稀有类分类问题研究
2016-04-06毛海涛郭华平
毛海涛,郭华平
(信阳师范学院 计算机与信息技术学院,河南 信阳 464000)
稀有类分类问题研究
毛海涛,郭华平*
(信阳师范学院 计算机与信息技术学院,河南 信阳 464000)
摘要:稀有类问题又称为不平衡类问题,可以描述为从一个分布极不平衡的数据集中识别那些所占比例极少却意义显著的少数类实例。识别并正确分类稀有类实例,对现实生活具有重要的意义。本文探讨了稀有类的特征、影响稀有类分类的因素,重点阐述了现行的稀有类分类方法。
关键词:稀有类;分类;分类方法;评价标准
稀有类问题又称为不平衡类问题,可以描述为从一个分布极不平衡的数据集中识别那些所占比例极少却意义显著的少数类实例。在实际应用领域,正确识别并分类稀有类实例往往比正确识别多数类实例如更有意义。例如,医疗诊断过程中,绝大多数检验者为健康人只有少数检验者为癌症患者,显然,如何识别少数癌症患者比正确识别健康人更为重要。
在不平衡数据集中稀有类实例数目所占比例非常稀少,分布不平衡,因此传统的分类算法在分类稀有类时效果不佳。本文从稀有类的特征,影响分类的因素,主要分类方法及评价标准等方面对现阶段业界在稀有类分类问题的研究给予论述。
1稀有类问题的特征
(1)稀有且难区性:在数据集中,目标类样本所占比例非常稀少,分布又不平衡,稀有类实例的识别区分度非常低,难于区分。
(2)广范应用性:稀有类分类问题广泛应用于生活的各个领域,如:疾病诊断、网络安全监测、军事情报分析等。以社会安全分析为例,在和平稳定的社会大环境下,大多数的安全分析都是正确的,如果极端暴恐小概率事件不能提前有效分析出来,就会对国家安全造成难以估量的影响。
(3)复杂多态性:多数类和目标类都有多个子类,不同的子类又具有不同的特性,从而导致分类情况更加复杂。
2影响稀有类分类效果的因素
目前分类有很多经典的算法,如:贝叶斯算法[1]、决策树算法[2]、神经网络学习算法[3]、SVM算法[4]、Adaboost[5]、Bagging[6]等。
不过在不平衡数据集的使用过程中,上述几种算法的准确率不是很高[7]。经研究发现,稀有类分类的准确率受诸多因素影响。
2.1不平衡的类分布影响分类效果
在不平衡数据集中,目标类样本所占比例非常低,数据分布不平衡,难以构建恰当的算法模型,造成数据分类准确率不高。
2.2不恰当的评价标准影响分类性能
在数据挖掘领取,衡量分类器的主要依据是评价标准,在传统的分类算法中,衡量算法性能的主要指标是分类正确率。但是,不平衡数据集不同于正常的数据集,仅以正确率来评价不平衡数据集的分类优劣性,有失偏颇。
2.3不恰当的归纳偏置影响样本分布
传统算法在应用过程中,归纳特定样本时都会设置一个偏置[8]。通过归纳偏置,可以提高分类器的泛化能力。但在稀有类的分类过程中,如果同样使用归纳偏置,就会把少数类样本误分为多数类,导致错误的分类结果,影响分类精度。
3稀有类数据常用分类方法
在一般的分类过程中,经常会采用抽样的分类方法。在对稀有类分类进行研究时,也可以使用抽样的分类方法。抽样算法的基本思想是通过抽样来改变数据集中的样本分布。在抽样过程中平衡数据分布,在平衡的数据集上构建学习模型,如随机过采样[9]、SMOTE[10]、随机欠采样[11]以及综合采样[12]等算法。
3.1随机过采样
随机过采样算法的核心思想是从稀有类中随机抽取一个样本集E并将其加入的训练数据集中。具体地,假设数据集中稀有类(正类)样本集为Dp,使用又放回重复抽样方法从Dp中抽取一个子集E,并将该子集加入到源训练数据集D中。通过这种方法,Dp的大小增加了|E|,进而相应地调整了D的数据分布。该过程如图1所示,其中,▲代表稀有类样本,○代表多数类样本。值得注意的是,这种方法提供了一种随意改变数据分布的一种机制。同时,该方法既容易理解也容易可视化,因此,该方法一直受到研究者们的关注。

不均衡数据集 均衡数据集不均衡数据集均衡数据集
图1随机过采样将不均衡数据集转换为均衡数据集图2随机欠采样将不均衡数据集转换成均衡数据集
3.2随机欠采样
与随机过采样向训练数据集中添加样本的做法不同,随机欠采样技术则是通过随机的移除多数类样本以调整数据样本分布。具体地,设Dn为负类样本集,从Dn选择一个子集E,并从D中移除这些实例集,直到|D| =||Dn| +|Dp|-|E|。该过程如图2所示,其中,▲代表稀有类样本,○代表多数类样本。
比较过抽样和欠抽样技术,我们容易发现,他们的功能似乎很相似,其原因是他们都能改变原始数据集的大小,同时能保证处理后的数据集是平衡的,即:多数类和少数类实例数目相当。当然,这两种方法各存有不足之处,例如,在欠抽样技术中,从多数类实例中移除大量的负类样本有可能导致分类器不能获得保留在负类样本中的概念模式。在过抽样技术中,随机的添加重复的样本可能导致某些样本出现频度过高,进而导致模型过分拟合训练数据集。
3.3SMOTE算法
SMOTE(Synthetic Minority Oversampling TEchnique)是一种典型的人工合成过抽样技术,该技术已经成功地应用到很多实际应用中。该技术根据正类实例间的特征相似性来人工合成新的正类实例。具体如下,对于正类实例集Dp∈D,考虑Dp中的每个实例xi∈Dp的k-近邻,其中该k-近邻定义为Dp中的k个实例与xi的欧几里德距离最小的前k个实例。然后,从这k-近邻中随机的选择一个近邻,并在相应的特征向量上乘以一个[0, 1]的因子,并加上xi以获得新实例,形式化地
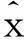
3.4综合采样技术
当采用欠采样技术进行分类时,多数类在分类过程中会丢失有用的信息;而当采用过采样技术进行分类时需要增加很多训练时间和复杂度来处理少数类数据,甚至会使分类器过分拟合。通过研究发现,可以将欠采样和过采样技术进行整合,也可以很好地解决不平衡数据集的分类问题,这种新技术就是综合采样技术。
参考文献:
[1]D.Heckerman.Bayesian Networks for Data Mining[J].Data Mining and Knowleged Discovery, 1997:79-119.
[2]K. Alsabti, S. Ranka , and V. Singh.CLOUDS: A Decision Tree Classifier for Large Datasets[C]. In Proc. of the 4th Intl. Conf. on Knowledge Discovery and Data Mining, New York, 1998:79-119.
[3]C.M.Bishop.Neural Networks for Pattern Recognition[J].Oxford Univerity Press,Oxford,U.K., 1995.
[4]Duda,R.O,Hart,P.E,Stork,D.G李虹东,姚天翔译.模式分类[M].第二版.北京:机械出版社, 2007:373-375.
[5]E.S.Robert.Theoretical view of boosting[C]//In:Proc of Europea rence on Cn Confeomputational Learning Theory. Nordkiechen, germany. Springer-Verlag, 1999:1-10.
[6]L.Breiman.“Bagging predictors” Machine Learning. 1996,24(1):123-140.
[7]高嘉伟,梁吉业.非平衡数据集分类问题研究进展[J].计算机科学,2008,35(4):10-13.
[8]谷琼.面向非均衡数据集的机器学习及在地学数据处理中的应用[D]. 武汉:中国地质大学,2009.
[9]Shao Kuoyi,Zhai Yun,Sui Haifeng et al.A New Over-sample Method Based on Distribution Density[J].Journal of Computers, 2014,9(2):483-490.
[10]N.V.Chawla,K.W.Bowyer.SMOTE:synthetic minority over-sampling technique,Journal of Artificial Intelligence Research. Vol 2002 (16):341-378.
[11]C.Li. Classifying Imbalanced Data Using A Bagging Ensemble Variation (BEV). Proceedings of the 45th annual southeast regional conference,March 23-24, 2007, Winston-Salem, North Carolina.
[12]J.Laurikkala.Improving Identification of Difficult Small Classes by Balancing Class Distribution. Proceedings of the 8th Conference on AI in Medicine Europe:Artificial. 2001:63-66.
(编辑:严佩峰)
On the Classification of Rare Class
MAO Hai-tao,GUO Hua-ping
(School of Computer and Information Technology, Xinyang Normal University,Xinyang 464000, China)
Abstract:Imbalanced problem, also called class-imbalance problem, is characterized as recognizing the rare class examples from the data with severe class distribution skews. However, it is very important to correctly classify the rare class examples. In this paper, we study the characters of imbalance problem, the factors influencing its performance, the classifier method and the corresponding evaluations.
Keywords:rare class;classification;classification methods;evaluation measure
中图分类号:TP274
文献标识码:A
文章编号:2095-8978(2016)01-0121-03
作者简介:毛海涛(1983—),男,河南上蔡人,助教,硕士,主要研究方向为数据挖掘,数字图像处理.*通讯作者:郭华平(1982—),男,河南固始人,讲师,博士,CCF会员(No. E200034572M),主要研究方向为机器学习、数据挖掘.
基金项目:信阳师范学院2015年度青年基金项目(15044)
收稿日期:2015-10-26
