一种基于神经网络的人脸图像超分辨率重构算法
2016-04-22高志荣蓝雯飞
高志荣,蓝雯飞
(中南民族大学 计算机科学学院,武汉 430074)
一种基于神经网络的人脸图像超分辨率重构算法
高志荣,蓝雯飞
(中南民族大学 计算机科学学院,武汉 430074)
摘要提出了一种基于神经网络的超分辨率重构算法.首先用基于l1范数的最小全变分约束对输入的低分辨率图像进行去模糊处理,得到初始复原图像;再根据结构相似度原则选择初始复原图像在训练集中最相近的M幅图像,并加权求和作为神经网络的初始输出;结合贝叶斯后验概率,用RBF神经网络进行迭代训练,最后输出复原的高分辨率图像.算法充分利用了不同人脸图像之间的相似性,并加入了最小全变分约束,以保持图像边缘的奇异性及非边缘的平滑性.实验结果表明:算法能有效提高下采样及模糊人脸图像的分辨率,具有一定的实用价值.
关键词人脸图像;超分辨率;最小全变分;结构相似度;径向基函数
Neural Network Based Super Resolution for Face Image
GaoZhirong,LanWenfei
(College of Computer Science, South-Central University for Nationalities, Wuhan 430074,China)
AbstractThis paper proposed a new neural network based super-resolution reconstruction algorithm for blurring face image. The norm based minimum total variation was firstly used to deal with the problem of blurring in low-resolution image. The M images in the training database with the most similar to the initial restored image were following identified according to the structure similarity measure. Then the weighted sum of the M images was calculated for initial output of the neural network. Combining with Bayesian posterior probability, RBF neural network was trained iteratively for finally outputs of the high resolution image. The algorithm took full advantages of the similarity between different face images for reconstruction and the constraints of the minimum total variation for edge singularity and smoothness. The experimental results showed that the algorithm effectively improved the resolution of input low face image and had some practice value.
Keywordsface image; super resolution; minimal total variation; SSIM; RBF
在智能视频监控等应用中,具有清晰细节特征的高分辨率人脸图像对于提升系统性能十分重要.而在实际应用中,由于采集目标与相机的距离较远,因此导致获得的图像分辨率及图像质量较低,给后续人脸识别和跟踪等应用带来很大的困难.尽管通过减少传感器大小、增加传感器密度可进一步提升获取图像的分辨率,但是这种方法不仅大大提高了系统的硬件实现成本,而且也导致散射噪声的增加,因此难以满足人们的应用需求.基于软件实现的图像超分辨率(SR)技术[1]是提升图像分辨率的一种有效方法,其基本思想是以若干模糊、有噪、频谱混叠的低分辨率(LR)图像为输入,通过信号处理技术融合成一幅高分辨率(HR)图像.这种技术可以弥补硬件方法的不足,从软件角度显著提高图像的空间分辨率,目前已应用于社会生活的许多领域,并成为获取高质量图像的重要手段,也成为近年来图像处理领域的重要热点问题.人脸图像的超分辨率也称为人脸虚幻.
过去的几十年,图像超分辨率已得到广泛研究,并形成了许多的有用方法.这些方法大体可以分为三类:基于插值的方法,基于重构的方法[2-4]和基于学习的方法.
基于插值的方法是直观且高效的,其主要包括传统的基于双线性插值和样条插值等,然而在放大倍数较大时,这些方法的性能将不再令人满意.基于重构的方法建立在成像降质模型的基础上,其基本思想是组合包含在多帧低分辨率图像中的非冗余信息以生成高分辨率图像.基于重建的方法需要输入足够多的低分辨率图像,才能恢复出原来的高频信息.在实际应用中,多数情况下无法满足这个要求,当只有一幅低分辨率图像输入时,得到对应的高分辨率图像就变得更加困难.同时由于传统基于重建的方法在提高分辨率时,随着分辨率提高倍数的增加,算法性能下降很快,会出现细节丢失、边缘模糊等问题[5].近年提出的基于学习的方法也称为基于样本的方法,通过从一组低分辨率图像和对应高分辨率图像组成的训练集寻找某种关系,并由此估计出低分辨输入图像丢失的高频细节.基于学习的方法利用样本的先验知识来提供更强的约束,因此往往能得到更好的结果.
基于学习的超分辨率重构算法最早由Freeman等人[6]提出,其基本思想是先学习低分辨率图像与高分辨率图像之间的关系,然后利用这种关系来指导对图像进行超分辨率.该方法运用马尔科夫网络建立低分辨率图像块和高分辨率图像块之间的对应关系,并使用贝叶斯置信算法寻找后验概率的局部最大值进行求解.这一算法需要耗费大量的时间来构造图像训练集,整个重构过程耗费的时间很长.Chang等人[7]把流形学习中邻域嵌入的思想引入超分辨率重构算法中,从而假定低分辨率图像块和高分辨率图像块具有相似的局部流形结构.通过图像训练,得到低分辨率图像块和高分辨率图像块的训练集,然后进行匹配重建.Yang[8]把压缩感知的部分思想引入到超分辨率算法中,他们利用线性规划求解LR图像块的稀疏表示,并通过与HR图像块的线性组合得到高分辨率图像.这种方法无需设定用于稀疏表示的低分辨率图像块的数目,但字典的构建具有随机性,很难泛化.
近年来,专门针对人脸图像的超分辨率重构算法得到了研究者们的广泛关注.人脸图像作为一种特殊的、多维的非刚性模式,具有非常复杂的生理学构造.相比于其他图像形式,基于人脸图像的超分辨率图像重构具有更大的挑战性.在人脸图像超分辨率重构算法中,Baker等人[9]第一次提出“虚幻脸”算法,通过引入图像的梯度先验信息进行训练.朱华生等人[10]结合稀疏表示理论,提出了一种基于局部约束的人脸图像超分辨率重构算法.张地等[11]在传统基于像素空间超分辨率重构算法的基础了,提出了一种基于特征空间的人脸超分辨率图像重构算法.An等[12]提出了一种基于二维典型关联分析人脸图像超分辨率重构算法.
以上基于人脸图像的超分辨率算法,在图像降质严重的情况下,重构效果并不理想,例如在某些轮廓部分产生不规则边缘,图像清晰度不足等.为此,本文提出一种新的基于学习的人脸图像超分辨率重构算法.通过查找训练库中与输入图像最接近的M幅人脸图像,并加权求和作为初始的输出;结合贝叶斯后验概率,利用径向基函数(RBF)神经网络进行训练,以提高算法的效率和泛化特性;引入了基于l1范数的最小全变分对重构过程进行约束,以保持图像边缘的奇异性及非边缘的平滑性.实验结果表明,算法在忠实于原始图像的同时,分辨率也得到了有效的提高.
1图像降质模型
超分辨率图像序列的退化模型可用一个线性过程来描述[13].假设观测到的低分辨率图像序列包括K幅M×N大小的低分辨率图像y={y1,y2,…,yn},其中yi(i=1,2,…,K)代表第i幅低分辨率图像.从中复原一幅S1M×S2N的高分辨率图像,这里s1、s2分别代表水平和垂直方向图像的放大倍数.在不考虑运动退化的情形下,该模型可由式(1)的退化过程表示:
yk=DHx+ek,k=1,2,…,K,
(1)
其中x是高分辨率图像,D和H分别为下采样算子和模糊算子.本文中假设采样因子和模糊点扩散函数(PSF)都是已知的;e表示加性噪声.
由已知的低分辨率图像序列yk估计高分辨率图像x是一个病态逆问题.解决病态逆问题的一个有效方法是采用正则化约束.如早期的Tikhonov正则化方法,全变分(TV)正则化和稀疏表示正则化方法等.其中,全变分方法可以在处理的过程中较好地保留图像的边缘信息,并对超分辨率重建中的去噪和去模糊有效,因此在图像复原领域得到了广泛的关注和使用.
在不考虑下采样的情况下,全变分正则化复原模型可以用式(2)来描述:
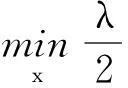
(2)
其中λ>0为正则化常数,它在TV范数项和保真项之间起着重要的平衡作用,H为模糊算子,y为低分辨率图像,Ω表示图像区域.
2基于学习的人脸图像超分辨率重构
尽管TV正则化模型可以较好地保留图像边缘,并对超分辨率重建中的去噪和去模糊有效,但在图像降质严重的情况下,还需要进一步的学习才能得到复原效果更好的图像.本文将TV正则化模型用于人脸图像超分辨率重构的预处理,得到初始复原图像,再经过进一步的学习,以得到更加理想的高分辨率图像.
2.1贝叶斯后验概率法
基于学习的超分辨率算法假定训练样本与输入图像包含相同类型的信息,以输入图像为依据,用学习过程从训练样本集中获取先验知识作为超分辨率的依据.因而能较好地用于人脸图像的超分辨率重构复原中.
由前述图像降质模型可知,超分辨率复原需要解决的问题是在已知低分辨率图像y的条件下,求出最优的高分辨率图像x,最常用的方法是最大后验(MAP)估计.根据贝叶斯估计理论,x的后验概率可由式(3)来描述:
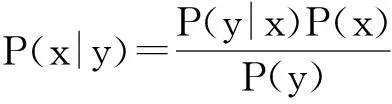
(3)
其中,P(x)和P(y)分别是高分辨率图像x和低分辨率图像y的先验概率;P(y|x)为给定了高分辨率图像x时,观测y的条件概率.满足后验概率P(x|y)取得最大值的x就是最优的,即:
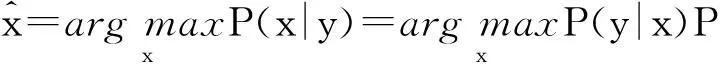
(4)
这里P(x)表示高分辨率图像x出现的先验概率,代表了对高分辨率图像的一种评价标准以避免病态问题的出现[14].P(x)又称为正则项,对控制最终结果的图像质量可起到关键作用.
2.2径向基函数神经网络模型
相比于统计方法和一般神经网络模型,RBF神经网络具有更快的学习速度和更强的泛化能力,它具有高度的非线性映射能力,可以任意准确度地逼近一个给定的非线性函数,具有全局最优和最佳逼近性能.目前较少有文献将该方法用于人脸图像超分辨率重构中.因此,本文采用RBF神经网络模型对人脸图像进行训练以重构高分辨率人脸图像,后续实验证明了该方法的有效性.
RBF神经网络是一种具有拓扑结构的前向神经网络,主要由输入层、隐含层和输出层构成.隐含层采用径向基函数作为网络的激活函数,径向基函数是一个高斯型函数,它将该层权值矢量与输入矢量之间的欧氏距离与偏差相乘后作为网络激活函数的输入.RBF神经网络的基本模型如图1所示.
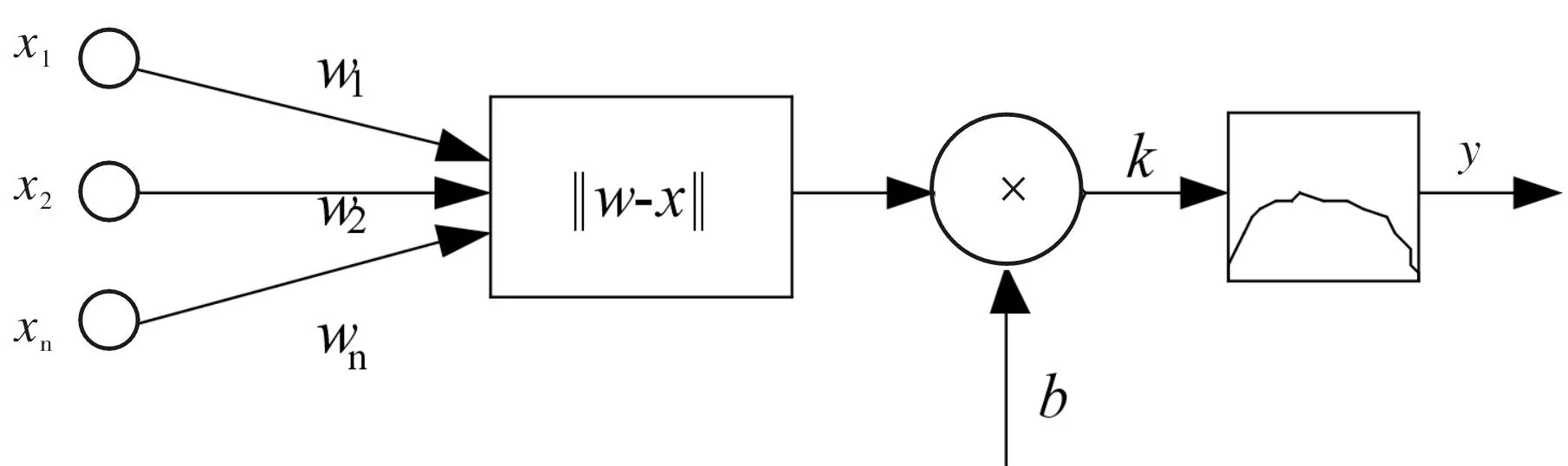
图1 RBF神经网络模型Fig.1 Model of RBF neural network
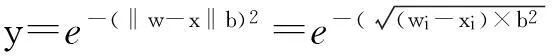
(5)
由式(5)可知,随着w与x之间距离的减少,径向基函数的输出将增加;当其输入为0,即w和x之间的距离为0时,输出最大值1;从而可以将一个径向基函数神经元作为一个当输入矢量x与其权值矢量w相同时,输出为1的探测器.
径向基层中的偏差b可以用来调节其函数的灵敏度,常用伸展常数C来表示.它可以用来确定每一个径向基层神经元对其输入矢量,也就是w与x之间距离的面积宽度.
2.3算法描述
本文算法的基本过程为:
Step1训练库的建立:根据式(1)的退化模型,将N幅原始图像TR_HRi(i=1,2,…,N)进行降采样,得到对应的低分辨率图像TR_LRi(i=1,2,…,N),在这个过程中,假设退化模型是已知的.
Step2 图像配准:由于测试的低分辨率人脸图像与训练库中人脸图像的获取时间、传感器及拍摄条件均存在不一致性,通过对输入低分辨率人脸图像TT_LR进行空间几何变换,使之与训练库中的图像具有几何意义上的匹配.
Step3图像去模糊:采用基于l1范数的全变分方法对输入的低分辨率图像TT_LR进行上采样和去模糊处理,得到初始复原的图像TT_HR0.
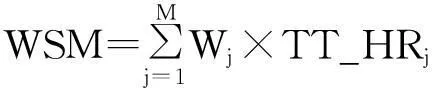
Step5RBF网络初始化:基于贝叶斯正则化优化算法,创建RBF神经网络,初始输入为TT_HR0,初始输出为WSM,扩展常数C=0.8326.
Step6迭代训练:经过网络的多次学习和训练,同时用梯度下降法对权值和扩展常数进行调整,最终得到输入低分辨率图像TT_LR的高分辨率图像TT_HR_TOP,使得均方根误差RSME(TT_HR0,TT_HR_TOP)小于给定的阈值T.
3模拟实验
本文以AR人脸库为例,在Windows7.0操作系统以及Matlab7.10.0平台上进行了模拟实验.AR人脸库包括训练库和测试库,分别有100个人,每人7幅图像,共1400幅图像.与bicubic插值及文献[4](记为L1TV)进行了模拟比对.随机选取其中4幅图像高斯低通滤波降质后,再进行下采样,其重构结果如图2和图3所示.其中图2的高斯滤波窗口大小为3×3,标准差为1;图3的高斯滤波窗口大小为5×5,标准差为2.
从图2中可以看出,在模糊程度较轻的情况下,L1TV算法和本文算法都能较好地恢复降质图像,优于bicubic算法.而在模糊程度进一步加强时(如图3),L1TV算法恢复效果有明显下降,从视觉效果上看,与bicubic算法较为接近;而本文算法则在以上2种情况下,均输出较为理想的高分辨率图像,从人类视觉角度证明了本文算法的有效性.

图2 重构结果(hsize=[3 3],sigma=1)Fig.2 Reconstruction result (hsize=[3 3],sigma=1)

图3 重构结果(hsize=[5 5],sigma=2)Fig.3 Reconstruction result (hsize=[5 5],sigma=2)
采用峰值信噪比(PSNR)和结构相似度(SSIM)作为算法有效性的客观评价标准.分别对测试图像加高斯低通滤波和下采样,其比较结果如图4~7所示.其中图4、图5是子窗大小为3×3,标准差为1时的PSNR和SSIM值,图6、图7是子窗大小为5×5,标准差为2时的PSNR和SSIM值.从图4~7中可以看出,本文算法的PSNR和SSIM性能最好,L1TV算法次之,bicubic算法的性能最差.同时,当模糊程度较轻时,L1TV算法和本文算法的PSNR及SSIM性能较为接近,本文算法效果更好;当模糊程度进一步加强(如图6、7所示),L1TV算法的性能有明显下降,与bicubic算法较为接近.说明L1TV算法仅能处理程度较轻的图像模糊,但本文算法在较大程度模糊时仍具有较好的鲁棒性,从客观角度证明了本文算法的有效性.
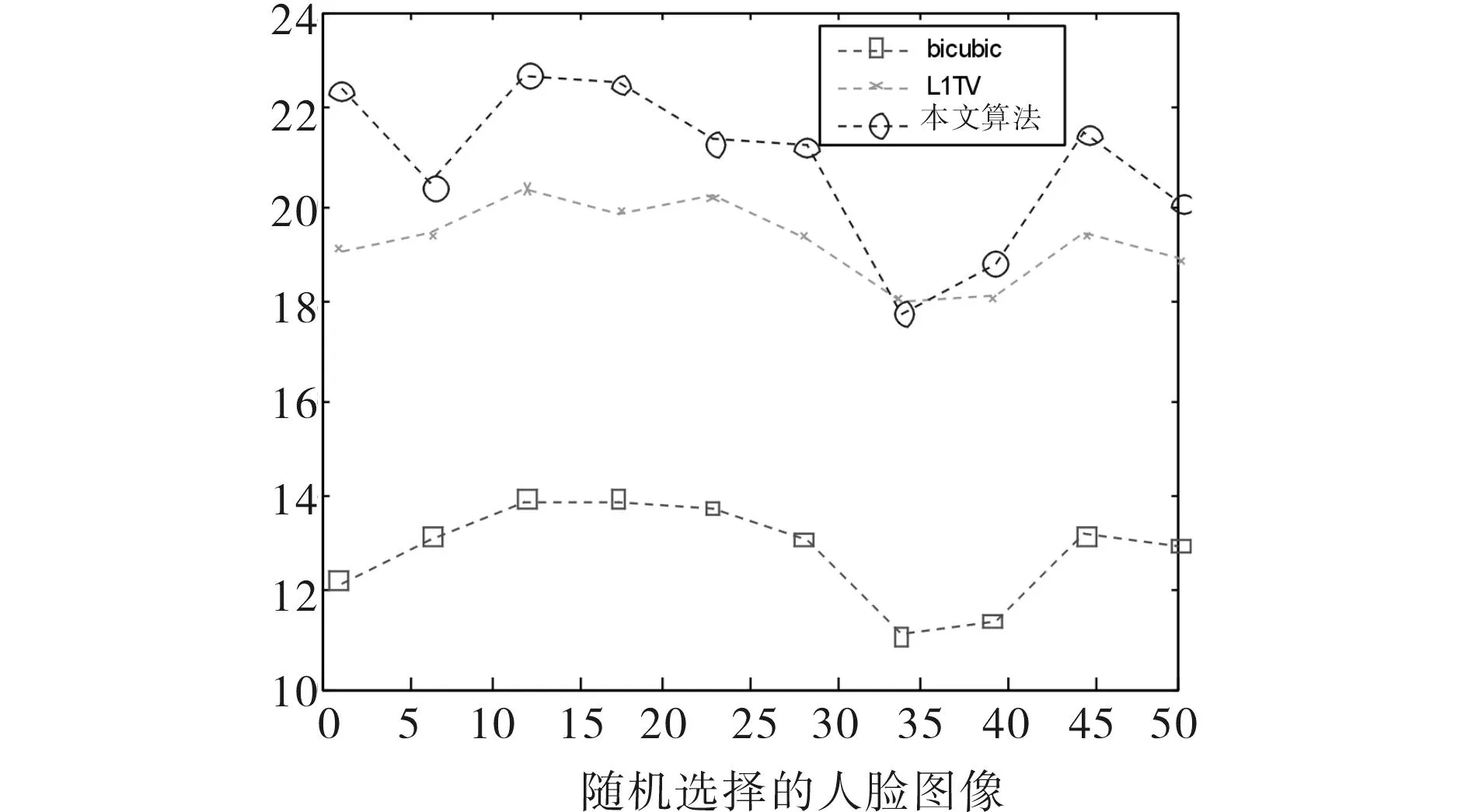
图4 PSNR性能(hsize=[3 3],sigma=1)Fig.4 PSNR (hsize=[3 3],sigma=1)
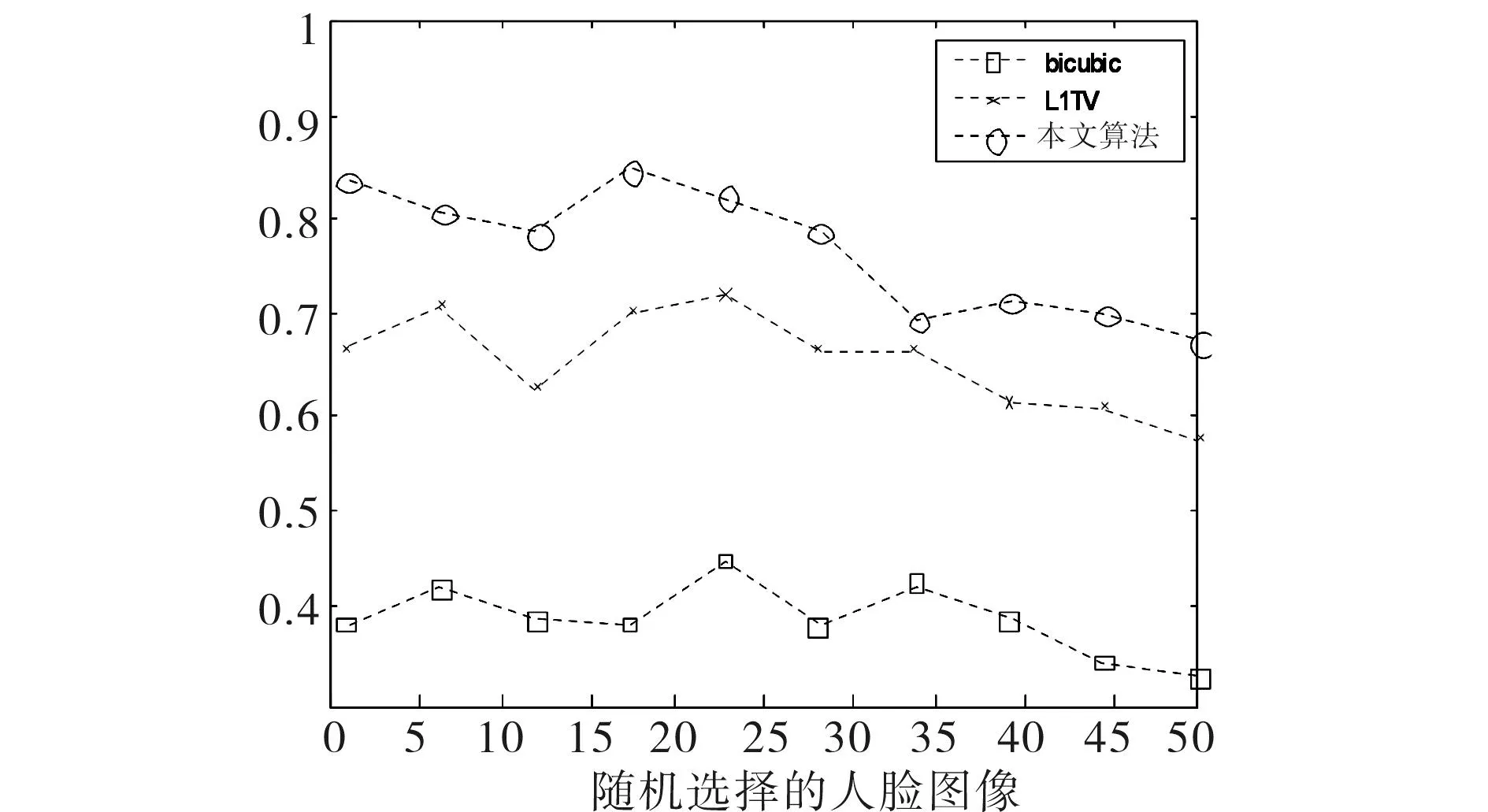
图5 SSIM性能(hsize=[3 3],sigma=1)Fig.5 SSIM (hsize=[3 3],sigma=1)
4结语
针对人脸图像采集过程中硬件设备等方面的不足,导致图像分辨率低的问题,本文提出一种新的基于学习的模糊人脸图像超分辨率重构算法.首先对输入的低分辨率图像上采样后,再用基于l1范数的最小全变分约束进行去模糊处理,得到初始复原图像.根据结构相似度原则选择初始复原图像在训练集中最相近的M幅图像,并加权求和作为神经网络的初始输出.结合贝叶斯后验概率,用RBF神经网络进行迭代训练,最后输出复原的高分辨率图像.算法充分利用了不同人脸图像之间的相似性,并加入了最小全变分约束,以保持图像边缘的奇异性及非边缘的平滑性.实验结果表明,算法在忠实于原始图像的同时,分辨率也得到了有效的提高.
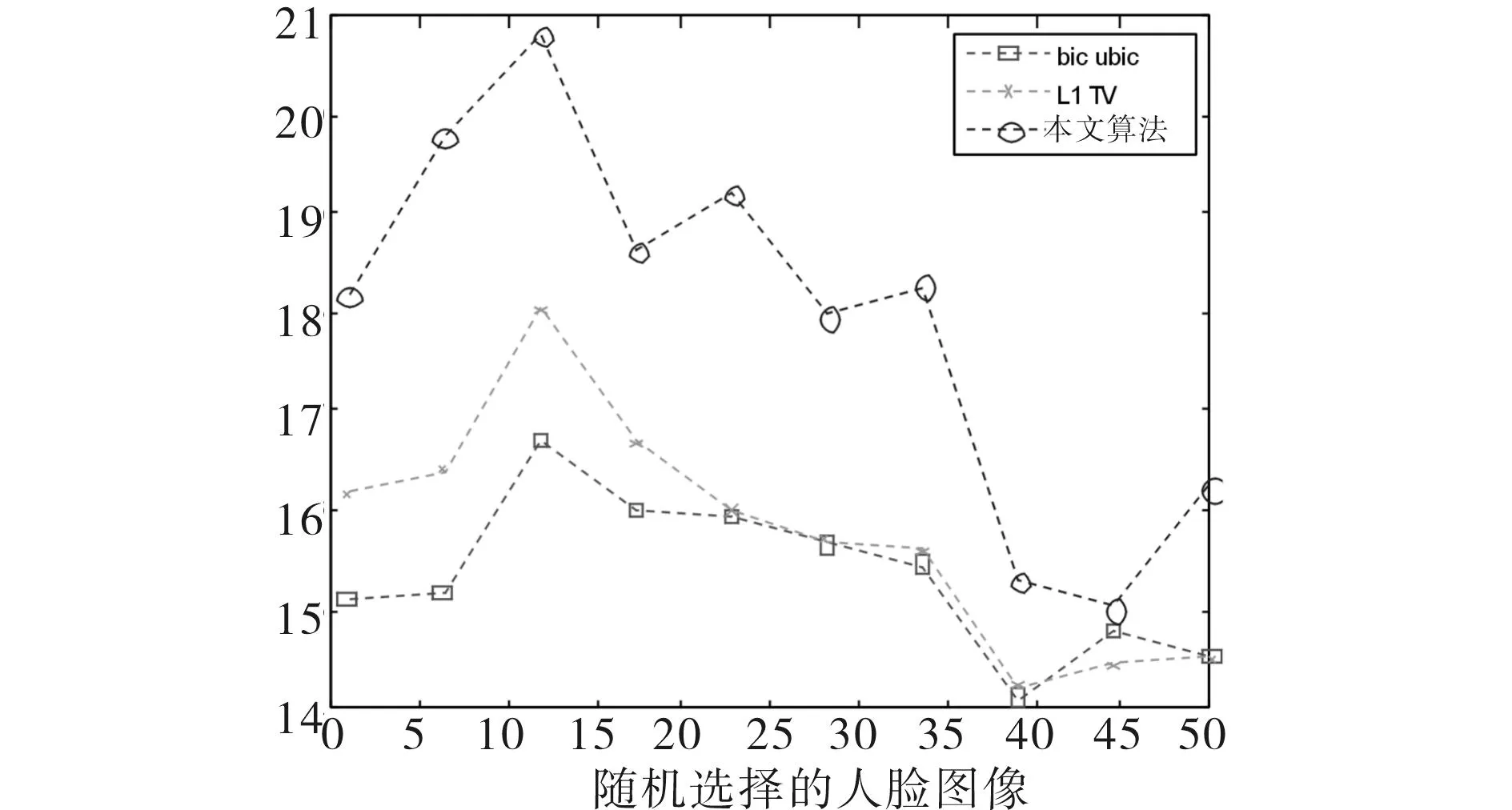
图6 PSNR性能(hsize=[5 5],sigma=2)Fig.6 PSNR(hsize=[5 5],sigma=2)
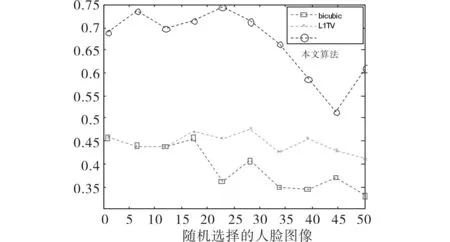
图7 SSIM性能(hsize=[5 5],sigma=2)Fig.7 SSIM (hsize=[5 5],sigma=2)
目前有关基于学习的图像超分辨率技术的研究尚处于理论研究阶段,远远没有达到使用阶段.未来研究方向主要集中在以下几个方面:(1)建立更有效的学习模型,以提供更完备的先验知识;(2)完善学习算法和搜索算法,提高学习训练速度和匹配速度,减小运算量.随着各应用领域的发展,相关理论和技术的不断提高,必将推动基于学习的超分辨率技术的进一步发展.
参考文献
[1]Park S C, Park M K, Kang M G. Super-resolution image reconstruction: a technical overview [J]. IEEE Signal Processing Magazine, 2003, 20(3):21-36.
[2]Gunturk B K,Gevrekci M.High-resolution image recon-
struction from multiple differently exposed images [J]. IEEE Signal Processing Letters, 2006, 13(4):197-200.
[3]Choi B, Ra J B. Region-based super-resolution using multiple blurred and noisy undersampled images[C]//IEEE. International Conference on Acoustics, Speech and Signal Processing. Toulouse: IEEE, 2006: 609-612.
[4]Zhan M Q, Deng Z L. L_1 norm of total variation regularization based super resolution reconstruction for Images[J]. Science Technology & Engineering, 2010,10(28):6903-6906.
[5]Baker S, Kanade T. Limits on super-resolution and how to break them[J]. IEEE Trans On Pattern Analysis and Machine Intelligence, 2002, 24(9):1167-1183.
[6]Freeman W T, Jones T R, Pasztor E C. Example-based super-resolution[J]. Computer Graphics & Applications IEEE, 2002, 22(2):56-65.
[7]Chang H, Yeung D Y, Xiong Y. Super-resolution through neighbor embedding [C]//IEEE. International Conference on Computer Vision and Pattern Recognition. Washington DC:IEEE,2004: 275-282.
[8]Yang J, Wright J, Huang T, et al. Image super-resolution as sparse representation of raw image patches [C]//IEEE. International Conference on Computer Vision and Pattern Recognition. Anchorage:AK, 2008:1-8.
[9]Kanade T, Baker S. Hallucinating Faces[C]//IEEE. International Conference & Workshops on Automatic Face & Gesture Recognition. Grenoble:IEEE, 2000:83-89.
[10]朱华生, 徐晨光. 基于局部约束的人脸图像超分辨率重构算法[J]. 激光与红外, 2014, (2):217-221.
[11]张 地, 何家忠. 基于特征空间的人脸超分辨率重构[J]. 自动化学报, 2012, 38(7).
[12]An L, Bhanu B. Face image super-resolution using 2D CCA[J]. Signal Processing, 2014, 103(10):184-194.
[13]安耀祖, 陆耀, 赵红. 一种自适应正则化的图像超分辨率算法[J]. 自动化学报, 2012, 38(4).
[14]苏衡, 周杰, 张志浩. 超分辨率图像重建方法综述[J]. 自动化学报, 2013, 39(8):1202-1213.
中图分类号TP183;TP391.4
文献标识码A
文章编号1672-4321(2016)01-0114-05
基金项目国家自然科学基金资助项目(61471400, 61201268);湖北省自然科学基金资助项目(2013CFC118)
作者简介高志荣(1972-),女,副教授,博士生,研究方向:智能计算、机器学习.E-mail:gaozhirong@mail.scuec.edu.cn
收稿日期2015-12-20
