基于Hadoop的业务过程模型管理方法研究
2016-03-25卢厅刘建勋文一凭周栋石敏
卢厅刘建勋++文一凭+周栋++石敏++陈聪阳


摘要:目前现有业务过程模型研究的共同特点便是基于单机环境来构建业务过程库,并基于传统关系数据库来管理业务过程模型,完成相关的检索、存储等操作。为提高大规模业务过程模型检索与存储的效率,本文提出一种新的业务过程模型管理方法。该方法采用基于Hadoop大数据处理平台对业务过程模型进行管理,并采用Map/Reduce编程框架和HDFS文件系统分别对业务过程模型进行检索和存储,提高了业务过程模型存储效率,减少了模型检索匹配的时间。通过原型系统进行试验验证评估,证明了所提方法在存储和检索效率方面高于单机环境。
关键词:业务过程模型管理;Hadoop;检索;存储;效率
中图分类号:TP311文献标识码:A
1引言
随着计算机与网络的不断发展与成熟,以信息技术为主导的各种高新技术为企业的发展提供了极大的支持,其中敏捷制造、并行工程、企业业务过程重组、供应链管理等先进制造技术的应用与推广成为当前企业赢得市场竞争采取的主要手段。以上技术都以企业业务过程为基础施行的,从而要求企业管理的模式从传统面向功能部门制的管理转化为面向企业业务过程的管理,简称面向过程的管理。业务过程是指在人员和技术的协调下所进行的一组为实现共同业务目标而采取的活动。在20世纪90年代以前企业采用的基于功能部门制的管理方式是一种严格的递阶式关系管理,易造成组织之间交流上的障碍。而面向过程的管理方式,通过业务过程将企业中的活动连接起来,模糊了组织边界,通过组织间的无障碍交流提高企业工作效率。
业务过程模型是一种通过定义组成活动及活动间逻辑关系,来描述工作过程的模型,是企业业务过程分析与重组的基础,是记录和保存企业经营过程知识的一种有效途径。由于业务过程模型描述了业务是如何一步步被处理的,也描述了在业务处理过程中数据是如何被处理的,人员是如何配置的,因此业务过程模型成为了组织部门很重要的资产。随着业务过程管理系统越来越广泛的应用,导致各行各业积累了越来越多的业务过程模型,有些企业已经积累了上千的业务过程模型。这样便产生了一系列新的问题,例如:如何存储业务过程模型?如何进行业务过程模型的检索?
国内外已有相关学者对此展开研究,但现有研究的共同特点便是基于单机环境来构建业务过程库,并基于传统关系数据库来管理业务过程模型,完成相关的存储、检索等操作。但事实上,从信息处理的角度看,业务过程模型可视为一种特殊类型的数据,由于业务过程模型是由众多企业组织机构生成的,它具有数据源多样性、分布性等特点,当业务过程模型的规模增长到一定规模时,传统关系数据库在处理这些这样海量的数据时出现性能和可扩展性的瓶颈。更为重要的是,利用单台主机来管理业务过程模型,尽管主机能达到很高的硬件配置,但其处理能力还是有限的。因此,采用分布式存储和计算来管理大规模业务过程模型将是一种必然的发展趋势。
目前,分布式存储和计算领域,全球约有上百种不同的方案,而Hadoop是其中使用较为广泛的一种。近年来,随着大数据研究与应用兴起,工业界已经广泛使用 Hadoop 作为其大数据处理平台,且具有相对较为成熟的商业应用。Hadoop技术宗旨就是在于分布式处理数据,采用分布式计算和存储技术,并且将简化了分布式处理细节。Hadoop非常适合处理非结构化的海量数据。因此,基于Hadoop来完成海量分布的业务过程模型管理可能是一种可行的解决方案,该研究不仅具有重要的理论意义,同时也具有十分重要的实际应用价值。
计算技术与自动化2015年12月
第34卷第4期卢厅等:基于Hadoop的业务过程模型管理方法研究
2相关研究
业务过程模型可以采用图表示,因此可以基于图检索领域相关工作和业务过程模型检索领域两个方面分析业务过程领域相关工作。在基于图检索领域可以借鉴的工作的有基于图结构的精确检索与基于图结构的相似性检索。在文献[1]中,作者Ke Y总结了图检索方面的工作。Shasha D 等人[2]基于图路径建索引,用户设定被索引的最长路径的长度;文献[3]改进了FG-Index,对于经常使用的查询建立了索引。
在基于业务过程模型检索领域也出现了很多相关工作。文献[4-6]提出基于业务流程建模标注BPMN的模型检索语言,采用了数据库管理系统的检索性能来加速BPMN模型检索的机制;文献[7,9]是业务过程模型相似检索工作的综述,文中涉及的所有工作由于无索引来提高检索效率,因此采用逐个模型与检索样例模型比较相似度的方法,十分耗时。在文献[9]中,作者提出了基于度量树索引方法,该方法使用图编辑距离计算模型相似度。在文献[10]中,作者基于最大公共子图和最小公共超图的图匹配方法,提出了JTangWFR流程推荐系统,该方法使用图编辑距离计算模型相似度。作者曹斌[11]基于近距离最大子图优先方法,提出了流程推荐系统。文献[12]基于Levenshtein距离计算最小深度优先搜索编码,提出了新的流程检索。上述业务过程模型检索各项的工作均没有采用模型行为语义。
文献[13]尝试利用Hadoop云平台来进行海量数字图像的数据挖掘,解决日益增多的图像进行有效的存储和快速的数据挖掘的问题。因为单机不能够满足海量数据推荐计算的需要,文献[14]提出了基于分布式计算开源软件框架Hadoop的系统解决方案,解决推荐系统的可扩展性问题。文献[15]中针对海量小文件小而多的特点提出了多Master分布式存储与检索,解决了海量小文件的分布式存储与检索问题。
BeeHiveZ是一个过程模型数据的应用开发框架,可在此之上进行过程模型相似性度量、过程模型检索等应用开发。BeeHiveZ实现是一个开源的软件(SourceForge.net)。它能够实现业务过程模型作为数据进行有效的管理、建立企业过程模型库,并支持对过程模型的存储、浏览、相似性度量、检索等操作。
3基于Hadoop分布式业务过程模型库管理方法
为了提高模型检索的效率,结合Hadoop框架特点,将模型检索分为过滤、验证两个阶段。在Map阶段使用过滤,得到能满足用户需要模型候选集,在Reduce阶段仅针对少量候选集进行验证。本文设计了基于Hadoop业务过程模型管理平台,实现模型库分布式管理,解决传统单机环境下模型管理效率低的问题。结合业务过程模型特点对Hadoop文件存储系统进行改进。
3.1模型库管理平台模型
本文提出了基于Hadoop业务过程库管理平台,设计了过程库管理平台模型。此模型根据业务过程模型小文件的特性对Hadoop进行相应改进。利用Hadoop分布式处理能力,采用Map/Reduce编程框架,Master/Slave原型,对模型库进行分布式管理,其业务过程库管理模型如下图:
图1所示为Hadoop业务过程库管理平台模型。如图所示,NameNode为主节点Master,管理数据块映射,处理客户端发送的读写请求,配置副本策略,管理HDFS的名称空间。SecondaryNameNode处理NameNode的部分工作量,例如某些比较消耗内存的工作,是NameNode的冷备份,即NameNode失效后不会立即启动,仅恢复部分数据,减低失效带来的损失;合并Fsimage和edits然后再报送到NameNode。Fsimage为元数据镜像文件(文件系统的目录树)。Edits为元数据的操作日志,针对文件系统做的修改操作记录。DataNode为Slave从节点,负责将client发来的数据块block存储到具体相应位置,执行数据块的读、写操作。其中,JobTracker主要职责是负责监控资源和调度作业。JobTracker会将任务执行进度和资源使用情况反馈给调度器,调度器再根据反馈信息,进行资源再次分配,从而实现资源的动态调度。JobTracker将任务(Task)一一分发到各个相应TaskTracker上面执行的过程称之为Hadoop作业调度。TaskTracker周期性通过Heartbeat向JobTracker汇报资源使用情况以及任务进度。
模型在存储之后且被检索之前,在线下对模型集进行基于路径的索引构造。Map再很据路径索引进行过滤,过滤后得到的模型交给Reduce,在Reduce阶段进行精确检索,在模型库中检索出包含样例为子图的模型。
3.2过程库存储机制
基于Petri网描述业务过程模型的时候,可以将Petri网视为特殊的有向图,其库所和变迁是图节点,弧是图的边。文献[16]详细描述了Petri网在业务过程建模领域的应用和分析。
业务过程模型采用图方式存储,而模型图检索处理海量的数据时,传统的单节点存储难以满足快速存储的要求。本系统采用Hadoop文件存储框架,采用Master/Slave结构,其中NameNode为Master负责维护集群元数据,DataNode为Slave负责存储数据。利用Hadoop分布式文件系统HDFS进行数据管理,结合业务过程模型小文件的特点将Hadoop文件存储做相应改进。
如图2所示HDFS客户端将模型文件按64M分块,再向NameNode发送写请求。NameNode节点负责记录块(block)信息,并将可用的DataNode节点信息返回给client,Client向DataNode发送64k Package,将Package写入块中,DataNode向NameNode和Client发送本次Package“写完”报文,Client再向NameNode发送“写完”报文。Client又开始写新的Package和block,如此循环,当Client把所有模型写完,Client向NameNode发送“写完”报文,模型存储操作就完成了。
在GFS/Hadoop中,把所有的,模型与块之间的关系放在内存中,这样不利于对海量小文件进行存储。单个业务过程模型都是小文件(小于1M),模型通常是一次写、多次读,除某些特定情况外不会对模型进行频繁的修改。针对海量模型,需要对HDFS进行修改设计模式来更加高效的支持。针对上述问题,将HDFS进行以下修改:
允许一个块存放多个模型,一个块对应多个模型;使用分布式内存Cache系统来缓存业务过程模型和块的对应关系。
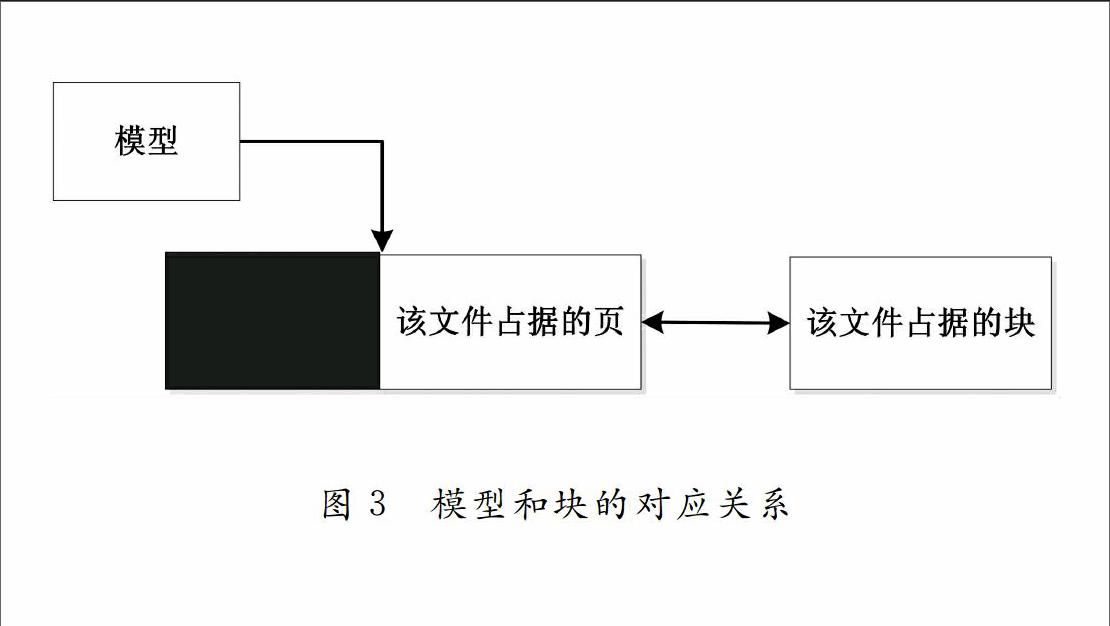
设计模型存储格式,对模型与块的关系进行修改,增加块内偏移,即一个模型和块的对应关系为:模型名<-->{块ID+块内偏移}+{中间ID}+{块ID+块内偏移+场内长度};其中{中间块ID}代表0到N个块间的ID;块内长度以页为单位的(默认一页16K),每一页有一定长度的页头用来描述该页信息,假设为20字节。模型和块的对应关系如图3所示:
Master设计模型
由于模型和块的关系数量巨大,已经不能全部放在内存中了。因此,简单的存储已经不能满足需要,需要使用多台数据存服务器来存储模型和块的关系。
Master负责映射关系数据和逻辑分配管理系统。整个Master系统具体负责有分配新的文件分配块,文件副本的增加和减少,以及存储文件和块的映射函数。当系统应用程序希望读取某个文件数据时,Master返回该文件及Meta信息和块相关信息。
3.3Hadoop平台过程库检索机制
定义1 (Petri网): Petri网是一个三元组N=(P; T; F),其中P和T表示库所和变迁的集合并且满足P∩T=Φ,F(P×T)∪(T×P)是弧的集合,表示流关系。
定义2 (基于路径定义索引):一个R模型库基于路径索引InR,路径长度为n,例如(Φi;Φi.list),其中Φi是长度为n的变迁路径,Φi.list是所有包含Φi的模型集合。
为了使路径索引的效率更高,不直接存储(Φi,Φi.list),而是将(Φi,Φi.list.pointer)存储到二叉树中,使用倒排表存储(Φi.list.pointer,Φi.list),其中Φi用作二叉树键值,Φi.list.pointer指向倒排表中Φi.list的位置。为了提高I/O性能,这些列表被存储在固定长度的存储块中。当一个列表需要多个块时,第一个块包含了一个指针信息指向第二个块,需要更多块时,依此类推。Φi.list.pointer实际上指向列表第一个存储块的位置。上述存储结构如图4所示。在目前大多采用的方法中,B+树的根节点被存储在内存中,而其它结点以及相应的倒排表都存储在文件中,为了提高性能,目前针对B+树的结点和倒排表使用了缓存机制。
Map函数模型检索如算法1所示:第1行,Map函数接口将大文件数据分割成若干个数据块;第2到5行所有路径被顺序处理;第3行,将过滤到的模型位置存放在list中;第4行,将目标模型存放在context当中;第5行,返回context作为Map函数的输出。Reduce函数模型检索如算法2所示:第1行,Map函数输出作为本阶段输入;第2到第5行行顺序执行;第3行,将检索到的模型位置存放在R中第5行,包含path路径的模型作为输出。
Algorithm 1: Map
Function Map
输入:查询样例模型
输出:单个节点上的样例模型
1 Data_Block ← All Data;
2 for Data_Block do
3 list ← PathIndexQuery (path);
4 add list to context;
5 return context;
Algorithm 2: Reduce
Function Reduce
输入:context
输出:目标模型R
1 get context;
2 for context do
3 list ←LengthOnePathIndex(Data_Block);
4 add list to R;
5 return R;
模型被检索之后对模型的读取,应用程序调用HDFS 的Client API库,读模型的数据;Client API收到请求后,发出获取文件Meta和块信息请求给查询Master;查询Master向后台数据管理系统查询该模型相关的信息,查询后返回给Client API;Client API得到Meta信息块的信息后,向对应的块服务器发出读相关的块数据指令;块服务器根据指令读取相应的块数据返回给Client API;Client API 返回请求给应用程序,如图5所示:
4实验评估
为了验证本文提出模型管理方法的有效性,在Hadoop平台中实现了模型分布式检索,并在模型集中验证了方法的有效性和性能。平台实验环境为:Vmware 7,VMware ESX 4.1,Intel(R) Xeon(R) CPU E5620, CentOS 6.4,内存4.0 GB;Hadoop-1.2.1,Eclipse,JDK1.7。
基于Hadoop业务过程管理平台具体实现步骤:第一步,将BeeHiveZ源码中模型检索模块中的某一个检索算法[13]提取出来;第二步,在服务器安装三台linux虚拟机,搭建完全分布式Hadoop平台,对Hadoop存储进行调整以更好支持小文件存储;第三步,利用BeeHiveZ自动生成业务过程模型,在Hadoop分布式文件系统HDFS进行存储,存储索引,为简化索引生成将单机生成索引拷贝到HDFS中;第四步,将过滤、检索与Map/Reduce编程模式相对应,Map阶段,采用索引过滤,Reduce阶段将第一步得到的算法进行检索;第五步,运行调试Hadoop代码进行检索,记录实验时间,得出实验结果。
方法有效性验证:将产生的查询实例模型F添加到模型库中,产生一个查询样例模型集合F添加到模型库中,之后将产生包含更多模型集合S添加到总模型库中,针对每一个查询实例模型f ∈F,在模型库F∪S中进行检索,验证集合中是否包含实例模型f。通过实验验证,在单机平台和Hadoop都能检索出相应的模型。
图6(a)显示了无索引情况下即不采用模型检索算法不同平台检索需要的时间,目标模型会与模型库中模型一一比较,从而检索出目标模型,可以看出Hadoop平台检索时间明显少于单机平台检索时间;图6(b)显示了在采用索引情况下使用LengthOnePath检索算法[16]不同平台检索需要时间,可以看出Hadoop平台检索仍然优于单机平台检索。从图6(a)(b)两图红色三角形可以看出,Hadoop平台能够在采用检索算法情况下有效提
升检索效率,保证检索的高效性。
图6(c)单机下索引生成时间,为简化索引生成将单机生成索引存储到Hadoop平台,索引在模型检索之前,存储之后在单机环境下增量更新,而模型每次增量更新时间很短。图6(d)显示了两平台存储空间大小比较,HDFS为保证Hadoop平台鲁棒性采用备份机制,同等存储内容条件下,其存储空间为单机条件下3倍。采用Hadoop平台管理业务过程模型确实可以提高效率但也会带来带宽、存储空间等资源消耗,其硬件要求也高于单机环境。
如图6所示单机平台与Hadoop平台检索性能综合比较比较,在不同平台中将业务过程模型库增量更新,比较两种平台的效率。从实验结果可以得出,在同等条件下,无论采用索引与否Hadoop平台检索效率明显高于单机环境。
5结束语
针对单机环境下传统关系型数据库对大量业务过程模型检索、存储效率不高的问题,本文提出并实现了分布式环境下基于Hadoop的业务过程模型管理方法。本文采用Hadoop中Map/Reduce和HDFS作为过程库的检索和存储框架,对Hadoop存储进行了改进;设计了业务过程模型索引结构,采用过滤、验证模式快速检索模型,本文实验模型由BeehiveZ中模型生成器自动生成。Hadoop平台整体资源开销大于单机环境,存储空间以及流量带宽会是单机环境的3倍。通过这些开销能够换得理想的模型管理效率。结果表明:基于Hadoop的业务过程模型管理方法可以有效实现业务过程模型分布式管理,并且其管理效率比单机环境下要好。在已有成果基础上,本课题组将围绕分布式业务过程模型库检索算法的研究展开工作。
参考文献
[1]Ke Yiping, Cheng James, Yu Jeffrey Xu. Querying Large Graph Databases[J]. Proceedings of DASFAA (2), 2010. 487-488.
[2]Shasha Dennis, Wang Jason TL, Giugno Rosalba. Algorithmics andApplications of Tree andGraph Searching[C]// Proceeding of the 21st ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems. New York, N. Y. USA: ACM, 2002: 39-52.
[3]Cheng James, Ke Yiping, Ng Wilfred. Effcient Query Processing on Graph Databases[J].ACM Trans. Database Syst, 2009, 34(1): 2.
[4]AWAD A,POLYVYANYY A,WESKE M. Semantic Querying of Business Process Models[J]. Proceedings of EDOC, 2008. 85-94.
[5]SARKR S,AWAD A. A Framework for Querying Graph-Based Business Process Models[J]. Proceedings of WWW, 2010. 1297-1300.
[6]AWAD A,SAKR S. Querying Graph-Based Repositories of Business Process Models[J]. Proceedings of DASFAA Workshops, 2010. 33-44.
[7]Dumas Marlon, GarciaBanuelos Luciano, Dijkman Remco. Similarity Search of Business Process Models[J].IEEE Data Eng. Bull., 2009, 32(3):23-28.
[8]Dijkman Remco, Dumas Marlon, Dongen Boudewijn, et al. Similarity of Business Process Models: Metrics and Evaluation[J]. Inf. Syst., 2011, 36(2):498-516.
[9]张良将. 基于Hadoop云平台的海量数字图像数据挖掘的研究[D] .上海:上海交通大学,2013.
[10]王东京, 邓水光, 曹斌,等. JTangWFR一个高效可靠的流程推荐系统[J].计算机集成制造系统, 2013, 19(8):1883-1990.
[11]曹斌, 尹建伟, 邓水光,等. 一种基于近距离最大子图优先的业务流程推荐技术[J].计算机学报, 2013, 36(2): 263-274.
[12]曹斌, 尹建伟, 陈慧蕊. 基于Levenshtein距离的流程检索方法[J].计算机集成制造系统,2012, 18(8):1766-1773.
[13]唐真. 基于Hadoop的推荐系统设计与实现[D].成都:电子科技大学,2013.
[14]叶伟. 互联网时代的软件革命--SaaS架构设计[M].北京:电子工业出版社, 2009.
[15]VAN DER AALIST W M P. The application of Petri nets to workflow management [J].Journal of Circuits, Systems, and Computers, 1998, 8(1): 21-66.
[16]金涛. 业务过程模型检索与重构[D]. 北京:清华大学,2012.
