Event relation classification based on Tri-Training
2016-01-26DINGSiyuanHONGYuZHUShanshanYAOJianminZHUQiaoming
DING Si-yuan,HONG Yu,ZHU Shan-shan,YAO Jian-min,ZHU Qiao-ming
(Provincial Key Laboratory of Computer Information Processing Technology,Soochow University,Suzhou 215006,China)
Event relation classification based on Tri-Training
DING Si-yuan,HONG Yu,ZHU Shan-shan,YAO Jian-min,ZHU Qiao-ming
(Provincial Key Laboratory of Computer Information Processing Technology,Soochow University,Suzhou 215006,China)
Abstract:As one of natural language processing techniques, event relation detection aims at exploring logical relationship between pairwise events. To solve the problem of lacking enough training data in event relation detection tasks, we propose a novel approach based on Tri-Training to augment the training corpus. We firstly use labeled training data to learn three different classifiers, and then exploit majority voting method to expand training corpus with higher confidence samples, iteratively optimize the model and eventually improve the performance of event relation classification. Experimental results show that compared to other methods, the Tri-Training based method achieves 64.3% F1-score over four general semantic relations.
Key words:event relation;frame;semi-supervised learning;Tri-Training
1引言
事件关系是指事件与事件之间相互依存和关联,且具有客观性和规律性的逻辑形式。事件关系检测以事件为主体元素,通过分析事件文本的结构信息及语义特征,挖掘事件之间深层的逻辑关系,进而辅助事件的衍生、发展以及信息的推理与预测。事件关系检测包含事件关系识别和事件关系判定两个部分。本文只研究事件关系判定任务,将事件关系判定看作分类问题。

Figure 1 Structure of event relations图1 事件关系体系结构图
目前,针对事件关系分类的研究相对较少,仍缺乏完善的事件关系体系定义。而与事件关系较为类似的篇章关系研究已然获得更多关注,相关任务定义和研究方法也得到一定程度的验证和实践。基于此,杨雪蓉等[1]通过分析事件关系检测与篇章关系检测的异同点,建立一套基于篇章关系分析的事件关系体系。本文延续杨雪蓉等[1]提出的事件关系检测研究方法,以篇章关系为桥梁,借助篇章关系的任务定义,辅助指导事件关系分类。事件关系类型分成两层(如图1所示):第一层包含四种主要关系:Expansion(扩展关系)、Contingency(偶然关系)、Comparison(对比关系)和Temporal(时序关系);第二层关系针对第一层的事件关系进行细分,共包含10种关系。本文主要研究第一层的四种主要事件关系。图2为包含四种事件关系类型的文本实例,其中E1~E4为四个相关的事件片段(EventArg)。

Figure 2 Instances of four top event relations图2 四种事件关系实例图
此外,事件关系研究尚缺乏权威的标注语言学资源,为解决该问题,杨雪蓉等[1]标注了部分事件关系样例,然而该样例的数量仍不足以解决事件关系研究中语料不足的问题。针对该问题,本文提出一种基于Tri-Training的事件关系分类方法,该方法旨在利用少量的已标注事件关系样本训练三个不同的分类器,通过分类器之间的协同合作,从大规模未标注数据资源中挖掘错误率较小的未标注数据,进而扩充训练样本,以提高分类器的分类性能。具体实现过程中,本文首先从大规模语言学资源GIGAWORD纽约时报新闻语料(LDC2003T05)中挖掘包含Golden连接词(Golden连接词:指向某一事件关系概率大于96%的连接词,如连接词“now”指向时序关系的概率为100%。)的“事件对”,借助框架语义知识库(FrameNet)[2]过滤不具备事件特征的样本,然后将Golden连接词所对应的事件关系作为未标注事件对的先验关系类别,以此构造未标记事件关系数据集。其次,基于Tri-Training方法在小规模人工标注事件关系数据集上训练三个不同的分类器,在协同训练过程中,每个分类器新增的训练样本均由其余两个分类器协作投票提供,以此对少量人工标注的事件关系数据集进行扩充,最终达到提高事件关系分类性能的目的。图3为事件关系分类任务框架,输入为待测事件关系片段对EventArg1和EventArg2,输出则为具体的事件关系类型。

Figure 3 Task framework of event relation classification 图3 事件关系分类任务框架
本文的组织结构如下:第2节介绍相关工作;第3节介绍框架语义知识库及未标注样本数据的获取;第4节给出基于Tri-Training的事件关系样本扩展方法;第5节给出实验结果与分析;最后总结全文并展望未来工作。
2相关工作
由于事件关系检测的研究刚刚起步,仍缺少权威的事件关系体系,相关研究工作主要集中于某种特定事件关系类型的判定[3~5],主流的研究方法大致可以分为模板匹配法和元素分析法。
(1)模版匹配法。事件关系检测的主要方法之一是借助事件特征的模式匹配法。例如,利用事件触发词(Trigger)的关系模式匹配,根据人工定义的模板,对文本中符合模板的事件关系进行抽取。 Chklovski T等[4]首先定义六种时序关系:“similarity”(“相似”关系),“strength”(“加强”关系),“antonymy”(“相反”关系),“enablement”(“支持”关系),“happens”(“发生”关系)和“before”(“前”关系),再利用人工收集的词-句匹配模板LSP(Lexcial-Syntactic Pattern)抽取包含这六种时序关系的“事件对”,并将抽取的结果形成称为“VerbOcean”的知识库。人工定义的事件关系模板往往受数量限制,造成关系检测的低召回率问题。Pantel P[5]提出利用Espresso算法进行自动模板的构建,该算法根据给定的少量关系实例,通过机器学习方法对现有模板进行迭代扩展,在一定程度上提高了模板匹配方法的召回率。
(2)元素分析法。以事件元素为线索的研究大都继承了Harris[6]的分布假设。Harris分布假设指出,处在同一上下文环境中的词语往往具有相同或相似的含义。Lin D[7]提出了一种结合Harris分布假设和建立依存树思想的无监督方法,称为DIRT算法。该算法将所有事件构造成依存树形式,树中的每条路径表示一个事件,路径的节点表示事件中的词语,若两条路径的词语完全相同,则这两条路径所表示的事件相同或者相似。

Figure 4 Same frame semantic meanings between Event 1&2 图4 Event1与Event2中相同的框架语义
(3)其它。杨雪蓉等[1]在2014年的工作中,通过分析事件关系检测与篇章关系检测的异同点,建立了一套基于篇章关系分析的事件关系检测体系,同时提出了基于跨场景推理的事件关系检测方法。该方法通过构建事件场景向量,计算待测事件对与已挖掘到的包含连接词的事件对之间的事件场景向量相似度,将最相似的事件对所指派的事件关系作为该待测事件对的最终关系类别。但是,这种通过计算相似度的方法,不仅要求语料规模足够大,而且,仅仅根据Golden连接词的映射获取事件关系的方法很难保证准确性。
针对事件关系分类中语料不足的问题,本文提出一种基于Tri-Training事件关系分类方法。该方法根据已有的少量人工标注的事件关系数据集,利用Tri-Training方法,从挖掘到的大量未标注数据集中选择高置信度的样本扩充训练语料,继而提高事件关系分类性能。
3框架语义知识库及未标注样本数据获取
3.1 框架语义知识库
框架语义知识库(FrameNet)是由美国加州大学伯克利分校构建的基于框架语义学 (Frame Semantics)的词汇资源,知识库通过框架(即词语背后隐藏的概念结构和语义等信息)描述单词的释义,对词语意义和句法结构研究提供一种理论框架。该语言学资源共标注1 028个框架语义,其中能够触发事件属性的框架语义共540个。
在框架语义知识库中,对句子的框架语义标注是一种类似于“谓词-论元”结构的“目标词-框架语义(Target-Frame)”结构。每个句子可能包含一个或多个“目标词-框架语义”结构。从图4中可以看出,在两个事件实例Event1和Event2中,Amy和lady对应的框架语义为Person,code与password对应Message框架语义,而anesthetic和wine对应Drag框架语义。虽然两个事件具有不同的语义描述,但却存在相同的框架语义。这就说明,通过框架语义,能够有效地挖掘语义相近的事件,辅助事件关系推理。
3.2 未标注样本集合数据获取
本文使用的外部数据资源为GIGAWORD纽约时报新闻语料(LDC2003T05),共包含4 111 240篇文本。本文从该语料中抽取符合下述要求的未标注事件关系样例:
条件1切分后的文本由事件片段1(EventArg1)和事件片段2(EventArg2)组成;
条件2事件片段2中包含Golden连接词,借此将Golden连接词对应的事件关系作为未标注事件片段对的先验知识,通过后续方法进一步提高标注准确率;
条件3事件片段对中须包含能触发事件的框架语义,从而保证挖掘到的未标注样本是一个事件样本。
例1EventArg1:ThisisagreatawardhereinSweden,
EventArg2:[so]wewillrememberitallourlives.
例1为符合挖掘规则的未标注事件关系样例,该样例为一个事件关系对,且包含两个具有独立语义信息的文字片段,两者之间通过连接词“so”进行关联。图5给出挖掘到的以Golden连接词为关系类别先验知识的各事件关系类型样本分布比例。从图5中可以看出,四种事件关系类型中,Expansion与Comparison关系类型分布比例较大,而Temporal关系的分布比例较小。
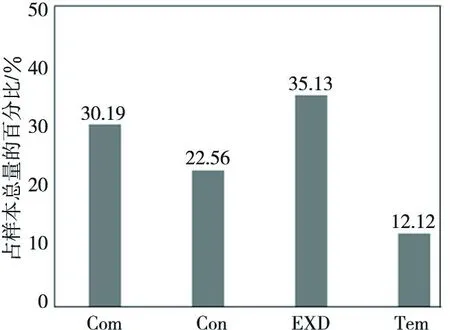
Figure 5 Distribution of four relations using Golden connections as prior knowledge图5 以Golden连接词对应的关系作为先验知识的各关系类型样本分布
4基于Tri-Training的事件关系样本扩展方法
图6给出了本文基于Tri-Training的事件关系分类方法流程图。该方法以GIGAWORD语言学资源(LDC2003T05)作为外部数据资源,从中挖掘包含Golden连接词的事件关系对,将Golden连接词对应的关系类别作为先验知识。在此基础上,抽取框架语义、事件触发词、触发词词性和事件类别四种特征生成未标注事件关系数据集。在对少量人工标注的事件关系数据集抽取相同的特征后生成已标注集。本文将其中一半的已标注集作为训练集,另一半作为测试集。然后,利用Tri-Training的方法从未标注集中选取较高置信度的事件对加入到训练集中,不断迭代训练模型,直到未标注集为空或未标注集大小不再变化为止。最后,根据学习好的模型对测试集进行分类,生成最终的分类结果。
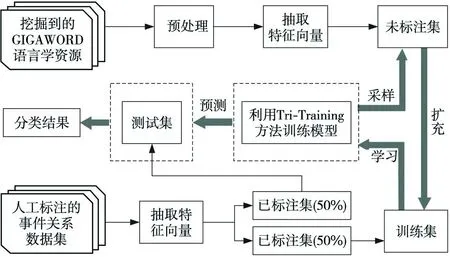
Figure 6 Flow chart of event relation classification based on the Tri-Training图6 基于Tri-Training的事件关系分类方法流程图
Tri-Training算法旨在对少量已标注数据集进行重复采样,训练三个不同的分类器X,Y,Z,通过三个分类器之间的一致性判断,对大量未标注样本数据进行分类标注。详细而言,在训练过程中,任意一个分类器(例如分类器X)所获得的新标记样本由另外两个分类器(分类器Y和分类器Z)协作判定,如果两个分类器对同一个未标记样本x给出相同的分类标签L,Y(x) = Z(x),那么就将该未标记样本加入当前分类器X中。该方法的主要优点是无需使用不同的分类方法,就可以实现大量未标注样本的标注任务[8]。由于本文的已标注事件关系集很小,可重复采样效果并不是很好。因此,本文将GoldmanS和ZhouY[9]的Co-Training思想应用到Tri-Training方法上,即在同一份已标注集上,使用三种不同算法训练三个不同类型的分类器。以下是基于Tri-Training的事件关系样本扩展流程:
初始化:
准备实验数据,将已标注的数据集按照一定比例分为训练集L和测试集T,对于未标注数据,根据连接词标上先验关系,记作U。
训练:
(1)根据训练集L分别训练三个分类器C1、C2和C3;
(2)分别用分类器C1、C2和C3对未标注数据集U进行预测,得到预测结果R1、R2和R3;
(3)对R1、R2和R3采取多数投票的方式得到带有标记的样本,若该样本类别与先验关系类别一致,则将其加入到第三个分类器的训练集中;
(4)重复(1)~(3)操作,直到U为空,或者U的大小不再变化训练停止。
值得注意的是,在第(3)步中,对于一个未标注事件关系对,在两个分类器给出的分类结果相同的情况下,还需满足与先验关系类别相同的条件,该事件对才会被加入到第三个分类器的训练集中。例如,某未标注事件对先验关系类别为Expansion,而分类器C1与C2给出的类别均为Expansion,那么该事件对就会被加入到已标注集合L中,并且将类别标记为Expansion,否则就不加入L中。
5实验与分析
5.1 实验数据集
本文选取杨雪蓉等[1]在2014年标注的事件关系语料作为已标注数据集,该语料是以FrameNet-1.5中的新闻语料作为标注集,由两名具有一定领域知识的标注人员,对每篇新闻中描述的事件以及事件关系类型进行标注,标注结果的Kappa值为0.78。该语料共包含968个事件对,各关系分布情况如表1所示。本文主要研究第一层四种关系类型,包括Comparison(Com)、Contingency(Con)、Expansion(Exp)和Temporal(Tem)。其中,本文将468个关系样例作为训练集,剩余的500个样例作为测试集,具体实验数据分布情况如表2所示。
本文并未将挖掘到的全部外部资源作为实验的未标注集,而是根据四种关系的分布比例,从各关系中随机等分布地选取一定数目的事件对,作为最终的未标注集。未标注集中各关系的分布如表2所示。所采用的评价方法是标准的准确率(Precision)、召回率(Recall)和F1值。

Table 1 Distribution of annotated relations

Table 2 Distribution of training sets and test sets
5.2 分类特征
本文选用框架语义(Frame)、事件触发词(Trigger)、触发词词性(Trigger POS)和事件类别(Event Type)作为分类特征。下面分别对这四种特征予以介绍。
(1)框架语义(Frame):即本文在3.1节中介绍的框架语义,其中具有事件属性的框架语义共540个。本文选择具有事件属性的框架语义作为特征之一。
(2)事件触发词(Trigger):事件触发词直接引发事件的产生,是决定事件类别的一个重要特征。根据ACE(Automatic Content Extraction)2005[10]中对触发词的定义,本文选择触发词作为分类特征之一。
(3)触发词词性(Trigger POS):根据事件触发词抽取对应的词性(POS),并且将其作为分类特征。
(4)事件类别(Event Type):ACE2005定义了8种事件类别以及33种子类别。本文将事件类别与事件子类别统称为事件类别,并将此作为一种分类特征。
本文通过SEMAFOR(http://www.ark.cs.cmu.edu/SEMAFOR)工具抽取框架语义特征,根据Li Q等[11]提出的基于结构化感知机制的联合事件抽取方法分析一个事件的触发词、触发词词性及事件类别。例如,对于事件片段EventArg:Fifteen people died in the traffic accident.所抽取的各特征如表3所示。
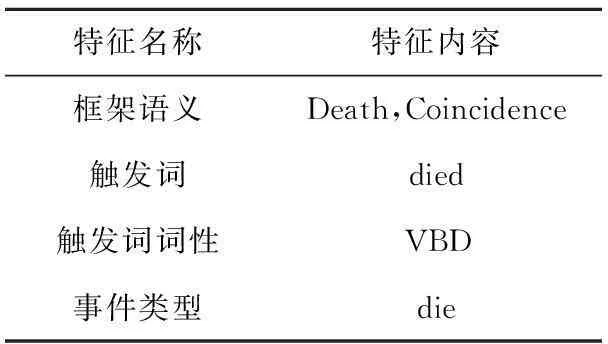
Table 3 Extracted features of EventArg
5.3 实验系统
为了验证本文所提方法的有效性,本文设计如下6个实验系统。详细介绍如下,
(1)Baseline1:不使用Golden连接词所对应的事件关系作为先验知识,按比例随机从未标注集中抽取事件对作为最终的扩充样本,训练LIBSVM(http://www.csie.ntu.edu.tw/~cjlin/libsvm)分类器对测试集进行预测。实验共进行10次,最终性能取平均值。
(2)Baseline2:以标有先验事件关系类别的未标注集作为训练语料,不使用本文提出的基于Tri-Training的事件关系分类方法,训练四个二元LIBSVM分类器,对测试集进行预测。
(3)YangSystem:重现杨雪蓉[1]的方法,即利用“框架语义对”构建事件场景,然后计算待测事件对与已挖掘到的事件对之间的事件场景相似度,将拥有最大相似度的事件对中连接词所对应的事件关系作为待测事件对的最终事件关系。
(4)SelfTraining:基于Self-Training[12]方法的对比实验。在实验过程中,本文通过融合Golden连接词对应的先验关系类别与分类器预测结果,对待标记样本的事件关系类型进行标记,进而扩充训练集。例如,在使用Self-Training方法从未标注集中选择扩充样本时,若分类器对某事件对预测的类别为Expansion,那么只有该事件对的先验关系类别为Expansion时,该事件对才会被加入到已标注集中。实验选择的分类器为LIBSVM。
(5)CoTraining:基于Co-Training[9]的半监督学习方法的对比实验。同样地,在实验过程中,本文通过融合Golden连接词对应的先验关系类别与分类器预测结果,对用以扩充训练集的待标记样本的事件关系类型进行标记。例如,在使用Co-Training方法的过程中,对于某一待标记样本,当且仅当两个分类器给出的预测结果与先验事件关系类别均相同时,该样本才会被加入对方的已标注集中。实验选择的分类器为LIBSVM和MaxEnt(http://github.com/lzhang10/maxent)。
(6)TriTraining:本文所提出的基于Tri-Training的事件关系分类方法实验系统。分类器选择为LIBSVM、MaxEnt与NaiveBayes(http://mallet.cs.umass.edu/)。
5.4 实验结果与分析
表4给出各系统分别在四种事件关系上的分类性能。从表4中可以看出,采用随机采样的Baseline1系统在四类关系上的分类性能均在50%左右,这与理论的情况也基本吻合。而Baseline2相较于Baseline1,在四大事件关系类别分类性能上都有着明显的提升,这一现象说明,利用连接词所指向的关系类别作为未标注语料的先验事件关系,有利于提高各关系的分类性能。因此,本文在使用Self-Training、Co-Training和Tri-Training三种半监督学习方法的实验中,均以Golden连接词对应的事件关系作为该事件对的先验关系类别。
实验结果表明,杨雪蓉等[1]所提出的方法在Expansion关系上达到较好的性能(60.74%),然而在其他三种事件关系上的结果都不是很理想。原因在于,杨雪蓉等[1]所采用的方法是通过计算事件场景的相似度,找出包含连接词的未标注样本中与待测事件对最相似的事件对,以该事件对中连接词所属的关系类别作为该待测事件对的事件关系类别。但是,这种通过计算相似度的方法,不仅要求语料规模足够大,而且,直接将Golden连接词所对应的事件关系作为最终的关系类别很难保证准确性。
本文采用Self-Training和Co-Training方法的两个对比实验在事件关系的分类任务上相比于Baseline2都有着很好的分类性能提升,说明将半监督学习方法运用到事件关系分类任务中,对提升分类性能有着明显的作用。本文提出的基于Tri-Training的事件关系分类方法,在四大类事件关系上均获得了不同程度的性能提升。图7显示了Tri-Training方法在各事件关系上的学习曲线,可以发现随着迭代次数的增加,F1值呈总体上升趋势,并最终达到稳定。由于迭代过程中会引入噪音,因此F1值有一定的波动。

Figure 7 Learning curves of Tri-Training in four relations图7 Tri-Training方法在四种事件关系上的学习曲线
对比Baseline2,TriTraining系统在这四种事件关系分类性能上分别提高了16.08%、6.12%、0.74%和5.07%,而且相比于SelfTraining与CoTraining,该系统在Comparison、Contingency和Temporal三个关系的分类性能上分别提高了12.33%、5.17%和1.56%,与7.84%、4.73%和4.17%,均达到最高的F1值。从表5也可以看出,Tri-Training方法在四种关系上的综合分类性能也是最高的,F1值为64.36%。这充分说明了本文将Tri-Training方法与Golden连接词所对应的先验关系类别相结合来辅助事件关系分类的合理性与有效性。
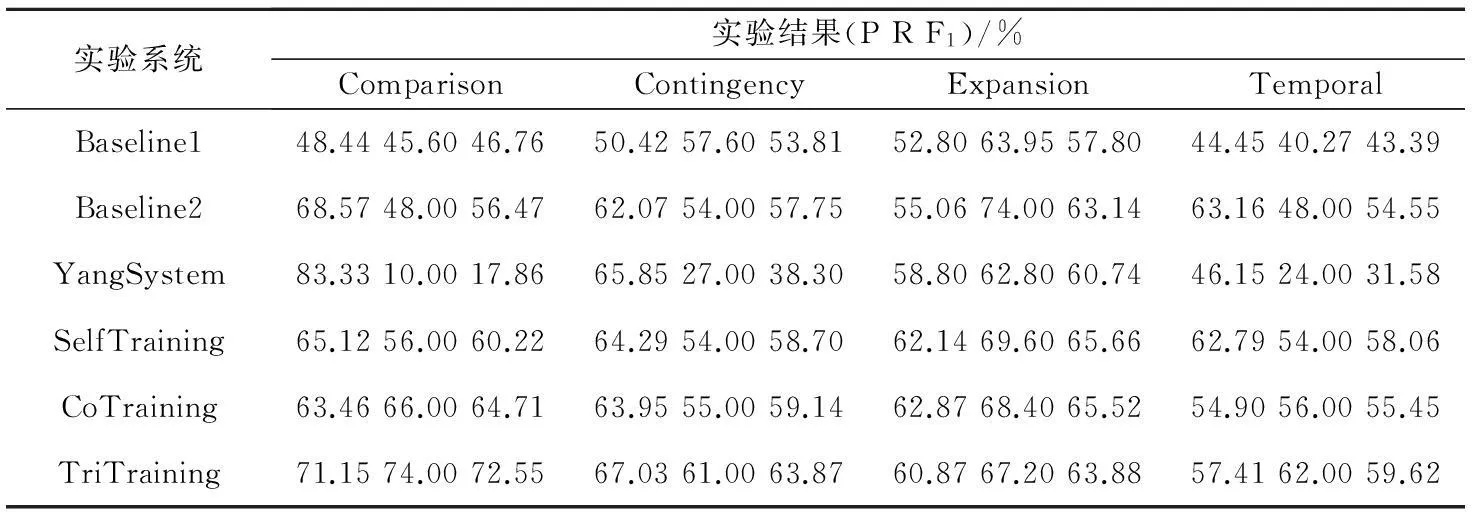
Table 4 Classification performance of each method in four relations

Table 5 Comprehensive performance of each method
6结束语
本文主要研究基于Tri-Training的半监督学习方法在事件关系分类任务中的应用。该方法针对事件关系分类任务中训练语料不足的现象,利用Tri-Training方法在少量已有人工标注的事件关系数据集上训练三个不同的分类器,然后从挖掘到的包含Golden连接词的大量未标注数据集中,通过简单投票的方式对训练语料进行扩充,继而提高事件关系分类性能。由实验结果可以看出,相比于其他几种方法,基于Tri-Training的事件关系分类方法,在各事件关系分类性能上均有不同程度的提高。该方法在四种关系上的综合分类性能也达到了最高的F1值,为64.36%。这就说明,在事件关系标注语料很少的情况下,使用基于Tri-Training的半监督学习的方法扩充事件关系训练语料能够有效地提高事件关系分类的性能。在下一步工作中,我们将尝试使用更多的分类特征,如事件上下文和词典信息等特征,以此进一步提高事件关系分类性能。
参考文献:附中文
[1]Yang X R, Hong Y, Chen Y D, et al.Detecting event relation through cross-scenario Inference [J].Journal of Chinese information Processing,2014,28(5):206-214.(in Chinese)
[2]Fillmore C J,Johnson C R,Petruck M R L.Background to framenet[J].International Journal of Lexicography,2003,16(3):235-250.
[3]Hashimoto C,Torisawa K,Kloetzer J,et al.Toward future scenario generation:Extracting event causality exploiting semantic relation,context,and association features[C]∥Proc of the 52nd Annual Meeting of the Association for Computational Linguistics,Association for Computational Linguistics,2014:1.
[4]Chklovski T,Pantel P.Global path-based refinement of noisy graphs applied to verb semantics[C]∥Natural Language Processing-IJCNLP 2005,2005:792-803.
[5]Pantel P,Pennacchiotti M.Espresso:Leveraging generic patterns for automatically harvesting semantic relations[C]∥Proc of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics.Association for Computational Linguistics,2006:113-120.
[6]Harris Z S.Mathematical structures of language[M].New York:Interscience Publishers John Wiley & Sons,1968.
[7]Lin D,Pantel P.DIRT@ SBT@ discovery of inference rules from text[C]∥Proc of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2001:323-328.
[8]Zhou Z H,Li M.Tri-training:Exploiting unlabeled data using three classifiers[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(11):1529-1541.
[9]Goldman S,Zhou Y.Enhancing supervised learning with unlabeled data[C]∥Proc of ICML,2000:327-334.
[10]Linguistic Data Consortium.ACE (Automatic Content Extraction) Chinese annotation guidelines for events[EB/OL].[2009-09-08].http://www.ldc.upenn.edu/Projects/ACE.
[11]Li Q,Ji H,Huang L.Joint event extraction via structured prediction with global features[C]∥Proc of the 51st Annual Meeting of the Association for Computational Linguistics,2013:73-82.
[12]Zhu X.Semi-supervised learning literature survey[R].Technical Report 1530. Madison:Computer Sciences, Univerity of Wisconsinnadison,2005.
[1]杨雪蓉,洪宇,陈亚东,等.基于跨场景推理的事件关系检测方法[J].中文信息学报,2014,28(5):206-214.

丁思远(1992-),男,江苏滨海人,硕士生,CCF会员(E200040583G),研究方向为事件抽取和事件关系分类。E-mail:dsy_ever@hotmail.com
DING Si-yuan,born in 1992,MS candidate,CCF member(E200040583G),his research interests include event extraction, and event relation classification.

洪宇(1978-),男,黑龙江哈尔滨人,博士,副教授,CCF会员(E200011434M),研究方向为信息检索、话题检测与跟踪和篇章分析。E-mail:tianxianer@gmail.com
HONG Yu,born in 1978,PhD,associate professor,CCF member(E200011434M),his research interests include personal information retrieval,topic detection and tracking, and discourse analysis.
作者简介:
