一种基于维基百科的中文词语相关度学习算法
2016-05-04黄岚杜友福
黄岚,杜友福
(长江大学 计算机科学学院 湖北 荆州434000)
一种基于维基百科的中文词语相关度学习算法
黄岚,杜友福
(长江大学 计算机科学学院 湖北 荆州434000)
词语相关程度计算是语义计算的基础。维基百科是目前最大、更新最快的在线开放式百科全书,涵盖概念广,概念解释详细,蕴含了大量概念间关联关系,为语义计算提供了丰富的背景知识。然而,中文维基百科中存在严重的数据稀疏问题,降低了中文词语相关度计算方法的有效性。针对这一问题,该文利用机器学习技术,提出一种新的基于多种维基资源的词语相关度学习算法。在三个标准数据集上的实验结果验证了新算法的有效性,在已知最好结果的基础上提升了20%—40%。
词语相关度;维基百科;中文信息处理;回归;链接结构
1 引言
计算词语之间的相关程度是实现智能信息处理的基础。比如当用户检索“Siri”时能自动识别出“iPhone”是与之相关程度很高的词语,而词语“梨”的相关程度则很低。利用词语间语义相关程度来提升信息处理智能化水平,已成功应用于智能搜索[1-3]、文本分类与聚类[4-6]、文本理解[7-8]等领域。
传统的词语相关度计算方法往往需要从大规模人工编撰的语义资源中获得背景知识,比如WordNet[9-10]、Cyc[11]、中文知网HowNet[12]等。这类语义资源由人工编撰和维护,耗费人力物力且更新周期长,难以捕获新兴事物。针对这个问题,从大众编写的在线百科网站中自动抽取结构化知识,并基于此开发语义分析技术,在近几年得到很大发展。
维基百科*http: //www.wikipedia.org/是目前最大的在线百科网站,其内容虽然由用户提供,但质量可以与专家编写的传统百科全书媲美[13]。维基百科的最大优点是涵盖范围广、信息开放、更新快。目前针对英语词语最成功的相关度计算方法大多基于英文版维基百科实现[14-18]。在用中文版维基百科实现针对中文词语的相关度计算方法时我们发现,中英文版本在资源数据量上存在非常大的差别,比如中文版本中收录的概念只有英文版本的百分之十。为了获得有效的中文词语相关度计算方法,必须解决中文维基百科中存在的数据稀疏问题。
本文针对中文维基百科中的数据稀疏问题,提出综合多种资源的词语相关度计算方法,并利用成熟的机器学习技术学习不同资源的最佳整合方式。本文首先介绍词语相关度的基本概念和研究背景,归纳出几类基本的利用维基百科资源实现词语相关度计算的方法。基于此,选取用于中文词语相关度计算的维基资源,并设计其描述特征。最后在三个基准数据集上评测各部分特征的表现,得出面向中文的词语相关度计算模型。实验结果表明,本文提出的计算模型在已知最好结果的基础上提升了20%—40%。
2 词语相关度的基本概念
在针对中文的词语相关度计算研究方面,近年来利用知识库的方法渐渐得到关注。比如,刘群等[19]和王红玲等[12]利用知网HowNet实现了基于结构化知识库的中文词语相关度计算,用词语对应HowNet意元间路径长度衡量语义关联程度。
在利用维基百科作为背景知识库的研究方面,北京邮电大学的李赟等[20]研究了从维基百科中自动抽取语义相关词对的方法,北京大学的万富强和吴云芳将显式语义分析方法应用于中文语境[21]。国防科技大学的汪祥和贾焰等[22]及华中师范大学的涂新辉和何婷婷等[23]均考察了用维基百科中的链接结构和分类体系来计算词语间语义关联程度的有效性,并分别采集了人工标注的中文词语相关度数据集。据笔者所知,这两个数据集是目前仅有的中文人工标注数据集,因此也是本文实验的基准数据集。
纵观目前中文词语相关度研究,仍存在三个方面的问题没有解决。首先,没有量化中文维基百科中存在的数据稀疏问题,本文从各类型资源的角度进行了详细分析,为选取计算资源提供了基础。其次,不同类型资源的数据量和性质都不相同,传统的线性整合方式缺乏理论支持。第三,没有考虑维基百科类目结构与传统结构化知识库如WordNet和HowNet的本质区别。本文针对这三个问题,在借鉴英文成功计算方法的基础上,提出一种新的基于机器学习的中文词语相关度学习算法。
3 基于维基百科的词语相关度计算方法
3.1 基于维基百科的结构化知识抽取
与传统Web站点相比,维基百科的内容高度结构化,便于实现结构化知识的自动抽取。维基百科中的页面大体分为五类: 文章(Article)、类目(Category)、重定向(Redirect)、消歧(Disambiguation)和管理(Administration)页面。除管理页面外,前四类常被用于抽取结构化知识[23-24]。比如从文章页面中抽取单个概念的信息,从重定向页面中获得概念同义词,从消歧页面中获取多义词的不同释义,从类目页面和类目层级结构中获取概念间的上位和下位关系。图1展示了维基页面中信息与结构化知识的对应关系。
除此之外,维基百科页面之间的链接及其附带的锚文本也是重要的结构化知识资源。比如“麦金塔电脑”页面有“Macintosh”、“Macintosh电脑”、“苹果机”等28个不同的锚文本,即其他维基页面用这些词语指向“麦金塔电脑”。这些链接锚文本提供了非常丰富的同义词。同时,页面附属的出链接和入链接也可用于量化概念间的语义关联强度。
从维基百科中抽取的结构化资源为相关度计算提供了丰富的背景知识。按照所用资源的类型,可将基于维基百科的词语相关度计算方法归纳为四类: 基于链接结构的、基于文章全文的、基于类目层级结构的和综合多种资源的计算方法。下面分别进行介绍。
3.2 基于链接结构的计算方法
维基百科文章之间存在大量互链接,构成了庞大的链接网络,通常表示为一个有向无权图。每个文章对应于图中的一个顶点,文章的出链接和入链接分别对应于该顶点的出边和入边。
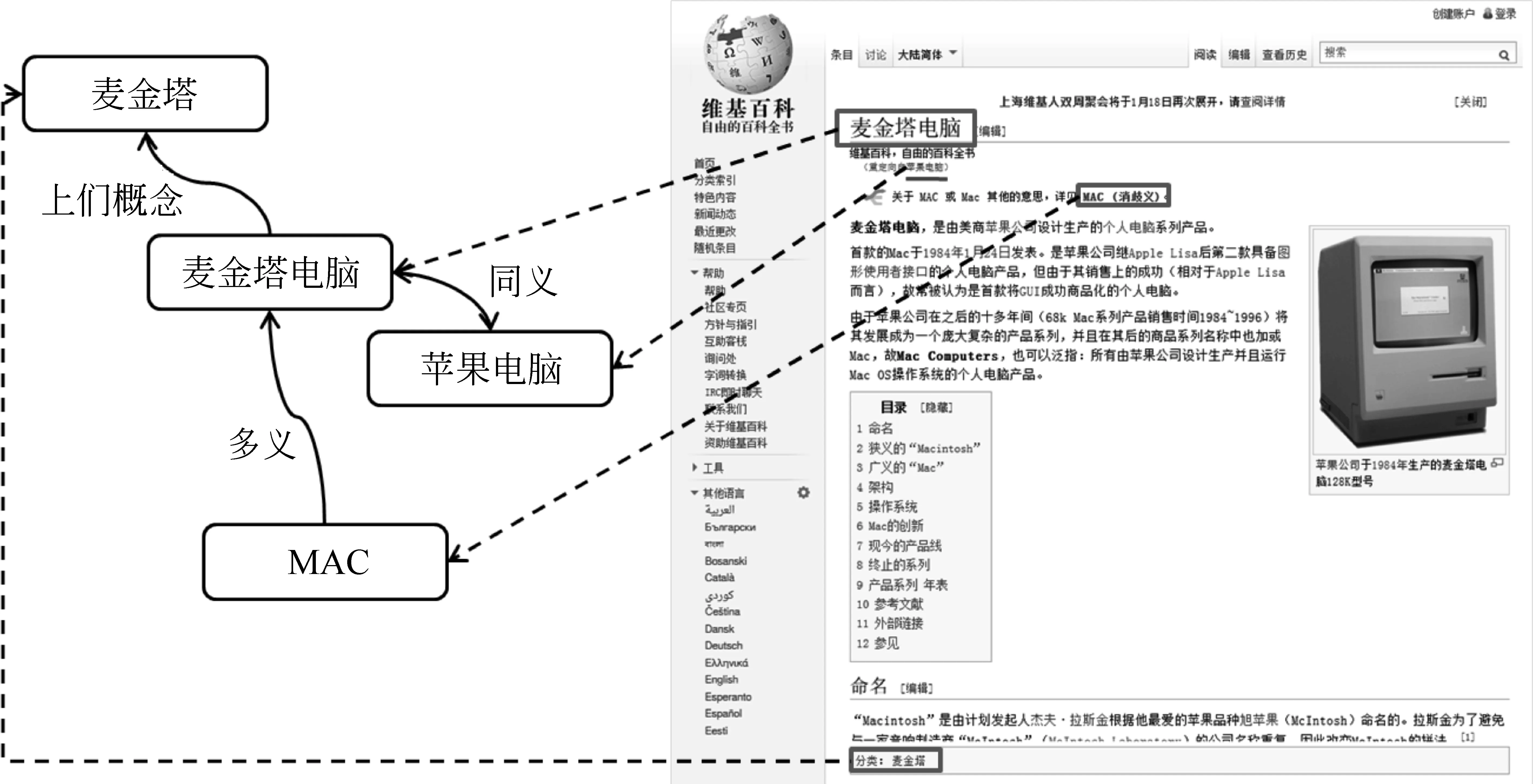
图1 基于维基百科文章的结构化知识抽取
根据所使用的链接网络是全局还是局部的,可将基于链接结构的相关度计算方法分为两类。前者多采用基于全局网络结构的图随机游走方法,代表为个性化PageRank算法(Personalized PageRank,PPR)[18]。不同词语对应的跳转向量(teleport vector)不同,生成的PageRank分布向量也不同,而分布向量间的相似度(如余弦相似度)即可作为词语相似度。由于要遍历整个网络,这类算法的开销大,且效果欠佳[18]。
第二种方法以文章节点的近邻局部网络结构为基础,首先将文章表示为其邻居节点的加权向量[16]。邻居节点即对应于当前文章的链入和链出文章。然后用向量间相似度(或距离)作为词语语义关联程度。常用的向量相似度计算方法有Jaccard相似性、余弦公式、Google距离公式[25]等。
基于链接结构的计算方法不要求解析维基百科文章的内容,不依赖于语言相关的自然语言处理技术,因此通用性好、效率高。然而,由于链接结构依附于节点,即维基文章,此类方法往往只适用于概念,即存在对应维基页面的词语。前期研究中我们发现维基百科中收录概念以实体居多,如人物、地点、事件等。很多常用词语并不存在对应的维基概念,如“重视”、“方便”和“敌意”。仅考虑文章链接的方法无法处理这些未登录词语。针对这一问题,我们对基于链接结构的计算方法进行了扩展,使之也能适用于不存在对应维基概念的未登录词语(见4.1节)。
3.3 基于文章全文的计算方法
维基百科页面也是以自然语言书写而成,与其他文本无异,词语出现过的文章一定程度上描述了词语的含义。比如,“篮球”出现频次最多的文章有“NBA”、“篮球”、“姚明”、“迈克尔·乔丹”等。此类方法的代表是由Gabrilovich和Markovitch提出的显式语义分析(ESA,Explicit Semantic Analysis)方法[15,21]。
通过解析维基文章的内容,可将词语表示为该词语所出现过的文章的向量。其中每个维度对应一个维基文章,维度上的取值取决于词语在文章中的出现频次。换句话说,此类方法通过解析维基文章内容构建词语的概念表示空间,即用维基概念表示词语语义内涵。与传统概念空间模型如LSA和LDA方法不同,这里每个维度都有着明确、显式的定义,是可解释的,因此称为显式语义分析。最后,词语相关度可由其对应概念向量的相似度计算得到。本文称这类方法为基于概念空间的计算方法。
适用范围广是此类方法的最大优点。只要是在维基文章中出现过的词语,即可计算其语义关联程度。比如本文所解析的中文维基百科版本中总共包含 48万概念和122万词语,词语数量远远超过了概念数量。
此类方法的不足主要存在于两方面。首先,解析文章内容依赖于语言相关的自然语言处理技术,比如中文分词,英文stemming等。其次,词语对应的概念向量往往规模庞大,导致实时计算向量相似度的效率较低。比如,中文维基百科中的词语平均出现在54.9篇文章中,最多出现于39万篇文章,即概念向量中非零元素的平均数量为54.9,最大值为39万。本文6.3节专门针对这些因素进行了实验研究。
3.4 基于类目层级结构的计算方法
维基百科的文章和类目之间的包含与被包含关系构成了类目网络,类似于WordNet中层级式的概念组织方式。因此最初基于维基百科的词语相关度计算方法便是将定义于WordNet上的算法移植到维基百科的类目结构中[14]。
然而,维基百科的类目结构与WordNet的层级结构有着本质差别。首先,WordNet的层级结构有着严格的上下位关系内涵,而维基类目结构的内涵模糊。维基类目层级除了表示IsA和ClassOf关系之外,还可以表示地理位置的包含关系、关联概念等等。其次,WordNet中同类POS词语间的层级结构为严格的树结构。而维基百科允许一个概念或类目有多个父类目,因此形成网状结构。由于这些本质上的区别,基于维基类目结构的计算方法效果往往欠佳[14-16]。
类似于基于链接的计算方法,应用类目结构也要求首先将词语映射到维基百科概念上。因此,此类方法的适用范围有限。综合上述分析,本文没有使用类目结构这一维基资源。
3.5 综合多种资源的计算方法
前述的三种计算方法都各有优点和缺点,为了扬长补短,整合多种资源来计算词语相关度成为最自然的解决方案。比如可先用每种方法计算得到一个相关度数值,再取其加权平均值作为最终的词语相关度[22]。然而,如何确定各类资源的权重仍有待解决。本文提出用机器学习算法,通过学习标注数据,即人工标注的词语对间语义关联程度,得到各种资源的最佳配置。
4 词语相关度学习算法
4.1 特征设计
特征选取往往是决定机器学习算法有效性的关键。基于前面的分析,我们从链接结构和文章全文资源中抽取设计了八个特征,如表1所示。根据是否需要先将输入词语映射到维基概念,将特征分为两类: 需要映射、描述概念间关联的特征(F1-F3)和不需要映射、描述词语间关联的特征(F4-F8)。前者称为概念相关度,后者称为词语相关度。

表1 各种相关度计算指标及其复杂度比较
4.1.1 概念相关度特征的计算方法
给定一对概念
(1)
其中,|l|为向量长度,|li∩lj|为li和lj交集的大小,|W|为维基百科中所有文章页面的总数。NGD基于ci和cj的共现链接数以及各自特有的链接数来衡量两者间的语义关联程度。余弦相似度的计算方法如式(2)所示。
(2)
其中,lik为li中k维上的取值。具体实现时,向量li和lj均为稀疏向量,因此可只遍历取值非零的元素。不同于NGD,余弦相似度考虑了每个链接的权重。沿用文献[16]的方法,给定s和t为维基文章,且存在s→t的链接,则该链接的权重如式(3)所示。
(3)
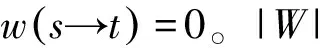
4.1.2 词语相关度特征的计算方法
概念相关度是进一步计算词语相关度的基础。给定一对词语
最后,F9为类特征。对于训练数据,其取值等于该词语对上所有人工标注数值的平均值。对于测试数据,其取值为算法的预测值。
4.1.3 特征的计算效率分析
表1还列出了各个特征的计算复杂度。其中,|L|为 维基文章附属链接向量的平均长度,并可根据链接方向分为入链接向量和出链接向量。中文维基百科中,入链接和出链接向量的平均长度分别为20.9和14.6,而英文维基文章的平均值分别为21.3和17.8。|S|指词语所有可能对应的维基概念数量。比如“苹果”有六个候选中文维基概念,每个概念表示一种可能释义。而“apple”有37个候选英文维基概念。C指常量,因为F6和F7为wiwj作为词组出现的先验概率,可离线计算。|V|为概念向量(稀疏表示)的平均长度,比如中文维基百科中这一数值为54.9。
除了计算复杂度之外,是否必须实时计算是另一个影响计算效率的重要因素。无需实时计算的特征可预先离线计算得到,比如词组可能性。而链接向量的交集运算等特征则需要基于输入数据实时计算得到。综合复杂度和计算实时性分析,描述词语可能释义间相关度的特征(即F4和F5)是最耗时的特征,而词组可能性类特征是计算复杂度最低的特征。
4.2 机器学习算法
根据学习过程中是否利用了人工标注数据,机器学习算法可分为监督式和非监督式学习。监督式学习又可根据预测变量是数值型还是离散型,分为回归和分类两类。相关度学习属于典型的回归问题,即学习从一个数值变量集合到另一个数值变量的映射关系。经典的回归学习算法有线性回归、高斯过程、基于支持向量机的回归算法、回归树等。在前期工作中我们得出平均性能最好的是高斯过程(Guassian Process)算法[26],因此本文结果都基于Weka数据挖掘软件[27]中高斯过程算法的实现得到。
5 实验设计
5.1 数据集
本文用三个基准数据集来测试相关度计算方法的有效性: Sim353、Words240和Words30。为了学习概念相关度,首先通过人工消歧,为数据集中的词语找到与之对应的维基概念。表2比较了三个数据集的规模,包括词语对、词语、概念对和概念的数量。
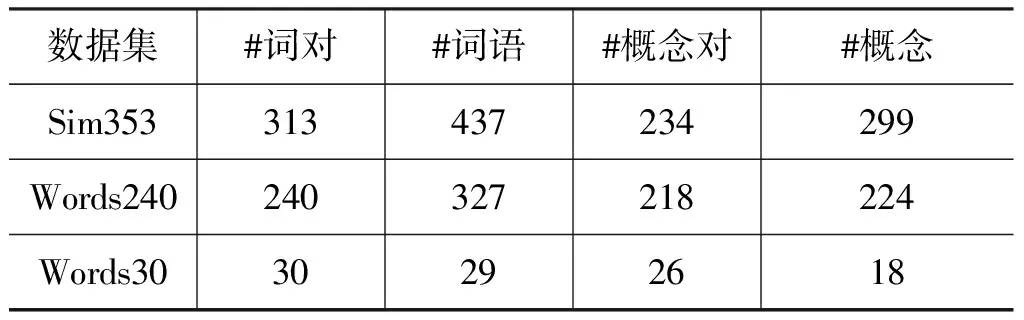
表2 基准数据集及其规模比较
Sim353数据集由Finkelstein等人收集[28],原始数据集包含353个英语词对,是广泛用于测试词语相关度算法的基准数据集。本文在Milne和Witten[16]处理得到的英文数据集(包含313个词对)基础上,参照其处理方式,对其中全部词语进行人工消歧,并映射到中文维基概念。在去掉不存在对应概念的词语和涉及这些词语的词对后,最终得到234个概念对。
Words240数据集是由国防科技大学的汪祥和贾焰等人[22]参照Finkelstein创建Sim353数据集的方法而收集的面向中文的词语相关度基准数据集。经过人工消歧,得到218个维基概念对。
Words30数据集由华中师范大学的涂新辉和何婷婷等[23]收集,类似于Miller和Charles在1991年收集的数据集[29]。其中包含了30个中文词对,人工消歧后得到26个维基概念对。
5.2 中文维基百科预处理
本文使用WikipediaMiner[24]工具解析维基百科XML备份文件。中文和英文分别是2012年5月23日和2011年7月22日生成的版本。其中,中文版本包含约48万篇文章,英文版本包含约357万篇文章,与维基百科官方统计数据一致*http: //en.wikipedia.org/wiki/Wikipedia: Non-English_Wikipedias。
对中文版本的预处理包括繁体中文到简体中文转换,使用中国科学院ICTCLAS分词工具*http: //www.ictclas.org/对文章内容进行分词,将英文词语转换为其小写形式,过滤URL、数字和无意义字符。预处理后总共得到122万词语,其中包含44万英文词语。
5.3 性能指标
依照之前的研究,本文沿用Spearman相关系数作为衡量词语相关度算法性能的指标[15-18,21-24]。Spearman相关系数衡量机器计算结果与人工标注值的一致程度。给定两个变量,其取值介于[-1,1]之间,值越高意味着两变量的取值正向单调相关程度越高。
为了清楚行文,以下用“相关度”表示语义关联程度(即relatedness),用“一致性”表示算法预测的结果与人工标注值之间相关性(即correlation),即Spearman系数。除6.3节外,所有结果都是十次10-折交叉验证得到的平均值。
6 实验结果分析
本节首先分析了中文维基百科中的数据稀疏问题,然后依次分析了基于链接结构的概念相关度学习算法的效果、基于概念向量的词语相关度学习效果和结合两者的词语相关度学习效果。最后探讨了交叉数据集上的学习效果。
6.1 中文维基百科中的数据稀疏问题
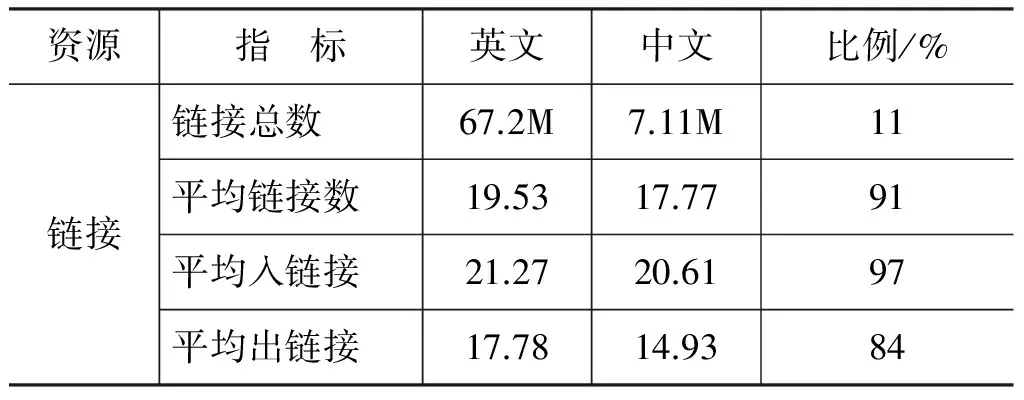
中文维基百科有约48万个文章页面(即概念),为英文维基百科文章总数的十分之一。除了概念收录范围上的巨大差距之外,数据稀疏问题也普遍存在于其他类型的维基资源中。表3从多个角度比较了中文和英文维基百科的数据规模。
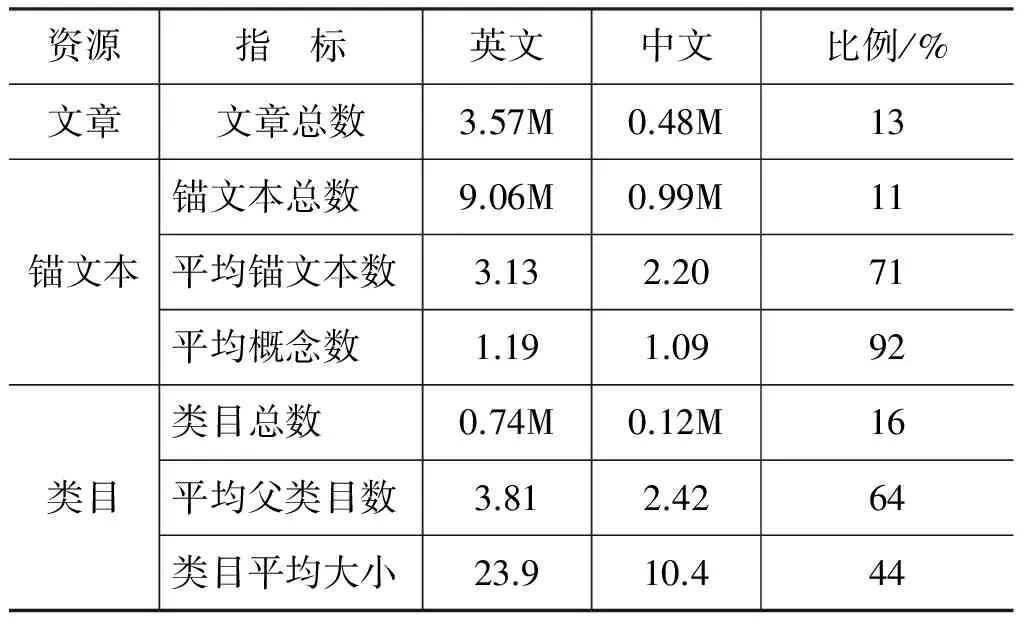
表3 中文与英文维基百科中相关度计算资源的规模比较
续表
“平均锚文本数”指维基文章的平均链入锚文本数量,反映维基文章的别名多寡程度。比如“苹果公司”有19个锚文本: “苹果公司”、“苹果电脑公司”、“Apple”、“苹果”、“苹果计算机”“Apple Store”和“苹果机”等。而在英文维基百科中,“Apple Inc.”有84个锚文本。“平均概念数”反映锚文本的歧义程度,指每个锚文本可能对应的概念个数,数值越低,说明歧义程度越低。比如“苹果”可以指“苹果”、“苹果公司”、“苹果 (电影)”、“苹果电脑”、“麦金塔电脑”和“iPhone”。在英文维基百科中,“apple”有37种可能释义。“平均父类目数”指维基文章所属父类目的平均数量,而“类目平均大小”指类目包含的子类目和文章数量的平均值。
从表3中可以看到,中、英文版本在文章的平均链接数上差别比较小。这说明局部链接结构是比较稳定的,实际实验结果也显示了这一点(表4)。而即便是这一最稳定的资源,其中的数据稀疏问题也已经严重影响到中文词语相关度计算的有效性,凸显出整合多种资源的必要。
6.2 概念相关度学习效果
表4列出了基于链接结构的概念相关度学习算法(即CRM,concept relatedness measure)在三个基准数据集上的效果,并比较了链接方向对学习算法的影响。最后一列CRM同时考虑出链接和入链接。
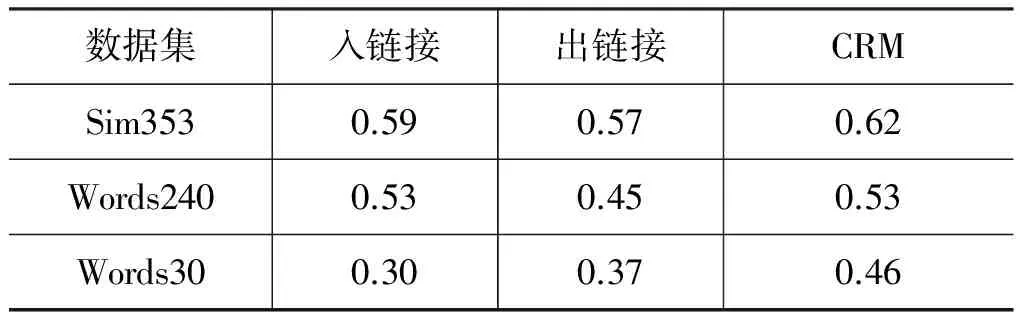
表4 基于链接结构的概念相关度学习算法准确度
在英文Sim353数据集上,Agirre等人[10]取得了0.78的一致性,为当前最好结果。其方法用到两种资源: 从Web文本集中得到的词语分布相似度(distributional similarity)和基于WordNet概念层级结构的概念相关度。Agirre与本文方法的最大不同在于使用支持向量机学习词对排序,即不同词对相关程度的相对大小。然而,实际应用中往往只有当前词对的信息,无法与其他词对进行比较。而且词对相关度的具体数值往往比其相对排序更有价值,比如在计算文本间的语义相关程度时。与本文直接相关的是Milne和Witten提出的WLM算法[16],该算法的最好结果为0.74,是本文算法的比较基准。
Sim353数据集上的比较结果显示了数据稀疏问题的负面作用。同样的算法和同源的数据,由于中文维基百科中的数据稀疏问题,中文相关度计算方法的一致性只有0.62,相较于英文的0.74下降了16%。
在针对中文的相关研究中,三个数据集上的已知最好结果分别为0.59、0.47和0.52,前两者由汪祥等人[22]取得,后者由涂新辉等人[23]获得(见表7)。直观地看表4中的结果,在Sim353和Words240数据集上,使用单一链接结构的CRM方法与人工标注相关度的一致性已超过最好结果。然而,CRM的结果是在概念对上取得,而已知结果是针对词语的,比较基准不同。本文第6.4和6.5节进行了更公平的比较。
6.3 基于概念空间的词语相关度计算效果
依照3.3节和4.1.2节的描述,本节将词语表示为概念空间中的向量,以概念向量间相似度作为词语间语义关联程度。理论上,这样的计算方法适用于所有曾出现在维基百科中的的词语。表5比较了基准数据集中能够直接处理的词语对与概念对数量,以及词语相关度算法(即WRM,word relatedness measure)与概念相关度算法CRM的效果。由于本节测试的是单一特征(即F8)与人工标注(即F9)的一致性,没有使用机器学习算法(6.4节将探讨使用机器学习算法的效果),因此没有用交叉验证的实验方法,实验结果是基于所有数据一次得到。
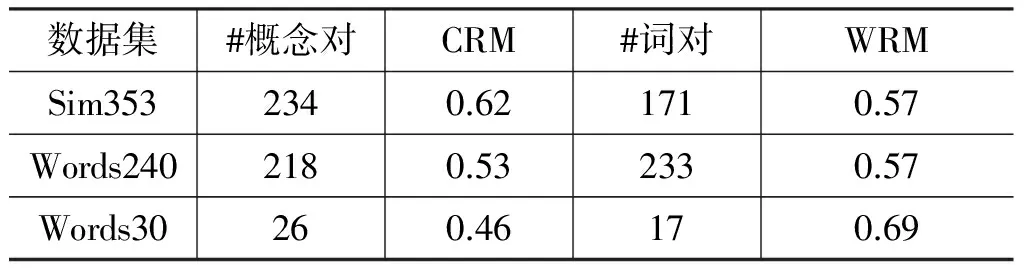
表5 基于概念向量的中文词语相关度计算准确度
从表5中结果可以看到,WRM能够直接处理的词语对数并不多,甚至少于概念对的数量。这是由中文分词问题造成的。数据集中的部分词语可被切分为多个词语,比如“中世纪”可被分为“中”“世纪”;“联邦调查局”可被分为“联邦”“调查局”;“不明飞行物”可被分为“不明”“飞行物”。在解析维基文章内容时,即构建词语的概念向量表示时,这些词语是经过切分的。也就是说,预处理过程会对“不明”“飞行物”分别构建概念向量,而倒排索引中不会存在“不明飞行物”对应的向量条目。因此,有必要对基准数据集中的词语进行相同的分词处理。
6.3.1 中文分词的影响
本文采取的策略是切分输入词语,并将分词所得词语与原始词语合并,构成词语集合。比如“联邦调查局”切分后集合由三个词组成: {联邦调查局,联邦,调查局}。再提取每个词语的概念向量,并将其合并。虽然索引中没有“联邦调查局”,但通过合并“联邦调查局”(向量为空)、“联邦”和“调查局”的概念向量即可得到“联邦调查局”的概念表示。
这一策略成功处理了大多数原先不能直接处理的词语。WRM在三个数据集上的处理率从原来的55%、93%、57%提升至99%、100%和100%。由于解析中文维基百科文章时过滤了所有数字,导致Sim353中有两个词语“5”和“7”不能处理,少了两个词语对,总共为311对词语。
表6比较了分词前后学习算法与人工标注的一致性。其中第五列中结果显示,分词之后,三个数据集上的一致性好像都有不同程度的下降。然而,第三列和第五列的计算基准不同,分词后能够处理的词语对数大幅增加。以Words30为例,两者分别在17对和30对词语上计算得到。为了公平衡量分词效果,我们只比较能直接处理的数据,即表6的第三列和第七列。结果显示本文的分词策略并不会负面影响词语相关度计算结果: Words240和Words30数据集上的结果与分词前持平,而在Sim353数据集上还有些微提升。同时,分词能极大扩展算法的
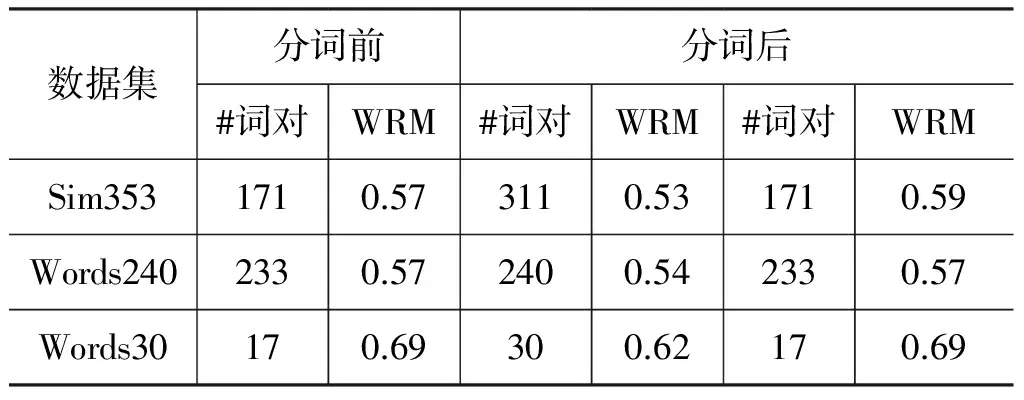
表6 分词对中文词语相关度计算准确度的影响
适用范围。因此本文余下部分所有涉及概念空间相似度(即F8)的部分都是经过分词的。
6.3.2 概念向量长度的影响
概念向量的长度k对向量相似度算法的效果和效率有重要影响。k值越大,考虑的信息越全面,算法的开销也越大。图2比较了k的不同取值对词语相关度计算的影响。k=10意味着词语的概念向量中最多只包含该词语出现频次最多的前十个维基概念。图2中横轴的最后一个维度比较了当k取值为all时的情况,即考虑词语出现过的所有概念。
从图2(a)可以明显看出k值并非越大越好。实际上,三个数据集上的最好结果都在k∈[150,500]取得。同时,k值越大,运行时间的开销越大。当考虑所有概念时(k=all),运行时间是只考虑前200概念的1000倍。因此,综合效果和效率,我们选取k=200为缺省值。
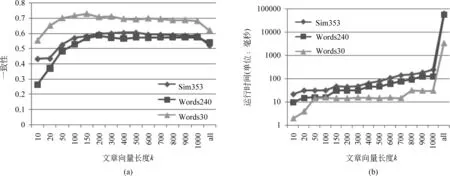
图2 概念向量长度对中文词语相关度计算的影响: (a) 对准确度的影响; (b) 对效率的影响
6.4 词语相关度学习算法的效果
上一节单独考量了基于概念空间的词语相关度计算方法的效果,并没有用到机器学习。本节综合基于链接结构的概念相关度和基于概念空间的词语相关度,考察运用机器学习算法将两者结合的效果。
给定一对词语和指定的特征类型,算法分别在三个基准数据集上以十次10-折交叉验证的方式构建高斯过程回归模型,并对其进行测试。表7比较F4—F8中不同特征组合所生成模型与人工标注结果的一致性,并在最后一列对比已知最好结果。

表7 中文词语相关度学习算法的准确度
首先,从表7第二列的结果中可以看出,由于采用了分词和整合概念向量的策略,词语相关度算法能够处理所有词语对。而概念相关度算法(即CRM)只能处理其中的已登录词语(见6.2节),不能处理维基百科未收录的词语,适用范围有限。
其次,在整体性能方面,应用机器学习所得的词语相关度计算模型是有效的。在全部三个数据集上,训练生成模型都取得了超过CRM且超过已知最好结果的准确度。由此可见,本文提出的词语相关度学习算法不仅适用范围更广,且准确度更高。
在所有特征中,可能概念相关度(即F4、F5)和概念向量空间模型(F8)两类特征的表示能力最强,它们的结合也取得了不错的准确度(即表7第8列)。F4和F5是基于局部链接结构的,F8则是基于维基文章全文的,各自从不同角度描述了词语之间的语义关联程度。因此,这一结果也体现出综合不同类型维基资源的必要性。
由于不能单从两个词语能否组成一个合法词组来判断词语间的相关程度,因此没有对词组可能性类特征(即F6、F7)单独进行测试。从表7第6列和第7列的结果可以看出,用词组类特征描述词语间关联程度的效果并不明显,尤其在Words30数据集上。这可能是因为Words30中词语对作为单一词组出现的可能性不高,比如“不明飞行物”和“飞碟”。相比较下,在效果最明显的Words240数据集中,词语对作为词组出现的可能性较高,比如“发表”和“文章”、“北京”和“奥运会”、“自然”和“环境”等。
综合考虑表7中的实验结果,本文余下部分采用第8列对应的模型,即结合可能概念相关度(F4、F5)和概念向量空间模型(F8)两类特征。
6.5 交叉数据集对词语相关度学习效果的影响
本文首次同时使用了国内学者采集的Words240和Words30数据集与英文中最常用的Sim353数据集。在前面的实验中我们发现,算法在不同数据集上的表现不尽一致。为了更深入了解数据集的性质与之间关联,我们进一步开展了交叉数据集的实验。
给定两个数据集D1和D2,先用D1中的全部数据训练生成词语相关度计算模型,再在D2中的全部数据上进行测试。表8比较了三个数据集的所有可能交叉结果。
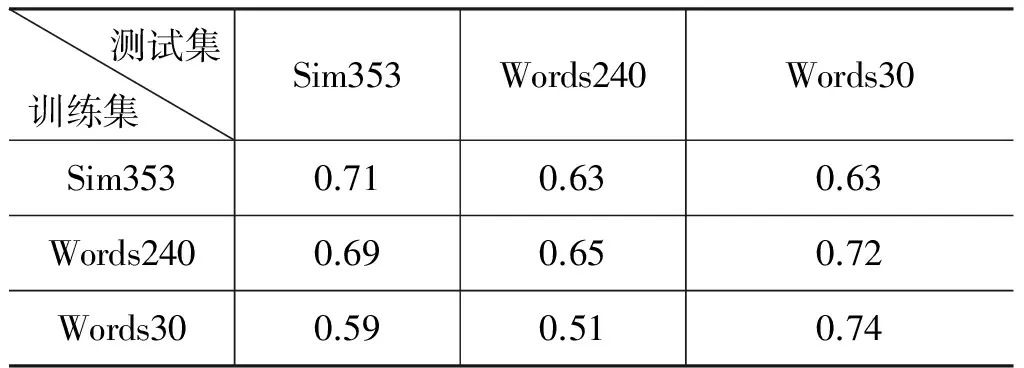
表8 交叉数据集对中文词语相关
一般情况下,当训练集和测试集为同一数据集时,训练所得模型的一致性应该最高,尽管这样的实验方法存在过度拟合的风险。然而,值得注意的是,在Words240上训练所得模型在另外两个数据集上都取得了更好的结果,不仅接近本文算法在该测试数据集上的最好结果(即表8对角线上的结果),更超过了已知的最好结果。比如,在Words30上取得了0.72的一致性,在已知最好结果基础上提升了39%。这说明该模型具有很好的泛化能力,能很好预测未见词语对的相关度,比较适合实践应用。另外,由Sim353训练生成模型的泛化能力也不错,在Words240和Words30上取得的一致性均为0.63,相较于已知的最好结果0.47和0.52分别提升了34%和21%。相比较之下,Words30数据集由于其规模与前两者相差较大,导致其生成模型的泛化能力有限。
7 结束语
本文针对中文维基百科中存在的数据稀疏问题,综合链接结构和维基文章全文两种不同类型的维基资源,从中分别抽取描述词语间语义关联程度的特征,应用机器学习算法从人工标注数据中学习不同特征的最佳配置。实验结果验证了本文所提出方法的有效性,在已知最好结果的基础上提升了20%—40%。本文还系统考察了中文分词、概念向量长度对词语相关度计算的影响,研究了各类特征的预测能力,最后比较了不同基准数据集所生成模型的泛化能力。下一步的工作首先是将本文中的词语相关度学习算法应用于中文文本分析任务,比如聚类和信息检索。其次是进一步研究百科知识的跨语言处理和应用。
[1] 36Kr.下一代搜索引擎即将来临: 知识图谱的用户体验报告[OL]. 2014[2014-7-12]. http: //www.36kr.com/p/205737.html.
[2] Ruiz E L,Manotas I G,GarcíA R V. et al. Financial news semantic search engine[J]. Expert Systems with Applications,2011,38(12): 15565-15572.
[3] Milne D,Witten I H,Nichols,D M. A knowledge-based search engine powered by Wikipedia[C]//Proceedings of the 16th CIKM. New York: ACM,2007: 445-454.
[4] Gabrilovich E,Markovitch,S Feature generation for text categorization using world knowledge[C]//Proceedings of the 19th IJCAI. SanFrancisco: Kaufmann,2005: 1048-1053.
[5] Hu J,Fang L,Cao Y,et al. Enhancing text clustering by leveraging Wikipedia semantics[C]//Proceedings of the 31st ACM SIGIR. New York: ACM,2008: 179-186.
[6] Huang A,Milne,D Frank,E Witten,I H Clustering documents with active learning using Wikipedia[C]//Proceedings of the 8th IEEE ICDM. Washington,DC: IEEE Computer Society,2008: 839-844.
[7] Pippig K,Burghardt D,Prechtel N. Semantic similarity analysis of user-generated content for theme-based route planning[J]. Journal of Location Based Services,2013,7(4): 223-245.
[8] Yan P,Jin W. Improving cross-document knowledge discovery using explicit semantic analysis[C]//Proceedings of the 14th DaWaK. Heidelberg: Springer-Verlag,2012: 378-389.
[9] Huang L,Milne D,Frank E,Witten I H. Learning a Concept-Based Document Similarity Measure[J]. Journal of the American Society for Information Science and Technology,2012,63(8): 1593-1608.
[10] Agirre E,Alfonseca E,Hall K,et al. A study on similarity and relatedness using distributional and WordNet-based approaches[C] //Proceedings of NAACL. Stroudsburg: ACL,2009: 19-27.
[11] Lenat D B. CYC: A large-scale investment in knowledge infrastructure[J]. Communications of the ACM,1995,38: 33-38.
[12] 王红玲,吕强,徐瑞. 中文语义相关度计算模型研究[J]. 计算机工程与应用,2009(7): 167-170.
[13] Giles J. Internet encyclopaedias go head to head[J]. Nature,2005,438: 900-901.
[14] Strube M,Ponzetto S P. WkiRelate! Computing semantic relatedness using Wikipedia[C]//Proceedings of the 21st AAAI. Menlo Park,CA: AAAI Press,2006: 1419-1424.
[15] Gabrilovich E,Markovitch S. Computing semantic relatedness using Wikipedia-based explicit semantic analysis[C]//Proceedngs of the 20th IJCAI. San Francisco: Kaufmann,2007: 1606-1611.
[16] Milne D,Witten I H. An effective,low-cost measure ofsemantic relatedness obtained from Wikipedia links[C].//Proceedings of the Advancement of Artificial Intelligence Workshop on Wikipedia and Artificial Intelligence. Menlo Park,CA: AAAI Press,2008: 25-30.
[17] Yazdani M,Belis A P. Computing text semantic relatedness using the contents and links of a hypertext encyclopedia[J]. Artificial Intelligence,2013,194: 176-202.
[18] Yeh E,Ramage D,Manning C D,et al. WikiWalk: Random walks on Wikipedia for semantic relatedness[C]//Proceedings of the 2009 Workshop on Graph-Based Methods for Natural Language Processing. Stroudsburg,PA: ACL,2009: 41-49.
[19] 刘群,李素建. 基于知网的词汇语义相似度计算[J]. 中文计算语言学,2002,7(2): 59-76.
[20] 李赟,黄开妍,任福继,钟义信. 维基百科的中文语义相关词获取及相关度分析计算[J]. 北京邮电大学学报,2009,32(3): 109-112.
[21] 万富强,吴云芳. 基于中文维基百科的词语语义相关度计算. 中文信息学报,2013,27(6): 31-37,109.
[22] 汪祥,贾焰,周斌,丁兆云,梁政. 基于中文维基百科链接结构与分类体系的语义相关度计算[J]. 小型微型计算机系统,2011,32(11): 2237-2242.
[23] 涂新辉,张红春,周琨峰,何婷婷. 中文维基百科的结构化信息抽取及词语相关度计算方法. 中文信息学报,2012,26(2): 109-114.
[24] Milne D,Witten I H.An open-source toolkit for mining Wikipedia[J]. Artificial Intelligence,2013(194): 222-239.
[25] Cilibrasi R L,Vitányi P M. The Google similarity distance[J]. IEEE Transactions on Knowledge and Data Engineering,2007,19(3): 370-383.
[26] Rasmussen C E,Williams C K I. Gaussian processes formachine learning[M]. Cambridge,MA: MIT Press,2006.
[27] Hall M,Frank E,Holmes G,et al. The WEKA Data Mining Software: An Update[J]. SIGKDD Explorations,2009,11(1): 10-18.
[28] Finkelstein L,Gabrilovich Y M,Rivlin E. et al. Placing search incontext: The concept revisited[J]. ACM Transactions on Information Systems,2002,20(1): 116-131.
[29] Miller G A,Charles W G. Contextual correlates of semantic similarity[J]. Language and Cognitive Processes,1991,6(1): 1-28.
Learning the Semantic Relatedness of Chinese Words from Wikipedia
HUANG Lan,DU Youfu
(College of Computer Science,Yangtze University,Jingzhou,Hubei 434000,China)
Semantic word relatedness measures are fundamental to many text analysis tasks such as information retrieval,classification and clustering. As the largest online encyclopedia today,Wikipedia has been successfully exploited for background knowledge to overcome the lexical differences between words and derive accurate semantic word relatedness measures. In Chinese version,however,the Chinese Wikipedia covers only ten percent of its English counterpart. The sparseness in concept space and associated resources adversely impacts word relatedness computation. To address this sparseness problem,we propose a method that utilizes different types of structured information that are automatically extracted from various resources in Wikipedia,such as article’s full-text and their associated hyperlink structures. We use machine learning algorithms to learn the best combination of different resources from manually labeled training data. Experiments on three standard benchmark datasets in Chinese showed that our method is 20%-40% more consistent with an average human labeler than the state-of-the-art methods.
word relatedness; Wikipedia; Chinese information processing; regression; hyperlink structure

黄岚(1982—),博士,主要研究领域为机器学习和文本分析。E⁃mail:lanhuang@yangtzeu.edu.cn杜友福(1961—),硕士,教授,主要研究领域为人工智能。E⁃mail:dyf@yangtzeu.edu.cn
2014-02-26 定稿日期: 2014-07-15
长江青年基金(2015cqn52)
1003-0077(2016)03-0036-10
TP391
A
