慢病管理是社区就医切入点
2016-03-16刘国恩
■文/黄 洁 刘国恩 谭 莹
慢病管理是社区就医切入点
■文/黄 洁 刘国恩 谭 莹
慢性疾病具有不可治愈性,患者需要长期接受健康行为干预,因此为慢病患者提供健康管理服务成为基层医疗机构工作人员日常的主要工作。广东省中山市某镇于2010年开始对当地高血压患者进行健康管理。社区卫生服务站医务人员主动找到高血压患者并询问其是否愿意参加慢病管理,项目的内容包括组织健康教育、提醒并督促患者服药、定期测量血压等生理指标,并提供有针对性的用药指导与健康指导。
描述性统计
本文的分析基于广东省中山市某镇卫生局提供的“高血压患者2012至2013年的门诊数据库”和“2012至2013年参与慢病管理项目的患者名单”等数据。 为了使用双重差分法,我们保留了2012年且2013年有门诊记录的高血压患者,在此基础上把2012年没有参加管理项目,且2013年参加了管理项目的高血压患者定义为处理组,把2012年、2013年都没有参加管理项目的高血压患者定义为控制组。最终得到5429个个体的平衡面板数据,其中有847个个体属于处理组,4582个个体属于控制组。
效果指标的选取。根据研究需要,本文选取是否参加慢病管理作为解释变量;选取“年人均社区门诊次数占年人均总门诊次数百分比” “年人均社区门诊费用占年人均总门诊费用百分比”“去社区门诊的可能性”作为评价慢病管理对分级诊疗效果的指标。效果指标的描述性统计结果显示,在没有控制其他变量,并且没有与控制组作对比的情况下,患者参加基层慢病管理后三个效果指标两年间变化为正,且在统计上显著异于零。初步结论是基层慢病管理对分级诊疗有促进作用。但是控制组在没有基层慢病管理政策干预的条件下,所有效果指标在两年间的变化也为正且显著异于零。以上结果说明政策之外的时间趋势对效果指标有显著作用,因此有必要用控制组的时间趋势估计处理组的时间趋势,通过双重差分来估计政策的净效果。
logit模型的变量选取。考虑到是否参加慢病管理并不是随机分布的,而是患者自我选择的结果,因此需要控制影响患者选择行为的因素。本文考虑的影响患者选择行为的因素包括两类。
第一类是患者对自身情况的考虑。由于慢病管理是社区为患者免费提供的服务,因此家庭经济收入对选择行为影响不大,所以我们的影响因素包括性别、年龄、疾病严重程度。值得注意的是,本文使用基期的门诊服务利用相关指标作为疾病严重程度的代理变量。理由如下,首先,由于数据的可得性,本研究无法用生理指标表示疾病严重程度。其次,自评健康、慢性病个数等健康状况指标与医疗服务利用高度相关,因此在没有疾病严重程度直接指标的情况下,用基期的门诊服务利用相关指标作为代理变量能有效提高项目参与概率估计的准确性。具体来说,门诊服务利用相关指标包括年人均门诊费用、年人均门诊药费、年人均门诊次数。
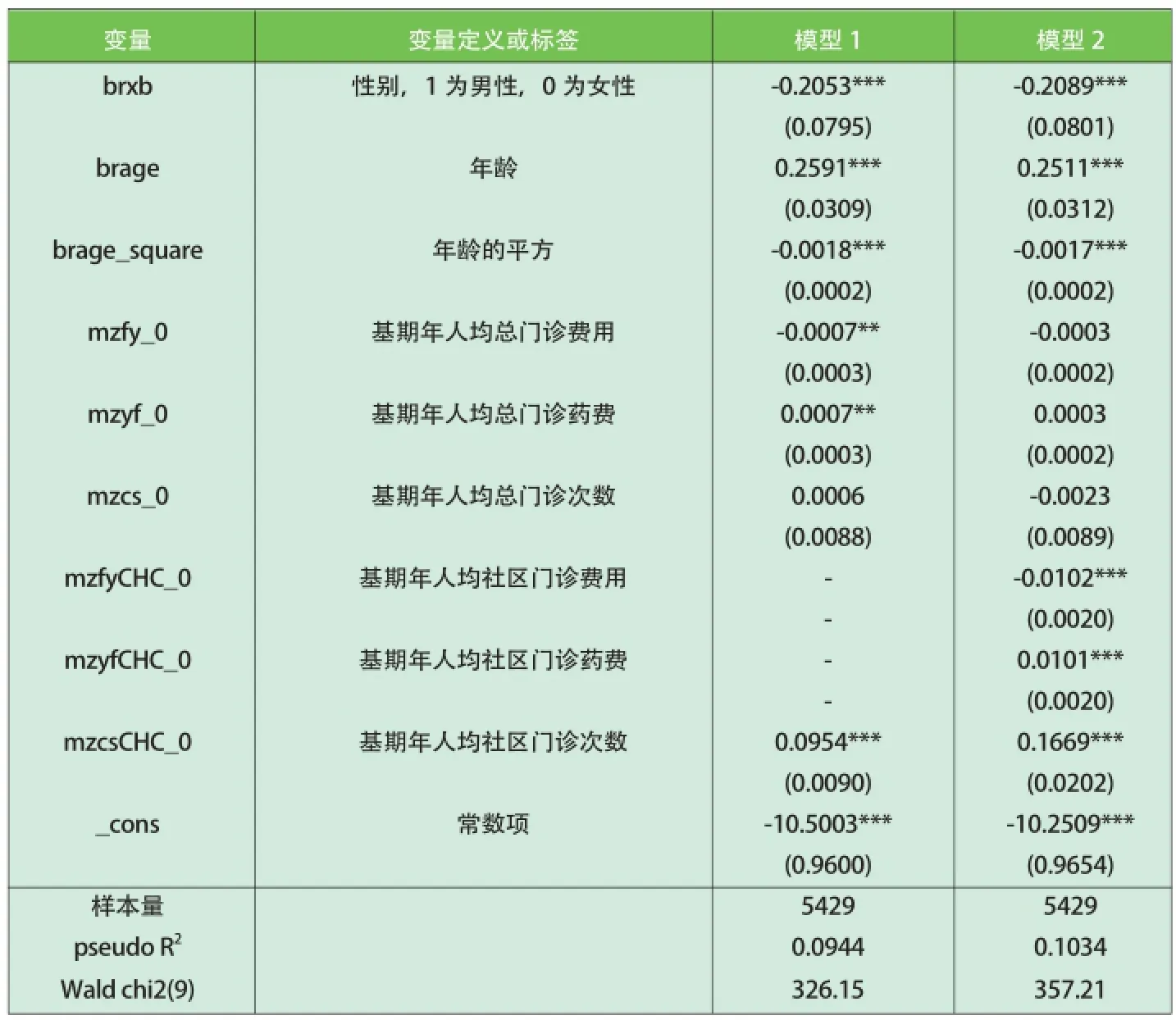
表1 高血压患者参加慢病管理可能性的logit回归结果
第二类是患者对医疗机构的认知。社区门诊服务利用程度高的患者对社区更熟悉,更容易与医务人员产生信任关系,于是更容易接受慢病管理。具体来说,社区门诊服务利用相关指标包括年人均社区门诊费用、年人均社区门诊药费、年人均社区门诊次数。
用logit模型估计患者参加慢病管理的可能性。统计结果显示,处理组与控制组在大部分变量上存在显著差异,这些差异有可能导致处理组与控制组的时间趋势不同。因此有必要进行匹配,在保证处理组与控制组时间趋势相同的前提下,采取双重差分的方法剔除处理组的时间趋势效果,得到纯粹的慢病管理对分级诊疗的政策效果。
倾向得分匹配
为了使处理组与控制组在基期可观测变量上没有显著差异,首先构建一个项目参与的logit模型,对每个患者参与项目的可能性进行预测,获得个体的倾向得分;再使用倾向值作为距离函数进行匹配,从而完成倾向得分匹配;最后根据匹配后样本用双重差分法估计平均处理效应。
倾向得分估计。根据影响患者是否选择参加基层慢病管理相关因素构建的项目参与概率的logit模型如下所示:

其中TreatmentGroupij是一个虚拟变量,表示2011年没有参加慢病管理的高血压患者在2012年是否参加慢病管理,TreatmentGroupij=1表示该患者在2012年参加了慢病管理。Xij是与患者项目参与率相关的基期(2012年)变量,包括性别、年龄、年龄平方、年人均总门诊次数、年人均社区门诊次数、年人均总门诊费用、年人均社区门诊费用、年人均总门诊药费、年人均社区门诊药费等9个变量。
根据上述logit模型,我们发现总门诊费用、总门诊药费的估计系数变得显著,社区门诊次数估计系数变小,这说明模型2中变量间的相关性使我们不容易区分它们各自对被解释变量的单独影响力,当我们希望准确估计单个解释变量的贡献时,显然模型1更合理。但是我们的研究目的仅在于预测Y,我们不关心具体的回归系数,只关心整个方差预测被解释变量的能力,有多重共线性的模型仍可以较准确的估计所有变量的整体效应。因此最终选择用pseudo R2更高的模型2对每个患者参与慢病管理项目的可能性进行预测,获得个体的倾向得分。在稳健性分析部分用模型1重新预测倾向得分值并进行匹配与双重差分分析。
匹配质量的统计检验。基于上述logit模型,我们对每个患者参与慢病管理项目的可能性进行预测,从而获得每个患者的倾向得分值,并采用不同的匹配方法将处理组与控制组匹配。具体匹配方法包括k近邻匹配、卡尺匹配、卡尺内的k近邻匹配、核匹配。经过变量平衡性检验,匹配质量最好的是核匹配。基于核匹配法的变量平衡性的检验结果表明匹配后处理组与控制组在9个变量上没有显著差异,并且9个变量的联合分布也没有差异。
双重差分法估计平均处理效应
为了保证结果的稳健性,我们采用bootstrap技术重复运行1000次从而保证有一个稳定的估计。结果发现高血压慢性病一经确诊,则需要长期治疗且治疗方法相对固定,对高血压患者进行慢病管理是高血压治疗的基础,它要求基层医疗机构的医护人员主动找到被医院确诊为高血压的患者,并为他们建立健康档案,定期为患者测量血压并给予专业的健康指导。参加慢病管理后,医务人员的宣传提高了患者对基层医疗机构的认知度,定期的血压测量与健康指导增进了医患间的相互了解与信任,这些改变了患者的就医习惯。具体来说,患者参加基层慢病管理后,去社区门诊的可能性增加了5个百分点,社区门诊次数占门诊次数百分比增加了4个百分点,社区门诊费用占门诊费用百分比增加了3个百分点。
进一步分析慢病管理对那些参加项目前就已经有社区门诊记录的患者的就医行为产生的影响,发现两个效果指标的变化在统计上并不显著。为了探索原因,我们估计了其他相关指标,包括年人均总门诊费用、年人均总门诊次数、年人均社区门诊费用、年人均社区门诊次数的平均处理效应。发现以上指标均为正且在1%的显著性水平上显著。对于在参加项目前已经有社区门诊记录的患者而言,医护人员的宣传与专业健康指导提高了其对高血压防治的科学认识,使其更愿意遵从医嘱定期服药并进行检查,因此门诊总费用与门诊总次数都增加。对于参加项目前不去社区门诊的患者而言,慢病管理提高了他们对基层服务机构的认识,增进了与医生间的相互了解,提高了患者到基层就诊的可能性,从而提高了社区门诊费用占比与社区门诊次数占比。■
作者单位:西南财经大学北京大学国家发展研究院陈星海医院公共卫生管理科
