Collaborative recommendation method improvement based on social network analysis[J]. Journal of Computer Applications, 2013, 33(3): 841-844.)
[17]夏小伍, 王卫平.基于信任模型的协同过滤推荐算法[J]. 计算机工程, 2011, 37(21):26-28.(XIA X W, WANG W P. Collaborative filtering recommendation algorithm based on trust model [J]. Computer Engineering, 2011, 37(21):26-28.)
[18]周璐璐.融合社会信任关系的改进推荐系统[J].计算机应用与软件, 2014, 31(7): 31-35.(ZHOU L L. Improved recommendation system based on social trust relation[J]. Computer Applications and Software, 2014, 31(7): 31-35.)
