基于深度学习与图数据库构建中文商业知识图谱的探索研究
2016-03-29王仁武袁毅袁旭萍
王仁武 袁毅 袁旭萍


摘 要: 将知识图谱应用到商业领域是大数据时代企业的迫切需求。文章通过引入深度学习算法中的深度置信网络,自动提取领域信息中蕴含的知识单元及单元之间的关系,以此解决知识单元提取这一难点。同时,采用Neo4j图形数据库来存储知识图谱中包含的知识单元及其关系。当需要对知识图谱中包含的知识单元进行查询时,可以采用该图形数据库的Cypher查询语言进行查询。文章的研究方法可为商业领域快速构建知识图谱提供借鉴。
关键词:知识图谱;深度学习;图数据库;深度置信网络
中图分类号: G203 文献标识码: A DOI:10.11968/tsyqb.1003-6938.2016017
Study on the Construction of Chinese Knowledge Graph Based on Deep Learning and Graph Database
Abstract Application of Knowledge graph to business areas is the urgent need of the enterprises in big data era. In order to solve the knowledge element extraction difficulties, the author tries to automatically extract the knowledge units and its relationships contained in the given field by introducing the deep belief network learning algorithm. At the same time, the knowledge unit and its relationship in the knowledge graph are stored by using the Neo4j graphics database. When you need to query the knowledge unit in the knowledge graph, the Cypher query language of the graph database can be used. The research method of this paper can provide reference for the rapid construction of knowledge graph in the commercial field.
Key words knowledge graph; deep learning; graph database; deep belief networks
1 引言
近些年,随着大数据时代的到来,传统的用于学科研究的科学知识图谱[1]也开始在其他领域有所应用。Google早在2012年就发布了其知识图谱产品—Google Knowledge Graph[2]。2013年2月,百度也推出了自己的知识图谱。“打开手机百度,用户搜索‘王菲的时候不仅可以查到她的歌曲,还能知道她的前夫是李亚鹏,李亚鹏的前女友是周迅,周迅和汤唯恰好是同乡”,这就是基于大数据技术的知识图谱,百度为用户编织了三维知识网络,满足其对日益增长的知识获取需求。近年来,还涌现了一些较有影响的知识图谱,包括YAGO[3] 、DBpedia[4] 、NELL[5] 、Freebase[6] 等,这些知识图谱包含数以百万计的节点和数十亿的边。另外,在社交网络领域,Facebook和Twitter则推出了社交图谱和兴趣图谱。知识图谱在商业领域的应用,扩展了原先科学知识图谱的内涵,也使得它的应用场景得到了延伸。
商业领域中的信息不同于学科领域的信息,以往对学科领域的知识图谱研究多基于文献来进行研究,关键词、摘要等信息可以作为绘制知识图谱的重要信息来源。而商业领域中的信息相比学科领域要更加杂乱无序,因此,对这些信息进行语义分析,提取出能用于绘制知识图谱的知识单元并找出知识单元之间的联系就显得极为重要。
提取用于绘制知识图谱的知识单元可以映射为对大量信息的命名实体进行识别,而寻找知识单元之间的关系也可以映射为对命名实体关系的抽取,两者都可以通过机器学习的方法进行。以往在对命名实体的识别和实体关系抽取的时候,人们通常会选择SVM(支持向量机)或CRF(条件随机场)之类的浅层学习方法,系统还需要融入大量适用于特定学习任务的人工特征,从而会导致部分特征的丢失。
深度学习作为一种模拟人类认知行为的算法,它会像人类的大脑一样按照层次来对概念进行组织。它会学习最简单的概念,然后根据这些简单的概念组成更加抽象的概念,逐层深入,通过对低层特征的组合,形成越来越抽象的深层表示,从而能达到更准确的认知。将深度学习用到对知识单元和单元之间的关系的提取中,可以为知识图谱的绘制提供良好的基础;同时,图数据库是使用节点、边、属性等图数据结构来表示和存储信息,比较适合知识图谱的存储。
2 知识图谱构建的相关研究概述
2.1 商业知识图谱的构建方法
目前商业领域知识图谱构建方法根据知识图谱数据来源划分,可以分为以下几种:
(1)基于网络百科资源的知识图谱构建方法。以维基百科为例,可以通过它的文章页面的关系来采集各类实体、实体的同义词、同音异义词以及实体的概念及其上下文关系和实体对应的类别。AVP 知识抽取(Attribute-value Pairs Mining)是一种知识图谱信息提取的重要方法,采用这种方法可以提取出百科类资源中包含的属性-值对信息[7]。
(2)基于结构化数据的知识图谱构建方法。RDF是一种资源描述框架,可以形式化地表示结构信息,它一般用来描述网络资源,例如某个Web页面的内容、作者等。采用RDF可以对知识进行结构化组织,进而采用图形化的方式展示出来[8]。
(3)基于半结构化数据的知识图谱构建方法。主要是一些中文百科类的站点中,数据的结构化程度远比不上维基百科,许多属性隐藏在一些半结构化的表格或列表中,可以采用模式学习的方法构建一个或多个模式来实现自动化的信息抽取,但是需要通过人工调整或新增模式等方法来进行改进与提高[9] 。
(4)基于非结构化数据的知识图谱构建方法。许多特定领域缺乏结构化和半结构化的知识来源,此时非结构化数据是主要的知识数据来源。它比较复杂,目前应用并不广泛。前面提到的NELL(Never-Ending Language Learning)系统旨在从数亿的网页中根据输入的本体抽取知识实体以及这些知识间的联系。
2.2 商业知识图谱的构建过程
在知识图谱的构建方面,叶六奇等[10]将知识图谱的构建分为3个部分:要素识别、关联分析、结构化展示。此外杨思洛等[11]也给出了知识图谱的构建流程,这些流程虽然各有差异,但都提到了知识图谱绘制中最重要的环节:构建知识单元、构建单元关系、知识图谱的结构化展示。
在构建商业知识图谱时,由于信息来源具有多样性,如何对半结构化、非结构化的信息进行处理,抽取出有效的知识单元是一个重要的议题。当前采用较多的技术主要是利用文本挖掘对知识单元进行抽取。Hao等[12]通过TF-IDF算法抽取出文本中重要的单元,从而构建出某个领域的知识地图。Ong等[13]利用词频统计和PAT-tree等技术从文本中抽取出重要的知识单元,随后采用SOM神经网络算法将知识单元进行分类,针对中文的金融和健康领域的在线新闻提供了一种可视化的图形展示。Liu等[14]抽取复合电子服务的属性元数据作为知识单元,通过主题图的方法构建知识图谱。张静[15]认为可以采用自动标引技术解决这一问题。
为发现知识间的关系,更好地展示各单元,则需要样本数据的进一步处理,即简化分析。当前采用较多的方式有关联分析、因子分析、多维尺度分析、自组织映射图(SOM)、寻址网络图谱(PTNET)、聚类分析、潜在语义分析、最小生成树法等。
在知识图谱的存储研究中,目前主要是RDF数据库和图数据库,从顶向下设计的RDF数据库没有从底向上设计的图数据库成功,图形数据库在存储知识图谱的知识单元和单元关系上效果最佳。目前,图形数据库并没有一套完整的标准,但是大部分图形数据库都包含了节点、关系、属性这三个元素。节点可以用来存储知识单元,关系可以用来展示知识单元之间的联系,属性可以表征知识单元的相关特性。目前使用较多的图形数据库主要有Neo4j[16]、FlockDB[17]、TAO等。
3 基于深度置信网络的中文知识单元及其关系识别
在知识图谱的构建中,最重要的三个环节就是知识单元的抽取、知识单元间关系的识别,以及知识图谱的存储与使用。其中尤以知识单元抽取和知识单元间关系的识别最为关键。本文为了研究方便,将知识单元的抽取、知识间关系的识别映射为命名实体的识别和实体关系的识别。命名实体识别是指识别文本中包含的以名称为标识的命名实体,包括人名、组织名、地名等基于深度学习算法的商业知识图谱构建流程(见图1)。
这个流程中在命名实体识别阶段,由于中文文本没有明确的分词边界,需要首先对文本进行分词,然后针对特定的场景,选择适当的特征并构建特征向量用于后续模型的学习与测试,之后便是模型的训练与测试。在实体关系识别阶段,仍然需要选择合适的特征并构建特征向量,然后进行模型训练与测试。
3.1 深度置信网络
深度置信网络(Deep Belief Network,DBN)是深度学习领域的经典算法之一。它通常由多个受限玻尔兹曼机(RBM)和一层反向传播网络(BP)组成,其中受限玻尔兹曼机是无监督的,而反向传播网络则是有监督的。
在深度置信网络的训练过程中,首先会无监督地训练每一层RBM网络,以将数据样本的内在特征映射到不同的特征空间中,然后利用BP网络有监督地训练,将之前学习到的特征组合进行分类,并且通过反向传播对参数进行调整,最终获取深度置信网络的最优参数(见图2)。
其中,深度置信网络包括3个RBM层和1个BP层。其中V0是输入层,接受原始的样本数据,H0是第一层的隐藏层。样本输入至输入层后,模型会先学习V0和H0层之间的参数W0。第一层训练好后,第一层的隐藏层H0会作为第二层RBM网络的可视层V1,V1和H1一起组成第二层的RBM网络,此时模型会训练第二层RBM的参数W1。假设以n代表RBM的层数,则第n-1层的输出会作为n层的输入,模型会学习第n层RBM网络的参数Wn-1。结束所有的RBM网络训练后,深度置信网络进入反向传播阶段,此时,BP网络会根据输出与期望输出的误差对参数进行调整,以达到深度置信网络的最优参数。
3.2 中文命名实体识别
(1) 命名实体识别。目前,命名实体识别主要采用的有基于实体词典的方法,基于实体规则的方法,以及基于机器学习的方法。与前两种方法相比,机器学习的方法能够利用标注过的语料来学习,学习后的模型可以直接应用到该领域的命名实体识别中。
(2) 命名实体识别中的特征选择。深度置信网络对命名实体进行识别时,需要输入命名实体的特征向量。可以选取的命名实体的特征有字特征、词特征、词性特征、上下文窗口特征等。本文选择词特征、词性特征、上下文窗口特征、词典特征、其他统计特征来对命名实体进行描述。
①词特征:将分词后的所有词组成字符表D={d_1,d_2,…,d_n},其中d_i表示一个词,i∈[1,n]。将每个词E的词特征向量表示为V(E)={v_1,v_2,…,v_n},其中v_i代表该词是否对应字符表D中的d_i,v_i的计算方式如下:
②词性特征:词性特征的构建与词特征的构建方式一致。首先构建词性表D={d_1,d_2,…,d_m},假设该词E的词性为p,则该词的词性特征向量为V(E)={v_1,v_2,…,v_m},其中v_i代表该词的词性是否对应词性表D中的d_i,v_i的计算方式如下:
③上下文窗口特征:在一段文本中,连续多个词组成的上下文窗口有时也会存在一定的规律,如新闻中阐述某个人的观点时,通常会使用“陌陌CFO张晓松表示”类似的表述方式,此时分析该词的上下文窗口就可以为该词的识别提供依据。通过“张晓松”后面的“表示”一词可以初步判定“张晓松”为人名,而通过“陌陌”后面的“CFO”可以初步判定“陌陌”为公司名。上下文窗口可以根据具体场景进行设置,如设置为3,则表示选择该词的前一个词和后一个词纳入到分析中,如设置为5,则表示选择该词的前两个词和后两个词纳入分析。
词典特征可以选择与实体相关的词组成词典,如人物的称谓、组织机构的后缀等组成词典。同样采用上文提到的特征向量构造方式构造每个词的特征向量,假设词典为D={d_1,d_2,…,d_n},将每个词E的词特征向量表示为V={v_1,v_2,…,v_n},其中v_i代表该词是否对应词典D中的d_i,v_i的计算方式见公式(1)。
其他统计特征在命名实体识别时,同样可以增加一些统计特征进行计算,如自然语言处理中经常使用的TF-IDF。
3.3 中文命名实体的关系识别
(1)实体关系识别。实体关系是指实体间存在的语义关系,其中这些语义关系可以是显性的,也可以是隐性的。例如从“阿里巴巴负责人马云”这个描述中可以看出,“阿里巴巴”和“马云”是两个实体,其中,“阿里巴巴”是组织机构名,“马云”是人名,他们之间的联系属于角色关系,“马云”隶属于“阿里巴巴”。ACE(Automatic Content Extraction)是一个全球性的信息抽取项目,该项目主要解决信息抽取中的实体抽取、关系识别和事件识别。它将实体关系分为了以下几类:Role(角色关系)、Part(整体与部分的关系)、At(位置关系)、Near(邻近关系)、Social(社交关系)等。除了ACE列出的实体关系,还可以根据不同的情况定义不同的实体关系,如作者与著作之间的从属关系等。
目前,实体关系识别主要采用三种方法:基于模式匹配的方法、基于特征的方法和基于核函数的方法。基于特征的方法采用句法分析及词法分析将关系实例转化为特征向量,继而可采用机器学习模型进行处理,计算特征向量的相似度,并对实例关系进行分类。采用基于特征的方法,一般需要基于大量的数据构造完整的特征,常用的特征包括词特征、词性特征、语义特征、实体属性特征等。这些特征的提取又依赖于对语料的预处理工作,一般预处理效果越好,实体识别效果越好。本文采用基于特征的方法,通过深度置信网络算法对中文实体之间的关系进行识别,采用这种方法可减少大量的人工参与,使特征的提取更加简单有效。
(2) 实体关系识别中的特征选择。在实体关系识别中,将实体对作为分析的数据,一般选择字符特征、实体的类型特征、实体对的相对位置、上下文窗口特征等特征进行判别。目前大部分实体关系识别的研究都是基于句子级的,即研究同一个句子中两个实体之间是否存在关系。而对于一句话中研究的是两个实体之间的关系还是两个以上实体之间的关系没有一个统一的规范[18]。本文也采用句子级的粒度,研究一句话中任意两个实体之间是否存在联系。
本文对实体对的定义如下:假设一个句子中包含实体集SE={E_1,E_2,…,E_n},若存在E_i∈SE,E_j∈SE,且i≠j,则{E_i,E_j}为一个实体对。
本文选择实体特征、实体类型特征、实体对相对位置特征、实体间距离特征、上下文窗口特征作为实体关系识别的特征。
实体特征在命名实体识别阶段,曾经构造了词特征。这里的实体特征与命名实体识别的词特征相似,只不过将基于词的字符表改成了基于实体的字符表。加载实体特征中,字符表D存储所有的实体字符。D={d_1,d_2,…,d_n},其中d_i代表一个实体。每个实体对E1和E2的特征向量为V={v_1,v_2,…,v_n,v_(n+1),v_(n+2),…,v_2n}。特征向量的维数为D的两倍。v_i的计算方式如下:
实体类型特征:实体类型特征代表该实体属于哪个命名实体类别,如人名、机构名、地名等。对于一些特定的实体关系,实体的类别对于实体关系识别非常重要。如判断某人与某机构能否构成角色(Role)关系时,实体对必须满足有一个实体为人名类型实体,另一个实体为机构名类型实体。该特征能够描述实体对中的实体分别属于哪个类别,为实体关系的判别提供依据。
实体对相对位置特征:实体对的相对位置特征能够描述该实体对里的两个实体之间的位置关系。按照常识而言,实体之间的位置关系越靠近,这两个实体越有可能存在语义关系。实体间的相对位置关系一般有三种:嵌套、相邻以及分离。其中嵌套代表某个实体嵌套在另一实体中,相邻代表两个实体之间是相邻的,没有字符相隔,分离代表两实体之间由其他字符隔开了。
实体间距离特征:当两个实体之间是分离状态时,可以通过计算它们之间的距离来衡量它们分离的程度。实体间的距离特征主要计算两个实体间由多少个词隔开。
上下文窗口特征在实体关系识别中,上下文窗口特征仍然是一个重要的识别特征。尤其是两个实体中间的内容,往往对于识别实体间的关系具有重要的参考价值。如“河狸家创始人孟醒”这个表述中,“河狸家”和“孟醒”分别为一个公司实体和一个人名实体。这两个实体中间的“创始人”一词就描述了这两个实体之间的关系。因此,上下文窗口特征对于实体关系识别也有着重要意义。针对不同场景,可以建立不同的上下文窗口特征。
4 实验及结果分析
4.1 实验数据源及领域词典构建
实验采集了凤凰网科技频道下“移动互联”子频道的2014年1月1日到2014年3月31日5017条新闻文本,希望能准确识别出这些文本中包含的人名、公司名这两种命名实体,继而通过实体关系识别将形成角色关系的人名与公司名实体对识别出来。为了达到这个目的。实验对这5017条新闻文本进行分词,并人工标注分词后的实体,为模型训练和评估提供依据。
实验环境为Windows7操作系统,采用MySQL和Neo4j进行数据存储,其中MySQL用于存储,用来进行命名实体识别和实体关系识别的语料及特征数据,Neo4j存放识别后的命名实体和实体关系。数据预处理和建模工作采用Python进行。其中采用Python的Theano模块用来进行深度置信空间算法的训练和测试。
因移动互联网领域是个新兴领域,目前并没有完整的领域词典,实验对该领域词典进行了构建,以提高分词的准确性。词典的构建过程如下:首先对百度百科的词条标签进行分析,选择了“互联网”、“移动互联网”、“电子商务”、“科技”、“电子产品”、“数码”等56个标签;然后采用Python编写爬虫,爬取这56个标签下的词条,并对采集到的词条进行去重,得到32380个词条;最后由于采集的是百度百科的Tag页面下的词条,而Tag页面中最多只列出了76页词条,那些没有列出的词条没有办法通过程序直接采集。基于这个原因,实验通过人工查看数据集中的内容,补充没有采集到的词条,人工添加的词条共有346个。
加入自建的词典,对数据集进行分词。5017篇新闻分词及去停用词后得到257059个词。这些词用来进行命名实体识别。
4.2 命名实体识别
(1) 命名实体识别。主要是构建前面提到的词特征、词典特征等。构建这些特征需要大量的数据预处理过程,具体的数据预处理过程如下:
①语料的清洗。基于Web新闻采集下来的文本语料的分段与分句。在上下文窗口特征中,由于跨句子的上下文窗口词中包含的信息量较少,所以对每个词的上下文窗口词进行提取时,只提取该词所在句子中的前两个词和后两个词。这就要求对语料进行分句,每一句进行单独存储。分句后的数据存储至MySQL数据库中。
②提取每个词的上下文窗口词。其中,句子中的第一个词没有上文窗口词,故将其上文窗口词都设为空值,句子末尾的词的下文窗口词也设为空值。
③计算词特征、词性特征、词典特征。在计算上下文窗口特征时,为了尽可能多地获取词的上下文特征,将窗口设为5,提取该句子中当前词的前两个词和后两个词进行分析。并对每个词的上下文窗口词建立基于计算词特征与词性特征的词表和词性表的特征向量。最后再计算每个词对应与该新闻文本的TF-IDF值。
④本次实验采取有监督的学习方法,因此在实验前,需要人工对实体类型进行标注,经过标注和审查后,得到人名类的实体共3678个,公司名类的实体共5316个。
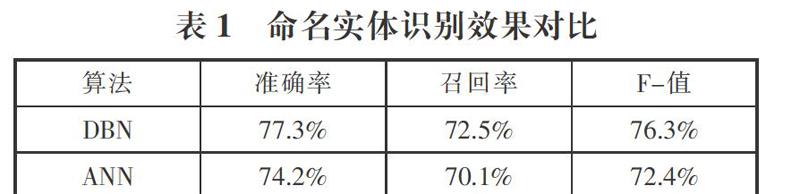
(2)实验结果分析。实验采用Python中的深度学习Theano包编写了基于深度置信网络(DBN)的命名实体识别程序,模型共包括三个隐藏层,各层节点均为1000个。采用70%的数据进行训练,30%的数据进行测试。并将实验结果(见表1)与人工神经网络(ANN)作了对比后发现,实验中深度置信网络的结果均高于采用浅层学习的人工神经网络,体现了深度学习的优势。
4.3 命名实体关系的识别
(1)命名实体的关系识别。基于命名实体识别部分识别出来的人名和公司名,在实体关系识别中,希望能将人名与公司名对应上,找出实体关系中的角色(Role)关系。需要做以下的数据预处理工作:
①实体对提取。提取语料中所有的实体对。每一个句子中出现的任意两个实体都标为一个实体对。每个实体对保存为如下格式:
其中,Sid代表该实体对所在的句子编号,Wid1 和Wid2代表这两个实体在分词后的词编号,Eid1 和Eid2代表这两个实体的实体标号,E1 和E2则存储这两个实体的具体内容,Etype1 和Etype2代表这两个实体的实体类别。
②计算实体特征、实体类型特征、实体对相对位置特征、实体间距离特征、上下文窗口特征。
(2)实验结果分析。实验仍然采用Python中的Theano深度学习包构建深度置信网络算法,仍然采用准确率、召回率和F-值衡量测试效果。从实验结果(见表2)数据上看,深度置信网络算法与人工神经网络算法相比,在召回率和F-值上都取得了相对较好的结果。
表2 实体关系识别效果对比
4.4 知识图谱的存储与使用
实验得到命名实体和实体关系后,将其存储在Neo4j图形数据库中,以便知识图谱的绘制和查询。Neo4j是一个稳定且成熟的,具有较高性能的图形数据库。具有完整的ACID支持、高可用性、可扩展性,通过Neo4j的遍历工具可以高速检索数据。Neo4j的查询语言是一种可以对图形数据库进行查询和更新的图形查询语言Cypher,它类似于关系数据库的SQL语言。Cypher的语法并不复杂,然而它的功能却非常强大,它可以实现SQL难以实现的功能。例如,六度分割理论中曾指出任何两个人之间所间隔的人不会超过六个。只要数据足够完整,采用Cypher可以很容易地找到任何两个人之间是通过哪些人联系起来的,而这一点SQL很难实现。
一段完整的Cypher查询通常是由一些子句组成的,Cypher的常用子句如下:
①MATCH子句:MATCH子句通常用来对数据库中的数据进行匹配,从而获取满足查询条件的数据。
②WHERE子句:WHERE严格意义上不能算是一个子句,它一般作为MATCH子句的一部分,指定查询需要满足的条件。这与SQL中的WHERE也是相似的。
③RETURN子句:RETURN子句指定查询需要返回哪些内容。
④CREATE子句:CREATE子句可以用来创建节点、关系或属性等。
假设我们需要创建一个名为“阿里巴巴”的节点,可以在查询区域输入“CREATE(n:Company {name:“阿里巴巴”});”。创建成功后,输入“MATCH(company:Company{name:“阿里巴巴”}) RETURN company”既可以将该节点展示出来。
图3展示了基于部分实验数据所绘制的知识图谱。其中图的左上角采用图示标注了不同颜色节点代表的实体类型,图形区域展示了company类型实体、person类型实体及两类实体之间的角色关系。
图4是知识图谱的一个查询实例。假设我们需要获取“中国手游”这个公司的公司成员,可以在Neo4j的查询页面输入“MATCH (a:company{name:"中国手游"})<-[r:Role_of]-(p) return a,r,p”,从而获得该公司的公司成员。从图4中可以看出,“应书岭”、“孙晶艺”、“肖健”与“中国手游”都有Role_of的关系,即这三个人都是“中国手游”公司的成员。
5 结语
商业知识图谱与学科知识图谱在构建方面存在很大的区别,在商业知识图谱构建中,如何自动地提取大量文本中隐藏的知识单元和知识单元之间的关系一直是有待解决的技术难题。为了解决这两大难题,本文将深度学习算法引入到商业知识图谱的构建中,采用命名实体识别和实体关系识别这两大机器学习的任务来解决知识单元抽取和知识单元关系抽取这两个难题。此外,本文还将图形数据库纳入到构建商业知识图谱的体系中来,采用图形数据库对知识单元进行存储及展示,为商业知识图谱的绘制提供了一种思路。进一步的研究工作可以将深度学习用于商业领域的中文分词及业务命名实体及其关系识别上,研究不同深度学习框架的应用效果;同时图数据库在商业知识图谱构建上应有较大的空间,本文只是作了一些探索,深入研究还有待展开。
参考文献:
[1] 梁秀娟. 科学知识图谱研究综述[J]. 图书馆杂志, 2009 (6): 58-62.
[2] A.Singhal,“Introducing the Knowledge Graph:things,not strings,”[EB/OL].[2015-11-20].http://googleblog.blogspot.com/2012/05/introducing-knowledge-graph-things-not.html.
[3] F. M. Suchanek, G. Kasneci, and G. Weikum,“Yago:A Core of Semantic Knowledge,” in Proceedings ofthe 16th International Conference on World Wide Web[C].New York, NY, USA:ACM, 2007:697-706.
[4] S. Auer, C. Bizer, G. Kobilarov, J. Lehmann,R. Cyganiak, and Z. Ives,“DBpedia: A Nucleus for a Web of Open Data,” in The Semantic Web[M]. Springer Berlin Heidelberg, 2007:722-735.
[5] A. Carlson, J. Betteridge, B. Kisiel, B. Settles, E. R. H.Jr, and T. M. Mitchell,“Toward an Architecture for Never-Ending Language Learning,” in Proceedings of the Twenty-Fourth Conference on Artificial Intelligence(AAAI 2010)[C].AAAI Press, 2010:1306-1313.
[6] K. Bollacker, C. Evans, P. Paritosh, T. Sturge, and J. Tay-lor, “Freebase: a collaboratively created graph database for structuring human knowledge,” in Proceedings of the 2008 ACM SIGMOD international conference on Management of data[C]. ACM,2008:1247-1250.
[7] Wu F, Weld D S. Autonomously semantifying wikipedia[C].Proceedings of the sixteenth ACM conference on Conference on information and knowledge management. ACM, 2007: 41-50.
[8] 项灵辉. 基于图数据库的海量RDF数据分布式存储[D].武汉:武汉科技大学, 2013.
[9] 王昊奋.知识图谱技术原理介绍[EB/OL].[2015-11-25].http://wenku.baidu.com/view/b3858227c5da50e2534d7f08.html.
[10] 叶六奇,石晶. 知识地图的构建方法论研究[J].图书情报工作,2012(10):30-34.
[11] 杨思洛,韩瑞珍. 国外知识图谱绘制的方法与工具分析[J].图书情报知识,2012(6):101-109.
[12] Hao J, Yan Y, Gong L, et al. Knowledge map-based method for domain knowledge browsing[J].Decision Support Systems, 2014(61): 106-114.
[13] Ong T H, Chen H, Sung W, et al. Newsmap: a knowledge map for online news[J].Decision Support Systems, 2005, 39(4): 583-597.
[14] Liu D R, Ke C K, Lee J Y, et al. Knowledge maps for composite e-services: A mining-based system platform coupling with recommendations[J].Expert Systems with applications,2008,34(1):700-716.
[15] 张静. 自动标引技术的回顾与展望[J].现代情报,2009(4):221-225.
[16] Baranov D, Fender W R, Hamstra A N. Graph-based system and method of information storage and retrieval:,US8954441[P]. 2015.
[17] Klint Finley, 五个值得关注的图形数据库[EB/OL].[2015-12-10].http://www.csdn.net/article/2012-03-14/313107.
[18] 王晶. 无监督的中文实体关系抽取研究[D]. 上海:华东师范大学, 2012.
