科技文献引文价值测度的改进方法
2016-03-24祝清松
■祝清松
中国电子科技集团公司第三十八研究所《雷达科学与技术》编辑部,安徽省合肥市高新区香樟大道199号 230088
1 引言
科技文献之间的相互引用形成学术引文网络,表明了新知识对原有知识的使用情况,揭示出学术研究的动态变化,这对于发现学科间的关联及进行学科发展趋势分析和预测具有重要作用[1]。科技文献的引文价值是测度学术引文网络中具有引用关系的科技文献之间关联程度的文献计量指标,主要度量被引文献对施引文献的学术参考价值。
目前对科技文献引文价值的测度主要基于引文分析展开研究。引文分析经过数十年的发展,在理论研究和实践应用方面都取得了长足进展,已经广泛应用于科学知识评价、科学发展模式揭示和科学前沿探测等方向[2],对科技创新和决策具有重要的支撑作用。然而,传统引文分析将所有引文赋予相同权重,在此基本假设下,引文分析的相关测度主要基于被引频次这个核心计量指标展开。由于同一施引文献引用不同被引文献的动机并不相同,因此只通过被引频次并不能揭示出被引文献对施引文献所贡献的学术价值。随着全文本文献可获取性的不断提高和文本挖掘技术的持续发展,基于全文本内容的引文分析将成为下一代的引文分析。Ding等[3]提出基于引文内容的语法和语义分析框架,分析了引文内容分析的潜在价值及应用方向,并将其作为传统引文分析的有效补充。目前引文价值测度还停留在传统引文分析层面,有必要对其进行改进。
因此,本文在相关研究基础上,深入全文本内容来分析影响引文价值测度的关键因素,并提出基于关键影响因素的改进方法。改进方法能够有效揭示施引与被引文献之间的语法和语义关联,从而更好地测度被引文献对施引文献所贡献的学术价值。科技期刊的选题策划和组稿约稿主要围绕领域当前的研究热点和发展趋势展开。改进方法可以识别出学科领域中具有高引文价值的一组科技文献簇,并通过对文献簇的主题演化分析,进而更有效地揭示出科技文献簇所表征研究领域的研究热点和前沿趋势,有利于领域科技期刊更有针对性地开展选题策划和组稿约稿等编辑出版工作。
2 有关引文价值测度的文献综述
引文关系是科技文献引文价值测度的关键。引文关系包括直接引文关系和间接引文关系,前者即直接引用关系,引文之间是施引与被引文献的关系,后者指引文之间需要通过另一篇引文进行关联的关系。参照Small给出的定义[4],间接引文关系可分为共引、耦合和传递三种关系。其中,传递关系的定义为:如果文献A引用了文献B,文献B引用了文献C,那么文献A和文献C之间即为传递关系。
目前具有代表性的引文价值测度方法包括Combined Linkage(CL) 算 法[4]、 Weighted Direct Citations(WDC) 算法[5]、Normalized Similarity Index(NSI)算法[6]。这些代表性算法所涉及直接引文关系的情况及间接引文关系的类型如表1所示。

表1 引文价值测度方法
为凸显直接引文关系的重要性,CL算法将直接引文关系的权重设置为间接引文关系的两倍。CL算法的计算公式如下:
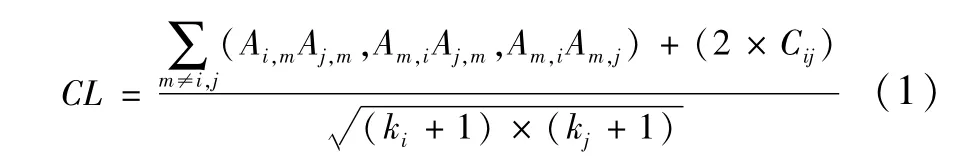
WDC算法没有涉及直接引文关系,仅利用了共引和耦合两种间接引文关系来测度引文价值。WDC算法的计算公式如下:

NSI算法使用Jaccard方法进行标准化处理,代替了CL算法的平方根方法,计算结果更加合理。NSI算法的计算公式如下:
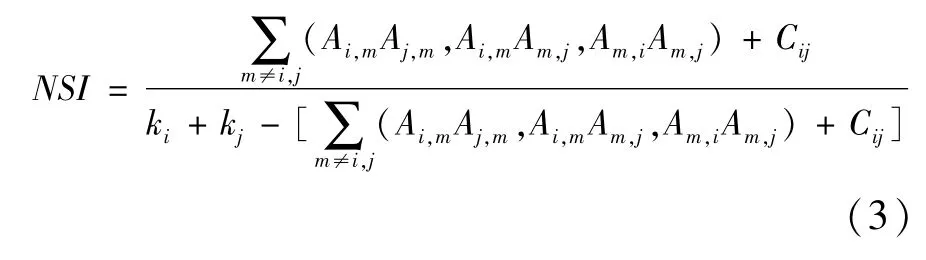
式(1)~(3)中,i和 j分别表示施引与被引文献,(Ai,mAj,m, Ai,mAm,j, Am,iAm,j)表示三种间接引文关系,Cij表示直接引文关系。因为基于传统引文分析的学术引文网络是二值图,而且i和j为直接引文关系,所以Cij只能用1来表示。因此,目前引文价值测度方法充分考虑各种间接引文关系,但忽略了最直接、最本质的直接引文关系。这是本文对引文价值测度方法改进的主要出发点。
引文价值测度忽略直接引文关系的问题本质上而言是被引频次的权重问题。很多学者都针对该问题展开了研究,旨在对被引频次进行修正。如在期刊评价方面,Moed和Zitt等[7-8]文献计量学家提出了从施引文献的引文数量角度对被引频次进行改进的建议;针对不同主题领域的学科特性差异导致引文影响力评价存在的比较有效性问题,Moed在Garfield领域“引用潜力”指标的基础上,提出了可以测度不同主题领域引文影响力的SNIP指标,其利用了来源标准化的方法,通过篇均引文数来校正不同主题领域引用行为的差异。但是,这些对被引频次的修正仍然是从引文数量的角度出发,而没有从引文质量的角度思考。
随着基于全文本内容引文分析的发展,引文分析的对象正在从篇向节、段、句深入,这使得引文分析的颗粒度更加精细化。如Ding等[9]提出了一种通过统计被引文献在施引文献全文中被提及的次数来计算总被引频次的方法。这种基于全文本内容的引文分析与传统的引文分析相比,可以更全面地揭示引文真实的被引频次,可以更好地用于预测和挖掘新的高被引论文,在科学评价和科学预见等领域有着非常重要的应用价值[10]。以上这些研究为本文对引文价值测度的改进提供了借鉴作用。
3 关键影响因素分析
针对目前科技文献引文价值测度存在的问题,本文从基于全文本内容引文分析的视角出发,归纳出影响引文价值测度的关键因素,旨在为引文价值测度方法的改进提供思路。经过总结与分析,本文将引文价值测度的关键影响因素归纳为语法和语义两个层面,前者涉及引用频次和引用位置,后者涉及引用类型和引用主题,如图1所示。

图1 引文价值测度的关键影响因素
3.1 引用频次
3.2 引用位置
引用位置是指施引文献在全文中引用被引文献的章节。引用位置直接反映了施引文献的引用动机,即出现在不同章节的被引文献对施引文献的贡献不同,在方法、实验、结论等部分引用的引文往往比在引言、研究现状或背景等部分引用的引文对施引文献的学术价值更大。Halevi等[13]将引用位置分为引言、文献综述、方法论、结果、讨论和结论。刘盛博[14]将引用位置分为引言、背景、方法、数据、结果、应用、讨论和结论,并通过实验发现在各个章节中引用文献的目的性具有明显差别:在引言中引用时,通常是陈述别人工作;在背景中引用时,除了陈述他人工作外,还会指出本文的研究特点;在方法中引用时,主要介绍施引文献本身所使用的方法等。
3.3 引用类型
引用类型是指通过对引用内容的语篇分析来识别施引文献引用被引文献的动机。引用内容是被引文献出现在施引文献全文中的句子或上下文,是施引文献对被引文献的重新组织。Small[15]将引用内容作为观点表达的概念符号,认为将共被引聚类和被引内容分析结合起来能够更好地揭示研究领域的知识基础。引用类型主要包括引用功能(被引文献对施引文献的作用,如背景、基础、比较等)和观点倾向(施引文献对被引文献的态度或立场,如肯定、否定、中立等)两种定义。不同引用功能和观点倾向的被引文献对施引文献的学术价值不同。Nanba等[16]将引用类型分为类型B(将其他研究者的理论或方法作为理论基础)、类型C(与相关工作进行比较,指出存在的问题或差距)和类型O(其他类型)三种。许德山[17]将引用类型分为理念引用、论据引用、参考引用和叙述引用。
3.4 引用主题
科技文献符合一定的主题分布规律,而且可以通过一组揭示其主要研究内容的主题词来表征。因此,施引与被引文献都可以用一组主题词来表征各自的主题分布,并通过主题分布的相似度来测度被引文献对施引文献的学术价值。与施引文献主题分布越一致的被引文献对施引文献的贡献和价值越大。Liu等[18]基于此假设提出了利用有监督主题模型(LLDA)和网络分析算法(PageRank)来提高传统文献计量分析的全文本引文分析方法。其中,利用LLDA来表示文献和引文的主题分布,并用顶点表示文献,边表示引文。文献和引文的主题概率分布就可以转换成顶点的先验概率分布和边的转移概率分布,形成主题加强的引文图。
4 基于关键影响因素的改进方法
通过以上分析可知,引用频次、引用位置、引用类型和引用主题都对科技文献引文价值的测度有很大影响。在相关研究的基础上,本文提出一种基于关键影响因素的引文价值测度改进方法。为了更有针对性地论述改进方法,本文对间接引文关系不再赘述,仅阐述对直接引文关系的改进,并用Vdir表示基于直接引文关系的引文价值。被引文献的引文价值由引用频次、引用位置、引用类型和引用主题四个分量构成,分别用Vfre,Vpos,Vtyp和Vsub表示,其权重分别用a,b,c和d表示,且a+b+c+d=1。本文中测度引文价值的计算公式如下:
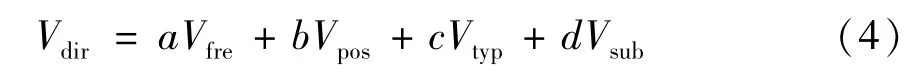
权重的设置表征了各个关键影响因素对引文价值测度的重要程度。本文对4个关键影响因素赋予相同权重,均设置为0.25。
4.1 实例分析
以韩国高丽大学Shin研究团队有关碳纳米管纤维的一篇科技文献为例。这篇文献的正文包含了引言、实验、结果与讨论、结论四部分,并引用了6篇参考文献,例文章节结构及引用情况如图2所示。本文选取的实例主要是为了说明改进方法的基本思路,实际应用时还需要根据科技文献的篇章结构、参考文献情况等进行适当调整。
被引文献在施引文献全文中以特定的形式进行标记,即引用标记,如例文中的[2,3]和[4-6]等。引用频次即通过识别引用标记来获得。
Maricic等[19]将引用位置分为引言、方法、结果、讨论或结论四部分,权重分别设置为15、30、30、25。本文以此为参考,给出引用位置的权重,如表2所示。

表2 引用位置的权重设置
本文借鉴许德山[16]依据情感倾向和使用类型给出的引文利用价值量化强度指标,如表3所示。引用类型的确定利用线索词匹配的方法。

图2 例文章节结构及引用情况

表3 引用类型的权重设置
利用C-value算法识别施引与被引文献的主题分布,并选取排名前10的核心主题词进行表征,结果如表4所示。通过核心主题词匹配的方法测度施引与被引文献的引用主题相关度。
4.2 结果与讨论
根据实例分析的方法、数据和权重,得到例文的引文价值测度结果,如表5所示。

表4 施引与被引文献的核心主题分布
由表5可知,被引文献(4)的引文价值最大,其次是被引文献(5)、(6)和(2),被引文献(1)和(3)的引文价值最小。通过人工判读分析可知:被引文献(4)出现在施引文献的实验部分,借鉴其从多壁碳纳米管纺出碳纳米管纤维的方法,为施引文献的研究提供了方法论,且被引了3次,表明其对施引文献的贡献较大;被引文献(4)还与被引文献(5)和(6)一起出现在结果和讨论部分,为施引文献实验结果的讨论提供了对比数据,且被引文献(5)和(6)被引两次;被引文献(1)、(2)和(3)仅出现在引言部分,只提供了施引文献研究的背景信息,表明其对施引文献的贡献较小。通过分析可知,实验结果具有一定的合理性,在一定程度上验证了本文改进方法的可行性。
实例分析针对的是单篇施引文献中多篇被引文献的引文价值测度情况,主要为了阐述改进方法的基本思路。在实际应用中,单篇被引文献在多篇施引文献中的引文价值测度情况更有意义,其对应传统引文分析中的被引频次。高引文价值的科技文献相比高被引频次的科技文献对学科领域研究创新的学术价值更大。另外,除了对单篇文献的引文价值测度,本文方法可推广到科技期刊的引文价值测度,用于评价科技期刊在领域研究创新中所贡献的实际学术价值。
5 结语
本文针对目前科技文献引文价值测度存在的问题,从基于全文本内容引文分析的视角出发,从语法和语义两个层面归纳出了影响引文价值测度的关键影响因素。在此基础上,本文提出了引文价值测度的改进方法,并通过实例分析验证了改进方法的可操作性和可行性。
基于全文本内容的引文分析使引文分析从数量角度转向质量角度。随着科技文献全文数据变得越来越易得,尤其是结构化的全文数据,如Elsevier的XML全文数据,可以方便地从施引文献全文中识别出引用频次、引用位置、引用内容等信息[20]。这为本文提出的改进方法提供了数据基础。另外,基于间接引文关系的引文价值测度方法还受到文献数据库收录范围的限制,数据库的差异会导致测度结果的不同,而基于直接引文关系的引文价值测度方法不受此限制,结果更加客观有效。
本文研究更多还是理论分析,下一步工作需要通过更多的领域实验来验证改进方法的普适性和应用性。尤其是需要进一步研究关键影响因素的权重设置,以及引用位置和引用类型的分类等问题。另外,引用类型的识别需要构建线索词库,在相关研究的基础上还要注意数据的差异性研究。
[1]Hey T,Tansley S,Tolle K.第四范式:数据密集型科学发现[M].潘教峰,张晓林,等译.北京:科学出版社,2012:199.
[2]梁永霞.引文分析学知识图谱[M].大连:大连理工大学出版社, 2012:118.
[3]Zhang G, Ding Y, M ilojevic S.Citation content analysis(CCA): A framework for syntactic and semantic analysis of citation content[J].Journal of the American Society for Information Science and Technology, 2013, 64(7): 1490-1503.
[4]Small H.Update on sciencemapping: creating large document spaces[J].Scientometrics, 1997, 38(2): 275-293.
[5]Persson O.Identifying research themes w ith weighted direct citation links[J].Journal of Informetrics, 2010, 4(3): 415-422.
[6]Nassiri I, Masoudi-Nejad A, Jalili M, et al.Normalized sim ilarity index:An adjusted index to prioritize article citations[J].Journal of Informetrics, 2013,7(1): 91-98.
[7]Zitt M.Citing-side normalization of journal impact: A robust variant of the audience factor[ J].Journal of Informetrics,2010, 4(3):392-406.
[8]Moed H F.Measuring contextual citation impact of scientific journals[J].Journal of Informetrics, 2009, 4(3):265-277.
[9]Ding Y,Liu X, Guo C, et al.The distribution of references across texts: Some implications for citation analysis[J].Journal of Informetrics, 2013,7(3):583-592.
[10]胡志刚,陈超美,刘则渊,等.从基于引文到基于引用:一种统计引文总被引次数的新方法[J].图书情报工作,2013,57(21):5-10.
[11]Herlach G.Can retrieval of information from citation indexesbe simplified?Multiplemention of a reference as a characteristic of link between cited and citing article[J].Journal of the American Society for Information Science, 1978, 29 (6):308-310.
[12]LieversW B, Pilkey A K.Characterizing the frequency of repeated citations: The effects of journal, subjectarea, and selfcitation[J].Information Processing and Management, 2012,48(6): 1116-1123.
[13]Halevi G, Moed H F.The thematic and conceptual flow of disciplinary research:A citation context analysis of the journal of informetrics, 2007 [ J].JournaI of the American Society for Information Science and Technology, 2013, 64(9): 1903-1913.
[14]刘盛博.科学论文的引用内容分析及其应用[D].大连:大连理工大学,2014.
[15]Small H G.Cited documents as concept symbols[J].Social Studies of Science, 1978,8(3): 327-340.
[16]许德山.科技论文引用中的观点倾向分析[D].北京:中国科学院文献情报中心,2012.
[17]Nanba H, Kando N, Okumura M.Classification of research papersusing citation linksand citation types:Towards automatic review article generation[C].Proceedings of the SIG Classification Research Workshop, 2000:117-134.
[18]Liu X, Zhang J, Guo C.Full-text citation analysis: A new method to enhance scholarly networks[J].Journal of the American Society for Information Science and Technology,2013,64 (9):1852-1863.
[19]Maricic S, Spaventi J, Pavicic L, et al.Citation context versus the frequency counts of citation histories[J].Journal of the American Society for Information Science, 1998, 49(6):530-540.
[20]胡志刚,陈超美,刘则渊,等.基于XML全文数据引文分析系统的设计与实现[J].现代图书情报技术,2012,28(11):72-77.
