转基因产品标准物质定值系统设计与应用
2016-02-06刘立波宁夏大学数学计算机学院宁夏银川750021
陈 璞,刘立波(宁夏大学 数学计算机学院,宁夏 银川 750021)
转基因产品标准物质定值系统设计与应用
陈 璞,刘立波*
(宁夏大学 数学计算机学院,宁夏 银川 750021)
针对转基因产品标准物质定值对象复杂、流程繁琐、效率低下、准确度低的现状,设计并实现集数据抽取、数据分类、数据筛选与定值为一体的转基因产品标准物质定值系统。通过分析转基因生物标准物质的表现形式并对其分类,解决对象的复杂性问题;采用精密性检验、正态性检验、组内可疑值检验、组间平均值检验4个环节进行数据筛选,优化工作流程,提高定值效率;在此基础上,对筛选出的数据进行定值分析,最终提高了转基因产品标准物质的定值效率与准确度。试验证明,该系统能够满足实际应用的需求。
转基因产品; 标准物质定值; 数据抽取; 数据分类; 数据筛选
随着转基因产品的研发及大规模商业化,其安全性问题备受社会各界关注[1-2]。为此,各国积极开展转基因产品检测技术、方法及其标准化研究[3-4]。在保证转基因检测结果的可比性、溯源性,推进转基因产品检测方法标准化等方面,转基因生物标准物质(genetically modified organisms-reference material,GMO-RM)发挥着十分重要的作用[5-6]。
转基因生物标准物质是具有1种或多种足够均匀和很好地确定了的特性(转基因成分和含量)的一种材料或物质,并被证实适用于测量或标称特性检验。其是转基因生物安全监管、定性与定量检测、检测方法建立与标准化过程中不可缺少的物质基础[7-8]。目前,实现各类转基因产品中的标准物质高效准确定值,已成为该领域的重点研究方向,而定值对象复杂性、算法复杂性和数据复杂性是阻碍这一目标实现的难点所在。2012年,我国出台国家标准《标准物质定值的通用原则及统计学原理》[9],为标准物质的定值提供了理论支持。至今,尚未见针对转基因产品标准物质进行高效、全面定值的系统。为此,以转基因产品标准物质全面、高效、准确定值为落脚点,通过分析转基因生物标准物质的表现形式对其进行数据分类,参照《标准物质定值的通用原则及统计学原理》设计定值算法,进而优化定值流程,完成数据筛选,在此基础上,对筛选后的数据进行定值分析,最终实现各类转基因产品中的标准物质全面、高效、准确定值,从而为完善我国转基因产品的检测、监测和管理提供技术支持。
1 标准物质定值相关原理
1.1 定值方法
标准物质的定值一共有4种方法:用高准确度的绝对或权威测量方法定值、用2种以上不同原理的已知准确度的可靠方法定值、用有证的一级标准物质定值、多个实验室联合定值。在上述方法中,用高准确度的绝对或权威测量方法定值过于复杂,定值成本高,无法广泛应用;用2种以上不同原理的已知准确度的可靠方法定值和用有证的一级标准物质定值这2种方法均存在局限性,不能够应对日益增长的新兴转基因产品标准物质定值;多个实验室联合定值成本相对较低,能够对各类转基因产品定值,随着网络的发展,该方法逐渐成为主要的定值方法。因此,本研究选取多个实验室联合定值作为转基因产品标准物质的定值方法。
1.2 定值原则及统计学原理
在标准物质定值前,应对数据的精密性、均匀性、稳定性和正态性进行检验,并检测组内可疑值,然后判断是否存在组间显著性差异。在此过程中,调整或删除存在问题的数据,保证定值的准确性。
由于测量水平不一致,可能会导致部分数据的偏差过大,甚至出现错误数据,因此,依据国际现行通用的惯例[10],在进行转基因产品标准物质定值前,应对数据进行精密度检验,经此审查后,得到符合国际标准的数据。
均匀性与稳定性是标准物质的基本属性,前者用于描述其特性的空间分布特征,后者用于描述标准物质的特性值随时间变化的性质,即时间分布特征,在标准物质的定值过程中必须对二者进行评估,为计算该标准物质的不确定度提供依据。
正态性即试验结果应遵循对称分布[11],其不仅可以用来描述数值变量的分布特征,还为统计推断提供了极大的方便[12]。在标准物质定值前,可以参照既往基于大样本所推测的变量分布形式,确定正态性假定的合理性。如果缺少相关文献支持,就应基于实际的观测数据,实施正态性检验[13]。
组内可疑值与组间显著性差异是在选择数据测量方法、设置测量条件或数据检测过程中出现差错而产生的,对定值的准确性和不确定度的计算带来极大的干扰。因此,在定值前应用适当的统计学方法消除它们的干扰。
2 系统设计
2.1 系统框架
根据实际需求,转基因产品标准物质定值系统主要分为5大模块,如图1所示。

图1 转基因产品标准物质定值系统功能模块
建立检测表:此模块功能是采集标准物质的定值数据并记录相关信息。在该模块,系统通过数据抽取获取标准物质检测数据,并记录下数据数量、数据组长度、检测日期、提取浓度等信息。
标准物质种类识别:此模块功能是根据数据格式等信息,判断将要定值的数据属于哪一种转基因标准物质。
数据检测:数据检测是本系统的关键部分,也是难点所在。系统将通过精密性检验、正态性检验、组内可疑值检验、组间平均值检验4道程序完成对数据的筛选,最大程度地保证定值准确度。
定值报告:该模块功能是对筛选后的数据定值并生成定值报告。用户被要求输入标准值,结合标准值与筛选后数据的相关系数计算出标准物质的定值及不确定度,最终生成一份Word文档。
历史检测:该模块负责保留每一次定值的原始数据、检验过程中产生的临界值与检验系数以及筛选后的数据以及定值结果,用户可在此检查定值流程并进行多次检验,有利于定值方法的优化和结果验证。
2.2 定值流程
2.2.1 数据抽取 为了节约时间,避免人工输入数据时出现差错,本系统采用数据抽取的方式从数据源自动导入数据,如图 2所示。
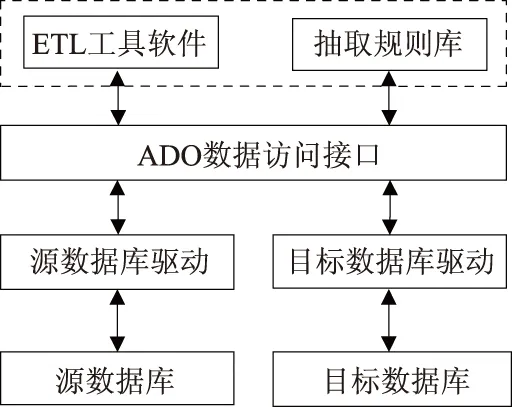
图2 数据抽取
系统借助ETL工具软件,根据数据的长度、逻辑顺序建立抽取规则,通过 ADO 数据访问接口,连接到异构的数据源执行数据抽取,经转换后,加载到目标数据库。系统数据源既可以是关系数据库,也可以是普通的数据文件,如Access数据库、Database2、Oracle、SQL Sever、SAS系统、Excel电子表格、文本文件等。抽取方式分为全量抽取与增量抽取2种,其中,全量抽取比较简单,只需将数据源中的数据复制到目标数据库中;增量抽取相对复杂,抽取数据源中新增、修改、删除的数据。
2.2.2 数据分类 数据成功抽取之后,要确定数据属于哪一种转基因标准物质,以便于后续的数据筛选处理能够选择合适的检验方法。因此,在数据筛选之前要进行数据分类操作。
目前,国内外研制的转基因生物标准物质主要有4个种类:基体标准物质、基因组DNA标准物质、质粒DNA标准物质和蛋白质标准物质。在本系统中,蛋白质标准物质与基体标准物质数据组中的元素相互独立,并且数据单位分别为质量单位和百分比;基因组DNA标准物质与质粒DNA标准物质数据组中的元素存在逻辑关系,但二者的逻辑关系不同。系统根据上述差别设计分类标准。
2.2.3 数据筛选 由于数据库中的数据是面向某一主题的数据的集合,这些数据从多个数据源中抽取而来并且包含历史数据,因此就无法避免错误数据或相互之间有冲突的数据,而这些数据会影响定值准确性,所以在定值前要对数据进行数据筛选。
数据筛选是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性、处理无效值和缺失值等。数据筛选的任务就是按照一定的规则过滤不符合要求的数据,在本系统中,这些不符合要求的数据主要分为不完整数据、错误数据、重复数据三大类。
虽然筛选环节越多效果越好,但实际应用中的成本也随之增高,为平衡效果与成本,本系统数据筛选采用精密性检验、正态性检验、组内可疑值检验、组间平均值检验4个检验环节,在成本处于合理范围的情况下,最大限度地消除影响定值准确性的数据因素。
2.2.3.1 精密性检验 在精密性检验环节,计算每组样本的组内标准偏差(组内SD)、组间标准偏差(组间SD),通过组内SD计算出组内相对标准偏差(组内RSD),通过组间SD计算出组间相对标准偏差(组间RSD),若组内RSD>25%或组间RSD>35%,则样本数据存在可疑值。
2.2.3.2 正态性检验 正态性检验环节设置4个检验:偏态系数和峰态系数检测、夏皮洛威尔克检测、达格斯提洛检测、艾珀斯普利检测。选用3个检测方法对数据进行检测,其中,偏态系数和峰态系数检测、夏皮洛威尔克检测为必选方法,当数据组数据量低于50时,选用达格斯提洛检测,否则选用艾珀斯普利检测。3个方法若有1项检验不合格,则正态检验不合格。
偏态系数和峰态系数检测应计算出被检验数据的偏态系数和峰态系数,首先应计算出样本m阶中心距Bm,公式如下:
然后分别计算出偏态系数Cs和峰态系数Ck。公式如下:
将计算出的偏态系数和峰态系数与临界值表中的临界值对比,若小于临界值,则合格。
夏皮洛威尔克检测是对有序数组进行正态检验,检验前要将被检测数据排序,计算公式如下:
其中,xi为按照由小到大顺序排序后的被检测数据,ai为固定系数。将计算出W与临界值表中的临界值对比,若大于临界值,则合格。
其中,B2为方差,即二阶中心距,C1和C2为常数,分别为0.282 094 79和0.029 985 98。将计算出的Y与临界值表中的临界区间对比,若属于临界区间,则合格。
艾珀斯普利检测计算公式如下:
将计算出的TEP与临界值表中的临界值对比,若小于临界值,则合格。
2.2.3.3 组内可疑值检验 组内可疑值检验分为3个检验:Grubbs检测、Dixon检测和T检测。选用2个检测方法对数据进行检测,其中,Grubbs检测为必选方法,当数据组中数据相互独立时,选用Dixon检测,当数据组中数据存在逻辑关系时,选用T检测。若有1项检验不合格,则组内存在可疑值。
Grubbs检测首先将被检验数据中每个元素与均值做差,然后求绝对值,然后将计算出的绝对值数列与临界值表中的临界值对比,若小于临界值,则合格。
Dixon检测计算公式如下:
r1=(x2-x1)/(xn-x1)
rn=(xn-xn-1)/(xn-x2)
其中,x1为最小值被检验数据升序排列后的第一项(最小值),xn为最后一项(最大值)。将计算出的r1、rn与临界值表中的临界值对比,若小于临界值,则合格。
T检测将各数据组均值排序,选取均值差别最小的2组数据进行检验。将计算出的T值与临界值表中的临界值对比,若小于临界值,则合格。
2.2.3.4 组间平均值检验 组间平均值检验分为2个检验:Cochran检测和F检测。当数据组相互独立时,选用Cochran检测;当数据组存在逻辑关系时,选用F检测。若检验不合格,则被检测的2组数据存在显著性差异。
Cochran检测计算公式如下:
其中,Smax为被检验数据组中的最大方差,Si为每个数据组的方差,将计算出的C与临界值表中的临界值对比,若小于临界值,则合格。
F检测将2组被检验数据求方差,然后计算大方差与小方差的比值,将计算出的比值与临界值表中的临界值对比,若小于临界值,则合格。
2.2.4 标准物质定值 数据筛选后,对符合标准的数据进行定值及不确定度计算。首先要求输入标准值a,定值A、不确定度B的计算公式如下所示:
A=(mean-a)/a × 100%

3 系统测试与验证
为了对系统进行检测并验证结果的有效性,对一未知转基因产品的标准物质样本组进行定值。成功抽取数据后,经识别确认为蛋白质标准物质,生成的原始数据如表1所示。其中, R1、R2、…、R9分别表示每一个样本组中的样本数据,本次测试抽取10组样本组,每个样本组中包含9个样本数据。

表1 原始数据 ng/μL
在精密性检验中,计算每组数据的组内SD与组间SD,然后分别计算出组内RSD与组间RSD,发现第3、4组数据组内RSD大于25%,将这2组数据剔除后,剩下数据均合格。由于剩下8组数据每组数据量均小于50,且数据组之间、各组数据之间均相互独立,故正态性检验选择偏态系数和峰态系数检测、夏皮洛威尔克检测、艾珀斯普利检测3种方法,组内可疑值检验选择Grubbs检测、Dixon检测2种方法,组间平均值检验选择Cochran检测。正态性检验结果如表2所示。
表2 正态性检验结果

样本组序号CsCkWTEP10.312.580.990.0220.101.460.870.1850.642.280.900.136-0.102.080.980.037-0.241.840.950.0780.161.530.920.159-0.521.800.860.2210-0.161.790.830.09
经查表,在8个样本组每组9个样本的情况下,偏态系数临界值为1.42,表中数据均小于临界值;峰态系数临界区间为1.46~3.70,表中数据均处于该范围,偏态系数和峰态系数检测合格。夏皮洛威尔克系数临界值为0.82,表中数据均大于临界值,夏皮洛威尔克检测合格。艾珀斯普利系数临界值为0.34,表中数据均小于临界值,艾珀斯普利检测合格。因此,正态性检验通过。
在组内可疑值检验中,首先进行Grubbs检测,被测样本组中的样本与该样本组样本均值差的绝对值小于临界值2.12,Grubbs检测合格;Dixon检测中的系数均小于临界值0.72,Dixon检测合格。因此,组内可疑值检验通过。
在组间平均值检验中,计算得出8组样本组的Cochran系数为0.23,小于临界值0.29。因此,组间平均值检验通过。
在定值环节,输入参考值1.00,计算后最终定值及不确定度表述为:-7.24%±0.13%。将此结果与用高准确度的绝对或权威测量方法定值的结果进行比对,完全一致。为继续验证该系统的有效性,对4种转基因产品标准物质各进行10次定值,并将结果与用高准确度的绝对或权威测量方法对比,大多数试验结果一致,少数不一致的结果误差均在0.1%以内,因此,本系统满足实际应用的需求。
4 结论
本研究以数据预处理为切入点,采用数据抽取、数据分类和数据筛选技术,在转基因产品标准物质的定值前规范定值数据并尽可能多地剔除错误数据,极大程度地降低定值过程中可能出现的干扰因素,进而提高定值准确性。基于此,设计并实现了转基因产品标准物质定值系统,通过与用高准确度的绝对或权威测量方法定值的结果对比,证明了系统定值准确度较好,能够满足实际应用需求。在测试过程中发现,不确定度的计算结果存在少量偏差,因此,改进数据筛选流程,进一步完善系统性能将作为后续工作的重点。
[1] 盛耀,许文涛,罗云波.转基因生物产业化情况[J].农业生物技术学报,2013,21(12):1479-1487.
[2] Bawa A S,Anilakumar K R.Genetically modified foods: Safety,risks and public concerns—A review[J].Journal of Food Science and Technology-Mysore,2013,50(6):1035-1046.
[3] Caprioara-Buda M,Meyer W,Jeynov B,etal.Evaluation of plasmid and genomic DNA calibrants used for the quantification of genetically modified organisms[J].Analytical and Bioanalytical Chemistry,2012,404(1): 29-42.
[4] Christoph E.Genetic technology and food safety:Country report—Switzerland[J].Genetic Technology and Food Safety,2015,18(14):255-285.
[5] 董莲华,赵正宜,李亮,等.转基因植物标准物质研究进展[J].农业生物技术学报,2012,20(2):203-210.
[6] European C,Joint R.Verification of analytical methods for GMO testing when implementing interlaboratory validated methods[R/OL].[2015-10-20].http://www.jrc.ec.europa.eu/.
[7] 张丽.转基因产品检测标准物质研究[D].北京:中国农业科学院,2012.
[8] 张丽,吴刚,武玉花,等.转基因产品检测标准物质的定值和不确定度研究进展[J].农业生物技术学报,2014,22(3):362-371.
[9] 国家标准物质研究中心.标准物质定值的通用原则及统计学原理:JJF 1343—2012[S].北京:中国标准出版社,2012:1-61.
[10] Marco M,Hermann B,Marzia D,etal.Definition of minimum performance requirements for analytical methods of GMO testing[R/OL].[2015-10-20].http://www.jrc.ec.europa.eu/.
[11] 周洪伟.正态性检验的几种常用的方法[J].南京晓庄学院学报,2012,1(3):13-18.
[12] 马兴华,张晋昕.数值变量正态性检验常用方法的对比[J].循证医学,2014,14(2):123-128.
[13] 何清,王震坤.正态性检验方法在教学研究中的应用[J].高等理科教育,2014,1(4):18-21,77.
Design and Implementation of Certified Reference Material Value Characterization System for Genetically Modified Organisms
CHEN Pu,LIU Libo*
(Department of Mathematics and Computer Science,Ningxia University,Yinchuan 750021,China)
In light of the current value characterization of certified reference material with complex objects,complicated process,inefficient and low accuracy for genetically modified organisms,a certified reference material value characterization system for genetically modified organisms was designed and implemented,which integrated data extraction,data classification,data filters and value characterization as an entirety.The object complexity was solved through the analysis of genetically modified organisms certified reference material’s manifestations and classification;the data filters were done using precision test,normality test,suspicious test within group and average test between groups,so as to optimize workflow and improve efficiency.On this basis,the selected data were analyzed and valued,finally improving the efficiency and accuracy of value characterization.The experimental illustrated that this system could meet the demand of practical application.
genetically modified organisms; value characterization of certified reference material; data extraction; data classification; data filters
2015-12-10
国家“863”计划项目(2012AA101105);国家自然科学基金项目(31571646)
陈 璞(1990-),男,河南信阳人,在读本科生,研究方向:智能信息处理。E-mail:zpchen2008@126.com
*通讯作者:刘立波(1974-),女,宁夏银川人,教授,博士,主要从事智能信息处理、数据挖掘与清洗方面研究。 E-mail:liulib@163.com
S188;Q789
A
1004-3268(2016)06-0040-05
