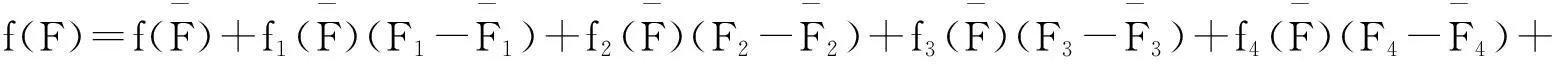基于非线性-主成分Logistic回归的会计舞弊识别研究
2016-04-09任朝阳
李 清,任朝阳
(吉林大学 商学院,吉林 长春 130012)
基于非线性-主成分Logistic回归的会计舞弊识别研究
李清,任朝阳
(吉林大学 商学院,吉林 长春 130012)
摘要:混沌理论认为,人类行为大多具有非线性特征。会计舞弊属于行为会计的研究范畴,而传统上基于统计理论构建的舞弊识别模型大多受限于线性约束假设,可能存在模型设定偏误和信息提取不充分的缺陷。以沪深A股受到监管处罚的上市公司及其配对公司为样本,借鉴Taylor展开式的非线性思想,并使用主成分分析消除变量多重共线性,构建了非线性-主成分Logistic回归的会计舞弊识别模型。与线性回归模型对比发现,前者具有更高的舞弊识别正确率,模型拟合度更优。应用这一模型有助于更加充分提取舞弊识别信息,提高舞弊识别效率。
关键词:非线性;主成分分析;Logistic回归;会计舞弊识别
一直以来,会计舞弊被视为阻碍资本市场健康发展的顽疾。那些由于经营不善、效率低下的“价值损伤型”公司通过实施会计舞弊抢夺了稀缺的市场资源,扭曲了资本市场的资源配置效率,认认真真创造价值的公司反而难以生存。传统上,会计舞弊识别大多基于线性思维构建舞弊识别模型。然而,越来越多的研究表明,舞弊行为具有典型的非线性特征,舞弊手段的多目标性也决定了使用线性模型进行识别的局限性。考虑到传统识别方法可能存在模型设定偏误和信息提取不充分的缺陷,本文提出在传统Logistic回归模型的基础上结合Taylor展开式的非线性思想,并使用主成分分析消除变量多重共线性,构建基于非线性-主成分Logistic回归的会计舞弊识别模型。本文的贡献在于突破了线性约束假设,探索了更加贴合企业舞弊行为规律的模型设定形式,以更充分地提取舞弊识别信息,为投资者有效识别舞弊提供更有力的支持。
一、文献回顾
随着学术界对会计舞弊研究的不断深入,研究成果也日渐丰富。早期研究如Albrecht和Romney关于会计舞弊“红旗”标志的问卷调查及Loebbecke和Willingham关于舞弊风险因子的概括开启了会计舞弊识别研究的先河[1-2]。之后的一些学者则从不同方面总结了会计舞弊的识别指标,如Beasley关于公司董事会特征与会计舞弊关系的研究发现,会计舞弊公司的外部董事比例显著低于非舞弊公司,且随着外部董事持股比例和任期的增加以及外部董事在其他公司兼职岗位的减少,会计舞弊的可能性降低[3]。又如,Summers和Sweeney及Beneish关于内部人交易与会计舞弊关系的研究发现,会计舞弊公司的管理者在舞弊期间的股票卖出量显著高于非舞弊公司[4-5]。再如,Lee等对应计盈余舞弊识别能力的研究发现,舞弊公司的应计盈余水平显著高于非舞弊公司[6]。针对舞弊识别指标的考察为舞弊识别综合模型的构建奠定了基础。Bell和Carcello以7个舞弊风险因子为基础,构建了舞弊风险识别的Logistic回归模型,模型识别正确率达到80%以上[7]。Spathis以38家会计舞弊公司为样本,以Altman的Z分值和9个财务指标为基础,构建了会计舞弊识别的Logistic回归模型,模型识别正确率也超过84%[8]。Green和Choi及Fanning和Cogger构建了人工神经网络模型用于识别会计舞弊。结果表明,人工神经网络模型以其良好的非线性特征也实现了较高的识别正确率[9-10]。
国内针对会计舞弊识别的研究起步稍晚。从研究方法看,国内学者对会计舞弊识别的研究可以大致划分为探索性研究、统计识别模型和人工智能识别模型。初期的研究大多基于案例分析、问卷调查或以描述性统计分析考察会计舞弊的行业、地区分布特征、手法与动机等[11-13]。后来亦有学者基于前人对舞弊识别的研究积累,通过指标选取、样本筛选及模型构建与训练,构建了会计舞弊识别的统计模型[14-17]。随着人工智能方法的日益成熟,基于人工智能方法构建会计舞弊识别模型的研究也逐渐增多,如支持向量机、人工神经网络、基于案例推理等[18-20]。然而,人工智能虽然无线性约束条件,但也存在固有缺陷,如人工神经网络方法的内部结构不够清晰,可能存在过拟合问题,模型的泛化能力受限;而基于案例推理方法的缺陷在于需要确定属性权重,否则可能爆发维度灾难[21]。
综上可见,已有文献基于统计方法构建的舞弊识别模型大多基于线性约束假设,而人工智能模型也存在固有缺陷,有必要考虑新的模型构建思路与方法。基于统计理论构建的线性模型用于识别会计舞弊可能存在模型设定偏误和信息提取不充分的缺陷。判断一个样本公司是否舞弊通常需要结合多个方面的因素,例如:某公司年度内应收账款的大量增加未必就是舞弊导致,还要观察其是否伴随着营业收入的增加或是客户付款能力的恶化等。可见,仅通过单一指标的异常就作出判断,容易将正常公司误判为舞弊公司,从而丧失投资机会。更严重的是,线性模型仅仅对指标进行简单相加,而忽视了其交互效应对舞弊识别的作用,对舞弊识别信息未能充分提取,导致某些单个指标并不突出实已危机四伏的舞弊公司成为漏网之鱼。这些资本市场的“定时炸弹”一旦引爆,投资者的损失将更加惨重。基于此,本文借鉴Taylor展开式的非线性思想,并使用主成分分析消除变量多重共线性,构建了非线性-主成分Logistic回归的会计舞弊识别模型,以期更充分地提取会计舞弊识别信息,为投资者更有效地识别会计舞弊,防范投资风险,提高投资收益提供支持。
二、变量选择与模型构建
(一)变量选择
会计舞弊是指企业在财务会计信息对外报告的过程中的故意漏报或篡改行为。按舞弊类型,会计舞弊主要划分为财务报表舞弊和会计信息违规披露。后者的判定通常涉及相关法律法规及交易所的规章制度,因而并非单纯会计问题。本研究仅关注财务报表舞弊。从以资产负债表为核心和以利润表为核心分析,财务报表舞弊可以划分为虚增净资产和虚增利润。虚增净资产通常表现为虚增资产、少计负债,常见的操纵项目为应收账款、应付账款、存货、折旧与待摊费用等应计类项目;虚增利润则往往通过提前确认或虚构收入,少计成本、费用,隐瞒亏损等手段达成,涉及的报表项目包括营业收入、营业利润、净利润、期间费用等项目。此外,已有研究表明,财务健康程度是影响企业会计舞弊的重要因素,Altman的Z分值提供了衡量企业财务健康度的综合观测[22]。基于上述分析,本文使用的会计舞弊识别指标如表1所示。

表1 变量及其说明
(二)模型构建
设公司会计舞弊的概率为p(0 一般地,Logistic回归模型设定为: 对等式两边取自然对数: 从而,普通线性Logistic回归模型形式如下: 为有效识别会计舞弊,模型中通常包含多维变量,然而变量维度的增加易导致多元解释变量之间高度相关。主成分分析是在模型中解释变量较多时,通过主成分变换,提取彼此不相关的主成分代替原变量,在最大程度保留原变量信息的基础上,消除变量间的相关性,同时达到模型降维约简的目的。主成分分析的操作步骤为: (1) 首先,将原始数据标准化,得到标准化数据阵X=(x1,x2,…,xq),其中,xi=(x1i,x2i,…,xni)';i=1,2,…,q;n为样本数;xni表示第n个样本的第i个指标值。 (2) 建立变量的相关系数矩阵R。 (3) 求R的特征根λ1≥λ2≥…≥λq>0 及相应的单位特征向量u1,u2,…,uq: (4) 第i个主成分可以表示为: Fi=u1ix1+u2ix2+…+uqixq,(i=1,2,…,q) (5) 因而,主成分Logistic回归模型的基本形式可以设定为: (i=1,2,…,q) (6)非线性-主成分Logistic回归模型 为了更充分地提取舞弊识别信息,提高舞弊识别效率,构建非线性模型。借鉴Taylor展开式的非线性思想,在主成分Logistic回归模型的基础上,构建非线性-主成分Logistic回归模型。以6个变量为例,主成分Logistic回归模型可以写为: f(F1,F2,F3,F4,F5,F6)= Rn(F1,F2,F3,F4,F5,F6) 其中,Rn(F1,F2,F3,F4,F5,F6)是余项。记 f(F)=f(F1,F2,F3,F4,F5,F6) 从而,基于二阶Taylor展开、省略余项的非线性-主成分Logistic回归模型可以写为: 其中,α0为常数项,αi、βi及γij为系数。 三、实证结果与分析 (一)样本与数据 基于证监会、财政部、沪深交易所等监管机构对沪深A股上市公司的处罚公告筛选舞弊样本,多年连续舞弊样本仅取其舞弊最早年度。在此基础上,删除金融保险行业样本公司;考虑数据可得性,删除上市前舞弊样本及舞弊前一年数据缺失的舞弊样本,最终获得73家舞弊样本公司。统计发现,其中制造业公司占舞弊样本59%,与中国上市公司行业分布比例一致。以交易所相同、主营业务行业相同、 资产规模相同或相近为标准,按照1:1比例匹配非舞弊样本公司。样本数据来自国泰安上市公司违规处理数据库,样本期间为1996—2011年。 为了检验模型识别效果,将样本分为训练集和测试集。考虑先建立模型后使用模型的时间顺序,以1996—2002年的106家样本公司为训练集,舞弊和非舞弊公司各53家;以2003—2011年的40家样本公司为测试集,舞弊和非舞弊公司各20家。 (二)变量多重共线性检验 由于Logistic回归对变量多重共线性敏感,在构建回归模型之前需要对解释变量进行共线性检验。已知容忍度是衡量变量多重共线性的常用指标,该指标值小于0.2表示变量存在明显的多重共线性,指标最大值为1,意味着变量相互独立。如表2所示,对15个解释变量进行多重共线性检验发现,变量存在较明显的多重共线性,违背了线性回归模型的经典假设,有必要进行变量约简以消除共线性,本文采用主成分分析法。 表2 解释变量多重共线检验表 (三)主成分分析 对15个会计舞弊识别指标提取主成分,并以特征值大于1为标准保留主成分。特征根及方差贡献率如表3所示: 表3 特征根及方差贡献率表 大于1的特征根对应的单位特征向量如表4所示。 第一主成分中,x11财务杠杆和x15AltmanZ分值的系数绝对值较大,因此可以把第一主成分看成是反映长期偿债能力和财务健康度的综合指标;第二主成分中,x3存货比例和x14速动比率的系数绝对值较大,因此可以把第二主成分看成是反映应计项目和短期偿债能力的综合指标;第三主成分中,x4应收账款周转率和x6总资产周转率的系数绝对值较大,因此可以把第三主成分看成是反映营运能力的指标;第四主成分中,x7总资产利润率和x8净资 表4 单位特征向量表 产利润率的系数绝对值较大,因此可以把第四主成分看成是反映盈利能力的指标。 以特征根最大的第一主成分F1为例,将其表示为原始变量的线性组合: F1=0.044x1-0.184x2-0.136x3+ 0.007x4+0.055x5-0.067x6+ 0.376x7+0.257x8+0.124x9- 0.163x10-0.468x11-0.154x12+0.433x13+ 0.173x14+0.479x15 其中,x1,x2,…,x15为标准化后的数据,按上式计算各样本公司主成分值。 (四)非线性-主成分Logistic回归模型 使用训练集样本数据,以特征根大于1的6个主成分及其二次项和交叉项为自变量,采用向后逐步选择的Wald方法,设定变量的概率值小于0.05则进入模型,大于0.10则从模型中剔除,最后建立的非线性-主成分Logistic回归模型如下: 0.431F1F5+0.640F2F4 (五)模型识别效果对比 为了对比改进后的非线性-主成分Logistic回归与传统线性Logistic回归和线性-主成分Logistic回归模型的会计舞弊识别效果,使用训练集样本数据,分别以15个解释变量或15个主成分为投入变量,采用向后逐步选择的Wald方法,设定变量的概率值小于0.05则进入模型,大于0.10则从模型中剔除,得到线性Logistic回归模型和线性-主成分Logistic回归模型如下: 18.536x3-3.819x10+8.205x11- 0.0716x12+3.980x14 经试算取0.4为分类阈值,p>0.4判定为舞弊公司,p≤0.4判定为非舞弊公司,各模型对样本训 练集及测试集的识别正确率如表5所示。 表5 模型识别效果对比表 其中,-2Log likelihood为似然函数值自然对数的-2倍,值越小表示拟合越好。Cox&SnellR2和NagelkerkeR2值越大表示模型拟合越好。对比发现,不论从模型拟合优度,还是舞弊识别效果看,非线性-主成分Logistic回归模型都比线性Logistic回归和线性-主成分Logistic回归模型更优。由于主成分之间互不相关,非线性-主成分Logistic回归模型的参数估计比线性Logistic回归模型更为可靠。从识别正确率上看,非线性-主成分Logistic回归模型对训练集具有更高的总体识别率。尽管线性-主成分Logistic回归模型对测试集的总体识别率略高,但其以损失对舞弊公司10%的识别正确率为代价,误判成本过高。 四、结论与建议 近年来,会计舞弊行为呈现更加隐蔽化的趋势,舞弊公司大多已经摒弃了原来简单地在账面上做手脚的手法,转而寻求更加隐蔽和复杂的财务-业务全流程造假。学术界针对会计舞弊识别长期以来沿用的线性建模思路日益显得捉襟见肘,难以达到及时发现和遏制会计舞弊的目的。鉴于这一研究缺陷,本文借鉴Taylor展开式的非线性思想,并使用主成分分析法消除变量多重共线性,构建了非线性-主成分Logistic回归的会计舞弊识别模型。结果表明,相比线性Logistic回归模型,该模型能够更好地识别和预测会计舞弊。启示我们,在今后的会计舞弊识别研究中,打破线性建模的简单化思路构建非线性模型有助于更加充分地提取舞弊识别信息,提高舞弊识别效率。 参考文献: [1]Albrecht W S, Romney M B. Red-flagging Management Fraud: A Validation[J]. Advances in Accounting, 1986(3). [2]Loebbecke J K, Willingham. Review of SEC Accounting and Auditing Enforcement Releases[D]. Working paper, University of Utah, 1988. [3]Beasley M S. An Empirical Analysis of the Relation between the Board of Director Composition and Financial Statement Fraud[J]. The Accounting Review, 1996, 71(4). [4]Summers S L, Sweeney J T. Fraudulently Misstated Financial Statements and Insider Trading: An Empirical Analysis[J]. Accounting Review, 1998, 73(1). [5]Beneish M. Incentives and Penalties Related to Earnings Overstatements that Violate GAAP[J]. The Accounting Review, 1999, 74(4). [6]Lee T A, Ingram R W, Howard T P. The Difference between Earnings and Operating Cash Flow as An Indicator of Financial Reporting Fraud[J]. Contemporary Accounting Research, 1999, 16(4). [7]Bell T, Carcello J. A decision Aid for Assessing the Likelihood of Fraudulent Financial Reporting[J]. Auditing: A Journal of Practice & Theory, 2000, 9(1). [8]Spathis C. Detecting False Financial Statements Using Published Data: Some Evidence from Greece[J]. Managerial Auditing Journal, 2002, 17(4). [9]Green B P, Choi J H. Assessing The Risk of Management Fraud through Neural Network Technology[J]. Auditing A Journal of Practice &Theory,1997, 16(1). [10]Fanning K, Cogger K. Neural Network Detection of Management Fraud Using Published Financial Data[J]. International Journal of Intelligent Systems in Accounting, Finance and Management, 1998, 7(1). [11]郑朝晖. 上市公司十大管理舞弊案分析及侦查研究[J]. 审计研究, 2001(6). [12]李若山,金彧昉,祁新娥. 对当前中国企业舞弊问题的实证调查[J]. 审计研究, 2002(2). [13]成慕杰, 李忠宝. 上市公司会计造假的手段及其甄别[J]. 商业研究, 2002(24). [14]李延喜, 高锐, 包世泽, 等. 基于贝叶斯判别的中国上市公司利润操纵识别模型研究[J]. 预测, 2007, 26(3). [15]韦琳, 徐立文, 刘佳. 上市公司财务报告舞弊的识别——基于三角形理论的实证研究[J]. 审计研究, 2011(2). [16]洪荭, 胡华夏, 郭春飞. 基于GONE理论的上市公司财务报告舞弊识别研究[J]. 会计研究, 2012(8). [17]房琳琳. 财务困境上市公司财务报告舞弊预警模型研究[J]. 经济与管理研究, 2013(10). [18]金花妍, 刘永泽. 基于舞弊三角理论的财务舞弊识别模型研究——支持向量机与Logistic回归的耦合实证分析[J]. 大连理工大学学报:社会科学版, 2014, 35(1). [19]李双杰, 陈星星. 基于BP神经网络模型与DEA模型的中国上市公司利润操纵研究[J]. 数理统计与管理, 2013(3). [20]李清, 任朝阳. 基于案例推理的财务报告舞弊识别研究[J]. 财经理论与实践, 2015, 36(3). [21]李清, 于萍. 财务危机预测主要方法比较研究[J]. 数理统计与管理, 2012(4). [22]Altman E T. Financial Ratios, Discriminant Analysis and Prediction of Corporate Bankruptcy[J]. Jouranl of Finance, 1968(9). (责任编辑:马慧) Using Nonlinear-Principal Component Logistic Regression for Accounting Fraud Identification LI Qing, REN Chao-yang (Business School, Jilin University, Changchun 130012, China) Abstract:Chaos theory suggested that most of human behavior appeared to be non-linear. Accounting fraud belonged to the field of behavior accounting. Traditionally, fraud identification model based on statistical theory limited to linear constraint assumptions mostly. There may be such defects as model specification errors and information extraction insufficiently. It chose Shanghai and Shenzhen A-share listed companies subject to regulatory sanctions and matching companies as samples. Based on the nonlinear ideology of Taylor expansion, and the principal component analysis to eliminate variables multicollinearity, it constructed a nonlinear - principal component Logistic regression of accounting fraud recognition model. The model has a higher recognition accuracy ratio, more reliability on parameter estimation and has higher goodness of fit than the linear regression model. The model is helpful to extract fraud identification information more fully, and improves the efficiency of fraud identification. Key words:nonlinear; principal component analysis; Logistic regression; accounting fraud identification 中图分类号:F234 文献标志码:A 文章编号:1007-3116(2016)03-0075-06 作者简介:李清,男,黑龙江逊克人,教授,博士生导师,数量经济学博士,研究方向:会计数据挖掘与会计信息系统; 基金项目:吉林省社会科学基金项目《吉林省上市公司内部控制指数构建与风险预警研究》(2014B21) 收稿日期:2015-10-30 任朝阳,男,河南新密人,博士生,研究方向:会计舞弊识别与治理。 【统计应用研究】