藏文字形结构分布研究
2016-05-03才智杰才让卓玛
才智杰,才让卓玛,2
(1. 青海师范大学 藏文信息处理省部共建教育部重点实验室,青海 西宁 810008;2. 陕西师范大学 计算机科学学院, 陕西 西安 710062)
藏文字形结构分布研究
才智杰1,才让卓玛1,2
(1. 青海师范大学 藏文信息处理省部共建教育部重点实验室,青海 西宁 810008;2. 陕西师范大学 计算机科学学院, 陕西 西安 710062)
字是语言文字的基本组成单位,字形结构统计研究是自然语言处理的基础,为字属性分析、输入法设计、排序、语音合成和字符信息熵研究等提供理论依据。该文通过分析藏文字形结构的特征,对藏文字的字形结构分成独体字和合体字,合体字按其构件的结构位和所含构件数进行分类。设计了藏文字形结构统计系统模型和算法,从约含8 500万藏文字的450M语料中对藏文字形结构进行统计,建立了藏文字形结构分布统计表,并对统计结果进行了分析。
中文信息处理;字形结构;独体字;合体字;频度统计
1 引言
语言是人类重要的交际工具,字是语言文字的基本组成单位,字形结构及分布研究是自然语言处理的基础,为自然语言处理中字属性分析、输入法设计、排序、语音合成和字符信息熵研究等提供理论依据[1-2]。不同语言的字属性分析有不同的侧重点,英语重点研究单词的构造[3-5];汉语言文字学以汉字为研究对象,研究汉字的起源、创制、发展、性质、造字法、正字法、形体与音义的关系、文字的改革和演变等。现代汉字学以定量、定形、定音、定序这“四定” 为核心研究其属性,发表了一系列学术论文,出版了一批现代汉字的通论性著作和有关现代汉字及信息处理方面的论著。苏培成教授的《现代汉字学纲要》[6]中详细叙述了现代汉字的分布、字量、构形法、构字法、音、字序、熵和多余度及现代汉字的规范化等内容。表明现代汉字结构、构字及分布等属性研究已取得很多成果[7-9]。藏文字形结构研究是藏语自然语言处理的基础,近年来随着藏语语料库规模的不断增大和藏语语料库建设技术的发展,为藏文字形结构研究奠定了基础,也使藏文字形结构研究变为可能。在藏文字形的结构及分布方面研究最早的报道见文献[10],文章通过采集常用词语30 428条,经处理得3 926个常用藏文字,以此为对象研究了藏文字的字长和构词频度、声母和韵母结构方式及频度,同时对藏文字的位置字符及结构方式做了简要分析;文献[11]对《中华大藏经·丹珠尔》(藏文)中的藏文字及构件频度进行了统计;文献[12]对藏文字做了字频、音节频度的统计,简单讨论了字丁熵值、音节的相对熵值和绝对熵值;文献[13]统计了19 380个藏文字的字长、字符频度及结构方式;文献[14] 通过建立现代藏文字属性分析字表库,设计了现代藏文字属性分析系统模型;文献[15]通过大规模藏语语料对藏文基本构件分布进行了统计分析;文献[16] 通过对藏文词典的统计,计算了现代藏文字在藏文中的使用频度,并对藏文字部件和字丁进行了分析,得出了藏文字构字方面的特征,同时依据藏文字声母和韵母的结构方式进行了统计。以上文献虽然从不同角度研究了藏文字、构件的分布,但存在两点缺憾: 一是对藏文字形结构及分布没有深层次研究,只是在藏文字分布统计时附带的讨论了字形结构,因而没能很好地反映字形结构分布规律;二是由于前些年藏语语料规模较小,分布统计普遍是静态的,动态统计的文献中所用语料要么是专用语料,要么规模很少,不具有一般性。针对以上缺憾本文借鉴汉语字形结构及分布统计的研究成果,通过收集整理政治、经济、文学、艺术、宗教、哲学、史学、科学技术和教材等领域的450M约含 8 500万藏文字的语料,深入全面地分析了藏文字结构特征,对藏文字形结构进行了分类,进而给出了藏文字形结构分布统计模型及算法,建立了藏文字形结构分布统计表,并对统计结果进行了分析。
2 藏文字形结构特征及分类
2.1 藏文字形结构特征
文字的性质是这种文字区别于其他文字的本质特征,是分析研究这种文字的基础。藏文字作为藏族人民的书面交际工具,自创制至今进行了三次较大规模的厘定,制定了详实的现代藏文文法,使藏语言文字步入了规范化的轨道[17]。符合现代藏文文法的藏文字称现代藏文字(没有特殊说明时本文所提藏文字都指现代藏文字)。字形是指字的形状、结构,藏文字形以一个辅音字母为核心,其余字母以此为基础前后附加和上下叠加组合成一个完整的字表结构,是一种由字母组成的拼音文字,如图1所示。字母包括30个辅音字母和四个元音字母,核心辅音字母叫“基字”,加在基字前的字母叫“前加字”,加在基字上面的字母叫“上加字”,加在基字下面的字母叫“下加字”,加在基字后面的字母叫“后加字”,后加字之后的字母叫“又后加字”。由此可见藏文字最少有一个辅音字母,最多含六个辅音字母,元音字母则加在基字的上或下,最多有一个。30个辅音字母中有十个可做后加字,后加字中的五个又可做前加字,两个可做又后加字。故藏文字结构上由基字、前加字、上加字、下加字、后加字、又后加字及元音组成,它不仅具有横向拼写性,同时也具有纵向拼写性,其中前加字、基字、后加字与又后加字横向拼写,而在基字所在的竖直方向上还可由上加字、基字、下加字和元音的纵向拼写[18-19]。
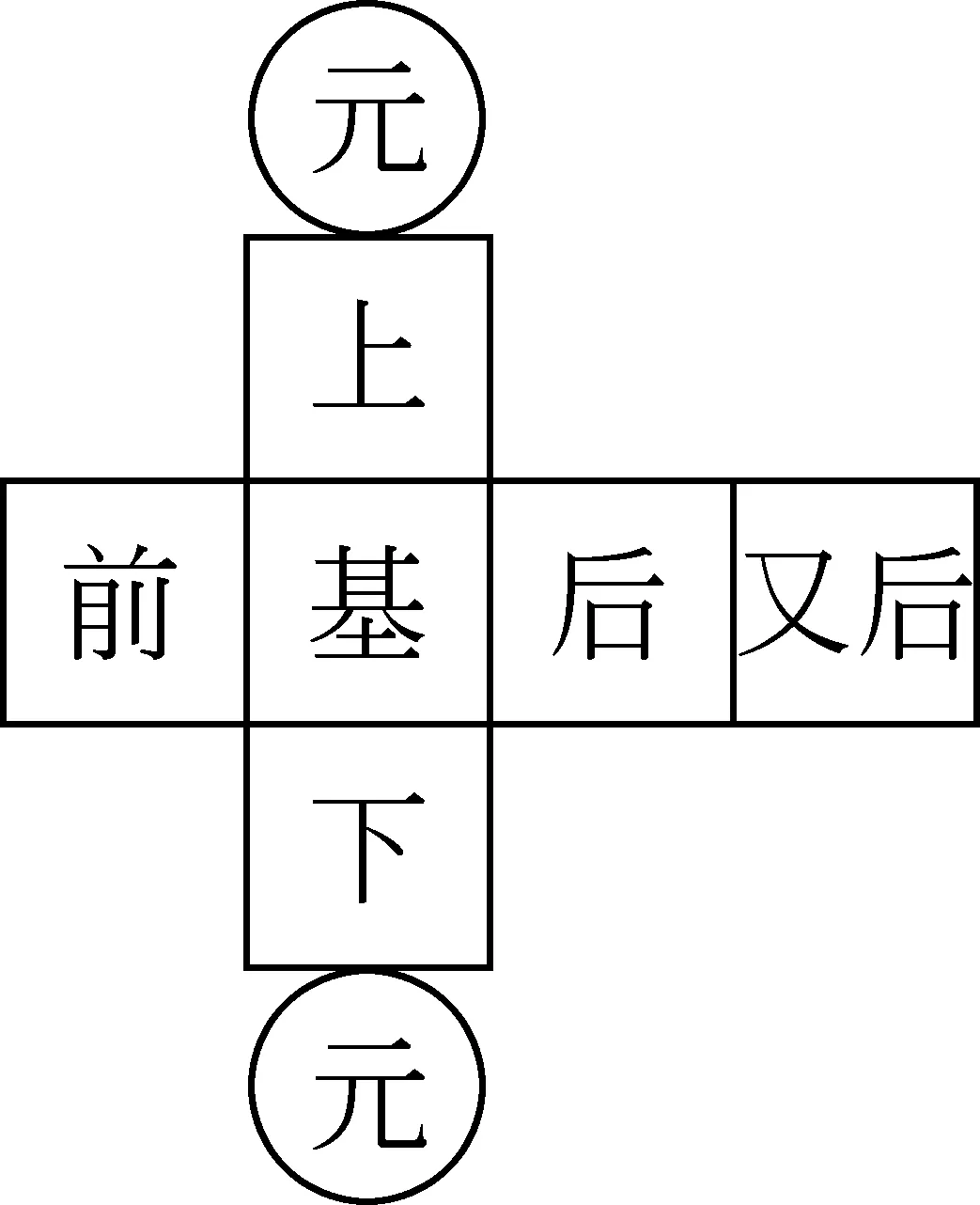
图1 藏文字结构
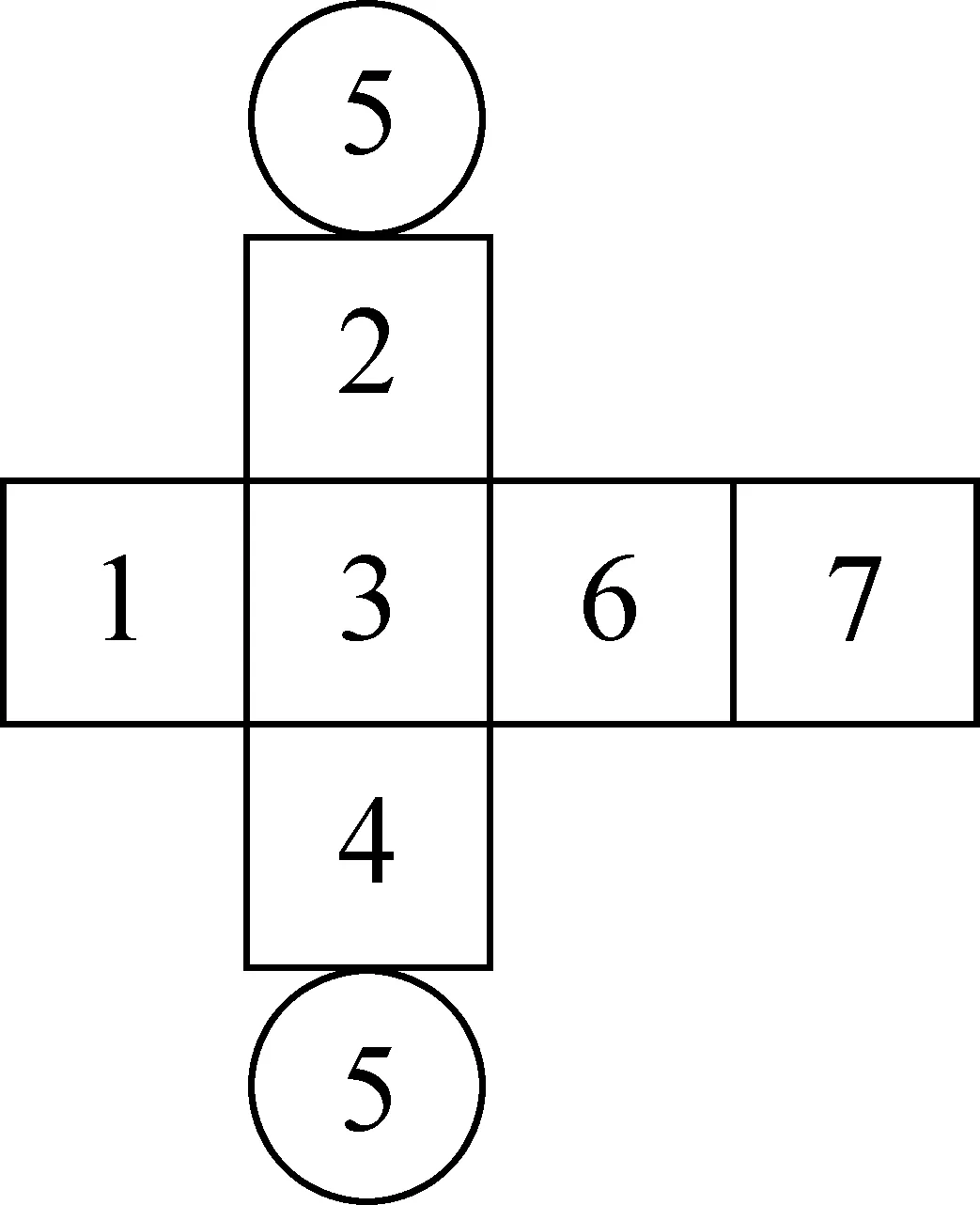
图2 藏文字结构位
藏文字形结构中“前加字”、“上加字”、“基字”、“下加字”、“元音”、“后加字”和“又后加字”的位置称做结构位,分别用1-7表示(图2)。藏文文法中对各个结构位上能出现的字母及其性质与数量均有一定的限制,相互之间也形成一种约束关系。结构位上的每个字母称为基本构件(Basic Component),在基字所在位置由基字和上加字或下加字或元音至少两个基本构件上下叠加而成的构件叫组合构件(Combinational Components)。因此,藏文字构件有基本构件和组合构件两种,其中基本构件一定是辅音字母(前加字、上加字、基字、下加字、后加字和又后加字)或元音字母,显然基本构件是原子类型;组合构件由上加字、基字、下加字和元音在基字所在位置上下叠加组合而成,可进一步分解为基本构件,一个藏文字中至多有一个组合构件。
从以上讨论可得藏文字形结构特征: 1)藏文整字是指藏文字中单个的字,是藏文字的使用单位,字与字间用字分隔符“.”分隔;2)藏文字是具横向拼写和纵向拼写的二维拼音文字;3)整字由构件组成;4)藏文字的构件包括基本构件和组合构件;5)藏文字的基本结构单位是基本构件,即30个辅音字母和四个元音字母。
2.2 藏文字形结构分类
字形结构包括字的内部结构和外部结构。内部结构研究字的字形、字音和字义三者之间的关系,是揭示字形和字义之间的联系;外部结构单纯研究字的外观结构,分析一个字如何由最小的构形单位逐层组合成完整的字,包括组合成分和组合模式,不涉及字音、字义及构字的字理。本文从外部结构角度研究藏文字的字形结构及分布。
藏文字的组合成分为构件,构件组合成整字,整字可分解为构件。将藏文字拆分为构件的过程叫构件分解,构件分解分为层次分解法和平面分解法。层次分解法指逐层拆分藏文字的构件,最后得到基本构件;平面分解法指一次拆分出基本构件。一般来说,一个字只要由三个以上的构件组成,其组合就有层次问题,拆分就要考虑到层次性,平面拆分要以层次拆分为基础。根据层次的不同,各个层级的构件分别叫一级构件、二级构件、三级构件等等,最后一个层次的构件叫末级构件,也就是基本构件。藏文构件自动分解方法见文献[20],藏文字层次拆分遵循如下规则。
(1) 分隔沟是构件和构件分界的显著标志,构件间沿着分隔沟进行划分;
(2) 分隔沟有多条时,长优先拆分,分隔沟长度相等一次多分;
(3) 层次拆分要符合藏文字结构的基本类型,不能破坏基本类型;
(4) 含有多层次部件的整字从大到小拆分,得到的部件叫做一级构件、二级构件、三级构件等,最小的不能再拆分的部件为基本构件。
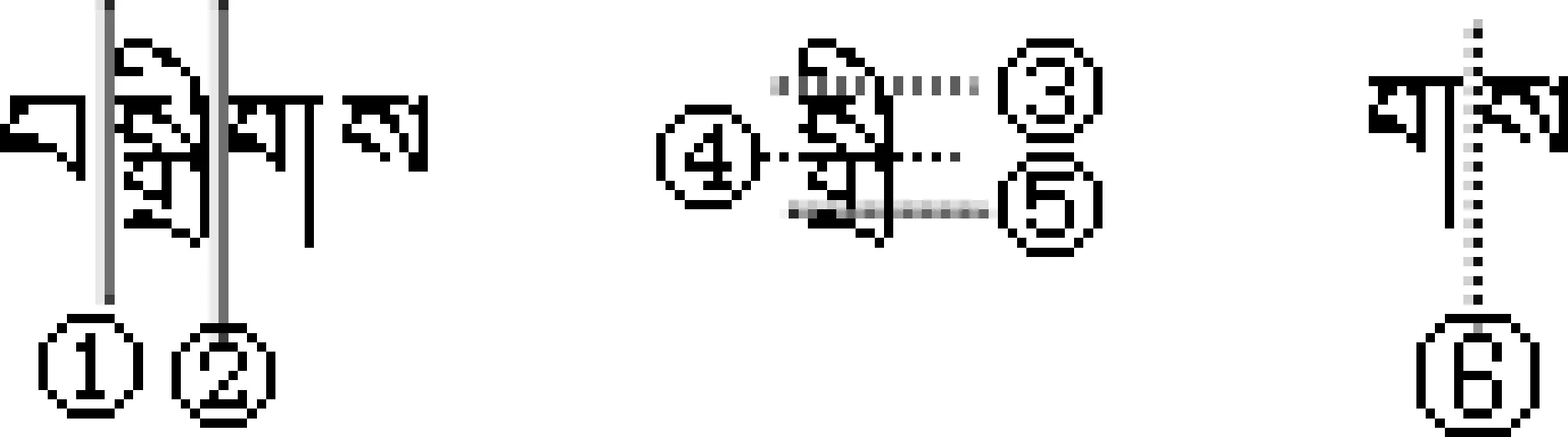
图3 藏文字拆分示例图
藏文字按其由单一基本构件或多个基本构件组成分为独体字和合体字。藏文独体字只有30个,即30个辅音字母都可成独体字;合体字中构件的组合方式多种多样,汉字合体字以构件位置特征和构件个数分为第一级构件组合模式和基本构件组合模式两种,按第一级构件组合模式将汉字合体字分成四大类13小类,按基本构件组合模式将汉字合体字分为八大类85小类[6]。英语是只有横向拼写的拼音文字,不注重字形结构。藏文字具有横向拼写性和纵向拼写性,而且构件结构位很明确,因此参照汉字组合模式的方法分析藏文字字形结构合适、可性。
第一级构件组合模式是按字中构件的结构位分类,由2.2节分析可知,藏文字中构件的结构位非常分明,只有左右和上下结合,因此按第一级构件组合模式可将藏文字形分为左右结构和上下结构两大类。左右横向结合时最多有四个构件,所以左右型可分为左右型、左中右型、左中中右型等三种;上下纵向结合时也最多有四个构件,所以上下型又可分为上下型、上中下型、上中中下型等三种。故在第一级构件组合模式下可将藏文字形分为两大类六小类,见表1。
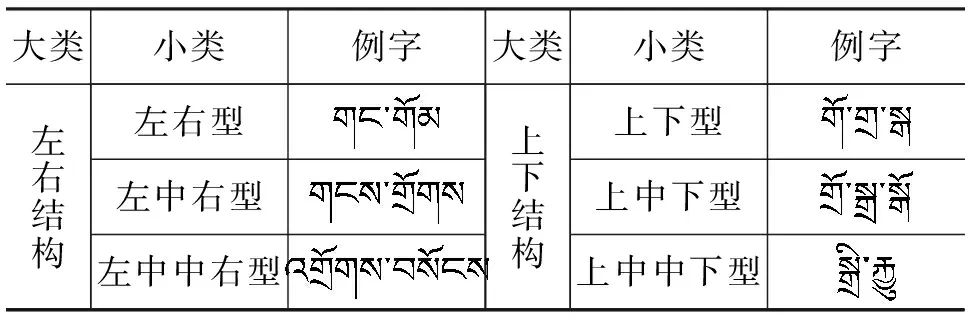
表1 第一级构件组合模式下藏文字形结构分类表
基本构件组合模式是按字所含构件数进行分类,按组成藏文字构件数分类时,有两种情况,一是将组合构件不分解而看成一个整体构件,此时藏文字形结构称为粗粒度藏文字形结构(Coarse Granularity Structure);二是将所有构件都分解为基本构件,此时的藏文字形结构称为细粒度藏文字形结构(Fine Granularity Structure)。在粗粒度藏文字形结构中,一个藏文字最多有前加字、组合构件、后加字和又后加字等四种构件,因而基本构件组合模式下粗粒度藏文字形结构可分为四大类六小类,见表2。在细粒度藏文字形结构中,藏文字的基本构件最少有一个,最多有七个,因而基本构件组合模式下细粒度藏文字形结构可分为七大类48小类,见表6。

表2 基本构件组合模式下粗粒度藏文字形结构分类表
3 藏文字形结构频度统计系统模型
3.1 系统模型
藏文字形结构频度统计系统包括语料处理模块、字处理模块和字形频度统计模块。其中,语料处理模块是收集、整理、加工藏语语料库,通过规范化语料得到机器直接可读的文本;字处理模块的功能是读取文本,从读取的文本中识别每个藏文字,并对藏文字进行校正、紧缩词分离使之得到规范藏文字,最后进行藏文字构件分解;频度统计模块用于藏文字形频度统计、统计归类,从而建立不同字形结构的统计表,得到统计分析表,系统模型如图4所示。

图4 藏文字形结构统计系统模型
3.2 统计算法
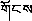
藏文字字形频度统计算法(Character Pattern Frequency Statistics Algorithm, CPFA) While(not eof(File)){ Step0:初始化字形向量 a[1..7]=0; step1:读入文本 Text=Read (File); step2:识字 s=WordRecognise(Text); //将规范藏文字存入s step3:构件分解 wordDecompose(s,a);//通过分解字S设置向量a的值 step4:字形结构频度统计 if(a[i] isΣ) //根据向量a的分量确定字形 count (Σ_DB);//相应字形结构累加1 Step5:输出统计结果 Output(Σ_DB);} 其中,Σ表示根据向量a的分量确定字形的规则,Σ_DB表示相应字形频度统计库
4 藏文字形结构分布统计及分析
字形结构分布由其频度反映。频度统计有动态统计和静态统计两种,静态统计以字典、词典中字为统计对象,动态统计以语料中字为统计对象,统计语料中实际使用的字在样本里出现的次数,并且计算出它在全部样本字数中所占的比例,如式(1)所示。
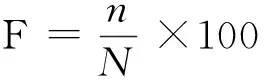
(1)
其中,F表示频度,n表示某字的出现次数,N表示抽样资料总字数。
本文在450M藏语语料中采用动态统计方法进行统计,共出现84 584 110个藏文字,不同的藏文字共出现42 966个。独体字共出现30个(30个辅音字母都以独体字的形式出现),出现总次数为5 314 860,占总字数的6.28%;合体字共出现6 290个,出现总次数为79 269 250,占总字数的93.72%,从而可见藏文字以合体字为主。独体字和合体字分布统计见表3和图5。

表3 藏文独体字和合体字分布统计表
在第一级构件组合模式下,大类左右结构共出现66 077 106次,占藏文总字数的78.12%,其中小类“左右”型占51.89%,小类“左中右”型占24.04%,
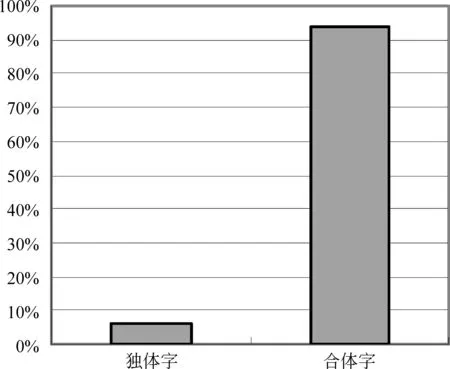
图5 藏文独体字和合体字分布统计图
小类“左中中右” 型占2.19%;大类上下结构共出现18 507 004次,占藏文总字数的21.88%,其中小类“上下”型占15.88%, 小类“上中下”型占4.98%,小类“上中中下”型占1.02%。从而可见,“左右”型是第一级构件组合模式下藏文字的主要组成形式,达到了整个藏文字数的一半,“左中右”型和“上下”型所占比例基本相同,“左中中右” 型、“上中下”型和“上中中下”型出现的较少。第一级构件组合模式下藏文字形结构分布统计见表4和图6。

图6 第一级构件组合模式下藏文字形结构分布统计图

大类频率/%小类频率/%大类频率/%小类频率/%左右结构78.12“左右”型51.89“左中右”型24.04“左中中右”型2.19上下结构21.88“上下”型15.88“上中下”型4.98“上中中下”型1.02
在基本构件组合模式下的粗粒度藏文字形结构中,二构件字共出现39 940 617次,占总字数的47.22%,约占到所有藏文字的一半,其中“组+后”型占42.78%,是基本构件组合模式下粗粒度藏文字形结构的主要形式;一构件字和三构件字分别占总字数的28.85%和21.86%,四构件字只占2.07%。基本构件组合模式下粗粒度藏文字形结构分布统计表见表5和图7。
在基本构件组合模式下的细粒度藏文字形结构中,一构件字占13.04%,二构件字占27.79%,三构件字占31.53%,四构件字占21.42%, 五构件字占5.65%, 六构件字占0.53%, 七构件字占0.04%。

图7 粗粒度藏文字形结构分布统计图

大类频率/%小类频率/%大类频率/%小类频率/%一构件字28.85二构件字47.22“单组合构件”型28.85“前+组”型4.44“组+后”型42.78三构件字21.86四构件字2.07“前+组+后”型15.11“组+后+又后”型6.75“前+组+后+又后”型2.07
可见,二构件、三构件和四构件是基本构件组合模式下的细粒度藏文字形结构的主要形式。基本构件组合模式下细粒度藏文字形结构分布统计表见表6和图8。
表6 基本构件组合模式下细粒度藏文字形结构分类及分布统计图
续表
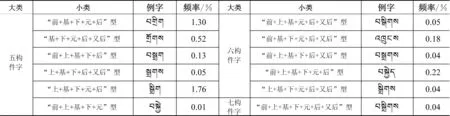
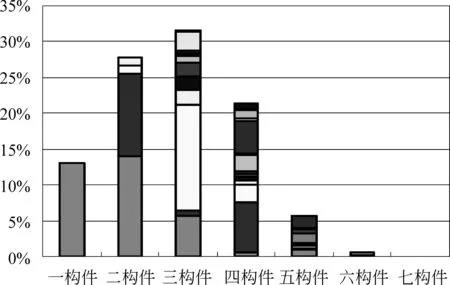
图8 细粒度藏文字形结构分类及分布统计图
综上统计及分析可得藏文字形分布具有四条规律: 一、从藏文字的构成方面看,藏文字以合体字为主,合体字是藏文字的主要构成形式;二、从藏文字结构方面看,藏文字以左右结构为主,“左右”型是藏文字的主要结构形式;三、从所含构件角度看,在粗粒度度情况下以二构件为主,在细粒度情况下三构件为主,整体而言以“基+后”型和“基+元+后”型为主;四、藏文字的使用频率越高,构成字的构件数越少,字的使用频率越低,构成字的构件越多,字的使用频率和字的构件数成反比,使用频率高的字一般趋向简化。
5 结束语
本文借鉴汉字字形结构的研究成果对藏文字形结构进行了深入研究,将藏文字分成独体字和合体字,对合体字按其构件结构位(第一构件组合模式)和所含构件数(基本构件组合模式)依次进行了分类。第一构件组合模式下藏文字形结构分成了左右型和上下型两大类六小类;基本构件组合模式下藏文字形结构从粗粒度字形结构和细粒度字形两个层面进行了分类,粗粒度字形结构下分成了一构件字、二构件字,三构件字和四构件字等四大类六小类,细粒度字形结构下分成了一构件、二构件、……、七构件字等七大类四十八小类。设计了藏文字形结构分布统计系统模型和算法,从450M大型藏语语料中对藏文字型结构分布进行了统计分析,建立了藏文独体字和合体字分布统计表、第一级构件组合模式下藏文字形结构分布统计表、基本构件组合模式下粗粒度藏文字形结构分布统计表、基本构件组合模式下细粒度藏文字形结构分类及分布统计表,并分析出了藏文字形分布特征。今后在该研究成果的基础上进一步研究藏文字符生成技术和藏文句型分布,为藏文字符信息熵计算、藏文句型结构分布、藏文字符排序、藏语语音合成和藏汉机器翻译研究提供理论依据和数据基础。
[1] 冯志伟.自然语言处理的形式模式[M].北京:中国科学技术大学出版社, 2010.
[2] 陈玉忠,俞士汶.藏文信息处理的研究现状与展望[J].中国藏学,2003(4):97-107.
[3] 俞敏洪.英语词汇速记大全[M].北京:世界知识出版社出版, 2000.
[4] 赵志文.英语语法规律[M].吉林:延边大学出版社, 2002.
[5] 恒星英语[DB/OL]. http://www.hxen.com/word/goucifa/,2013,10.
[6] 苏培成.现代汉字学纲要[M]. 北京:北京大学出版社, 2001.
[7] 中国语言文字网[DB/OL].http://www.china-language.gov.cn/wenziguifan/index.htm,2013,10.
[8] 李乐强,唐常杰,左劼等.基于同现度和自学习的中文字符组合发现[J].计算机研究与发展,2007(z3):268-272.
[9] 李世明,李铮,苑志伟等.基于搜索引擎的模糊字频统计[J].计算机工程与设计,2010,31(2):443-446.
[10] 江荻,董颖红. 藏文信息处理属性统计研究[J].中文信息学报,1994,2(9):37-44.
[11] 扎西次仁.《中华大藏经·丹珠尔》藏文对勘本字频统计分析[J].中国藏学,1997,(2):122-133.
[12] 王维兰,陈万军.藏文字丁、音节频度及基信息熵[J].术语标准化与信息技术, 2004(2):27-31.
[13] 高定国,龚育昌.现代藏文字全集的属性统计研究[J].中文信息学报,2005,19(1):71-75.
[14] 才智杰,才让卓玛.基于语料库的藏文字属性分析系统设计[J].计算机工程,2011,37(22): 270-272.
[15] CaiZhijie,CaiRangzhuoma.Statistical Analysis for Frequency of The Corpus-based Modern Tibetan Basic Components[J].The 4th International Conference on Intelligent Networks and Intelligent Systems,2011,11:214-217.
[16] 艾金勇,于洪志,李永宏.藏文字形结构计量统计分析[J].计算机应用,2009,29 (07): 2029-2031.
[17] 百度百科.藏文[EB/OL].http://baike.baidu.com/view/230052.htm,2013,01.
[18] 才智杰.藏文自动切分系统中紧缩词的识别[J].中文信息学报,2009,23(1):35-37.
[19] 才智杰,才让卓玛.班智达藏文标注词典设计[J].中文信息学报,2010,24(5):46-49.
[20] 才让卓玛,才智杰.现代藏文字构件分解方法[J].青海大学学报(自然科学版),2010,28(4):83-86.
[21] D A Huffman.A Method for the Construction of Minimum Redundancy Codes[C]//Proceedings of IRE.1952,40 (10):1098-1101.
[22] C E Shannon.A mathematical theory of communication[C]//Proceedings of the ACM Sigmobile Mobile Computing and Communications Review.2001.
Research on the Distribution of Tibetan Character Forms
CAI Zhijie1, CAI Rangzhuoma1,2
(1. Key Laboratory of Tibetan information processing, Ministry of Education,Qinghai Normal University, Xining,Qinghai 810008,China;2. College of Computer Science, Shaanxi Normal University, Xi’an, Shanxi 710062, China)
Researching on the distribution of Tibetan character forms is the foundation of Natural languages processing, provides a theoretical basis for word attribute analysis, input design, sorting, speech synthesis and character information entropy studies. This paper classified the Tibetan character forms into single-element character and combined-element character, and further classify the combined-element characer by their artifacts’ structures and numbers. This paper conducts statistical analysis of glyph structure from 85 million Tibetan words in 450M corpus containing, establishes distribution statistics of Tibetan glyph structure.
Chinese information processing; character forms; single-element character; combined-element character; frequency

才智杰(1970-),教授,博士研究生,硕士生导师,主要研究领域为藏文信息处理,藏语自然语言处理。E-mail:czjqhsd@163.com才让卓玛(1970-),教授,博士研究生,主要研究领域为自然语言处理,藏文信息处理,计算智能。E-mail:cr_zhuoma@163.com
1003-0077(2016)04-0098-08
2014-06-09 定稿日期: 2015-04-25
国家自然科学基金(61163018, 61262051, 61363055);国家社科基金(13BYY141);教育部“春晖计划”合作科研项目(Z2012093);“长江学者和创新团队发展计划”创新团队资助项目(IRT1068);青海省科技厅应用基础研究计划基金(2011-Z-755,2011-Z-754);青海师范大学科研创新计划基金资助项目
TP391
A
