Bloom Filter在重复数据删除技术中应用的研究
2016-02-23陈春玲
陈春玲,陈 琳,熊 晶,余 瀚
(南京邮电大学 计算机学院 软件学院,江苏 南京 210003)
Bloom Filter在重复数据删除技术中应用的研究
陈春玲,陈 琳,熊 晶,余 瀚
(南京邮电大学 计算机学院 软件学院,江苏 南京 210003)
为了缓解存储系统中因为重复数据索引而引起的存储设备访问过于频繁的问题,深入研究重复数据删除技术,并针对目前重复数据删除技术中Bloom Filter的运用以及存在的存储设备访问性能问题进行分析和研究,提出一种基于Bloom Filter的高效去重优化模式。针对单一Bloom Filter固有的假阳性的缺陷,增加辅助Bloom Filter,从而减小误判率,达到减少存储设备访问次数的目的;针对因系统软件错误引起的Bloom Filter假阴性错误,引入单校验位的错误校验机制可以实现避免假阴性值存储的同时又能减小内存存储开销。仿真实验结果表明:改进方法能够兼顾Bloom Filter的误判率与存储设备访问开销问题。通过引入一种判断机制配合辅助Bloom Filter和单校验位机制,能够达到误判率降低、存储设备访问开销减小的高性能优化效果。
Bloom Filter;假阳性;假阴性;单位校验;访问开销
0 引 言
大数据时代的到来使得数据呈现爆炸性增长态势,信息存储的应用领域越来越广泛,指数级增长的数据无疑给企业的业务运营乃至人们的日常生活都带来了巨大的挑战[1],数据占用的存储空间变得越来越大。根据国际数据公司(International Data Corporation,IDC)的最新预测,在未来的10年内,全球的数据总量将增长为现在的50倍[2]。爆炸式增长的数据量对现有的存储系统的容量、吞吐性能、能耗管理和可扩展性等都带来了新的挑战。研究发现,所存储的数据中约有六成以上都是冗余的,并且随着时间的推移,这种冗余所造成的存储成本与管理能耗问题将变得越来越严重。为了节省存储空间资源,重复数据删除技术应运而生,并因其能够在很大程度上缓解存储利用率低的问题而应用广泛,并成为近年来存储领域的研究热点。该技术可以识别并消除大量的冗余数据,从而大大降低存储成本,提高数据索引的质量。
通过优化存储方式可以减少数据对存储设备的访问次数。Bloom Filter是一种支持重复数据快速判断的轻量级索引机制。在付出一定误判率的前提下,其所需的存储容量只和条目数相关,而与具体字符的个数无关[3]。并且它的存储空间和通过k个hash函数进行插入/查询的时间都是常数O(k),同时BloomFilter占用的空间很小,BloomFilter的比特位通常被存放在内存里,而且存储BloomFilter所需的空间又远小于其可以存储的元素个数,因此访问BloomFilter的查询速率很高,所以被广泛应用于众多领域。当查询一个数据块是否为重复数据时,在访问存储设备之前先访问BloomFilter。如果在BloomFilter内查找不到该块的索引,说明数据块不存在,是一个新的数据块,可以直接存储数据块的相关信息和元数据本身,而不需要访问存储设备进一步查找,能够大大减少对存储设备的I/O访问次数[4],从而减小访问开销。
1 相关技术
1.1 Bloom Filter
Bloom Filter,即布隆过滤器,由Burton Howard Bloom于1970年提出。它是一种空间效率极高的随机数据结构,可以用于检索一个元素是否在一个集合中,因此通常被应用于基于磁盘的备份系统中,旨在减少存储系统中使用的存储容量和磁盘访问量。不管这个元素大小如何,Bloom Filter都只以一种类似“签名”的方式使用几个比特位来表示并存储在数组中。它包括一个m位的数组B,并将每位初始化为0,数组存储一个来自通用集的集合S中的元素信息。BloomFilter可以分为插入与索引:
插入:将集合S里的n个元素x1,x2,…,xn插入到BloomFilter过滤器,通过k个不同且相互独立的hash函数hi(x),1≤i≤k,hi(x)取值范围为数组B的下标[0,m-1],随机映射到m位数组B中对应的k个比特位上,并将数组B上对应的B[h1(x)],…,B[hk(x)]置为1。图1展示了将元素插入到k为3、数组大小为m的BloomFilter的过程[5]。
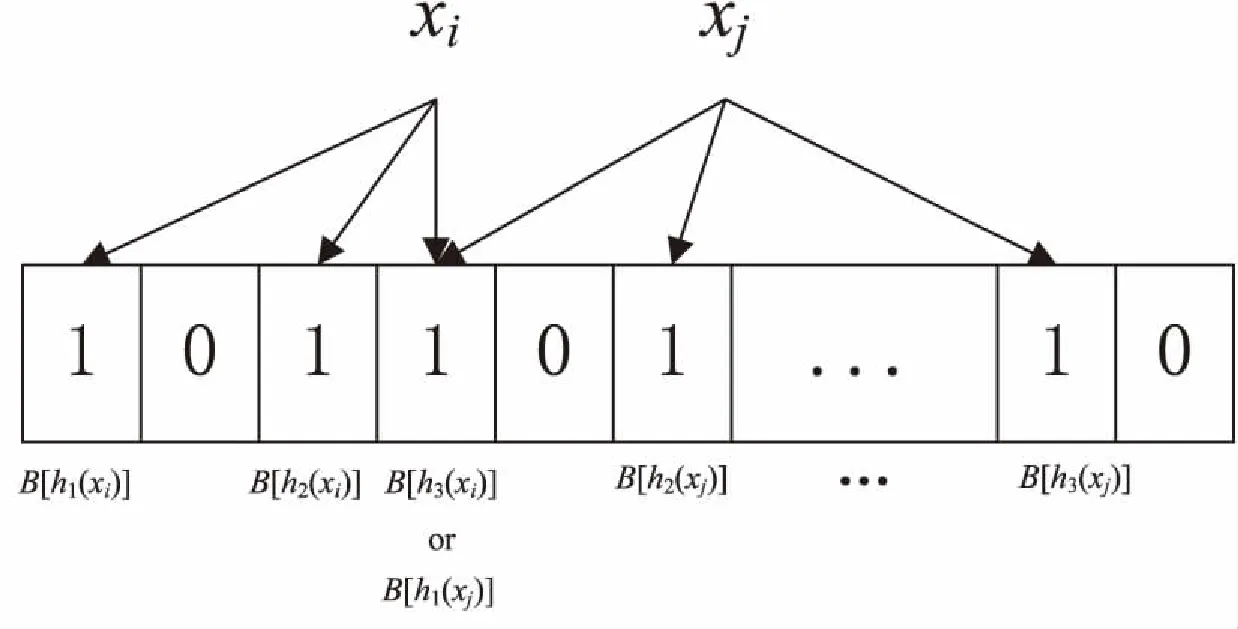
图1 元素插入示意图
其中数组下标为3的比特位上,元素xi和xj都映射到了该位置。
检索:当检索一个元素x是否属于集合S时,通过k个hash函数映射到BloomFilter对应的数组里的k个比特位上,看该k个位置是否全为1。如果全为1,就以一定的误判率认为该元素x属于集合S;若发现k个位置上有一位为0,就可以肯定元素x一定不属于集合S。索引的示例图如图2所示。
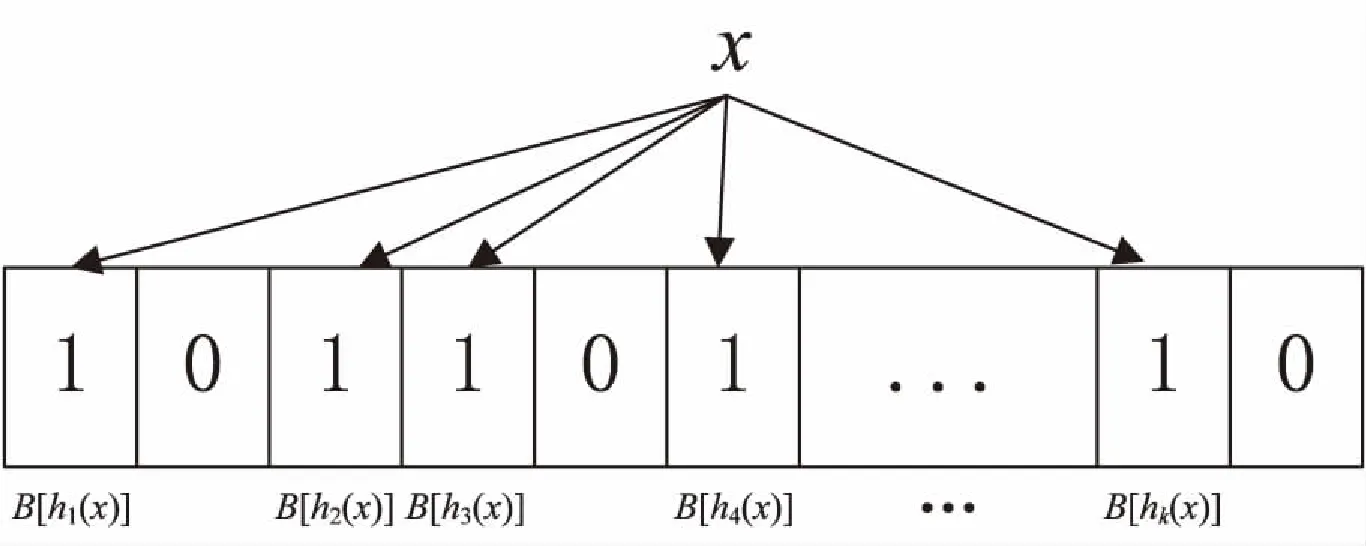
图2 元素索引示意图
一个BloomFilter不会存在假阴性的情况,即如果显示一个元素不在数组里,那么在数组里就真没有该元素;但是BloomFilter存在假阳性,即使待索引的元素不在集合里,经过k个hash函数映射进BloomFilter里也有可能产生阳性结果,即认为该元素已在集合内[6],而这个元素所映射到的比特位之所以为1是由于别的元素经过hash函数后映射到了该位,如图1中就存在了这样的问题。所以BloomFilter即使判断出一个元素在数组里也不一定就真的在数组里,也就是说BloomFilter存在误判率,可以表示为:
(1)
其中,n为集合中元素的个数。

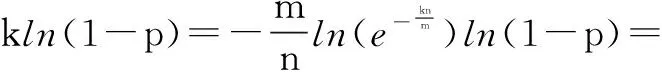
(2)
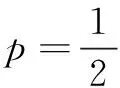
(3)
内存极易受到软件错误的攻击,给Bloom Filter的计算带来不必要的麻烦。但是,在Bloom Filter中假阳性是固有的,因此,软件错误导致假阳性的概率不会显著增加,因此给过滤器带来的影响也几乎可以忽略不计。但是由于软件错误造成的假阴性值的问题将给Bloom Filter的判重性能带来质的影响,尤其是当Bloom Filter运用在安全领域时,假阴性值将带来致命的错误。因此必须针对一些可能造成Bloom Filter假阳性或者假阴性的系统软件错误引入系统纠错码来识别并纠正错误[8]。ECC中比较具有代表性的是单一纠错码(Single Error Correction code,SEC)。它将Bloom Filter里m比特的数组映射为内存字进行存储,并对每个字都设置校验位进行校验。
SEC能够成功识别出被系统错误修改的字,并加以改正,但是用于纠错在内存中引入了大量的校验位,无疑会给内存带来更多存储空间的需求,造成了存储开销的增加。不仅如此,由于内存空间是有限的,即使是SEC,也因为引入了额外的内存存储空间,使得BloomFilter的比特位数量不得不减少来让出更多的比特校验空间,这样反过来也增加了误判率,而且对读写所必须的编码和译码的使用也会影响ECCs的访问次数,一定程度上以增加能耗来换取对系统软件错误的检测效果[9]。
文献[10]中提到可以运用多个BloomFilter指纹摘要阵列来存储相邻存储节点里的信息,通过先列后行的方式检索,使得每个节点不仅可以快速判断出新数据块,还能够进行全局范围的重复数据删除,并且消除各节点之间的冗余数据,确保不会因为误判率而错误删除新数据。但是它必须在每个节点里都存储这样的指纹阵列,这样会增加存储开销,在一定程度上降低了系统的性能。
文献[11]针对在大数据环境下查询存储系统里的一个源文件花费时间长的问题,在存储系统中应用一种加强版的布隆过滤器来加速在大型存储系统中索引文件的过程,其产生的假阳性率与假阴性率也能控制在一个很小的范围,证明了BloomFilter在存储系统中的运用是高效可行的,但是对于因BloomFilter表没有及时更新所带来的假阴性值的处理与预防方式还没有进行深入研究。
基于上述情况,文中引入辅助BloomFilter,通过两次BloomFilter判断,不仅可以减小内存开销,同时能够实现较低的误判率,进而减少对存储设备的访问频率;引入单校验位以期达到SEC的校验效果,又能够减少对内存空间的需求,同时可以防止因为系统软件错误导致的假阴性情况的发生。
2 针对Bloom Filter判重关键技术的研究与改进
文中提出的优化模式通过引入一个辅助Bloom Filter,来识别原Bloom Filter识别为阳性的结果,如果经过辅助Bloom Filter仍识别为阳性结果,就需要访问存储设备里的hash索引表,判断其是否为重复数据[12]。而针对原Bloom Filter识别为阴性的结果不是直接将其判定为新数据块进行存储,而是使用单校验位的校验机制进行字的校验。如果校验结果为没有被软件错误修改过,那么就认为是新数据块可以进行存储;如果发现被软件错误修改为阴性结果,就要改正并访问存数设备的索引表查看是否为重复数据。具体实现过程如图3所示。

图3 改进Bloom Filter的判重过程图
针对情况一,在查询一个输入x是否为集合内的元素时,如果经过k个hash函数计算后B(hi(x))为1,x就被认为是集合S经过BloomFilter后的一个阳性结果。记集合A(S)为集合S里元素经过BloomFilter中k个hash函数后B(hi(x))为1的所有元素,即A(S)是S集合中BloomFilter为阳性的集合。如果有元素x∈S,那么经过k个hash函数后的B(hi(x))就为1且x∈A(S)。因此可以推出集合S属于A(S)。但也存在一些元素不属于集合S却因为别的元素映射到了该位,使得该元素的B(hi(x))也为1,称这样的元素为x∈A(S)-S,即A(S)-S为假阳性。有关系如下:
A(S)=S∪(A(S)-S)
(4)
S∩(A(S)-S)=∅
(5)
式(1)中的误判率f是假设x∉S的情况下成立的,故称这种有条件的集合为S',此时f可以表示为:
(6)
其中,S'为集合S的补集,此时P(A(S))可以表示为:
(7)
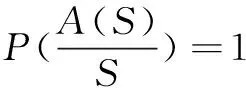
P(A(S))=P(S)+P(S')f
(8)
由式(4)、(5)、(8)可以推出:
P(A(S)-S)=P(S')f
(9)
其中,式(4)、(5)可以推出P(A(S)-S)=P(A(S))-P(S)。
可以使用A(S)和(A(S))'两部分来表示通用集,而A(S)又可以由S和A(S)-S表示;同理,通用集也可以由A(S')和(A(S'))'两部分表示,而A(S')同样可以由S'和A(S')-S'表示。因此可以推断出通用集由A(S)-S,(A(S))',A(S')-S'和(A(S'))'四部分组成,而(A(S'))'属于S,并且(A(S))'属于S',因此可以推测出通用集由(A(S'))',A(S)∩A(S'),(A(S))'三部分组成,进而推出A(S)∩A(S')可以由A(S)-S和A(S')-S'表示:
A(S)∩A(S')=(A(S)-S)∪(A(S')-S')
(10)
(A(S)-S)∩(A(S')-S')=∅
(11)
其中,A(S)∩A(S')表示两个BloomFilter均产生阳性结果,也就意味着其中一个过滤器产生了假阳性值,这时就需要访问hash表判别是否存在该重复数据块在存储系统中[13]。此时引入辅助的BloomFilter,令n'表示集合S'里元素的个数,可以推出对辅助BloomFilter的误判率为:
(12)
故两个BloomFilter都呈现假阳性的概率可以表示为:
P(A(S)∩A(S'))=P(A(S)-S)+P(A(S')-S')=P(S')f+P(S)f'
(13)
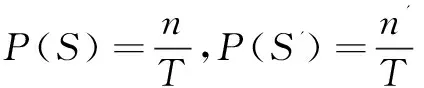
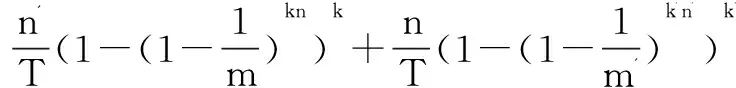
(14)
单个BloomFilter的情况下可以通过控制m的大小使误判率降到很小,那么两个BloomFilter同样可以通过控制m的大小,使得误判率达到一个更小的值。
针对情况二,如果原BloomFilter产生了阴性的值,那么不能直接判定该元素就是新数据块,因为可能存在软件错误引起的假阴性值的情况。文中通过将BloomFilter里m比特的数组映射为内存字存储,假定每个字大小为L比特,那么数组一般可以表示成m/L个字,图4展示了单比特位校验机制。
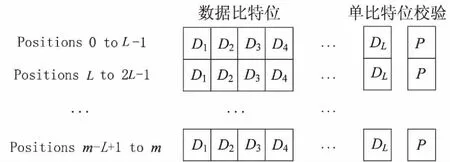
图4 单比特位校验机制
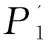
经过比特校验位之后的数据块,如果没有发现被软件错误修改,那么直接可以判断出该数据块为新数据块,如果发现内存中字的校验位被改变时,则使用文中提出的方法进行纠错。一旦发现出现了假阴性值,定位出出错比特位后再去访问存储设备内对应的索引表,如果找到该索引,则证明该数据块是重复数据,可以删除;如果没有找到对应的索引,则证明该数据块是新数据块,可以直接存入存储设备。
3 实 验
改进的BloomFilter在时间复杂度上相比标准BloomFilter仍能保持常数级别的时间复杂法,不增加任何负担。
3.1 实验软硬件配置及参数选取
仿真环境采用戴尔PowerEdge T410电脑,处理器为Intel Xeon E5506 16G,系统为64位Windows7,算法采用Java语言实现。
在性能测试中,针对标准Bloom Filter需要访问存储设备里的hash表的概率与文中改进方法对存储设备访问率进行比对。选取一个尺寸因子α来表示原BloomFilter和辅助BloomFilter的大小,m=αn,m'=αn'。根据式(3),分别选取α为2,22,23,24,相应的k取1,3,6,11来表示。针对引入的单校验位错误校验机制,对其所有字对应的位设为1所带来的假阳性率进行实验,看其是否增加了额外的假阳性率。
3.2 实验结果及分析
在标准Bloom Filter里,即使在对一个Bloom Filter里m值设置很大且误判率很低的情况下,产生每个阳性结果都会导致一次存储设备的访问。而文中提出的优化方法可以有效限制由于BloomFilter产生假阳性结果所引起的存储设备访问问题。
图5为单一标准BloomFilter与文中提出的改进BloomFilter,随着α因子大小的增加而产生的存储设备访问变化的比较。
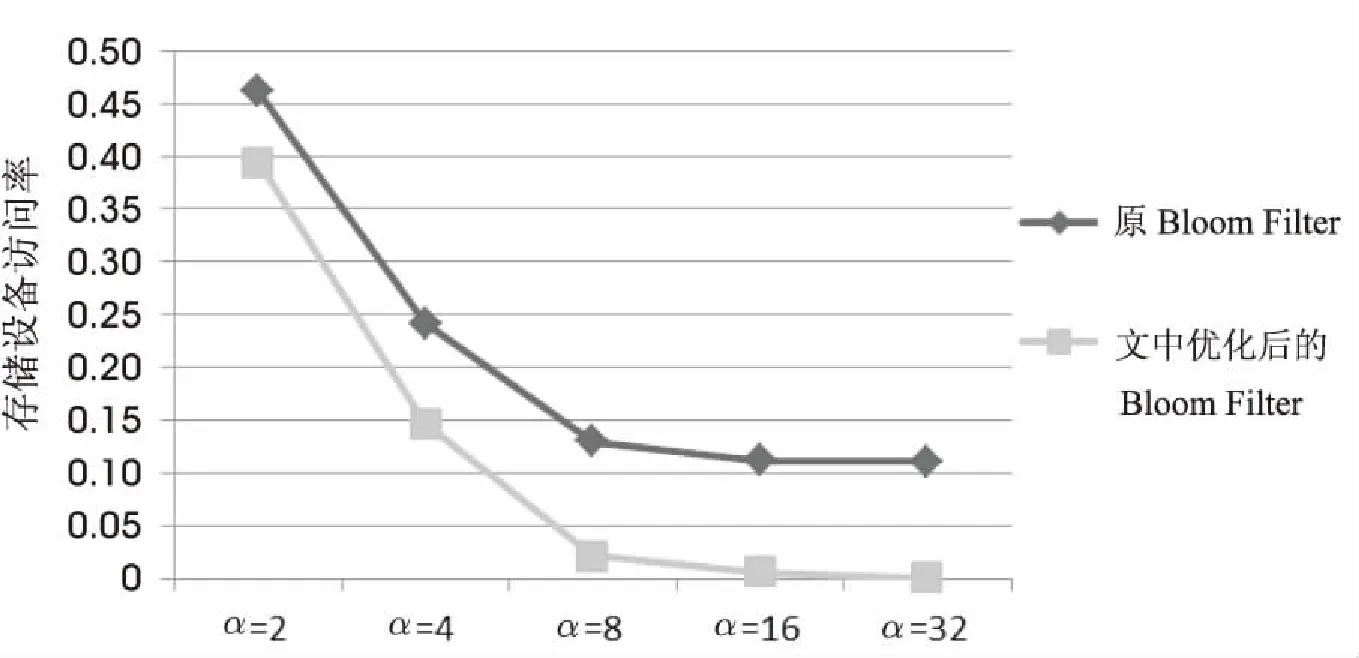
图5 存储设备访问率对照表
从图中可以发现,文中提出的优化BloomFilter方法使得访问存储设备里hash表的访问量大大降低,并且随着α因子的增大而性能更优,当α为32时达到最佳情况,从而大大减小了存储设备的访问开销。
图6为引入单校验位机制中为了避免假阴性值的产生,而将存储字里的所有位都设为1可能带来的假阳性率的变化情况。
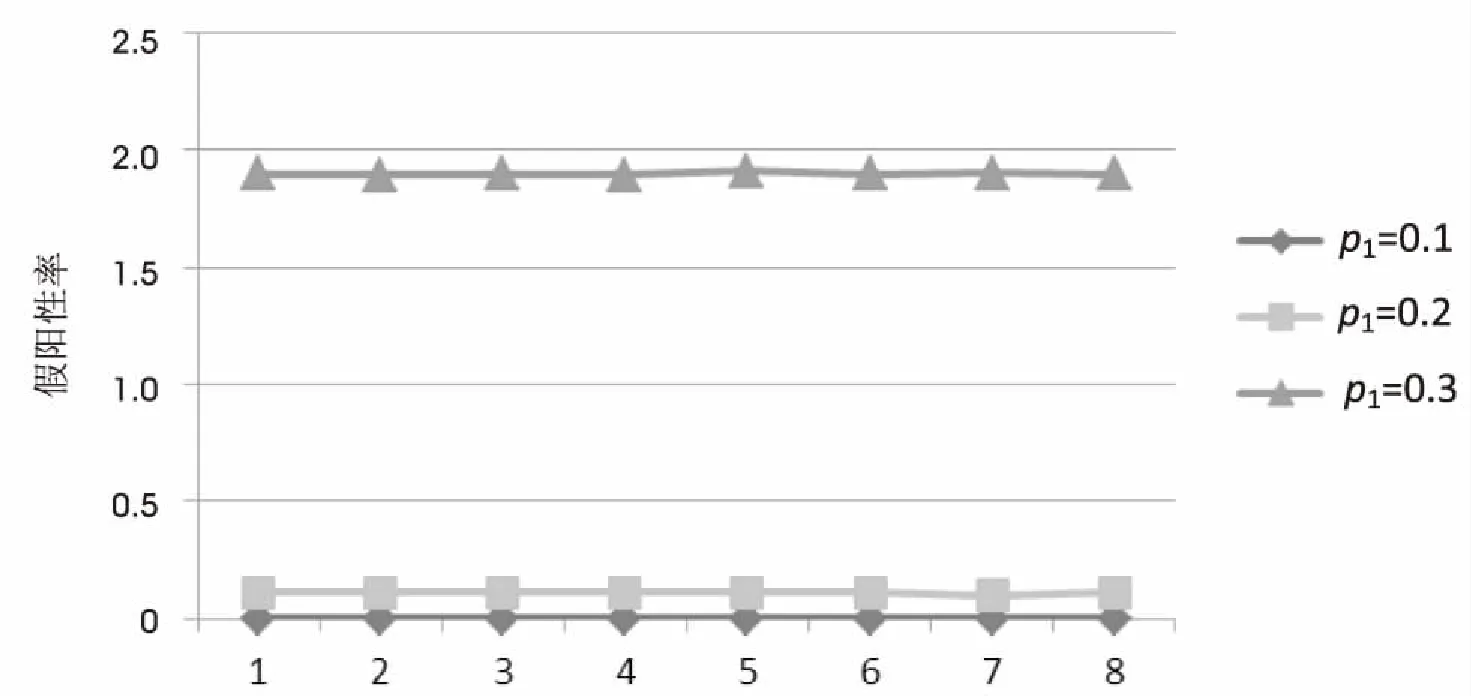
图6 假阳性率变化表
从图中可以看到,产生的假阳性概率的变化频率很小,在同一标准下的波动几乎可以忽略不计。
实验结果表明,文中改进的BloomFilter算法,引入的辅助BloomFilter能够有效降低假阳性率,减少对存储设备的访问量,大大减小了访问存储设备的开销,优化了性能;引入的单校验位错误校验机制,没有像SEC校验那样需要消耗大量的内存空间,仅使用一位校验位,降低了对内存存储空间的需求,同时将所有校验字位设为1所带来的额外假阳性率在大部分的应用场景中几乎可以忽略不计,因此大大提高了存储设备的空间利用率,在降低存储访问和存储成本的同时,又能保证BloomFilter的高效性。
4 结束语
结合目前针对存储设备访问开销的问题进行研究,引入辅助BloomFilter减少由假阳性值带来的多次访问存储设备的问题,在减小访问开销的同时,运用数学方法证明了引入辅助BloomFilter的可行性。引入单校验位校验机制避免因假阴性值所带来的不必要的存储系统访问和存储空间的浪费,进而使得BloomFilter判重的性能得到优化,在容错率允许的情况下识别出由系统软件错误带来的假阴性问题,同时又使得改进方法所带来的假阳性率小到忽略不计。通过一种判断机制,对BloomFilter产生值进行区分处理,改进的BloomFilter方法可以在保证准确率更高、性能更优的情况下,使判重效率更高,空间更加节约,访问存储设备开销更小。未来可以在进一步探索如何实现高效重复数据删除的同时兼顾重复数据删除技术的可靠性、实时性以及索引等问题。
[1] 谢 平.存储系统重复数据删除技术研究综述[J].计算机科学,2014,41(1):22-30.
[2] Labrinidis A,Jagadish H V.Challenges and opportunities with big data[J].Proceedings of the VLDB Endowment,2012,5(12):2032-2033.
[3] 黄慧群,何 敏,兰巨龙.基于布鲁姆过滤器的未决兴趣表查找方法研究[J].信息工程大学学报,2015,16(1):84-89.
[4] 张星煜,张 建,辛明军.相似性-局部性方法相关参数分析[J].计算机技术与发展,2014,24(11):47-50.
[5] Gong Q,Yang T,Tong H,et al.Reducing the number of Bloom filters[C]//Proc of international conference on progress in informatics and computing.[s.l.]:IEEE,2014.
[6] Guo D,Wu J,Chen H,et al.The dynamic Bloom filters[J].IEEE Transactions on Knowledge & Data Engineering,2010,22(1):120-133.
[7] Tang S,Jin A,Wang Y.A comment on “fast bloom filters and their generalization”[J].Molecular Medicine,2016,13(3-4):303-304.
[8] Saravanan K, Senthilkumar A, Chacko P.Modified whirlpool hash based bloom filter for networking and security applications[C]//Proc of 2nd international conference on devices,circuits and systems.[s.l.]:IEEE,2014.
[9] Xia W,Jiang H,Feng D,et al.Similarity and locality based indexing for high performance data deduplication[J].IEEE Transactions on Computers,2015,64(4):1162-1176.
[10] 王国华.高效重复数据删除技术研究[D].广州:华南理工大学,2014.
[11] Kim M,Oh K H,Youn H Y,et al.Enhanced dual Bloom filter based on SSD for efficient directory parsing in cloud storage system[C]//Proc of international conference on computing,networking and communications.[s.l.]:IEEE,2015:413-417.
[12] Rottenstreich O,Keslassy I.The Bloom paradox:when not to use a Bloom filter[J].IEEE/ACM Transactions on Networking,2015,23(3):703-716.
[13] Antikainen M,Aura T,Särelä M.Denial-of-service attacks in bloom-filter-based forwarding[J].IEEE/ACM Transactions on Networking,2014,22(5):1463-1476.
Research on Application of Bloom Filter in Data Deduplication
CHEN Chun-ling,CHEN Lin,XIONG Jing,YU Han
(School of Computer Science & Technology,School of Software,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
In order to alleviate the problem of the frequent access to storage device which caused by the indexes using in data deduplication,data deduplication is deeply studied,making analysis and research on the application of Bloom Filter at the present situation of data deduplication and existing problems of the access of storage system performance and proposing a high-efficiency and optimal model based on Bloom Filter.Aiming at the situation that the probability of false positives is in the nature of Bloom Filters,an additional Bloom Filter is used to reduce false positive rate,achieving the purpose of reducing times of the access for storage system.In view of the situation that the system software errors may bring Bloom Filter false negative,single bit error checking mechanism is introduced to prevent it from happening,at the same time,it can reduce memory overhead.The simulation shows that the proposed method can balance the false positive rate and the access of storage system costs.By introducing a judgment mechanism with complement Bloom Filter and single bit error checking mechanism,it can achieve the effects of the reducing of false positive rate and the access of storage system costs.
Bloom Filter;false positive;false negative;single bit error checking;access costs
2015-11-26
2016-03-04
时间:2016-08-01
国家自然科学基金资助项目(11501302)
陈春玲(1961-),男,教授,研究方向为软件技术及其在通信中的应用、网络信息安全等;陈 琳(1990-),女,硕士研究生,研究方向为软件技术及其在通信中的应用和大数据。
http://www.cnki.net/kcms/detail/61.1450.TP.20160801.0904.030.html
TP39
A
1673-629X(2016)08-0182-05
10.3969/j.issn.1673-629X.2016.08.039
