局部证据RBF人体行为高层特征自相似融合识别研究
2016-03-25蒋加伏赵怡�k
蒋加伏++赵怡�k


摘要:针对传统人体动作识别算法,往往重点解决某一类行为识别,不具有通用性的问题,提出一种局部证据RBF人体行为高层特征自相似融合识别算法。首先,借用随时间变化的广义自相似性概念,利用时空兴趣点光流场局部特征提取方法,构建基于自相似矩阵的人体行为局部特征描述;其次,在使用SVM算法进行独立个体行为识别后,利用所提出的证据理论RBF(Radial Basis Function)高层特征融合,实现分类结构优化,从而提高分类准确度;仿真实验表明,所提方案能够明显提高人体行为识别算法效率和识别准确率。
关键词:局部特征描述;证据理论;RBF网络;自相似;高层特征融合
中图分类号:TP39文献标识码:A
1概述
近年来,人体行为识别已得到广泛应用,特别是在医疗诊断、视觉监控等领域[1]。该算法主要涉及到人体运动检测/估计,身体和手脚跟踪以及行为理解等三个方面,本文研究重点研究人体行为活动的识别和描述 [2]。识别过程为:传感器信息获取、特征描述、行为识别三个过程。
在普适计算应用方面,常用方法有三种:一是外部传感器,如文献[3]接触式红外压力式传感器组合;二是可穿戴传感器,如文献[4]基于穿戴RFID对人体行为进行捕获判定;三是环境监测传感器,主要有温度、湿度及光照传感器等,通常作为补充[5]。外部传感器使用方便,辐射小,应用最为广泛。
在人体特征表示上通常分为:全局和局部特征两种。在全局特征描述中,对整个视频上对人体行为进行特征提取,然后进行相似性识别。如文献[6]改进方向全局人体行为特征描述,可对形状相近的人体行为进行有效识别。在局部特征描述中,方法是在视频序列中,提取人体行为的局部特征,利用直方图或者时序模型构建人体行为特征,如文献[7]三维梯度直方图人体行为局部特征描述。相对于全局特征描述,局部特征描述优点在于能够更为有效地对时域和空域信息进行融合。
在完成局部的人体行为特征描述后,进行的人体行为识别,常用的方法有距离匹配和状态空间法。状态空间法对人体行为进行直接建模,能够对人体行为时序信息进行充分利用,不足之处是算法的控制参数较多。而距离匹配虽简单,但未考虑人体行为动态过程,因此算法的识别率相对较低[8]。
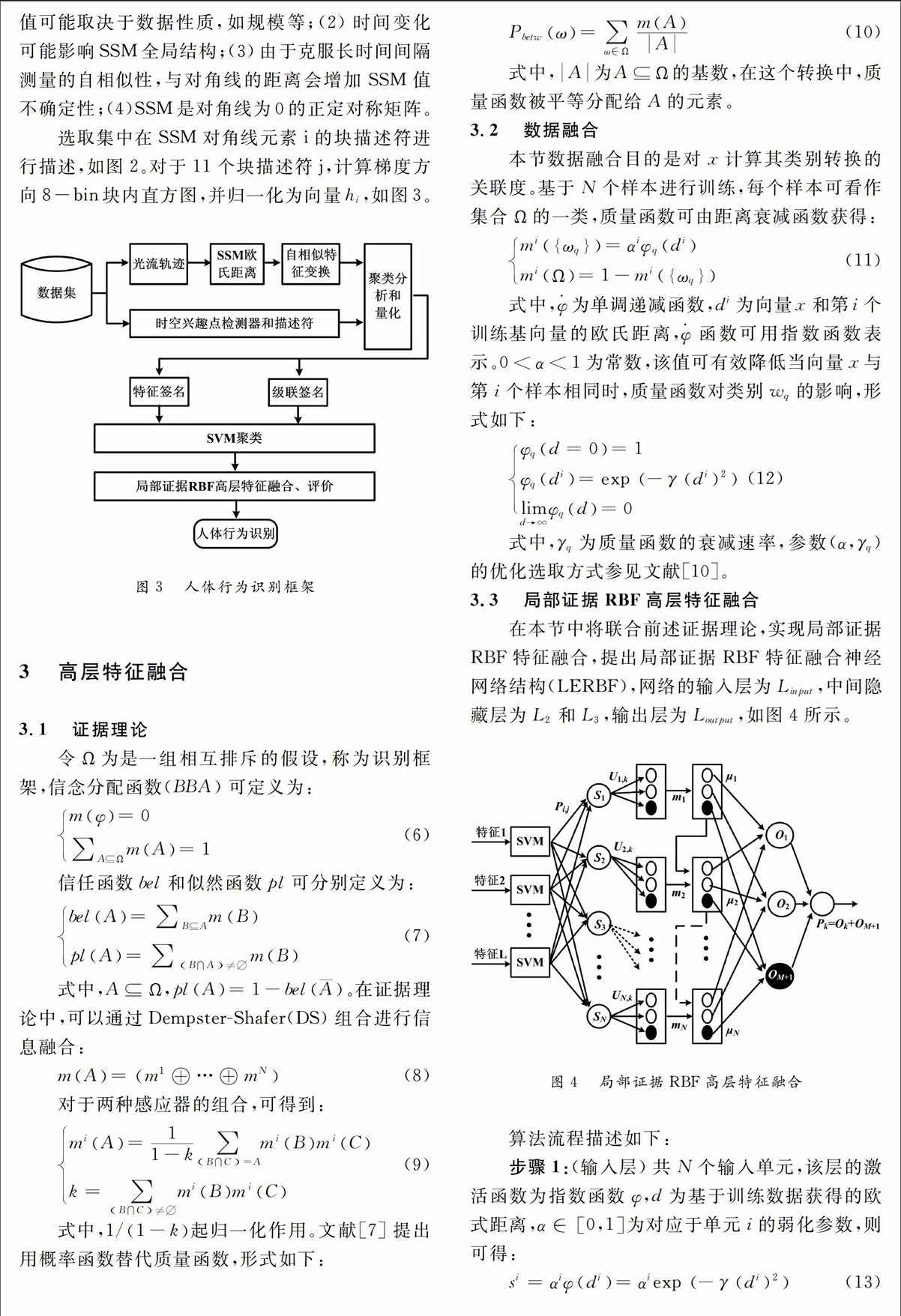
综合上述分析,本文构建自相似矩阵人体行为局部特征描述,并设计证据理论RBF高层特征融合算法,实现人体行为识别分类结构优化。
4实验与分析
本节实验基于KTH数据库及较复杂的多视角MuHAViMAS14数据库进行实验。硬件条件:CPU:I5-4590,3.3GHz;内存:金士顿ddr3 1600,4GHz。
对比算法:文献[11]局部SVM算法(LSVM),文献[12]动态贝叶斯算法(DBN),文献[13]单纯时空兴趣点特征提取SVM算法(STIPSVM)。
仿真指标选取平均预测精度mAP,可定义如下:
AP=Numar/Numtar·Numtra (19)
式中,Numar为获取数量;Numtar为行为总数;Numtra为人体行动总数。
KTH数据库:该数据库有6种人体行为:行走、慢跑、快跑、拳击、摆手、拍手,如图5所示。KTH数据库含有2391幅不同人体行为图像。
每种人体动作行为各选取该动作行为图像总数量的1/4作为训练数据集。算法各运行30次,上述6种人体行为的平均预测精度mAP值见表1所示。
从表1中可看出,上述算法均能对KTH数据库进行较有效识别,平均识别精度在70%以上。其中对比算法在行走、慢跑、快跑三种行为的识别率偏低,原因是这三种人体行为存在边界交叉,因此三种算法在对其进行识别时,识别率偏低,平均在71%~77%之间。而在区别较大的拳击、摆手、拍手三种行为中,这三种算法识别率能达到82%~89%间。本文所提算法识别率均明显好于对比算法,能达到90%~96%之间,显示了算法良好识别能力。为更清晰对比,平均预测精度和运行时间曲线如图6所示。采用本文算法获得的混淆矩阵如图7所示。
从图6可看出,在预测精度上,本文算法要始终高于对比算法,保持在90%以上,而对比算法识别率互有高低,保持在70%~90%之间;在算法运行时间上,本文算法的运行时间最短,保持在7s~9s之间,其次是DBN算法,运行时间在10s~11.5s之间,其余两种算法因用到SVM算法,运行时间相近,保持在14s~18s间。从图7混淆矩阵可看出,本文算法除在个别行为间达到15%混淆概率外,其他行为间的混淆比例很低,说明识别效果很好。
MuHAViMAS14数据库:该数据库作为较复杂测试对象,来进一步验证本文算法的性能有效性。该数据库中一共含有14种人体行为,分别进行编码{a,b,c,d,e,f,g,h,i,j,k,l,m,n}。该数据库示例图片如图8所示。该数据库由两个人在两个视角下完成,视角分别为:正面和45度角。这两个视角下各有68个视频,包含角度和动作的变化,识别难度大。对比算法同上,仿真指标选取上述14种人体行为识别率均值(运行30次),计算方法参见公式(19)。对比结果如表2所示,表2同时给出算法30次运行时间均值。图9给出算法混淆矩阵。
表2给出对比算法在MuHAViMAS14数据库中14种人体行为的平均识别率结果,从图中可明显看出,本文算法在更为复杂的数据库上的识别率虽有所降低,但仍然保持在80%以上识别率,而对比算法的识别率均出现大幅降低,仅能保证60%多的识别率。在算法运行时间方面,本文算法的运行时间需要17.3s比KTH数据库要长1倍左右,而对比算法的运行时间均在30s左右。
图9给出本文算法在MuHAViMAS14数据库中获取的混淆矩阵,从该矩阵中可看出,在个别行为之间存在较大混淆概率,比如在人体行为f与人体行为h之间存在25%的混淆概率,在g与h之间也存在25%的混淆概率等,比在KTH数据库上的混淆概率要高很多。
5结束语
针对传统人体动作识别算法识别率不高的问题,提出一种局部证据RBF人体行为高层特征自相似融合识别算法,进行有效解决,实验结果显示,本文算法在识别率和收敛速度上均要好于对比算法。存在的不足是,在复杂的多视角MuHAVi-MAS14数据库上个别人体行为间的混淆概率值依然较高,仍然存在较大的提升空间。
参考文献
[1]MEDINA J R, LORENZ T, HIRCHE S. Synthesizing Anticipatory Haptic Assistance Considering Human Behavior Uncertainty[J]. IEEE Transactions on Robotics, 2015, 31(1): 180-190.
[2]田国会, 尹建芹, 韩 旭. 一种基于关节点信息的人体行为识别新方法[J]. 机器人, 2014, 36(3): 285-291.
[3]Gu Tao,Wang Liang,Wu Zhanqing. A pattern mining approach to sensor—based human activity recognition[J].IEEE Transactions on Knowledge and Data Engineering, 2013, 23(9): 1359-1372.
[4]STIKIC M, HUYNH T, LAERHOVEN K V.ADL recognition based on the combination of RFID and aceelerometer sensing[C]. //Proceedings of the International Conference of Pervasive Computing Technologies for Heahhcare, Tampere, Finland, 2008, pp. 245-250.
[5]PHILIPOSE M, FISHKIN K P, PERKOWITZ M. Inferring activities from interactions with objects[J]. IEEE Pervasive Computing, 2004, 3(4): 50-57.
[6]CAI J X, FENG G C, TANG X. Human action recognition using oriented holistic feature[C]. // 20th IEEE International Conference on Image Processing, USA, IEEE, 2013, pp. 2420-2424.
[7]ALEXANDER K,MARCIN M, CORDELIA S. A spatiotemporal descriptor based on 3dgradients[C]. //British Machine Vision Conference, IEEE Computer Society, 2008, 995-1004.
[8]蔡加欣, 冯国灿, 汤鑫. 基于局部轮廓和随机森林的人体行为识别[J]. 光学学报, 2014, 34(10): 1-10.
[9]JUNEJO I N, DEXTER E, Laptev I. Crossview action recognition from temporal self similarities[J]. //Proceedings of the European conference on computer vision, USA, IEEE, 2008, pp. 293-306.
[10]BARRI A, DOOMS A, JANSEN B. A Locally Adaptive System for the Fusion of Objective Quality Measures[J]. IEEE Transactions on Image Processing, 2014, 23(6): 2446-2458.
[11]SCHULDT C, LAPTEV I, CAPUTO B. Recognizing human actions: a local SVM approach[C]. //Proceedings of the international conference on pattern recognition, USA, IEEE, 2004:32-36.
[12]NIEBLES J C, WANG H, LI F F. Unsupervised learning of human action categories using spatial-temporal words[C]. //British machine vision conference, Copper Mountain, IEEE,2006:22-28.
[13]WONG S F,CIPOLLA R. Extracting spatio-temporal interest points using global information[C]. //IEEE conference on computer vision and pattern recognition. Rio de Janeiro, IEEE,2007:1-8.
