汉语谓词组合范畴语法词库的自动构建研究
2016-05-04周强
周强
(清华大学 信息技术研究院语音和语言技术中心 北京 100084)
汉语谓词组合范畴语法词库的自动构建研究
周强
(清华大学 信息技术研究院语音和语言技术中心 北京 100084)
谓词词库是深层语法模型分析和理解的核心资源。近年来的常规方法是人工构建或从标注语料库中自动获取,标注规模和信息容量的扩大受制于巨大的人工投入量和标注库体系设计。该文提出了一种多资源融合自动构建汉语谓词组合范畴语法(CCG)词库的新方法。从知网、北大语法信息词典和大规模事件句式实例中提取汉语谓词的不同句法语义分布特征,融合形成CCG原型范畴表示,将它们指派给各资源信息完全重合的谓词形成核心词库。然后通过自动分类和隶属度分析相结合方法对其他谓词的CCG范畴进行预测,并对两者结果进行融合得到扩展词库,最终合并形成包含约15,000个词条的汉语谓词CCG词库。通过在随机均匀抽样的1000个谓词上通过多人独立标注形成的标准测试库上进行不同角度的性能分析实验,表明该词库的预期准确率达到了96.3%。
组合范畴语法;汉语谓词词库;多资源融合
1 引言
对文本内容的深度理解一直是自然语言处理研究的核心课题。在句子分析层面,随着一些浅层句法分析(如层次结构树和依存树)和浅层语义分析(如语义角色标注)方法的不断发展和完善,近年来的研究工作开始转向深层语法理论和相关资源研究方面。
深层语法理论的主要特点是可以内置谓词-论元(Predicate-Argument,PA)关系描述和分析机制,从而可以方便地解决句子语义分析中的句法语义链接(Syntactic Semantic Linking)问题。理想情况下,一个基于深层语法理论的自动分析器可以同时得到句子的浅层句法结构树或依存树表示和浅层语义角色标注信息,从而为自动提取句子的深层语义表示打下很好的基础。
深层语法理论的描述核心是融合句法语义链接关系描述的词汇知识库(词库Lexicon)和相应的词汇组合规则体系。早期的研究人员一般手工构建词库和规则库,不仅耗时费力,而且很难完全覆盖真实文本中的各种复杂语言现象。近年来的主流方法是利用现有标注语料库自动转换生成针对不同深层语法理论的大规模标注库,再从中提取得到覆盖面更广的深层语法词库和规则库。这大大提高了词库构建的灵活性和适用性,但前期资源标注仍需要投入大量的人工。
本文则希望探索一种能自动构建出准确全面的深层语法词库的有效方法。其核心是融合多个语言资源提供的丰富句法语义分布信息来预测词库标记。为此,我们选择了组合范畴语法(CCG)描述体系,其简洁的范畴描述形式可以方便地融合不同资源信息。然后,我们设计了一套有效的多资源融合算法,通过融合从知网中获取的动词义原的事件框架和语义角色信息、从北大语法信息词典中提取的动词句法分布表和从大规模真实文本中自动提取的典型事件句式分布,可以自动预测大部分汉语谓词的CCG范畴,并建立起CCG范畴中的核心论元与知网事件框架语义角色和典型事件分布实例之间的内在联系,为进一步进行各个核心论元语义限制的自动获取打下了很好的基础。
在下面几节中,第二节分析前人的相关工作以及存在的问题;第三节介绍多资源融合方法的基本思路;第四节给出具体实现算法的描述;第五节通过实验评价验证了该方法的可行性和有效性;第六节进行总结和展望。
2 相关工作
深层语法理论主要包括树邻接文法(LTAG)[1]、词汇功能语法(LFG)[2]、中心词驱动短语结构语法(HPSG)[3]和组合范畴语法(CCG)等。LTAG由句法组合以及语法推导树集合组成。通常包含一个或者多个邻接树。M Candito[4]指出,LTAG难以准确地展现,同时扩展和维护更令人头痛。LFG展示了结构树之间的关系,能够总结形成一般化语言学处理方法。但M Dalrymple[5]指出LFG需要庞大的信息库或特征集、统一的语法单元,难以通过人工的方法构建,而自动方法又难以保证其准确性。HPSG是一种基于特征的语法标注框架,W D Meurers[6]的工作生成了一个语法体系集合,其中仍然存在类似LFG的问题。
而CCG语法却是一种表达明确同时能够高效处理的语法描述体系。M Steedman[7]提到CCG可以通过简练的描述形式表现出句子中各成分的句法语义关系。英语方面的初步实验[8-9]显示CCG具有很强的分析效率。因此本文选择了CCG描述体系进行汉语谓词词库的自动构建研究。
构建谓词词库通常有两种方法: 人工标注和通过语料库转换生成。K K Schuler[10]以人工方式对WordNet的谓词分类信息进行处理,筛选出WordNet分类中符合谓词论元组合规律的谓词及其语义角色信息生成VerbNet词库。SA Boxwell[11]人工筛选出ProbBank里能够对应到论元的语义角色信息,进而归纳出谓词的CCG范畴词库。J Hockenmaier[12]提出了一种自动提取Penn树库中谓词同论元组合分布信息转换生成CCG范畴构建词库的算法。
近年来汉语方面词库构建也进行了探索,比较有代表性的是袁毓林老师的汉语配价语法研究[13]。通过定义谓词配价,即谓词能够支配的名词性成分的数量,明确表示谓词的句法特性以及语义关系。语言学家通过人工方式推断出动词的价,最终可以汇总得到汉语谓词知识词库。
同时袁老师还分析了语义角色标注对于构建汉语词库资源的作用[14-15],提出语义角色的信息能够很好地帮助描述词库中谓词的语义层面的组合信息,这样有助于词库对于语义理解信息方面的提升。
上述工作的主要问题在于人工处理过于依赖主观知识背景,不同标注人员差异较大,同时人工筛选效率过低无法应用于大规模词库构建。自动方法通过单一语料库作为处理输入无法获取到谓词同论元间丰富的语义角色关系。因此本文希望探索能融合不同资源自动构建出含有不同维度语义、句法信息的、客观全面的汉语谓词词库的有效方法。
3 问题描述
CCG体系下的汉语谓词描述范畴大多是复杂范畴,由原子范畴(如: S,NP,SP,PP等)通过左斜杠“/”和右斜杠“”两种不同方向的组合操作得到。它们隐含了这样的信息: 1) 一个谓词可以控制的核心论元数目;2) 它们在浅层句法形式上的典型组合顺序。表1列出了我们目前总结的几种典型CCG范畴形式,它们覆盖了汉语中绝大部分的谓词分布情况。

表1 典型汉语谓词的CCG范畴表示
汉语谓词CCG词库的构建目标,是为每个谓词,选择确定合适的CCG范畴标记。考虑到多义谓词在真实语境中的不同分布特点,一个谓词可能会指派多个CCG范畴标记。同时,为便于后续的分析应用,对于每个谓词在CCG范畴中控制的核心论元,我们还希望能给出合适的语义角色标记,并收集一定规模的典型搭配词语,便于进行后续的语义限制约束的自动挖掘研究。
为此,我们选择了以下语言资源:
1) 知网(HowNet)语义词典[16](以下称HowNet)
这是人工编撰的汉语词语概念描述词典。我们从中选择了全部的事件类概念描述,包括其中每个谓词义项的概念定义(DEF)、事件框架和语义角色描述。它们反映了词典编撰者对某类事件语义的典型认知图式的判断和把握,可以为CCG范畴的核心论元确定和语义角色选择提供重要参考信息。
2) 北大语法信息词典[17](以下简称PKU_GD)
对汉语常用词语的语法分布特征信息进行了详细描述。我们从中选择了汉语动词的主要句法分析特征,提取形成以下特征动词表: 不及物动词表(vi)、体宾及物动词表(vtn)、谓宾及物动词表(vtv)、双宾动词表(dobj)和兼语动词表(comp)。它们反映了词典编撰者从母语语感中提炼出的不同动词的句法分布特点,可以为相应动词的CCG范畴选择确定提供参考。
3) 真实文本的事件句式描述实例
它们记录了汉语真实小句的主、谓、宾、状、补等句法骨架分析信息。我们从中选择了五种基本事件句式: 主谓(SP)、主谓宾(SPO)、主状谓(SDP)(介词短语pp.作状语D)、主谓宾宾(SPOO)、主谓宾补(SPJC)。在大多数情况下,它们可以与表1中列出的几个CCG范畴之间建立一一对应关系,从而可以为不同谓词的CCG范畴预测提供重要的客观分析数据支持。目前,我们主要使用了以下两种事件句式描述实例。
A. 从TCT树库中自动提取的事件句式实例(以下称TCT_EC)
由于利用了树库中的人工校对句法树,因此相应事件句式的准确度很高,但数据规模较小,对汉语谓词的覆盖率较小;
B. 从北大人民日报标注库中利用现有的事件句式分析器[18]自动分析得到的事件句式实例(以下称RMRB_EC)
可以达到很大的数据规模和谓词覆盖率,但自动分析结果存在一些错误噪声。
表 2显示了这些资源的基本统计数据。如果我们把CCG范畴标记作为描述汉语谓词的句法语义链接关系的原型范式,这些资源则分别从不同角度提供了对这个原型范式的句法语义分布判据。这里的直观假设是: 如果这些资源提供的句法语义分布信息的重合度越高,则相应谓词的CCG范畴的原型性越强,从而确定该CCG范畴标记的可靠性就越高。据此,我们形成了通过不同语言资源融合来构建汉语谓词CCG词库的基本设想: 选择不同资源描述重合部分构建CCG核心词库,从中挖掘不同资源对核心词库的特征贡献,以此为基础,探索汉语谓词CCG范畴的自动预测方法,构建其他CCG扩展词库。

表2 不同语言资源的基本信息统计
4 算法设计
图1显示了这种融合方法的总体框架。其中输入资源为知网(HowNet)、北大语法信息词典(PKU_GD)和事件句式实例,通过融合各资源特征形成每个谓词的句法语义描述向量,从中提取各资源信息完全重合的谓词形成核心词库,其他谓词作为待确定词库。对核心词库,按照CCG范畴原型假设,为其中的每个谓词指派合适的CCG范畴标记。将它们与各自的特征描述向量相结合,形成初始的训练知识库;对待确定词库中的每个谓词,则通过CCG范畴的自动预测方法获得合适的CCG范畴指派而形成扩展词库,最终合并两个库形成最终完整的谓词词库。

图1 算法框架图
4.1 资源融合和核心词库生成
三个资源均无法单独确定谓词的CCG范畴,因此通过提取三类资源的对应特征,相互作用能够更好地应用于后续的核心词库建立以及扩展词库预测。从三类资源中可以提取出一个37维的特征向量,各个资源提供特征内容如下。
HowNet核心语义角色可以提供特征信息: 核心语义角色数量,根据HowNet语义角色含义预估其可能对应CCG的论元位置得到论元对应的核心语义角色数量,根据核心语义角色计算出CCG含有各论元的概率,共形成15维特征。
PKU_GD谓词所属类别可以作为特征信息,为了计算方便特征统一为二元特征,利用8维特征分别表示谓词是否属于一个或多个类别。
事件句式提供谓词事件句式类型的分布信息,这些分布信息以及相互交叉得到的二元信息形成14维特征。
按照论文基本假设对于三类资源重叠部分提取出谓词的CCG范畴,配合HowNet语义角色对应CCG论元的预估得到各论元对应的语义角色,再添加事件句式提供的搭配实例形成核心词库。资源重叠的判断方法如表3所示。不符合表3内容的谓词作为待确定词库通过自动预测方法进行CCG范畴指派。

表3 资源特征对齐原则
4.2 待确定词库的CCG范畴预测
这部分主要通过自动分类和隶属度分析两种方法分别预测CCG范畴,然后通过结果融合最终确定出待确定词库谓词的CCG范畴形成扩展词库。
4.2.1 CCG范畴自动分类
以核心词库作为训练集合,CCG范畴特征量作为分类特征量,通过目前常用的SVM分类方法进行待确定词库的自动分类将谓词映射到不同的CCG范畴。
资源融合时产生的37维特征向量可以体现谓词的语义句法信息,利用该特征向量进行SVM训练及分类能够充分利用谓词的各类信息区分出不同谓词特点,对待确定词库CCG进行指派。
4.2.2 隶属度分析
很多谓词缺少HowNet和PKU_GD词典提供的特征信息,而且自动分类的训练集主要来自于核心词库,因此自动分类器可能存在训练不充分问题。另一方面,从大规模真实文本中获取的事件句式分布实例已经能够提供非常丰富的谓词句法意义分布特征,因此不妨忽略前两个资源提供的语义和句法信息,而提出绘制谓词隶属度图谱确定CCG范畴的方法。所谓的隶属度就是事件句式类型频率分布。
根据核心词库中不同CCG范畴下所有谓词的隶属度计算平均值作为该CCG范畴的核心隶属度,这样定词库中每个谓词根据隶属度向量可以计算出该谓词同各个CCG范畴标准隶属度的欧氏距离,选取距离最近的CCG范畴作为该谓词的隶属度分析结果CCG。
4.2.3 结果融合
通过自动分类和隶属度分析分别得到了待确定词库中谓词的CCG范畴。自动分类利用不同资源的统计信息提取CCG范畴却忽略了真实文本中使用的变形、省略等情况,隶属度分析基于事件句式实例的分布趋势,却无法区分出相同词形不同词义的情况。两者融合可以使得最终结果更加准确客观。基本方法是: 当两者预测结果相同时,选择该CCG范畴指派给谓词;当两者预测结果不同时,则通过分析发现不同差异特点选择合适的CCG范畴。
根据两种结果的不同差异情况具体分析能够总结出不同结果的融合情况。如自动分类结果为“(SNP)/NP”,隶属度分析结果为“SNP”的情况是由于谓词在实际使用中会根据前文省略宾语,例如 “我-完成-任务”省略为“我-完成了”,最终CCG范畴应为“(SNP)/NP”;自动分类结果为“(SNP)/NP”,隶属度分析结果为“(SNP)PP”的情况产生于宾语用介词引导作为状语修饰谓词,例如 “我-关闭-电脑”,表现为“我-将-电脑-关闭”,最终CCG范畴应为“(SNP)/NP”;
通过两种独立的自动分析方法确定出扩展谓词库中谓词的CCG范畴,通过融合的方法得到最终的CCG范畴。根据CCG范畴确定出HowNet语义角色同CCG范畴各论元的对应关系形成扩展谓词库。核心词库和扩展词库合并整体上作为最终的汉语谓词CCG词库。
5 实验分析
5.1 总体融合数据分析
最终该方法得到了15 468个谓词义项CCG范畴结果,表4从不同角度分析了核心和扩展两部分词库的分布特点。
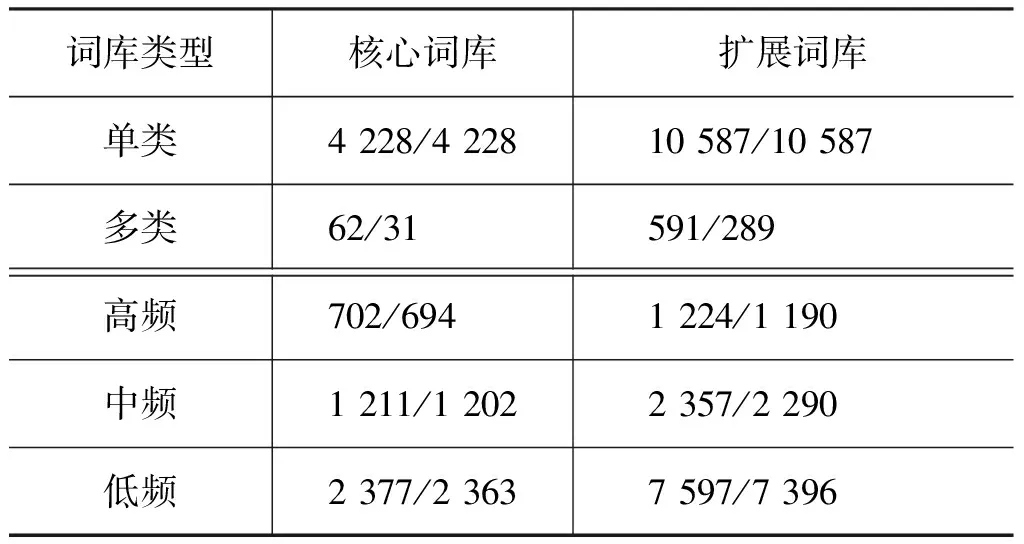
表4 谓词库规模统计
首先,按照谓词被指派的CCG范畴数目分出单类和多类两类谓词;其次通过统计谓词在现有事件句式库中包含的基本事件句式总数,分出如下的高中低频三类谓词: 事件句式数量小于5的谓词属于低频,大于20的属于高频,中间部分属于中频。表格中每个结果包含“token/type” 两个频度值。
对比核心词库和扩展词库,三类资源能够完全重叠的核心词库数量明显较少,表明待确定词库的CCG范畴自动预测方法是必要的;对比单类和多类数量结果,大部分谓词CCG范畴均较为固定,即使谓词本身存在多种含义,但是其CCG范畴的性质都是近似的,例如,谓词“滋生”本身具有“{ResultIn|导致}”和“{reproduce|生殖}”两种含义,但是其CCG范畴都是“(SNP)/NP”;对比高中低频的谓词数量,汉语谓词在真实本文中的使用存在较为明显的长尾效应,较少的高频谓词会重复使用,剩余大量谓词很少出现。
表5列出了词库中不同CCG范畴的分布特点。由于多类词具有多个CCG范畴,按CCG范畴分类统计type频度会产生分歧,因此每个表格单元仅包含对应的token频度。
通过这一结果可以发现大部分CCG结果为 (SNP)/NP和SNP。这与人们所知的常识是一致的,即在实际句子中SPO和SP类型的句子是最为常见的。
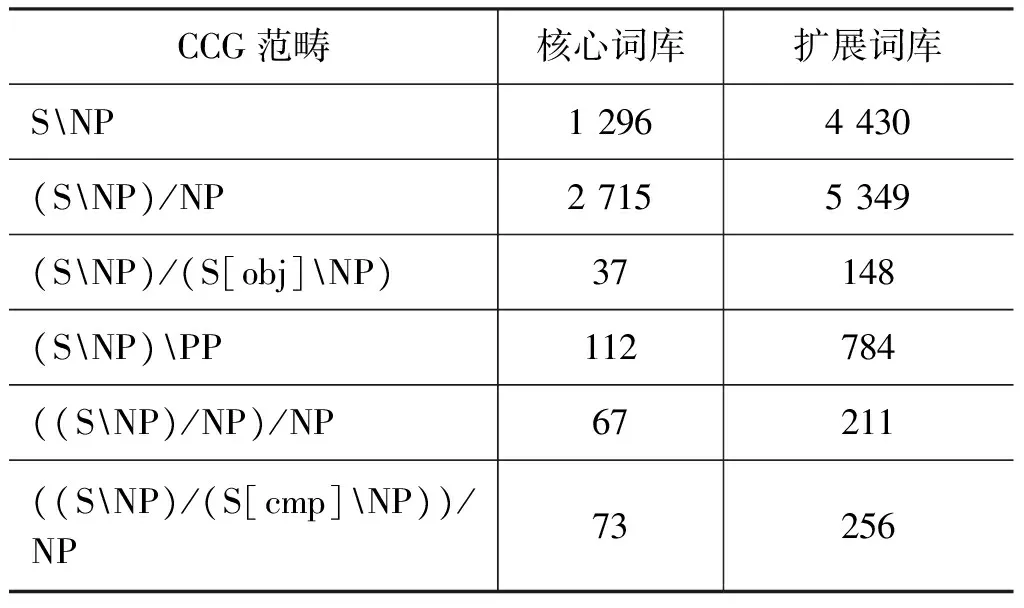
表5 不同CCG范畴token数量统计
词库中近900个(SNP)PP类型谓词较为特殊,下面进行具体实例单独分析。表6列出部分(SNP)PP类型谓词,可以看出这类词语通常具有两个核心论元,但是并不能直接形成SPO的形式,而是以“和”,“与”等词语引导的介词结构状语如表中“比较”“操心”或通过联合主语如表中“协商”来表达完整含义。
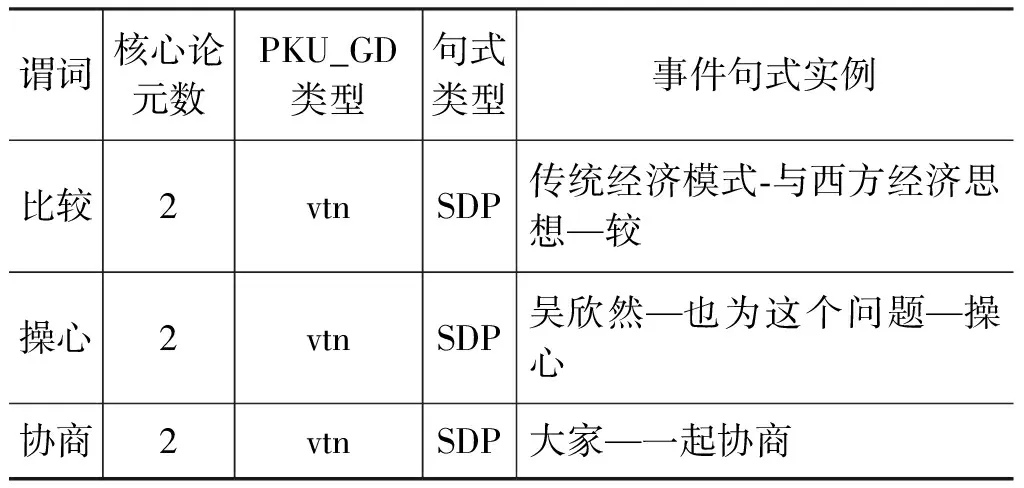
表6 (SNP)PP类型谓词实例
5.2 CCG范畴预测准确性分析5.2.1 标注数据集合构建
为了能够有效地对谓词结果准确性进行评价,需要构建出一个标准的评测集。
从所有谓词中按照上述不同频度不同类型的分布随机均匀选取1 000个谓词词条作为评测集合。评测集合token分布如表7所示。
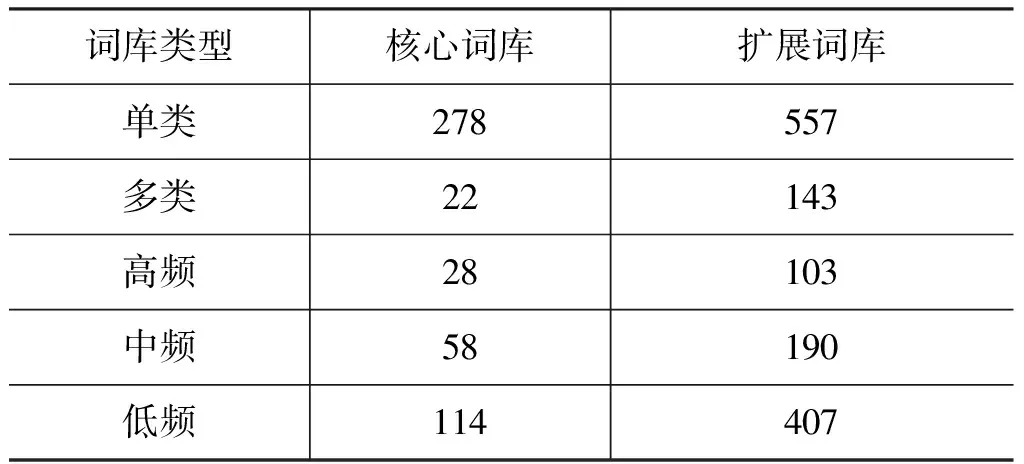
表7 标准集合规模统计
安排两个标注人员独立对评测集的谓词进行标注,对每个谓词分别按照五种不同的CCG类型构造事件句式,判断构造出的句式是否满足特定条件[19],满足条件的事件句式对应的CCG为该谓词的正确指派,否则不是。对比两个标注人员的结果,选择一致结果作为标准集合的结果,对于不一致的结果通过第三个标注者进行进一步确认以保证标准集合数据的客观性和可靠性最终形成评测集合。表8列出部分人工标注结果样例,其中两位标注者分别给出谓词对应CCG以及构造出的事件句式实例,由第三名标注者对前两名标注者不同结果进行修正,如表中前三词分别为不同CCG谓词标注结果一致情况,“订婚”为标注结果不一致通过第三名标注者确定的情况,“繁殖”为标注结果不同,最终合并为多类词的情况。
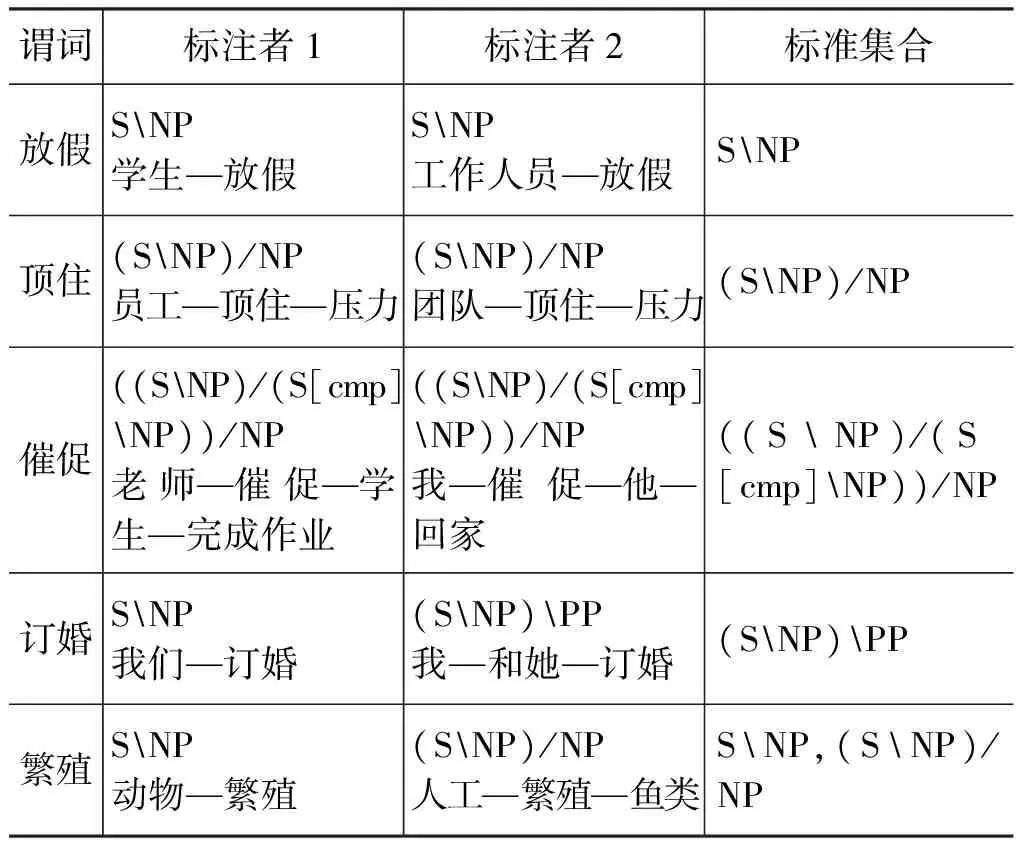
表8 标准集合人工标注样例
为评价评测集合的质量,本文采用J Cohen[20]提出的Kappa系数作为评价指标。在不告知两位标注者构造句式判定条件的情况下进行独立标注,计算出两名标注者的理论一致率Pe为0.4230,在进行标注指导后标注者再次进行标注,计算出实际一致率Po为0.9940,根据式(1)。
(1)
最终得到了测试集的Kappa值为0.9896,符合评测要求。
5.2.2 准确率评价
评测使用的准确率具体计算公式为式(2)。
(2)
其中P是传统准确率,R为自动CCG结果同人工标注CCG结果完全一致token总数,对于多类词分别统计每个CCG结果同人工结果是否一致,计算出一致的token数,S为评价集合结果token总数。
表9展示出了不同类型谓词的准确率评价结果。
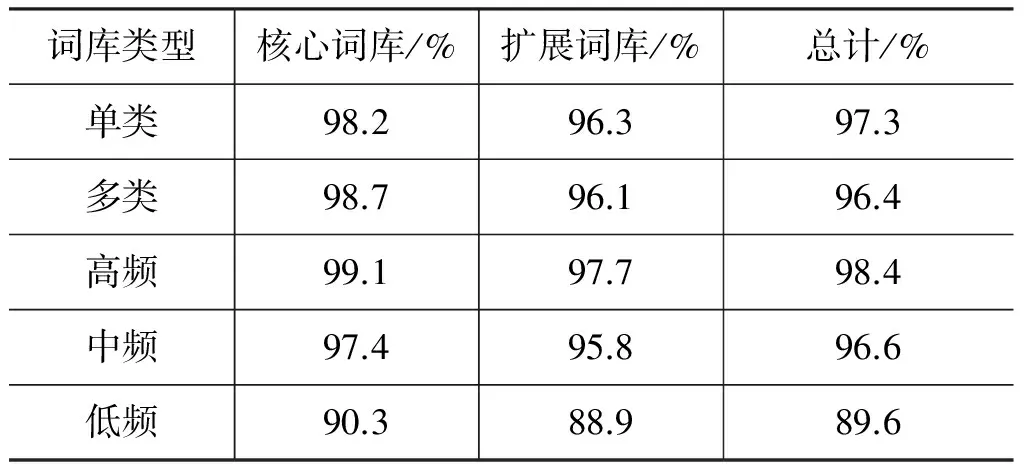
表9 不同谓词准确率
核心词库的准确率均要高于扩展词库,说明三类资源重叠部分得到的CCG原型范畴更为准确,第三节提出的直观假设成立。同时单类词准确率高于多类词,这是因为组合单一的谓词更容易从不同资源中提取准确CCG范畴。事件句式实例频度同准确率成正比,因为更丰富的组合实例为CCG范畴确定提供更准确的句法组合信息。
上方评价是考虑词库整体得到的,下面对比CCG自动预测中不同方法准确率结果。具体结果如表10所示。
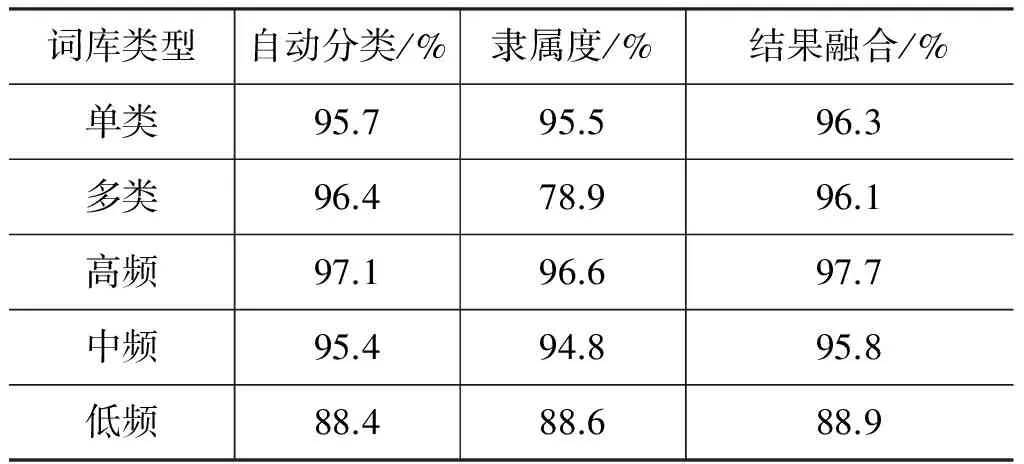
表10 不同方法准确率
整体上结果融合的表现均高于单独的处理方法,表明该处理方法中结果融合方法的正确性及必要性。但是数据中多类情况较为特殊,其隶属度结果较差,这是由于基于事件句式分布得到的隶属度分析结果不能区分多类词范畴,通过自动分类结果的弥补有效地保证了结果准确性。
目前方法仍然存在一些缺陷: 1) 由于事件句式实例无法区分相同谓词的不同CCG,导致多类词处理存在偏差,如“提升”有SNP和(SNP)/NP两种CCG,例如“水平-提升”和“队伍-提升-水平”,但句式分布仅表明两类句式比例都很高,无法表明谓词确实存在两种CCG还是由于变形导致;2) 低频谓词无法提供详细准确的事件句式信息,使得这部分谓词准确率偏低,如“扩招”句式实例中仅出现一次为省略宾语形式“学校-扩招”,但是该谓词CCG应为(SNP)/NP。因此未来需要进一步探索改进事件句式的处理方式。
6 总结
本文通过融合不同汉语语言资源,提取对应特征信息,将资源特征重叠的谓词根据CCG原型假设指派对应CCG范畴,形成比较可靠的核心词库。以特征信息和核心词库为基础通过CCG自动分类、隶属度分析等不同方法对其他谓词的CCG范畴进行自动预测,并融合不同方法结果得到扩展词库,合并两个词库得到希望的谓词词库。通过词库规模以及准确性的评价分析,表明前文提出的直观假设成立,不同CCG预测方法有效,词库准确率满足使用要求。最终形成一个完整可靠的汉语谓词CCG词库。
论文后续工作可以从以下方面入手: 1)根据词库配合事件句式实例的搭配词汇自动提取出谓词CCG论元的语义约束限制,提升现有词库的使用范围;2)加强对短语动词如述补式结构的CCG范畴获取研究,分析其事件复合特点;3)开发实现针对本谓词词库的相关支撑平台;4)同目前汉语的其他大规模人工编撰词库如袁毓林老师的动词配价库的性能对比分析。
致谢
感谢董振东先生提供知网2008版的研究许可,感谢北大计算语言所提供语法信息词典1998版和人民日报2000年全年标注库的研究许可,感谢硕士研究生乌兰、张远洋提供评测集合标注帮助。
[1] K V Shanker,Y Schabes. Structure sharing in lexicalized tree-adjoining grammars[C]//Proceedings of the 14th conference on Computational linguistics(COLING ’92),1992,1: 205-211.
[2] R M Kaplan,J Bresnan. Lexical-functional grammar: A formal system for grammatical representation[J]. Formal Issues in Lexical-Functional Grammar,1982: 29-130.
[3] C Pollard,I A Sag. Head-driven phrase structure grammar[M]. Chicago: University of Chicago Press and Stanford: CSLI Publications,1994.
[4] M H Candito. A principle-based hierarchical representation of LTAGs[C]//Proceedings of the 16th conference on Computational linguistics,1996,1: 194-199.
[5] M Dalrymple. Formal Issues in Lexical-functional Grammar[M]. New York: Center for the Study of Language & Information,1995.
[6] W D Meurers,G Minnen. A computational treatment of lexical rules in HPSG as covariation in lexical entries[J]. Computational Linguistics Archive,1997,23: 543-568.
[7] Steedman M,Baldridge J. Combinatory categorial grammar[J]. Non-Transformational Syntax Oxford: Blackwell,2011,181-224.
[8] M McConville. Inheritance and the CCG Lexicon[C]//Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics,2006: 1-8.
[9] S Clark. Large-scale syntactic processing: Parsing the web[J]. Final Report of the 2009 JHU CLSP Workshop,2009.
[10] K K Schuler. VerbNet: A broad-coverage,comprehensive verb lexicon[D]. Ph.D. thesis: University. of Pennsylvania ,2005.
[11] S Boxwell,M White. Projecting propbank roles onto the ccgbank[C]//Proceedings of the International Conference on Language Resources and Evaluation,2008.
[12] J Hockenmaier,M Steedman. CCGbank: a corpus of CCG derivations and dependency structures extracted from the Penn Treebank[J]. Computational Linguistics,2007,33: 355-396.
[13] 袁毓林. 汉语配价语法研究[M]. 北京: 商务印书馆,2010.
[14] 袁毓林. 语义角色的精细等级及其在信息处理中的应用[J]. 中文信息学报,2007,21(4): 10-20.
[15] 袁毓林. 语义资源建设的最新趋势和长远目标——通过影射对比、走向统一联合、实现自动推理[J]. 中文信息学报,2008,22(3): 3-15.
[16] 董振东,董强. 知网[DB/OL].http: //www.keenage.com/zhiwang/c_zhiwang.html.2003.
[17] 北大计算语言学研究所. 现代汉语语法信息词典规格说明书[DB/OL].http: //icl.pku.edu.cn/icl_groups/syntac-dictn.asp. 2000.
[18] 陈丽欧. 汉语事件内容分析系统研究与实现[D]. 清华大学,2012.
[19] 邱晗. 汉语动词CCG范畴人工标注规范[R]. 清华大学: 信息技术研究院语音和语言技术中心,2011.
[20] J Cohen. A coefficient of agreement for nominalscales[J]. Educational and Psychological Measurement,1960,20(1): 37-46.
Automatic Construction of Chinese Predicate Lexicon for Combinatory Category Grammar
ZHOU Qiang
(Speech and Language Technologies R&D Center.Research Institute of Information Technology,Tsinghua University,Beijing 100084,China)
Predicate lexicon is the core resource of analyzing deep grammar. In contrast to the exsisting manual construction methods,this paper proposes a new method of generating the predicate lexicon for Combinatory Category Grammar (CCG) from multi-resources. This method extracts semantic and syntactic features from HowNet,PKU_GD and large scale Event Patterns,generating CCG prototype and then assigning it to part of predicate whose all features and information are overlaped. Then an expanded predicate lexicon is generated by merging the result of classification and membership analysis. For the finally achieved predicate lexicon with 15 thousands predicates,the evaluation on a standard set annotated independently by multiple humans with 1000 homogeneous distributed predicates shows that its precision can achceve 96.3%.
combinatory category grammar;Chinese predicate lexicon;multi-resources integration

周强(1967—),研究员,主要研究领域为自然语言理解、词汇语义学、语料库语言学。E⁃mail:29_lxd@mail.fsinghua.edu.cn
2014-01-20 定稿日期: 2014-05-23
国家重点基础研究发展计划(2013CB329304),国家自然科学基金(61373075)
1003-0077(2016)03-0196-08
TP391
A
