云计算下大数据非结构的稳定性检索方法
2016-05-14陈志华刘晓勇
陈志华 刘晓勇
摘 要: 传统的云计算Hadoop 分布式多层体系架构数据检索模块难以满足云计算下大数据非结构的稳定性检索需求,因此采用需要结合存储非结构化大数据的特点,塑造新的集群的基础环境,通过云、端并重的形式,实现大数据非结构的稳定性检索。引入一种非结构大数据索引框架,作为非结构化数据库,当成数据检索引擎,改进云计算下大数据非结构的检索服务,给出检索技术在检索非结构化大数据过程中的关键代码。实验结果表明,所设计系统在检索云计算下非结构大数据的过程中,具有较高的查准率和较低的检索时间,可实现非结构云数据的稳定性检索。
关键词: 云计算; 大数据; 非结构稳定性检索; 数据检索引擎
中图分类号: TN911?34 文献标识码: A 文章编号: 1004?373X(2016)06?0058?04
Methods of unstructured big data stability retrieval in cloud computing
CHEN Zhihua, LIU Xiaoyong
(Guangdong Polytechnic Normal University, Guangzhou 510665, China)
Abstract: It is difficult for the traditional cloud computing Hadoop distributed multi?layer architecture data retrieval module to meet the demand of the unstructured big?data stability retrieval in the cloud computing, so it is necessary to combine the characteristics of the unstructured large data storage, shape a new clustering basic environment, and pay equal attention to the form of cloud and end, to realize the stability retrieval of the unstructured big data. A big data index framework is taken as a unstructured database and as a data retrieval engine to improve the unstructured data retrieval service in cloud computing, and give the key code of the retrieval in the process of unstructured big data retrieval. Experiment result shows that the designed system, in the process of unstructured big data retrieval in the cloud computing, has high precision and short retrieval time, and can realize the stability retrieval of the structured cloud data.
Keywords: cloud computing; big data; unstructured stability retrieve; data retrieval engine
0 引 言
随着云计算技术的快速发展,不同类型服务器数据信息呈现爆炸式增长,市场迫切需要先进的大规模云计算数据存储和检索技术[1?3]。云计算下大数据检索的研究和应用顺应了市场的发展需求。当前的云计算下海量数据中,有高于80%的数据都是非结构化数据,但是,当前的信息关联检索主要依靠的是建立结构化的关联规则,无法满足云信息检索需求,寻求有效方法快速从中检索到有价值信息,成为相关学者研究的热点[4]。
文献[5]提出了热度敏感的非结构化数据检索排名算法,但是该方法对数据的属性特征具有较高的敏感性,存在较高的局限性。文献[6]分析了基于Lucene算法的文件全文检索解决方案,可快速有效地分析出不同结构数据的信息,但是存在耗能高和检索效率低的缺陷。文献[7]分析的分布式索引方法采用多节点备份实现系统检索,但是当备份的节点同时发生故障,则无法恢复失效节点上的索引,导致检索精度降低。文献[8]提出了以索引服务为基础的本地索引方法,直接为检索服务的方法,确保检索同索引集群紧密结合,极大提高了该种方法的容错性,但是同时也增加了该种方法的复杂性。
为了解决上述分析的问题,本文以云计算Hadoop 分布式多层体系架构为基础,分析存储非结构化大数据的特点,将非结构大数据索引框架当成非结构化数据库,提供云计算下大数据非结构的检索服务。实验结果说明,所设计系统在检索云计算下非结构大数据的过程中,具有较高的查准率和较低的检索时间,可实现大数据非结构的稳定性检索。
1 云计算下大数据非结构的架构分析
1.1 Hadoop架构的非结构化分析
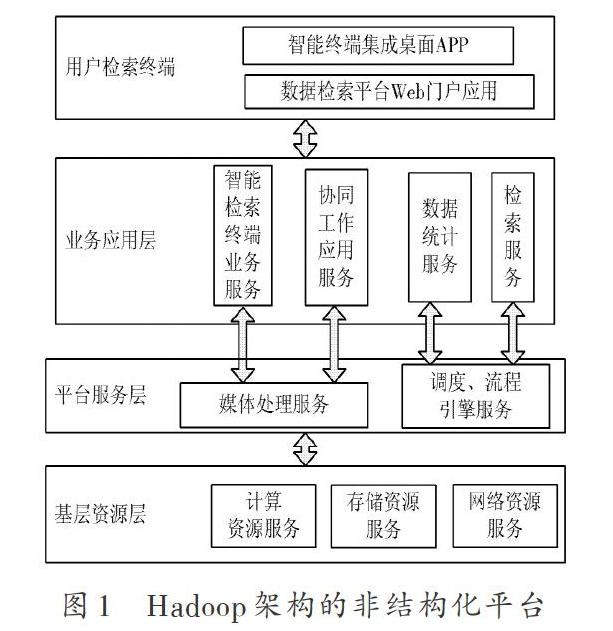
云计算下存储的大数据种类较多,都是以非结构检索关系存在的,总体架构如图1所示。该检索平台依托云计算,云平台采用了 Hadoop 分布式多层体系架构存储非结构化大数据,并塑造集群的基础环境,通过云、端并重的形式,实现大数据非结构的稳定性检索。
当前的云计算下大数据非结构检索系统通过互联网采集云计算下的海量数据,通过后台系统实现大数据非结构的自主加工和统计操作。该平台还能够统计分析热点信息。在获得大量非结构数据后,系统根据检索业务策略定义,在检索引擎的配合下,完成大数据非结构检索的存储服务。
1.2 云存储下数据的非结构特点分析
上述系统总体架构采用多层体系架构设计,并依据多层架构的基础服务进行塑造。在多层体系架构下,通过云、端并重的形式,实现大数据非结构的稳定性存储,存储过程程序非结构的特点如下:
(1) 用户检索终端数据的非结构化。面向终端检索用户,通过Web门户应用以及移动终端 APP为用户提供大数据检索的服务中,因为用户信息的多样性,无法形成稳定的结构。
(2) 业务应用层数据的非结构化。业务应用层服务为系统提供各种应用程序,系统以服务的方式对外提供大数据业务支撑,同时将该部分的服务部署在云平台中。用户检索终端应用通过访问云平台中的业务应用层服务,完成云计算下大数据非结构的稳定性检索业务。但是,由于应用程序在种类和开发过程中的差异性愈来愈大,导致该层数据也存在较大的非结构化的特点。
(3) 平台服务层数据的非结构化。平台服务层为业务应用层和基础资源层提供相关的服务,包括媒体处理服务和调度、流程引擎服务。平台服务层中包含关键的大数据检索引擎。但是随着检索模式的不断增加,该层数据也存在较大的非结构化的特点。
(4) 基础资源层数据的非结构化。基础资源服务层是云平台的基础设备层,通过计算资源服务、存储资源服务以及网络资源服务,通过逻辑资源池的方式实现云平台的调控。该检索平台中的基础资源服务,主要指云平台的基础资源,包括云存储、虚拟计算资源以及操作系统等基础部件,随着基础设备的不断增加,设备数据之间也无法形成稳定的结构特征,形成非结构化的特点。
2 云计算下大数据非结构的检索实现
在云计算下,差异大数据非结构检索是一个复杂的过程,通过第1节的分析可以看出,平台中存储着海量非结构化数据。传统的依据结构化索引的方法无法满足非结构数据稳定的检索要求。本文通过构建非结构化大数据的分布式索引系统,可满足云计算下非结构大数据的稳定性检索需求。
2.1 设计非结构化数据的索引框架
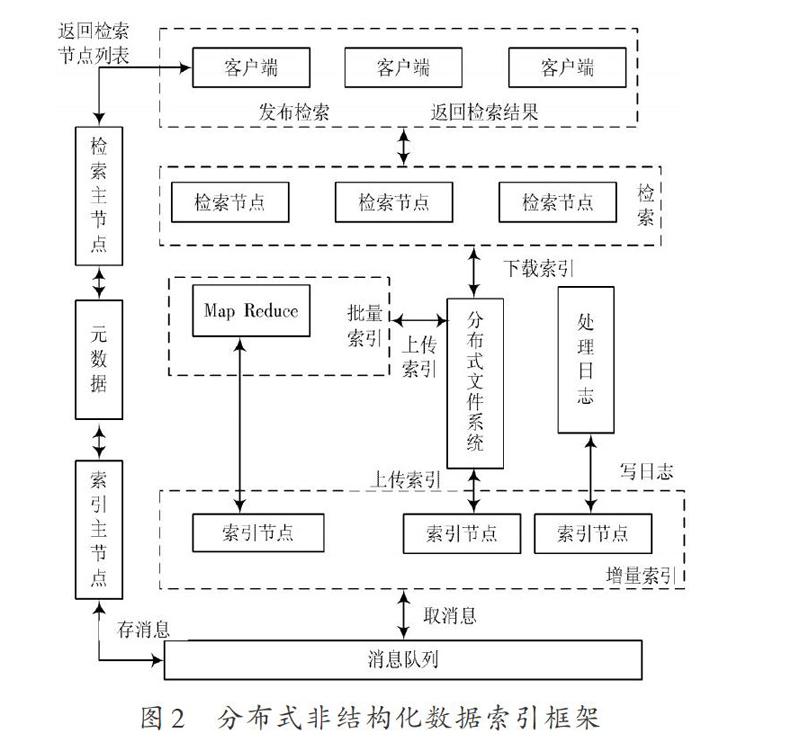
通过塑造分布式非结构化大数据索引框架可以对非结构数据建立类似于结构化的框架,设计的框架如图2所示。该分布式索引框架包括索引集群、检索集群以及分布式文件系统。
2.2 索引集群的引入
在非结构框架下,设计索引集群可塑造分布式大数据非结构检索的索引。索引集群采用Master?Slave结构,由一个索引主节点以及多个索引节点构成。通过该结构能够将索引任务分割到不同的索引节点中,确保不同的索引节点能够并行塑造索引,增强系统对云计算下非结构数据的操作性能。索引集群服务于批量和增量索引模式。系统保存非结构数据后会向索引主节点传递增量式索引任务的消息。索引主节点按照该消息中的数据特征以及内容,使用索引分片方案,判断相应的数据归属于索引分片,再在分布式索引消息队列中存储相关的消息。
不同结构的数据索引节点相互独立,并从消息队列中采集消息。若采集的消息属于相应索引节点,则对消息进行相关的检索,否则将消息反馈到对应的索引节点再进行操作。若对应的操作索引节点无法正常运行,则通过索引主节点完成消息的操作,并将新的索引节点配置给对应消息。索引集群能够增强总体系的吞吐量。
2.3 非结构化下的检索集群的设计
在非结构数据框架下,检索集群包含检索主节点、检索节点以及检索客户端。检索集群通过Master?Slave结构确保索引文件高效率的部署到不同的检索节点中,增强数据检索服务效率。检索节点依据Master?Slave结构能够获取总体检索集群中不同检索节点的负载情况。当用户通过检索客户端发出数据检索申请后,检索主节点将按照不同检索节点的负载情况,获取一个节点列表,并将该列表反馈给检索客户端,检索客户端依据获取的检索节点列表进行检索。用户采用检索客户端可申请检索,并获取相应的检索结果。
2.4 云计算下大数据非结构化的检索代码
当前多使用SQL全文检索技术实现云计算下大数据非结构化的检索设计,详细过程为:启动SQL Server的full text search全球检索服务,设置数据库服务器的默认语言为2052(中文);运行SQL语句启用全文检索:Executesp_fulltext_StructDabase‘enable;选择“全文索引”中的“定义全文索引”,融入全文检索向导对话框,选择将要对其进行全文索引的字段和全文目录。
重新启动SQL Server则能够采用检索语句CONTAINS以及FREETEXT对所设置的表进行查询。其中,CONTAINS语句可在表的全部列中搜索,词或短语以及同对应词相近的词等;FREETEXT语句可在一个表的全部列或指定列中搜索一个自由文本各种的字符串,并返回同该字符串匹配的数据行。
如在Doc表中查找文件内容中包含“暴恐”,所采用的SQL语句为:
SELECT*FROM Doc Where CONTAINS(DocumentConnotation ,′暴恐′)
检索非结构化数据的界面中,输入关键字,单击“检索”按钮,则可将文件内容中包含该关键字的文件名、文件类型显示处理。实现文档中关键字检索的主要代码为:
Public StructDaTable StructDaSearch(string keyword,string steConn){string sql= "select * from doc where CONTAINS (DocumentConten,""+key?word+"")";
SqlStructDaAdaper da=new SqlStructDaAdaper(sql,strConn);
StructDaSer da=new StructDaSet();
da.Fill(da); return da.Tables[0];}
若需打开某文档,则对总体文档进行详细分析,在.net环境中,通过设置Response的ConnotationSpecies属性和调用BinaryWrite方法则能够站在浏览器中显示相关的文档内容。显示Word文档以及Excel文档内容的关键代码为:
3 实验分析
实验采用云计算非结构NUS数据集,将该数据集中低维特征提取出来的视觉单词特征,当成测试集合。本实验从该非结构数据集中随机抽取100万个特征作为样本训练集合。实验采用检索时间和查准率两个指标评估本文系统和平均分配检索系统的优劣。
查准率=检索结果中相关的结果总数/检索结果的总数
为了得到比较全面的实验结果,实验选择了10组实验,每组实验的文件数分别为10万,20万,30万,40万,50万,60万,70万,80万,90万以及100万。再计算出检索时间的平均值以及查准率的平均值对各个系统进行评价。
3.1 以查准率为评估指标
实验先以查准率作为评价指标进行实验。在每种实验系统中,依次输入不同检索目标进行检索,并设置最长搜索时间为3 s进行实验。统计不同检索目标的查准率,并运算平均值。再比较各系统的查准率。本文方法下系统和平均分配系统的查准率对比如图3所示。
分析图3可得,本文方法下的查准率明显好于平均分配检索系统,说明使用的本文方法进行大数据非结构的检索具有较强的优势。
3.2 以检索时间为评估指标
实验依据检索平均时间为指标评估不同的检索系统。在两个实验系统中,分别输入不同的检索目标进行检索,同时设置不同的检索结果数进行多次实验。运算不同系统中差异结果下的检索平均时间,再比较两个系统的检索时间。在本文系统和平均分配系统中对10 个实验目标进行检索,统计各目标在两个系统中的检索时间,运算出平均检索时间,如图4所示。
从图4中可以看出,平均分配检索系统在平均搜索时间上高于本文系统,则证实应用了本文检索系统在查询时间和查准率这两个评价指标上,都优于传统的平均分配系统。
上面的实验比较可以看出,本文检索系统对非结构数据的性能优于传统的平均分配系统。说明本文系统可实现云计算下大数据非结构的稳定性检索,具有较高的应用价值。
4 结 语
本文以云计算为基础,采用Hadoop 分布式多层体系架构存储非结构化大数据,并塑造集群的基础环境,通过云、端并重的形式,实现大数据非结构的稳定性检索。将非结构大数据索引框架作为非结构化数据库,当成数据检索引擎,提供云计算下大数据非结构的检索服务,该分布式索引框架包括索引集群、检索集群以及分布式文件系统。给出SQL Server 2008的全文检索技术在检索非结构化大数据过程中的关键代码。实验结果说明,所设计系统在检索云计算下非结构大数据的过程中,具有较高的查准率和较低的检索时间,可实现大数据非结构的稳定性检索。
参考文献
[1] 中国互联网络信息中心.中国互联网络发展状况统计报告[R].北京:CNNIC,2014.
[2] 车晓蕙,周立民,陈钢,等.大数据为王第三次流通革命在望[N].经济参考报,2013?09?11(5).
[3] 李淑芝,刘锋,杨书新.基于云仿真的Web服务选择研究[J].计算机应用研究,2013,30(4):1069?1071.
[4] 杜芸芸.一种面向纠删码技术的云存储可靠性机制[J].计算机应用与软件,2014,31(2):312?316.
[5] 林菲,张万军,孙勇.一种分布式非结构化数据副本管理模型[J].计算机工程,2013,39(4):36?38.
[6] 翟岩龙,罗壮,杨凯,等.基于Hadoop的高性能海量数据处理平台研究[J].计算机科学,2013,40(3):100?103.
[7] 韩晶,宋美娜,鄂海红,等.HotRank:热度敏感的非结构化数据检索排名算法[J].计算机应用研宄,2013,30(5):1306?1308.
[8] 郭永利,卢颖颖.基于Lucene对文件全文检索的研究与应用[J].微型电脑应用,2014,31(1):51?54.
