改进遗传算法的云数据容灾备份方案*
2016-02-07袁海峰
袁海峰
(苏州科技大学 网络与教育技术中心,江苏 苏州 215009)
改进遗传算法的云数据容灾备份方案*
袁海峰*
(苏州科技大学 网络与教育技术中心,江苏 苏州 215009)
针对云服务供应商的数据容灾系统中成本和恢复时间优化问题,提出一种基于改进型遗传算法(IGA)的云数据容灾备份方案.首先,根据各云供应商的存储价格、通信价格和带宽等属性构建数据备份模型.然后,提出一种改进型遗传算法,通过一个替换重组操作来提高算法的收敛速度和寻优能力.最后,以备份成本和恢复时间的加权和为优化目标,利用IGA求解最优备份方案.实验结果表明,该方案在备份成本和恢复时间方面具有优越的性能.
云计算;数据容灾;改进型遗传算法;备份成本;恢复时间
随着云计算的快速发展,形成了大量的应用程序和用户数据,通常这些数据会存储在云服务供应商的数据库中[1].数据的安全性是关键问题之一,为此,云服务供应商(Cloud Provider, CP)需要将数据进行备份,以防止数据大量丢失(数据灾难)给用户带来巨大影响[2].解决数据灾难问题的方法称为容灾(disaster recovery, DR)策略[3].通常情况下,云供应商会将关键数据备份1个或多个副本,然后租用其他云供应商的存储器,用来存储副本,利用数据冗余性和异地分布性来实现容灾[4].然而,这样也就产生大量费用开销.如何选择备份数据的存储位置,使数据备份费用和灾难恢复时间最低,是一个NP困难问题.
目前,针对云数据容灾备份存储的优化方案主要有3种:基于规则、基于整数线性规划和基于智能进化算法的策略.例如,[5]以备份费用为优化目标,在考虑恢复截止期限约束下, 利用整数线性规划模型求解问题.然而,该方案没有优化恢复时间,这会影响实际应用中的时效性.另外,该方法中,若数据量很大时,其计算时间太长.[6]以备份成本和恢复时间为优化目标,提出一种基于遗传算法(Genetic Algorithm, GA)的多目标优化模型.然而,其并没有给出成本与时间的具体表达式,另外其采用传统GA,存在收敛速度慢、寻优能力差等缺陷.
为此,本文提出一种基于改进型遗传算法(Improved Genetic Algorithm, IGA)的云数据容灾备份方案,称为ETDRS.在传统GA中融入了替换重组操作,提高算法的收敛速度和寻优能力.另外,根据存储价格、通信价格和带宽等因素,给出了备份成本和恢复时间的表达式,并加权这两个因素来构建目标函数.实验结果表明,本文方案获得了最低的备份成本和最短的恢复时间.
1 容灾系统模型
1.1 云数据容灾系统基本架构
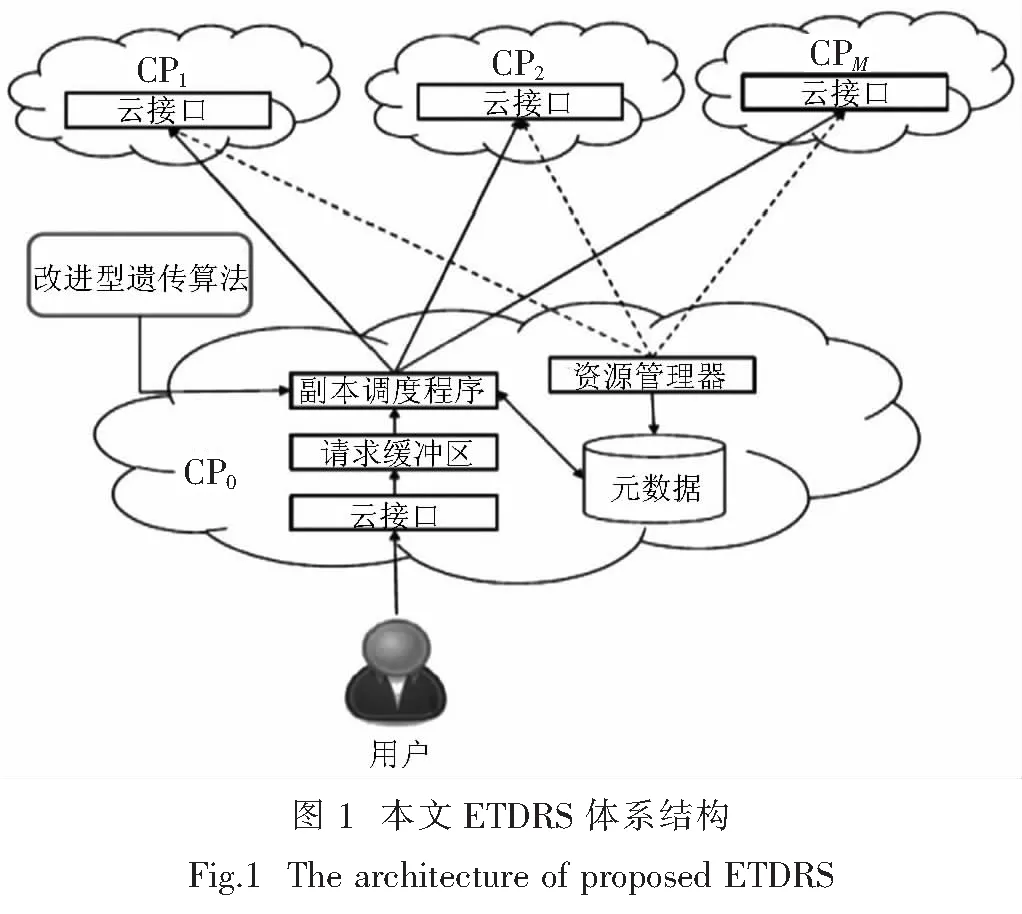
本文基于一种IGA,提出一种成本和时间有效的容灾系统模型(Cost and Time Effective Disaster Recovery System, ETDRS),来获得最优的云数据存储方案,以此降低云灾难的影响,及时恢复数据.本文ETDRS可以有效地从不同类型的云供应商中选择数据库来存储备份数据,提高数据的可靠性,并降低存储成本.另外,当灾难出现时,使其获得较低的恢复时间.本文ETDRS中,数据被备份为3份.在引导数据备份过程中,根据存储成本、网络通信成本、带宽等因素,以缩短数据恢复时间和减少数据备份成本为优化目标,利用IGA使其合理地从多个云提供商(CP)中选择存储资源.本文方案的基本架构如图1所示.
容灾系统模型通常包含数据DR用户和多个云CP,DR用户可能是个体、企业或其他云CP[7].CP1到CPM表示为CP0提供存储资源的云CP.CP的云接口为一个云存储接口,用来向用户发送或接收数据.CP0为DR用户所在的CP,其中的请求缓冲区用于缓存排队的存储请求.
当副本调度程序从请求缓冲区获得请求时,它创建三个副本,并将副本发送到3个CP中进行储存.资源管理器负责观察所有CP资源利用率的变化情况.元数据是一个云数据库,包含CP资源利用率和副本位置的信息.
1.2 数据恢复过程
当云数据发生灾难后,需要从事先存储备份数据的CP中读取数据进行恢复,数据恢复过程的执行流程如下:
(1) 当发生数据灾难时,用户向数据灾难恢复服务提供商CP0发出数据恢复请求.
(2) 一旦请求到达CP0,则CP0对用户执行身份认证过程,一旦发现用户不合法,就忽略该请求.
(3) 若用户认证通过,CP0读取资源管理器中元数据库的信息,找到用户数据的备份位置.
(4) 如果CP0在三个不同位置处的CP中发现了用户备份数据,则将比较所有CP,并选择具有最高频宽的云CP读取数据.
(5) 假设所选择的位置为CPm,那么CPm的恢复管理器通知读取数据的恢复代理已经取得临时访问授权.此时,CPm会告知CP0.
(6) 用户的恢复代理接受来自CP0的授权消息和备份数据位置,并从CPm中读取备份数据.
1.3 数据备份成本
数据备份成本(COST)主要包含网络通信成本和数据存储成本[8],其公式表示为:
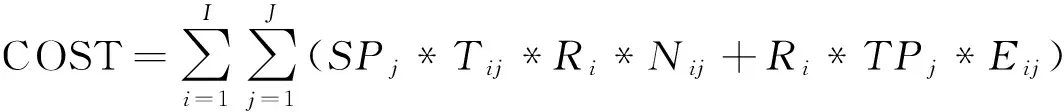
(1)
其中SPj表示第j个云CP制定的存储价格;Tij表示第i个数据块在j个云CP中存储的时间;Ri表示第i个数据块的数据副本量;Nij表示在j个云CP中存储的第i个数据块的数据副本数量;TPj表示第j个云CP制定的通信价格;Eij为一个布尔变量,当CP中存储了数据副本时,将布尔变量设置为1,否则将其设置为0.
1.4 数据恢复时间
恢复时间(TIME)主要由恢复数据的大小、各云CP的带宽和链路数量决定,其表达式为:
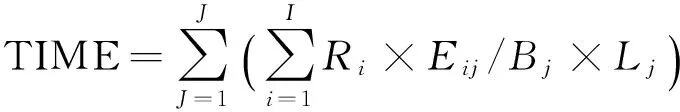
(2)
其中Bj为第j个云CP提供的可用带宽;Lj为第j个云CP提供的可用链路数量.
2 基于IGA优化数据备份方案
在本文提出的ETDRS体系结构中,CP0中副本调度模块执行的优化调度策略是非常重要的,决定着数据恢复时间和数据备份成本.本文提出一种融入改进型的遗传算法(IGA)来对云数据存储进行调度.GA是一种模拟自然进化过程来寻找最优解的人工智能技术[9].与传统GA不同的是,本文融入了替换重组操作,在每一轮遗传过程结束后,将一定比例的较低质量的染色体进行替换,重新构建种群.以此提高种群的质量,使其能够快速收敛到最优解.
本文的优化目标是最小化恢复时间和恢复成本,因此,在评价方案可行性的适应度函数中需要权衡考虑这两个因素.本文通过一个权重因子k来调整上述两个因素的重要性[10].为了构建适应度函数,根据所设定的上下限,将成本因素COST和时间因素TIME归一化到[0,1]范围内,以此获得Nor_COST和Nor_TIME.那么,染色体s的适应度函数表达式如下:
fitness(s)=k×Nor_COST+(1-k)×Nor_TIME .
(3)
本文IGA算法分为以下5个步骤:

步骤2 (选择操作):根据适应度函数评估各染色体的适应度值,并按照选择概率P(sn)来选择两个染色体作为下一代的父代,其中具有高适应度的染色体被选择的概率较大.每个染色体被选择的概率表达式如下:
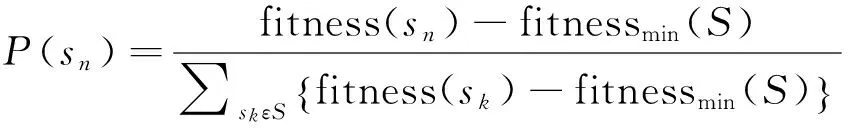
(4)
其中fitness(sn)为第n个染色体的适应度值,fitnessmin(S)为群体中染色体的最小适应度值.
步骤3 (交叉及变异操作):为了从所选的染色体对中生成新的染色体,本文以交叉概率pc执行单点交叉操作.其中,交叉截止点是随机确定的,且父代和子代的强度相同.交叉结束后,对每个染色体进行变异操作,其中变异概率为pm.
步骤4 (替换重组操作):在执行完选择、交叉和变异步骤之后,评估每个染色体的适应度值,并进行排序.根据替换概率Prep执行替换操作.即在从当前种群中移除Prep的具有较小适应度值的染色体,然后再随机生成同等数量的染色体进行补充,重新构建一个高质量的种群.
步骤5 (停止):迭代执行步骤2到步骤4,如果满足停止条件,则终止该过程,并输出最优解.
3 实验及分析
本文通过Matlab构建仿真实验,实验中构建10个云存储供应商CP,各自具有不同的存储价格(单位为$/GB·d)、通信价格(单位为$/GB)和带宽(单位为MB/s),如表1所示.这里假设每个CP具有无限的存储空间.对于需要备份的数据块,本文随机生成100个大小不等的数据块,数据块大小范围为[10,100]GB,每个数据块分别在3个不同的CP上进行备份.
对于本文采用的IGA,设定参数如下:种群大小为30;交叉概率(Pc)为0.9;变异概率(Pm)为0.1;替代率(Prep)为20%;最大遗传代数为50.对于IGA中染色体适应度函数中备份成本和恢复时间的权重因子k,由于在实际应用中,数据灾难不是经常发生,相比于恢复时间,备份成本对企业的影响更大.所以本文设置k=0.7.

表1 云存储供应商CP的参数Tab.1 The parameters of cloud storage provider CPs
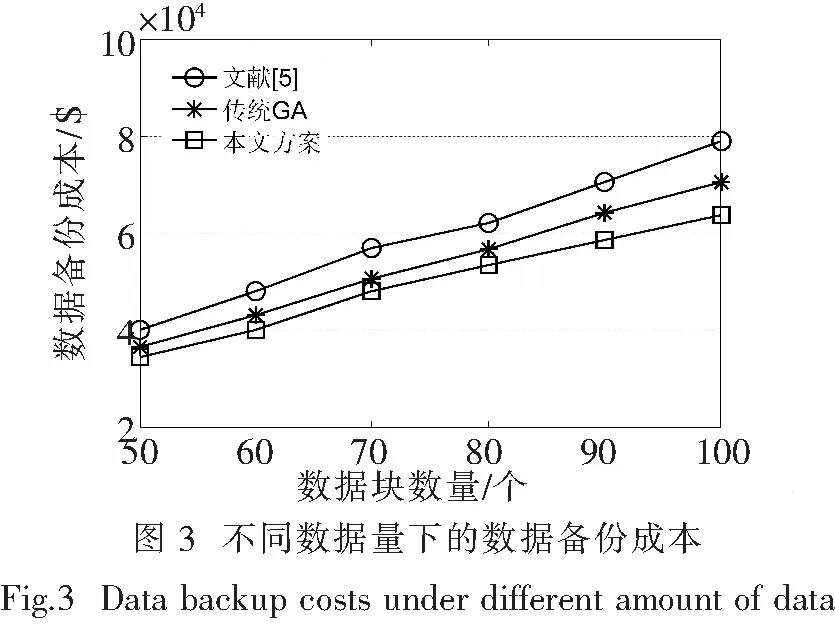
首先,本文进行云数据备份存储实验,分别生成50、60、70、80、90、100个大小为10~100 G不等的数据块,在具有10个CP的供应商中进行备份存储30 d,并计算数据备份成本.将本文方法与[5]提出的整数线性规划方案、[6]提出的基于传统GA的方案进行比较,结果如图3所示.
从图3可以看出,具有智能优化算法的数据备份方案的成本明显低于传统[5]方法.其中,本文方案的备份成本最低,且随着数据量的增加,优势更为明显.这是因为,本文融入了替换重组操作,提出了一种改进型的GA,其比传统GA具有更强的搜索能力,所获得的解决方案也更优.
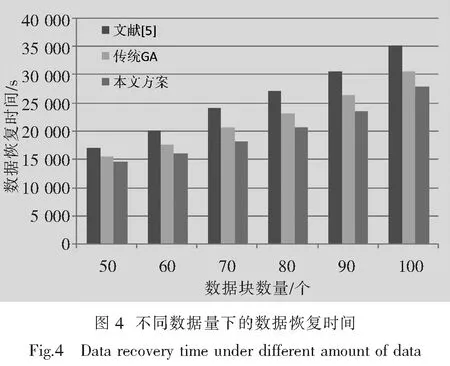
下面在数据恢复时间方面评估各种方案的性能.实验中,设定数据存储30 d后发生数据灾难,此时需要读取备份数据进行恢复,记录数据传输时间,如图4所示.可以看出,本文方案的恢复时间最短,这是因为,本文在优化过程中将恢复时间融入到了适应度函数中,使生成的备份方案除了考虑成本外还考虑了恢复时间.当数据量为100时,本文方案的恢复时间比[5]缩短了约26%,比传统GA缩短了约10%.
4 结束语
本文提出一种基于IGA的云数据容灾系统中的数据备份方案,利用融入替换重组操作的遗传算法,以备份成本和恢复时间为优化目标,获得最优的容灾方案.仿真实验结果表明,与现有方法相比,本文容灾方案具有较低的备份成本和恢复时间,且数据量越大性能优势越明显,具有可行性和有效性.
[1] 宋俊锋. 基于MILP的云计算数据中心扩张策略优化模型[J]. 湘潭大学自然科学学报, 2015, 37(4): 105-110.
[2] 项菲, 刘川意, 方滨兴,等. 新的基于云计算环境的数据容灾策略[J]. 通信学报, 2013, 34(6): 92-101.
[3] LI G, ZHANG Q, LI W, et al. The design and verification of disaster recovery strategies in cloud disaster recovery center[J]. Telkomnika Indonesian Journal of Electrical Engineering, 2013, 11(10):231-239.
[4] 李峰, 刘晓洁, 林翰翮. 基于Oracle数据库的容灾系统[J]. 计算机工程与设计, 2011, 32(11):3573-3576.
[5] BOSSCHE R V D, VANMECHELEN K, BROECKHOVE J. Cost-optimal scheduling in hybrid IaaS clouds for deadline constrained workloads[C]// Cloud Computing (CLOUD), 2010 IEEE 3rd International Conference on IEEE, 2010: 228-235.
[6] SUGUNA S, SUHASINI A. Enriched multi objective optimization model based cloud disaster recovery[J]. Karbala International Journal of Modern Science, 2015, 1(2):122-128.
[7] 钟睿明, 刘川意, 王春露,等. 一种成本相关的云提供商数据可靠性保证算法[J]. 软件学报, 2014, 25(8): 101-104.
[8] TANG K. Research on disaster recovery model of cloud-based digital library[J]. Applied Mechanics & Materials, 2013, 33(6):2134-2137.
[9] 朱志勇, 刁洪祥. 基于改进遗传算法的车辆路径问题研究[J]. 湘潭大学自然科学学报, 2011, 33(3):115-118.
[10] YU S, KIM S W, OH C W, et al. Quantitative assessment of disaster resilience: An empirical study on the importance of post-disaster recovery costs[J]. Reliability Engineering & System Safety, 2015, 13(7):6-17.
责任编辑:龙顺潮
Cloud Date Disaster Recovery Backup Scheme Based on Improved Genetic Algorithm
YUANHai-feng*
(Network and Educational Technology Center, Suzhou University of Science and Technology, Suzhou 215009 China)
For the issue that the cost and time optimization in data disaster recovery system of cloud service providers, a cloud date disaster recovery backup scheme based on Improved Genetic Algorithm (IGA), is proposed in this paper. Firstly, the date backup model is built according to the storage price, communication price and bandwidth of cloud service providers. Then, an improved genetic algorithm is proposed, which can improve the convergence speed and search ability of the algorithm by replacement and recombination operation. Finally, the weighted sum of the backup cost and recovery time is used as optimization object, and obtains the optimal backup scheme by IGA. Experimental results show that the proposed scheme has excellent performance in terms of backup cost and recovery time.
cloud computing; date disaster recovery; improved genetic algorithm; backup cost; recovery time
2016-02-07
江苏省自然科学基金项目(BK2012166)
袁海峰(1977-),男,河南 周口人,工程师. E-mail:yuanhaifengsz@126.com
TP391
A
1000-5900(2016)03-0084-05
