基于分布式集群环境的图聚类信息高效处理方案
2016-03-17刘娟娟丁嘉宁
刘娟娟 丁嘉宁
1(天津天狮学院信息与自动化学院 天津 301700)
2(天津大学港口与海洋工程天津市重点实验室 天津 300072)
3(军事交通运输研究所 天津 300161)
基于分布式集群环境的图聚类信息高效处理方案
刘娟娟1丁嘉宁2,3
1(天津天狮学院信息与自动化学院天津 301700)
2(天津大学港口与海洋工程天津市重点实验室天津 300072)
3(军事交通运输研究所天津 300161)
摘要针对人工智能领域图聚类数据分析与处理能力无法适应于日益复杂的分布式集群环境等问题,设计出一种基于并行计算的高效率图聚类信息处理方案。通过对Minhash算法以MapReduce架构理论进行改进,使其实现对数据的并行化分析处理,以确保其能够在日益复杂的分布式集群计算环境下高效处理图聚类数据信息。通过相关实验表明,该方案不仅可行,而且能够对图聚类数据信息进行快速稀疏化处理,具有一定的高效性。
关键词人工智能数据挖掘MapReduce图聚类Minhash
EFFICIENT GRAPH CLUSTERING INFORMATION PROCESSING SCHEME BASED ON DISTRIBUTED CLUSTER ENVIRONMENT
Liu Juanjuan1Ding Jianing2,3
1(College of Information and Automation,Tianshi College,Tianjin 301700,China)2(Key Lab of Harbor and Ocean Engineering of Tianjin,Tianjin University,Tianjin 300072,China)3(Military Transportation Institute of the General Logistics Department,Tianjin 300161,China)
AbstractIn order to solve the problem that the analysing and processing abilities of graph clustering data in artificial intelligence field can’t adapt to the increasingly complex distributed cluster environment, we design a parallel computing-based efficient graph clustering information processing scheme. In this scheme, the Minhash algorithm is improved based on MapReduce framework theory to enable it to achieve the paralleled analyses and processing on the data, so as to guarantee it being able to efficiently process graph clustering data information in increasingly complex distributed cluster environment. It is indicated by related experiment that this scheme is more than feasible, it can also quickly carry out sparseness processing on graph clustering data information, and has certain high efficiency.
KeywordsArtificial intelligenceData miningMapReduceGraph clusteringMinhash
0引言
网络交互体系变得越来越复杂,将其建模成图模型[1]是其必然的趋势。在这种图模型里面,各结点主要用来描述对象实体,而各边主要是描述对象实体的关系。例如社交网络体系即属于无向图模型结构的范畴,各结点所指代的内容为社交个体或群体,各边指代社交个体或者群体间的关联,主要包括朋友、同事等[2]。现阶段,伴随信息技术和网络的日益发展,尤其是Web3.0网络的问世,各种虚拟网络应用产品在实践中得到普及,例如微博等,其图数据信息的处理量不断增加,形成了海量图数据信息,从而使图数据挖掘与分析应用能力面临一系列非常严峻的挑战[3-5]。
作为图数据挖掘与分析应用的重要作用之一,图聚类主要根据聚簇对图模型中的各结点实施分类操作,同时增加同类聚簇图结点对象实体的关联性,减小异类的关联性。现阶段,图聚类在实践中已经普及,如交通运输规划分析等。因此,伴随各种超大规模图数据信息与处理机制的问世,怎样科学合理地进行图聚类分析与处理,在此基础上,对其中潜在的有效数据进行挖掘,已经发展成为该领域的一个重要课题[6]。
数据抽样[7]属于其中非常有效的一个方式。其大致步骤为:抽取整体数据集合里面的局部样本,利用这种方式实施数据挖掘处理与分析,旨在实现时间和挖掘处理结果的高性能比。在分析过程中,应当先依次对图模型里面包含的各结点和边实施数据抽样操作,通常情况下,这个步骤叫做图稀疏化处理;然后对上一步得出的结果实施图聚类分析,这样就可以使图聚类分析与处理的有效性有所提升。
作为图聚类中非常关键的步骤之一,图稀疏化处理机制[8]已经在诸多领域中得到应用。针对小区域范围、小规模的图模型数据信息,当前业界形成的图稀疏化处理机制大体上涉及到k-最近邻图、L-Spar等技术。但是,当前的技术均无法满足较大区域与规模图模型数据信息的需要,除此之外,还无法在分布式集群计算环境中有效应用。
考虑到当前图模型应用产品的日益更新,其应用规模同样逐渐增加,数据信息逐渐增大,单一的计算环境无法充分适用数据分析与处理,同时导致图稀疏化处理机制不能发挥作用。所以,引入MapReduce并行计算理论已成为目前一个明显趋势,其能够关联操作大规模服务终端,可以充分解决大规模数据分析与处理的需要。鉴于这个方面的原因,笔者主要阐述了基于并行计算的高效图稀疏化处理算法。
传统的最小哈希算法[9](Minhash)基本上是用来求解若干数据集合间的相似程度,目前为止,该种方法在诸多热门课题中得到应用[10]。具体来说,该种算法基本上是参考Jaccard相似度,通过K个Hash函数分别对2个数据集A、B实施Hash操作,两者分别得到K个Minhash参数值。这样,两者的相似值即Minhash参数值一样的元素数和总体元素数之比。截至目前,业界许多相关专家已经对图聚类的性质展开探讨,得到一种启发式图聚类规则集合,叫做同一聚簇条件下的各结点相似的邻居结点集合。因此,邻居结点集合内的相似结点非常有可能处在同个聚簇之中。在稀疏化处理机制中,该种规则集合即2个关联结点存在的边能够被存储。不同的是,要是2个结点的邻居结点集合具有相对偏低的相似程度,在这种情况下,则2个关联结点的边将被删除。这与Minhash算法大致相似。
基于上文中提出的基本原理,笔者细致深入地探讨了在分布式集群计算环境下对超大规模、超大区域范围图数据信息的稀疏化分析与处理机制的改进[11]。笔者主要是基于MapReduce理论,对Minhash算法实施并行化分析,通过研究,阐明了以并行计算为基础的高效图稀疏化处理方案。自技术层面入手,该方案通过并行计算MapReduce框架结构[12],对诸多任务的推算进行研究:(1) Minhash算法签名推演;(2) 邻居结点数据集合推算;(3) 各结点相互间的签名哈希存储;(4) 稀疏化处理计算。除此之外,笔者在Hadoop计算环境下,对方案的性能实施相应的实验,通过研究发现,在图聚类稀疏化分析与处理机制中,引入该方案为机制的高效性能提供了坚实的保障。
1相关研究
这一部分细致深入地阐述了Minhash算法和并行计算MapReduce架构理论等相关内容。
1.1Minhash算法
上文中我们已经提及,Minhash算法基本上是参考Jaccard相似度实施的推算。Jaccard为相似参数值,主要是在检测若干数据集合相互间相似度的过程中应用。例如利用其对A、B数据集合实施相应的操作,就能够得出:
(1)
式中,Jaccard参数值为A、B的对比数值。可以看出,2个数据集合相似度越高与Jaccard参数值呈正比例关系。但是,当数据集合相对较大时,Jaccard参数值将为交并集合的规模所限制,它的效率就不能增加。
Minhash算法主要参考Jaccard参数值有关理论,首先,通过Hash函数求解两个数据集合的总元素数量,其次,得到相关结果信息,也就是Minhash(A)和Minhash(B),因此:
(2)
这样,在这一个算法里面,相似度问题就转变为若干数据集合的等值概率数学问题,最终在很大程度上优化了计算效率。
1.2并行计算理论
谷歌最早阐明了分布式框架理论体系,基本上是在超大规模、超大区域范围的数据集合分析与处理机制中应用。作为并行计算的一个重要架构,MapReduce能够使相关人员在并行编程过程中,仅仅需要侧重其应用体系内的分析与处理机制就可以,根本不必考虑那些冗余、繁琐的分布式事务。这同样属于并行计算理论所具有的一个非常明显的优势。
MapReduce并行计算的操作步骤如图1所示。

图1 MapReduce并行计算工作流程
通过图1得知,一般情况下,MapReduce分布式任务往往都离不开有关分析与处理过程,大致步骤如下:
(1) Mapping环节:利用这一个步骤,任一Map函数操作若干Split数据集合,在此基础上,将有关参数值输出,也就是若干
(2) Combine环节:对第一步中若干
(3) Reducing环节:这一个步骤主要是对上文中经过有关处理的若干
Hadoop为并行计算工具,目前已经得到普及推广。笔者在这里主要通过Hadoop实现本文所设计方案的模拟实验处理过程。模拟实验操作于Hadoop平台下的MapReduce应用程序,其大体上包括Mapping类(1个)、Reducer类、新建的JobConf驱动方法及关联Combiner类。
2问题描述
当前业界研究结果中,L-Spar算法的原理如下所示:就图模型的边v(i,j)来说,根据i和j两个结点间的Jaccard参数值来选择相应的删除或存储方法。按照式(1)能够求解出i和j两个结点的Jaccard参数值,则有:
(3)
式中,Adj(i)表示和i结点的邻居数据集合,与之相同,Adj(j)则表示和j结点的邻居数据集合。
Sim(i,j)输出数值的高效计算应用了最小哈希函数在数据集合相似程度求解过程中的优势。其具体求解过程见图2所示。

图2 L-Spar算法具体描述图
对于L-Spar算法来说,其基本上是基于小规模环境中的图聚类稀疏化分析与处理机制。当其处于超大规模分布式集群计算条件下时,在这种情况下,它的算法优势将不能得到充分发挥。所以,为妥善解决超大区域范围、超大规模的分布式集群计算问题,笔者在这里主要基于并行计算MapReduce架构理论体系,在此基础上,优化L-Spar算法,然后把它引入到图聚类的稀疏化分析与处理机制,最终得到以并行计算为基础的高效图稀疏化处理方案。笔者在后文会细致深入地对该方案进行阐述。
3高效处理方案
针对超大规模、超大区域范围的分布式集群计算条件提出的方案,其具体操作步骤大体上涉及到4方面内容,分别为:(1) Minhash算法签名推演;(2) 邻居结点数据集合推算;(3) 各结点相互间的签名哈希存储;(4) 稀疏化处理计算。
3.1邻居结点数据集合推算
本文所设计方案的首个环节是对一组Map任务得出图模型中任一边结点的邻居结点数据集合,具体来说,其操作步骤见图3所示。

图3 邻居结点数据集合推算流程
通过图3得知,Map任务获取一组键值对数据信息,结点信息为vi和vj。经由求解发现,输出键值对数据信息为
Map:
→
3.2Minhash算法签名推演
本文所设计方案的第二个环节是对图模型中任意结点的Minhash算法签名数据信息进行推算。鉴于此,本文所设计方案可结合Map和Reduce任务,在此基础上,推算Minhash算法签名数据信息,具体来说,其操作步骤见图4所示。

图4 结点Minhash算法签名推算流程
在这里,Map任务的输入参数值为首个环节得到的输出结果。通过上面的图形,Map任务主要是将若干Minhash函数(k个)当作其输入参数值,在此基础上,利用Hash推算,就能够得到其键值对数据信息
Map:
→
(m=1,2,…,k)
Reduce:
→
此部分的操作步骤包括若干子环节,接下来笔者将进行阐述:
(1) Map任务处理描述
输入
输出
1. list[Hm]←φ/*初始化结点的邻居结点数据集合的Minhash值列表*/
2. foreach vi in Graph do
for m in k
/*对结点的邻居结点数据集合进行k次Minhash计算,并将hash结果存储于Hm列表中*/
Hm=Minhash(list[Ni])
end for
end foreach
(2) Reduce任务处理描述
输入
输出
1. Sig[i][m]←φ/*初始化结点的签名矩阵*/
2. foreach vi in Graph do
Sig[i]=sortSig(Hm)
/*对结点的hash值列表排序,依次存储结点的签名矩阵*/
end foreach
3.3结点签名之间的哈希存储
本文所设计方案处理操作的这一个部分旨在判断图模型里面每一结点关联邻接边是否为图聚类稀疏化结构。实质而言,其主要是通过结合Map和Reduce的方式推算任一个结点,其具体描述步骤如图5所示。

图5 结点签名的哈希存储处理流程
通过图5得知,这个环节的Map任务环节输入为该方案的首个环节中获取的键值对数据信息
Map:
→
Reduce:
→
这一个部分与该方案的第二环节一样,其处理步骤同样包括若干子环节,见下文所示:
(1) Map阶段处理描述
输入
输出
1. list[S]←φ/*初始化结点的邻接边的签名数据集合列表*/
2. foreach vi in Graph do
for vj in list[Ni]
/*分别找出对应于结点和邻居结点数据集合中的结点的签名序列*/
temp1=FindSignature(vi,Sig)
temp2=FindSignature(vj,Sig)
/*函数FindSignature(x,Sig)返回在签名矩阵Sig中x结点的签名序列*/
S(Sig[i],Sig[j])=Integration(temp1,temp2)
/*函数Integration(x,y)返回x与y结合的集合*/
end for
end foreach
(2) Reduce阶段处理描述
输入
输出
1. list[SortCij]←φ/*初始化排序后的结点与邻居结点签名匹配列表*/
2. foreach vi in Graph do
foreach
/*分别对结点与邻居结点的签名进行hash操作*/
hashtable1=Minhash(Sig[i])
hashtable2=Minhash(Sig[j])
Countij=MatchTable(hashtable1,hashtable2)
/*函数MatchTable(x,y)返回x与y之间相同数量*/
SortCij=sortCount(Countij)
/*函数sortCount(x)返回降序排序的x列表*/
end foreach
end foreach
3.4图聚类过程中的稀疏化处理计算
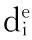

图6 保留存储结点处理流程
Map:
→
这一个部分的处理步骤见下文所示:
输出
1. list[top]←φ/*初始化结点需要保留的邻居结点数据集合*/
2. foreach vi in Graph do
/*函数ToSave(x,y)返回x列表中前y条边,并且根据边找到其所含的结点,并记录下来*/
end foreach
在该方案的最后一个环节实施以后,图模型里面的各结点都对e大于1的边的数量进行存储,这样就为图模型处于连通状态提供了保障。
4模拟实验
现简要模拟本文所设计方案,并通过对比检验其效率。
Hadoop平台主要是由最基础最重要的两种组成元素组成,底层为用于存储集群中所有存储节点文件的文件系统HDFS (Hadoop Distributed File System),上层由用来执行 MapReduce 程序的 MapReduce 引擎[13]。HDFS 是一个分布式文件系统, 具有高容错性的特点,能够完整展现出分布式集群环境中集群的特点[14];按照计算机分布式思想,分布式计算是指将巨量的计算任务分配成许多小任务并由众多的计算机进行处理,Hadoop平台上的MapReduce 编程架构可以实现任务的分配,并把分配后任务的运算结果汇总,完全可以实现对分布式集群环境运算模式的仿真,因此本文选择Hadoop平台正是基于以上目的,有效体现分布式集群环境的特点,并对其可能存在影响因素通过在Hadoop仿真平台进行实践。
4.1相关配置
笔者在这里采用MapReduce,将其引入到Hadoop分布式集群计算条件中。主要包括若干服务器和终端等方面,其中包括主机1台,别的均为附属机,计算环境下的每一结点CPU处理器工作频率始终处于3.20 GHz,因特尔双核处理芯片,内存必须≥1 GB。Hadoop分布式计算环境版本为1.0.5,OS,Java语言。数据信息源为新浪微博社交虚拟网络的关联图模型。
模拟过程中主要通过Speedup参数值描述本文所设计方案的性能指标参数变化。其具体可以通过下面的公式进行描述:
Sspeedup=Ti/T1
(4)
上面的式子里面,Ti指第i个分布式集群计算条件下结点对图模型稀疏化分析与处理所用时间,T1指单机条件下对图模型稀疏化分析与处理所用时间。
4.2操作和分析
模拟过程中选择不同的图模型稀疏化处理机制,得到的图模型稀疏化比率参数值e同样存在着一定的差异,为解决各种数据信息量和分类的图模型数据信息,对应的最合理的e值同样存在一定的差异。笔者在这里取e为0.15,在此基础上实施有关操作。
为体现本文设计方案在超大规模、超大区域范围的分布式集群计算环境下的高效性能,模拟过程中笔者主要使用不同并行计算条件下的执行算法。该方案第一步是对Map和Reduce任务阶段实施过程处理,接着分析了图模型数据信息,完成稀疏化分析与处理机制。模拟过程中涉及到的数据信息如图7所示。

图7 模拟实验分析结果
通过图7发现,对于超大规模、超大区域范围的分布式集群计算环境下,引入Hadoopp并行计算平台可以明显减少时间损失,最终可以显著提高Speedup。按照MapReduce理论,图模型数据信息规模与图聚类过程稀疏化比率参数值两者存在正相性;但是伴随分布式集群计算条件下每一结点的通信过于频繁,同样能够消耗或多或少的数据信息性能,当图模型数据信息交互规模相对偏小时,在这种情况下,图聚类过程稀疏化分析与处理机制效率将有所下降,对应的e参数值同比降低。另一方面,当Speedup和分布式集群计算环境不断提高时,其图聚类过程稀疏化分析与处理机制同样不断增加,其e参数值同比提高。
4.3算法聚类能力准确度分析
为了体现本文算法在分布式集群环境中准确度的优势,下面在Hadoop平台上,将本文所设计方案与基于MapReduce的K-means聚类算法做对比(这种算法的实现见参考文献[16])。在准确度评价体系上,这里引入F度量值来衡量算法的聚类准确度效果,具体涉及查准率与查全率[17],其中:
查准率=(第i类的正确文本数/第i类的实际文本数)*100%
查全率=(第i类的正确文本数/第i类的应有文本数)*100%
F度量值综合查准率和查全率,将两者等同考虑,以此来衡量算法的聚类准确度,第i类:
其中Pi是第i类的应有文本数,P是文本数。
在本对比实验中,原始数据来自于国家超级计算机中心的数据库的相应的数据类别中随机调取的部分数据[18],原始数据见表1所示。

表1 实验基础数据
实验结果见表2所示,从表2可以看出本文所设计方案的F度量值要优于基于MapReduce的K-maens聚类算法,即其聚类质量占优,同时其分类准确率也相应提高。

表2 F度量值对比值
4.4方案运行时间分析
为了进一步检验本文所设计的算法的效率,下面将本文所设计稀疏化方案与基于k-medoids聚类算法局部图稀疏化方案[19],在运行时间上做对比。k-medoids聚类算法具有收敛快、运行简单的特点,在业内时间复杂度上有较为明显的优势。运行平台与4.3节相同,实验素材采用DBLP数据集[20],运行时间对比数值见表3所示。

表3 运行时间对比图 单位:s
表3中e代表稀疏化比例参数,从表3可知,本文设计的方案,在与k-medoids聚类算法相比仍具有一定的时间优势,并且在不同的稀疏化比例条件下,其性能表现较为稳定。
经由模拟实验我们发现,本文所设计的方案更适合超大区域范围、超大规模的分布式集群计算环境下的图数据信息,因在该方案里面增设排序组合机制,正是这一个方面的原因,导致结点和邻接结点间的通信消耗有所减小,也就是图数据信息规模与算法效率性价比两者呈正比例关系。
5结语
针对超大规模、超大区域范围的分布式集群计算环境,笔者主要是基于MapReduce理论,对Minhash算法实施并行化分析,通过研究,阐明了以并行计算为基础的高效图稀疏化处理方案。这一个方案可以对图聚类数据信息进行高效处理。经由模拟实验可知,这一个算法具有较高的可操作性,同时可以快速稀疏化处理图聚类数据信息,简单高效。
参考文献
[1] Lin J,Schataz M.Design patterns for efficient graph algorithms in mapreduce[C]//MLG,2010,22(3):78-85.
[2] Lv Qin,Josephson W,Wang Zhe,et al.Multi-probe LSH:efficient indexing for high-dimensional similarity search[C]//Pro of the 33rdInt Conf on Very Large Data Bases(VLDB’07).Vienna Austria:VLDB Endowment,2007,10(2):950-961.
[3] Yang H C,Dasdan A,Hsiao R L,et al.Map-Reduce-Merge: Simplified relational data processing[C]//Proc of ACM SIGMOD International Conference on Management of Data,New York:ACM,2007:1029-1040.
[4] Vrba Z,Halvorsen P,Griwodz C,et al.Kahn process networks are a flexible alternative to mapreduce[C]//Proc of IEEE International Conference on High Performance Computing and Communications,Piscataway:IEEE,2009:154-162.
[5] Sandholm T,Lai K.MapReduce optimization using regulated dynamic prioritization[J].Performance Evaluation Review,2009,37(1):299-310.
[6] Liu Q,Todman T, Luk W,et al.Combining optimizations in automated low power design[C]//Proc of Design, Automation&Test in Europe Conference&Exhibition,Piscataway:IEEE,2010:1791-1796.
[7] Chen Quan,Zhang Daqiang,Gao Mingi,et al.SAMR:A self-adaptive mapreduce scheduling algorithm in heterogeneous environment[C]//Proc of IEEE International Conference on Computer and Information Technology,Los Alamitos:IEEE computer society,2010:2736-2743.
[8] Nicolas Garcia-Pedrajas,Aida de Haro-Garcia.Scaling up data mining algorithms:Review and taxonomy[J].Process in Artificial Intelligence,2012,1(1):71-87.
[9] Satu Elisa Schaeffer.Scalable uniform graph sampling by local computation[J].SIAM Journal on Scientific Computing,2010,32(5):2937-2963.
[10] 温菊屏,钟勇.图聚类的算法及其在社会关系网络中的应用[J].计算机应用与软件,2012,29(2):161-178.
[11] Arun S Maiya,Tanya Y Bergerwolf.Sampling community structure[C]//Raleigh,North Carolina,USA:WWW,2010:701-710.
[12] Choi Seung-Seok,Cha Sunghyuk,Charles C Tappert.A survey of binary similarity and distance measures[J].Systemics,Cybernetics and Informatics,2010,8(1):43-48.
[13] Apache.Apache hadoop[CP/OL].http://hadoop.apache.org/core/.
[14] 万波,党琦,杨林.基于HDFS管理MapGISK9瓦片地图集的研究与实现[J].计算机应用与软件,2013,30(12):232-235.
[15] 丁祥武,李清炳,乐嘉锦.使用MapReduce构建列存储数据的索引[J].计算机应用与软件,2014,31(2):24-28.
[16] 江小平,李成华,向文,等.k-means聚类算法的MapReduce并行化实现[J].华中科技大学学报:自然科学版,2011,39(S1):120-124.
[17] 肖升,何炎祥.改进的潜在语义分析中文摘录方法[J].计算机应用研究,2012,29(12):4507-4511.
[18] 高贺庆.一种适应高速数据流的聚类算法研究[D].长沙:湖南大学,2013.
[19] 温菊屏,林冬梅.图稀疏化:加速图聚类的有效方法[J].计算机工程与设计,2013,34(11):3934-3938.
[20] http://www.informatik.uni-trier.de/~ley/db/.
中图分类号TP311
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.02.051
收稿日期:2014-04-26。国家自然科学基金创新研究群体科学基金项目(51021004)。刘娟娟,讲师,主研领域:数字媒体技术。丁嘉宁,工程师。
