基于特征粒子算法的云资源调度策略研究*
2016-03-15李明
李 明
(上海青年管理干部学院 上海 200083)
基于特征粒子算法的云资源调度策略研究*
李明
(上海青年管理干部学院上海200083)
摘要详细分析特征粒子算法的基本原理和特征粒子算法数学模型,将特征粒子算法的基本思想结合云计算环境中实际的服务质量参数要求,设计基于特征粒子算法来的参数的设置以及计算资源的优劣度评价标准,给出任务调度的算法流程。最后详细在CloudSim上进行仿真。通过仿真实验,将特征粒子算法与CloudSim自带的时间最优调度算法和贪婪算法进行了比较,验证了该算法的正确性和有效性。
关键词特征粒子; 云计算; 资源调度; 任务分配
Research about the Scheduling Strategy of the Cloud Resource Based on the Characteristics Particle Algorithm
LI Ming
(Shanghai Institute for Youth Management, Shanghai200083)
AbstractThe fundamental principles and mathematical model of the characteristics particle algorithm were analyzed detailed. And the basic idea of the characteristics particle algorithm was combined with the service quality parameter requirement in the cloud calculation environment, then evaluation criterion of the calculation resource was designed based on the design of the characteristics particle algorithm parameter, and the algorithm process of the task scheduling was presented. Finally, the related experiments were simulated on the CloudSim, and the characteristics particle algorithm was compared with the time optimal scheduling algorithm and greedy algorithm built in the CloudSim, then the correctness and effectiveness of this algorithm was verified.
Key Wordscharacteristics of particles, cloud computing, resource scheduling, task allocation
Class NumberTP393
1引言
云数据中心的资源调度技术是云计算应用的核心,是云计算得以大规模应用、提高系统性能、兼顾节约能源的关键技术。优越的动态资源调度,对于提高政府、学校和企业计算资源的利用效率、节约能源、提高资源共享和降低成本。建立起了云计算应用平台,加上一套完善的资源管理与调度过程进行软配合,才可以充分利用云计算这个大平台的所有资源,发挥云平台最大的效率。目前已经把贪婪算法、粒子群算法、蚁群算法运用到了云计算数据中心的资源调度上面。不过每种算法都有明显的优缺点,本文在总结以上各种算法的基础上,提出了基于特征粒子的调度算法,该算法不仅具有全局性,可以解决贪心算法很难找到一个简单可行并难以保证正确的缺点;而且还有很强的目的性,解决粒子群算法随机性非常大的缺点。
2特征粒子算法的基本原理
特征粒子算法是模拟从没有(或者很少)相似性、彼此之间离散分布的人群中寻找一个具有特定特征的目标人物的过程,设计出的根据特征群体分布寻找目标的智能搜索算法。运用特征粒子算法进行搜索的时候,不再考虑搜索的路径,而是对一个个的群体进行特征匹配搜索。当搜索的时候,将这个特征群体中最具有代表性的特征提供出来,然后将目标粒子的特征与该群体的特征进行特征集对比,如果这个特征群体完全不具备目标粒子的特征,则该群体中的所有的粒子将不再进行搜索。
面对大量的配置不同、效率不同的计算节点,初期采用动态对群体协作方法,主群侧重于全局搜索,次群侧重于局部搜索,将众多不同的计算节点根据特征系数ρ而分成不同的群体。每一个子群,计算出群的特征常量系数ρ:
(1)
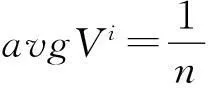
(2)
ρ=avgV1:avgV2:avgV3:…:avgVn
(3)
(4)
其中,Vi表示计算节点第i号属性的属性值,一个节点可以有n个属性;totalVi表示一个计算节点分组属性Vi的总和;avgVi表示属性Vi在一个分组中的平均值;ρ表示一个分组的分组特征系数;Mi表示第i个分组中单个节点的特征对比常量,该常量表示与该分组的匹配度,常量越大,表示节点越不匹配当前所在组。
(5)
根据式(1)~式(3),获得子集的特征系数,对比每一代子群每个节点的特征系数ρi,根据学习参数M,将其找到的处于学习范围之外的子集Ri(Ri∈Ui)。根据式(4),获得子集中的每一个计算节点的子集相对系数,根据式(5),将Ri中的每一个节点Rij归并到其他的能够容纳到相似特征系数的子群中,逐层计算子集并进行子集迁移,形成新的不同于初始化的集合,每一个集合都拥有在学习参数M认识范围内的子集;或者根据学习参数M无法找到被筛选出来的非子集的归属,则将未归属的子集,建立起新的集合Rnew(如图1所示)。最终形成一个拥有相似特征系数的集群。
(6)
T(i)表示一个特征节点执行模拟任务消耗的时间,g(Pi)表示节点的性能函数,f(ρi)表示节点i在模拟任务中执行函数。
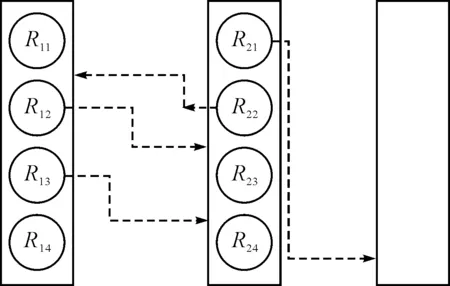
图1 节点迁移示意图
对已经特征化的种群搜索,主群对全局进行匹配搜索,次群则根据个体要求,从每一个特征种群中提取出最优特征个体,并满足个体的成本要求,从而得到次群中最优解,子群将最优可用个体集信息传递给主群,主群根据式(6),对子群最优个体重新进行归并优化,逐层挑选出最优个体。
通过这种方式,可以将各种特征的节点有序地管理在可控域中,对自己进行检索,即将各个自己中最优个体直接筛选出来,从而可以更加快速地避免对额外节点的筛选。
3参数设置及计算资源的优劣度评价条件
根据Map-Reduce架构模型,云中的每个计算节点由两部分组成:主作业调度节点、任务分配节点。主作业调度节点,负责一个区的节点任务分配,以及最终的任务执行结果的汇总处理;任务分配节点则负责执行被分配的作业,以及提交完成的作业。任务分配时,主作业调度节点将一个可分配的大任务,分解为可独立、并发执行的小任务——任务片段,并将这些任务片段,根据调度算法分配到各个任务分配节点中。Map端分配完成后,由各个节点分别执行被分配到节点上的任务,完成后通知主作业调度节点,完成收集任务节点执行的结果,并根据原来已经设计好的组合方案将结果整理起来并反馈最终结果——Reduce操作。
资源调度的优先级分配中,本地资源的优先级最高,异地的优先级次之。在分配作业的时候,如果本地的节点资源足以承受被分配的资源任务,根据本地优先的原则,将按照任务需要以及负载均衡的办法,完成本地资源的分配,保证任务可以完成的同时,整体使用的硬件资源最低、时间成本最低。如果本地的资源无法满足,则需要根据资源调度算法,对远程的节点进行任务分配。本文提到的特征粒子调度算法就是调度算法中的一种。
根据云计算资源调度的高度目的性——时间成本或价格成本等特性,可将各个节点根据成本进行特征划分。
根据资源特性,首先将本地资源充分利用,根据资源与任务的关系,可以获取一个任务曲线T、资源特征曲线R、时间成本矩阵M。如果任务曲线比较平缓,说明子任务的划分比较均衡;如果资源特征曲线比较平缓,说明本地的节点资源在性能上比较均衡;时间成本矩阵是根据当前的任务和当前的资源性能做出的一个时间成本无向图G(V,E),矩阵中每一个元素,都表示该任务在对应特征资源中使用的时间成本。
首先将本地的资源根据特征资源做一个基本的特征均衡分配,保证本地的资源已经被完全使用,并模拟测算出本地的模拟时间tsimu,根据tsimu将云中分配的多个主控域管理的最快时间进行对比,直接淘汰掉不符合最小时间成本的云团。当淘汰掉不符合基本时间成本的云团之后,在剩余的云团Cuse中,根据时间成本曲线Se,从云团中找到对应的特征节点,并由主作业调度节点,对该特征集中的节点进行预算,找到其中的最佳匹配节点,并反馈到最原始主作业调度节点中,针对尚未分配的资源节点,形成一个新的时间成本矩阵Gnew(V,E)。
Gnew(V,E)中V由多个异地节点组成,原本已经分配m个接近平衡的任务,一共有ntotal个任务需要分配,则需要从云节点中分配的节点为
V={v1,v2,…,vn};n=ntotal-m
而每一个云节点上的时间消耗,由计算市场tcalc和因在网络上传输的消耗tdelay组成:
ti=tcalc+tdelay;i∈[1,n]
当本地的资源分配的特征变化很大、本地资源不足以承担任务时,则将任务以游离的方式,在附近的云中的主作业控制节点进行资源交流,从而将任务特征属性转移到临近的资源节点中进行调度,而时间的成本,由原有的资源为起始进行叠加。直到找到在限制条件以内的时间成本尽量小的资源调度结果。
4算法调度的工作流程
首先,获取用户的任务并按照优先级进行排序、分类,分类体现了用户任务对不同QoS的需求,并根据的特征分类,利用特征粒子调度算法进行资源调度、分配。最大限度地满足要求、整体任务计划执行时间相对最短,达到此目标之后,即表示已经挑选出了最佳的任务分配,将计算任务与云中的计算资源进行M-N进行绑定,运行任务。其流程图如图2所示。
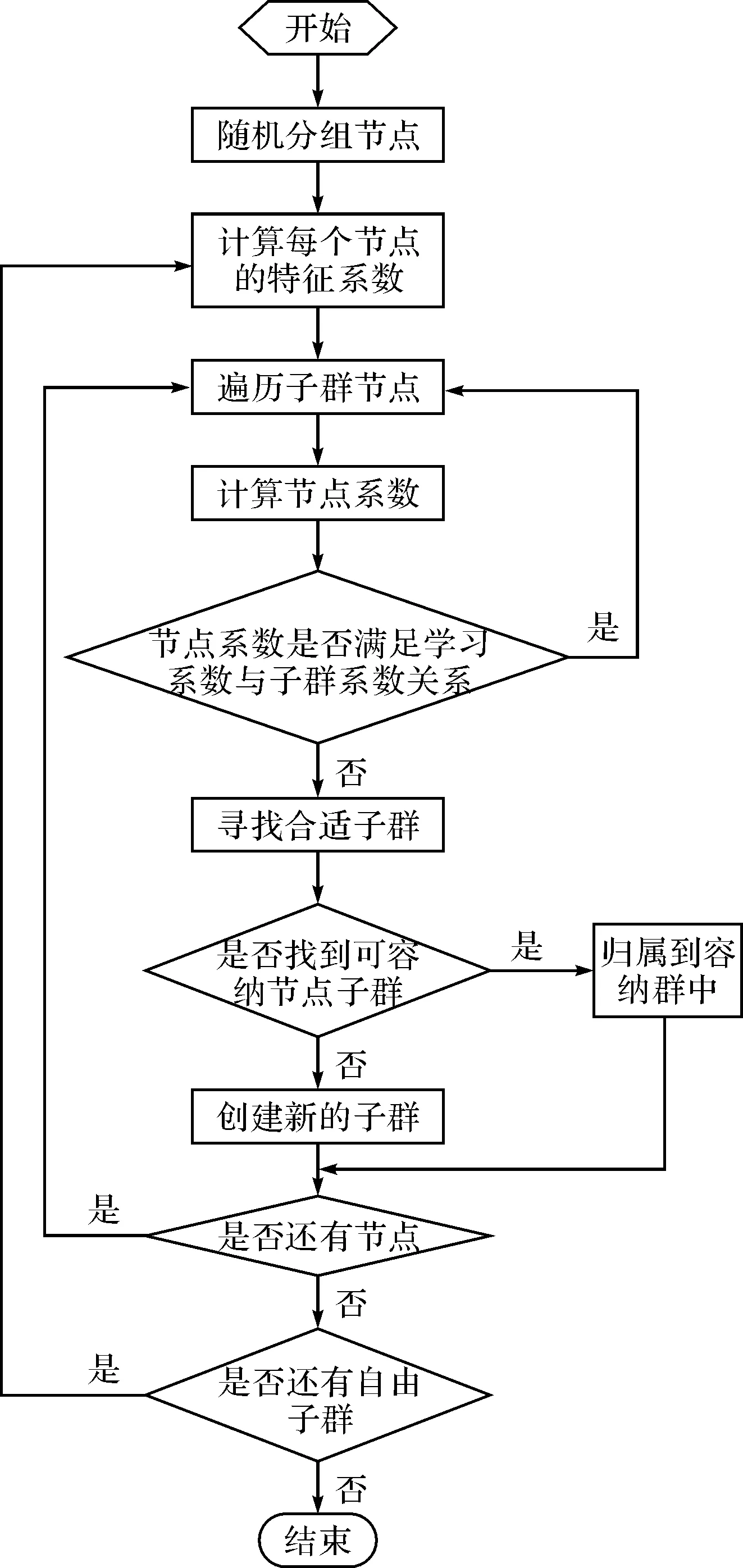
图2 算法调度流程图
5调度算法验证
由于CloudSim平台的限制,各个虚拟机资源的实时资源占用情况、虚拟机的故障率无法直接从平台中获取,以及CloudSim平台本身在通信上的约束管理上的不确定性,现使用CloudSim中任务的最终完成时间进行验证调度算法。为了验证调度算法,需要模拟尽可能复杂、具有代表性的虚拟环境条件,因此根据最有效的参数进行模拟:带宽、CPU的Mips、内存。
模拟分为两组进行,第一组的模拟,使用完全相同的虚拟机配置,对不同的任务进行处理;第二组使用不同的虚拟机配置——虚拟机具有不同的参量比,对不同的任务进行处理。
第一组:
虚拟机配置:

表1 虚拟机硬件配置
任务设置:
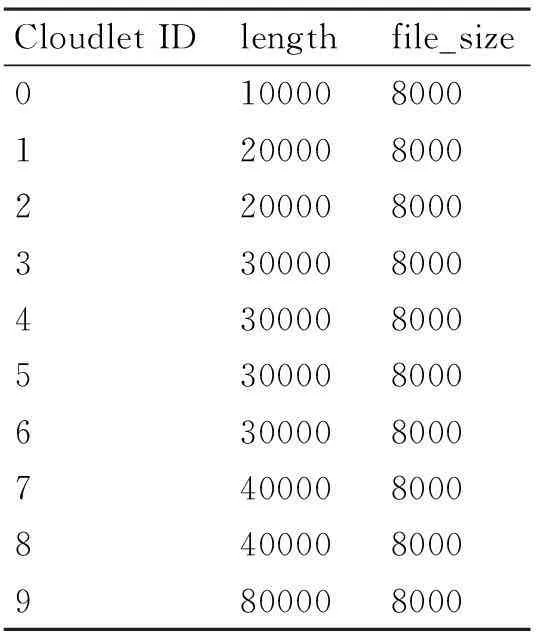
表2 虚拟机模拟云任务长度配置
对于第一组的虚拟机、任务的设置,所有的虚拟机都是用了相同的配置,在任务执行的时候,虚拟机之间没有了性能上的差异,则重点就在于对于任务的处理上。这里分别使用了轮转法、贪心法、特征粒子算法执行相同的任务,得出在相同配置条件下执行任务使用的时间来进行对比。
第二组:
虚拟机配置:
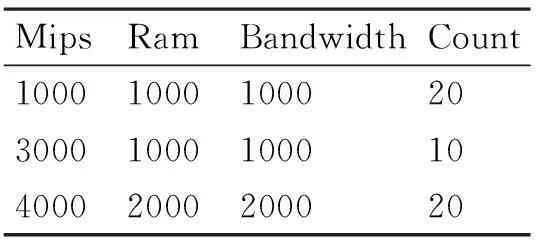
表3 不同虚拟机不同的硬件配置
任务设置:
表4 虚拟机模拟不同云任务长度配置
对于第二组来说,更接近于现实的环境,使用了三组计算能力分别不同,形成了三组特征粒子,使用的是相同的任务配置。对这样的接近现实的环境,继续使用三种不同的调度算法(轮转法、贪心法、特征粒子算法)执行,并对最终的执行时间进行对比。
第一组为多组相同配置虚拟机、多组相同任务、多次运行取平均值的模拟结果统计:
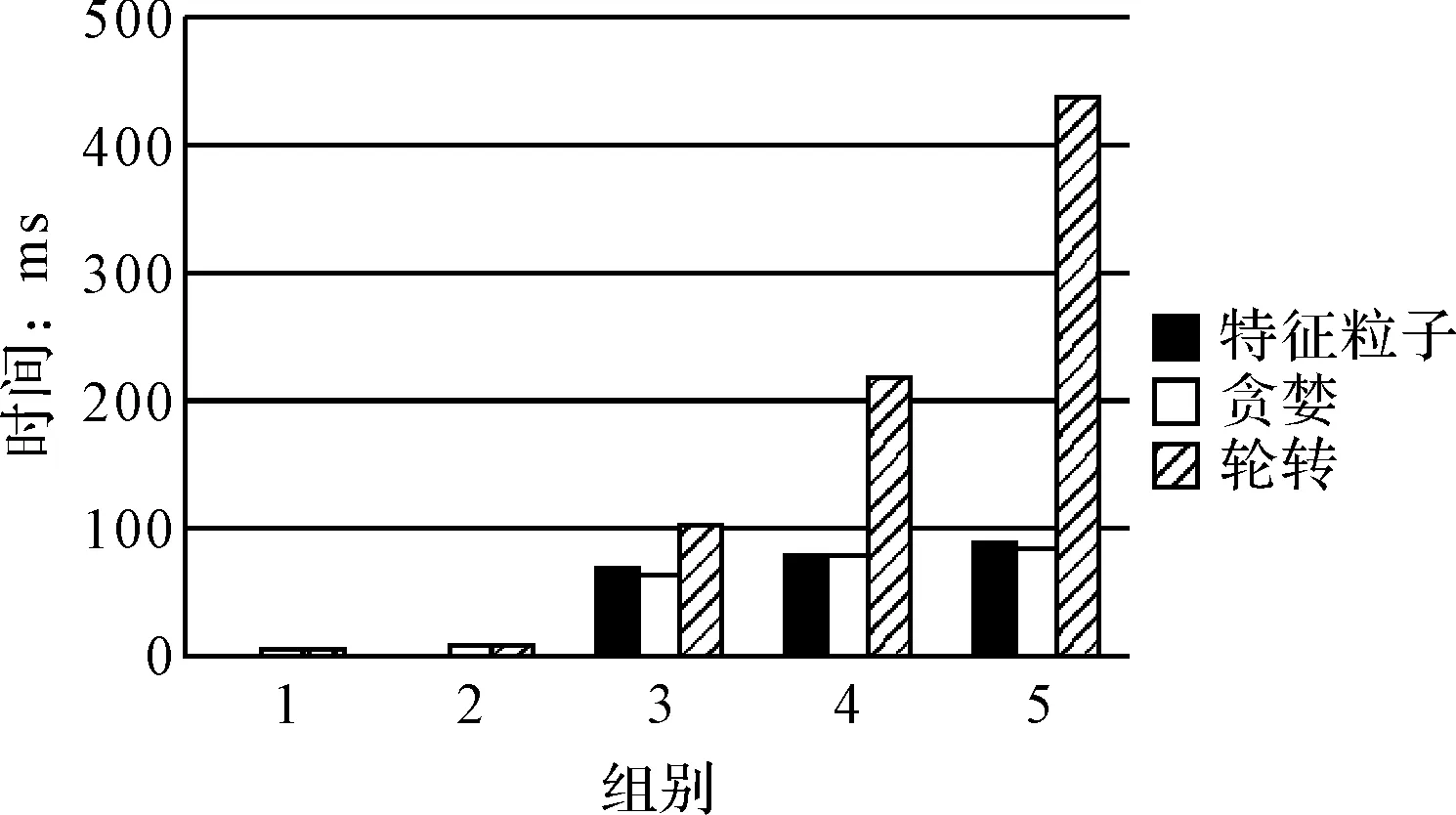
图3 同任务同虚拟机配置对比结果
第二组为多组不同的虚拟机、多组不同的任务、多次运行取平均值的模拟结果统计:
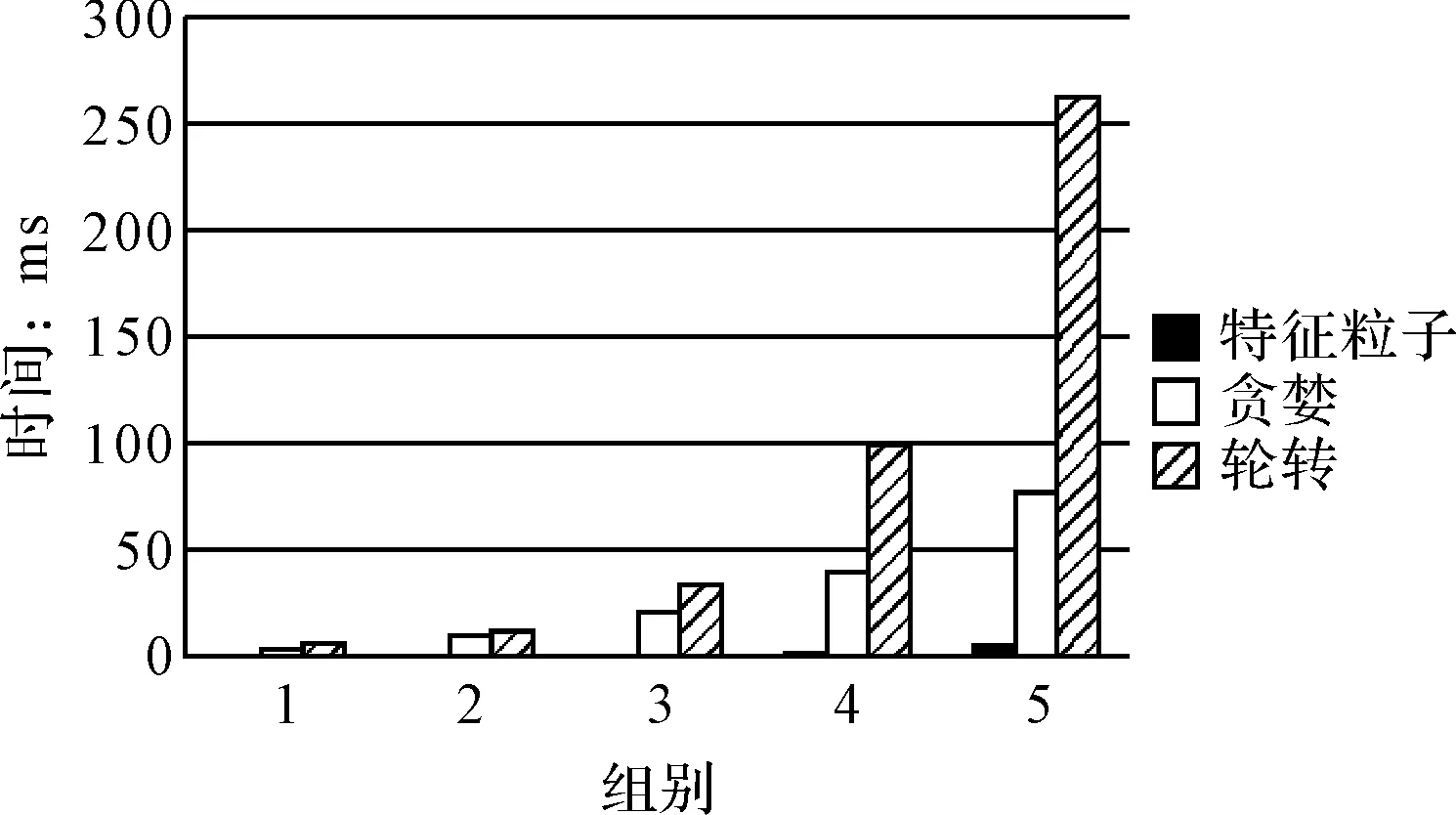
图4 不同任务不同虚拟机配置对比结果
对于稳定性和健壮性而言,轮转法整体上波动范围比较大,虽然是最基本的调度算法,但是对于这样的执行效率上的波动,还是相当大的。而对于轮转法来讲,在相同的配置的情况下,无论是执行效率,还是执行时间,都有一个相对稳定的线性增长,属于比较稳定的一种,而对于配置条件完全不同的任务和虚拟机而言,则执行情况存在一个明显的曲线,整体上无法解决配置不同的情况。
在时效上,轮转法一直没有什么优势,而对于贪婪法和特征粒子法而言,贪婪法在相同配置的条件下,寻找虚拟机的过程比较容易,相对于特征粒子来说,省去了小部分的计算时间,因此相同的配置条件下,和特征粒子没有什么区别。而对于不同配置的大环境下,贪婪法由于无状态的部分最优的局限性便展现出来,对于特征粒子法而言,它考虑了整体上的处理效率的问题,因此在整体上会寻求一个平衡点,从而解决整体上运行的时间问题。
综上,对于特征粒子调度而言,它能够有效地规避不可用节点,以及效率低下的节点,可以从全局出发,对全局的节点进行了统筹管理,对于高效的、具有特征性的处理机有机地划分为一组,另一方面,云计算节点的搜索非常具有目的性,因此对于特征粒子算法而言,恰巧应用了这一优势,有效地利用了所有的资源,并保证了处理效率。
6结语
云计算的技术特性、需求特性、发展趋势,决定
了云计算中针对数据中心的调度方式,必须具备高效、合理的资源调度管理方案,以及快速的用户作业处理两个特性。本文分析了基于特征粒子算法在资源调度在云计算中的应用与实现,该算法在节点的全局统筹方面具有很大的优势,无论是在搜索过程,还是在负载均衡方面,均具有特殊的优势。
参 考 文 献
[1] L. Smarr, C. Catlett. MetaComputing[J]. Communications of the ACM,1992,35(6):452.
[2] Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters. OSDI’04: Sixth Symposium on Operating System Design and Implementation,2004:137-150.
[3] Wickremasinghe B, et al. CloudAnalyst: A CloudSim-based Tool for Modeling and Analysis of Large Scale Cloud Computing Environments[C]//Proceddings of the 24th IEEE International Conference on Advanced Information Networking and.
[4] I. Foster. Internet Computing and the Emerging Grid[D]. Nature Web Matter, December 7,2000.
[5] Jeffrey Dean, Sanjay Ghemawant. MapReduce: Simplelied Data Processing on Large Clusters[C]//OSDI,2004.
[6] Sabata B, Chatterjee S, Davis M, et al. Taxonomy forspecifications[C]//Proceddings of the 3rd International Workshop Object-Qriented Real-Time Dependable System,1997:100-107.
[7] Rodrigo N. Calheiros, Rajiv Ranjan, Cesar A. F. De Rose, and Rajkumar Buyya, CloudSim: A Novel Framework for Modeling and Simulation of Cloud Computing Infrastruct users and Services. Technical Report, GRIDs-TR-2009-1, Grid Computing and Distributed Systems Laboratory, The University of Melbourne, Australia, March 13,2009.
[8] 李立.GridSim网格仿真工具研究[J].电脑知识与技术,2007,(7):43-44.
LI Li. Research of GridSim Grid Simulation Tool[J]. Computer Knowledge and Technology(Academic Enchange),2007,(7):43-44.
中图分类号TP393
DOI:10.3969/j.issn.1672-9722.2016.02.029
作者简介:李明,男,硕士,讲师,研究方向:计算机技术与软件。
*收稿日期:2015年8月11日,修回日期:2015年9月20日
