基于PDTB的自动显式篇章分析器
2016-05-04周国栋
李 生,孔 芳 ,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
基于PDTB的自动显式篇章分析器
李 生,孔 芳 ,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
自动篇章处理是自然语言处理中非常有挑战的一个任务,对自然语言处理的其他任务,如问答系统,自动文摘以及篇章生成都有重要的作用。近年来,大规模篇章语料PDTB的出现为篇章研究提供了一个公共的平台。该文在PDTB语料之上提出了一个完整的基于条件随机场模型的显式篇章分析平台,该平台包含连接词识别、篇章关系分类和关系论元提取三个子任务。给出了在PDTB上各模块的实验结果,并针对错误传播问题,给出了完整平台的性能及详细分析。
篇章处理;条件随机场;宾州篇章树库
1 引言
自动篇章处理是自然语言处理中一项极具挑战的任务,是自然语言理解的基础,对许多自然语言处理的应用而言(如问答系统、自动文章摘要、篇章生成等)意义重大。
近年来,篇章理论的发展以及大规模篇章语料的构建,使得篇章级的分析应用越来越受到研究者的关注。2008年发布的最新版的宾州篇章树库(The Penn Discourse Treebank,PDTB)[1]是一个在D-LTAG[2]框架下标注的篇章级语料库。它以词法为基础,标注了谓词论元形式的篇章结构。该语料库同时还和宾州树库(The Penn Treebank,PTB)[3]进行了对齐,研究者可以很方便地从词法、句法、语义等多个视角分析篇章。PDTB语料库标注了显式和隐式两类关系。其中显式关系由连接词触发,驱动两个论元,形成的关系都具有明确的语义类别。该语料库为篇章分析提供了一个统一的平台,针对该标注体系,目前已有一些子任务得到了大量的关注,取得了很好的效果。本文给出了一个基于条件随机场模型的完整的显式篇章分析器平台,该平台由三部分构成: (1)连接词识别,判断某一给定的候选连接词是否真的承担连接词角色;(2)关系类别识别,判断连接词驱动的关系所属的语义类别;(3)关系论元的抽取,提取给定连接词驱动的文本域,并识别文本域承担的角色(Arg1或者Arg2)。三部分级联构成了一个自动显式篇章分析器,本文通过PDTB上的实验分析了影响显式篇章分析器性能的各类因素,并对三个模块间的错误传播进行了评测和分析。
本文其他部分的组织如下:第二节给出了基于PDTB语料库的显式篇章分析的相关研究;第三节提出了完整的基于条件随机场模型的显式篇章分析器平台;第四节给出了PDTB语料库上的详细实验结果及分析;最后给出了结论,并对下一步工作进行了展望。
2 相关工作
近年来,篇章理论的发展以及大规模篇章语料库的构建使得篇章级的分析受到越来越多的关注。本文关注焦点是基于PDTB语料库的显式篇章分析,下面就基于PDTB语料库的显式篇章分析的相关工作进行介绍。
在连接词识别研究方面,代表性工作包括: Pilter等[4]使用最大熵分类模型详细探讨了句法信息对连接词消歧的贡献。Lin等[5]在Pilter等工作的基础上又针对连接词消歧提出了一些补充特征,进一步提升了连接词识别的性能。目前,在正确句法树上,连接词识别的F值达到了95%;在自动句法树上,该模块的F值约为93%。
在关系类别的识别方面,代表性的工作包括: Pilter等在连接词识别的基础上使用朴素贝叶斯方法依据连接词和句法信息特征对第一层显式关系进行识别,其准确率(Accuracy)达到了94.15%。Lin等针对第二层显式关系使用最大熵分类模型依据连接词上下文特征进行了关系分类。在正确的句法树上,关系类型识别的F值达到了86%;在自动句法树上,该模块的F值约为80%。
在关系论元的抽取方面,代表性的工作包括: Dinesh等[6]针对Subordinate类型的连接词提出了一个tree subtraction算法来自动完成论元的抽取,但该方法使用了一套具有很强针对性的规则,对其他类别的连接词并不完全适用。Lin等借鉴Dinesh的tree subtraction算法,借助机器学习方法首先识别覆盖论元的最小子树,再利用tree subtraction算法在子树中抽取论元。但覆盖论元的最小子树也会包含非论元的部分,造成后续的抽取不能完全正确。他们的实验结果也证实了这一点: 完全精确匹配的标准下,Arg1和Arg2同时正确的性能仅为40%,而在部分匹配的标准下,这一性能可达到80%以上。Wellner等[7]提出一个机器学习的方法来确定连接词对应论元Arg1和Arg2的head,但是PDTB语料中并没有标注论元的head信息,因而评测上缺乏一致的标准。Ghosh等[8]基于条件随机场模型将论元抽取看成序列标注问题,给出了一个论元识别方案,但他们使用了一些来自PDTB的标准信息,例如语义类别、Arg2信息等,给出的结果也只考虑了标准句法树,未对自动句法分析结果进行评测。
本文侧重于显式关系篇章分析器的构建,与他们方法不同的是,连接词方面我们提出一个基于CRFs的序列标注模型;论元抽取方面,我们抽取完整的论元而不是论元的head,此外我们分为两步建模,先识别Arg2部分,再完全自动化地识别Arg1(未使用任何标准信息,所有特征均自动获取);为了系统的完整性,还构建了显式关系类别的识别模块。在此基础上,我们探讨了两种句法树类型以及模块之间错误传播对篇章分析器的性能影响。
3 显式篇章分析器
本文提出的篇章分析器的框架如图1所示*PDTB体系认为连接词是篇章级的驱动谓词,它驱动两个论元形成一定的语义关系。已有的研究表明,对显式关系而言,连接词及其上下文已经提供了足够的信息来确定语义关系的类别。此外,我们的初步实验表明引入任何的论元信息都将降低语义类别的识别性能,再加上自动论元识别的性能低于50%,它的引入必将降低语义类别的识别性能。因此,本文提出的显式篇章分析器框架采用仅利用连接词信息进行关系类别的识别,在关系类别识别的基础上,结合连接词信息进行关系论元的抽取。,可以看到该框架由三部分构成:连接词识别、显式关系类型判别和论元抽取。其中,论元抽取分两步进行,首先识别与连接词关系密切的Arg2论元,在已经识别出Arg2论元的基础上再抽取Arg1。

图1 篇章分析整体框架

图2 一个显式篇章关系示例
具体流程我们以图2给出的示例进行解释。这是摘自wsj_2015文章中表达时序关系的一个关系实例,连接词用下划线标出,论元Arg1用斜体表示,论元Arg2用粗体表示。我们的平台首先通过篇章连接词识别模块确定候选连接词“after”的确是一个篇章连接词;然后利用显式关系类型判别模块识别出当前的连接词“after”表述的语义关系是Temporal;最后在论元抽取部分对连接词“after”驱动的论元进行二步式抽取:首先识别出Arg2是“having been unchanged in October”,然后再识别出Arg1是“Factory output dropped 0.2%, its first decline since February”。
下面我们将详细介绍显式篇章分析器中每一构成部分。
3.1 篇章连接词识别
篇章连接词的识别是显式篇章分析的第一步,目标是根据上下文信息确定某一候选连接词是否真正承担连接词角色。由于后续的篇章关系类别和论元识别都与连接词密切相关,这一步的性能对整个显式篇章分析至关重要。目前传统的连接词识别方法是:根据PDTB预设的候选连接词列表*在PDTB语料库中预先设定了100个不同类型的候选连接词。获取当前上下文中的候选连接词,针对每个候选连接词提取其所在的上下文词汇、句法及语义信息来判断其是否真正承担连接词角色。可以看到,传统的连接词识别方法对预设的候选连接词有着极大的依赖。有些研究表明这些预设的候选连接词具有一定的领域性。例如,Balaji等[10]针对PDTB和BIODRB[11](生物医学篇章关系语料库)进行了分析,发现两个语料库公共的候选连接词仅占各自候选连接词的40%左右,使用不同的候选连接词列表将严重影响篇章连接词识别的性能。
本文将连接词识别问题看成是一个序列化标注问题,提出一个基于条件随机场模型的连接词识别方法。该方法不依赖候选连接词列表,可方便地应用于多个不同领域、不同语言的篇章关系语料库。
在序列化标注问题中,我们首先需要确定需要使用的标注集合。依据连接词是否可以跨句,是否由不连续的几部分构成,我们将连接词分成三类:(1)group:连续的不可分的,只能出现在一个句子中,例如,as a result;(2)senIntra:只能出现在一个句子中,包含分散的多个部分,例如,if...then;(3)senInter:出现在两个句子中,包含分散的多个部分,例如,on one hand...on the other hand。其中第三类连接词出现的频度极低,本文后续的工作暂时忽略了这一类型。借鉴中文分词以及短语识别的标注集合,我们使用了五个标注符:B,连接词包含多个单词,当前词为这一连接词的开始;I,连接词包含多个单词,当前词位于连接词的中间;E,连接词包含多个单词,当前词是连接词的最后一个词;S,连接词仅包含一个单词;O,不属于连接词。标注符与连接词类别相结合,在我们的连接词识别模块中共使用八个标注符,B/I/E分成group和senIntra两种,而S只针对group类别,O与连接词无关。具体标注符如表1所示。
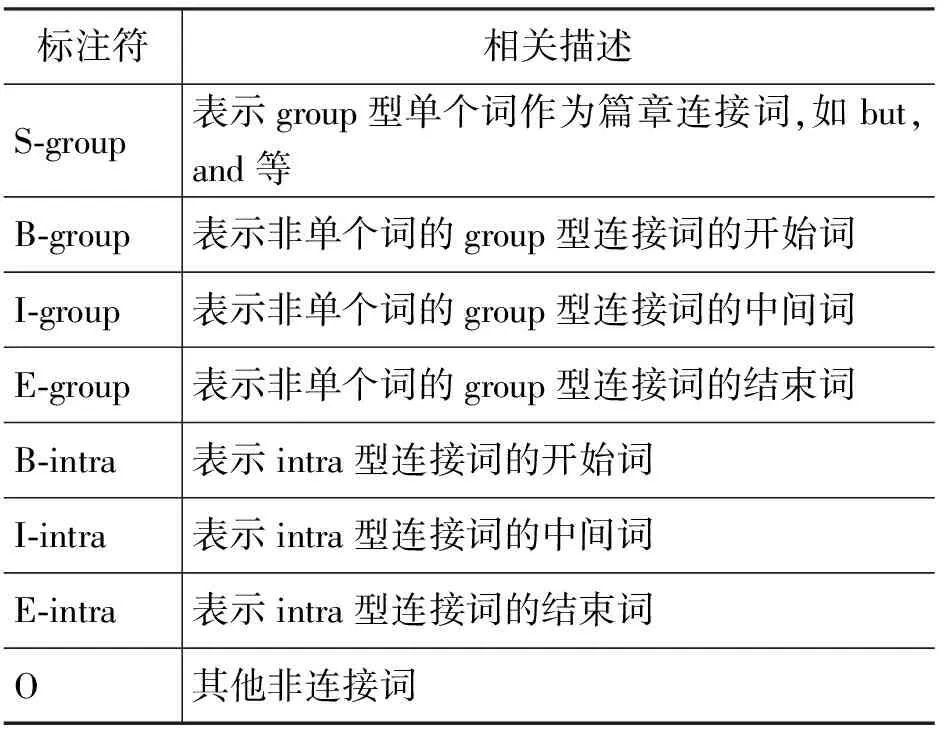
表1 篇章连接词识别使用的标注集
确定了标注集合后,我们从词法、句法等方面提出了一系列上下文特征用于连接词的识别,连接词识别使用的相关特征如表2所示(我们假设当前词是图2给出的示例中的连接词“after”,该示例对应的标准句法树如图3所示。
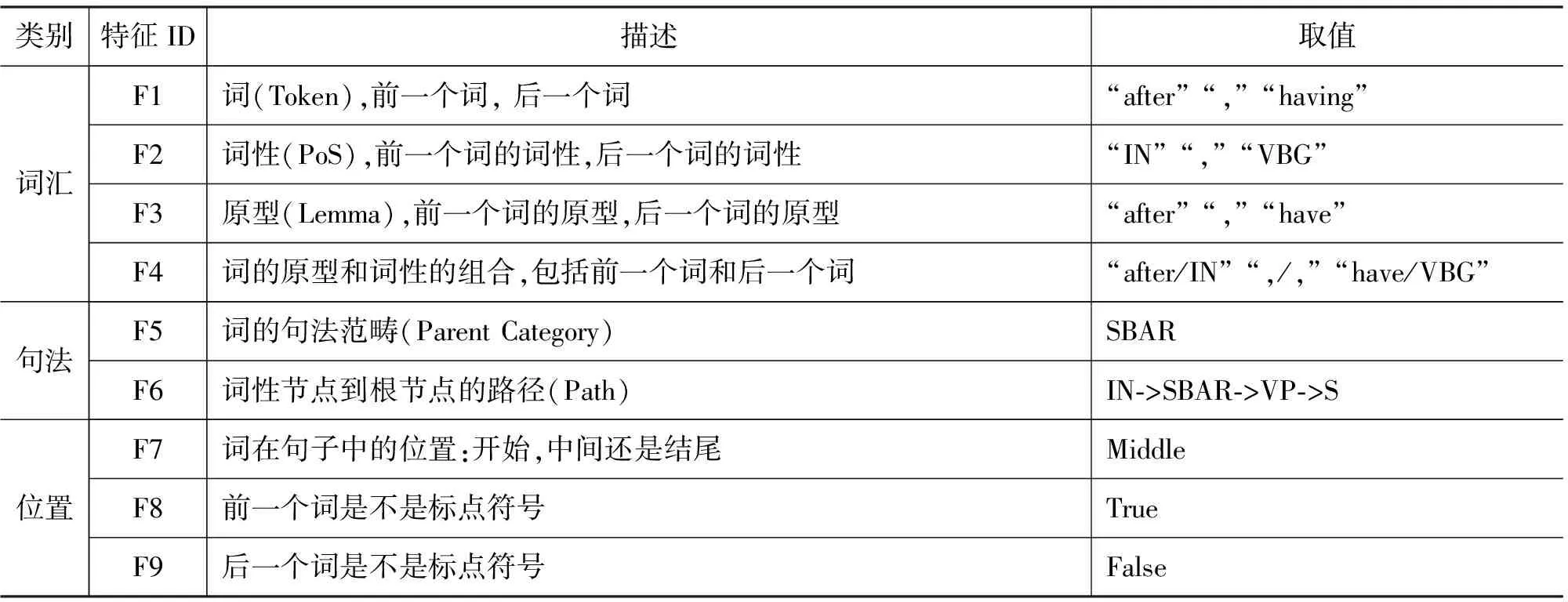
表2 篇章连接词识别使用的特征及对应描述

图3 图2给出示例对应的标准句法树
特征F1~F4都是自然语言处理中常见的特征,除了当前词,我们还同时考虑了词的上下文环境以及相关组合特征。特征F5描述了一个词的句法范畴,我们称之为Parent Category,从句法树上来看它的值就是该词的词性节点的父节点的值。特征F6也是一个句法类型的特征, 它描述了节点的语法推导信息,句法特征对连接词的消歧被证明是非常有效的[3]。特征F7描述了一个词出现在句子中的位置信息,通过观察语料我们发现一些词出现在特殊的位置,例如,but出现在句子的开始,那么它很有可能是作为篇章连接词。特征F8和F9是两个相似的特征,描述了词的上下文是否含有标点符号。标点符号的出现常常表示关键信息(如连接词,命名实体等)的开始或结束。特别的,一个句子的开始词我们认为其前面是有标点符号的;相似的,一个句子的末尾词其后面也是有标点符号的。
3.2 显式关系类型识别
识别出篇章连接词后,我们需要进一步对其表达的篇章关系的语义类别进行识别。PDTB语料中关系的语义类别分为三个层次, Class、Type和Subtype。第一层共有四种类型:TEMPORAL, COMPARISON, CONTINGENCY和EXPANSION。TEMPORAL是一种时序关系,表明关系论元在时间上存在先后或者交叉等某种联系;COMPARISON表明两个论元之间存在对比关系;CONTINGENCY表示一种偶然性,表明论元之间存在因果或条件依赖等某种联系;EXPANSION表示扩展关系,一个论元对另一个可能进行了补充说明等。
已有的研究表明,连接词本身已经蕴含了足够的信息来对其所属的语义类别进行分类,采用与Lin等[8]提出的类似的方法,我们使用连接词本身、连接词前后的词及其词性为特征,使用最大熵分类器实现了一个显式篇章关系类别识别模块。虽然第一层四大类语义类别的定义略显宽泛,但对许多NLP应用(例如文本摘要)已经足够。相比而言,第二层的16类定义更加严谨规范。鉴于此,本文分别给出了第一层和第二层上显式关系类型的识别结果。
3.3 论元文本域的抽取
确定了篇章连接词以及对应的篇章关系语义类别后,我们尝试进行精确的论元文本域的识别。
根据PDTB手册中对论元Arg1和Arg2的定义我们可以看到,Arg2与连接词的关系非常紧密,它严格受连接词的驱动,常规情况下都与连接词同属一个语句;相比Arg2,Arg1与连接词间的关系松散很多,位置也更加灵活,既可以与连接词同属一个语句,也可出现在连接词所在语句之前的任意句子中。因此,已有的研究已经明确,Arg1论元的识别更具挑战性。此外,PDTB语料中Arg1所处位置的统计表明,60.9%的Arg1论元与连接词处于同一语句,30.1%的Arg1论元位于连接词所属语句前直接相邻的语句中,其他情况仅占10%。因此,传统的论元识别方法是:同时进行Arg1和Arg2论元的识别。其中Arg2论元的搜索空间限定在连接词所在句子,而Arg1则首先根据连接词所处的上下文判别其所处位置(与连接词处于同一语句SS,还是不同语句PS),再根据结果采用不同的策略进行Arg1论元的抽取。
考虑到连接词与Arg1和Arg2之间的关系并不等价,同时也想探究一下自动识别出的Arg2论元是否有助于Arg1论元的抽取,我们将论元文本域的抽取分成两个步骤:首先以连接词所在语句为搜索空间进行Arg2论元的识别;在已知Arg2论元信息(自动识别)的基础上,以论元所在语句和前一语句为搜索空间进行Arg1论元的识别。虽然这两个步骤的搜索空间不同,使用的特征也存在一定的差异,但都可以看作独立的序列标注问题。同时序列标注任务在确定搜索空间后也无需再区分SS或是PS的状况,而对于这两类序列标注问题,我们可以采用统一的B/I/E/O标注集进行标注。表3给出了这两个步骤所使用的特征集合。

表3 论元抽取的特征描述
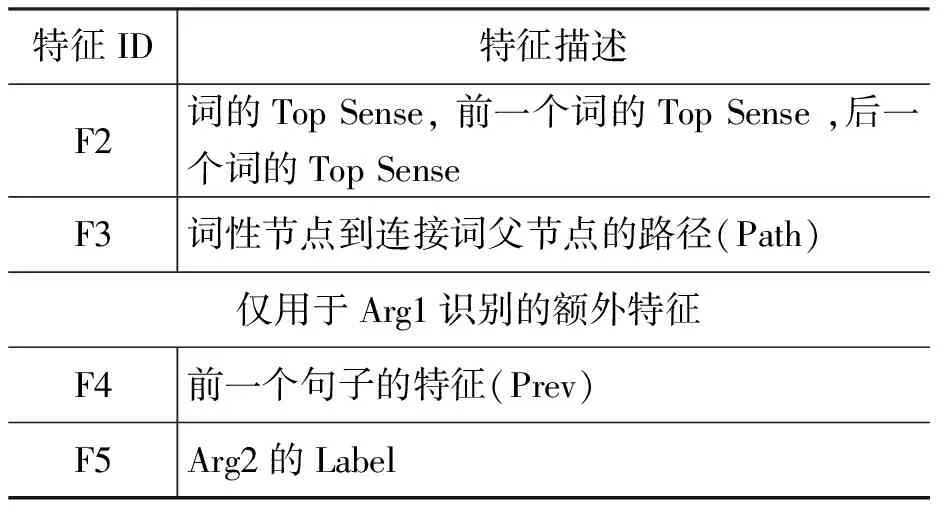
续表
特征F1描述了一个词以及它的上下文信息,是自然语言处理中常见的特征。特征F2是指PDTB标注体系中语义关系的第一层,我们使用关系语义识别模块自动确定关系的语义类型。显然只有那些是连接词的token才有Top Sense值,非连接词的该特征取值为none。特征F3是从句法树中提取的路径信息,我们的路径从词性节点开始到连接词的父节点。如果连接词是一个短语,我们取它们的最低公共节点作为父节点。特征F4主要是用来判断Arg1的句子边界,我们认为如果下一个句子的开始词是某一连接词驱动的论元的一部分时,Arg1很有可能在前一个句子中。特征F5是指当前词是否属于第一步识别出的Arg2中的一部分,因为Arg2和Arg1是不重合的,我们使用该特征可以进一步限定Arg1的范围。
4 实验结果及分析
4.1 实验设置和评测方法
为了与已有的研究进行性能比较,我们采用了与Lin等一致的数据集和评测方法。
所有实验均使用PDTB语料,将其中的section 02~21作为训练集,section23作为测试集,section 00~01作为开发集。整个平台中,我们使用了CRF++*http://crfpp.sourceforge.net/这一序列化标注工具,OpenNLP中附带的maxent工具包*http://maxent.sourceforge.net/作为最大熵分类器,所有参数均选择默认值。为了和Lin等进行公平的比较,自动句法树也使用Charniak句法分析器*ftp://ftp.cs.brown.edu/pub/nlparser/得到。
评测指标采用标准的准确率(Precision),召回率(Recall)以及F1值。特别说明的是,在评测论元抽取的性能时,我们采用严格的精确匹配标准进行评测,即排除开始和结尾的标点符号后使用字符串严格匹配来判定论元提取是否正确。
我们考察了三个不同实验设置下显式篇章分析的性能,分别是:
(1) GS+noEP: 使用标准句法树,模块之间没有错误传播,即每一步的前一个环节完全正确;
(2) GS+EP:使用标准句法树,模块之间有错误传播;
(3) Auto+EP:使用自动句法树,模块之间有错误传播。这一评测给出了整个端对端自动显式篇章分析的性能,可以应用于完全自动的显式篇章分析。
4.2 实验结果与分析
表4给出了在标准句法树下三种类别特征对连接词识别性能的贡献,仅用词汇特征(F1-F4)已经能达到88.43%的F1值,结合句法特征(F5-F6)能显著提高识别性能。使用位置特征(F7-F9)也能进一步提高连接词的性能。
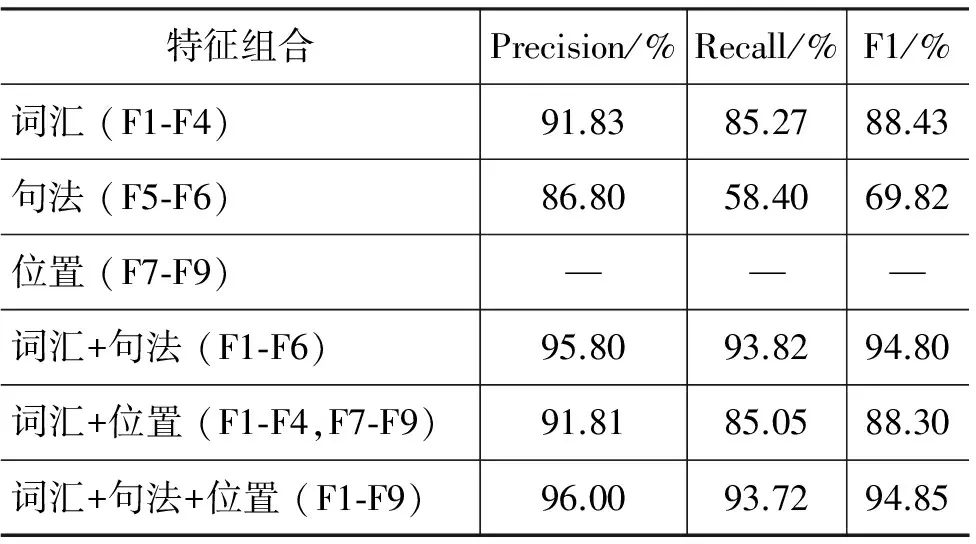
表4 标准句法树下不同类别特征对连接词的贡献(—表示0)
表5给出了分别使用标准句法树和自动句法树时获得的连接词识别的性能,连接词识别处于整个框架的第一步,不存在错误传播问题。

表5 两种不同句法树下篇章连接词识别的性能
从连接词的识别效果来看,GS和Auto的性能相差1.86%,自动句法树对连接词识别性能的影响较小。分析识别结果我们发现,“and”和“but”引起的歧义最大。表6的最后一列给出了目前性能最好的Lin等[5]的连接词识别的性能,比较发现,我们给出的基于CRFs的连接词识别的性能略逊于Lin等系统的性能,但我们的连接词识别方法的优势在于它可应用于不同领域、不同语言。
表6给出了不同实验配置下关系语义类别识别的性能。Prasad等人[10]指出整个显式关系中,标注人员对第一层和第二层语义关系一致认可率有94%和84%,实验中我们仅使用连接词及其前后词的信息在第一层语义上就获得了95.88%的F1值,这也说明连接词识别的性能是至关重要的,如果不能正确识别连接词,就无法确定它表达的关系语义信息。

表6 关系分类的性能
我们按照平台构建的顺序评测论元抽取的性能,首先对论元Arg2的抽取性能进行评测,GS+noEP下提取的性能最好,F1值达到了81.57%,GS+EP下性能相较GS+noEP配置下获得的性能下降了2.71%, Auto+EP配置下F1值相比GS+EP又下降了3.85%。论元Arg2抽取的误差有两个来源:连接词识别的误差和显式关系类型识别的误差。只有连接词被识别为篇章连接词时才有论元识别过程,这两方面的误差传播导致在Auto+EP配置下,我们系统的性能较GS+noEP配置下衰减了6.56%。

表7 Arg2 抽取性能
抽取出论元Arg2后我们利用其结果辅助论元Arg1的抽取。从前文分析可知,Arg2和连接词在同一个句子,而Arg1的位置并不固定,所以Arg1的识别不如Arg2容易。从表8结果来看也证实了我们的猜测,没有误差传播情况下GS+noEP的性能最高,F1值达到58.94%。由于误差传播的原因,GS+EP和Auto+EP下性能都有不同程度的衰减。论元Arg1之间存在三个误差来源,分别是连接词识别、篇章关系类型以及论元Arg2的抽取误差。对比分析Arg2和Arg1识别性能,我们发现一点相似之处,CRF给出的召回率相对准确率较低,这可能由于CRF在预测时偏于保守。

表8 Arg1 抽取性能
在论元Arg1抽取中,我们使用了Arg2识别的结果作为Arg1的一个特征。表9给出了在GS+noEP环境下Arg2特征对Arg1抽取性能的影响,可以看出使用Arg2能显著提高Arg1的抽取性能约0.54%(p<0.005)。

表9 特征Arg2对Arg1抽取性能的影响
相对于Arg2,论元Arg1的位置比较灵活,实验中我们将连接词所在的句子以及前一个句子作为Arg1的候选空间。表10评测了Arg1在不同位置的抽取性能,从结果来看不同句的论元Arg1抽取性能相对于同句的低了很多,这导致了Arg1的整体性能在50%左右。此外,可以看出不同实验设置下的性能差异主要来源是与连接词同句的Arg1的性能间的差异。

表10 不同位置的Arg1的抽取性能
按照PDTB的标注要求,每个显式篇章关系有一个篇章连接词和对应的两个论元Arg1和Arg2。为此我们评测了Arg1和Arg2同时抽取成功的性能。表11给出了不同配置下的抽取性能,并给出了相同配置下Lin等的性能。相对于GS+noEP配置,GS+EP和Auto+EP配置下论元抽取的F1值分别下降了约3%和5%,最终Auto+EP配置下系统的F1值只有45.13%。分析识别结果发现有些连接词我们的CRF方法无法提取出对应的论元,这显然违背了PDTB标注要求。我们在将来准备尝试进行全局化的学习,加上这一约束,来提高论元识别性能。
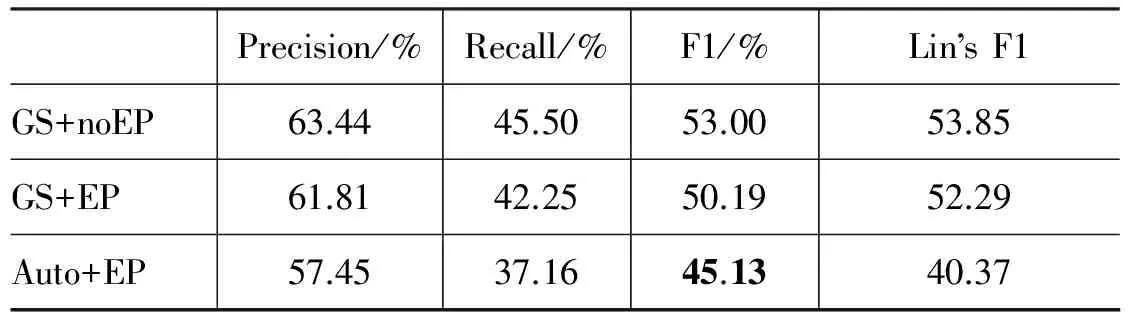
表11 Arg1 和Arg2同时抽取正确的性能
表11最后一列给出了Lin等论元抽取性能,与Lin等提出的平台对比,我们的平台在Auto+EP环境下的性能好于他们,主要原因是:Lin等采用的是传统论元识别方法,即首先确定论元Arg1与连接词的位置关系,然后使用不同策略进行Arg1的抽取。显然论元Arg1位置识别是否正确将会严重影响后续抽取的性能,而他们汇报的结果表明,在Auto+EP配置下位置识别的性能低于90%。因此Lin等论元抽取性能,在Auto+EP配置下相对于GS+EP配置下降了约12%,而GS+noEP配置与GS+EP配置下的抽取性能仅相差约1%。我们给出的论元抽取方法去除了位置识别步骤,而直接以连接词所在语句以及前一语句作为搜索空间来识别Arg1论元,从而避免了位置判断的影响。
至此,我们对每一个模块进行了细致的评测。最后我们评测了显式篇章分析平台的整体性能,评测的依据是:连接词正确识别,其所表述的关系语义类别识别正确,并且由连接词驱动的两个论元Arg1和Arg2也精确识别时,我们认为这一显式关系分析正确。由于GS+noEP条件下各模块相互独立不存在误差传播,所以没有整体性能这一指标。

表12 系统整体性能
从表12中可以看出篇章分析器整体性能无论GS+EP还是Auto+EP性能都不算十分理想。一方面模块之间存在误差传播;另一方面论元Arg1的抽取,尤其是与连接词不同句的Arg1,相对困难给整体的性能带来了很大的影响。我们在以后的工作准备对论元抽取进一步研究来提高抽取性能。
5 总结
本文提出了一个基于条件随机场模型的完整的显式篇章分析器平台,该平台包括连接词识别、篇章关系分类和关系论元提取三个子任务。在PDTB语料基础上给出了各模块的实验结果,并针对错误传播问题,给出了完整平台的性能及详细分析。
从实验结果来看,论元Arg1的提取性能还有待提高,特别是与连接词不同句的Arg1提取性能。此外有些连接词我们CRF方法无法提取出对应的论元,这违背了PDTB标注的要求。在未来的工作中,一方面我们尝试全局化的方法来提高显式篇章分析的整体性能;另一面我们尝试将篇章分析应用于自动文摘、篇章耦合等其他自然语言处理任务中。
[1] PDTB-Group. The Penn Discourse Treebank 2.0 Annotation Manual[OL]. The PDTB Research Group, 2007.
[2] Bonnie Webber. D-LTAG: Extending lexicalized TAG to discourse[J]. Cognitive Science, 2004,28(5):751-779.
[3] Mitchell P Marcus, Beatrice Santorini, Mary Ann Marcinkiewicz. Building a Large Annotated Corpus of English: the Penn Treebank[J]. Computational Linguistics, 1993,19(2):313-330.
[4] Emily Pitler, Ani Nenkova. Using syntax to disambiguate explicit discourse connectives in text[C]//Proceedings of the ACL-IJCNLP 2009 Conference Short Papers, Singapore,2009.
[5] Ziheng Lin, Hwee Tou Ng, Min-Yen Kan. A PDTB-styled end-to-end discourse parser[C]//Proceedings of the Natural Language Engineering,2012.
[6] Nikhil Dinesh, Alan Lee, Eleni Miltsakaki, et al. Attribution and the (non)-alignment of syntactic and discourse arguments of connectives[C]//Proceedings of the ACL Workshop on Frontiers in Corpus Annotation II: Pie in the Sky, Ann Arbor, MI, USA,2005.
[7] Ben Wellner, James Pustejovsky. Automatically identifying the arguments of discourse connectives[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), 2007: 92-101.
[8] Sucheta Ghosh, Richard Johansson, Giuseppe Riccardi, et al. Shallow discourse parsing with conditional random fields[C]//Proceedings of the 5th International Joint Conference on Natural Language Processing (IJCNLP 2011), 2011:1071-1079.
[9] R Prasad, S McRoy, N Frid, et al. The biomedical discourse relation bank[OL]. BMC Bioinformatics, 2011.
[10] Ramesh Balaji, Hong Yu. Identifying discourse connectives in biomedical text[C]//Proceedings of the AMIA Ann Symp Proc, 2010.
[11] Rashmi Prasad, Nikhil Dinesh, Alan Lee, et al. The Penn Discourse Treebank 2.0[C]//Proceedings of the 6th International Conference on Language Resources and Evaluation,2008.
A PDTB-Based Automatic Explicit Discourse Parser
LI Sheng, KONG Fang, ZHOU Guodong
(School of Computer Sciences and Technology, Soochow University, Suzhou, Jiangsu 215006, China)
Automatic discourse processing is considered as one of the most challenging NLP tasks which is helpful to many downstream NLP tasks, such as question answering, automatic summary and natural language generation. Recently, the large scale discourse corpus PDTB is made available, which provides a common platform for discourse researchers. On the basis of PDTB corpus, the paper proposes an end-to-end explicit discourse parser with conditional random fields. The parser consists of three components joined in a sequential pipeline architecture, which includes connective classifier, explicit relation classifier and relation argument extractor. We report the performance on each component, and, from error-cascading perspectives, we analyses the parser’s overall performance in detail.
discourse processing; conditional random fields; PDTB

李生(1989—),硕士研究生,主要研究领域为自然语言处理、篇章分析。E⁃mail:shengli.ls@aliyun.com孔芳(1977—),博士,副教授,主要研究领域为机器学习、自然语言处理、篇章分析。E⁃mail:kongfang@suda.edu.cn周国栋(1967—),博士,教授,主要研究领域为自然语言处理、篇章理解。E⁃mail:gdzhou@suda.edu.cn
1003-0077(2016)02-0018-08
2013-09-09 定稿日期: 2013-12-20
国家自然科学基金(61003153,61272257,61273320);国家863项目(2012AA011102)
TP391
A
