基于多维时间序列模型的社会安全事件
2016-04-27关联关系挖掘与预测
关联关系挖掘与预测
孙越恒1, 王文俊1, 迟晓彤2, 宁溥泰1, 邢 磊1
(1. 天津大学计算机科学与技术学院, 天津 300072; 2. 天津大学软件学院, 天津 300072)
基于多维时间序列模型的社会安全事件
关联关系挖掘与预测
孙越恒1, 王文俊1, 迟晓彤2, 宁溥泰1, 邢磊1
(1. 天津大学计算机科学与技术学院, 天津 300072; 2. 天津大学软件学院, 天津 300072)
摘要:近年来社会安全事件频繁发生,给人民群众的生命和财产带来了严重损害。文章基于大规模时序数据,通过挖掘事件触发因素,利用多维时间序列模型量化分析其与社会安全事件发生的关联关系,并对未来事件的发生数量进行预测。另外,提出一种基于态势主导的多维时间序列相似性度量方法,量化分析不同类别事件之间发展趋势的相似程度,并对三类具体的社会安全事件进行相关分析及预测。实验表明,从时序数据角度分析可以很好地挖掘触发事件的隐形因素,并较为准确地估计事件发生数目和事件发展趋势,为管理者预防和控制此类事件的发生提供了一种新的思路和方法。
关键词:社会安全事件; 关联关系挖掘; 多维时间序列
危害社会安全事件近几年来在各地频发,管理者预防此类恶性事件发生的第一步就是分析触发事件发生的原因。除了贫富差距变大、民族矛盾激化等社会原因外,此类事件发生与近年来互联网技术的普及也有极大的关系。互联网使事件消息的传播不再受到空间限制,传播范围越来越广,传播时效性也越来越强,这就可能造成了事件之间的模仿效应,事件与事件之间不再是独立存在,一个事件可能如蝴蝶效应一般触发另一个事件[1]。因此,找到事件与事件之间的关联关系和触发因素对于控制与预防类似事件发生尤为重要。
由于非结构化数据的文本处理困难以及人的思想与情感极强的不确定性,对于由人主导的社会安全事件之间关联关系挖掘还处于起步的定性阶段,量化分析较少,主要集中在对其传播特征的挖掘及应对上[2-3],只有极少的研究分析社会安全事件的发生机理[4]。通过对社会安全事件产生的大量网络数据特征的分析,本文将运用时间序列分析的相关基础研究对事件的关联因素进行挖掘与定量分析。
时间序列是指一串按时间先后顺序排列的而又相互关联的数据序列。时间序列分析就是对这种依赖性关系的挖掘以及根据分析结果对未来某时刻值进行预测的一种分析技术[5],在诸多领域得到广泛应用,例如自然界气象领域中的气象数据,社会经济领域中一个国家的国民生产总值(GDP),物价指数等都可以构成时间序列数据并进行分析[6-7],而时间序列也越来越多地应用于事件的预测中,例如经济领域对于金融事件的预测[8],医学领域对于疾病发病率预测[9]以及医疗事故的时序分析[10]等等。这些都证明时间序列分析方法对于分析具有时序特征的数据较为有效,且应用更加灵活。
当将多个独立发生事件映射到等划分的时间段内观测到的事件数目可形成时间序列数据,不同时间区间发生的同类事件之间可能具有相互依赖或者相关关系,因此采用时间序列分析模型研究事件发生规律是可行的。而当前时间段内的事件发生不仅与此前发生的同类事件本身性质相关,也可能与其带来的附加影响相关,例如前段时间内已发生事件的热度、该事件的传播影响大小以及民众对于事件的情感倾向都可能与此时间段事件的发生有关。为了使分析和预测更加准确,将这些信息作为附加的相关变量形成多元变量,通过多维时间序列分析挖掘同类事件发生的关联因素。对于事件性质不同的异类事件,我们认为事件性质或发生数目可能差别明显,但是其变化趋势却可能相同,因此采取基于态势主导的多维时间序列相似度分析,通过态势距离衡量异类事件发展趋势的相似程度,为进一步分析异类事件关联关系做铺垫。具体内容包括:1)定义并抽取事件相关因素;2)挖掘同类事件之间的关联因素并预测;3)不同类别事件的相似度分析。
一、 模型基本概念定义
1. 相关定义
定义1:时间间隔。时间间隔是模型分析最基本的观测时间单元,记作τ。所有观测数值在基本时间间隔内观测获得,以基本时间间隔做切分。定义整体观测时间段的起始和终止时间点为ts与te,整体时间被划分成n个时间段,其中n=(te-ts)/τ。
定义2:阶段事件发生数目。事件性质的量化数值用事件数目代表,阶段事件数目指单位时间间隔内该类别事件发生的数目。第i个时间段内事件发生数目定义为Yi,其中i=1,2,…,n。这是观测向量中最重要一维观测数据,既属于观测影响因素,又属于被影响因素。
定义3:阶段影响因子。一个时间段内一类事件发生而产生的影响中引起下一阶段同类事件发生的影响因子称为此类事件的阶段影响因子。本文定义了两个危害社会安全事件的阶段影响因子,分别为阶段事件热度与阶段情感倾向,前者指此阶段事件的发生引起的社会关注与民众讨论的热烈程度,后者指此阶段民众对该类事件的发生的态度与情感倾向,例如赞同、支持、反对或者愤怒等等。定义第i个时间段内事件热度与民众情感倾向分别为Hi与Ei。
定义4:多维时间序列。多维时间序列指连续时间间隔观测到的事件多维序列数据。第i个时间段内的事件发生数目Yi及附加影响因子事件热度Hi和民众情感倾向Ei组成第i个时间间隔内的观测向量Ai=
2. 影响因子抽取
当前网上事件发布渠道主要包括权威资讯网和热门微博,这些网络媒体或传播平台使得公众言论更加开阔,可追溯性也越来越强。我们选取这两类传播媒体,通过消息的传播路径,量化事件的阶段热度以及阶段情感倾向。
(1) 阶段事件热度。计算热度的意义是能够对话题的被关注程度有一个量化的、直观的表示,以便可以将热度因素考虑进入模型中,实际热度值最终呈现在模型中只是转化为话题之间关注度比例的问题,而不局限在其量化值本身。因此选取最简单最常用的加权法进行话题热度计算。
基于已有的数据集,从资讯网来源量化事件热度,选定资讯网网媒集合M,对于资讯网m,根据发布事件的资讯网的网媒权重km、对于事件j的新闻总报道数目Qmj,发布的所有新闻报道中民众的评论量数量Cmj,点赞数量Amj的量化值,通过资讯网传播因子结合式(1)得到资讯网传播的事件热度为
(1)
从微博传播的角度衡量事件热度,选定微博号集合W,对于微博号w,根据事件发布源的意见领袖权重lw以及民众参与量Qwj的量化值,通过微博传播因子结合式(2)得出微博传播的事件热度为
(2)
定义事件j的事件热度hj定义为zhj与whj之和。定义J类事件在第i个时间段内的阶段事件热度为
(3)
(2) 阶段情感倾向。同话题热度类似,情感倾向的计算只是为反应民众当前阶段的整体情感,该量化值最终也会转化成为模型中的不同阶段情感比例,而不局限在其量化值本身。因此,我们用最简单的某类情绪占比来标识阶段情感倾向即可。
民众对社会安全事件的情绪复杂多样,可以根据其激烈程度分成多个等级。为方便计算,在此只将情绪分为两类:积极情绪和消极情绪。积极情绪是指激动、兴奋、有正义感,这种情绪可能会抑制此类事件再次发生;而消极情绪是指言辞激烈,甚至有可能引发冲动性的行为,这种情绪则可能导致此类事件再次发生。将阶段情感倾向量化为积极情绪所占比例,分析其与下一阶段该类事件发生的关系。定义在第i个时间段内对J类事件的积极情感数目为PosiJ,消极情感数目为NegiJ。
因此,J类事件在第i个时间段内的阶段事件情感倾向为
EiJ=PosiJ/(PosiJ+NegiJ),iτ≤tj<(i+1)τ
(4)
二、 模型建立
1. 假设
假设当前时间段内事件的发生会与过去p个时间段内发生的事件成线性关系,且不仅与之前时间段内发生的事件性质相关,也与其阶段事件热度以及阶段情感倾向相关。
2. 多维时间序列模型
观测到的时间序列为{A1,A2,…,An},其中At代表第t个时间段的观测向量,观测向量包含第t个时间段内事件发生数目Yi,第t个时间段阶段事件热度Ht与阶段民众情感倾向Et三个维度。假设当前时间段内事件的发生与过去p个时间段内观测向量成线性关系,通过一维时间序列ARp阶线性时间反演时序模型扩展对多维时间序列的关联关系进行定量分析。设定模型阶数为p,令t=p+k(k=1,2,…,n-p),则模型表示为
(5)
式中:δ为误差向量,记作δ=[δp+1,δp+2,…,δn]T;β为关联参数向量,即与每一维度属性相关程度,记作β=[β1,β2,…,βp]T。
将观测向量用矩阵表示为
Z=[Ap+1,Ap+2,…,An]T
则多维时间序列关联模型可以表示为
Z=βX+δ
(6)

βLS=(X′X)-1X′Z
(7)
3. 基于态势主导的多维时间序列相似性度量模型
基于态势主导的多维时间序列相似度度量的假设基础是:不同的多维时间序列其各维度所在量级也许不同,但其变化趋势可能会相同。也就是说,不同类型事件的事件性质的体现可能不同,但是其事件的变化趋势也许相同。对于给定的两个观测向量A,B,通过计算它们之间的态势距离DS(A,B)来衡量两个序列发展趋势的相似程度。
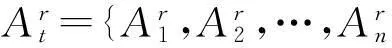
每个时间段内的态势值设定为三个,上升态势用“1”表示,平稳态势用“0”表示,下降态势用“-1”表示。即t时间段内r维度态势值表示为
(8)
则观测向量A,B的态势距离定义为对应时段间的平均距离为
(9)
A,B的态势距离DS(A,B)越小,表示A,B发展趋势越相近。
三、 实验设计与结果分析
1. 数据集介绍
本实验数据集由“第二届中国大数据技术创新大赛”协办单位“海量智能数据技术有限公司”提供,数据类型为互联网媒体报道和UGC用户生成数据,训练集主要提供资讯和微博两类数据,其时间跨度为2011年4月至2014年4月共三年,数据量为55万条左右。由于选择的资讯网和微博较为权威和全面,因此分析结果基本可以代表事件在网络传播的实际情况,进而反应实际事件发生的规律。
数据集共包含三类危害社会安全事件,分别为:公交车爆炸事件数据,暴力恐怖事件数据和校园砍伤事件数据。数据集提供字段主要包括资讯和微博的发布时间、标题、正文、摘要、原始出处、是否原创、评论量、转发量、正文分词等信息。微博人物资料信息,包括性别、生日、等级、粉丝数、个人标签等。
2. 实验步骤
(1) 事件提取。基于上述数据集,数据预处理步骤包括数据去重与事件提取。数据去重基于数据库的前缀索引特点,以时间、媒体源和报道题目的前70个字符为索引去掉本质相同的数据记录,去重的准确率达到98.8%。事件提取采用人工标注事件与训练文本分类相结合的方式,提取独立事件以及事件相关的新闻报道和微博发布。由于突发事件数量并不多,人工标注事件的方法可行且准确。通过标注事件利用TF-IDF方法[11]进行人名、地名向量提取,并结合余弦相似度的计算提取同个事件相关的资讯和微博内容。在反复人工标注、修正的迭代下,获得了很好的事件提取效果。
(2) 时间间隔选取。由于危害社会安全事件的发生相对来讲并不频繁(例如暴恐事件可能三个月或者半年发生一次),观测数据较为稀疏,因此,将时间间隔尽量扩大,保证数据的可观测性。这里取时间间隔即基本数据观测单元τ为3个月,所有观测数据统计与计算都以3个月为间隔进行。整体时间跨度为2011年4月至2014年4月三年,因此共有12个时间间隔,即n=12。
(3) 影响因子抽取与向量构建。事件发生数目向量构建:通过人工标注事件,对三类危害社会安全事件进行事件提取,提取的事件数目按3个月为时间间隔进行统计。
阶段事件热度向量构建。热度计算需要考虑资讯网报道的媒体权重与微博报道的意见领袖权重。我们采用HITS算法思想[12],基于“数量假设”与“质量假设”两点计算资讯网各网媒权重,而微博意见领袖权重的计算依据其微博用户自身性质(粉丝数、等级)进行分级评估设定。通过对单个事件相关报道以及微博转发评论数量的提取,结合资讯网媒和微博意见领袖权重,根据式(1)~(3)以时间间隔τ=3分别计算12个间隔的阶段事件热度。
阶段情感倾向向量构建。情感倾向分析的限制关键在于文本的信息抽取。利用情感词典(董振东HowNet)以及总结的微博表情词典,将待分析的资讯评论与微博评论转发文本通过开源分词软件进行文本分词,并将分词结果与情感词典比较,根据两类权值计算每个文本的情感倾向。最后根据式(4)计算与某个事件相关的所有评论的正面情感比例,即事件情感倾向。
3. 实验结果与分析
(1) 事件影响因素挖掘。根据以上分析与计算,得到以3个月为时间间隔的观测向量。以“校园砍杀”类型事件为例,其观测向量三个维度如表1所示。
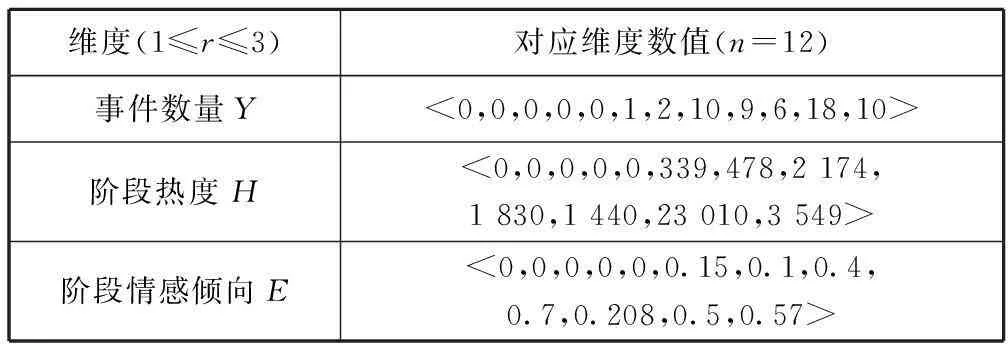
表1 “校园砍杀”事件观测向量
观察数值呈上升趋势,因此要进行数据去趋势平稳化,此处采用对数线性去趋势平稳化方法。由于要考虑三个维度中每个维度对于事件发生的贡献比例,因此对数据进行归一化使其在同一量级上更便于我们分析结果。同时,观察到前5个时刻事件发生数量为0,无法采集相关的事件报道评论以及微博传播报道。因此,向量从第6时刻开始截断。将多维观测向量输入模型求得参数向量结果如表2所示。

表2 相关系数
以“校园砍杀”类型事件为例,β=[2.729 1,1.533 7,-0.983 1],模型阶数p=1。表明校园事件的发生和前一个时间段,也就是前三个月内此类事件的发生相关。其中,与其事件本身性质(事件发生规律)关系度为2.729 1最大。另外,此类事件的事件热度与事件发生成正比关系(1.533 7),也就是说事件,被讨论越多,传播越广,越有可能导致更多该类事件的发生,可以理解为很多人也许会受到已经发生的该类事件的影响而去效仿。第三个维度参数小于0表明,事件发生与民众正情感的比例成反比,如果民众的态度较为积极向上,则会抑制此类事件发生,但是效果并不明显。
根据参数β与阶数p以及历史值,可以预测下一个时间段即2014年4月~2014年6月内校园砍伤事件发生的数目为13,根据实际的网络统计数据统计下三个月内的校园砍杀事件数目为15, 综合另两类事件训练集的预测误差在15.6%左右。由于无法预测出具体可能发生的事件内容,而仅能预测事件发生数目,因此仅可以根据历史相关数据判断未来事件发生趋势,为管理者针对当前事态变化和民众情绪提供下一步管理的方向指示和紧急预警。
(2) 事件相似度衡量。根据三类事件观测向量每个时间段的变化趋势确定其态势向量。三类事件以数量维度上的态势向量为例,如表3所示,对应态势图如图1所示。

表3 事件发生数量维度态势向量

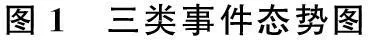
通过计算三个维度态势向量,计算三类事件的多维时间序列的态势相似度,结果如表4所示。

表4 三类事件态势相似度
从模型可以得知,某类事件时间序列的态势指其各时间段内发生数目、事件热度以及民众情感倾向整体的状态。两个时间序列的态势距离越小,说明其形态越相近,两类事件整体趋势越接近。
通过事件的态势相似性距离可以看出,校园砍杀与暴力恐怖类型的事件态势距离为1.189,最为相近,也就是说这两类事件的发展趋势最为接近,这可能由于两类事件都是由人的主观意识控制造成,事件传播极可能引起人的效仿,导致模式相近。而公交爆炸事件与暴力恐怖事件和校园砍杀事件的态势距离相对来说较远,分别为1.745和1.897,这可能由于公交爆炸事件多是天气原因自燃或者极少意外引发的。
四、 结语
本文提出了一种新的思路来量化分析社会安全事件的发生,假设此类事件的发生不仅与其事件性质有关,还受一些附加因素影响。将事件本身与附加因素映射至多个时间段内,形成多维时间序列进行关联关系分析,挖掘出可能影响事件发生的因子。并通过事件的态势相似度分析不同类别事件的发展趋势相似性,为控制和预防危害社会安全事件发生提供了新的思路和方法。但是,由于非结构化文本处理困难,影响因子提取的准确性无法估测。因此,未来的工作我们更多地要对定义的影响因子进行评估并优化影响因子的提取过程,同时将事件的关联关系由线性向非线性进行扩展。
参考文献:
[1]韩立新, 霍江河. “蝴蝶效应”与网络舆论生成机制[J].当代传播, 2008 (6):64-67.
[2]陈虹, 沈申奕. 新媒体环境下突发事件中谣言的传播规律和应对策略[J].华东师范大学学报:哲学社会科学版, 2011, 43(3):83-91.
[3]刘铁民.危机型突发事件应对与挑战[J]. 中国安全生产科学技术, 2010, 6(1):8-12.
[4]朱正威, 胡永涛, 郭雪松. 基于尖点突变模型的社会安全事件发生机理分析[J]. 西安交通大学学报:社会科学版, 2011, 31(3):51-55.
[5]Chatfield C.TheanalysisofTimeSeries:AnIntroduction[M]. Boca Raton: CRC press, 2013.
[6]钞小静, 任保平. 中国经济增长质量的时序变化与地区差异分析[J]. 江苏商论, 2014 (27):26-40.
[7]Engle R F. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation[J].Econometrica:JournaloftheEconometricSociety, 1982, 50(4): 987-1007.
[8] 白旻. 金融时间序列数据预测方法探析[J]. 商业时代, 2012 (21):80-81.
[9] 罗静, 杨书, 张强, 等. 时间序列ARIMA模型在艾滋病疫情预测中的应用[J]. 重庆医学, 2012, 41(13):1255-1256.
[10] Schaffer A, Muscatello D, Broome R, et al. Emergency department visits, ambulance calls, and mortality associated with an exceptional heat wave in Sydney, Australia, 2011: A time-series analysis[J].EnvironHealth, 2012, 11(1): 273-279.
[11] Sparck Jones K. A statistical interpretation of term specificity and its application in retrieval[J].Journalofdocumentation, 1972, 28(1): 11-21.
[12] Gibson D, Kleinberg J, Raghavan P. Inferring web communities from link topology[C]//ProceedingsoftheNinthACMConferenceonHypertextandHypermedia. Pitsburgh: ACM Press, 1998: 225-234.
Correlation Mining and Prediction of Social Security Events Based on
Multi-dimensional Time Series Model
Sun Yueheng1, Wang Wenjun1, Chi Xiaotong2, Ning Putai1, Xing Lei1
(1. School of Computer Science and Technology, Tianjin University, Tianjin 300072, China;
2. School of Computer Software, Tianjin University, Tianjin 300072, China)
Abstracts: In recent years the frequentoccurring of social security events has led serious damage to masses’ life and property security. Based on large-scale time series data, this paper quantitatively analyzes the correlation between the trigger factors and the happening of social security events, then predicts the number of security events that may happen in the future. In addition, this paper presents a multi-dimensional time series similarity measurement method which is based on situational dominant, trying to quantitatively analyze the similarity of development tendency among different kinds of events, and make correlation analysis and predictiontowards three kinds of specific social security events. The experiment result shows that time series analysis can well mine the invisible trigger factorsand accurately estimate the number and tendency of public security events’ happening. It can provide a new thought and method for administrators to prevent and control the happening of these kinds of events.
Keywords:social security events; correlationmining of events; multi-dimensional time series
中图分类号:G350.7
文献标志码:A
文章编号:1008-4339(2016)02-097-06
通讯作者:王文俊, wjwang@tju.edu.cn.
作者简介:孙越恒(1974—),男,讲师.
基金项目:国家社科基金重大资助项目(14ZDB153);教育部人文社会科学研究基金资助项目(13YJC870023).
收稿日期:2015-04-27.
