Hadoop集群作业调度算法优化技术研究
2016-05-14单冬红郭静博赵伟艇
单冬红 郭静博 赵伟艇
摘 要: 针对当前云计算技术的广泛使用,提出对Hadoop集群作业调度算法进行研究的构想。在对Hadoop新版本中提出的Hadoop Map Reduce V2(Yarn)框架进行深入研究的基础上,设计一个详细完整的对比实验,针对各种作业调度算法的优势与不足进行全面的测试。通过使用不同的作业调度算法运行相同的作业,进行细致横向的对比,并得到各种作业调度算法之间以及计算框架之间在计算能力、运行时间、资源占用等方面的优劣。实验结果表明,公平调度算法和计算能力调度算法相较于传统的FIFO算法具有更灵活、更高效的特点。
关键词: 云计算; Hadoop; HDFS; 作业调度; 集群
中图分类号: TN911?34 文献标识码: A 文章编号: 1004?373X(2016)06?0025?05
Research on optimization technology of Hadoop cluster job scheduling algorithm
SHAN Donghong, GUO Jingbo, ZHAO Weiting
(School of Software Engineering, Pingdingshan University, Pingdingshan 467002, China)
Abstract: Conception of studying Hadoop cluster job scheduling algorithm is composed in allusion to extensive application of the current cloud computing technology. According to the deep study of Hadoop Map Reduce V2 (Yarn) in the new edition Hadoop, a complete contrast experiment was designed, and the advantages and disadvantages of all kinds of job scheduling algorithms were tested. The comparison was carefully made by applying the different job scheduling algorithms on the same job. The differences and characters in calculation ability, operation time, and resource occupation of all the job scheduling algorithms and calculation frameworks were obtained. The experimental results show that the fair scheduling algorithm and the calculation capacity scheduling algorithm are more flexible and more efficient than the traditional FIFO scheduling algorithm.
Keywords: cloud computing; Hadoop; HDFS; job scheduling; cluster
随着科学技术的快速发展,互联网中所容纳的数据规模正在以一种爆发式的增长速度激增。应用的丰富和数据规模的增长,使得云计算的使用者对于功能的需求已经大大超出了原有的云计算平台所能提供的能力范围[1]。Hadoop作为一个开源的云计算平台的代表,在近些年得到了十分广泛的应用。对Hadoop作业调度算法的研究对研究整个Hadoop平台、提升平台的资源利用率有着至关重要的意义。
近年来,国内外的相关学者对Hadoop中的作业调度以及资源管理等方面技术进行了十分深入的研究。但是由于云计算模式这种特有的商业服务的特点,加之目前仍处于研究的初级阶段,所以对作业调度的研究仍然相对偏少。作业调度的优劣直接影响到云计算平台的性能和资源利用率[2]。对作业调度算法的研究对提高Hadoop的运算效率、优化资源利用都起着至关重要的作用。本文对Hadoop集群作业调度算法进行研究,重点通过实验对比相关算法的优劣,为Hadoop的后续开发奠定一定的技术基础。
1 Hadoop平台及其作业调度算法
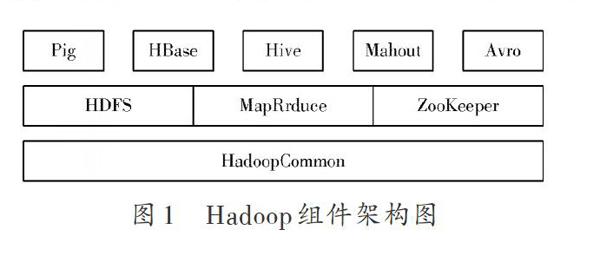
Hadoop是Apache基金会开发的一个分布式系统架构,是由很多子项目组成的集合[3]。除了大家都熟知的HDFS,MapReduce以及HBase三个核心的技术之外,Hadoop还有很多其他的用于数据处理和分析的组件,并且也逐渐开始得到十分广泛的应用,这些组件之间往往在功能上实现了互补,从而更加完善了整个Hadoop平台。Hadoop的组件架构图如图1所示。
Hadoop对Google的GFS进行了实现,形成了自己的分布式文件系统(Hadoop Distribute File System,HDFS)。HDFS是Hadoop的一个核心的子项目。为了提升Hadoop平台的吞吐量,程序都能采用流式的形式访问数据,在HDFS设计之时,更多地考虑到了对数据进行批量处理。由于HDFS的特殊设计,使得主控节点并不需要占用特别多的资源就可以处理规模较大的文件。
Hadoop上的作业调度算法负责管理作业调度的全部过程,这个过程中包括资源的重新分配、节点的选择等操作。在Hadoop框架中主要有三种作业调度器。它们分别是:先进先出调度器(First In First Out Scheduler),公平调度器(Fair Scheduler)以及计算能力调度器(Capacity Scheduler)。随着Hadoop0.23.0版本的发布,Hadoop提出了一种新的Map Reduce框架(即Yarn)。
新发布的Yarn框架相较于早前的Map Reduce框架具有了较多的优点,通过使用新的Resource Manager降低了原有的Job Tracker对整个集群资源的占用。Yarn不是通过使用槽的概念进行资源的管理,而是将内存作为资源管理的基本单位[4]。作业中任务的运行情况在Yarn中都是通过Application Master进行监控,取代了原先版本在Job Tracker 的功能,Yarn中的Container框架实现了Java虚拟机的内存隔离,在以后的版本中可能会加入对资源管理的支持[5]。
2 实验环境的构建
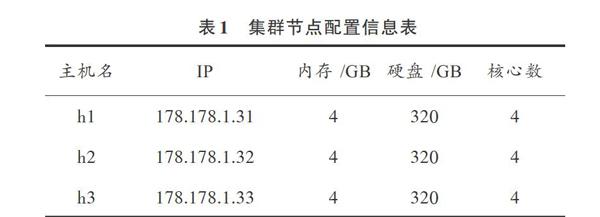
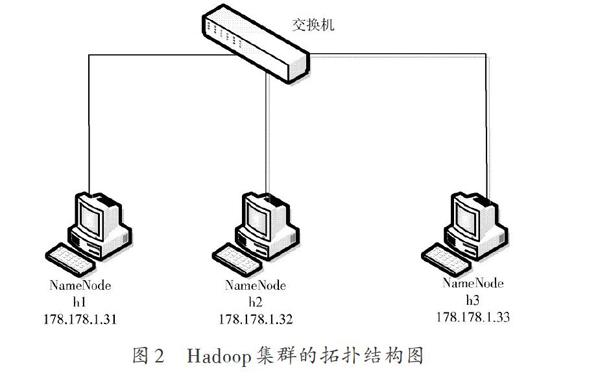
实验中的Hadoop集群是由实验室中的3台服务器构成。其网络拓扑结构图如图2所示。其名字节点的名字为h1,其IP地址是178.178.1.31。其余2台服务器为数据节点,名字分别为h2、h3,IP地址分别为178.178.1.32和178.178.1.33。集群节点的配置如表1所示。
实验过程中首先安装的Hadoop的版本是Hadoop?1.0.4。具体的安装过程如下:
(1) 首先要关闭集群中各台服务器的防火墙和Selinux;
(2) 修改各台服务器的主机名;
(3) 关闭DHCP,将各台服务器的IP地址修改为静态IP地址;
(4) 修改Host文件,使其能够解析主机名字;
(5) 为各台服务器安装JDK;
(6) 为各台服务器安装SSH服务;
(7) 配置名字节点的主机能够无密码SSH登录到数据节点的从机以及自己;
(8) 将hadoop?1.0.4?bin.tar.gz包拷贝到主控机器上;
(9) 对配置文件进行修改;
(10) 将配置好的文件通过网络发送给两台从机;
(11) 对从机进行部署。
由于对比需要,测试环境需要安装Hadoop2.2.0版本。由于一些公共环境的配置与Hadoop1.0.4版本的配置相同,所以上述过程的前6步不需要进行改动。Hadoop 2.2.0版本的简要的配置过程如下:
(1) 解压Hadoop 2.2.0压缩包;
(2) 修改hadoop?env.sh,yarn?env.sh,slaves,core?site.xml,hdfs?site.xml,mapred?site.xml,yarn?site.xml文件的内容;
(3) 将配置文件复制到其他的节点;
(4) 启动Hadoop。
Ganglia可以把检测到的资源信息通过图表的形式在网页上面展示给用户,这对资源的合理利用分配,提升系统资源利用率有着非常重要的作用。安装Ganglia也需要安装一些第三方的软件库。具体的安装步骤如下:
(1) 安装32位系统EP EL的rpm文件包;
(2) 在服务器端安装Ganglia;
(3) 在监控端安装Ganglia;
(4) 监控端配置Ganglia;
(5) 服务器端配置Ganglia;
(6) 启动服务;
(7) 服务器端Apache配置。
安装上述过程配置好后,在浏览器中输入http://
178.178.1.31/ganglia即可进入Ganglia集群监控页面。
3 实验的实施
以下主要通过实验对比的形式,比较各调度算法在不同情况下执行过程中所表现出来的差异。通过针对多个测试程序,使用多类型的作业在不同的作业调度算法下分别执行。通过这种交叉对比实验的模式得出实验数据。
通过运行命令在/terasort路径下生成大小分别为1 GB,10 MB以及15 MB的三组待排序的原始数据。这样的设计思路是:通过一个量级较大的作业以及两个规模相类似的较小的作业,对比在不同的调度算法中各种规模作业的运行时间和响应情况。
分别在Hadoop 1.0.4和Hadoop 2.2.0中运行TeraGen生成数据。需要注意的是,由TeraGen生成的数据的单位是行,并且每行的大小是100 B。所以根据要生成的总的数据量就可以计算出命令中需要使用的参数。接下来分别在三个控制台中提交这三个排序作业,为了确保该实验对比性质明显,在调用不同调度算法进行测试的时候也应该保持作业的提交顺序相同。
分别在Hadoop 2.2.0环境下以及Hadoop 1.0.4中使用三种作业调度算法分别生成1 GB,15 MB以及10 MB的数据。
3.1 TeraSort测试
(1) 使用FIFO作业调度算法运行。使用默认的FIFO作业调度算法进行作业调度,在三个控制台中分别按照顺序提交这三个作业,三个排序作业运行时间情况如表2所示。
由表2可以看出由于FIFO调度算法的局限性,只是简单的根据作业提交的前后的顺序进行调度。所以使得后面提交的两个作业量相对较小的作业执行实现受到了第一个提交的大作业的影响。由于都在等第一个作业的完成,所以运行时间都要比单独运行的时间要长。
(2) 使用公平调度算法运行。将Hadoop集群的作业调度算法改为公平调度算法,将fair scheduler的jar包拷贝到lib目录下,然后修改mapred?site.xml文件的内容,保存编辑好的上述文件后,重启jobtracker。重新运行TeraSort排序程序,仍然按照与使用FIFO调度算法进行实验时候相同的作业提交顺序[6]。执行完成上述实验操作之后,统计试验中各个作业的运行时间情况,具体数据如表3所示。
通过作业的运行时间表看出,在公平调度算法进行作业调度时,作业的提交时间并没有成为进行调度的依据,而是确保每个提交的作业都可以尽量平均地使用集群的资源。
(3) 计算能力调度算法。以下实验采用计算能力调度算法,具体的配置步骤是首先将capacity scheduler的jar包拷贝到lib目录下,然后对mapred?site.xml文件的内容进行修改。完成上述配置后,重启Hadoop。重新运行TeraSort排序程序,三个排序作业运行时间情况如表4所示。
通过实验结果可以看出,由于计算能力调度算法支持多个作业队列,各个作业队列之间的资源可以动态做出调整,本次实验中的各个作业的整体运行时间较使用默认的FIFO调度算法时有所提升。当集群规模足够大,作业数目增多时,可以预见将对集群整体的吞吐量带来较大的提升。
3.2 WordCount测试
WordCount的主要功能是获取出入文件中的单词出现的次数。实验中所使用的测试文件为三篇英文小说,先将这三篇小说拷贝到HDFS中,输入文件创建好之后,就可以分别运行几种调度算法执行测试。
(1) 使用FIFO作业调度算法运行。使用默认的FIFO作业调度算法进行作业调度,在三个控制台中分别按照顺序提交这三个作业,每个作业的运行情况如表5所示。
(2) 使用公平调度算法运行。修改mapred?s ite. xml文件,将作业调度算法更换为公平调度算法,并重新按照同样的操作方式执行上述过程,每个作业的运行情况如表6所示。
(3) 计算能力调度算法。以下实验采用计算能力调度算法,具体的配置步骤是首先将capacity scheduler的jar包拷贝到lib目录下,然后对mapred?site.xml文件的内容进行修改,每个作业的运行情况如表7所示。
3.3 Grep测试
Grep测试程序主要完成的是对指定文档里面的指定的的单词进行出现次数的计算,在Grep程序运行时将对CPU资源造成较大的消耗。
(1) 使用FIFO作业调度算法运行。使用默认的FIFO作业调度算法进行作业调度,在三个控制台中分别按照顺序提交三个作业。
(2) 使用公平调度算法运行。修改mapred?site.xml文件,将作业调度算法更换为公平调度算法,并重新按照同样的操作方式执行上述过程。
(3) 计算能力调度算法。采用计算能力调度算法,具体配置步骤是先将capacity scheduler的jar包拷贝到lib目录下,然后对mapred?site.xml文件的内容进行修改。
3.4 Pi测试
Pi程序采用Quasi?Monte Carlo算法对Pi的值进行估算。通过运行测试实验,分别在使用FIFO调度算法、公平调度算法和公平能力调度算法以及在Yarn框架中执行Pi程序之后,得到的整个集群负载情况见图3。
4 实验结果分析与研究
第三节对实验的过程进行了详要的介绍。以下将实验中获得的信息进行整合。使用Hadoop 1.0.4版本结束实验后,集群的主要负载情况如图4所示。
<各种测试实验中的作业平均运行时间如图5所示。
使用Hadoop 2.2.0版本实验过程结束后,集群的主要负载情况如图6所示。
各种测试实验中的作业平均运行时间如图7所示。
从上述实验结果可以看出,在执行WordCount程序时,各个算法之间无论是在集群负载还是在运行时间方面所体现出来差异并不是十分明显,这主要说明当输入的数据集的规模没有足够大的时候,调度算法没有办法充分发挥其优势。
在Pi程序的测试实验设计中,使用的是单个作业的提交,所以三种算法之间的作业运行时间基本一致。对比TaraGen和TeraSort程序,在TeraGen测试程序中,使用公平能力调度算法时由于是使用了多个用户分别提交作业,所以各个作业队列之间的作业可以并行执行,所以其运行时间要大大低于使用FIFO调度算法时的运行时间。而在TeraSort测试程序中所涉及的实验步骤为没有使用多个用户分别提交,由于单个作业队列中使用的仍然是FIFO作业调度算法,可以看出在这种情况下的公平能力调度算法相比于FIFO调度算法并不具有什么优势。而相比于使用Hadoop 1.0.4版本测试时候的实验结论,可以看出在Hadoop 2.2.0版本中,由于对原有的Hadoop框架进行了优化,在目前的实验环境下,仍然可以看到其在执行效率、资源消耗等方面带来的显著提升。
从实验结论还可以得出,即便是在相同作业使用相同的作业调度算法的情况下,如果采取的配置不同,往往也会对集群的效率造成影响。这种情况下,在选择公平调度算法或计算能力调度算法时,需要注意结合集群中的实际情况设置合适的资源池或者作业队列的数量和大小,以便发挥这两种作业调度算法在处理多用户情况时所具有的优势,提升整个集群的资源利用率。
5 结 语
本文通过对开源云计算平台Hadoop的研究,在实验室服务器上搭建了一个小型的Hadoop集群,并结合对集群资源进行实时监控的工具Ganglia实时对整个集群的硬件资源以及网络情况进行监控,实时地了解整个集群的运行情况。通过对Hadoop平台的作业调度算法的研究,并通过具体的实验测试各种调度算法的实际性能。在进行实验操作的过程中,利用集群资源监测软件Ganglia实时地对实验中集群的使用情况进行监测。实验结果表明,公平调度算法和计算能力调度算法相较于传统的FIFO算法具有更灵活、更高效的特点。当前的一些作业调度算法在具体的实际应用中也都存在着一些缺陷和不足。在未来的工作中,要跟据具体的作业需求,不断地去优化和改进对作业的调度。并通过详尽的实验测试,以验证算法的性能,并且不断地加以改进。
参考文献
[1] SHVACHKO Konstantin, KUANG Hairong, RADIA Sanjay, et al. The Hadoop distributed file system [J/OL]. [2011?09?17]. duanple.blog.163.com .
[2] 张建勋,古志民,郑超.云计算研究进展综述[J].计算机应用研究,2010,27(2):429?433.
[3] WHITE T,周敏奇,钱卫宁,等.Hadoop权威指南[M].北京:清华大学出版社,2011.
[4] TAI Stefan, NIMIS Jens, LENK Alexander, et al. Cloud service engineering [J/OL]. [2011?05?09]. www.docin.com/p?200029455.html.
[5] 张向丰.改进的蚁群引导电网系统云数据聚类故障检测[J].科技通报,2014,30(10):187?189.
[6] 赵晓冰.Hadoop平台下的作业调度算法的研究[D].郑州:郑州大学,2013.
