面向分布式流体系结构的多副本积极容错技术*
2016-01-26李鑫,林宇斐,郭晓威
面向分布式流体系结构的多副本积极容错技术*
通信地址:410073 湖南省长沙市国防科学技术大学高性能计算国家重点实验室Address:The State Key Laboratory of High Performance Computing,National University of Defense Technology,Changsha 410073,Hunan,P.R.China
李鑫1,3,4,林宇斐2,郭晓威1
(1.国防科学技术大学高性能计算国家重点实验室,湖南 长沙 410073;2.国防科学技术大学研究生院,湖南 长沙 410073;
3.解放军理工大学,江苏 南京 210007;4.总参第六十三研究所,江苏 南京 210007)
摘要:随着互联网环境下计算系统规模的不断扩大,分布式流体系结构的可靠性问题面临着严峻的挑战。以多模冗余容错技术为基础,针对软错误提出了一种面向分布式流体系结构的多副本积极容错技术TREFT,利用三个程序副本进行高效的检错与纠错。在分布式流体系结构原型系统上的实验结果表明,该技术能有效提高系统的可靠性,具有较低的容错成本,平均增加10.77%的容错开销。
关键词:分布式流体系结构;容错技术;三模冗余
1引言
互联网环境资源规模巨大,通信环境复杂,各种网络资源呈现异构性与动态性。随着商用器件的广泛使用、计算系统规模的持续扩大与异构系统的兴起流行,互联网分布式计算模型的可靠性问题面临着严峻挑战。作者近期提出了一种新型的分布式流体系结构DSA(Distributed Stream Architecture),在互联网环境下提供高效的大数据计算环境,其可靠性面临着同样的问题。
近年来,面向互联网应用的数据中心的计算系统规模在持续增加,如2015年6月TOP500前10名系统的平均处理器核数已经突破83.7万颗[1],并继续向百万颗迈进。随着系统计算部件数目的增加,计算系统的可靠性将会持续下降,如IBM ASCI White平均无故障时间仅为40个小时[2],Google拥有的8 000个节点的集群系统平均36个小时发生一个故障[3],超过10万个处理器核的IBM Blue Gene/L的平均无故障时间预测可能只有几十分钟[4]。据美国Los Alamos国家实验室10年超级计算机系统的统计数据显示,高性能计算机单个节点的平均故障率为1/(512 h)[5,6],这意味着128个节点系统的平均无故障时间仅为4小时。
同时,采用异构系统加速应用程序已成为一种新型的计算模式,具有较高的效能比,如CPU-GPU与CPU-MIC典型系统,已经成功应用在Tianhe-1A[7,8]与Tianhe-2等系统中。然而,作为异构系统的加速部件,其强大的计算能力来源于更高的芯片集成度与简单的控制逻辑,目前硬件尚未提供强大的容错支持,显然会带来严重的可靠性问题[9,10]。例如,60个NVIDIA GeForce 8800 GTS GPU同时连续工作72小时就会发生7个GPU故障,同时GPU故障都发生在存储器,且不易被感知[11]。
因此,对于在互联网上运行长达几个小时甚至几天的应用来说,保证程序在分布式环境下的可靠运行显得尤为重要,如蛋白质折叠应用计算就需要连续运算几个月时间[12]。分布式系统容错技术主要基于空间冗余、时间冗余或数据世系等方法来实现。空间冗余进一步可划分为硬件冗余、软件冗余、数据冗余等。Hadoop中的分布式文件系统HDFS中采用的是多副本数据的软件冗余方法,以保证在大规模廉价PC服务器上提供可靠的数据访问能力。已有研究[13]表明,多副本容错技术是一种针对大规模计算的有效手段。Google提出的数据纠删码技术就是一种典型的数据冗余方法[14]。时间冗余方式主要包括回滚恢复技术与并行复算技术等,传统高性能计算领域经常采用基于检查点的回滚恢复技术来处理故障。数据世系方法通过记录数据之间的关系与操作,一旦发生错误就从最近数据记录点开始恢复计算,具有较高的容错效率,已经被应用在Spark[15]等大数据技术中。
本文基于分布式流体系结构的特点,针对节点故障引起的不易察觉的软错误,设计了一种多副本积极容错技术,将需要进行检错的程序区域标识为容错程序段,通过三个程序副本比较其数据变量以发现可能的错误。本文的主要创新工作在第3节与第4节,其中,第2节概述了分布式流体系结构[16],对节点发生瞬时故障引起的软错误进行了分析;第3节详细说明了多副本积极容错技术;第4节描述了实验方法与结果分析;第5节是本文总结与研究展望。
2分布式流体系结构概述及其故障分析
2.1 分布式流体系结构概述
分布式流体系结构在分布式环境下扩展了传统流体系结构中的概念,其中,计算核心(Kernel)是指可用的软硬件对象,流或数据流(Stream)是指计算数据与控制状态数据。流包括计算数据流和控制数据流,计算核心根据其功能分为六种:软计算核心SK(Soft Kernel)、硬计算核心HK(Hard Kernel)、应用计算核心AK(Application Kernel)、客户管理计算核心CMK(Client Management Kernel)、资源管理计算核心RMK(Resource Management Kernel)与服务管理计算核心SMK(Service Management Kernel)[16]。其中,SK与HK分别封装了软件资源与硬件资源信息,AK封装了主程序相关信息,负责资源申请与管理程序运行过程,CMK负责提供用户服务接口,RMK负责命令解释与任务具体执行,SMK维护服务、计算核心等元信息,提供资源调度与应用生命周期管理等[17]。
如图1所示,在分布式流体系结构上运行一个应用程序通常需要1个host节点与多个device节点。
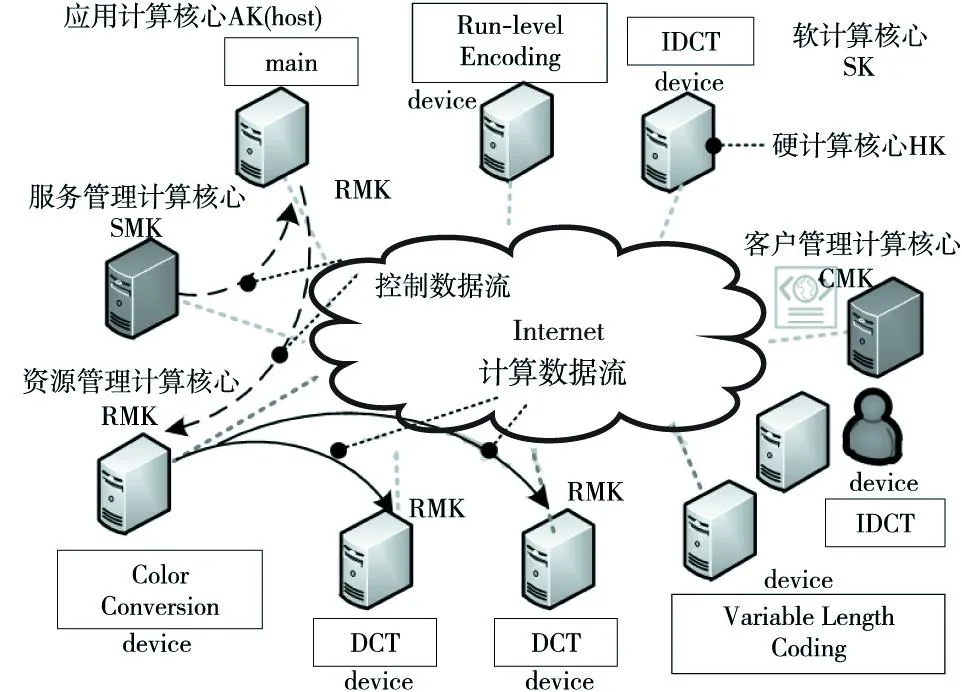
Figure 1 Basic concepts of the distributed stream architecture图1 分布式流体系结构基本概念
host节点上RMK会启动一个线程执行主程序(AK)以管理任务执行流程。AK会根据编译指导命令将计算核心任务划分成多个子任务并行执行。同时,AK负责向SMK申请软硬件资源,申请成功后通知目的节点下载代码与数据,并在计算完毕后更新计算状态,以保证全局信息的一致性。AK如此推进计算过程直到所有计算核心执行完毕。
2.2 分布式流体系结构故障分析
在分布式流体系结构中,按照错误在程序执行中产生的原因可以分为原生节点错误与继生节点错误两类:
(1)原生节点错误:由于节点硬件故障等直接造成的错误,使得系统存储数据的数值与正确值之间出现了影响结果正确性的偏差。
(2)继生节点错误:由于与其他错误数据之间存在数据依赖关系而随着程序执行传播产生的错误,造成系统存储数据的数值与正确值之间出现了影响结果正确性的偏差。
分布式流体系结构上运行的Kernel函数是具有数据并行性的计算程序,通常以线程级并行方式或任务级并行方式运行在远程节点上,本文将Kernel函数调用语句称为并行计算核心(并行Kernel)。同时,主程序串行运行在本地节点上,本文将非Kernel函数调用的执行语句统称为串行计算核心(串行Kernel)。因此,这些计算核心错误间的传播关系如图2所示。
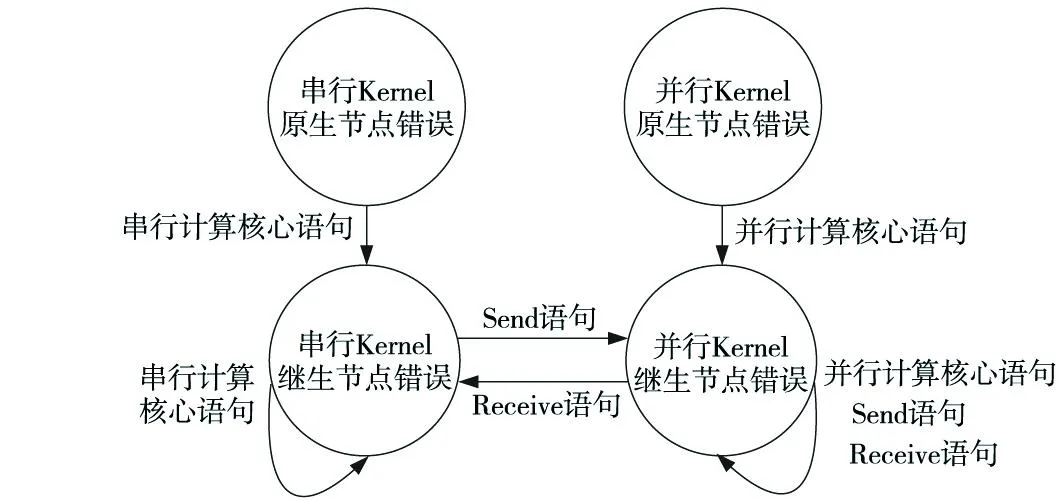
Figure 2 Serial Kernel errors and parallel Kernel errors图2 串行Kernel错误与并行Kernel错误
可见,分布式流计算程序节点错误的传播途径主要是通过程序语句执行在节点内传播或通信语句在节点间传播。本文假设主程序运行的节点是可靠的,即不考虑串行Kernel原生节点错误,只关心并行Kernel相关错误导致的主程序失效问题。
本文提出的容错技术是在系统发生故障的情况下,仍然可以保证程序的正确运行,主要针对节点硬件故障引起的不易察觉的软错误(Soft Error),在错误传播期间对其进行检测与恢复,以防止系统出现失效,其故障模型如图3所示。该类软错误是指运行并行Kernel的节点发生瞬时故障所引起的程序员不易察觉的软错误,不会立即导致程序失效,而是通过程序语句执行传播影响其他正常数据而出现新的错误,并最终在主程序中继续传播而导致其失效。这类软错误由于不易察觉,检错比较困难,本文考虑基于空间冗余方式对比数据以检错与纠错。

Figure 3 Fault model of the instantaneous fault occurred in the parallel Kernel nodes图3 并行Kernel节点发生瞬时故障的故障模型
3面向分布式流体系结构的多副本积极容错技术:TREFT
多副本积极容错技术是一种主动的空间冗余容错方法,又称为多模冗余NMR(N-Modular Redundancy)方法,即多个相同程序副本以空间并行的方式同时执行,当程序执行遇到同步点时,程序会主动比较多个副本数据进行检错,遵循“用三取二”方法选择多数相同的结果,并对错误的数据进行纠错,以防止错误进一步传播。目前有研究[17]表明,当单个副本程序的可靠性达到80%时,三模冗余容错方法的系统可靠性就可以达到90%以上。考虑到容错成本开销以及容错技术实现的复杂性,本文多副本容错技术采用三模冗余积极容错技术TREFT(Triple modular Redundancy Eager Fault-tolerant Technique)。
TREFT通过比较三个程序副本活跃变量数据的一致性,从而有效检测出故障引起或正在传播的不易被发现的软错误。假设错误是随机出现的,若计算核心重新执行时,则本文认为出现相同错误的概率很低,一般可以获得正确的输出数据。由于两个以上独立程序副本运行同时出错的概率非常小,因此,本文对于两个(含)以上副本同时出现错误的情况不予考虑。
3.1 TREFT基本概念
本文中TREFT进行容错的对象是Kernel函数的输出数据,因此,需要对包含Kernel函数的程序段标识成容错程序段,以便于进行检错与纠错处理,其基本概念定义如下:
定义1
(1)起始同步点:标记容错程序范围的起始位置;
(2)比较同步点:标记容错程序范围的结束位置,同时也是执行同步操作的位置,在该位置上将数据发送到其他副本节点上进行数据比较。
定义2
(1)容错程序段:主程序中需要进行容错的程序语句序列,一般使用起始同步点与比较同步点标记容错程序的范围,包含多个串行语句与Kernel函数调用语句。一个Kernel函数调用语句就可以构成一个基本的容错程序段。
(2)非容错程序段:主程序中容错程序段之间的程序语句序列,执行时不会产生本节定义的软错误,因此不需要进行容错处理。
(3)容错程序段活跃变量:是指由容错程序段包含的Kernel函数调用语句中进行定值操作的流变量,其在后面的程序执行时可能被引用,若这些变量发生错误而没有进行纠错,则会形成错误的传播。
如图4所示,程序员或编译器需要在容错程序段的前后分别插入起始同步点与比较同步点进行标记。容错程序段可以将错误传播的范围控制在一个有限的程序区域内,使得错误不会传播出所在的容错程序段而影响其他部分。即使出现软错误,程序只需要重新纠正错误的活跃变量,而不需要重新执行程序,从而降低容错开销。

Figure 4 Schematic diagram of the related concepts of the fault-tolerant program section in the TREFT图4 TREFT容错程序段相关概念示意图
TREFT中各节点的表决器模块使用“用三取二”多数判决逻辑准则对错误数据进行判定:
(1)正常情况下三个副本数据都是相同的,则使用各自程序结果作为正确输出;
(2)若任何一个程序副本出错,其输出不同于其他两个程序副本,则表决器采用多数程序副本的数据结果作为正确结果进行故障恢复,即对该错误活跃变量直接进行赋值,防止错误进一步传播。
3.2 TREFT容错程序段设置规则
容错程序段的设置是TREFT同步技术的关键问题,会影响程序容错粒度与容错开销,根据分布式流应用的程序语句类型的特点,TREFT中包括五个基本设置规则:
规则1Write操作之前必须设置容错程序段以保证其输入变量的正确性。因为Write操作在主程序中接收错误数据,为了主程序不失效,所以在数据传回主程序之前进行容错,Write操作涉及的数据也属于活跃变量,该规则保证错误不会继续在主程序中传播。
规则2所有Kernel函数调用语句都必须处于容错程序段中。显然,本节假设的错误都发生在运行并行Kernel的节点上,即对应于主程序中Kernel函数执行过程,该规则保证TREFT对所有可能发生的并行Kernel原生错误都进行了容错处理。
规则3每个Kernel并行执行模式[16]中的所有Kernel函数调用语句必须处于同一个容错程序段中。由于这些Kernel函数调用语句都是并行执行的,即以空间并行或时间并行的方式运行多个相邻的Kernel,所以无法确定它们之间的真实执行顺序,而该规则保证了其并行执行语义。
规则4采用数据流Eager传输策略[16]而提前传输的数据必须在数据原本所在的容错程序段内进行检错与纠错,如果提前传输的数据发生错误,则需要进行重传,从而保证了后继Kernel计算的正确性。
规则5设置合理容错粒度的容错程序段。若以主程序中的每个计算核心为容错粒度,容错粒度过小,同步点设置过密,就会引发频繁的检错纠错操作,数据传输操作过多,致使容错执行效率不高,因此,应该尽可能合并可以一次容错的语句。
3.3 TREFT容错机制实现方法
本文在分布式流体系结构编程模型中设计了TREFT容错起始同步点与比较同步点的语法,即
#pragma brs treftsyn startProgramCode
#pragma brs treftsyn finish
该编译指导语句使用在需要进行容错的程序段开始处和结尾处,其语义是指该范围内的语句序列是容错程序段,当程序运行到比较同步点时,需要执行TREFT检错与纠错流程。编译器对所有人工标记的容错程序段进行标识,生成容错程序段索引表以及包含的计算核心与对应的输出活跃变量,并为每个容错程序段创建一个事件消息队列用于接收相关容错处理的消息。
如图5所示案例,存在三个程序副本TR1、TR2与TR3,例如每个程序副本的host节点上都创建了1个执行线程(Executor Thread)执行主程序(AK代码),由其进一步创建1个工作线程(Worker Thread)与1个子任务工作线程(Subworker Thread)管理任务的执行过程,同时在1个device节点上创建了执行线程用于执行计算核心代码(SK)。其中,host节点上:
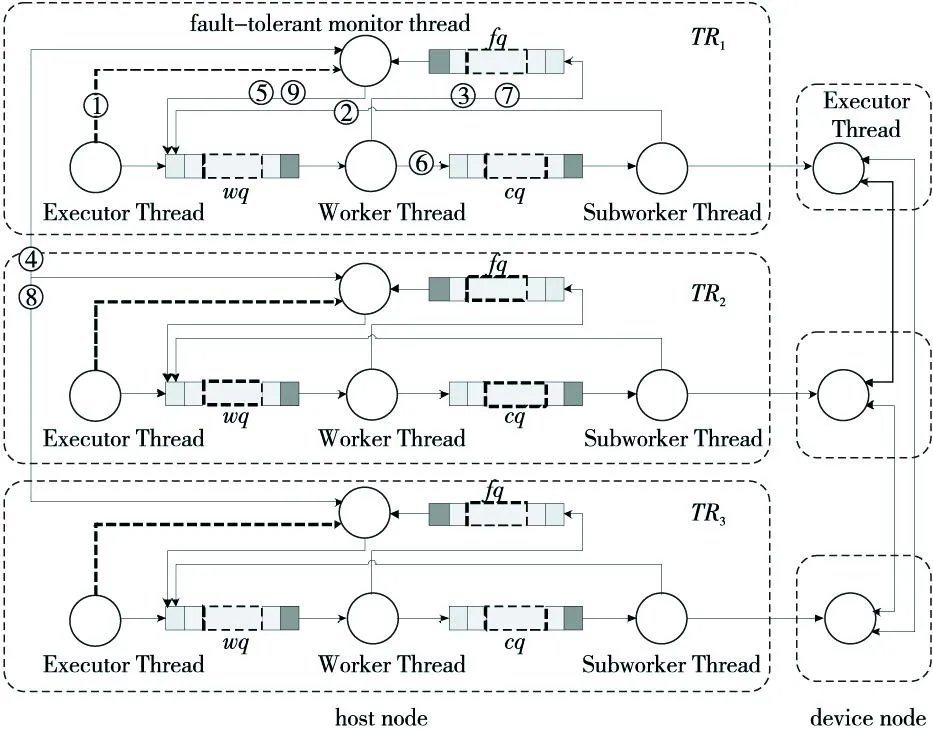
Figure 5 Schematic diagram of the runtime that supports the TREFT fault-tolerant technique图5 支持TREFT容错技术的运行时结构示意图
(1)Executor Thread:运行主程序(AK代码)以管理整个程序的执行过程,并依次按照指定的语义执行Kernel计算任务;
(2)Worker Thread:执行对Kenrel计算任务的相关操作,包括请求下载与执行代码等,负责监控任务状态与更新全局信息列表,以保证数据一致性;
(3)Subworker Thread:负责执行子任务的所有相关操作以及状态监控,当程序划分为多个任务执行时,编译器运行时中会创建相应数目的线程来维持子任务的运行;
(4)device节点上Executor Thread:负责直接执行计算核心的子任务,包括下载数据与代码、启动执行子任务等。
不同工作线程之间是通过事件消息队列来传递信息的,工作线程(Worker Thread)与子任务工作线程(Subworker Thread)的事件消息队列分别记作wq与cq。如图5所示,为了支持TREFT容错机制,分布式流体系结构的运行时组织结构添加了容错监控线程(Fault-Tolerant Monitor Thread)与相应的事件消息队列(Fault-Tolerant Queue),其中:
(1)Fault-Tolerant Monitor Thread:是主程序执行线程创建的TREFT容错监控工作线程,负责与其他副本的容错监控线程同步、请求交换数据、请求检错与纠错等。当三个副本的容错监控线程互相同步且都准备好时,则本地容错监控线程将请求检错与纠错的事件操作压入对应的工作线程事件消息队列进行处理,并由子任务工作线程负责执行数据交换与检错纠错任务。
(2)Fault-Tolerant Queue:用于接收其他副本容错监控线程与计算核心工作线程反馈的消息,并进一步交给容错监控线程处理,并记为fq。
本文采用一种线程操作表的伪代码方法来描述TREFT实现与执行细节,如表2所示。假设存在计算核心K1划分为3个子任务K1i执行,1≤i≤3且i为正整数,使用K1i.OP表示计算核心子任务K1i执行操作OP,用ex(OP)表示指定线程执行操作OP,wq.p(OP)表示事件消息队列wq压入操作OP并进行处理。

Table 1 Operation list of Kernel and Stream in the TREFT
如表2所示,存在两个串行执行的计算核心K1与K2,并对其进行检错与纠错,KR表示容错监控线程,最右边一列表示各线程事件执行的大致顺序。TREFT容错机制中检错与纠错过程是一个阻塞事件过程,只有结束后才能继续执行程序,整个TREFT容错机制的主要运行流程如下:
(1) 当程序执行到标记同步点时,三个副本程序创建各自的容错监控线程,同时传递容错程序段索引号给该线程,以便于容错监控线程可以在容错程序段索引表里检索相应Kernel的活跃变量信息,同时监视容错程序段中Kernel任务的执行状态,如图5和表2中①所示。
(2) 当程序执行到比较同步点时,由于在TREFT容错模式下,所有计算核心执行完毕后阻塞等待并不立即退出,而是将计算任务状态通知给工作线程与容错监控线程,如图5和表2中②与③所示。
(3) 当监测到容错程序段中所有Kernel计算完毕时,容错监控线程向其他两个副本的容错监控线程发送初始化同步操作OPRS,得到两者回复才可以确认三个副本都已经到达同步点。由于同一时刻只有一个容错程序段处于运行状态,因此,通过容错程序段索引号保证只有一个容错程序段进行处理。接着,三个副本之间同步需要检错的资源信息,包括其他两个副本程序活跃变量信息所在的节点信息,并将对应信息更新到各自的全局信息列表中,如图5和表2中④所示。

Table 2 Thread operations in the TREFT fault-tolerant technique
(4) 当数据同步结束后,容错监控线程将数据检错纠错操作OPTR压入对应的计算核心Kernel工作线程的事件消息队列进行处理,如图5和表2中⑤所示。
(5) 对应Kernel工作线程接收OPTR操作后,通过子任务工作线程请求其他两个副本程序传输活跃变量数据到指定副本程序绑定的节点上,由该节点上的RMK启动数据检错与纠错任务,并在执行结束后通知子任务工作线程,如图5和表2中⑥所示。
(6) 子任务工作线程将容错操作结果OPTF反馈给工作线程,当所有子任务完成后,工作线程通知容错监控线程当前计算核心已经完成了容错操作OPTF,如图5和表2中⑦所示。当容错程序段中所有Kernel都完成容错操作时,容错监控线程再一次与其他两个副本执行完成容错的同步操作OPRFS,如图5和表2中⑧所示,并通知所有Kernel计算完成结束工作线程操作OPET,如图5和表2中⑨所示。
(7) 执行线程等待容错程序段所有计算核心结束,并在最后阻塞等待容错监控线程结束,以确保程序执行语义的正确性,如表2中⑩所示。
4实验验证
4.1 实验方法
整个实验评估是在由20个节点组成的互连网络上完成的,每个节点由一个多核CPU组成,实验平台参数如表3所示。分布式流体系结构实验原型系统由C/C++语言实现,主要包括编译器以及资源管理等,可以支持多种计算资源与编程语言,包括GPU(Brook+、OpenCL、CUDA等)、CPU(C/C++等)等,支持多个Kernel并行执行,能有效开发程序的线程级并行性与任务级并行性。
实验测试用例采用NASGridBenchmarks(NGB)中的HelicalChain(HC)、VisualizationPipe(VP)与MixedBag(MB)三个用例,如图6所示,测试用例都是由单个NPB实例求解器(BT,SP,LU,MG或FT)组成的串行流处理模式,MF过滤器用于转换不同实例求解器之间的数据,实验测试用例选定反复执行2次流程。本文将实例求解器与对应的过滤器封装为一个计算核心,所有计算核心都按照顺序依次执行,并移植到分布式流体系结构上,并通过模拟的方法产生原始输入数据,如图6所示执行流程。

Table 3 Parameter list of the experimental platform

Figure 6 Schematic diagram of the computing process in test case VP,MB and HC图6 实验测试用例VP、MB与HC的计算流程示意图
本文实验中国际互联网模拟环境的延时采用Internet Traffic Report网站在2015年统计的五大洲延迟时间平均值100 ms,国际互联网带宽则采用Speedtest在2013年180多个国家与地区测量带宽平均值13.98 Mbps,其余时间都采用实际测试的时间,所有测试用例采用A与B两个规模级别的测试集。三个测试用例的控制依赖关系较为简单,因此,实验中TREFT版本将程序标识成一个粒度较大的TREFT容错程序段。本文设计了两个对比实验版本TREFT-E1与TREFT-E2,其中TREFT-E1是在TREFT容错程序版本的基础上分别采用了数据流Eager传输优化策略[16],可以主动传输数据,考察优化技术对TREFT容错技术的影响;TREFT-E2则以单个计算核心Kernel为TREFT容错程序段,其每个容错程序段的容错粒度较小,考察不同容错粒度下对容错开销的影响。
4.2 实验结果
如图7所示,采用TREFT容错技术后各测试用例平均增加10.77%的容错开销,并呈现出VP、MB与HC增加容错开销依次减小的趋势,其中,VP.B(20.03%)、VP.A(10.20%)与MB.B(10.12%)增加的容错开销均在10%以上。这是由于VP和MB测试用例中FT计算核心的活跃变量数据量较大,由于模拟的互联网带宽受限,所以造成通信时间成为TREFT容错同步过程的瓶颈。同时,HC测试用例中LU计算核心活跃变量的数据量较小,通信时间占据其整个执行时间比例开销较小,从而使得增加的容错开销较小。
当测试用例采用数据流Eager传输优化策略时,数据会尽可能主动传输到目标节点上,因此可以减少程序执行时间。如图7所示,TREFT-E1版本通常增加的容错开销较小(平均13.05%左右),比原始TREFT版本平均增加了2.28%的开销比例。VP.B(25.6%)是容错开销比例较大的测试用例。在采用性能优化技术后,VP和MB中容错同步的数据通信开销与检测开销没变,而程序整体执行时间减少,因此造成容错开销所占比例进一步增加。HC容错开销比例没有显著增加,这是由于HC中各个计算核心串行连续执行,采用数据流Eager传输策略后整体执行时间没有显著减少,因此,HC增加的容错开销不显著。
由此可见,TREFT容错技术可以有效支持数据流Eager传输优化技术,且采用后增加的容错开销(2.28%)比例较小,具有较高的容错效率。
TREFT-E2版本采用了计算核心级别的细粒度TREFT容错方法,如图7所示,各测试用例的容错开销平均增加52.77%,大约是正常TREFT增加开销的5倍,其中VP.A(69.12%)、VP.B(67.17%)、MB.A(54.39%)与HC.B(50.31%)增加的容错开销超过了50%。这是由于这些测试用例活跃变量的数据量较大,容易使得数据传输与检错成为容错同步过程的瓶颈。同时,HC.A(36.53%)与MB.B(38.09%)测试用例增加的容错开销相对较小,HC.A中活跃变量数据总和较小,容错同步需要的数据传输与比较时间较短,而MB.B的执行时间较长,因此使得其增加的容错开销比例没有其他情况高。

Figure 7 Percentage of the fault-tolerant overhead increased after using the TREFT in test case VP,MB and HC图7 测试用例在使用TREFT后的容错开销增加百分比
由此可见,当TREFT容错粒度过小时,容错操作频繁会造成较低的容错效率,当程序变得更加复杂时,随着TREFT容错程序段数目的增加,需要进行容错同步的数据量逐渐增大,这种趋势会愈加明显。
综上所述,TREFT容错技术具有较低的容错开销和良好的容错特性,可以有效提高分布式流体系结构下应用程序执行的可靠性。
5结束语
随着计算系统规模的持续扩大,分布式流体系结构中的可靠性问题面临着非常严峻的挑战。本文以多模冗余容错技术为基础,提出了一种面向分布式流体系结构的多副本积极容错技术TREFT,在分布式流体系结构原型系统上的实验结果表明,该技术能有效提高系统的可靠性,且具有较低的容错开销。
未来的研究将在已有研究基础上,通过数据流方法分析分布式流体系结构中的错误传播行为特点,构建数据流方程来刻画错误传播行为,以指导分布式流体系结构的容错技术研究,设计高效的容错算法,尽可能比较最小的错误数据集合,从而进一步减少容错开销。
参考文献:附中文
[1]Meuer H,Simon H,Strohmaier E,et al. TOP500 supercomputer sites[EB/OL].[2015-09-01]. http://www.top500.org.
[2]Lu C-D. Scalable diskless checkpointing for large parallel systems[D]. Urbana-Champaign:University of Illinois,2005.
[3]Bosilca G,Bouteiller A,Cappello F,et al. MPICH-V:Toward a scalable fault tolerant MPI for volatile nodes[C]∥Proc of SC’02,2002:1-18.
[4]Engelmann C,Geist A. A diskless checkpointing algorithm for super-scale architectures applied to the fast Fourier transform[C]∥Proc of the 1st International Workshop on Challenges of Large Applications in Distributed Environments,2003:47-52.
[5]Los Alamos National Laboratory. Operational data to support and enable computer science research[EB/OL]. [2015-09-01]. http://institute.lanl.gov/data/lanldata.shtml.
[6]Wu M,Sun X-H,Jin H. Performance under failures of high-end computing[C]∥Proc of the 2007 ACM/IEEE Conference on Supercomputing,2007:1-11.
[7]Yang X,Liao X,Xu W,et al. TH-1:China’s first petaflop supercomputer[J]. Frontiers of Computer Science in China,2010,4(4):445-455.
[8]Yang X-J,Liao X-K,Lu K,et al. The TianHe-1A supercomputer:Its hardware and software[J]. Journal of Computer Science and Technology,2011,26(3):344-351.
[9]Borucki L,Schindlbeck G,Slayman C. Comparison of accelerated DRAM soft error rates measured at component and system level[C]∥Proc of the 2008 IEEE International Reliability Physics Symposium,2008:482-487.
[10]Schroeder B,Pinheiro E,Weber W-D. DRAM errors in the wild:A large-scale field study[C]∥Proc of the 11th International Joint Conference on Measurement and Modeling of Computer Systems,2009:193-204.
[11]Maruyama N,Nukada A,Matsuoka S. Software-based ECC for GPUS[C]∥Proc of the 2009 Symposium on Application Accelerators in High Performance Computing (SAAHPC’09),2009:1.
[12]Bronevetsky G,Marques D,Pingali K,et al. Automated application-level checkpointing of MPI programs[C]∥Proc of the Symposium on Principles and Practice of Parallel Programming (PPoPP 2003),2003:84-94.
[13]Wang Z Y,Yang X J,Zhou Y.Scalable triple modular redundancy fault tolerance mechanism for MPI-oriented large scale parallel computing[J]. Journal of Software,2012,23(4):1022-1035. (in Chinese)
[14]Plank J S. A tutorial on reed-solomon coding for fault-tolerance in RAID-like systems[J]. Software-Practice & Experience,1997,27(9):995-1012.
[15]Zaharia M,Chowdhury M,Das T,et al. Resilient distributed datasets:A fault-tolerant abstraction for in-memory cluster computing [C]∥Proc of the 9th USENIX Conference on Networked Systems Design and Implementation. USENIX Association,2012:1.
[16]Li Xin,Guo Xiao-wei,Lin Yu-fei. Stream eager transmission:The performance optimization technique for the distributed stream architecture[J]. Computer Engineering & Science,2015,37(11):2035-2044.(in Chinese)
[17]Song W. Research on fault tolerance for transactional memory system[D]. Changsha:National University of Defense Technology,2011. (in Chinese)
[13]王之元,杨学军,周云. 大规模MPI并行计算的可扩展三模冗余容错机制[J]. 软件学报,2012,23(4):1022-1035.
[16]李鑫,郭晓威,林宇斐. 数据流Eager传输:一种分布式流体系结构中的性能优化技术[J]. 计算机工程与科学,2015,37(11):2035-2044.
[17]宋伟. 面向事务存储系统的容错技术研究[D]. 长沙:国防科学技术大学,2011.

李鑫(1984-),男,安徽安庆人,博士生,研究方向为高性能计算和大数据。E-mail:xinli@nudt.edu.cn
LI Xin,born in 1984,PhD candidate,his research interests include distributed computing, and big data.

林宇斐(1985-),女,江西南昌人,博士,工程师,研究方向为并行计算。E-mail:linyufei@nudt.edu.cn
LIN Yu-fei,born in 1985,PhD,engineer,her research interest includes parallel computing.

郭晓威(1986-),男,湖南益阳人,博士生,研究方向为并行计算与数值模拟。E-mail:guoxiaowei@nudt.edu.cn
GUO Xiao-wei,born in 1986,PhD candidate,his research interests include parallel computing, and numerical simulation.
A triple modular eager redundancy fault-toleranttechnique for distributed stream architecture
LI Xin1,3,4,LIN Yu-fei2,GUO Xiao-wei1
(1.The State Key Laboratory of High Performance Computing,National University of Defense Technology,Changsha 410073;
2.Graduate School,National University of Defense Technology,Changsha 410073;
3.PLA University of Science and Technology,Nanjing 210007;
4.The 63rd Research Institute of PLA General Staff Headquarters,Nanjing 210007,China)
Abstract:As computing systems continue to expand in size in the Internet environment, the reliability of the distributed stream architecture is facing serious challenges. Based on the N-modular redundancy technique, we propose a triple modular eager redundancy fault-tolerant method for the distributed stream architecture (TREFT). The TREFT employs three program copies to run the error detection and error correction processes efficiently. Experimental results on a prototype system of the distributed stream architecture show that the TREFT could enhance the reliability of the system at very low cost, increasing the fault-tolerant cost by 10.77% on average.
Key words:distributed stream architecture;fault-tolerant technique;triple modular redundancy
作者简介:
doi:10.3969/j.issn.1007-130X.2015.12.007
中图分类号:TP338.8
文献标志码:A
基金项目:国家自然科学基金资助项目(61221491,61303071)
收稿日期:修回日期:2015-11-26
文章编号:1007-130X(2015)12-2233-09
