基于本体的医疗卫生政策法律知识管理系统
2016-03-21,,
, ,
我国正致力于以全面维护和增进人民健康,提高健康公平,实现社会经济与人民健康协调发展为目标,以公共政策为落脚点,以重大专项、重大工程为切入点的国家战略。例如,中国卫生政策支持项目(HPSP项目)的目的是提高依靠证据建立并提高新政策的决策能力,通过合作机制,努力建立一个高效、公平和高质量的卫生政策支持系统,使各级卫生决策者能以合适方式及时地获得,从而为决策和管理服务。“健康中国2020”战略也提出了推动卫生事业发展的8项政策措施,其中包括建立与经济社会发展水平相适应的公共财政投入政策与机制。
国内已有的医疗卫生政策法规是卫生政策决策者制定新政策的重要依据之一,但相关政策法律又相当复杂,包括宪法、法律、行政法规、地方性法规、规章及规范性文件,其法律效力、层次、适用范围都不同。因此,卫生政策制定者在制定一项政策之前往往要查阅大量相关政策法规。
医疗卫生知识管理的主要内容是对现有证据进行有效收集、分析、综合和传播,以保证相关卫生政策制定是以知识或证据为基础。有效的知识管理系统能及时全面地从各知识源获取所需要的知识并分析整合,形成医疗卫生政策相关的证据,通过合适的方式发布,提高国家和省级政策制定者利用健康和医疗相关知识的能力,使决策者在选择政策时获得全面系统的知识以帮助和支持相应的决策过程。
1 国内外研究现状
任何知识管理解决方案都应包含一种知识组织模型的思路,其具体技术实现有本体(RDF/OWL)[1]、主题地图(Topic Maps)[2]、Prolog[3]等多种方式。它们在知识表示能力、推理能力等方面各有优劣(见表1),可根据具体应用的需要进行选择。

表1 主流知识管理技术特点比较
在W3C联盟提出的语义网结构蓝图中,本体作为URL、XML之上知识表示层有着非常重要的地位。W3C联盟在2001年提出RDF(资源描述框架)技术标准和2004年提出的OWL(Web本体语言)技术标准[4]都是本体描述语言的具体国际标准。随着语义网的发展,本体被广泛应用于医疗卫生、国防、制造业、生物学、历史学、情报学等领域。例如,浙江大学计算机学院与中国中医药研究院(China Academy of Traditional Chinese Medicine ,CATCM)合作开发的Dartgrid[5],通过拥有70多个类及800多个属性的中医药正式本体从语义上整合了70多个遗留中药数据库。其中,中医药本体是作为单独的语义层存在的,其作用在于弥合遗留异构关系数据库之间的差异,从而从语义上将它们整合到一起,并且提供对中医药团体的一体化语义提问、查询和导航服务。国外最早研究医疗卫生法律本体的是2000年Despres等提出的Medical Law Ontology[6],它利用已有的法律核心本体和来自医学专业人士访谈为基础,并采取文本挖掘技术从法律文本中抽取领域词表,最终设计了一套医疗卫生法律本体,并提供统一的医疗卫生法律检索系统。Alessio等在2014年扩展了Eunomos法律知识管理系统[7],并构建了医疗法律本体映射,其目的是利用本体打通法律领域和医疗领域的知识鸿沟,主要用于诊疗临床路径推理和医疗法律服务辅助等方面[8]。
主题地图是用来组织和表示专业领域知识的一种ISO标准,是为了方便人们对于海量知识的管理及导航。一个主题地图是一些人们感兴趣的具体科目的主题,一些表示这些科目间关系的关联,以及一些作为这些科目相关信息资源。主题地图因其在知识与资源关联的描述上的优势而被广泛应用于档案管理、数字图书馆、教育等领域。它的局限性在于知识描述能力没有本体强,且没有推理机制。例如,挪威Cerpus AS公司BrainBank产品[9]是一款基于概念的学习的教育工具,利用主题地图技术使知识得以文档化,还可以将不同用户的主题地图融合用来表征一个组织的知识结构。
Prolog是当代最有影响的人工智能语言之一,由于该语言很适合表达人的思维和推理规则,在自然语言理解、机器定理证明、专家系统等方面得到了广泛的应用,已经成为人工智能应用领域的强有力的开发语言。Prolog是陈述性语言,一旦提交必要的事实和规则之后,Prolog就使用内部的演绎推理机制自动求解程序给定的目标,而不需要在程序中列出详细的求解步骤。例如,Basic Medical Knowledge (BMK)[10]使用Prolog作为逻辑规则来建立不同条件下诊疗临床路径推荐目录。
综上所述,从研究内容来看,国内外相关研究主要是通过提供统一的框架,使用本体减少知识整合过程中在概念上和术语上的混淆,从而使医疗卫生法律知识整合更有效。本文选择本体技术作为医疗卫生政策法律知识管理系统的核心,主要是利用本体对知识的描述来检索知识库,从而提高检索的效率和精确度。从用户角度来看,国内外相关研究主要是针对使用者,如医疗工作者、医院管理人员和医患纠纷律师,帮助他们解决法律实施过程中的具体问题。本文则是针对医疗卫生政策决策者,提供医疗卫生政策法律的制定、修改和废止的决策支持。
2 医疗卫生政策法律文件
2.1 医疗卫生政策法律文件结构
现行《国家行政机关公文处理办法》规定国家行政公文有13种:命令(令)、决定、公告、通告、通知、通报、议案、报告、指示、批复、意见、函、会议纪要等。可以按照上行文、下行文和平行文将公文分为三类。其中议案兼有上行文和平行文的双重特征,通知同时属于平时文和下行文之列,会议纪要可以是下行文,也可以是平行文。
医疗卫生政策法律种类繁多,主要包括医政类政策法规、药政类政策法规、妇幼类政策法规、防预类法规、卫生监督类法规、计划生育类政策法规、医院检疫类政策法规、血液制品管理的规定等。但由于国家对红头文件的格式有一定的显性的限制,并且长期以来,红头文件的书写也产生了一定的潜在的规律。这些限制和规律为信息管理工作和医疗卫生领域本体构建提供了一定的便利。从某种程度上讲,电子档案介于纯文本和元数据结构之间。电子政务档案一般由文件头、正文和文件尾组成,某些文件可能有附件。正文标题由主送机关、原由和事项组成;原由有依据和目的两种,事项的书写方式一般有并列式和递进式两种。其结构如图1所示。
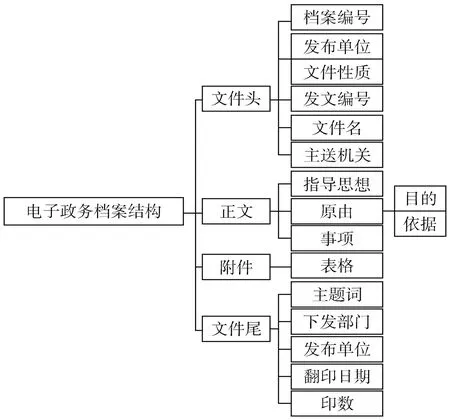
图1 医疗卫生政策法律文件电子档案结构
医疗卫生政策法律文件档案的载体多种多样,有些是Word文档,有些是tiff格式的扫描文件,还有一些是档案数据库,医疗卫生政策法律文件以扫描图片的方式进行存放居多。对于这种不同载体的数据的加工,需要对Word、PDF、tiff等各种形式的数据进行本文识别和抽取。本文采取基于XML的半自动方式进行本体知识提取。
2.2 医疗卫生政策法律文件关系
对于新制定的政策,知识管理模型应该能够指引出它和已有的政策法规之间的关系。以医疗卫生政策法律文件关系为例,从时间线来看存在着多种联系。如一旦上级召开某些医疗卫生政策会议,作为会议成果一般会产生一些新的思想和会议精神,一段时间后相关部门便会发布公文组织下属各级政府进行学习。
政府会承办一些活动,会组织各方面的人力物力来完成这些任务。具体来说,主要包括等价关系:新政策与已有的某个政策法规完全相同,那么就没有必要制定新的政策;矛盾关系:新政策与已有的某个政策法规完全相矛盾,那么需要考虑两个政策法规的法律效力的大小,即保留法律效力较大的那一个;包含关系:新政策的内容包含了已有的某个政策法规的内容,那么需要考虑新政策其他方面的内容;被包含关系:已有的某个政策法规的内容包含了新政策的内容,那么就没有必要制定新的政策;相关关系:新政策与已有的某个政策法规内容相关,那么可以做为相关参考。
3 医疗卫生政策法律本体知识库的构建
3.1 医疗卫生政策法律本体知识库内容
由于本文主要研究目的是让相关医疗卫生政策决策方便地使用医疗卫生政策法律文件,并将文件中所隐含的知识抽取出来建立本体知识库,使用户容易获取和利用。这些文件中的知识包罗万象,包括医学知识、诊疗规范和法律问题等,因此不太可能将其中所有的领域知识和常识知识全部抽取出来。
本文主要侧重于构建文件生命周期相关的知识,例如文件发布、文件修改、文件关系以及同一个法律问题的不同文件,它们也是医疗卫生政策决策者最关心的并在决策过程中希望搜索到的相关信息。搜索到之后,再根据文件内容进一步决策。
根据以上原则,本文选取OWL作为本体知识表示建模语言,用于构建知识分类树和知识关系。如表2所示,在领域专家的帮助之下设计了5个主要的本体知识分类,并用OWL语言进行了编码。

表2 主要的本体知识分类
医疗卫生政策法律文件并不是孤立存在的,它们之间存在着补充、修改、转发、印发、贯彻、集合各种关系,如表3所示。

表3 主要的本体知识关系
由于国内外环境的变化,我国各种医疗卫生政策创建、修改甚至废止非常常见,导致了医疗卫生政策法律文件相应的演变。不同版本的文件在不同时间节点上生效,涉及同一个医疗卫生社会问题而来自不同的政府部门颁布的文件也可能同时生效。这些医疗卫生政策决策者所无法回避的现实问题在本体知识库中都有相关定义。
3.2 医疗卫生政策法律本体知识的半自动抽取
由于医疗卫生政策法律文件特征非常明显,本文采取基于自然语言处理的方法,包括3个步骤。
3.2.1 文本提取
医疗卫生政策法律文件是tiff格式的扫描图片,包含若干个页面。本文利用微软的Office Document Imaging (MODI)来进行OCR文字识别,所有文件抽取的文本保存在txt文件中。如果医疗卫生政策法律文件是doc或者纯文本文件,那么不需要此步骤。
3.2.2 本体知识的正则表达式[7]抽取
由于文件都是按照特定格式严格撰写的,领域专家可以总结出基于正则表达式的本体知识抽取规则。例如,以下是两个文件之间“印发”关系的正则表达式:“([[[]&&[u4e00-/9fa5]][|<|(][u4e00-u9fa5》]])印发”。
3.3 标点符号识别
文件可以通过书名号“《》”识别,还包括兼容OCR错误识别出来的“<>”和“<<>>”等标点符号。这个步骤的产物是被识别出来的XML格式的本体知识以及本体知识关系本体编码:被抽取的本体知识通过Dom4j和Jena[11]来编码成OWL格式,最终被存储到Allegrograph[3]服务器中。
4 医疗卫生政策法律知识管理模型系统
4.1 后台知识管理系统
后台知识管理系统是通过Protégé[7]实现的,可以在知识库中录入数据或者修改数据。库中主要建立了“政策法规”“法律条文”“颁发单位”“专题”“事件”“时间”“卫生知识”“问题”“反映”等本体知识分类,图2为后台知识管理系统截图。
4.1.1 政策法规类
主要是描述国内卫生方面的政策法规。“政策法规”类具有一系列的属性来表示与该政策法规相关的一些知识:“发行时间”“实施时间”“失效时间”“标题”“所包含条文”“颁发组织”“文件编号”“前序法律”“后序法律”,其中“所包含条文”用来包含“法律条文”类的实例,“颁布组织”的取值范围为“颁发组织”类的实例。
政策法规类下面又分有8种子类:“卫生基本法”“ 公共卫生服务法”“ 医疗保障法”“ 健康促进法”“ 公共卫生监督法”“ 环境保护法”“ 公共卫生危机管理法”、“ 国际公共卫生法”,每个子类具有一系列的实例与其对应。如图2所示,“卫生基本法”就对应“中华人民共和国传染病防治法”“中华人民共和国卫生检疫条例”等8个本体实例。
4.1.2 法律条文类
用来表示政策法规中的每个条文,该类具有“所属法律”“全文”“编号”“细化法律”“相关知识”“关系”等属性。
“所属法律”表示该条文属于哪一个法律,“编号”表示该条文在其所属法律中是第几条,“细化法律”则是用来表示哪部法律有对该条文的进一步解释;“相关知识”用来表示跟该条文相关的一些知识,它的取值范围是“卫生知识”类的实例;“全文”则是表示该条文的全文;“关系”属性用来表示条文之间的关系,其下还有“细化”“包含”“冲突”“等价”4个属性,“细化”属性表示一系列属性是一个属性的细化说明,“包含”属性表示一个条文包含另一个条文,“冲突”属性表示一个条文与另一个条文相冲突,“等价”属性表示两个条文之间的等价关系。
4.1.3 专题类
用来表述一些人们特别关系的法律专题知识,该类具有“所包含的条文”“发布时间”“相关知识”。下面分有一系列子类:“药政”“医政”“防疫”“卫生监督”“中医药”“妇幼”“医药管理局”“爱国卫生”“卫生检疫”“计划生育”“地方法规”“其它”,每个子类又有一系列实例。如 “卫生防疫”具有“狂犬病”“血吸虫”“非典”等实例。“狂犬病”专题的“所包含的条文”属性值为一系列“法律条文”实例。
4.1.4 卫生知识类
用来描述与健康相关的知识或支持卫生系统的信息、技术、专业知识和经验等,具有“相关条文”“相关专题”“全文”等属性。
“相关条文”或“相关专题”用来表示与该知识相关的条文或专题,“全文”则表述该卫生知识的全文。“卫生知识”类有三个子类:“疾病信息”“ 健康危险因素信息”“ 基本卫生信息”,均含有一系列的实例。例如,“传染病”类对应于“SARS”“新生儿破伤风”“流行性疾病”“猩红热”“ 血吸虫病”“疟疾”等实例。
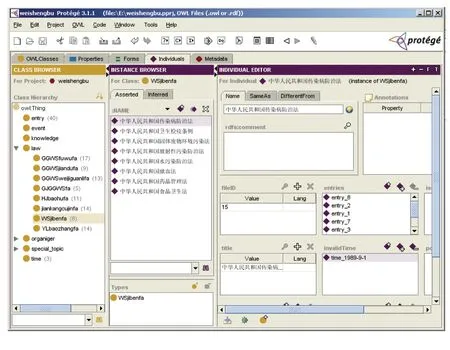
图2 后台知识管理系统截图
4.2 前台知识检索系统
系统前台提供基于关键词的法律法规全文检索功能。如图3所示,用户以“传染病”为检索关键词,将法律法规颁布时间限定在1976年1月至2007年1月之间。颁布部门限定在国务院,法律法规类型选项将检索结果限定在法律范围之内。满足以上条件的法律很多,返回结果有《中华人民共和国食品卫生法》等,证明用户对该法最为感兴趣。用户选择该法律之后,有关该法律的简要信息,包含用户关键字的条款等被返回给用户。
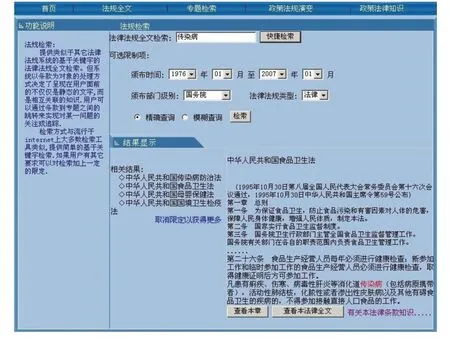
图3 法规检索系统功能
专题演变提供用户所选法律专题的不同时间段、不同行政级别所颁布的法律条文变化情况。如图4所示,在左栏的“专题演变”分类列表中用户选定“非典”专题,而在右上的“条件设置”栏目中,用户设定开始时间段和结束时间段以及颁布法律的行政级别及机构,比如选“部级”和“卫生部”,点击“提交”,在下面的栏目中将呈现图中的变化图片,图片中粉蓝色部分是2003年5月卫生部所颁布的法律条文,而粉红色部分是2003年6月颁布的法律条文,这两部分的重叠部分是5、6月颁布的法律中语义相同的法律条文。将鼠标移至某一条文,将在图中显示该条文所属法律文本的名称和颁布时间。
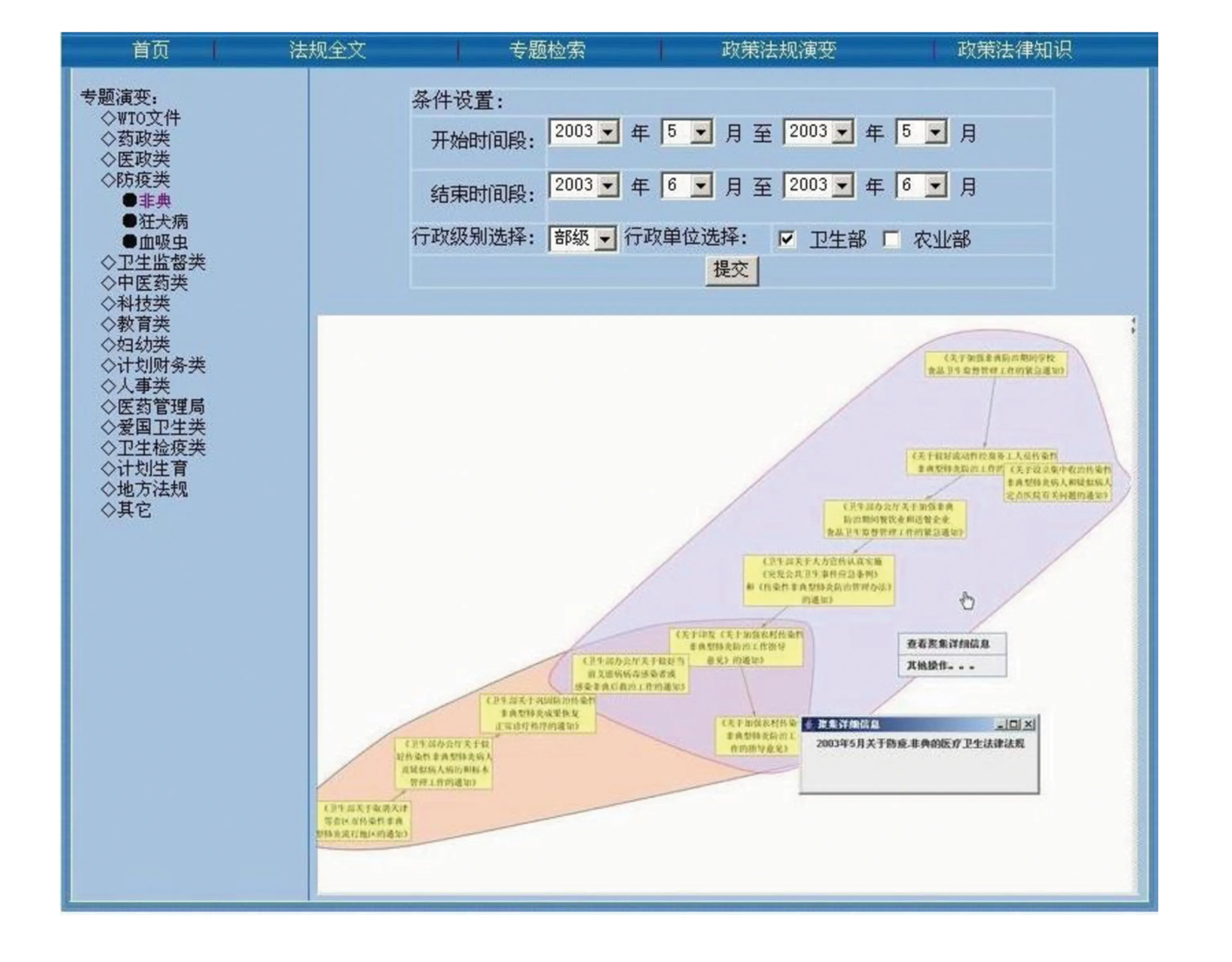
图4 专题演变系统功能
5 总结
本文提出了基于本体的知识组织模型具体实现机制,并以国内卫生政策法规为突破口,建立国内卫生政策方面知识库,使得决策者在制定政策时便捷地充分地获取相关政策法律知识以帮助和支持相应的政策制定过程,能够较好地解决卫生政策制定的知识组织、知识检索和知识服务等问题,达到提供给卫生政策制定领导并作为辅助决策的依据的目标。
在实践过程中,该系统在数据更新和发布方面有一定滞后性,主要原因在于知识管理后台系统在体系结构上属于单机系统,暂无法满足多用户快速更新维护数据的要求。未来将进一步研发和完善基于Web架构、网络版本的知识管理后台系统。
