基于Hadoop的交互式大数据分析查询处理方法
2016-02-23李聪颖王瑞刚梁小江
李聪颖,王瑞刚,梁小江
(1.西安邮电大学,陕西 西安 710061;2.陕西省信息化工程研究院,陕西 西安 710061)
基于Hadoop的交互式大数据分析查询处理方法
李聪颖1,王瑞刚1,梁小江2
(1.西安邮电大学,陕西 西安 710061;2.陕西省信息化工程研究院,陕西 西安 710061)
基于Hadoop的交互式大数据分析查询处理方法旨在快速分析查询大数据集的信息,最重要的特征就是查询速度快。该方法能够运行在上千节点的集群上,适于半结构化/嵌套数据的分析、兼容现有的SQL环境和Apache Hive。文中主要利用此方法实现连接HDFS、Hive以及Hbase进行查询测试,还完成了同时从不同数据源上关联查询数据。在同一Hadoop集群环境中,将该方法与Spark SQL对于10万、20万、50万、100万、500万条数据进行查询速度对比测试。经过多次实验后得出,基于Hadoop的交互式大数据分析查询处理方法速度快、效率高,能够帮助企业用户快速、高效地进行Hadoop数据查询和企业级大数据分析。
Hadoop集群;大数据处理;交互式查询;快速;SQL
0 引 言
随着计算机信息技术的发展和普及,互联网规模迅速扩大,各行业应用互联网所产生的数据呈爆炸性增长态势。近年来,生活中很多方面都依赖实时应用,例如通过社交媒体更新动态、在线购物、等待客户在线回应等,客户希望快速得到有效信息。因此,对大数据进行分析及查询,提高查询的性能和效率极其重要。
在服务器硬件及数据库配置等条件固定的情况下,传统查询方式随着数据量不断增大,其查询效率不断降低,查询的响应时间越来越慢,甚至会出现由于查询导致数据库无法使用的情况[1]。传统大数据分析查询速度慢且查询方式为非交互式。因此,需要一种能够对不同的数据源分析处理大数据并且交互式快速查询数据的方法。
1 整体框架设计
1.1 简 介
随着大数据时代的到来,查询速度成为Hadoop的
瓶颈,因为越来越多的用户需要一种快速而且互动的数据分析查询处理方法。
基于Hadoop的交互式大数据分析查询处理方法的目的在于:设计和实现一种大数据集的交互式分析查询系统。当用户使用SQL语句查询数据时,用户的查询请求首先被提交给SQL查询解析器,查询解析器将查询请求解析为逻辑计划,再由查询优化器读取逻辑计划并将其转化为物理计划,最后由执行引擎来执行物理计划,存储引擎将元数据信息提供给元数据库,并将查询的原生功能告知执行引擎。
基于Hadoop的交互式大数据分析查询处理方法是一种分布式SQL引擎,不需要定义和维护数据模式或数据转换,能够自动解析数据结构[2];不仅支持结构化和半结构化的数据查询,还支持复杂的嵌套式数据查询,并且使用全新标准的ANSI SQL:2003查询能力;可以连接多种后端数据源,如Hive,Hbase,HDFS,MongoDB,Cassandra,等等。尽管大数据交互式分析查询系统运行在Hadoop集群中,但它不局限于Hadoop集群,也可以运行在任何分布式集群中,能够适应上千节点的PB级数据的交互式商业智能分析场景[3]。
1.2 核心架构设计
如图1所示,基于Hadoop的交互式大数据分析查询处理方法的核心架构包括:远程访问模块、SQL解析器、查询优化器、任务计划执行引擎、存储插件接口、分布式缓存模块等。

图1 核心架构图
(1)远程访问模块。该模块是一个低开销的远程过程调用通信协议。此外,C++和Java API层也用于客户端应用程序与系统进行交互,在提交查询请求之前,客户端既可以直接与特定节点进行通信,也能通过zookeeper发现集群节点,从而更方便地管理维护复杂的集群。
(2)SQL解析器。基于标准SQL语句解析传入的查询请求,通过元数据应用程序接口请求模式信息,然后产生标准逻辑计划以供优化器进行优化,其语法树提供用户操作接口,灵活性高且该解析器的组件与语言无关。
(3)查询优化器。优化器将逻辑计划转化为物理计划,包含有子查询的SELECT语句是作为半连接执行的,所以子查询中每条记录返回最少的实例,优化器可以对表的扫描最小化并且有利于匹配内外表的SELECT记录。
(4)任务计划执行引擎。为了实现高性能的查询处理,引入一种分布式可扩展的执行引擎。该引擎提供数据本地化、容错以及基于行列的等级处理。
(5)存储插件接口。存储插件可以与数据源进行交互,数据的位置和优化规则有助于提升查询效率。
(6)分布式缓存模块。采用分布式缓存,提高查询性能,通过动态地增减集群节点来调节数据访问负载,从而提高资源利用率。
1.3 数据查询流程
基于Hadoop的交互式大数据分析查询处理方法的执行流是用户或机器产生的查询请求提交给查询解析器的过程,如图2所示[4]。
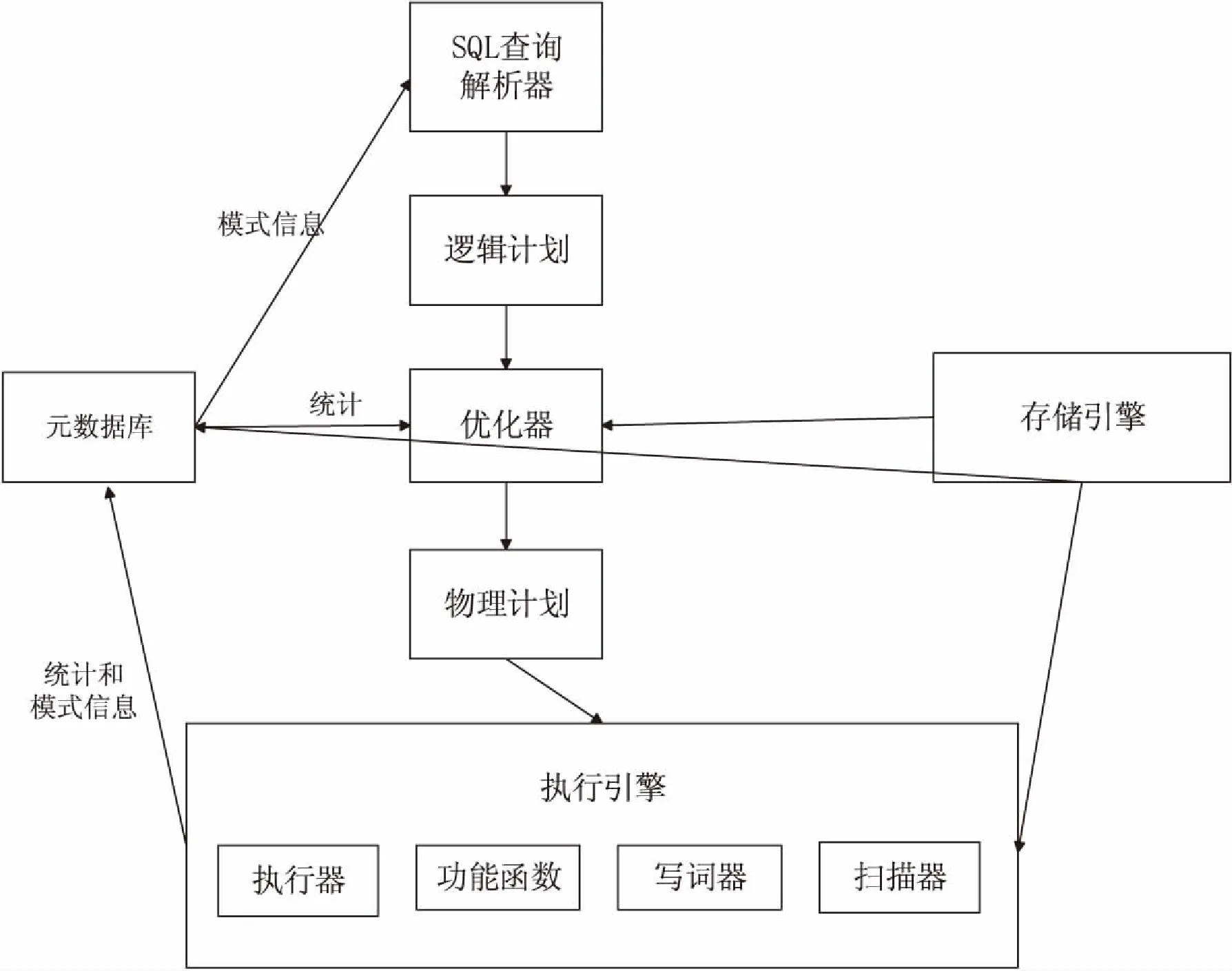
图2 执行流图
首先,SQL解析器对查询请求进行解析,包括词法分析和语义分析。在查询解析器中的查询请求会被解析为逻辑计划,而逻辑计划描述了查询操作的基本数据流。
其次,优化器读取逻辑计划并把逻辑计划转换为物理计划[5]。存储引擎和特定的数据源进行交互,提供读写功能,将元数据信息提供给元数据库,将原生功能告知执行引擎。
最后,由执行引擎执行物理计划,执行引擎依赖组件(执行器、功能函数、扫描器、写词器等),执行器负责转换数据流,功能函数将数据流转换为单独的数据,扫描器和写词器负责读写数据。元数据库查询执行框架并提供元数据信息,即时编译器将部分物理计划转换成本地代码。
如图3所示,基于Hadoop的交互式大数据分析查询处理方法主要支持文本、序列化、列存储等存储格式。其中,Hbase表、JSON、BSON都属于无模式的数据模型[3,6],CSV、TSV和Hbase表是扁平结构的数据,Parquet、JSON、BSON的数据结构是嵌套型的复杂数据,而Avro是一种序列化的复杂数据。

图3 数据结构图
当用户提交一个查询请求时,客户端或应用程序会把查询的SQL语句发送给集群中的节点。系统的进程在集群的节点上执行协调、规划、最大化查询。客户端和应用程序查询后端节点,然后驱动查询的组件。查询解析器解析SQL语句,将自定义规则应用到特定的SQL操作符,转换成特定的逻辑操作语法,集合逻辑运算符形成逻辑计划,逻辑计划描述了作业所需要生成的查询结果,定义数据源和应用操作[7]。
2 实现与测试
2.1 方法实现
2.1.1 底层环境
操作系统:ubuntu12.04;
Java环境:jdk1.7.0_67;
分布式Hadoop集群环境:主节点IP:10.10.10.39,从节点IP: 10.10.10.34,10.10.10.35,10.10.10.36,10.10.10.37,10.10.10.38。
2.1.2 存储插件配置
在每个节点上启动交互式大数据查询系统后,通过命令sqlline -h可以查看sqlline的参数,-u为链接地址,zk=localhost为zookeeper服务,需要在配置文件中配置zookeeper的IP,本地不用另外配置zookeeper服务,然后通过jdbc驱动连接到sqlline工具进行数据查询[8]。
查询系统服务启动后,在浏览器中通过服务节点IP和端口号即可访问Web页面,点开storage选项查看当前支持的数据源存储插件,默认只有cp和dfs可用。在Disabled Storage Plugins中点击不可用插件的Enable功能,就能使用该存储插件。若插件列表中没有所需的插件,则添加所需的插件并使其Enable可用,然后再进行配置。下面是一个典型的HDFS存储插件的关键配置信息:
{
"type":"file",
"enabled":true,
"connection":
"hdfs://hadoop34.newqd.com:8020/",
"workspaces":{
"root":{
"location":"/root",
"writable":true,
"defaultInputFormat":null
}
},
"formats":{
"csv":{
"type":"text",
"extensions":[
"csv"
],
"delimiter":","
}
}
其中,type为存储插件的类型,可以为File、Hive、Hbase或者Mongo;enable为存储插件是否可用的状态;connection为连接数据源的地址;location为工作空间的路径;writable为是否允许在工作空间中创建一个表或者视图;defaultInputFormat为输入格式的扩展名是否对输入数据有影响;csv为数据格式的名称;text为数据格式的类型;extention为可读数据格式的扩展名类型;delimiter为数据的分隔符[9]。
2.1.3 连接zookeeper集群
基于Hadoop的交互式大数据分析查询处理方法提供了一些访问数据源数据的方法,例如JDBC Driver,ODBC Driver。文中是基于JDBC Driver连接zookeeper服务。
连接本地zk
bin/sqlline -u jdbc:zk=local
连接zk集群
手动指定zk:
bin/sqlline -u jdbc:drill:zk=10.10.10.34,10.10.10.35,10.10.10.36:2181
如果是集群模式,也可以不跟上zk地址,如bin/sqlline -u jdbc:zk就可以自动读取override.conf文件中的zk配置信息。
当指定的zk是一个全新的zk,例如之前使用的是本地zk,那么在本次新的会话中Storage-Plugin的信息就都会丢失。因为指定的zookeeper集群是全新的,所以基于Hadoop的交互式大数据分析查询处理系统还没有往里面写入任何数据[10]。这是因为在WEB UI上对Storage Plugin进行update或者create的数据都会写入到对应的zookeeper节点上。因此需要在界面上update某一个数据源插件时并且enable后,通过show databases才可以看到数据源里的表。
2.2 方法测试
2.2.1 关联查询Hive,Hbase和HDFS
由于Hbase表中的数据要转码为UTF8才可以查询,所以在联合查询的过程中先把Hbase表转化为视图,保存在本地文件系统下,然后再关联视图查询。
如图4所示,关联查询的数据中,第一列数据studentid来自hive.student表,第二列数据name来自Hbase视图,第三列数据state来自HDFS中的sample.json文件。
selects.studentid,p.name,`state`from hive.student s,dfs.root.prodview p,hdfs.`/opt/test/sample.json` m where s.id=p.id and s.id=m.id;
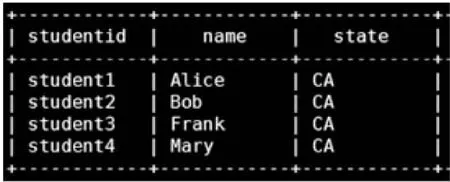
图4 关联查询Hive,Hbase和HDFS
2.2.2 与Spark SQL的对比测试
Spark SQL的前身是Shark,但是随着Spark的发展,Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等)制约了Spark各个组件的相互集成,所以提出了Spark SQL项目。Spark SQL抛弃原有Shark的代码,汲取了Shark的一些优点,如列存储、兼容Hive等,重新开发了Spark SQL代码。由于摆脱了Hive的依赖性,Spark SQL在数据兼容、性能优化、组件扩展方面都得到了极大的提升[11]。例如在数据兼容方面,不但兼容Hive,还可以从RDD、parquet文件、JSON文件中获取数据,未来版本甚至支持获取RDBMS数据以及cassandra等NOSQL数据;在性能优化方面除了采取In-Memory Columnar Storage、byte-code generation等优化技术外,将会引进Cost Model对查询进行动态评估,获取最佳物理计划,等等;在组件扩展方面,无论是SQL的语法解析器、分析器还是优化器都可以重新定义并进行扩展,因此Spark SQL的性能得到了极大提升[12]。
基于Hadoop的交互式大数据分析查询处理方法,在查询速度方面与Spark SQL对于10万、20万、50万、100万、500万条数据的查询测试对比结果分别见表1和表2。
表1为使用count()方法查询不同数据量的测试对表结果,表2为使用where语句从不同数据量中查询其中一条数据的测试对比结果。
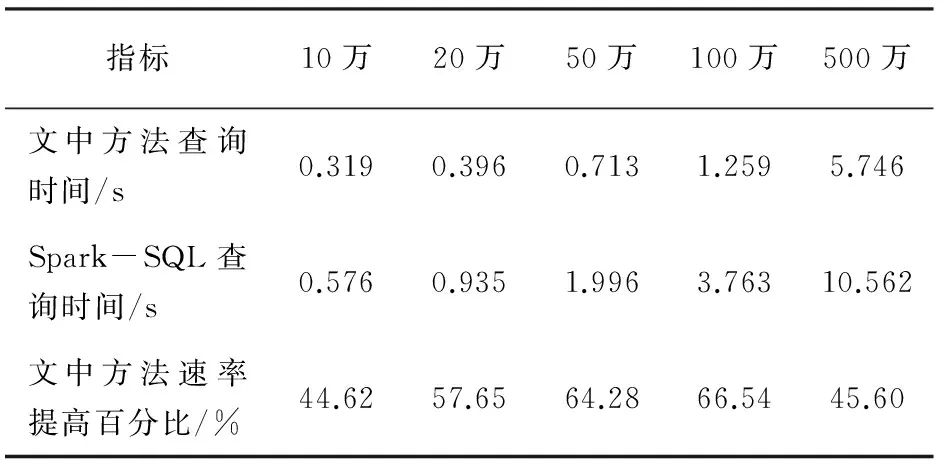
表1 统计数据数量测试对比结果
由表1可以看出,在同一Hadoop集群平台上,经过多次实验取平均值后,在查询10万、20万、50万、100万、500万条数据时,文中方法比Spark SQL的查询速度依次提高44.62%、57.65%、64.28%、66.54%、45.60%。

表2 提取一条数据测试对比结果
由表2可以看出,在同一Hadoop集群平台上,经过多次实验取平均值后,从10万、20万、50万、100万、500万条数据中依次查找一条数据时,文中方法比Spark SQL的查询速度依次提高了22.81%、21.62%、30.38%、32.73%、9.24%。
3 结束语
基于Hadoop的交互式大数据分析查询处理方法能够运行在上千节点的集群上,适于半结构化/嵌套数据的分析、兼容现有的SQL环境和Apache Hive,没有集中的元数据定义,可以在单次查询中从多种数据源中合并数据进行查询,是一种高吞吐量和低潜在因素的大数据处理方法[13]。
在同一Hadoop集群环境中,经过多次实验得出,在依次查询10万、20万、50万、100万、500万条数据时,文中方法比Spark SQL的查询速度平均高55.74%;在依次从10万、20万、50万、100万、500万条数据中查询一条数据时,文中方法比Spark-SQL的查询速度平均高23.36%。因此,该方法分析效率高,交互式查询速度快,满足了企业级大数据分析场景的应用。
[1] Manyika J,Chui M,Brown B,et al.Big data:the next frontier for innovation,competition,and productivity[EB/OL].2011.http://www.Mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation.
[2] Li G.Research status and scientific thinking of big data[J].Bulletin of Chinese Academy of Sciences,2012,27(6):647-657.
[3] 王元卓,靳小龙,程学旗.网络大数据:现状与展望[J].计算机学报,2013,36(6):1125-1138.
[4] Arthur W B. The second economy[EB/OL].2011.http://www.images-et-reseaux.com/sites/default/files/medias/blog/2011/12/the-2ndeconomy.pdf.
[5] Tempini N.Book review:'big data:a revolution that will transform how we live,work,and think'[J].Media Culture & Society,2013,37:78-105.
[6] 李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J].中国科学院院刊,2012,27(6):55-90.
[7] 孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报,2014,25(4):839-862.
[8] 陈立玮,冯岩松,赵东岩.基于弱监督学习的海量网络数据关系抽取[J].计算机研究与发展,2013,50(9):1825-1835.
[9] 程学旗,郭嘉丰,靳小龙.网络信息的检索与挖掘回顾[J].中文信息学报,2011,25(6):111-117.
[10] 中国电子科学研究院学报编辑部.大数据时代[J].中国电子科学研究院学报,2013(1):27-35.
[11] 王 珊,王会举,覃雄派,等.架构大数据:挑战现状与展望[J].计算机学报,2011,34(10):1741-1752.
[12] 王 鄂,李 铭.云计算下的海量数据挖掘研究[J].现代计算机,2009(11):22-25.
[13] 李伟卫,赵 航,张 阳,等.基于MapReduce的海量数据挖掘技术研究[J].计算机工程与应用,2013,49(20):112-117.
An Interactive Processing Method of Analysis and Query for Big Data Based on Hadoop
LI Cong-ying1,WANG Rui-gang1,LIANG Xiao-jiang2
(1.Xi’an University of Posts and Telecommunications,Xi’an 710061,China;2.Shaanxi Information Engineering Research Institure,Xi’an 710061,China)
An interactive processing method of analysis and query of big data based on Hadoop aims to analyze and query large data fast,whose important feature is the rapid query speed.The method is able to run on a cluster with thousands of nodes,suitable for analyzing semi-structured or nested data,combining with existing SQL environment and Apache Hive.The main purpose is to use the method to connect HDFS,Hive and Hbase for query,also achieving to query data from different data sources.Furthermore,in the same Hadoop clustering environment,the method and Spark SQL is compared in the query speed for data with 100 000,200 000,500 000,one million and five million.Several experiments show the method is fast and efficient,and enables business users to query data and analyze enterprise Hadoop big data quickly and efficiently.
Hadoop clustering;big data processing;interactive query;fast;SQL
2015-12-01
2016-03-09
时间:2016-08-01
2015陕西省信息化技术研究项目课题(2015-002)
李聪颖(1992-),女,硕士研究生,研究方向为云计算与大数据处理;王瑞刚,高级工程师,研究方向为多媒体通信。
http://www.cnki.net/kcms/detail/61.1450.TP.20160801.0904.038.html
TP302.1
A
1673-629X(2016)08-0134-04
10.3969/j.issn.1673-629X.2016.08.028
