维吾尔语比较句识别研究
2016-05-03王慧云田生伟加米拉吾守尔冯冠军
王慧云,禹 龙,田生伟, 加米拉·吾守尔,冯冠军
(1. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046; 2. 新疆大学 网络中心,新疆 乌鲁木齐 830046;3. 新疆大学 软件学院,新疆 乌鲁木齐 830008;4. 新疆大学 人文学院,新疆 乌鲁木齐 830046)
维吾尔语比较句识别研究
王慧云1,禹 龙2,田生伟3, 加米拉·吾守尔1,冯冠军4
(1. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046; 2. 新疆大学 网络中心,新疆 乌鲁木齐 830046;3. 新疆大学 软件学院,新疆 乌鲁木齐 830008;4. 新疆大学 人文学院,新疆 乌鲁木齐 830046)
识别比较句并提取被比较事物之间的关系是细颗粒度意见挖掘的重要研究内容之一。该文给出维吾尔语比较句的范畴、语法特点,定义了维吾尔语比较句识别的任务。提出两层识别模型,第一层是基于比较词的粗识别,第二层提出双向CSR挖掘算法(Bidirectional CSR Mining),以挖掘的模式为特征,利用支持向量机(SVM)筛选得到比较句,实现维吾尔语比较句的识别。实验F值达到70.93%,证明提出的两层识别模型可以有效识别维吾尔语比较句。
维吾尔语;比较句识别;双向CSR挖掘算法; 文本分类
1 引言
比较作为一种常见且具有一定说服力的表达方式,在各种不同的语言环境里均扮演着重要的角色。这些比较信息对于一些潜在的商品买家,或者一些投资者等的决策有着重要的参考价值。
Nitin Jindal[1-2]采用keywords和CSRs作为特征,以朴素贝叶斯分类器来识别比较句。对比较关系识别,提出了LSR方法,利用挖掘的序列规则,预测和抽取关系元素。Shasha Li等[3]利用以IEP序列做种子的Bootstrapping方法识别比较句并抽取比较实体。Dae Hoon Park等[4]选取语义和句法特征,并将其应用到三种不同的分类器实现比较句识别。汉语比较句研究中,黄小江等[5]结合汉语的语言特征,以比较词和序列模式为特征,用SVM分类器实现比较句的识别。宋锐等[6]通过建立中文比较模式库的方式实现比较句的识别,并用条件随机场抽取汉语比较关系。黄高辉等[7]增加了实体对象信息特征,采用SVM分类器识别比较句。李建军[8]运用熵值平衡算法对倾斜语料预处理,用SVM和NB分类器识别比较句。杜文韬等[9]则选择基于关联特征词表的机器分类法对比较句和非比较句分类。王素格等[10]利用序列模式挖掘算法获取比较模式,并利用该模式直接匹配待识别句子。Seon Yang[11]对韩语比较句识别做了研究工作,沿用了以比较词、词性和词汇序列为特征,机器分类的方法。这些研究工作推进了比较句的研究,但方法多依赖于人工定制的规则,代价大,可移植性不高。另外,比较句表达形式复杂多样,以上研究对象均是最通用的比较句型,有相当部分的特殊比较句尚未纳入研究范围。
针对维吾尔语的比较句研究还没有全面展开。虽然语言学家在文献[12-13]中对汉语和维吾尔语的常用比较句做了对比,并总结了在维吾尔语比较句中的典型句子结构。但是,在计算语言学领域并没有相关研究。本文深入结合维吾尔语比较句特点,利用现代计算机技术实现维吾尔语比较句自动识别。
2 维吾尔语比较句
2.1 维吾尔语比较句定义及识别任务
比较句是指谓语中含有比较词语或比较格式的句子。在结构上比较句包含比较主体、比较客体、比较点、比较结果四个要素。比较主体和比较客体统称为比较实体。我们将维吾尔语比较句划分为平比、差比和极比三类,其中差比又包括高下和不同两个子类。本文研究的比较句是比较意义明显的句子,语义模糊的句子不纳入比较句范畴。例如,
(维吾尔语句子从右至左书写)

(汉语: 这个班级的纪律比较好。)
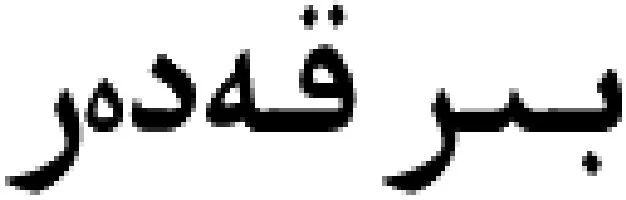
维吾尔语比较句识别研究任务可以分为三部分:1)比较句的识别。即对任意给定的句子判断其是否属于比较句。2)比较句类别识别。将任务1识别出的维吾尔比较句划分为平比(Equal)、极比(Superlative)、高下(Non-equal)、不同(Different)四种类别。3)比较关系抽取。抽取比较句中的比较关系四元素。本文的研究工作将围绕任务1,即比较句的识别展开。
2.2 维吾尔语比较句特点
维吾尔语隶属于阿尔泰语系突厥语族,是一种黏着性语言。维吾尔语比较句具有以下特点:1)维吾尔语的语法常由词根加不同的词缀体现。汉语和英语比较句均含有标志性的比较词,维吾尔语比较句中常由词缀体现比较意义。2)英语和维吾尔语比较句中都含有词缀,但两者所含词缀用法完全不同。在英语比较句中,词缀加在比较结果词(形容词或副词)后,表示比较级。例如,“higher”是形容词“high”的比较级,词缀“-er”加在形容词原级后,与介词“than”搭配表示比较的意义。维吾尔语表示比较意义的词缀附加于比较客体(名词或代词)后。
例如,

(汉语: 苹果比香梨好吃。)
这些特点将在实验中的产生序列环节得到具体应用。
2.3 常见维吾尔语比较词
比较词指的是表达比较的手段,包括词汇手段和语法手段以及某些表达比较的固定格式等。根据维吾尔语比较句中比较词的不同形式,将其分为两类。
1) 词缀表示比较
a.从格结构表示高下差比。
对第2种句式,动词作谓语的比较句,英语与汉语中均是宾语位于动词后,而维吾尔语中宾语却在动词之前。
b.相似格表示平比。
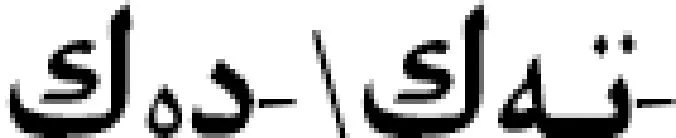
例如,

(汉语:衣服和照片上的一样漂亮。)

如果句子谓语是动词,其否定形式是对该动词的否定。
例如,
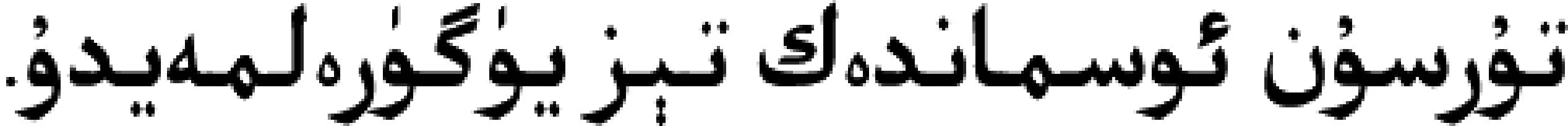
(汉语: 吐尔逊没有吾斯曼跑得快。)
2) 单词,单词与词缀组合表示比较

以上六种句式中,方向格具体选取哪种形式,需要根据语音和谐规律进行判断。在语义上,句式1和2相当于汉语中表示 "跟…一样"的比较句。
例如,
(汉语:喀纳斯景区跟黄山一样有名。)
b. 其他形式的单词,单词与词缀组合表示比较。

句式1相当于汉语中表示“与其…不如…”的比较句;句式2和3表示平比;句式4和5形式上与汉语比较句非常类似,也是由单独的单词体现比较的含义,与汉语比较句语序不存在明显不同。
例如,
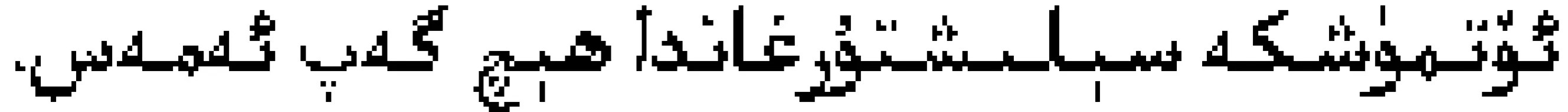

(汉语:这些困难和过去比起来还差得远。)
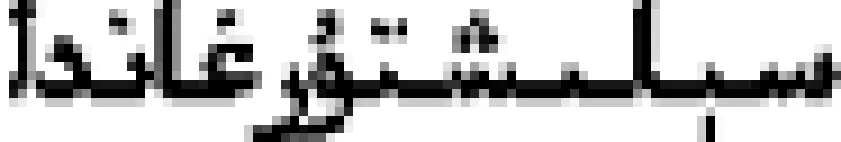


(汉语:库尔勒的香梨是全国最好吃的。)
3 维吾尔语比较句识别方法
根据以上所述维吾尔语比较句特点,提出一个两层比较句识别模型,具体识别流程如图1所示。
该识别模型首先结合人工总结的维吾尔语比较词初步进行粗识别;然后,以双向CSR挖掘算法挖掘的比较模式作特征,利用SVM分类器识别比较句。该模型通过利用比较词与机器学习算法结合的方式,兼顾了维吾尔语比较句识别的准确率和召回率。
3.1 基于比较词的粗识别

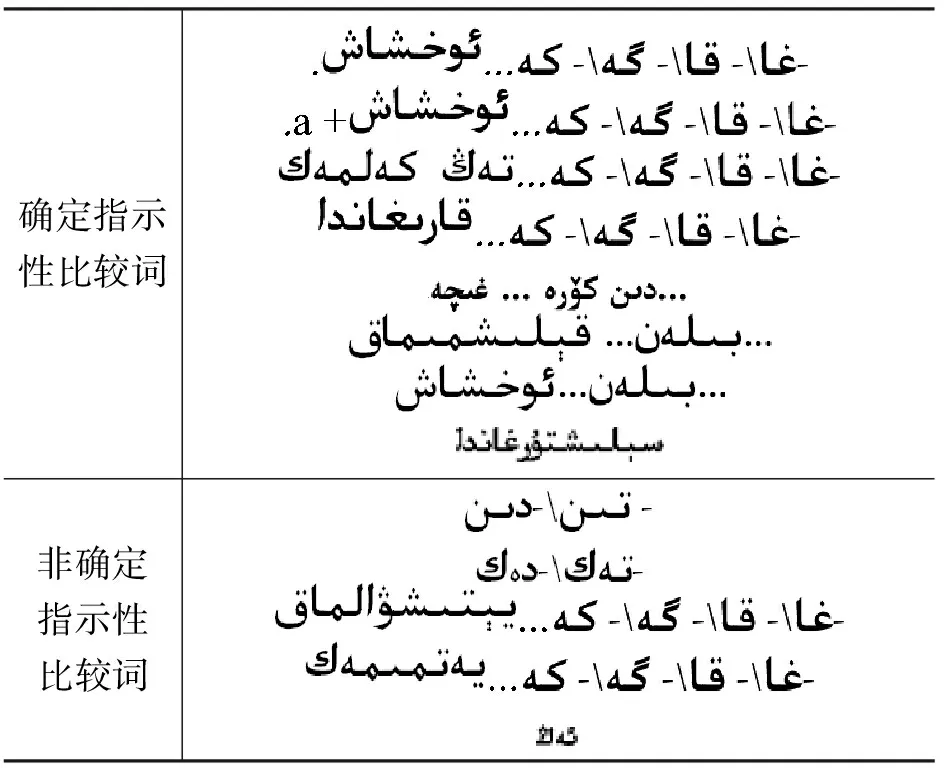
表1 比较词类别划分
模型第一层采用基于比较词的粗识别。基本思路是通过判断句子是否含有比较词来粗略区分比较句与非比较句。
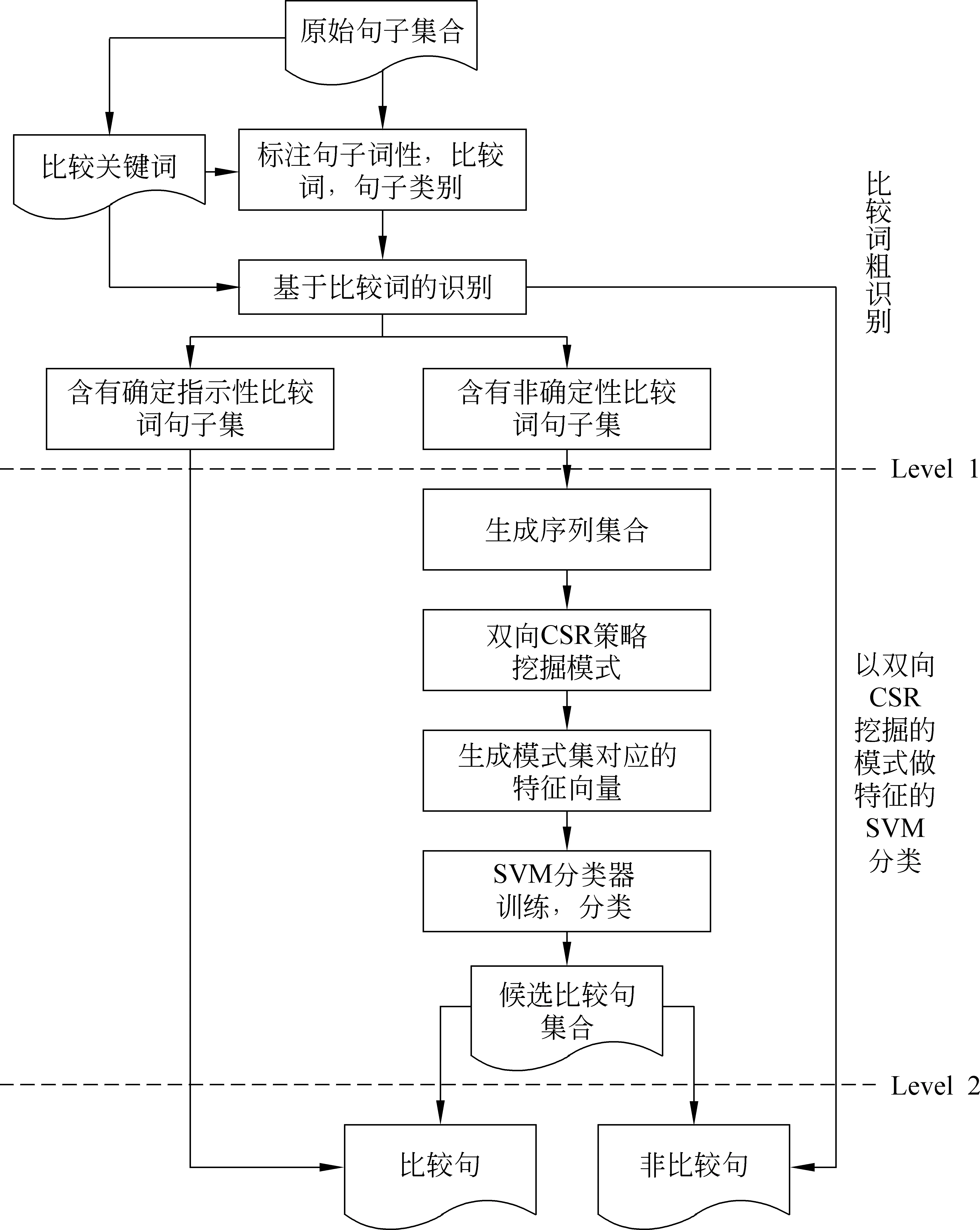
图1 维吾尔语比较句识别流程
维吾尔语比较词多由几部分组合而成,单独取出比较词中的任一部分(可能为词缀,单词)都不能表示比较意义, 必须将比较词作为整体用来识别比较句。因此,在实验过程中,我们采用正则表达式表达各个比较词。正则表达式能表达词缀,单词,并能体现比较词中各个词缀、单词之间的组合关系,即将比较词作为一个整体。
在识别前,我们将比较词集中的每一个比较词表示为对应正则表达式。识别时,将每一个待识别句子与比较词集中的每个正则表达式匹配。对确定指示性比较词,若存在成功匹配的情况,则直接认为该句子为比较句;对非确定性比较词,若存在成功匹配的情况,则将该句子作为候选比较句。所得候选比较句集合作为第二层模型的输入句子集,供进一步识别使用。图1中,level 1即为基于比较词的粗识别过程。
3.2 双向CSR挖掘算法(Bidirectional CSR Mining)
为了进一步筛选出真正的比较句,我们提出一种双向CSR挖掘算法,通过挖掘比较模式,并结合SVM分类器实现比较句识别。
3.2.1 序列选择
通常比较句式中比较词相对固定,而比较主体和比较客体可以任意替换。我们希望用序列模式很好地区分比较句和非比较句。因此,需要定义合适的支持度,来挖掘出每类特有的序列模式,与类别捆绑。
CSR(Class Sequential Rules)是一个蕴含式,前件是序列模式,后件是类别标签。

(1)
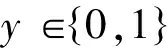
挖掘序列规则之前,需要将句子集生成对应的序列集。维吾尔语比较句句子结构紧凑,比较主体,比较客体分布于比较词附近,比较词的指示作用很强。因此,对序列长度选择问题,以比较词为中心,取其前后r个词的词性作为序列。通过实验发现,当r取3时,达到最优实验效果。
根据2.2节介绍的维吾尔语比较句特点,维吾尔语比较句中有大量词缀充当比较词。并且,多数比较词缀位于比较客体后。而比较客体是可以任意更换的,即其不具有比较句指示作用。因此,在生成序列时,不能直接将含有比较词缀的单词整体及其词性作为序列元素,而应取比较词缀及其所属单词的词性。否则,含有比较词缀单词的词干部分(一般是比较客体)将会干扰实验结果。对于比较词是单词的情况,取比较词及其词性作为一个序列元素,句中其他词只取词性作为序列元素。按照上述方法得到序列数据集,并为集合中每个序列标注类别。
3.2.2 算法描述
对生成的序列集进行序列模式挖掘,现存序列模式挖掘算法PrefixSpan[14]选择序列数据库中的一元模式作为挖掘的初始模式,这样得到一个相当大规模的模式集。其中包括大量的无用模式,即无法利用该模式识别比较句。这些无作用模式增大了模式挖掘的计算量,并会在接下来机器学习过程中,加大特征向量的维数,干扰最终分类效果。因此,为避免挖掘无用模式,将比较词作为初始模式。维吾尔语比较句中,比较主体和客体常位于比较词前,比较结果位于比较词后,比较词前后的词性信息是比较模式的重要组成部分。而比较词在序列所处位置并非列首,直接用PrefixSpan挖掘序列模式,会丢失比较词前的序列信息。 针对以上问题,提出一种双向的CSR挖掘算法(BidirectionalCSRMining,简称Bi-CSR),即以比较词为初始模式,向其前后两个方向挖掘比较模式。算法流程如图2所示。

图2 Bi-CSR算法流程图
图2将比较词集中的个体(单独的词缀或单词)作为挖掘的初始模式。以比较词为界,将序列切为两部分。对序列的前半部分,比较词位于列尾,我们将序列元素顺序倒置,形成形式上以比较词为首的子序列,然后运用PrefixSpan挖掘模式,得到模式,将所得模式元素顺序倒置,记作子模式。对序列的后半部分,将添加至子序列列首,对子序列运用PrefixSpan挖掘模式,得到比较模式。挖掘过程中,通过定义合适的最小支持度和最小置信度阈值,挖掘出满足条件的CSR。
比较句识别可以被看作是一个二分类问题,将给定的某些句子划分为比较句和非比较句两类。将Bi-CSR得到的比较模式作为特征,使每个测试序列与比较模式匹配,若匹配成功,则对应特征位置1,否则置0。采用二分类性能优越的SVM分类器,选出候选比较句。
4 实验与结果分析
4.1 语料收集与处理
实验所用语料来源于一些大型维吾尔语商业和BBS网站,共收集涵盖服装类、日用洗化类、干果类维吾尔句子3 900句(其中比较句1 555句,非比较句2 345句)。现有关于比较句的研究工作相对较少,所用比较句语料规模不大。图3是对本文及现存代表性比较句研究工作的语料规模的对比结果。
通过图3语料规模的对比,对于维吾尔语这种小语种,我们认为本文的语料规模满足现阶段实验要求。本文比较句语料类别分布情况如图4所示。
我们采用新疆大学新疆多语种信息技术重点实验室自主开发的词性标注器进行初步词性标注。由于该词性标注器的标注效果还不能完全满足实验需求,我们聘请多位维吾尔语语言专家对初步词性标注结果校正: 当专家意见一致时认为标注正确;当专家意见出现分歧时,由专家投票表决,采取多数专家认同的标注结果。语言专家也对比较词和句子类别(比较句和非比较句)进行标注,得到比较词集和比较句识别需要的熟语料。
4.2 实验结果与分析
按照图1所示流程,先进行基于比较词的比较句粗识别实验(KWS)。分别判断待识别句子是否含有表1所示两类比较词,若含确定指示性比较词,则此句子为比较句;若含有非确定指示性比较词,则此句子为候选比较句;若不含有比较词,为非比较句。实验结果如表2所示。
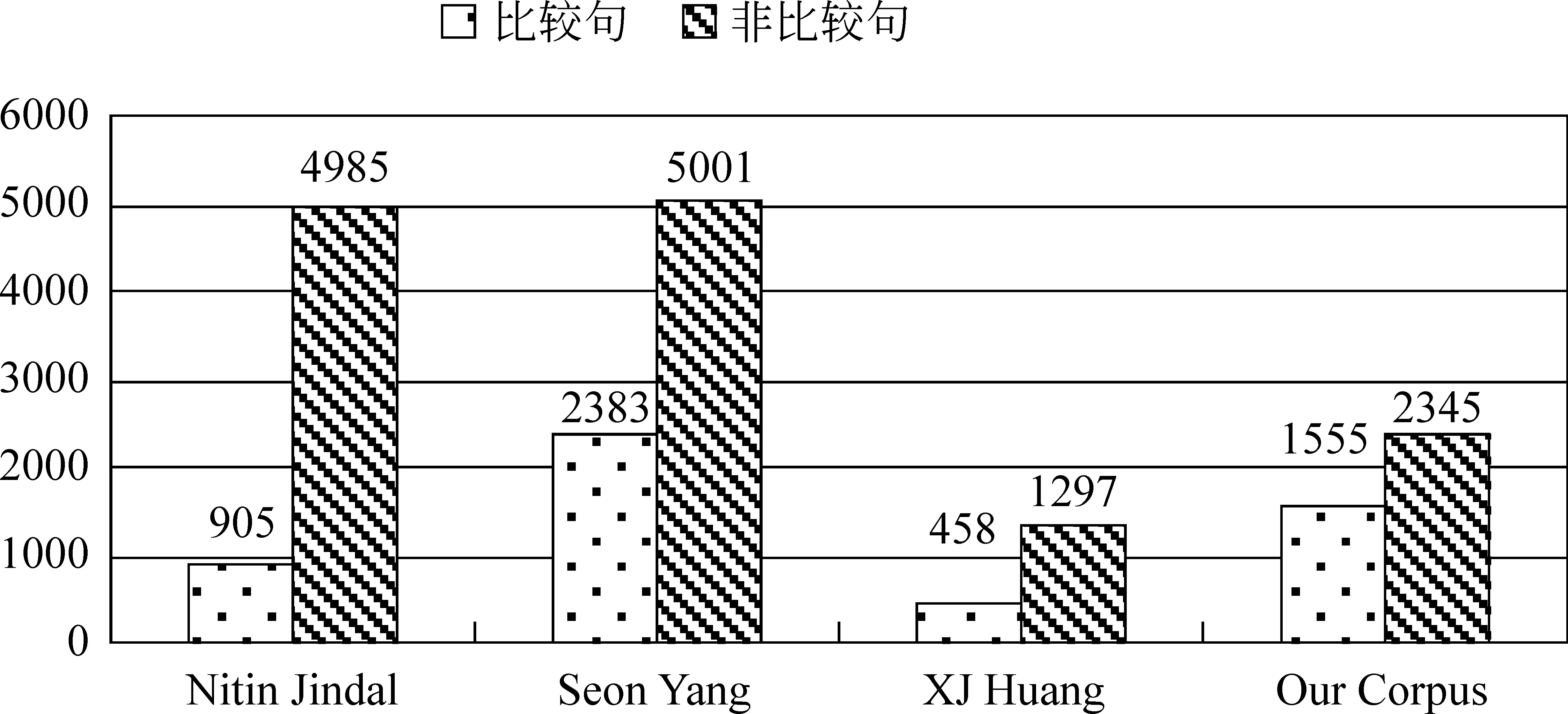
图3 比较句语料规模对比
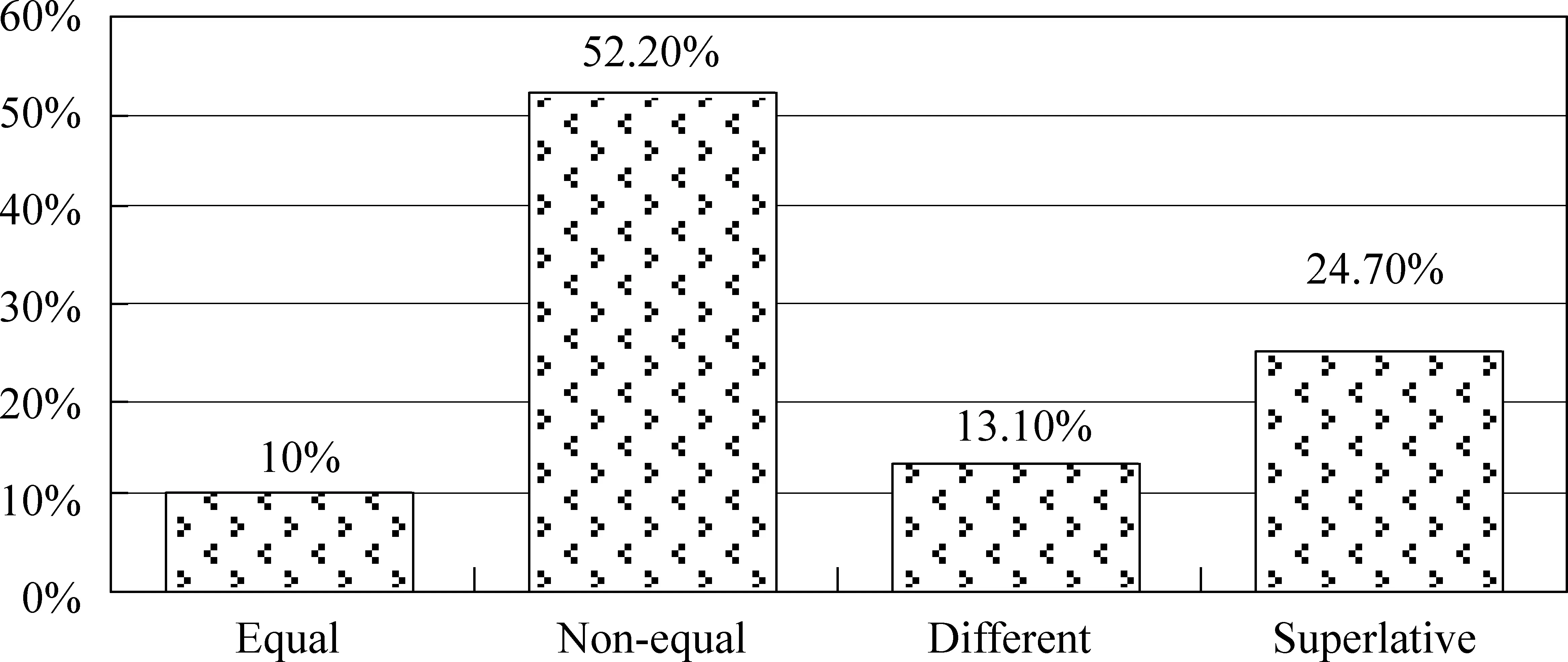
图4 本文比较句类别分布

表2 不同类型比较词识别比较句准确率对比
表2中含有确定指示性比较词的比较句识别准确率高达98.9%,说明含有此类比较词的句子就是比较句。KWS识别出该类句子后,直接将其放入最终比较句集合, 不作为后续实验的对象。对于含有非确定性比较词的句子,作为候选比较句,由第二层模型进一步识别。
以经过KWS筛选出句子作候选比较句集合,用Bi-CSR挖掘得到比较模式集,进入识别模型的第二层。进行如下两组实验:
1)基于CSR的实验(CSR)。直接运用Prefixspan挖掘比较模式,并通过判断句子是否匹配这些模式识别比较句。2)基于Bi-CSR的实验(Bi-CSR)。用Bi-CSR挖掘比较模式,判断每个句子是否与比较模式匹配,若匹配,则该句为比较句,反之,不是比较句。两种方法实验结果对比如图5所示。
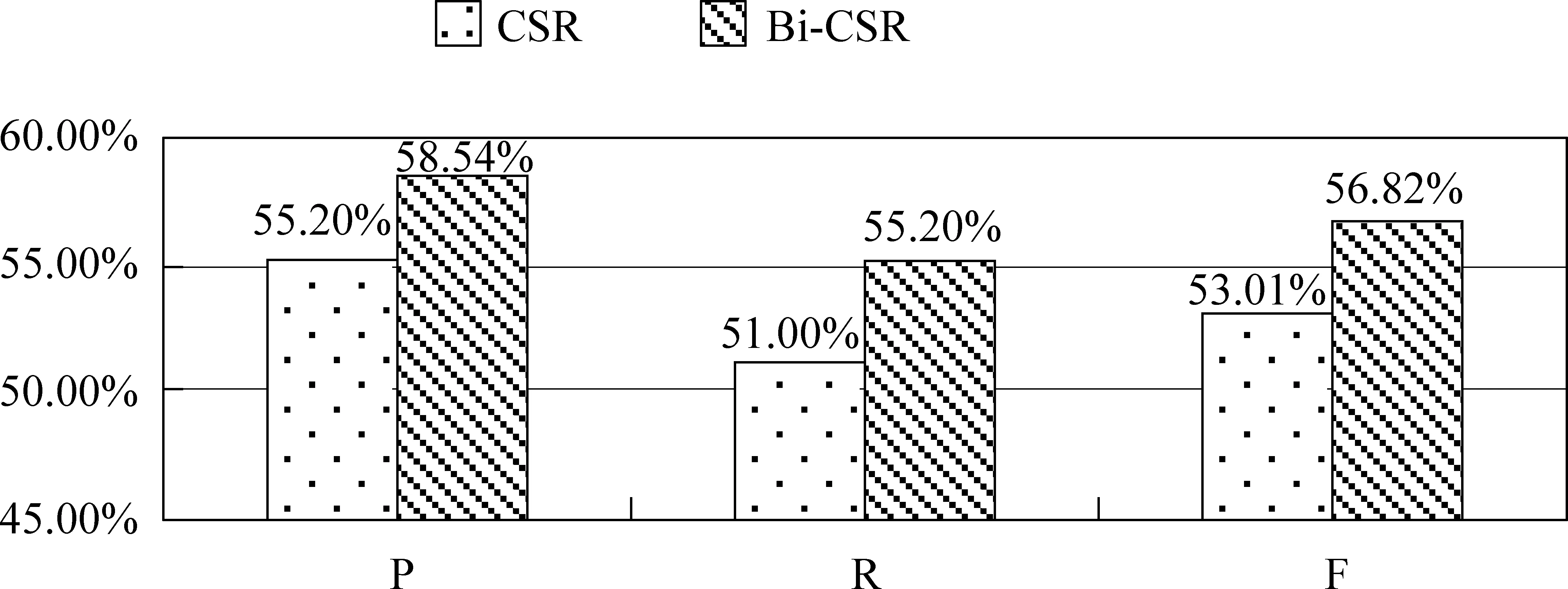
图5 不同挖掘算法识别比较句效果对比
实验过程中,分别采用现存Prefixspan挖掘算法和本文提出的Bi-CSR挖掘比较模式,得到对应的模式数分别为173和129。可见Bi-CSR可有效减小比较模式规模。观察图5,Bi-CSR识别比较句的F值达到56.82%,而CSR识别比较句F值为53.01%,证明Bi-CSR挖掘算法挖掘所得模式能较有效的识别比较句,且性能优于CSR。
采用性能较优的Bi-CSR结合SVM分类实验(Bi-CSR&SVM)。以Bi-CSR挖掘比较模式,将每种模式作为SVM分类器的一维特征,判断每个句子是否匹配比较模式,若匹配对应位则置1,反之,置0。得到对应句子的特征向量,用SVM分类器训练,测试。为了测试运用SVM方法结合Bi-CSR的实验性能是否优于单纯Bi-CSR,将两者实验结果做一对比,如图6所示。
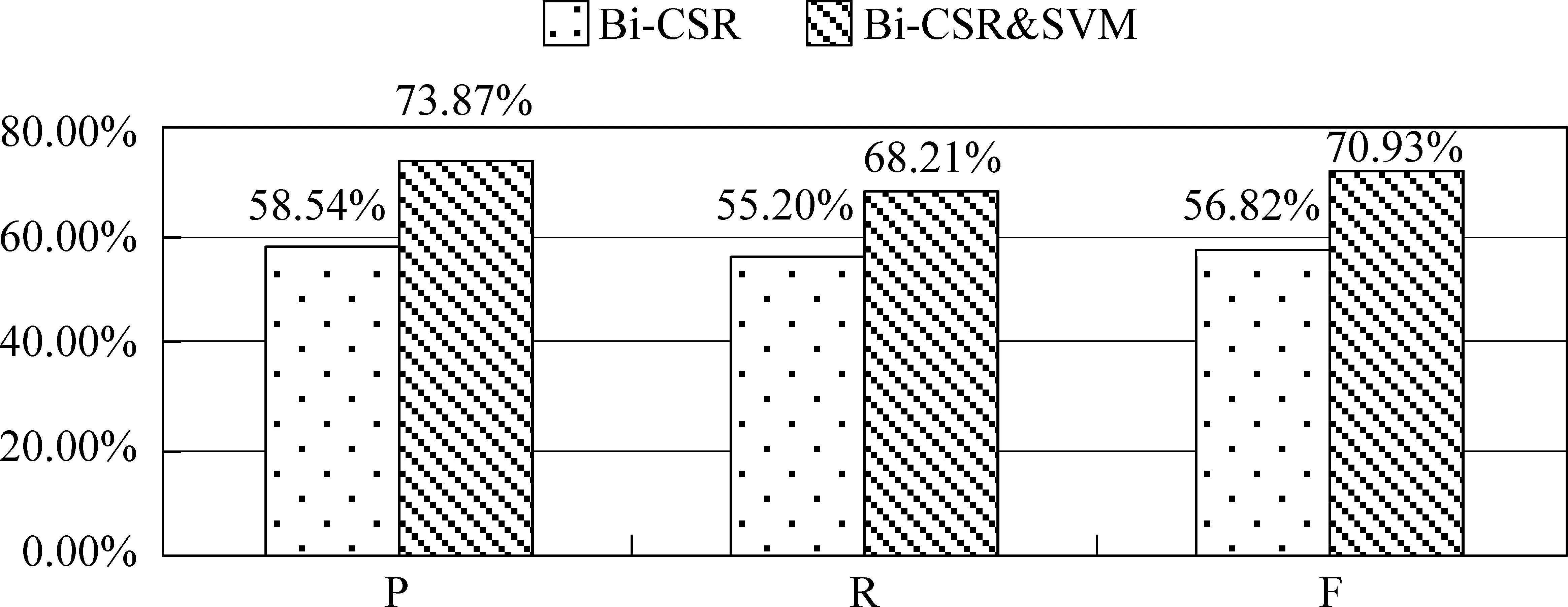
图6 Bi-CSR, Bi-CSR&SVM实验效果对比图
由图6可知,Bi-CSR&SVM的实验效果数值远高于Bi-CSR,说明SVM分类器能综合多个比较模式特征,最终学习得到更优的比较模式。Bi-CSR&SVM的F值达70.93%,说明该方法能较有效地识别比较句。
我们还运用Nitin Jindal[1-2]的方法在本文实验语料上进行实验,将实验结果与本文方法的结果作一对比,结果如图7所示。

图7 Bi-CSR&SVM , Nitin Jindal实验效果对比图
观察图7所示实验结果,本文方法在准确率方面较Nitin Jindal方法有小幅提升,而在召回率上提升幅度相对较大,这体现了Bi-CSR挖掘有效比较模式的优越性。但整体来看,实验各项数据仍有待提升,需要进一步深入结合维吾尔语语言特征,解决单词弱化等带来的词形变化问题,最终达到优化实验性能的目的。最终实验F值达70.93%,证明本文所提两层比较句识别模型能较好完成维吾尔语比较句识别任务。
5 结论
本文深入分析了维吾尔语比较句语法特征。依据比较词的不同类型,提出两层比较句识别模型。提出的双向CSR挖掘算法(Bi-CSR),有效减少无用比较模式的产生。结合SVM分类器,实现维吾尔语比较句识别,实验结果证明本文提出方法的有效性。维吾尔语比较句的研究工作没有全面展开,下一步需要建立大规模的比较句语料库,解决因维吾尔语丰富的词形变化而难以识别单词等基础问题,这将有助于进一步提高比较句识别的实验性能。在此基础上,完成维吾尔语比较句类别识别及关系抽取。
[1] Nitin Jindal, Bing Liu. Identifying comparative sentences in text documents [C]//Proceeding of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval New York, 2006: 244-251.
[2] Nitin Jindal, Bing Liu. Mining comparative sentences and relations[C]//Proceeding of the 21st National Conference on Artificial Intelligence. Boston, 2006: 1331-1336.
[3] Shasha Li, Chin-Yew Lin, Young-In Song, et al. Comparable Entity Mining from Comparative Questions[C]//Proceeding of the 48th Annual Meeting of the Associaton for Comutational Linguistics. Sweden, 2010: 650-658.
[4] Dae Hoon Park, Catherine Blake. Identifying comparative claim sentences in full-text scientific articles [C]//Proceeding of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju, 2012: 1-9.
[5] 黄小江, 万小军, 杨建武. 汉语比较句识别研究[J]. 中文信息学报, 2008, 22(5): 30-38.
[6] 宋锐, 林鸿飞, 常富洋. 中文比较句识别及比较关系抽取[J]. 中文信息学报, 2009, 23(2): 102-107.
[7] 黄高辉, 姚天昉, 刘全升. 基于CRF算法的汉语比较句识别和关系抽取[J]. 计算机应用研究, 2010, 27(6): 2061-2064.
[8] 李建军. 比较句于比较关系识别研究及其应用[D]. 重庆, 重庆大学硕士学位论文, 2011.
[9] 杜文韬, 刘培玉, 费邵栋, 张朕. 基于关联特征词表的中文比较句识别 [J]. 计算机应用, 2013, 33(6): 1591-1594.
[10] 王素格, 王凤霞, 宋雅. 基于序列模式的汉语比较句识别方法 [J]. 山西大学学报(自然科学版), 2013, 36(2): 172-179.
[11] Seon Yang, Youngjoong Ko. Finding relevant features for Korean comparative sentence extraction[J]. Pattern Recognition Letters, 2011, 32(2): 293-296.
[12] 丁文楼. 汉、维语比较句对照分析[J]. 语言与翻译, 1989,(2): 40-43.
[13] 努尔比亚·木合坦. 汉维比较句对比研究 [D]. 喀什, 喀什师范学院硕士学位论文, 2012.
[14] Jian Pei, Jiawei Han, Behzad Mortazavi-Asl, et al. PrefixSpan: Mining sequential patterns by Prefix-Projected growth[C]//Proceeding of the 17th International Conference on Data Engineering, 2001: 215-224.
Identification of Uyghur Comparative Sentences
WANG Huiyun1, YU Long2,*, TIAN Shengwei3, Jiamila Wushouer1, FENG Guanjun4
(1. School of Information Science and Engineering, Xinjiang University, Urumqi, Xinjiang 830046, China; 2. Network Center, Xinjiang University, Urumqi, Xinjiang 830046, China; 3. School of Software, Xinjiang University, Urumqi, Xinjiang 830008, China; 4. College of Humanities, Xinjiang University, Urumqi, Xinjiang 830046, China)
The identification of comparative sentences and the extraction of comparative relations are of substantial significance to fine-grained opinion mining. This paper outlines the famework of Uyghur comparative sentence identification, and proposes a two level identification model. A Bidirectional CSR Mining algorithm(Bi-CSR) is designed to mine sequential patterns, then the SVM classifier is applied to classify a Uyghur sentence into either “comparative” or not. The experimental results demonstrate the effectiveness of the proposed method.
Uyghur; comparative sentences identification; bidirectional CSR mining algorithm; text classification

王慧云(1989-),硕士研究生,主要研究领域为人工智能、自然语言处理。E⁃mail:hotwheather⁃123@163.com禹龙(1974-),通信作者,副教授,主要研究领域为计算机网络、人工智能。E⁃mail:yulong_xju@126.com田生伟(1973-),教授,主要研究领域为计算机网络、自然语言处理、并行计算。E⁃mail:tianshengwei@163.com
1003-0077(2016)01-0148-08
2013-06-11 定稿日期: 2013-12-16
国家自然科学基金(61262064,60963017, 61063026, 61063043,61331011,61563051); 国家社科基金资助项目(10BTQ045,11XTQ007); 自治区教育厅高等院校重点项目(XJEDU2011I08)
TP391
A
