一种策略融合的跨语言文本情感倾向判别方法
2016-05-04王素格李德玉
张 鹏,王素格,2,李德玉,2
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
一种策略融合的跨语言文本情感倾向判别方法
张 鹏1,王素格1,2,李德玉1,2
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
随着互联网的迅速发展,网络资源呈现领域开放性和语言多样性的特点。而语言多样性将造成网络信息交流上的障碍,整合多语言数据资源让用户快速了解其他语言信息具有重要的应用价值和现实意义。该文结合跨语言情感倾向判别的特点,提出策略融合的跨语言文本情感倾向判别框架。通过跨语言一致文本和跨语言混合概念空间的文本两种策略,构建基于双语协同文本情感倾向判别框架和基于跨语言特征混合文本情感倾向判别框架。在两种判别框架的基础上,融合两种框架判别结果,给出文本整体情感倾向性。实验表明,该文提出的融合策略在跨语言文本情感倾向判别上是有效的。
跨语言;倾向分类;多策略融合
1 引言
互联网络以及基于互联网的电子商务、社会网络等开放应用发展迅速,网络资源全球化进程加快,因特网所提供的资源呈现多语言化和跨语言的特点。网络资源的多语言特点给普通用户获取非母语网络信息造成语言障碍。如何整合多语言倾向信息,以通用的数据形式让用户了解多语言数据对某个对象的评价,具有重要的应用价值和现实意义。
在跨语言情感倾向分析任务中,由于语言习惯差异,不同语言表述相同对象、相近情感倾向所使用的表达方式和词汇差别较大,导致同义词汇在不同语言间分布差异较大。因此,跨语言情感倾向分析目的是利用源语言带情感倾向标签训练数据,克服词汇跨语言分布差异,对目标语言数据实现情感倾向分类。多语言环境下的跨语言情感倾向分析面临的主要困难有以下两点:
(1) 不同语言在词汇使用和句法结构上差异巨大,跨语言词汇特征的对应关系难于发现,导致不同语言数据表示特征对齐困难,使得多语言数据缺少一致的表示空间;
(2) 情感倾向观点本身具有分散性质,正面观点与负面观点判别性能差异较大,判别效果不稳定。
针对跨语言情感倾向分类任务,本文采用了两种跨语言情感倾向分析策略,一种是半监督框架的跨语言情感倾向判别方法,它通过调整原始特征空间方式实现跨语言情感倾向判别;另一种是基于词汇特征概念空间抽取策略的跨语言情感倾向判别方法,将特征一致性扩展到具有相似分布的潜层语义一致层面,抽取分布相近的情感倾向特征作为概念空间,在概念空间上实现跨语言情感倾向判别,以弥补原始特征稀疏分散的问题,这也是本文的主要创新。在这两种策略的基础上,本文提出了融合两种策略判别结果的框架,通过COAE2014任务2的实验,最终给出情感倾向在参赛的提交结果,得到了较好成绩。
2 相关工作
针对文本情感倾向判别分析,常采用机器学习方法,利用训练数据获得判别分类器,再对目标数据进行情感倾向分类。文献[1]首先使用了三种机器学习方法对文本情感倾向进行了判别,文本的倾向判别性能劣于传统话题分类任务,说明文本内容的构成对分类效果的影响至关重要。对于情感倾向判别任务,需要找到合理的与文本情感倾向相关的特征,以构建有效的数据表示空间。文献[2]利用了Fisher线性判别准则用于度量特征类别区分能力,从而获得类内聚集、类间分散的特征表示空间。实验表明,基于Fisher的特征选择方法可以在评论文本上获得更好的情感倾向分类效果。特征选择方法所确定的特征是单个词语,在数据量较大而文本篇幅较短时面临数据空间维度高而数据表示稀疏的问题,可利用数据压缩方法获得低维表示空间。文献[3]采用了潜层语义分析(Latent Semantic Analysis)方法,对原始数据进行降维表示,将原始数据表示在概念空间上。
对于特征对应关系发现任务,结构一致学习(SCL, Structural Correspondence Learning)[4]是一种较好的针对相同语言发现对应情感倾向特征对的方法。SCL通过发现相同语法结构和语义结构来构建特征对应桥梁。文献[5-6]则针对多语言任务提取高度相关的跨语言特征对。文献[7]则利用文本中常出现的情感表情符号网络建立情感倾向一致特征映射关系。本文借鉴了SCL发现一致语义结构的思想,通过特征融合方式表示跨语言情感倾向语义。另外,文本中存在“Great!”,“Fantastic!”,“Poor!”等独词句情况。而这些独词句含义单一、准确,具有类似于文献[7]中表情符号的性质,本文的特征将这些独词句作为特征。文献[8]则在已有基础上首次采用联合策略,将文本极性、表情符号和词语强度相结合,协同筛选主客观分类和情感倾向分类特征。
跨语言情感分类任务处理的对象是不同语种的语言,该任务可以通过语言自动翻译技术在目标语言和源语言上建立相同目标的任务数据集,这样便可以采用双语协同方式进行文本情感倾向判别[9]。文献[9]提出一种双语协同策略,针对源语言有少量可用标记样本点,而目标语言又有大量未标记样本点的情况,采用双语协同方式在源语言和目标语言上学习对等的分类器,对大量未标注样本点进行标注,之后利用一定的整合策略将源语言和目标语言上的预测结果整合在一起。在迭代过程中逐步将预测置信度较高的未标注样本点加入已知标记集合,这样便可逐步判别目标语言样本点,达到逐步引入目标语言样本和词汇特征的目的。文献[10]则介绍了编辑距离概念,本文利用编辑距离对齐误拼的西文单词。
3 双语协同跨语言文本情感倾向判别
在跨语言的文本情感倾向分类任务中,一般给定两部分数据集,即带有情感倾向标注的源语言训练数据集和未标注目标语言数据集。两部分数据集的情感倾向表示空间是不同的,因此,本文采用双语协同跨语言文本情感倾向判别策略,将情感倾向一致样本点作为载体,采用半监督学习方法在源语言和目标语言候选特征的并集中,建立情感倾向一致的表示空间。
用SO标记源语言数据集,用ST标记目标语言数据集。情感倾向标签y∈γ={-1,1},1表示正面情感倾向标签,-1表示负面情感倾向标签。SO和ST表示如下:
SO={(xi,yi)|i=1...M},FO={O1,O2,...,Om}。其中,SO为文本xi与标签yi映射对集合,FO为特征向量。ST={xj|j=1...N},FT={T1,T2,...,Tn},其中,ST为未标记文本点集合,FT为特征词向量。
为了建立FO和FT的部分语义映射关系,本文利用自动翻译技术实现FO和FT的语言互译,令FInt=FO∩FT,且FO∩FT≠∅。
跨语言文本情感倾向分类任务的目标是利用源语言数据集SO的情感倾向标签,预测ST中未标注样本点的情感倾向标签,即学习跨语言函数pSO(y|x)→pST(y|x)。为了构造跨语言函数,需要定义以下概念。
定义1 一致语言样本点是指在源语言和目标语言上具有相同的情感倾向性的样本点,即pO(y|x)和pT(y|x)是一致的,用Ssame表示。
根据定义1有Ssame⊆ST,即一致语言样本点集Ssame是目标数据的子集。这样,Ssame包含了ST上与SO一致的情感倾向信息。因此,Ssame可以由SO上的判别模型给出正确情感倾向标签,同时Ssame还包含了ST的情感倾向判别信息。通过Ssame上的判别模型还可以正确给出ST的情感倾向标签。
令S_train=SO∪Ssame,S_train为跨语言情感倾向判别数据集。在S_train上训练情感倾向判别模型,即为跨语言情感倾向判别模型。为了获得S_train,本文设计了双语协同跨语言情感倾向判别框架,整体过程如图1所示。
图1 双语协同半监督文本情感倾向判别
图1中的高置信度样本即为在源语言和目标语言上具有一致情感倾向性的样本点,即源语言模型和目标语言模型的判别结果是一致的。当无法发现新的高置信度样本点时,则迭代停止,此时获得的训练数据集即为S_train。
在整个文本情感倾向判别过程中,高置信度样本点的情感倾向在半监督训练过程中已被确定下来,剩余目标数据样本点情感倾向性需要最终判别结果确定。
高置信度样本点作为跨语言情感倾向信息的载体,可以看作包含源语言与目标语言共享的情感倾向观点词,同时包含部分目标语言常使用而源语言较少使用的情感倾向观点词。其中,共享情感倾向观点词数量已可以保证样本点被正确判别,且具有较高的置信度。如图2所示。
随着高置信度样本点逐步加入训练数据集中,目标语言上的情感倾向观点词被逐渐引入S_train中,从而实现跨语言情感倾向判别。
在半监督训练过程中,高置信度样本是跨语言情感倾向判别的桥梁,其核心问题是如何选择高置信度样本点。
3.1 高置信度样本选择
在单一语言上,判别模型对一个样本x给出的结果有如式(1)所示的约束。
(1)
即样本x属于正面概率P+(x)与属于负面概率P-(x)和为1。类别概率值的大小,反映了样本x属于正类或者负类的可能性。因此,属于正类和负类概率差值越大, 则说明判别结果越可靠。在判别概率基础上,定义置信度计算公式为式(2)。
(2)
Cfd(x)∈[-1,1],|Cfd(x)|越大,说明置信度越高,signal(Cfd(x))标记了样本x属于正类(正号)或负类(负号)。
在目标语言和源语言上同时具有较高可信度的样本能够寻找到高置信度的样本点,因此,设置高置信度样本的选择条件如下:
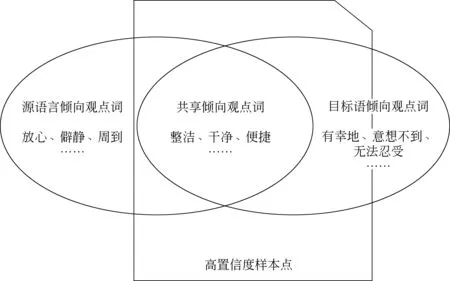
图2 高置信度样本点包含的情感倾向观点词
其中,α为选择阈值。满足以上条件的样本x应在源语言和目标语言上的判别结果同属正面或者负面,且置信度应同时高于阈值α。
3.2 双语情感倾向判别结果融合算法
通过半监督训练得到的训练数据集,包含原始训练数据和部分目标语言数据。在融合两种语言判别结果时,需要平衡目标语言与源语言判别结果的置信度。本文采用置信度加权叠加方式计算双语融合置信度,表示为式(3)。
(3)
其中,权重β调节源语言结果与目标语言结果对最终结果的影响程度,β的选择原则为偏向正确率较高的一方,若无法预知哪一方正确率较高时可以设置为相等权重。利用L(x)可以为样本x标记情感倾向标签。若L(x)≥0,则x为正面情感倾向,否则x为负面情感倾向。
综合上述高置信度样本点选择策略和双语情感倾向判别结果融合原则,基于双语协同策略的半监督情感倾向判别算法框架表述如下:
输入:Oo,Do,Od,Dd;//Od和Dd分别表示目标语言训练数据集和未标注数据集,Od和Dd分别表示源语言的训练集和未标注数据集,N为高置信度样本
输出:最终判别结果RF
Step 1分别在Oo,Od上,进行特征选择;
Step 2 在Oo和Od上分别训练分类器So和Sd;
Step 3 利用So和Sd,分别对Do和Dd进行情感倾向判别,得到带类别标签结果集为Ro和Rd;
Step 4若Ro∩Rd=∅,则转Step 8;
Step 5 若Ro∩Rd≠∅ ,则对每个x∈Ro∩Rd,若signal[CfdO(x)]=signal[CfdT(x)],|CfdO(x)|≥α,|CfdT(x)|≥α,则N=N∪{x};
Step 6 若N≠∅,则Oo=Oo∪N,Od=Od∪N,Do=Do-N,Dd=Dd-N;
Step 7 转Step 1;
Step 8 输出结果To=Ro,Td=Ed;
4 跨语言情感倾向特征混合
在双语协同跨语言文本情感倾向判别中,是以原始候选特征的子集作为表示特征用于文本表示,而原始词语作为空间表示仍然面临表示稀疏问题,本文采用跨语言情感倾向特征混合压缩的思想,抽取跨语言情感倾向特征。
在语言学上,词语具有同义关系,在概念上它们表达同一含义,这样使用多个同义词语作为特征会导致表示空间冗余、相同概念分散在多个特征词上,使得文本表示出现特征稀疏现象。情感倾向特征混合策略核心思想为将数据集映射到概念空间中,从而叠加原始特征信息,解决共享特征和样本点稀少问题。本质上,人对事物的认知具有一致性,因此,在文本中分布相似的词汇特征具有相近或相同的语义,本文采用提取同分布特征的方法获得概念空间。
设Sall=SO∪ST,Sall的特征词集为Fall=FO∪FT,Sall在Fall上的数据矩阵为Xall,其概念空间可以由奇异值分解(SVD)求得,如式(4)所示。
(4)
其中,U和V为两个单位正交矩阵,∑为正实数奇异值对角阵,奇异值按降序排列,即σ1≥σ2≥…≥σl。V中第i列向量对应表示重要程度为σi。选择奇异值最大的k(k≤l)个主成分作为语义空间,令P为V的前k列部分,即为式(5)。

(5)
则数据在概念空间映射为式(6)。
(6)
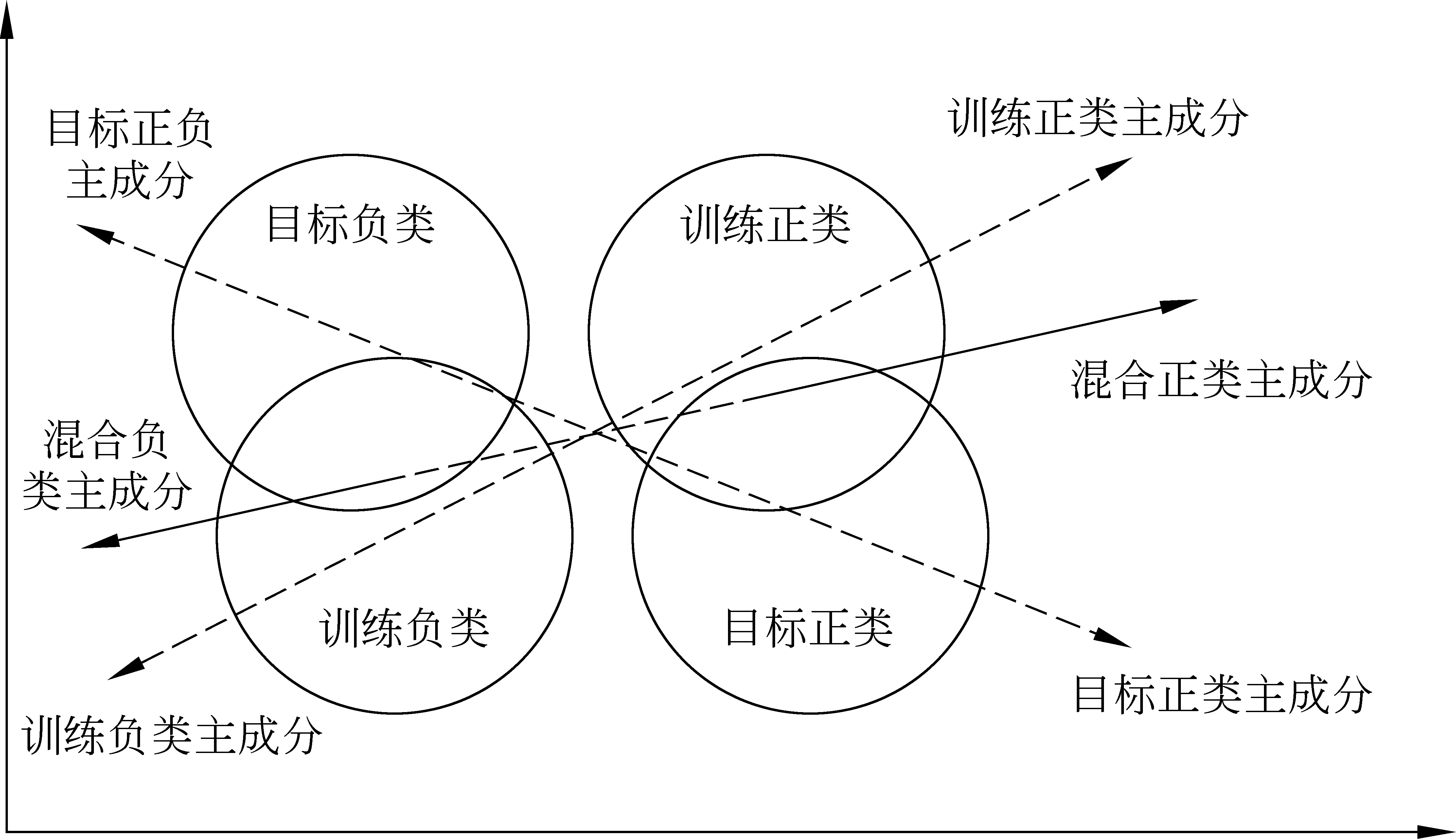
图3 跨语言特征混合
由图3可知,目标数据与训练数据混合后,混合情感倾向主成分会沿着混合数据分开的方向,同时较好地区分训练数据和目标数据。此时,训练集与目标数据集上的情感倾向信息同时被投影到主成分方向上,使得主成分综合了源语言数据和目标语言数据上的情感倾向信息。而混合后的主成分方向,它又位于训练数据和目标数据的主成分方向之间,是由源语言和目标语言所共享的情感倾向信息构成,因此,主成分可以强化不同语言间的情感倾向语义映射关系。
使用PCA混合情感倾向特征时,可将源语言和目标语言两种数据的并集作为PCA的输入,跨语言情感倾向特征混合判别的整体框架如图4所示。

图4 PCA跨语言特征混合
图4中所选取一致语言可以是目标语言或者源语言,也可以是其他中间语言。经过PCA跨语言特征混合后,选择一定数量的主成分作为混合特征空间,它的维度远小于输入原始数据维度,因此,通过PCA压缩后数据表示可以更加紧凑,从而减小了数据在高维空间中的稀疏性。
基于跨语言情感倾向特征混合策略的半监督跨语言学习过程,是将情感倾向特征混合方法替代双语协同分类过程,算法框架如下:

输入:一致语言训练集O,一致语言目标数据集D输出:最终判别结果RF1 在O∪D上进行PCA操作,获得混合空间H2 在H上O表示为Oh,D表示为Dh3 在Oh上,训练分类器S4 利用S对Dh进行情感倾向判别,获得结果集R5 利用第3.1节的高置信度选择条件,选择R上高置信度样本N6 若N≠⌀,则Oh=Oh∪N,转Step37 在Oh上训练分类器Fd8 利用Fd对Dd进行情感倾向判别,得到结果集RF
5 多策略跨语言情感倾向判别框架
在双语协同和跨语言情感倾向特征混合两种策略基础上,本文提出融合两种结果的多策略跨语言情感倾向判别框架,框架结构如图5所示。
图5中,数据预处理是基本的语言翻译、去停用词等操作;词语校准步骤用于对齐误拼的单词,以进一步对齐多语言词汇。融合操作是该框架的核心步骤,目的是将两种策略的判别结果合成为一个最终结果。
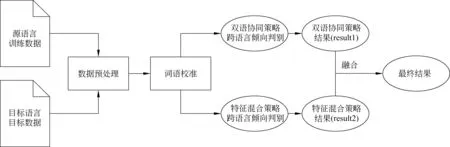
图5 多策略跨语言情感倾向判别框架
5.1 词语校准
由于目标数据为互联网数据,存在较多的拼写错误,所以需要对错误拼写进行校准,将误拼的单词统一为相同的拼写方式,这样可以增加一致特征数量,减小语言障碍。
根据拉丁语系语言特点,单词以字母编码表示,个别字母有拼写错误或误用的情况。较短的单词便于记忆,因此,通常不会被写错,而生僻的长单词错误率较高。通过计算编辑距离(edit distance /Levenshtein distance)可以度量两个字符串的最小差异, 文献[10]介绍了学习字符串间编辑距离的相关方法。
定义2 定义两个字符串a与b间的误拼距离如式(7)所示。
(7)


(8)
公式(8)中len(a)表示字符串a的长度,a[i]为字符串a的第i个字符。
由定义2中的ED(a,b)可以看出,若ED值越小(但不为0),a与b误拼的可能性越大。若a和b完全相同,ED值为零;在不同字母个数相同时,长字符串更容易为误拼字符串。通过对ED(a,b)设置一定的筛选条件和阈值,可以有效发现数据中误拼词对。再对数据中出现的误拼词进行合并操作,使它们具有相同拼写方式。
5.2 多策略结果融合
设双语协同策略判别作为第一个结果,记为result1;以特征混合策略作为第二个结果,记为result2。根据第三节样本置信度计算公式(1),设计样本整体置信度如式(9)所示。
(9)
由于样本整体置信度所属的区间不同,可能导致不同的判别结果,因此,设置如下融合策略:
(1) 若|cfd(x)|≥1,则说明两种策略判别结果相同,因此,直接将判别结果作为最终结果;
(2) 若 1>|cfd(x)|≥0.5,则说明两种策略判别结果不同,但结果区分度较大,以signal(cfd(x))作为最终结果;
(3) 若|cfd(x)|<0.5,两种策略区分度较小,此时以词语特征作为判别依据的结果1更为直接,所以将signal(cfdresult1(x))为最终结果。
6 实验与结果分析
本文实验针对COAE 2014的跨语言情感倾向分析任务(任务2)。实验数据包括四种语言,分别为德语(2 000篇)、英语(4 000篇)、西班牙语(2 000篇)、法语(2 000篇),共10 000篇。所有数据均为从互联网获得的原始文本数据。训练数据集为中科院计算所公开的带情感倾向标注的中文语料(2 000篇)。
对于COAE 2014的跨语言情感倾向分析任务(任务2)数据,进行以下预处理:
利用Google在线翻译器将训练数据和目标数据翻译为英文和中文两种表示形式,去除文本中的虚词、标点符号、数字和无法识别的符号。对于英语文本利用NLTK工具包进行词根化和词干化操作,将变形后的单词还原为其词根原形形式。
根据5.1节公式(7),给定三个误拼筛选条件:
(1) len(a)=len(b);
(2) len(a)>7,len(b)>7;
(3) B(a,b)≤3。
依据以上筛选条件,在任务数据集中共选择出1 856个误拼词对。经过语言处理和误拼词语校准后,在评测任务提供的数据集上共保留8 826个不同的英文单词,将其作为候选特征集,其他语言特征与英语相对应。外文文本翻译为中文后,错误拼写的单词无法被正确翻译,全部作为停用词去除。
采用LibSVM作为分类模型,采用线性核函数,其他训练参数为软件默认设置;文本特征权重采用Boolean方法,即特征词语是否出现。实验性能分析选用的评价指标为COAE 2014评测任务提供的评判指标。
为了验证本文提出的三种策略的有效性,设置三个实验。
(1) 双语协同策略实验:利用第三节介绍的方法,可实现从原始候选特征空间选择跨语言特征子集作为表示空间;
(2) 情感倾向特征混合策略实验:利用第四节介绍的方法,将得到的概念空间作为表示空间;
(3) 多策略结果融合实验,利用第五节介绍情感倾向判别框架,融合(1)和(2)两种实验结果作为最终结果。
6.1 双语协同策略实验
本实验使用文献[2]提出的Fisher线性判别作为特征选择方法,特征维度选100到1 500区间。双语判别结果融合的权重β=0.3,样本点置信度阈值α=0.95。实验结果为不同特征维度下性能指标的均值和浮动范围,见表1。
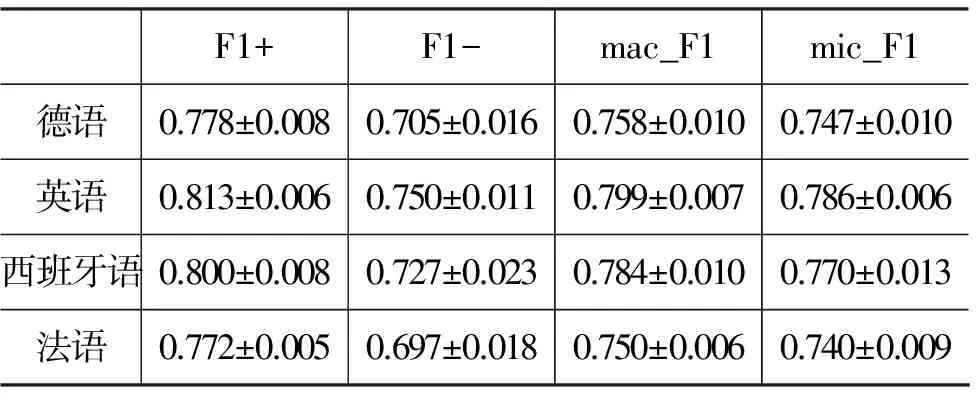
表1 双语协同策略实验结果
由表1可知,四种语言上正面观点判别性能(F1+)远超过负面观点判别性能(F1-),而且正面观点判别性能随特征数量浮动较小、较为稳定,负面观点判别性能浮动明显。主要原因如下:
(1) 由于正面观点较为集中,其特征容易被特征选择方法提取,在较少的特征区间上即可包含足够数量的正面观点特征,因此,正面观点判别性能随特征区间变化浮动较小。
(2) 负面观点相对较为分散,特征在不同数量的特征区间上分布不均匀,负面情感倾向判别性能变化幅度较大。互相冲突的负面观点特征可能会产生相互抵消的效果。
在酒店的评论数据中,正面评论集中在位置、服务、环境、交通、早餐等粗类别上,若没有什么明显缺陷之处时,评价通常不会太过于仔细,因此,正面评论原始特征相对集中;负面评价往往会指出具体不满意之处,如房间隔音差、地毯破旧、宠物限制、床太小、床单污染、清扫拖延等细类上,所以负面评论原始特征相对分散。
6.2 情感倾向特征混合策略实验
利用情感倾向特征混合策略替代特征选择方法,采用英语作为中间语言,主成分维度选择1 000维,以保持95%以上的样本方差,其他设置与双语协同策略实验相同。实验结果如表2所示。

表2 情感倾向特征混合策略实验结果
从表2结果可以看出:
(1) PCA跨语言特征混合方法在德语、西班牙语和法语上获得较好的结果,仅在英语上结果较差;
(2) 与表1结果对比可知,在德语、西班牙语和法语上,特征混合判别对负面情感倾向的判别性能有显著提高,正负面情感倾向差距减小。这是由于PCA特征混合有效地融合了较为分散的负面情感观点,有助于加强跨语言间的情感倾向关联;
(3) 在英语上面情感倾向的判别性能较表1下降。这是由于在PCA特征混合方法在选取主成分时,是以数据方差作为主成分重要性度量的。因此,PCA选取的混合特征与数据量有直接关系,数据量大的方向方差也大。实验英语数据集数据量远大于中文训练数据集,因而削弱了训练数据的指导性,使得判别性能下降。
6.3 多策略结果融合实验
对双语协同策略实验结果和多策略结果融合实验进行融合,并以评测任务作为横向比较平台。结果表明本文与其他单位的提交结果相比,取得较好的跨语言情感倾向判别性能。COAE2014任务2给出的性能指标与中位数、最好结果的比较如表3所示[11]。
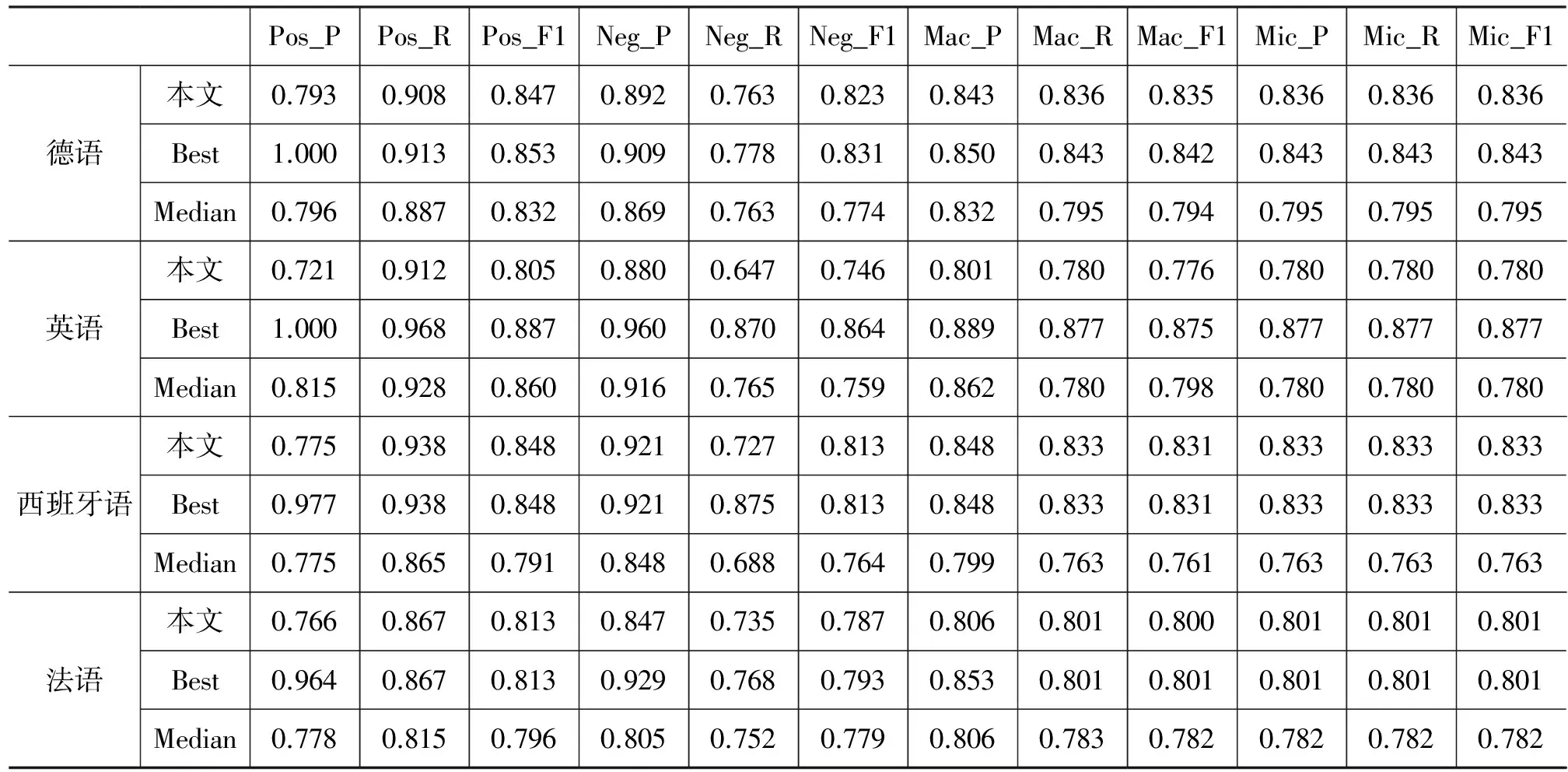
表3 评测任务结果
从表3可知,提交的评测结果的整体性能,在西班牙语和法语两种语言上均达到了最高准确率,在德语上略低于最高水平,在英语上达到平均水平。对比两种策略融合后的结果与单独采用两种策略的结果见图6所示,可以看出:
(1) 使用多策略融合框架提高了法语的判别性能,主要是在法语上各单独策略结果之间具有互补性;
(2) 在德语、英语和西班牙语三种语言上,两种策略的判别结果不具有互补性,融合后为两种策略的平均化。
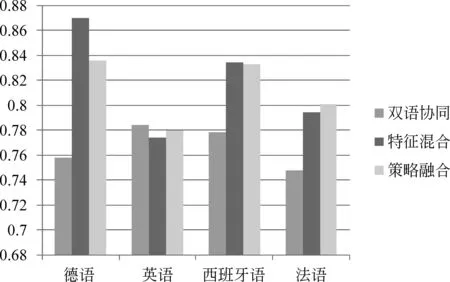
图6 结果准确度对比
7 结论与展望
本文提出采用多策略跨语言情感倾向判别框架,利用情感倾向一致点和情感倾向特征混合两种方式进行跨语言情感倾向判别。本文采用的方法可以有效地获取多语言情感倾向语义信息,并在评测任务中取得了较好的整体准确度。通过实验验证了情感倾向特征分布具有分散和聚集效应,说明了提出的特征混合策略在平衡情感倾向特征差异和缓解数据稀疏性上是有作用的。
情感倾向特征混合的目标是发现源语言与目标一致的跨语言情感倾向概念空间。在一致概念空间内,源语言与目标语言的情感倾向语义是独立同分布的,因而可以实现跨语言情感倾向判别。由于源语言与目标语言词汇的分布差异,从源语言和目标语言到一致情感倾向概念空间的变换方式应该是不同的。本文提出的特征混合方式则是采用相同方式将源语言和目标语言数据变换到相同的概念空间,且主成分特征提取方法受数据量大小的影响很大。因此,实验结果表现出了针对不同语言和不同数据量的判别性能存在差距的局限性。说明本文提出的线性组合的特征混合方法还没有反映出跨语言任务的本质,跨语言情感倾向判别任务具有多语言上和概念上的内在潜层语义结构。今后工作应从跨语言情感倾向概念空间结构以及多种语言到情感倾向概念空间的变换结构继续深入开展研究。
对于多策略方法融合而言,有效的融合集成需要基分类器具有效性和基分类器之间必要的差异性。如何针对跨语言任务设计一组好的基分类器仍有待进一步研究。基分类器需要针对跨语言任务从不同角度理解数据,这需要在对跨语言任务本质充分认识的基础上设计有效的融合集成策略。
[1] BoPang, Lillian Lee, Shivakumar Vaithyanathan. Thumbs up?: sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing, 2002,10: 79-86.
[2] Suge Wang, Deyu Li, Xiaolei Song, et al. A feature selection method based on improved fisher’s discriminant ratio for text sentiment classification[J]. Expert Systems with Applications, 2011, 38(7): 8696-8702.
[3] Thomas K Landauer, Susan T Dumais. Latent semantic analysis[J]. Annual Review of Information Science and Technology, 2004, 38(1): 188-230.
[4] John Blitzer, Ryan McDonald, Fernando Pereira. Domain adaptation with structural correspondence learning[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, 2006: 120-128.
[5] Peter Prettenhofer, Benno Stein. Cross-language text classification using structural correspondence learning[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, 2010: 1118-1127.
[6] Peter Prettenhofer, Benno Stein.Cross-lingual adaptation using structural correspondence learning[J]. ACM Transactions on Intelligent Systems and Technology, 2011, 3(1):338-343.
[7] Lumin Zhang, Shaojie Pei, Lei Deng, et al. Microblog sentiment analysis based on emoticon networks model[C]//Proceedings of the Fifth International Conference on Internet Multimedia Computing and Service, 2013: 134-138.
[8] Felipe Bravo-Marquez, Marcelo Mendoza, Barbara Poblete. Combining strengths, emotions and polarities for boosting Twitter sentiment analysis[C]//Proceedings of the Second International Workshop on Issues of Sentiment Discovery and Opinion Mining, 2013,2:1-9.
[9] Xiaojun Wan. Co-training for cross-lingual sentiment classification[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP,2009,1:235-243.
[10] Tric Sven Ristad, Peter N Yianilos. Learning string-edit distance[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(5): 522-532.
[11] 谭松波,王素格,徐蔚然,等. 第六届中文倾向性分析评测总体报告[R],第六届中文倾向性分析评测会议(COAE2014),昆明,2014:5-25.
A Multi-strategy Approach to Cross-Lingual Sentiment Analysis
ZHANG Peng1, WANG Suge1, 2, LI Deyu1, 2
(1.School of Computer and Information Technology, Taiyuan, Shanxi 030006, China; 2. Key Laboratory of Computational Intelligence and Chinese Information Processing of Ministry of Education, Taiyuan, Shanxi 030006, China)
The rapid development of Internet has built up a large number of cyber sources. This multi-lingual information come from a global environment with diversification. Considering the characteristics of cross-language sentiment identification, this paper proposes multi-strategy approach to perform cross-language sentiment analysis. The linguistic consistent sample and hybrid concept space are used to construct a bilingual cooperative framework and a sentiment feature mixture framework, respectively. Then results of tow framework are combined to decide the final sentiment label for a single sample. Experiments show that our strategy works well on cross-language sentiment analysis tasks.
cross-language; sentiment classification; multi strategy integration

张鹏(1988—),博士研究生,主要研究领域为文本情感分析。E⁃mail:zhpeng@sxu.edu.cn王素格(1964—),博士,教授,主要研究领域为自然语言处理与文本情感分析。E⁃mail:wsg@sxu.edu.cn李德玉(1965—),博士,教授,主要研究领域为数据挖掘与社会网络。E⁃mail:lidy@sxu.edu.cn
1003-0077(2016)02-0032-09
2014-05-20 定稿日期: 2014-09-08
国家863高技术研究发展计划基金(2015AA01407);国家自然科学基金(61175067, 61272095,61573231,61432011,U1435212);山西省科技基础条件平台计划(2015091001-0102);山西省回国留学人员科研项目(2013-014).
TP391
A
