基于数据场和全局序列比对的大规模中文关联数据模型
2016-05-04王汀徐天晟冀付军
王汀,徐天晟,冀付军
(首都经济贸易大学 信息学院,北京 100070)
基于数据场和全局序列比对的大规模中文关联数据模型
王汀,徐天晟,冀付军
(首都经济贸易大学 信息学院,北京 100070)
目前关联数据的研究工作主要集中在实例级别上展开,而在模式级别(Schema-Level)上的关联数据构建则易被忽视。本体映射是解决本体异构问题的重要途径和手段,同时,本体映射也可视为模式级别关联数据构建的典型情景。特别是在中文知识库方面,中文知识是关联数据网中的重要组成部分,但现有的中文本体映射系统在面对大规模本体映射任务时,显得效率较低且可用性不高,目前仍缺乏针对中文大规模本体映射的相关系统。为了解决在模式级别上的中文大规模关联数据构建问题,提出了一种新的基于数据场和序列比对思想的大规模中文关联数据构建模型。首先,基于改进的融合概念相似度和相异度的拟核力场势函数对大规模中文本体映射规模进行约简和压缩;其次,通过引入序列比对算法,对组合概念进行相似度的度量;最后,将本系统与相似度计算相关典型算法进行比较,表明其具备一定的可用性和较高的总体性能。
语义网;关联数据;本体映射;同义词词林;相似度计算
1 引言
语义Web的愿景是建立“数据之网”(Web of Data),以使机器能够理解网络上的语义信息[1]。本体作为语义Web的核心元素,是描述特定领域共享概念的形式化、规范化说明[2],是实现网络知识共享和语义互操作的基础。目前关联数据(Linked Open Data,LOD)[3]的研究工作主要集中在面向实例级别(Level of Instances)上展开,而面向本体模式(Schema-Level)的关联数据构建研究亦很重要[4]。同时,由于不同本体之间存在异构性,从而导致本体间的重用和共享变得困难。
本体映射(Ontology Alignment)作为模式级关联数据构建的典型场景已被广泛研究,其任务就是要发现异构本体或数据源(LOD Datasets)之间的概念语义关联。随着语义网的发展,大规模中文本体和知识库也被越来越多地构建和发布到Web上。然而,中文关联数据网的构建却尚处于起步阶段,目前更缺乏成熟的针对本体模式的中文关联数据模型。因此,本文主要探讨大规模中文关联数据环境下的本体映射解决方案。
2 相关工作
国内外研究人员已提出多种映射方法和典型系统。文献[5]中总结了基于编辑距离和基于Token的几种典型元素级相似度计算算法,并对几种算法的性能进行了评测。Melnik S等提出一种结构级本体映射算法Similarity Flooding,该系统利用本体概念体系构造相似度传播图,并对概念之间的相似度进行传播和修正[6]。Zhong Qian等提出RiMOM系统,该系统基于本体实例、概念名称以及本体结构等特征的多策略映射方式,并通过引入普适的场论思想,使其适用于大规模本体的映射任务[7]。Giunchiglia F等基于语言学方法,引入共享知识词典(如: WordNet[8]),利用语言关系进行语义关系发现[9]。文献[10]提出一种实例级本体映射算法,根据本体概念的公共实例数量来度量概念的相似度。
近年来,大规模中文本体库和关联数据构建的研究工作正逐步展开。李佳等提出一种基于知网(Hownet)[11]的元素层概念相似度算法,并实现了一个中文本体映射系统[12],该系统在面对大规模本体映射任务时,其适用性有待验证。田久乐等提出一种基于同义词词林的中文词语语义相似度计算算法[13],但其成果并未在语义网环境下应用。Wang Zhi-chun等学者[14]提出基于中文百科的分类体系抽取概念间的层次关系、获取含有Infobox的词条Web页面中的概念属性及百科词条实例,最终建立起基于百度百科和互动百科的两大中文大规模本体库,并根据简单的关键字匹配策略,与DBpedia建立起实例间的共指关系。Niu Xing等研究人员将百度百科*http://baike.baidu.com/、互动百科*http://www.hudong.com/以及中文维基百科[15]进行语义集成,并开发出基于中文描述的实例级关联数据应用系统[16]。王汀等基于同义词词林相似度算法和改进的拟核力场势函数,设计并实现了一种中文大规模本体映射系统[17]。Yidong Chen等提出利用中文百科Infobox中的属性-值对信息,自动提取良构的训练样本,进而基于统计学习模型从百科的非结构化文本中抽取海量的知识三元组,最终构建了一个面向开放域的中文知识库[18]。
3 问题定义
简单词元与未登录词都对应于本体概念。本文将简单词元称为原子概念(Atom Concept,AC),将未登录词称为组合概念(Component Concept,CC),并约定组合概念由若干个原子概念的线性排列组合而成。下面给出问题的定义:
定义1 本体映射: 两个待映射本体Os、Ot,对于Os中的概念Cs,在Ot中找到与其语义相同或接近的概念Ct,有映射函数map:Os→Ot:
对于∀Cs∈Os,∀Ct∈Ot,若sim(Cs,Ct)>t; 则有map(Cs)=Ct
sim(Cs,Ct)为Cs和Ct的相似度,t是阈值,当Cs与Ct的语义相似度大于t时,则将
定义2 对于《同义词词林》语义知识库(Semantic Knowledge Base,SKB),显然集合SKBTYCCL由原子概念组成,即有SKBTYCCL={AC1,AC2,…,ACN}。N为知识库中所收录的词元总数。
定义3 组合概念CCi由一系列原子概念的有序排列构成。即: 对于∀ACi∈SKBTYCCL,引入二维下标i和j,则有有序序列CCi=[ACi1,ACi2,…,ACij],其中j≥1且CCi∉SKBTYCCL,j为原子概念ACi在有序序列CCi中的排列位置。特别地,对于所有的原子概念ACi,可以有ACi=[ACi]。
定义4 对于本体Os和Ot中的概念Cs和Ct,有Cs=CCs=[ACs1,ACs2,…,ACsm],Ct=CCt=[ACtn,ACt2,…,ACtn]。m和n分别为概念Cs和Ct所对应的有序序列CCs和CCt的长度,则有m,n≥1。
4 中文大规模本体映射系统
主要由以下模块组成: 概念初始关联度计算、本体压缩和确定性映射。
4.1 基于编辑距离和同义词词林相融合的概念初始关联度计算
4.1.1 编辑距离相似度
在面对大规模本体的映射任务时,首先对待映射本体进行压缩。由于在进行初始关联度计算时优先考虑算法的高效性本系统,因此采用编辑距离算法首先进行概念集合之间的初始相似度计算。在获得待映射本体的初始关联度时,通过编辑距离算法SIME可以获取概念之间的字面相似性,而忽略其语义相关性。对于概念Cs和Ct的编辑距离和相似度值由公式(1)和公式(2)给出。
(1)
其中,|Do(Cs,Ct)|为Cs和Ct的编辑操作次数,L(Cs)和L(Ct)为概念的字符长度。
(2)
4.1.2 同义词词林相似度
同义词词林(Tongyici Cilin,TYCCL)是一个中文同义词典,它将每个词汇进行编码并以层次关系组织在一个树状结构中,自顶向下共有五层。每个层次都有相应的编码标识,五层的编码从左至右依次排列起来,构成词元的词林编码。树中的每个结点代表一个概念,词语与词语之间隐含的语义相关
度也随着层次的增加而提高。中文的概念共指关系识别实际上可以抽象为中文同义词的识别问题。本系统采用哈尔宾工业大学同义词词林(扩展版)*http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm作为本体映射的常识知识库:SKBTYCCL。
以词元“物质”为例(词林编码为: Ba01A02=),对词林编码格式进行解释,如表1所示。
根据词林的结构特点,首先对概念的词林编码进行解析,抽取出第一至第五层子编码,再从第一层子编码开始比较。若出现子编码不同,则根据出现的层次来赋予该映射对相应的相似度权重。子编码不同出现在越深的层次,则相似度权重越高,反之则越低。同时,每层的分支节点数的多少也对相似度有影响。在文献[13]的基础上,我们提出改进的本体概念相似度计算公式,如式(3)所示。

(3)
由于本体映射更关注概念之间的语义相似性,因此引入调节参数语义相关度因子λ,通过λ来调节不同层级概念间语义相关性和语义相似性的关系,以及控制处于不同层次分支的词元之间可能相似的程度,显然λ∈(0,1)。λ的值越大,表示不同层次之间的词元相似或等价的可能性越大,且不同层次的语义相关性对于最终概念相似度的影响越大,反之则越小。
由于中文本体映射更关注概念的语义相似度,因此λ的取值不宜过高。
其中,L={1,2,3,4,5},对于∀Li∈L,Li为第i层所代表的层数,|L|为集合L中的元素个数,在本系统中恒等于5。概念相似度权重系数为λ×(Li/|L|)。NT为词元Cs和Ct在第i层分支上的节点总数,D为词元Cs和Ct的编码距离。
特别是当待映射概念对的五层编码均相等,且词林编码最后一位为“=”号,则相似度值为1.0。显然,SIMT的值域为(0,1]。本系统将语义相关度因子设定为λ=0.9。
4.1.3 多策略融合关联度算法
由于SIME算法与SIMT算法具有语义互补性,因此本系统将两种算法的相似度结果进行互补融合,取两种算法结果的最大值。
算法一同时考虑两个概念Cs和Ct之间的相似度和相异度,并将其叠加进入每个概念Cs、Ct的最终关联度。定义两种相似度算法得到的最大值为ρ,ρ∈(0,1],则有公式(4)。
(4)
概念Cs和Ct之间的语义相关系数为λst,式(5)中的1-ρst用来度量两个概念Cs和Ct之间的相异度。-log(1-ρst)是以10为底的对数。本系统将其定义为严格单调递增函数,这样可以使相异度对相似度的变化趋势能够平稳地反映二者之间的因果关系。相似度ρst的值越大,相异度越小,则调节函数-ρst×log(1-ρst)的值越大。初始关联度ms综合考虑了源本体和目标本体概念之间的相似度和相异

算法一 InterlinkingValue(Os ,Ot)
度,从而使结果更加合理。为使式(5)收敛,规定ρ值属于区间(0.9,1]时,Cs和Ct之间的语义相关因子λst为1。
(5)
最终得到源本体概念Cs与目标本体Ot的初始关联度ms,见公式(6)。目标本体Ot的概念总数为n。
(6)
由关联度计算的对称性,目标本体的概念Ct的初始关联度mt同理可得。为使关联度的转移具有连续性,规定: 当某概念最终的初始关联度值为0时,则赋予其固定值为0.04。
4.2 大规模本体压缩算法
在面对大规模的本体映射任务时,传统的算法无论在时间还是空间复杂度方面都难以适应,因此需要相应的策略来对原本的待映射的本体进行压缩。
数据场理论[19]的提出是基于物理学中的场论思想,将数域空间中数据之间的相互关系抽象为物质粒子之间的相互作用问题,最终形式化为场论的描述方法。该理论通过势函数来表达不同数据间的相互作用关系,从而体现出数据的分布特征,并根据数据场中的等势线结构来对数据集进行聚类划分。但是,经典数据场所采用的短程场势函数往往只考虑了数据对象之间的路径距离对最终势值的影响,在面对本体映射问题时,就体现为忽视了数据对象间普遍存在的语义关联因素,例如,拟核力场势函数。拟核力场势函数只考虑数据场中对象之间的斥力,而忽视了对象间存在引力的现象。
本系统提出一种通过综合计算概念间的语义相似度和相异度来衡量数据对象势值的新方法,将Os和Ot中的概念间普遍存在的语义关联视为本体压缩的基础和前提,将本体概念视为数据场中的数据对象,将概念间的初始关联度视为数据对象的质量。通过引入本体中概念之间普遍存在的语义关联度因子,修正了拟核力场势函数在面对本体映射问题时的不足,使其在宏观上符合关联数据构建的特征。
4.2.1 势函数的定义
由于短程场能更好地反映出数据之间的相互作用情况,因此采用拟核力场势函数。其在本体映射问题中的具体定义如下。
待映射本体O中,概念之间的最短路径长度为||Ci-Cj||,由短程场的特性,定义概念之间的路径长度不大于2。基于数据场理论可得概念Ci与Cj之间相互作用的场强函数表达式,如公式(7)所示。
(7)
其中,mi代表每个数据点的质量,一般令mi=1,但是这种做法只能反映概念之间的路径距离对最终势值的影响,却使得概念之间的语义关联度完全缺失。本研究提出将概念之间的语义相似性和相异性引入势值计算,将mi的值定义为概念之间的初始关联度,mi值已由4.1.3节的公式(6)给出。通过将概念之间的相似度和相异度进行综合考虑,对公式(7)中的场强函数进行改进与完善。公式(6)证明,待映射本体中概念的初始关联度越大,则其在数据场中的质量越大。
本体概念集C={C1,C2,…,Cn}中,用Ci的初始关联度值mi来刻画本体中的每个概念对于其他概念的影响程度,即:M={m1,m2,…,mn}。经过修正的场强函数如公式(8)所示。
(8)
δ∈(0,+∞)反映概念之间影响的粒度,也称为缩放因子,不妨取δ=1,k=2。可得本体O中Ci的势值函数,如公式(9)所示。
(9)
最终得到本体O中全部概念的势值集合potentialMap_Os和potentialMap_Ot,记为:potentialMap_O
4.2.2 候选概念的抽取
将O中的概念集划分为候选区间和淘汰区间。具体地,对于算法一的输出数据结构Map_Ot和Map_Os,根据每个概念元素的关联度值统计出Map_Ot和Map_Os中关联度值等于0.04的概念总数,记为Range_Out,该变量为淘汰区间长度。而将Map_Ot和Map_Os中关联度值大于0.04的概念总数记为Range_Candidate,该变量为候选区间长度。
将potentialMap_Ot和potentialMap_Os中的概念以键值降序排序,对于∀Ci∈potentialMap_O,其排名记为Ranki。若Ranki∈ [1,Range_Candidate],则保留Ci作为候选待映射概念。若Ranki∈ [Range_Candidate+1,Range_Candidate+Range_Out],则Ci被淘汰。
4.3 基于Needleman-Wunsch算法的概念确定性映射
对于Os和Ot中的任意两个概念Cs和Ct,在进行语义相似度计算时有三种情况:
①Cs和Ct均为原子概念,即:Cs∈SKBTYCCL且Ct∈SKBTYCCL;
②Cs和Ct的其中之一为原子概念,而另一个为组合概念,即:Cs∉SKBTYCCL或Ct∉SKBTYCCL;
③Cs和Ct均为组合概念,即:Cs∉SKBTYCCL且Ct∉SKBTYCCL;
对于情况①,采用4.1.2节给出的公式(3)计算语义相似度。下面讨论情况②和情况③的相似度计算方法。
对于中文组合概念的相似度计算,许多学者给出了处理方案。例如,李佳等采用公式(10)对未登录词进行相似度计算。
(10)
其中,Bxy表示分别以两个词汇拆分后得到的简单词汇为行列组成的相似度矩阵的元素,maxi(Bxy)表示矩阵中数值排列为第i位的相似度。但是,该方法忽视了中文自然语言中普遍存在的语序敏感现象和“前轻后重”的特点,因此其必然带来语义相似度计算的误差。
例1 两个组合概念: “历史理论”和“思想史”,经过分词处理后得到两个由原子概念构成的有序排列: [历史,理论]和[思想,史]。采用前人普遍的处理未登录词方法则会得到如图1(a)所示的原子概念错误映射结果。

图 1
因此,本文提出一种新的基于全局双序列比对算法的概念语义相似度计算方法。
4.3.1 序列比对(alignment)算法概述
生物信息学中的双序列比对一般是指将两条DNA序列排列在一起并标明其相似处,序列中可以插入空位符,相同或相似的符号排在同一列上。通过比较两个序列的相似片断和保守性位点,寻找其可能存在的分子进化关系。
Needleman-Wunsch(NW)算法是典型的全局比对算法,其适用于比较全局宏观上相似程度较高的两个序列[20]。它是一种比对两条序列之间相似性的动态规划算法(Dynamic Programming,DP)。
4.3.2 构造动态规划打分矩阵
所谓序列是指由一系列字母标识,根据一定的排列规则所组成的字符串。本文将组合概念视为词串序列,序列中的各个元素即为原子概念。首先将组合概念进行分词处理,得到其对应的词串序列;本系统中采用中国科学院计算技术研究所研发的ICTCLAS 50* http://ictclas.org/作为分词工具。然后将本体映射的概念相似度计算抽象为两个词串序列的比对过程: 通过空位罚分函数,确定在词串序列中的相应位置插入空位符,使得两个序列长度相同,进而得到待比对序列的原子概念之间或原子概念与空位符的对应关系。
本文将待比对的两个词串序列以打分矩阵(scoring matrix)的形式表示,两条序列分别作为动态规划矩阵的两维。对于Cs和Ct,打分矩阵M的第i行对应词串序列CCs中的原子概念ACsi,第j列对应词串序列CCt中的原子概念ACtj,其中i≤m,j≤n。动态规划矩阵M中第i行第j列元素称为Mij。
例2 组合概念“第二次工业革命”和“第二次世界大战战犯”经过分词处理后,得到两个待比对词串序列: [第二,次,工业革命]和[第二,次,世界大战,战犯]。根据动态规划思想,将两个词串序列以行和列来表示。假设序列CCs的长度为m,序列CCt的长度为n,则可形成一个以序列CCs为行,序列CCt为列的(m+1)×(n+1)的二维矩阵,如图3所示。同理可得例一的打分矩阵,如图2所示。
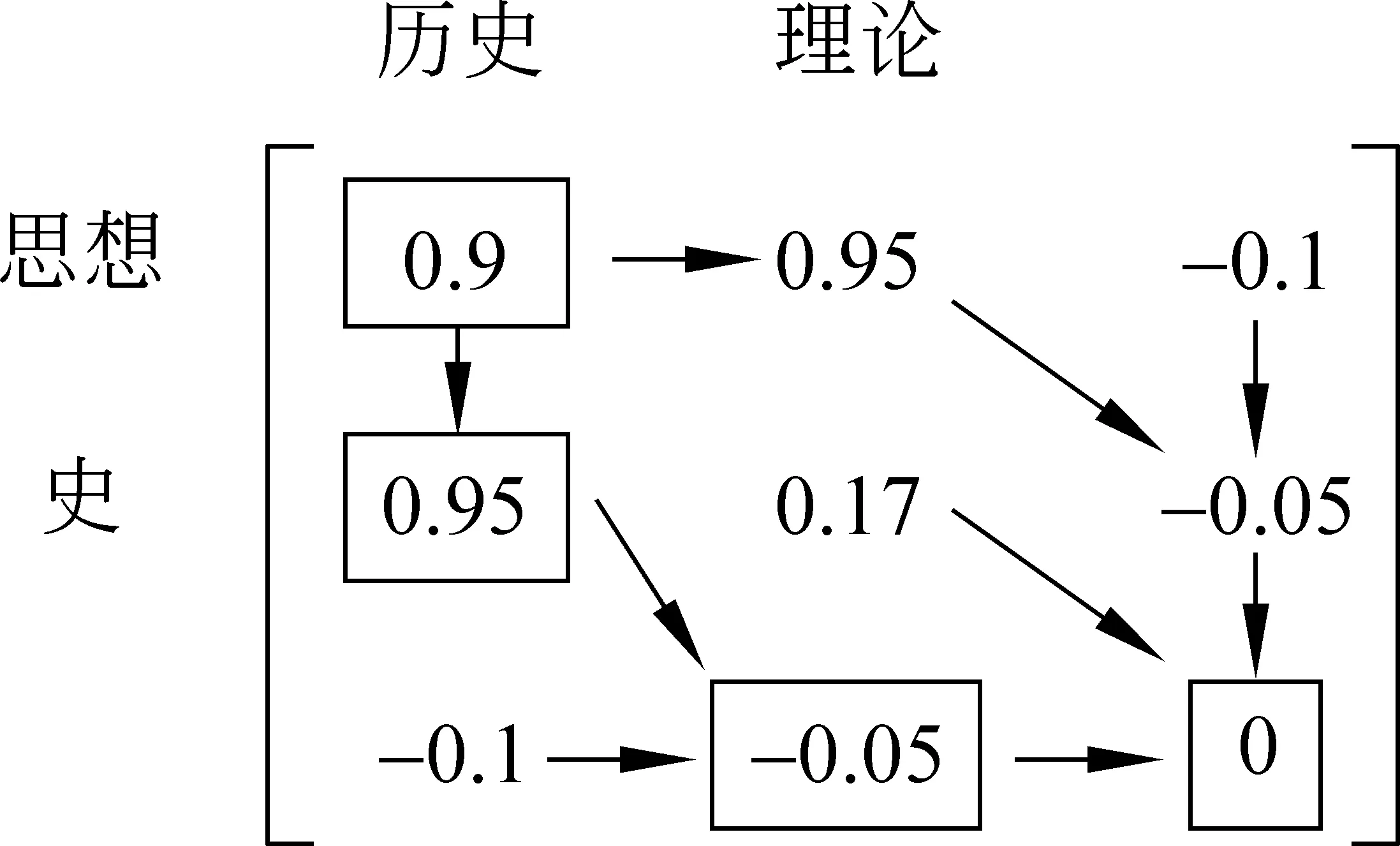
图2 例1的打分矩阵

图3 例2的打分矩阵
4.2.3 最优化的递归求解算法
基于NW算法对矩阵M中的最优比对路径进行递归求解。首先,给出序列比对算法的惩罚因子p=-0.05,并分别对矩阵的第m+1行与第n+1列进行初始化;其次,基于计算函数SIMT,对矩阵中其余m×n个元素进行递归求解。先给出记分函数f的定义,如公式(11)所示。
(11)
考虑到中文词汇普遍存在“前轻后重”的特点,因此将递归的起点选定为两个组合概念的结尾处,即矩阵中的Mmn元素。最后,从矩阵中的Mmn元素开始,回溯至矩阵中的M11元素结束,可得最优比对路径。如果得到的最优比对路径不止一条,则任选其一。递归规则如公式(12)所示。
(12)

图4 例二的序列匹配结果
(13)
5 实验结果及分析
5.1 实验数据
本文采用中文网络开放百科知识库作为实验数据源。除DBpedia(中文版)知识库以外,本系统基于文献[14-21]提出的方法,使用爬虫工具包HTMLParser,分别对百度百科和互动百科的开放分类页面和词条页面所包含的Infobox结构化信息进行爬取和解析,并将其以中文三元组(Triple)的形式组织起来,形成待映射的大规模中文开放域知识库。如表2所示,百科开放分类体系主要构成本体的概念体系。
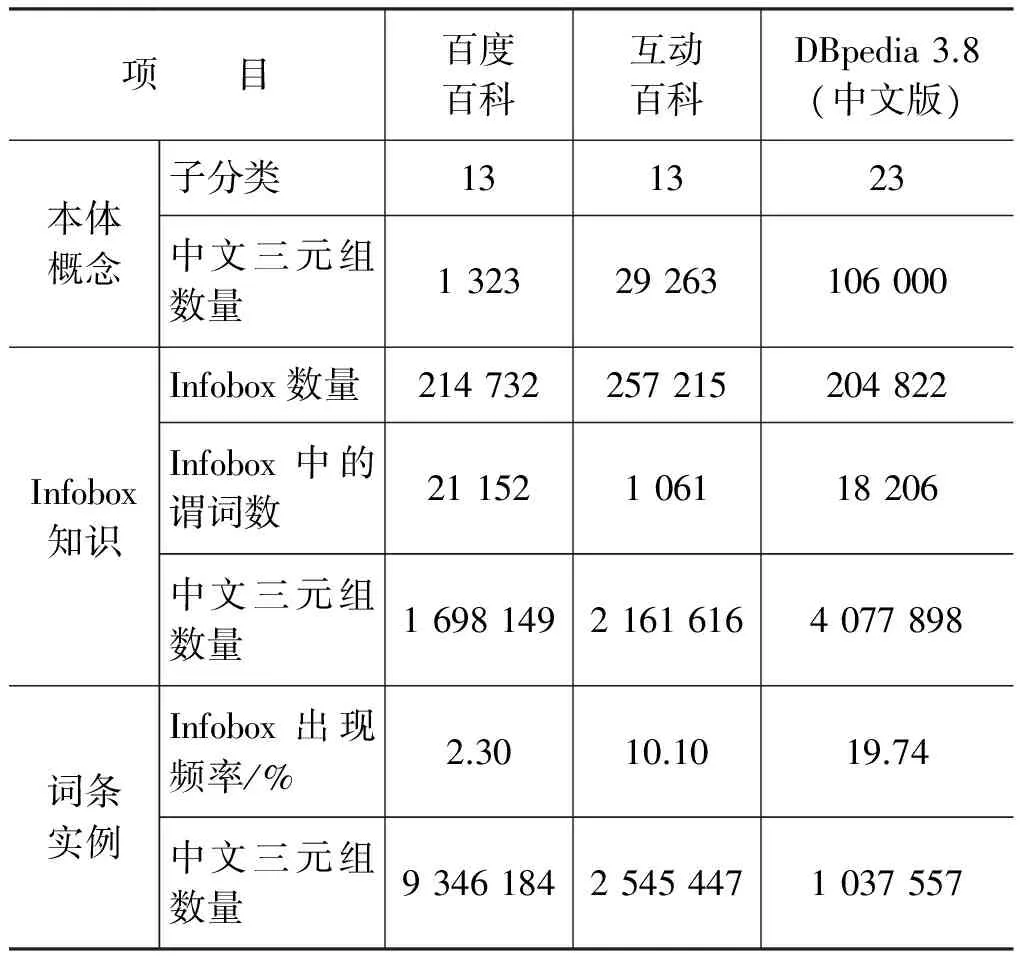
表2 中文网络百科知识库信息
5.2 评价指标
本文采用对等价关系识别的查准率(Precision)、查全率(Recall)和F-measure作为评价标准。其中:
Precision(P)=输出的正确映射对数/输出的映射对总数×100%
Recall(R)=输出的正确映射对数/标准结果中的映射对总数×100%
F-measure(F1)=2×P×R/(P+R)×100%
选取三大中文网络百科本体概念集中的顶层分类: 人物、科学、社会、地理和艺术子类中的正确映射对作为评价算法效率的参考映射,如表3所示。
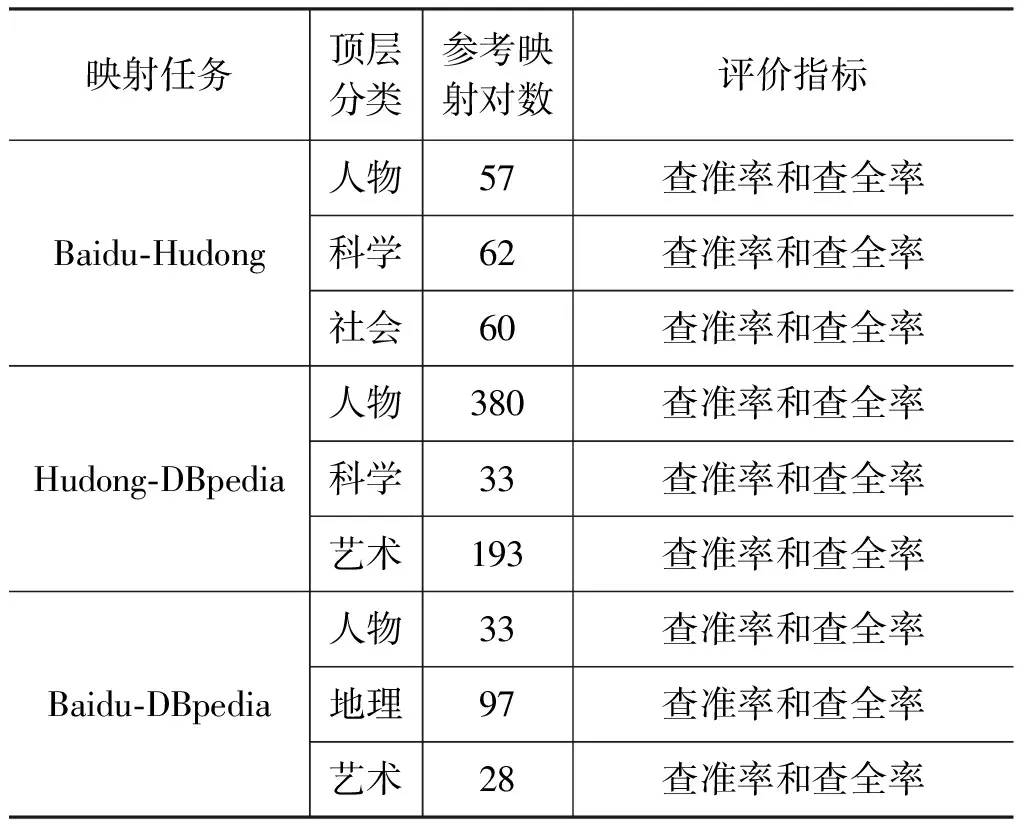
表3 三大中文百科本体映射任务参考映射统计
5.3 实验结果5.3.1 实验一: 大规模中文本体压缩
基于提出的综合计算概念间的语义相似度和相异度拟核力场势函数,首先对大规模本体进行了映射规模的压缩。在不同语义环境下可以获得的压缩效果如表4所示。其中,压缩率(%) = (压缩前本体规模 -压缩后本体规模) /压缩前本体规模。
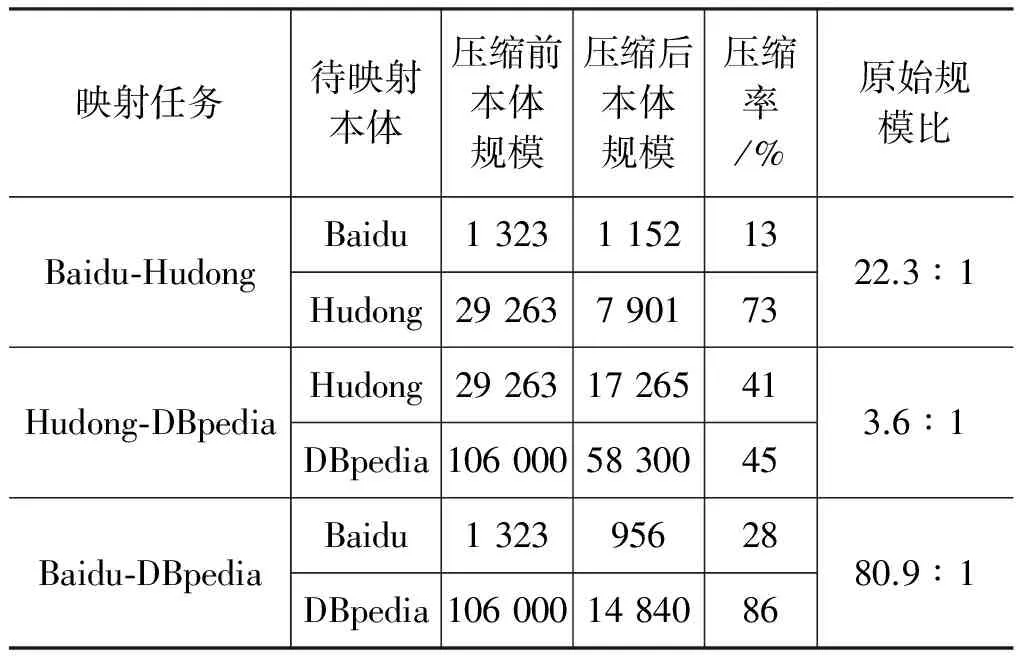
表4 大规模本体映射规模压缩效果
可以看出,当两个本体之间的原始规模相差较大时,相对较小规模的本体压缩率也较小,而较大规模的本体则更易获得较高的压缩率。在这种情况下,待映射本体所获得的压缩率相差较大。而当本体之间的原始规模趋近时,二者所获得的压缩率也趋同。由此可见,基于修正的拟核力场势函数可以获得较好的聚类效果,在进行确定性映射前,可以有效控制和约简大规模本体映射任务的时间和空间复杂度。
5.3.2 实验二: 大规模中文本体映射结果评测
三个映射任务的评测结果如表5所示,第一种算法为跨语言可通用的编辑距离相似度算法[22];第二种为田久乐等提出的基于同义词词林的中文词语相似度算法[13];第三种方法为本文提出的中文概念综合相似度算法。
为了保证公平性,将判定概念等价关系的相似度阈值统一设定为t=0.9。
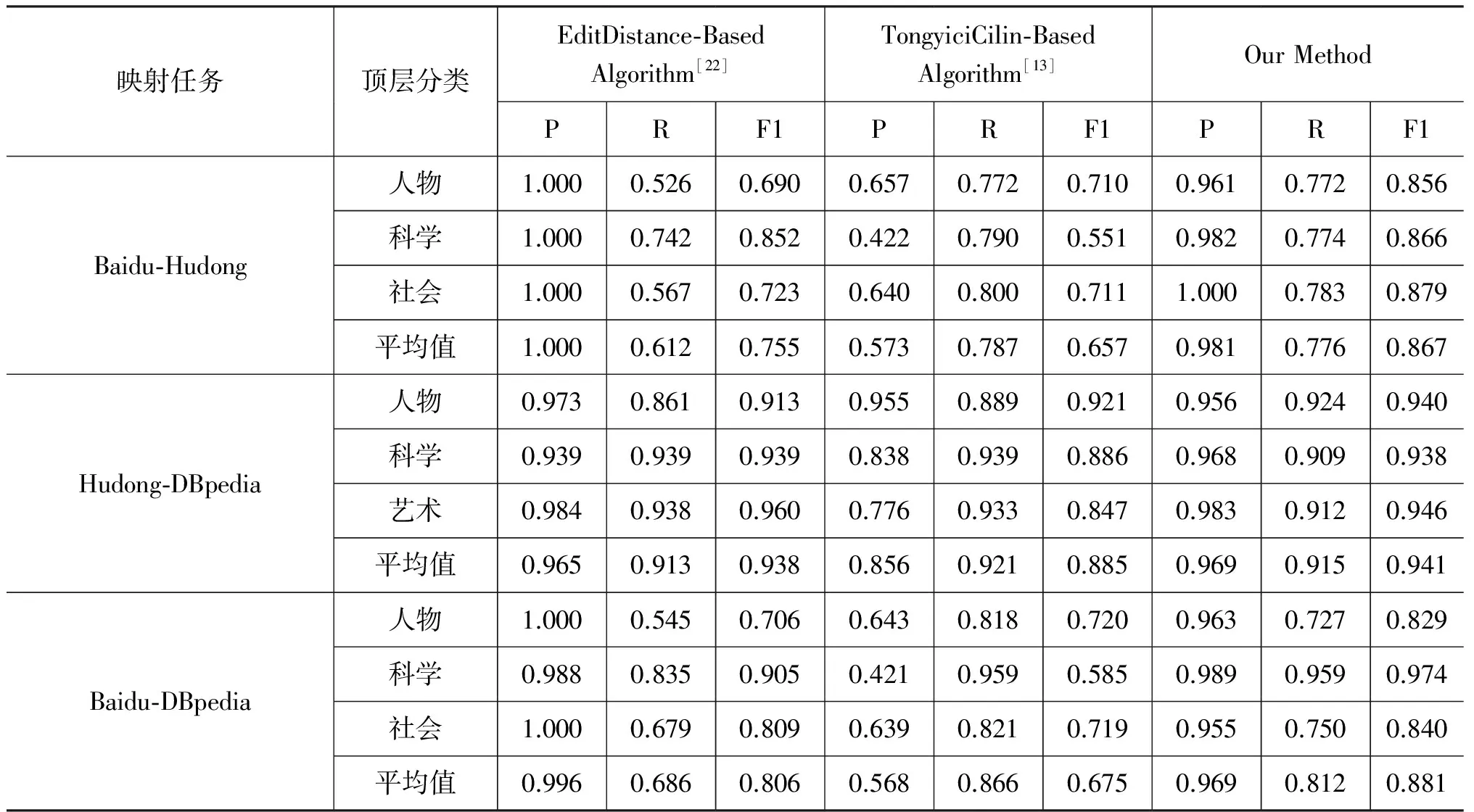
表5 三种典型相似度算法的评测结果
由表5可知,本系统在Baidu-Hudong映射任务的查准率与编辑距离相似度算法基本持平,同时查准率也明显高于文献[13]中的算法,因为本体映射更注重概念的共指关系识别,而文献[13]过分关注词语的语义相关度,从而导致词语相似度计算时引入较大误差。而Hudong-DBpedia映射任务得到的查准率则与编辑距离算法基本持平,同时高于文献[13]平均约9%。
在查全率方面,首先,由于引入同义词词林作为语义知识库,因此查全率方面也会高于基于编辑距离的相似度算法;其次,由三个映射任务的评测结果中也可以看出,在引入数据场势函数作为本体映射规模压缩因子后,我们也可以将其视为概念集合之间的结构级映射。因此,根据某些不同的百科子分类中概念元素可能存在的结构级特征,其也可以为本系统同时带来较强的纠错能力,即可能规避由于采用单纯元素级映射策略可能带来的误差。同时,通过引入基于生物信息学序列比对的组合概念相似度计算方法,不仅可以避免面向未登录词相似度计算的传统算法可能带来的错误映射,相比于文献[13]提出的相似度计算算法,由于其并未考虑未登录词问题,因此根据不同子分类所蕴含的组合概念的特征,更可能提高不同子映射任务的查全率。
最后,从总体性能上(F1值)看,本文系统在面对Baidu-Hudong映射任务时,比编辑距离算法和同义词词林相似度算法平均高出约11%和20%。在面对Hudong-DBpedia映射任务时,本文方法的总体性能高于文献[13]中提出的同义词词林相似度算法,而与编辑距离算法基本持平。在面对Baidu-DBpedia映射任务时,本文方法的总体性能仍分别高于文献[13]中提出的同义词词林相似度算法和文献[22]中提出的编辑距离算法约20%和8%。
6 结束语
现阶段缺乏成熟的中文大规模本体映射系统,本文提出一种基于同义词词林的中文本体映射原型框架,该系统解决了大规模本体映射系统的可用性问题。它着眼于现有中文大规模本体的特征进行概念元素级映射。今后将根据不同中文本体的特征,考虑引入实例级以及概念定义相似度的映射参数,以进一步提高中文映射系统的健壮性和准确性。
[1] Berners-Lee,T,Hendler J,et al: The Semantic Web. Scientific American,2001.
[2] Borst W N. Construction of Engineering Ontologies for Knowledge Sharing and Reuse[D]. Enschede: University of Twente,1997.
[3] Bizer C,et al. Linked data on the web[C]//Proceeding of the 17th International Conference on World Wide Web.ACM,New York,2008: 1265-1266.
[4] Jain P,Hitzler P,Sheth A P,et al. Ontology alignment for linked open data[C]//Proceeding of theISWC 2010. Springer Berlin Heidelberg,2010: 402-417.
[5] Cohen W,Ravikumar P,Fienberg S. A comparison of string distance metrics for name-matching tasks[C]//Proceedings of the IJCAI Workshop on Information Integration on the Web(IIWeb). Acapulco,Mexico,2003: 73-78.
[6] Melnik S,Garcia-Molina H,Rahm E. Similarity flooding: A versatile graph matching algorithm and its application to schema Matching[C]//Proceedings of the 18th International Conference of Data Engineering(ICDE). San Jose,California,2002: 117-128.
[7] Zhong Q,Li H,Li J,et al. A gauss function based approach for unbalanced ontology matching[C]//Proceedings of the 28th International Conference on Management of Data(SIGMOD). Rhode Island,USA,2009: 669-680.
[8] Stark M M,et al: Wordnet: An electronic lexical database[C]//Proceedings of 11th Eurographics Workshop on Rendering. MIT Press,Cambridge,1998.
[9] Giunchiglia F,et al: Element level semantic matching[D]. Italy: Dept.of Information and Communication Technology University of Trento,2004.
[10] Isaac A,Meij L,Schlobach S,et al. An empirical study of instance-based ontology matching[C]//Proceedings of the 6th International Semantic Web Conference and the 2nd Asian Semantic Web Conference(ISWC/ASWC). Busan,Korea,2007: 253-266.
[11] 董振东,董强,郝长伶. 知网的理论发现[J]. 中文信息学报,2007,21(4): 3-9.
[12] 李佳,祝铭,刘辰,等. 中文本体映射研究与实现[J]. 中文信息学报,2007,21(4): 27-33.
[13] 田久乐,赵蔚. 基于同义词词林的词语相似度计算方法[J].吉林大学学报,2010,28(6): 602-608.
[14] Z Wang,et al. Knowledge extraction from chinese wiki encyclopedias[J]. Journal of Zhejiang University-Science C,2012,13(4): 268-280.
[15] Bizer C,Lehmann J,et al: DBpedia-A Crystallization Point for the Web of Data[J]. Journal of Web Semantics,2009,7(3): 154-165.
[16] Niu X,Sun X,Wang H,et al. Zhishi.me-weaving Chinese linking open data[C]// Proceedings of ISWC 2011. Springer Berlin Heidelberg,2011: 205-220.
[17] 王汀,邸瑞华,李维铭. 一种基于同义词词林的中文大规模本体映射方案[J]. 计算机科学,2014,41(5): 120-123.
[18] Chen Yidong,Chen Liwei,Xu Kun. Learning Chinese entity attributes from online encyclopedia[C]//Proceedings of IEKB Workshop in APWeb.2012: 179-186.
[19] 李德毅,杜鹢. 不确定性人工智能[M].北京: 国防工业出版社,2005.
[20] Needleman S B,Wunsch C D. A General Method Applicable to the Search for Similarities in the Amino Acid Sequence of Two Proteins[J]. Journal of Molecular Biology,1970,48: 443-453.
[21] Wang T,Song J C.,Di R H,et al. A Thesaurus and Online Encyclopedia Merging Method for Large Scale Domain-Ontology Automatic Construction[J].M. Wang(ed.) KSEM 2013. LNCS (LNAI), Springer,Heidelberg.2013,8041: 132-146.
[22] Diogene Ontology Mapping Prototype,http://diogene.cis.strath.ac.uk/prototype.html
A Schema-Level Ontology Alignment Model for Chinese Linked Open Data
WANG Ting,XU Tiansheng,JI Fujun
(School of Information,Capital University of Economics and Business,Beijing 100070,China)
The current research on the linked open data(LOD) mainly focused on level of instances,while the task on finding schema-level links between LOD datasets is ignored. In order to solve the large-scale Chinese ontology mapping problem occurred in LOD,we propose a data field and sequence alignment-based ontology mapping architecture. Firstly,based on an improved nuclear field potential function,we compress dimension of unaligned large-scale Chinese ontology. Secondly,we use the sequence alignment algorithm to compute similarity between concepts. Compared to other typical similarity computing algorithms,the experimental results show that the proposed method has higher overall performance and usability.
semantic web; linked open data; ontology mapping; Tongyici Cilin; similarity computing

王汀(1985-),博士,讲师,主要研究领域为语义web技术、自然语言处理等。E⁃mail:wangting@cueb.edu.cn徐天晟(1972-),博士,教授,主要研究领域为自然语言处理、人工智能等。E⁃mail:xuts@cueb.edu.cn冀付军(1975-),博士,副教授,主要研究领域为计算机软件系统,IPv6资源平台。E⁃mail:jfj@cueb.edu.cn
2014-06-04 定稿日期: 2016-04-25
北京市社会科学基金(15ZHB011); 首都经济贸易大学科研项目(00791554410264,00791654490223); 国家社会科学基金(13CXW057); 2016北京市教委科研水平提高经费资助
1003-0077(2016)03-0204-09
TP391
A
