基于偏好相似度的混合信任推荐模型
2016-04-15谭文安沈腾腾
谭文安,沈腾腾,孙 勇
(1.南京航空航天大学 计算机科学与技术学院, 南京 210016;2.上海第二工业大学 计算机与信息学院, 上海 201209)
基于偏好相似度的混合信任推荐模型
谭文安1,2,沈腾腾1,孙勇1
(1.南京航空航天大学 计算机科学与技术学院, 南京 210016;2.上海第二工业大学 计算机与信息学院, 上海 201209)
摘要:针对P2P网络中可信数据不完整的问题,提出了将局部可信度与全局可信度相结合的基于偏好相似度推荐的混合信任模型(Preference Similarity Recommendation Trust,PSRTrust),借助相似随机游走策略修复稀疏的可信度矩阵;对不合理假设呈现power-law分布进行合理化改进;并给出了可信数据的分布式存储和计算的分布式方法。仿真实验表明,PSRTrust模型有效地提高了在可信数据不完整情况下的交易成功率,并且在遏制恶意节点影响上有一定提高。
关键词:对等网络;可信度;稀疏可信度计算;偏好相似度;分布式哈希表
P2P网络区别于传统互联网的Client/Server或者Brower/Server模型,是一种不借助中心服务器的分布式网络,其中每个节点不再仅仅是信息的消费者,它可利用自身资源为其他节点提供信息,使得存在于每个网络节点中的资源可以高度共享。但P2P网络具有动态性、匿名性等特点,容易受到恶意用户的攻击,还需承受理性用户“搭便车”的自私行为。为了避免以上安全风险,建立一个可靠的可信度评估模型是至关重要的[1]。
所谓信任模型,是指在已建立的评价体系中,依据用户节点间的历史交易记录,对每个用户节点的“被信任程度”进行量化评估[2-3]。一般可将可信度评估模型分为两类,局部信任模型和全局信任模型[4]。局部信任模型,是指单个用户节点参考有限的其他用户节点的推荐值,以预测某个用户节点的可信度,此方法获得的节点可信度往往是局部的和片面的[5]。VectorTrust[6]和M-Trust[7]是局部可信度计算模型,其中VectorTrust模型借助Bellman-Ford算法,在网络中寻找某节点与其他未交互节点的最短可达路径;M-Trust模型将Bellman-Ford、加权平均等方法进行结合,进行间接可信度评估。但两模型方法均需借助已有交互,受可信数据完整程度影响,而本文采用偏好相似度预测方法受其影响较小。
全局信任模型,是指全面考虑所有节点对该节点的反馈评价值,并对该节点的可信程度做出综合性评价[8]。已存在的一些经典全局信任模型[9-11]等,其中EigenTrust[9]模型量化可信度时,基于“全局可信值越高越可信”的假设,即大部分交互发生在少数全局可信度较高的节点上,这不仅使得少数全局可信度较高节点负载过重,其他节点资源浪费,并且忽略了节点选择偏好性,导致“可信”量化的不准确,交易成功率较低。
随着大量新进节点的加入,P2P网络节点、资源数目也越来越多。新进节点加入初期,由于节点间交互较少,记录节点间交互评价的可信度矩阵稀疏,造成可信数据的不完整,对于“可信”量化是一个极大的阻碍。
针对以上问题,笔者提出了一种将局部可信度与全局可信度相结合的混合信任模型,结合文献[12]与随机游走策略,提出相似随机游走策略预测间接可信度,解决可信数据不完整的问题;对power-law分布进行合理化改进;使用改进的Chord协议实现了信任数据的分布式存储与查询。
1PSRTrust信任模型
1.1模型定义和表示
定义1偏好向量。即不同用户节点在对提供不同服务节点进行反馈评价时,在各评价指标中的不同的偏重程度,评价指标可包括下载速度、文件质量、传输速度等。定义为(ωi1,ωi2,…,ωik),其中ωik为节点i对第k个指标的偏重程度,可取[0,5]中的整数。
定义2偏好相似度。节点i和节点j因对评价指标的偏重程度不同,导致评价行为也不同。计算相似度公式有很多,如皮尔逊相关系数公式、广义Dice系数法等,笔者使用余弦相似度公式,对不同节点的偏好向量进行相似度计算。定义为,
(1)
式中,Cij权重与相似程度成正比。
定义3偏好相似度矩阵。即(Cij)n×n.
定义4局部可信度。可分为直接可信度和间接可信度。直接可信度Dij,即节点i通过直接历史交易记录对节点j进行可信评估,计算公式为:
(2)
式中:Sij=Gij-Fij, 其中Gij是以节点i看来与节点j交互成功次数;Fij是以节点i看来与节点i交互失败次数,并且Dij=0。
间接可信度Tij,即节点i与节点j之间未有交互,节点i通过其他节点推荐而得到对节点j的可信度,本文采用偏好相似度推荐机制,计算公式为:
(3)
式中:R为与节点j有过交互的节点集合;Dkj为集合R中推荐节点k与节点j直接可信度;Cik为节点i与推荐节点k的相似度;Gk为推荐节点的全局可信度。
定义5可信度矩阵。即直接可信度矩阵(Dij)n×n.
定义6反可信度0~1矩阵。(Nij)n×n为根据可信度矩阵数据取值的0~1矩阵,
(4)
定义7全局可信度。即网络中所有节点对该节点的综合评价值,全局信任值向量为,
式中,Gi为节点i的全局可信度。
1.2模型的详细介绍
1.2.1相似随机游走

(5)
该迭代过程由马尔科夫随机游走向前推动,每一步考虑自身和所有邻居节点的局部可信度的迭代计算。
随着P2P网络规模扩大,节点和资源量不断增加。相较于较大的网络规模,节点间直接交互变少,使得直接可信度矩阵在一段时间内严重稀疏,出现了数据不完整问题。由于参与迭代的稀疏可信度矩阵造成的数据不完整问题,导致最终迭代结果节点全局可信度的不准确。
针对以上问题,笔者采用文献[12]中的第二种思想结合马尔科夫随机游走策略,提出相似随机游走策略,每一次迭代增加考虑节点间偏好相似,对缺损迭代矩阵进行修复,其中,间接可信度矩阵(Tij)n×n由式(6)进行偏好相似计算,并根据式(7)的偏好相似修复矩阵(Sij)n×n,对(Sij)n×n进行行正规化使其成为正规化矩阵,并由式(8)进行矩阵迭代计算。
(6)
(7)
(8)
1.2.2power-law分布合理化改进
在经典模型EigenTrust,PowerTrust中,提出模型成立的假设“节点全局可信度越高说明该节点越可信”,其节点反馈呈现power-law分布,即绝大多数请求响应只发生在少数全局可信度较高节点上。该倾向无疑使得少量全局可信度较高的节点负载过重,而大多数节点处在闲置状态,造成资源的浪费;并且类似于社会网络,P2P网络中的不同用户节点的需求偏好不同,该假设也减少了个人的选择空间,其直接交互记录以及偏好相似用户的推荐也是在交互选择中要考虑的因素。
笔者参考了以上因素影响,采取如图1所示策略。该改进策略中首先考虑节点i的个人交互记录,若待选择节点j与节点i之前发生过交互并且Dij大于可信临界值,即节点j是可信的,则节点j即被设为可选择对象;其次,若节点i通过偏好相似用户推荐得到节点j是可信的,则节点j亦被视为可选择对象;若两者未有过交互并且偏好相似用户推荐失败,此时查询节点j的全局可信度,此后选择策略与EigenTrust相同。

图1 合理化改进策略Fig.1 Reasonable updating strategy
2信任模型分布式计算的实现
2.1可信数据的分布式存储和查询
P2P网络的分布式的特点决定了网络中可信数据的分布式存储和查询,高度自治的特点决定了每个节点都可自主的进行可信的计算、数据的存储查询,但为了防止恶意节点随意篡改自己的可信度,每个节点都应有其他节点对其可信数据进行存储管理,这类节点被称为信任管理节点。分布式哈希表(DistributedHashTable,DHT)可用于信任管理节点的分配,其中CAN协议[13]和Chord协议[14]较为常用。
利用Chord协议进行不同节点的信任管理者的分配,Chord算法是按节点标识符(ID)顺序排成一个环,ID是由节点IP地址通过单向Hash函数(如SHA-1)映射得到的,每个节点ID是唯一的;键值k则是由标识符ID通过另一个单向Hash函数映射得到的,可知每个节点对应键值也是唯一的。若某个节点IDi是键值k按顺时针方向相距最近的后继节点的标识符,则该节点i即为键值k对应节点的信任管理者,记为Successor(k)=i。管理节点存储一张含有m条记录的指针表(2m≫网络中节点总数),用来映射关键字k和信任管理者的关系。具体过程如图2所示。
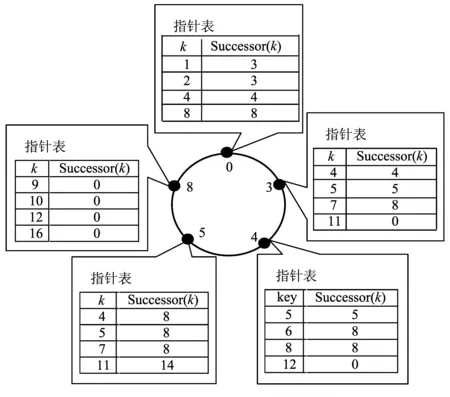
图2 m=4Chord协议Hash逻辑空间Fig.2 Hash space of Chord with m=4
Chord协议为P2P网络中每个节点分配到一个信任管理者,在P2P环境中恶意节点作为信任管理者可随意篡改其他节点的可信数据,而没有其他节点的制约,所以Chord协议中多对一的模型是不可取的。本文对Chord协议进行改进,使得每个节点对应多个信任管理者,即按顺时针方向选取距离关键字k最近的s个后继节点,作为k映射节点的信任管理者。如图2中ID3节点更改后的指针表如表1所示。

表1 s=3指针表
在该策略中,节点i要查询节点j的可信数据时,节点j的多个信任管理节点同时向节点i发送可信数据,其中少量不一致的可信数据被排除,并将提供不一致数据的恶意管理节点进行隔离排除,该方法较于EigenTrust中需要选取多个Hash函数更为简单易行,改进Chord协议指针表初始化如算法1所示。
SearchNext(IDArray,ID):在ID有序数组IDArray中查找ID的下一个id.
Insert(k,ID):为向指针表k的successor(k)中插入ID值.
算法1改进Chord协议指针表初始化算法。
输入:管理节点数m,键值k数组,ID有序数组
输出:改进指针表
01.For(Everyk∈指针表k数组){
02.ID=successor(k);
03.While(m>1){
04.ID=SearchNext(IDArray,ID);
05.Insert(k,ID);
06.m--;
07.}
08.}
09. 对网络中指针表进行以上初始化操作.
2.2间接可信度分布式求解算法
鉴于P2P网络中可信数据的分布式存储和查询,间接可信度需分散到各个信任管理节点上进行分布式计算。信任管理者中存储节点的直接/间接可信度、相似度向量和该节点的全局可信度,间接可信度计算首先需要通过改进Chord协议寻找查询节点信任管理节点,信任管理节点间进行数据查询传递,再由节点的所有信任管理者进行结果整合、筛选和记录,具体如算法2所示。
Sk:与节点j有过交互的节点的集合.
算法2间接可信度分布式算法.
输入:直接可信度,相似度,全局可信度
输出:节点间接可信度
01.For(Everyk∈Sk){
02.Mk=successor(kk);
03.For(Everyr∈Mk){
04.计算temp[k]=Dkj×Cik×Gk;
05.将temp[k]和Cik推荐给节点i;
06.}
07.Mk中节点进行temp[k]和Cik选择;
08.Sum=Sum+temp[k];
09.CSum=CSum+Cik;
10.}
11.计算Tij=Sum/CSum;
12.将Tij存储在i的信任管理者集合Mi中.
3实验与结果分析
选用QuantitativeTrustManagement(QTM)[15]仿真系统,用Java代码实现所描述的PSRTrust模型,由于本模型在全局可信度计算方面与EigenTrust模型相近,完成了本文模型与EigenTrust、在无信任系统情况下的对比实验。
在QTM仿真实验中,通过设置表2中参数对P2P网络进行初始定义,生成的路径文件仿真P2P网络中节点与拥有文件的映射关系,该映射中包括了对拥有文件是否有效的仿真,以及节点对(下载)需求文件的映射关系。在本文中用交易成功率对不同的模型进行比较。

表2 仿真参数
3.1可信矩阵稀疏性实验仿真与讨论
分别进行了两次与可信度矩阵稀疏性相关的仿真实验。第一次仿真研究可信矩阵的稀疏性对节点间交易成功率的影响,另一个研究了在不同规模网络中不同稀疏性的PSRTrust模型性能是否保持稳定的问题。
如图3所示,在稀疏度为5%~55%的变化过程中,由于可信矩阵稀疏度较大,而PSRTrust模型可信数据较于EigenTrust、None更为完整,所以在该稀疏度变化过程中,PSRTrust模型有更高的交易成功率,较EigenTrust可提高4%~11%的交易成功率,并且在稀疏度25%时处于交易成功率最高值;而后随着可信数据的不断增加,在60%~85%的变化区间内,由于可信数据完整性较好,PSRTrust与EigenTrust的交易成功率差距逐渐变小,最后两模型性能接近重合。
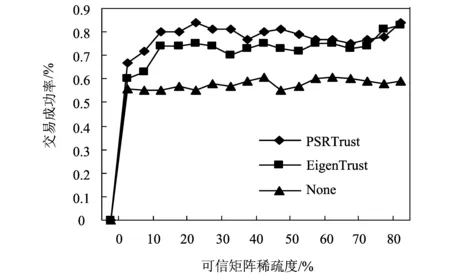
图3 可信矩阵稀疏性对交易成功率影响Fig.3 Effect of sparse rate in trust matrixto success rate of transactions
如图4所示,仿真可信度矩阵稀疏度为10%,20%,30%和40%情况下的PSRTrust模型在不同规模P2P网络下性能表现。随着网络规模的不断扩大,对于相同可信度矩阵稀疏度下的PSRTrust模型,其交易成功率变化在0%~0.6%之间趋于平缓;而在不同可信度矩阵稀疏度情况下的PSRTrust模型交易成功率差异较小,差异约在1%的范围内上下浮动。

图4 网络规模对不同稀疏性模型影响Fig.4 Effect of system size to modelwith different sparse rates
结合两个对比实验说明,PSRTrust模型通过相似随机游走策略可较为准确的预测缺省数据,使得在可信数据较少的情况下也具有较好的交易成功率,并且在可信数据较为完整情况下亦可达到EigenTrust模型交易成功率,且仿真结果PSRTrust模型受网络规模的影响较小,所以也适用于真实大规模P2P网络环境。
3.2恶意节点实验仿真与讨论
恶意节点的种类可分为孤立的恶意节点、协同的恶意节点和伪装的恶意节点[15],文中由于重点不在对不同种类恶意节点的处理方式上,所以文中提到的恶意节点为孤立的恶意节点,如图5所示。

图5 不同规模恶意节点对交易成功率影响Fig.5 Effect of malicious nodes with differentsize to success rate of transactions
随着恶意节点率增加,三者均承下降趋势,但三者下降速度不同,其中PSRTrust模型下降速度最慢。PSRTrust模型的交易成功率最高,较于EigenTrust模型,本文模型交易成功率提高了约1%~5%,较于None模型,本文模型提高了约1%~21%的交易成功率,并且在恶意节点率0%~25%区间内,PSRTrust模型的交易成功率均在90%以上,在区间0%~40%内交易成功率在80%以上,而假设网络中绝大多数用户均为恶意用户时便没有了现实意义,因此该模型在现实P2P网络中有较好的性能。
如图6所示,在不同稀疏度下的PSRTrust模型随着恶意节点率增加下降趋势基本一致,也同样说明PSRTrust可较为准确的预测缺省数据,可使在较低稀疏性情况下的PSRTrust模型亦有较好的性能,其中在稀疏度40%下的PSRTrust模型的交易成功率稍高。较于None模型,在稀疏度为35%时模型交易成功率相差最大为21%。

图6 不同规模恶意节点对不同稀疏性系统影响Fig.6 Effect of malicious nodes with differentsize to model with different sparse rates
本模型中改进Chord协议为防止恶意节点篡改信任值,为每个用户节点设定多个信任管理者,以上两个对比实验表明本模型在遏制恶意节点影响上有一定提高,但结果表明,随着恶意节点率增加,受影响程度越大,这也是以后论文努力的方向。
4结论
针对可信数据不完整问题,借鉴相似随机游走处理数据不完整问题的方法,构造了一个基于偏好相似度推荐的混合信任模型。仿真实验结果表明,该模型适用于大规模P2P网络,在可信数据不完整情况下能保持很好的性能,并且在遏制恶意节点攻击上有一定提高。
笔者并未介绍不同类型的恶意节点及其对应的遏制机制,同样,奖惩机制也是P2P网络安全机制中重要的组成部分,可以对恶意节点施加严厉的惩罚,更快的发现恶意节点。今后将在这两方面做进一步的研究工作。
参考文献:
[1]李勇军,代亚非.对等网络信任机制研究[J].计算机学报,2010,33(3):390-405.
[2]窦文.信任敏感的P2P拓扑构造及其相关技术研究[D].长沙:国防科学技术大学,2003.
[3]李景涛,荆一楠,肖晓雪,等.基于相似度加权推荐的P2P环境下的信任模型[J].软件学报,2007,18(1):157-167.
[4]朱锐,王怀民,冯大为.基于偏好推荐的可信服务选择[J].软件学报,2011,22(5):852-864.
[5]窦文,王怀民,贾焰,等.构造基于推荐的Peer-to-Peer环境下的Trust模型[J].软件学报,2004,15(4):571-583.
[6]ZHAOH,LIX.VectorTrust:trustvectoraggregationschemefortrustmanagementinpeer-to-peernetworks[J].JournalofSupercomputing,2013,64(3):805-829.
[7]QURESHIB,MING,KOUVATSOSD.M-Trust:AtrustmanagementschemeformobileP2Pnetworks[C]∥IEEE.ProceedingsoftheIEEETrustcom2010inconjunctionwith7thIEEE/IFIP.China:HongKong,2010:476-483.
[8]胡建理,吴泉源,周斌,等.一种基于反馈可信度的分布式P2P信任模型[J].软件学报,2009,20(10):2885-2898.
[9]KAMVARS,SCHLOSSERM,GARCIA-MOLINAH.TheeigenTrustalgorithmforreputationmanagementinP2Pnetworks[C]∥ACM.ProceedingofACMWorldWideWebConf.NewYork:ACMPress,2003:640-651.
[10]ZHOUR,HWANGK.PowerTrust:Arobustandscalablereputationsystemfortrustedpeer-to-peercomputing[J].IEEETransactionsonParallelandDistributedSystems,2007,18(4):460-473.
[11]XIONGL,LIUL.PeerTrust:supportingreputation-basedtrustforpeer-to-peerelectroniccommunities[J].IEEETransactionsonKnowledgeandDataEngineering,2004,16(7):843-857.
[12]王双成,林士敏,陆玉昌.用Bayesian网络处理具有不完整数据的问题分析[J].清华大学学报,2000,40(9):65-68.
[13]RATNASAMYS,FRANCISP,HANDLEYM,etal.Ascalablecontentaddressablenetwork[C]∥ACM.ProceedingsofACMSIGCOMM,NewYork:ACMPress,2001,31(4):161-172.
[14]STOICAI,MORRISR,KARGERD,etal.Chord:Ascalablepeer-to-peerlookupserviceforinternetapplications[C]∥ACM.Proceedingsofthe2001ConferenceonApplications,Technologies,Architectures,andProtocolsforComputerCommunications.NewYouk:ACMPress,2001:149-160.
[15]ZHENGY.TrustModelingandManagementinDigitalEnviromentalsfromSocialconcepttosystemdevelopment[M].WESTAG,LEEI,KANNANS,etal.Anevaluationframeworkforreputationmanagementsystems.PA:InformationScienceReference,c2010:283-308.
(编辑:朱倩)
Preference Similarity-Based Mixed Trust Recommendation Model
TAN Wenan1,2,SHEN Tengteng1,SUN Yong1
(1.CollegeofComputerScienceandTechnology,NanjingUniversityofAeronauticsandAstronautics,Nanjing210016,China;2.SchoolofComputerandInformation,ShanghaiSecondPolytechnicUniversity,Shanghai201209,China)
Abstract:A large number of new nodes in peer-to-peer network make the trust matrix sparse and data insufficient. This leads to inaccurate global trusts of peers which are computed by trust matrix iteration and finally the low success rate of transaction.PSR-Trust,a mixed trust model combining global trusts and local trusts based on preference similarities, restores sparse trust matrix by Similarity Random Walk. This model optimizes the unreasonable assumption, gives a distributed implementation method and data storage. Mathematic analyses and simulations results show that the proposed model is more robust under general conditions where malicious peers cooperate in an attempt to deliberately subvert the system, and the success rate of transactions is higher compared with current trust model.
Key words:peer-to-peer; trust; sparse trust calculation; preference similarity;distributed hash table
中图分类号:TP301
文献标识码:A
DOI:10.16355/j.cnki.issn1007-9432tyut.2016.01.013
作者简介:谭文安(1965-),男,湖北荆州人,博士,教授,主要从事软件构架技术、协同计算、服务计算与知识管理、信息化工程及其支持环境研究等的研究,(E-mail)wtan@foxmail.com
基金项目:国家自然科学基金资助项目:跨组织工作流系统可靠服务计算关键技术研究(6127036);上海第二工业大学重点学科基金资助项目(XXKZD1301)
收稿日期:2015-05-23
文章编号:1007-9432(2016)01-0062-06
