实时多通道数字助听器降噪算法
2016-05-09梁瑞宇王青云邹采荣
梁瑞宇 赵 力 王青云 邹采荣,3 荆 丽
(1东南大学信息科学与工程学院,南京 210096)(2南京工程学院通信工程学院,南京 211167)(3广州大学机械与电气工程学院,广州 510006)
实时多通道数字助听器降噪算法
梁瑞宇1,2赵力1王青云1,2邹采荣1,3荆丽1
(1东南大学信息科学与工程学院,南京210096)
(2南京工程学院通信工程学院,南京211167)
(3广州大学机械与电气工程学院,广州510006)
摘要:在兼顾降噪性能和功耗的基础上,提出了一种实时多通道数字助听器降噪算法.首先,将输入信号分解为16个子带,计算每个子带的声压级,并基于估计的声压级来计算子带噪声和语音概率;然后,利用直接判决方法计算子带信号的先验信噪比和后验信噪比;最后,计算子带增益函数以实现自适应降噪.将该算法与改进谱减法、自适应维纳滤波法和调制深度法进行了比较.结果表明:与其他3种算法相比,在10 dB白噪声的情况下,本文算法输出的平均信噪比减少约3 dB,主观语音质量评估得分最多提高0.90;在4种噪声环境下其平均主观语音质量评估得分提高0.41;所提算法采用子带声压级计算取代信号功率谱估计,节省了快速傅里叶变换的计算量,其时延较其他3种算法至少降低50%.
关键词:降噪;多通道助听器;自适应维纳滤波;声压级
引用本文:梁瑞宇,赵力,王青云,等.实时多通道数字助听器降噪算法[J].东南大学学报(自然科学版),2016,46(1) : 13-17.DOI: 10.3969/j.issn.1001-0505.2016.01.003.
噪声环境下听障患者的语音理解度是影响助听器使用的关键因素之一[1-2],故语音降噪算法是助听器中的一种核心算法.在超市、聚会等噪声环境下,即使说话人声音很大,听者仍然有可能无法理解语音内容[3],其原因在于,噪声使听障患者的听觉认知过载,从而干扰了神经系统对语音处理的能力[4].因此,在噪声环境下,不光要提高语音信号的可听性,更重要的是改善听障患者的理解度.长期以来,助听器的降噪方法主要包含方向性麦克风技术和语音降噪算法2类[5].在助听器设计中,集成方向性传声器的助听器通常假定使用者正前方的声音为有用声音,侧方和后方的声音为噪声[6].这种助听器技术在实际效果和用户满意度方面都存在一定的问题,且受到助听器体积和功耗的限制.此类助听器中也会使用降噪算法,如通过降噪提高环境识别算法性能[7].
在语音降噪方面,谱减法及其改进算法[8]是常用的降噪方法,其关键在于噪声功率的估计,但这类方法容易产生音乐噪声.在自适应降噪算法中,维纳滤波算法是助听器降噪算法中的研究热点之一[9],较高的算法复杂度一直是影响其实用化的关键因素.调制深度法是商用助听器常用的一种降噪算法,该算法通过检测调制深度来推断语音信号是否存在,从而调整信号增益以实现语音降噪.但是,当语音为竞争性噪声时,该算法不能区分期望的语音信号和不需要的噪声.除了经典算法外,研究者们基于时频分析、深度神经网络、正交分解、小波变换、压缩感知等提出了用于实现语音降噪的新算法[10-12],但大部分算法的复杂度较高,无法移植到助听器类低功耗、低时延的产品中.
针对现有问题,本文提出了一种改进的多通道数字助听器降噪算法.通过子带噪声估计,计算并调整每个子带的增益函数以抑制噪声.为了降低常用谱估计算法的复杂度,使用子带声压级估计代替信号功率谱估计.与改进谱减法[8]、自适应维纳滤波法[13]和调制深度法[7]相比,本文算法在信噪比(SNR)和主观语音质量评估得分(PESQ)方面都有一定改善,且算法时延最小.
1 多通道数字助听器降噪系统
多通道数字助听器降噪系统如图1所示.含噪语音信号通过预加重处理后进行多通道分解.系统选用6阶IIR滤波器组进行信号分解,通道数为16.信号分解后,在每个子带进行声压级计算、降噪和非线性响度补偿等基本操作.信号处理完成后,经滤波器综合并去加重,形成降噪后的语音信号.

图1 多通道数字助听器降噪系统框图
2 改进的子带降噪算法
设子带k的第m帧信号为y(m,k),可表示为
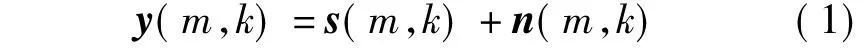
式中,s(m,k),n(m,k)分别为子带纯净语音信号和噪声信号.
在基于先验信噪比的维纳滤波算法中,子带k的增益函数G(m,k)为
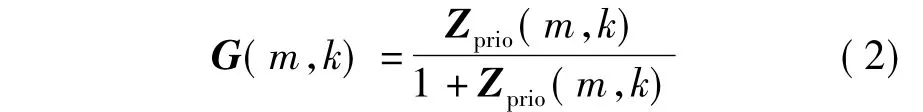
式中,Zprio(m,k)为子带k中第m帧信号的先验信噪比.当语音质量下降时,减少G(m,k)可抑制噪声.Zprio(m,k)通常采用直接判决算法[14]获得,即
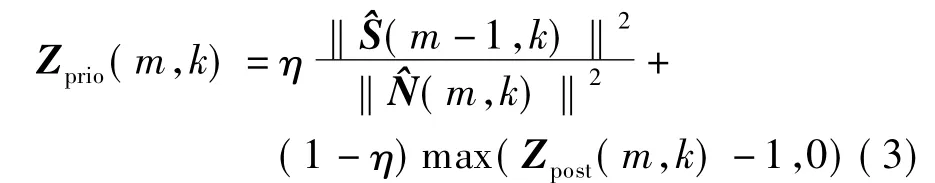

式中,‖Y(m,k)‖2为输入信号y(m,k)的功率谱.
功率谱通常基于FFT计算所得,故计算量较大.为此,本文结合助听器的基本算法,提出了一种改进策略,即采用声压级替代输入信号功率谱.声压级计算公式为

式中,pref=20×10-5Pa为参考声压; R为系统常量;‖y(m,k)‖2为输入信号能量.
①按照式(5)计算子带声压级L(m,k).
②计算平滑的子带能量,即
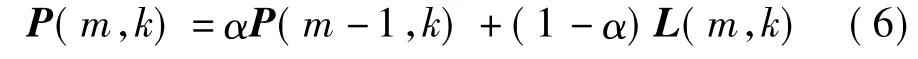
式中,α∈[0,1]为平滑系数,且此处取值为0.7.
③计算子带信号的最小能量Pmin(m,k),即
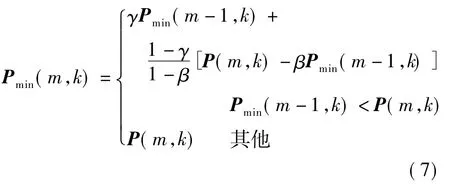

式中,δ为调整门限,此处取值为5.子带语音概率p(m,k)为
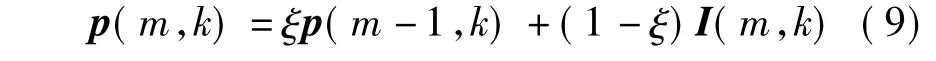
式中,ξ为概率更新系数,此处取值为0.2.
⑤计算估计的子带噪声功率谱,即
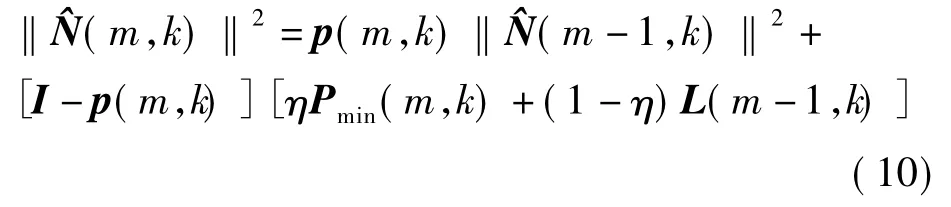
式中,η=0.8.
⑥将式(5)~(10)代入式(2)~(3),可得增益函数G(m,k).第m帧降噪语音^s(m,k)为

需要注意的是,系数η,α,β,γ,ξ的取值需要在语音质量和失真程度、响应速度和评估精度之间折中选择.为获得满意的性能,在不同的数字助听器或声学场景下需要采用不同的系数.
式中,β和γ为经验系数,此处β=0.96,γ=0.99.
④计算I(m,k),以确定子带内是否存在语音,其计算公式为
3 仿真与实验
3.1实验设置
为了考察本文算法的性能和计算量,将其与改进谱减法[8]、自适应维纳滤波法[13]和调制深度法[7]进行了比较.测试指标包括SNR,PESQ和算法时延.实验安排在静音室里进行,播放设备为扬声器阵列(包含4个扬声器和1个低音炮).使用声场景仿真软件SurroundRouter产生测试场景.实验噪声选自NoiseX-92噪声库,主要使用白噪声、驱逐舰噪声、语音噪声和粉红噪声.所选用的语音文件来自TIMIT语音库,信号的采样率为16 kHz.测试用助听器放置在扬声器阵列中心位置处.助听器声压级采用TES-52A声压计进行校准.实验过程中图1所示的响度补偿功能是关闭的.为比较分帧引起的时延,子带的帧长分别取为32,64,128.
3.2降噪性能比较
利用4种算法得到的降噪后的语音波形和语谱图见图2.所选语音片段为TIMIT语音库中的kdt_070文件,输入信噪比为10 dB,噪声类型为白噪声.由图可知,本文算法的效果最佳,所得的信号波形和语谱图与纯净语音信号最接近;改进谱减法的效果最差;调制深度法的效果略好;自适应维纳滤波法虽然过滤了大部分噪声,但在语音段的处理略差.

图2 降噪前后的语音波形和语谱比较
为了综合比较算法性能,给出了50段语音的平均输出信噪比和平均PESQ,结果分别见图3和表1.实验中选取的输入信噪比为0,10 dB,算法帧长为128.由实验结果可知,本文算法的平均性能与自适应维纳滤波算法的平均性能相近,明显优于其他2种算法.当输入信噪比为10 dB时,平均输出信噪比提高约3 dB.当输入信噪比为0 dB时改善程度不明显,说明算法在低信噪比情况下仍需改善.对于不同类型的噪声而言,本文算法对于白噪声和驱逐舰噪声的降噪效果最好;而对于其余2种噪声,自适应维纳滤波算法的性能最佳.对比4种算法,改进谱减法的平均输出信噪比最小.平均PESQ的比较结果与平均输出信噪比的比较结果基本相似.在4种噪声环境下,本文算法的平均主观语音质量评估得分提高0.41.4种算法的平均PESQ由高到低分别为:本文算法、自适应维纳滤波算法、调制深度法、改进谱减法.其中,在10 dB白噪声情况下,本文算法的平均PESQ最多提高0.90.
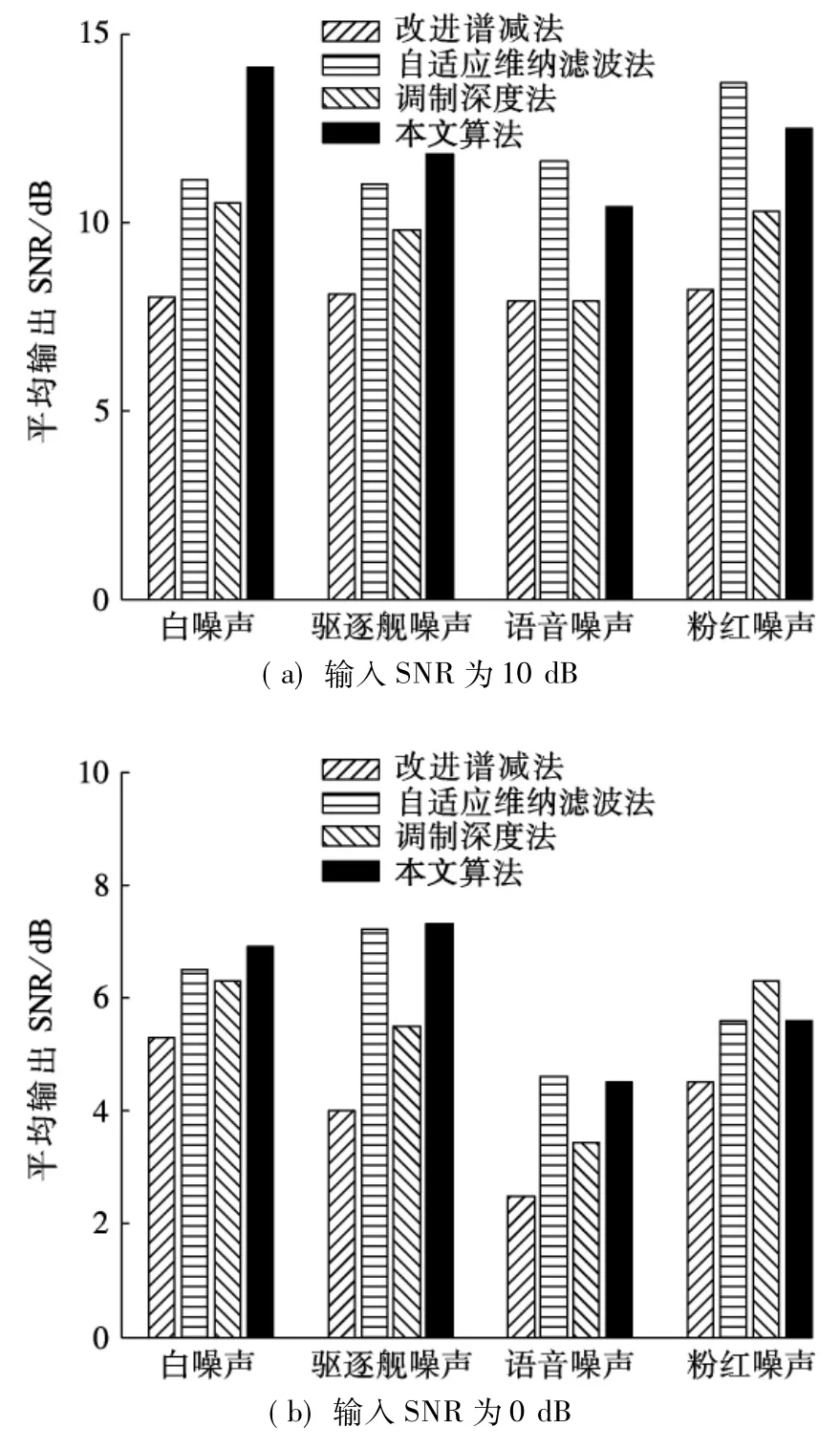
图3 4种算法的平均输出信噪比对比
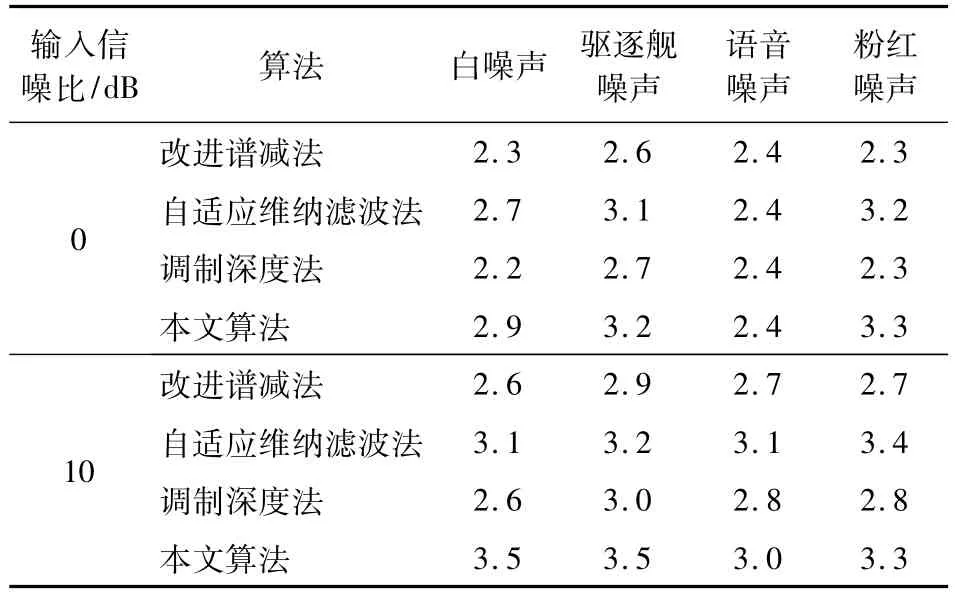
表1 4种算法的平均PESQ对比
3.3算法复杂度与实时性能比较
对于数字助听器来说,从输入到输出的时延不能超过40 ms.实际上,在一些高端商业助听器中,时延通常控制在十几毫秒.因此,计算复杂度是数字助听器算法的关键指标.低复杂度意味着实时性好、功耗低.
对于改进谱减法和自适应维纳滤波法而言,FFT和快速傅里叶逆变换(IFFT)是必不可少的.而调制深度法是通过计算调制深度幅度来估计噪声的,不需要进行FFT和IFFT运算,故其复杂度较低;但是当噪声本身为语音时,该算法的性能明显下降.本文算法使用子带声压级计算来替代复杂的信号功率谱估计,计算复杂度低,具有较佳的降噪性能.4种算法的时延性能如图4所示.统计的延时时间包括从分解到综合的全过程,即信号分解、子带声压级计算、子带降噪和语音综合,不包括响度补偿.由图可知,本文算法的时延最小,自适应维纳滤波法的时延最大.本文算法采用子带声压级计算取代信号功率谱估计,节省了FFT的计算量,其时延较其他3种算法至少降低50%.当帧长为128时,本文算法的时延至少减少2/3.
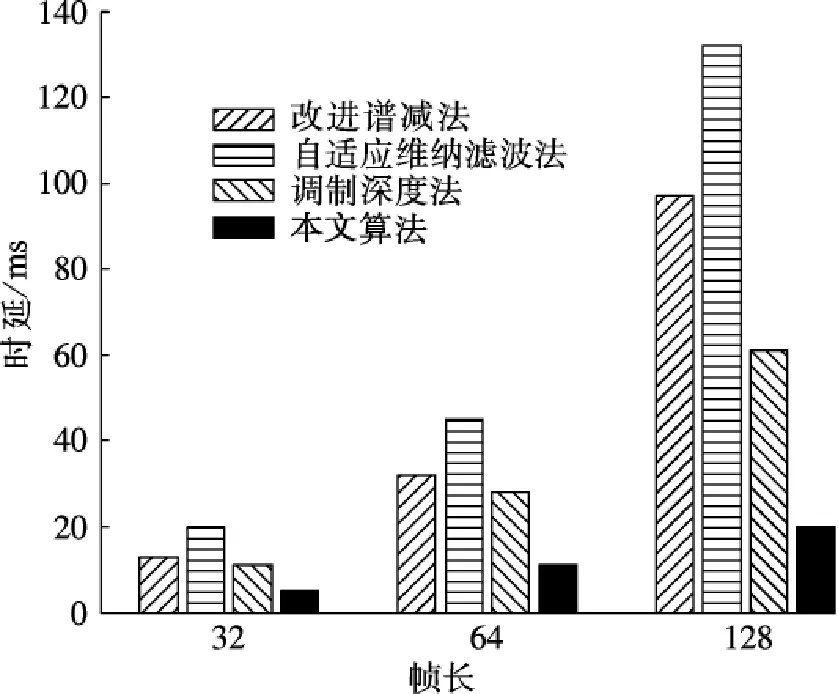
图4 4种算法的时延性能对比
4 结语
针对助听器降噪算法的特殊性,本文提出了一种实时多通道数字助听器降噪算法.该算法综合考虑了降噪性能和算法实时性,以子带声压级计算代替信号功率谱估计,从而有效降低了算法复杂度.与3种常用算法的对比实验结果显示,本文算法的综合性能最好.在输出信噪比和PESQ没有明显降低的情况下,本文算法的时延显著减少.未来的研究方向是通过分析不同的数字助听器和声学场景对算法系数的影响来选择算法参数,从而提高算法的适应性.
参考文献(References)
[1]Swanepoel D W,Clark J L,Koekemoer D,et al.Telehealth in audiology: The need and potential to reach underserved communities[J].International Journal of Audiology,2010,49 (3) : 195-202.DOI: 10.3109/ 14992020903470783.
[2]KochKiN S.MarkeTrakⅧ: The key influencing factors in hearing aid purchase intent[J].Hearing Review,2012,19(3) : 12-25.
[3]Lunner T,Sundewall-Thorén E.Interactions between cognition,compression,and listening conditions: Effects on speech-in-noise performance in a two-channel hearing aid[J].Journal of the American Academy of Audiology,2007,18(7) : 604-617.
[4]Kalluri S,Humes L E.Hearing technology and cognition[J].American Journal of Audiology,2012,21 (2) : 338-343.DOI: 10.1044/1059-0889(2012/12 -0026).
[5]Kamkar-Parsi A H,Bouchard M.Instantaneous binaural target PSD estimation for hearing aid noise reduction in complex acoustic environments[J].IEEE Transactions on Instrumentation and Measurement,2011,60 (4) : 1141-1151.
[6]Shinn-Cunningham B G,Best V.Selective attention in normal and impaired hearing[J].Trends in Amplification,2008,12 (4 ) : 283-299.DOI: 10.1177/ 1084713808325306.
[7]Chung K.Challenges and recent developments in hearing aids.Part I.Speech understanding in noise,microphone technologies and noise reduction algorithms[J].Trends in Amplification,2004,8(3) : 83-124.DOI: 10.1177/108471380400800302.
[8]Boll S F.Suppression of acoustic noise in speech using spectral subtraction[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1979,27(2) : 113 -120.DOI: 10.1109/TASSP.1979.1163209.
[9]Ngo K,Spriet A,Moonen M,et al.A combined multichannel Wiener filter-based noise reduction and dynamic range compression in hearing aids[J].Signal Processing,2012,92(2) : 417-426.DOI: 10.1016/j.sigpro.2011.08.006.
[10]Hendriks R C,Gerkmann T,Jensen J.DFT-domain based single-microphone noise reduction for speech enhancement: A survey of the state of the art[J].Synthesis Lectures on Speech and Audio Processing,2013,9(1) : 1-80.
[11]Benesty J,Chen J,Huang Y A,et al.Time-domain noise reduction based on an orthogonal decomposition for desired signal extraction[J].The Journal of the Acoustical Society of America,2012,132(1) : 452-464.DOI: 10.1121/1.4726071.
[12]Aggarwal R,Singh J K,Gupta V K,et al.Noise reduction of speech signal using wavelet transform with modified universal threshold[J].International Journal of Computer Applications,2011,20(5) : 14-19.
[13]Scalart P,Filho J V.Speech enhancement based on a priori signal to noise estimation[C]/ /IEEE International Conference on Acoustics,Speech and Signal Processing.Atlanta,GA,USA,1996: 629-632.
Real-time noise reduction algorithm for multi-channel digital hearing aids
Liang Ruiyu1,2Zhao Li1Wang Qingyun1,2Zou Cairong1,3Jing Li1
(1School of Information Science and Engineering,Southeast University,Nanjing 210096,China)
(2School of Communication Engineering,Nanjing Institute of Technology,Nanjing 211167,China)
(3School of Mechanical and Electric Engineering,Guangzhou University,Guangzhou 510006,China)
Abstract:A real-time noise reduction algorithm for multi-channel digital hearing aids is proposed based on the balance between noise reduction performance and power consumption.First,the input signal is decomposed into 16 subbands and the sound pressure level(SPL) of each subband is calculated.Based on the estimated SPL,the subband noise and the speech probability are computed.Then,the priori signal noise ratio (SNR) and the posteriori SNR of the subband signal are calculated by the direct decision method.Finally,the gain function is calculated to adaptively reduce noises.And the proposed algorithm is compared with the improved spectral subtraction,adaptive Wiener filter and the algorithm based on the modulation depth.The experimental results show that compared with the other three algorithms,the average SNR of the proposed algorithm decreases by about 3 dB and the perceptual evaluation of speech quality (PESQ) is at most improved by 0.90 when the SNR of the white noise is 10 dB.In addition,the average output PESQ is improved by 0.41 in four kinds of noisy environments.In the proposed algorithm,the estimation of the power spectrum is replaced by the calculation of the subband SPL and the fast Fourier transform computation is reduced,inducing at least 50% decrease of the time-delay compared with the other three algorithms.
Key words:noise reduction; multi-channel hearing aid; adaptive Wiener filtering;sound pressure level
基金项目:国家自然科学基金资助项目(61273266,61301219,61375028)、江苏省自然科学基金资助项目(BK20130241).
收稿日期:2015-08-30.
作者简介:梁瑞宇(1978—),男,博士,副教授;赵力(联系人),男,博士,教授,博士生导师,zhaoli@ seu.edu.cn.
DOI:10.3969/j.issn.1001-0505.2016.01.003
中图分类号:TN912.3
文献标志码:A
文章编号:1001-0505(2016) 01-0013-05
