基于隐马尔可夫模型的主观句识别
2016-05-03刘培玉费绍栋朱振方
刘培玉,荀 静,费绍栋,朱振方
(1. 山东英才学院 信息工程学院,山东 济南 250104;2. 山东师范大学 信息科学与工程学院,山东 济南 250014;3. 山东交通学院 信息科学与电气工程学院,山东 济南 250357)
基于隐马尔可夫模型的主观句识别
刘培玉1,2,荀 静2,费绍栋2,朱振方3
(1. 山东英才学院 信息工程学院,山东 济南 250104;2. 山东师范大学 信息科学与工程学院,山东 济南 250014;3. 山东交通学院 信息科学与电气工程学院,山东 济南 250357)
文本情感倾向分析是意见挖掘和情感文摘中的一个重要环节,而在情感倾向分析中涉及到的是主观性文本,这就需要进行主客观文本分类。当前的主客观文本分类方法主要是基于特征词典的概率统计方法,并没有考虑特征之间的语法与语义关系。针对该问题,该文提出一种基于隐马尔可夫模型(HMM)的主观句识别方法。该方法首先从训练语料中抽取具有明显分类效果的七类主客观特征,然后每个句子应用HMM进行特征角色类别标注,并依据标注的结果计算句子的权重,最终识别主观句。该方法在第六届中文倾向性分析评测任务中能够有效地识别主观句。
隐马尔可夫模型;特征标注;主观句识别
1 引言
随着互联网的发展,在论坛、微博和博客等各个在线交流平台上都存在大量的与当前热点话题或事物及其属性相关的评论信息,在进行情感倾向分析之前对主客观文本进行分类不仅可以提高情感分析的准确率还可以减少算法时间复杂度。文本情感倾向分析[1]是意见挖掘和情感文摘中的一个重要环节,而在情感倾向分析中涉及到的是主观性文本,这就需要进行主客观文本分类,从而提取给定文本中的带有情感倾向的主观信息,去除客观信息。关于主客观文本分类这一问题在文献[2-4]中均有涉及。
主客观句分类在国外起步较早,经过以往的研究与发展已经产生了很多优秀的分类算法。在文献[5-6]中,作者分别研究了形容词和名词两种不同词性的词对主客观分类的影响。在文献[7]中,Hatzivassiloglou & Wiebe进一步发现动态形容词、具有语义倾向的形容词和修饰程度不同的形容词对主客观分类具有很大的影响。在此基础上,Riloff等[8]使用Bootstrapping算法从训练集中学习获取主观性句子模式,进而识别主客观语句。Kamal[9]采用有监督的机器学习方法和基于规则的方法挖掘主观句中的特征-情感对,并取得很好的分类效果。
国内的学者对主观句抽取算法的研究也取得很大进展。上海交通大学的姚天昉等[10]对中文主客观文本进行了定义和区别,并且预选了主客观文本的分类特征。哈尔滨工业大学的叶强等[11]提出一种根据连续双词词类组合模式(2-POS)自动判断句子主观性程度的方法。福州大学的林惠恩等[12]分别采用主观线索和主观模式的方法来提取主观句子,并在此基础上结合两个方法进行主客观句抽取。实验结果表明,这些方法都能有效地对主客观句子进行分类。
可以看到,现在的主客观文本分类方法主要是基于特征词典的概率统计方法,并没有考虑特征之间的语法与语义关系。因此,本文提出基于隐马尔可夫模型的特征角色标注的中文主观句识别方法,实验结果表明,该方法可以有效地识别给定评论文本中的主观句。
2 基于HMM的主观句识别
在本节首先给出了基于HMM 的主观句识别算法的总体框架,从整体上对该算法进行描述,然后进行主客观特征词集的抽取,最后详述该算法的具体实现过程。
2.1 总体框架
基于HMM的主观句识别算法包括训练阶段和识别阶段,主要包含以下几步: 1)主观特征提取;2)建立HMM;3)应用HMM进行角色标注;4)提取主观句。系统总体流程图如图1所示。
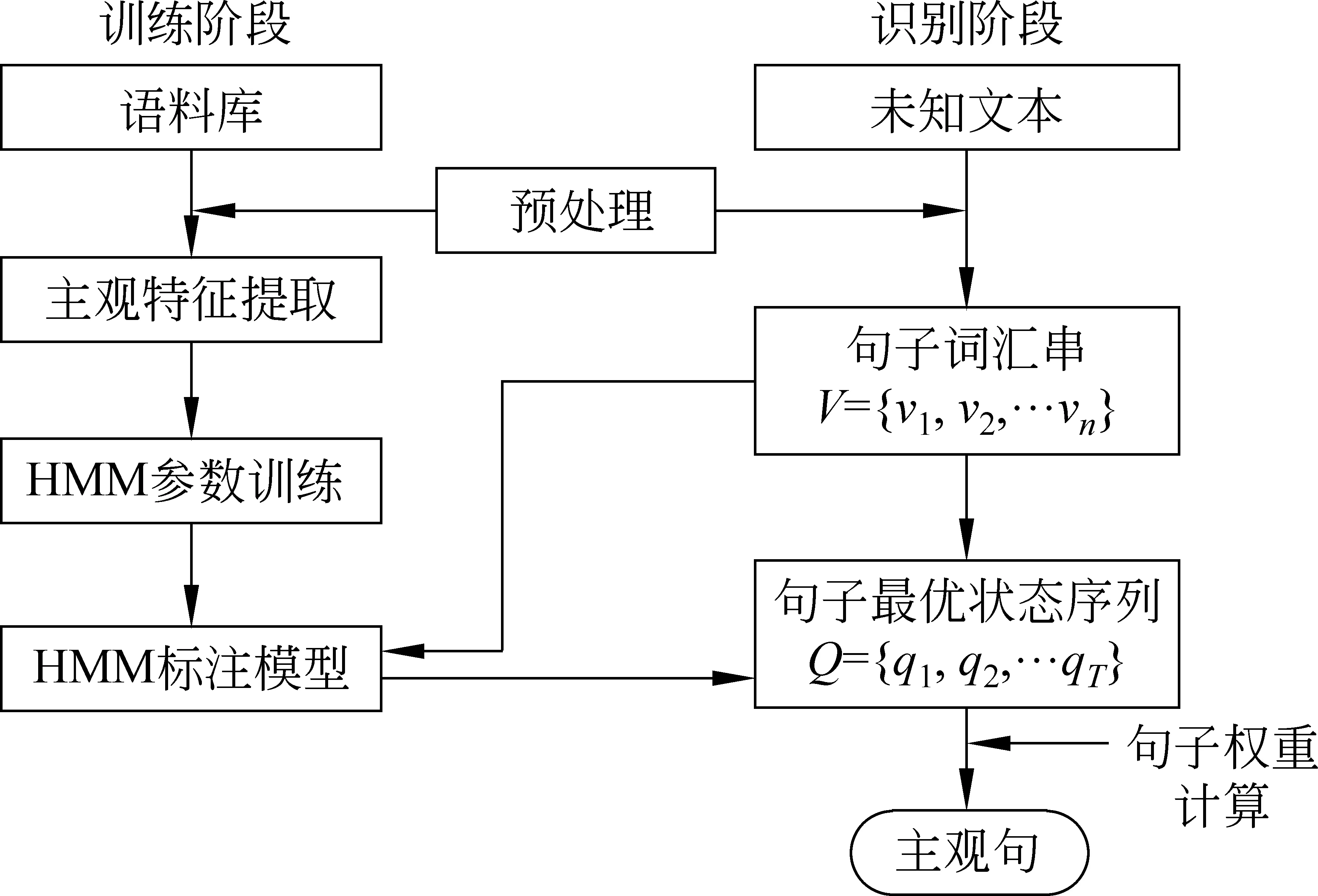
图1 系统整体流程图
2.2 主客观特征词集抽取
主客观特征主要是指既有区分力度又能代表主客观句类型的特征。该模块主要是对这些特征进行抽取,组成主客观特征词集。本文首先对已有的常用方法进行介绍,进而根据其优缺点提出结合信息增益与卡方统计的特征抽取方法。
2.2.1 目前常用的特征抽取方法
主观句在词、句和句型的使用上都与客观句有较大的差别,因此在这里提取对主客观句最有区分力度的特征集。特征选择算法中常用的有文档频率(TF-IDF),信息增益(IG)、相对熵(KL距离)、卡方统计(CHI)和点互信息(PMI)[13]。这几种方法针对不同的语料库各有其优缺点,其中相对熵和点互信息主要被用在计算两个随机变量之间的关系上,例如,依赖关系、相似关系等。
文档频率使用特征词在主观句中出现的次数来表示这个特征词与主观句的相关度,该方法实现最简单、算法复杂度最低,但有很多低频词带有很强烈的主观句类别信息,因此不能单单根据词频把它们去掉。信息增益刻画了一个词语在主观句中出现与否对主客观文本分类的影响,即一个词语在句子中出现前后的信息熵之差。卡方统计是通过度量候选特征词和句子之间的相关度,这种方法的理论基础是假设特征词和句子之间符合具有一阶自由度的χ2分布[10]。
2.2.2 结合信息增益与卡方统计的特征抽取方法
研究结果表明,信息增益只能考察特征对整个主客观分类系统的贡献,而不能具体到其中一个类别上,通过它得到的特征是适合全局的特征,而卡方统计可以针对具体类别进行特征提取。由于本文是针对主客观句的二分类问题并且需要获得能明显表示主观句或客观句的特征,因此根据信息增益和卡方统计各自的特点,本文将两者联合起来分层次共同作用于训练集提取出既有区分力度又能代表主客观句类型的特征。
对每个词汇t判断其是否为特征以及所属类型具体步骤。
step1 计算使用词汇t的进行预分类的信息增益IG(t);
step2 若IG(t)大于设定阈值,则判定其为预选特征,否则结束算法,进行下一个词汇的判断;
step3 计算词汇t的χ2(t,sub);
step4 如果χ2(t,sub)大于设定阈值,则判断其为主观特征,否则,判断其为客观特征。算法结束,进行下一个词汇的判断。
经过特征选择以后,可以得到对主客观分类较好效果的特征词集,但是分类的最终效果亦受特征维数的影响。实验表明,当特征维数最终趋向于一个相对稳定的范围时,分类效果趋于稳定。因此在本文中设具有最好分类效果的特征维数为K,并选择候选特征集中的前K个特征组成特征集,即features={f1,f2,…fi,…,fK}。
2.3 基于HMM的主观句识别算法
在本模块借鉴HMM在词性标注方面的应用将待分类的句子集合应用HMM标注特征角色,得到句子中包含的词汇所对应的特征类别。该模块分为特征类别划分、HMM模型建立、特征角色标注和主观句提取四个过程。
2.3.1 特征类别划分
在此,根据文献[6]中的特征类别及针对训练语料的所作的分析,将提取的特征词集分为两个大类七个小类别,两个大类为主观性特征集和客观性特征集,其中主观性特征集又分为六个小类别,即指示性动词、指示性副词、形容词、情感词、第一人称或第二人称代词、指示性标点符号。由于分类效果明显的客观性特征集较少,在这里不做具体分类统一将其作为一类,即客观性词。对其符号化为F={iv,iadv,adj,st,pro,pun.oj}。
2.3.2 隐马尔可夫模型建立
HMM是在马尔可夫模型基础上发展起来的,近些年在自然语言处理等领域获得了广泛应用。它是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。一个HMM是不确定的、随机的有限状态自动机,由不可观测的状态转移过程(一个Markov链) 和可观测的观察生成过程组成[14]。本文进行特征角色标注时使用HMM的参数初始化如下所示。
(1)Y为定义的词汇特征类别的数目,在2.3.1节定义了特征词集所属的七个特征类别。因而,Y的值为7,记为Y={q1,q2,…,q7}={iv,iadv,adj,st,pro,pun.oj}。qi为马尔可夫链在时刻t时所处的状态,其中,qi∈{q1,q2,…,q7}。
(2)X为即将要进行特征角色标注的词汇的数目,在这里令X=features={f1,f2, …fi,…,fK}。每个句子只选择这些词汇序列来作为其观测序列符号,vj为在时刻t所观测到的观测值,其中,vj∈{f1,f2,…fi,…,fK}。
(3)π为经过训练集的概率统计之后每个特征类别所占的初始概率,π=(πi),其中,πi=P(i1=qi),i=1,2,…,7是经训练语料中统计得出的时刻t=1处于状态qi的概率。
(4)A是状态转移概率矩阵:A=[aij]7×7。其中,aij=P(it+1=qj|it=qi),i=1,2,…,7;j=1,2,…,7表示在时刻t处于状态qi的条件下在时刻t+1转移到状态qj的概率。
(5)B为观测概率矩阵,B=[bj(k)]7×K。其中,bj(k)=P(ot=vk|it=qj),k=1,2,…,7;j=1,2,…,K是在时刻t处于状态qi的条件下生成观测vk的概率。
2.3.3 基于HMM模型的特征角色标注
建立HMM以后,应用其对每个预处理后的句子进行特征角色标注,并使用维特比[12]算法得到一个最优标注序列Q。维特比算法是在给定一个观测序列的基础上,根据已有的HMM找到一个概率最大的状态序列。
对一个已知句子s观测序列V={v1,v2,…,vT},应用维特比算法计算相应的最优标注状态序列Q={q1,q2,…,qT},T是句子s中的词序个数。
(1) 初始化δ(i)=πibi(v1),i=1,2,…,7
ψ1(i)=0,i=1,2,…,7
(2) 递推,对t=2,3,…,T
(3) 终止P*=max1≤i≤7δT(i)qT=arg max1≤i≤7[δT(i)]
(4) 最优特征状态序列回溯,对t=T-1,T-2,…,1得到qt=ψt+1(qt+1),最终求得最优特征状态序列Q={q1,q2,…,qT}。
2.3.4 主观句提取
在本文中最后提取主观句衡量其句子的权重大小,计算的方法是考虑句子中已标注特征角色的词汇的类别权重和句法类型的权重两方面的因素得到最终句子的权重,计算过程如下。
1) 特征词类的权重
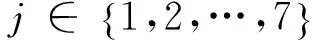
(1)
其中,L是特征词类Fj中特征词的个数,sub是特征词fi在主观句中出现的频数,obj是特征词fi在客观句中出现的频数,num=sub+obj表示特征词fi在训练语料中出现的总频数。
2) 句法类型的权重
本文认为组成一个句子的特征词汇越重要则该句子被判别为主观句的可能性会相应的越高。此外,从训练语料中可以得到句子的类型不同,成为主观句的可能性也不同。句子从语气上分,可分为陈述句、疑问句、祈使句、感叹句。疑问句是用来向别人提出问题的句子。感叹句是用来表示某种感情的句子,因而疑问句和感叹句是主观句的可能性要比陈述句要大得多。祈使句是用来要求别人做什么或不做什么的句子,往往表达的客观事实,从而祈使句是客观句的可能性要强与其他三类句子。
综合特征词和句法类型的句子s的权重计算方法如公式(2)所示。
(2)
其中,qi∈Qi=1,2,…,T是句子s经过HMM标注后的最优特征状态序列,η是变量调节参数,其取值通过训练语料获得。
用type表示待分类句子的句法类型,其具体赋值如公式(3)所示。

(3)
3 实验与分析
3.1 实验语料
本文的实验语料为第六届中文倾向性分析评测给出的任务一面向新闻的情感关键句抽取与判定中的10 000篇文本。该任务要求抽取出给定文本的情感关键句,因需要对文本中的句子进行倾向性分析,故首先要进行主观句识别。本文选取给定的前6 000篇文本,总共包含141 024个句子作为训练集,剩余4 000篇文本含有的106 350个句子作为测试集。
3.2 评价指标
实验将由本文所提出的算法提取出的主观句同Baseline方法进行比较,使用准确率、召回率和F值来反映主观句识别能力表示为式(4)~(5)。
(4)
(5)
(6)
其中a为算法识别出的主观句集合中准确的句子数,即在主观句集合和扔标注集合中都出现的句子的个数,b为算法识别出的主观句集合中的句子数,c为人工标注集合的句子数。
3.3 实验及结果分析
在本文中抽取主客观特征使用的是结合信息增益和卡方统计的方法,因此在实验一中分别采用文档频率、信息增益、卡方统计和本文方法这四种方法进行特征提取,并通过准确率和召回率反映每种方法的优劣。此外,在具体的主观句识别系统中需要有明确的K值,因此通过实验二来确定K最终的取值。实验三主要是对抽取出的特征类别在主观句中分布情况的展示。应用HMM标注特征角色时对每个类别的识别效率不近相同,因此本文在实验四中分别验证了HMM对每个特征类别的识别率。本文提出的方法与Baseline方法的比较实验在实验五中给出。
实验一 特征选择方法
本文分别应用文档频率、信息增益、卡方统计和本文方法分别进行特征选择的结果如图2所示。
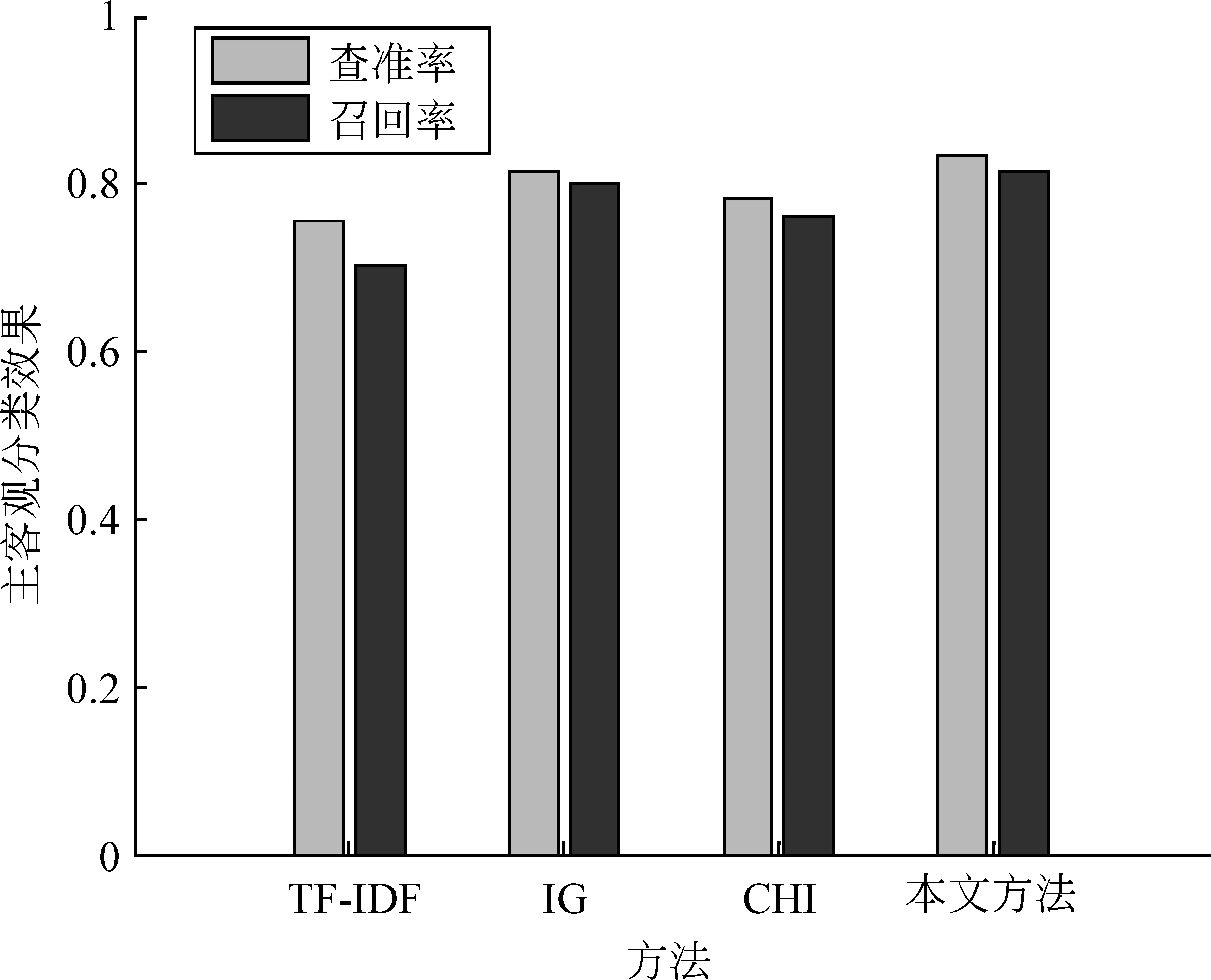
图2 特征选择方法对比
由图2可以看出,本文使用的信息增益和卡方统计联合分层次特征选择方法对主客观文本这个二分类问题具有更好的效果。
实验二 确定特征维数 K
为了确定具有最好分类效果的特征维数,在这里对K取不同的值对最后主客观句子分类的准确度进行验证,分别测试了K为200,400,600,1 000,1 200,1 400,1 600,1 800,2 000,2 200,2 400,2 600,2 800,3 000时主客观句子分类的准确度。

图3 主客观句分类的准确度随特征维数K的变化趋势
其中横坐标代表特征维数,纵坐标代表主客观句分类的准确度,图中的折线表示主客观句分类的准确度随特征维数变化的趋势。可以看出,当K=2 200时,主客观句分类的准确度最高并且趋于平衡,因此,对于本文所采用的语料库来说,特征维数K的取值为2 200。
实验三 主观特征集提取
应用本文特征提取方法总共获得七类2 200个主客观特征,其中每一类所包含的特征词的个数如表2所示。

表1 人工标注的主客观句分类结果
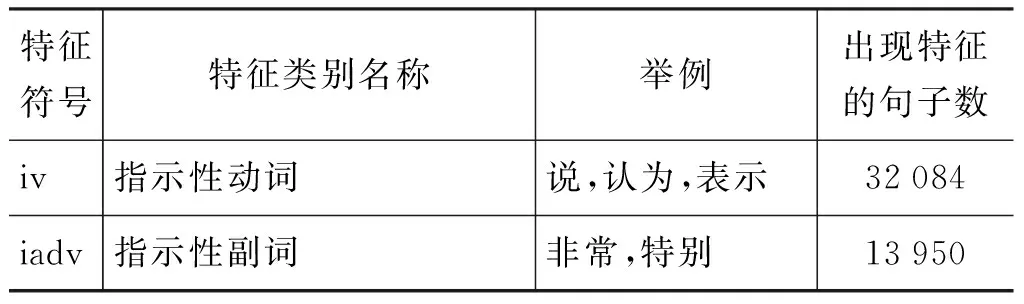
表2 主观句中的特征分布情况
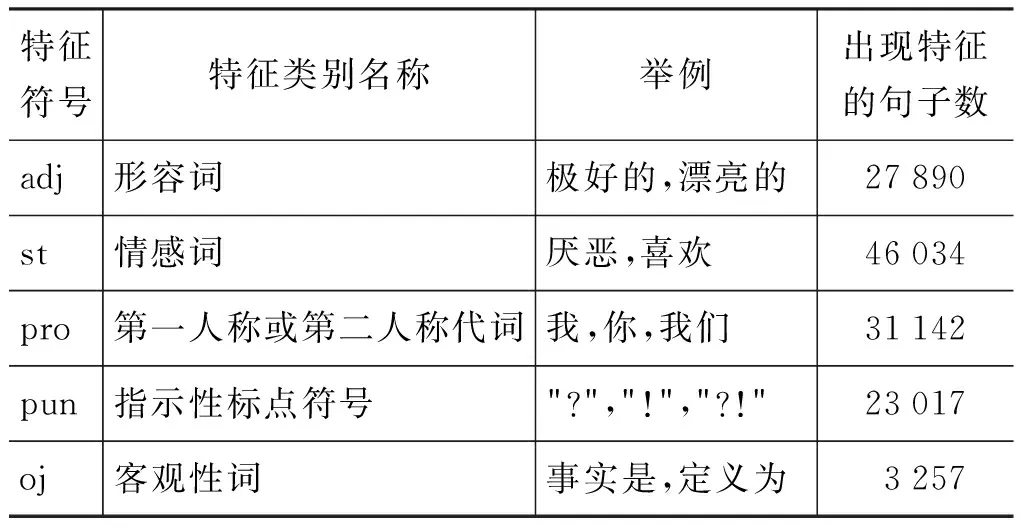
续表
实验四 HMM对各个特征类别的识别效果
应用HMM识别句子中的七类特征结果如图4所示。
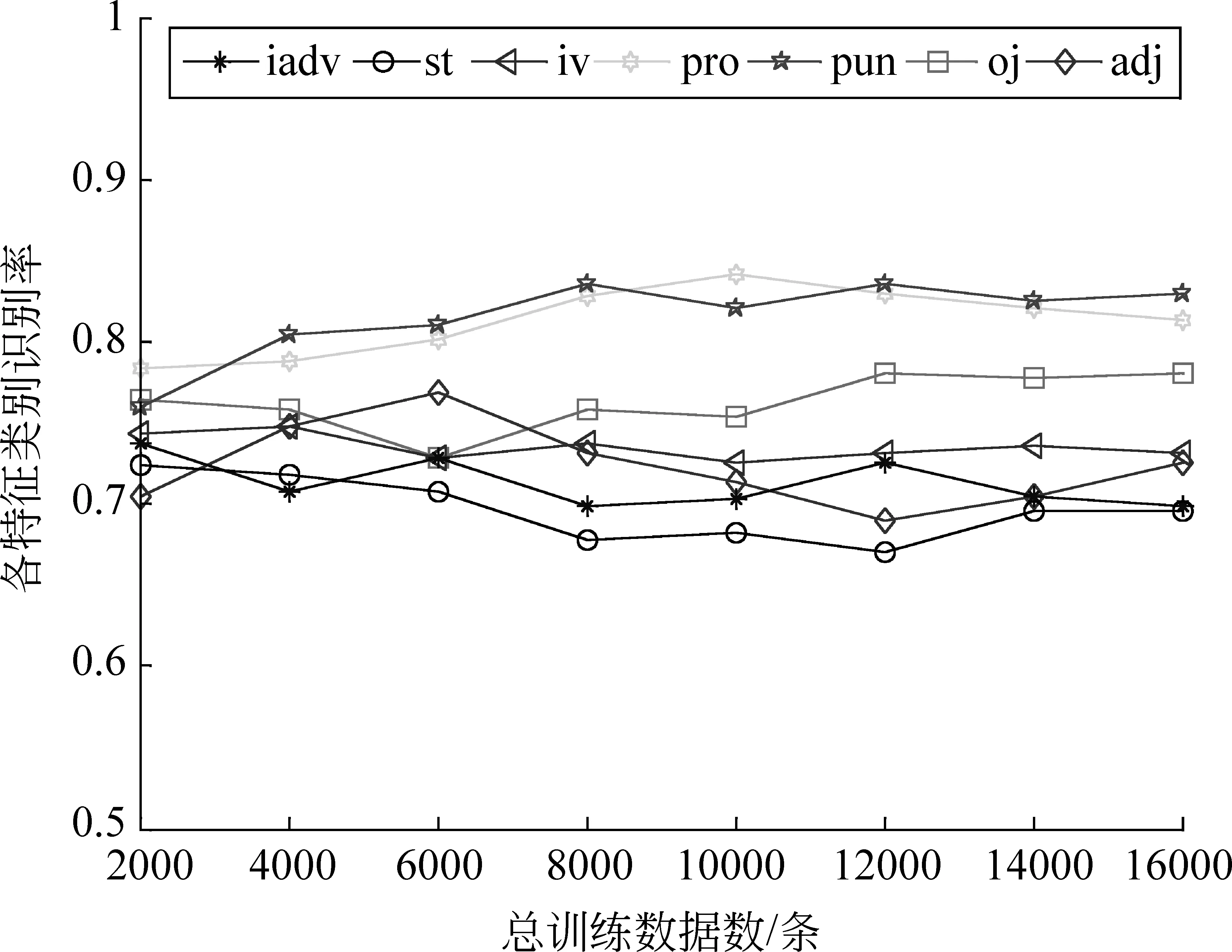
图4 各个特征类别的识别效率的变化趋势
从图4可以看出,HMM对特征类别的识别效率随着训练语料的增加维持在一个较稳定的水平,其中平均识别率为0.751。从而当语料库覆盖面足够大时,HMM特征角色标注方法可以很好的对句子的词汇序列进行标注。
实验五 对比实验
本文采用的Baseline方法为文献[15]和文献[16]中的方法。其中文献[7]中的方法是连续双词词类组合模式(2-POS)方法,文献[16]中的方法是基于特征词典匹配主观线索词的方法。接下来分别采用以上两种方法和本文方法对本文的测试语料进行主观句识别。由于最后抽取的结果受不同的η取值的影响,因此在这里首先对η取不同的参数值对系统的准确度进行验证,分别测试了η为2,4,6,8,10,12,14,16,18,20时系统的性能。

图5 系统的性能随调节参数 η的变化趋势
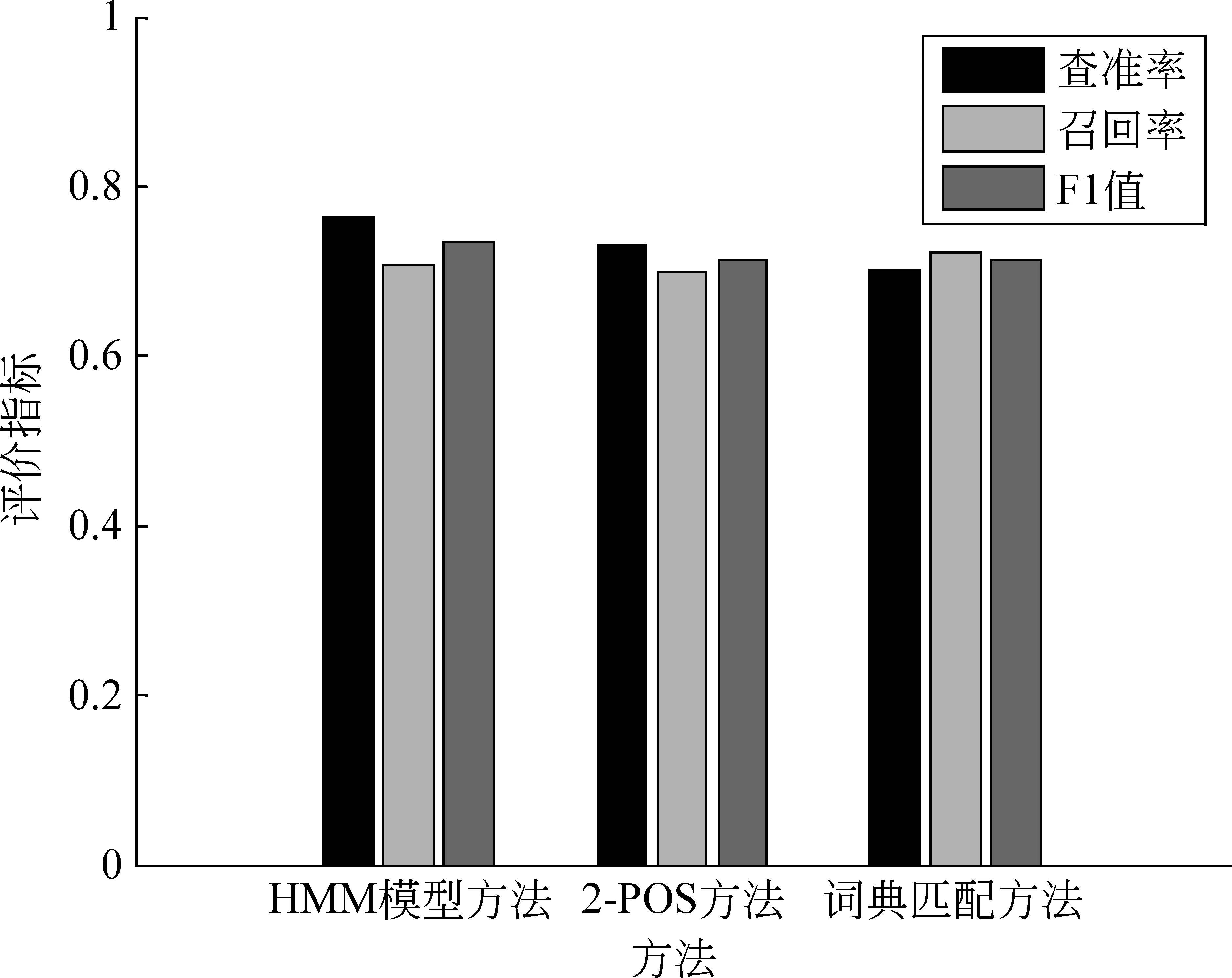
图6 三种主观句识别方法对比
其中,在图5中横坐标代表调节参数η的取值,纵坐标代表系统的性能,图中的折线表示系统的性能随调节参数η的变化趋势。可以看出当η的取值为12时,系统抽取出的主观句的准确度最好,因此本文中η=12。从图6中可以得到,应用基于HMM模型标注的识别主观句的方法查准率和F值均高于Baseline方法,查全率方面需要进一步的提高。由此可见,本文提出的基于HMM模型的主观句识别方法是可行的。
4 总结
本文主要包括主观特征词集提取、基于HMM模型的特征角色标注和主观句提取三个基本的模块。与传统的基于特征词典的概率统计方法相比,应用HMM模型标注特征角色可以考虑特征之间的语法与语义关系,从而提高特征识别的准确性,通过实验证明,该方法能够有效地识别给定文本中的主观句。本文只在特征词这一层面上进行分析,并没有分析短语和句子级别的关系,今后将往这方面做进一步的努力。
[1] 徐琳宏, 林鸿飞, 杨志豪. 基于语义理解的文本倾向性识别机制[J]. 中文信息学报, 2007, 21(1): 96-100.
[2] 李纲, 程洋洋, 寇广增. 句子情感分析及其关键问题[J]. 图书情报工作, 2010, 54(11): 104-107.
[3] 徐军, 丁宇新, 王晓龙. 使用机器学习方法进行新闻的情感自动分类[J]. 中文信息学报,2007,21(6): 95-100.
[4] 娄德成, 姚天叻. 汉语语句主题语义倾向分析方法的研究[J]. 中文信息学报,2007,21(5):73-79.
[5]BruceRF,WiebeJM.Recognizingsubjectivity:acasestudyinmanualtagging[J].NaturalLanguageEngineering, 1999, 5(2): 187-205.
[6]RiloffE,WiebeJ,WilsonT.Learningsubjectivenounsusingextractionpatternbootstrapping[C]//Proceedingsofthe7thConferenceonNaturalLanguageLearningatHLT-NAACL2003-Volume4.AssociationforComputationalLinguistics, 2003: 25-32.
[7]HatzivassiloglouV,WiebeJM.Effectsofadjectiveorientationandgradabilityonsentencesubjectivity[C]//Proceedingsofthe18thConferenceonComputationalLinguistics-Volume1.AssociationforComputationalLinguistics, 2000: 299-305.
[8]RiloffE,WiebeJ.Learningextractionpatternsforsubjectiveexpressions[C]//Proceedingsofthe2003ConferenceonEmpiricalMethodsinNaturalLanguageProcessing.AssociationforComputationalLinguistics, 2003: 105-112.
[9]KamalA.SubjectivityClassificationusingMachineLearningTechniquesforMiningFeature-OpinionPairsfromWebOpinionSources[J].InternationalJournalofComputerScienceIssues(IJCSI), 2013, 10(5).
[10] 姚天昉, 彭思崴. 汉语主客观文本分类方法的研究[C]//第三届全国信息检索与内容安全学术会议论文集. 2007.
[11] 叶强, 张紫琼, 罗振雄. 面向互联网评论情感分析的中文主观性自动判别方法研究[J]. 信息系统学报,2007,1(1):79-91.
[12] 林慧恩, 林世平. 中文情感倾向分析中主观句子抽取方法的研究[C]//全国第 20 届计算机技术与应用学术会议(CACIS·2009) 暨全国第1届安全关键技术与应用学术会议论文集 (上册). 广西 南宁. 2009.
[13]YangYiming,PedersenJO.Acomparativestudyonfeatureselectionintextcategorization[C]//Proceedingsof14thConferenceonMachineLearning.Nashville:MorganKaufmannPublishers, 1997: 414-420.
[14] 郭叶. 中文句子情感倾向分析[D]. 北京邮电大学, 2010.
[15] 杨健, 汪海航. 基于隐马尔可夫模型的文本分类算法[J]. 计算机应用, 2010 (9): 2348-2350.
[16] 朱颖. 基于HMM的汉语词性标注及其改进[D]. 太原理工大学, 2011.
Subjective Sentence Recognition Based on Hidden Markov Model
LIU Peiyu1, 2, XUN Jing2, FEI Shaodong2, ZHU Zhenfang3
(1. School of Information Engineering, Shandong Yingcai University, Jinan, Shandong 250104, China;2. School of Information Science and Engineering, Shandong Normal University, Jinan, Shandong 250014, China;3. School of Information Science and Electric Engineering, Shandong Jiaotong University, Jinan, Shandong 250357, China)
The current subjective and objective text classification methods are mainly based on statistical model over the feature lexicon, which didn’t take into account the syntax and semantic relationships between features. The paper proposes a Chinese subjective sentence recognition based on Hidden Markov Model. In this method, seven kinds of subjective and objective features for classification are extracted tagged among each sentence by HMM. The subjective sentences are decided by the importance of features and syntactic structure of sentences. The method is examined in the task of COAE2014 for its effeiciency.
Hidden Markov Model; feature tagging; subjective sentence recognition

刘培玉(1960-),教授,博士生导师,主要研究领域为计算机网络信息安全、自然语言处理。E-mail:liupy@sdnu.edu.cn荀静(1989-),硕士,主要研究领域为文本摘要、中文倾向性分析。E-mail:xunjing311416@163.com费绍栋(1984-),博士,主要研究领域为网络舆情分析#中文倾向性分析。E-mail:124659865@qq.com
1003-0077(2016)04-0206-07
2014-09-10 定稿日期: 2015-03-20
国家自然科学基金(61373148);国家社会科学基金(12BXW040);山东省自然科学基金(ZR2012FM038, ZR2011FM030);山东省优秀中青年科学家奖励基金(BS2013DX033)
TP391
A
