基于Spark框架的乘潮水位计算与可视化平台*
2016-01-26秦勃,朱勇,秦雪
基于Spark框架的乘潮水位计算与可视化平台*
通信地址:266100 山东省青岛市中国海洋大学信息科学与工程学院Address:College of Information Science and Engineering,Ocean University of China,Qingdao 266100,Shandong,P.R.China
秦勃1,朱勇1,秦雪2
(1.中国海洋大学信息科学与工程学院,山东 青岛 266100;2.国家海洋信息中心,天津 300171)
摘要:乘潮水位计算是海洋环境信息处理的重要组成部分,具有计算量大、计算复杂度高、计算时间长等特性。采用传统集群计算模式实现乘潮水位计算业务,存在计算成本高、计算伸缩性和交互性差的问题。针对以上问题,提出一种基于Spark框架的乘潮水位计算和可视化平台。结合对Spark任务调度算法的研究,设计和实现了一种基于节点计算能力的任务调度算法,实现了长时间序列的多任务乘潮水位数据的检索、获取、数值计算、特征可视化的并行处理,达到了海量海洋环境数据计算和可视化处理的目的。实验结果表明,提出的基于Spark的乘潮水位计算和可视化平台可以有效地提高海量乘潮水位数据的分布式并行处理的效率,为更加快速和高效的乘潮水位计算提供了一种新的方法。
关键词:Spark;乘潮水位;任务调度算法;并行处理;海洋环境信息
1引言
随着海洋经济和海洋开发在社会发展中的作用越来越大,海洋科学技术更加受到重视,数字海洋[1]项目的立项和实施,是我国海洋事业发展的一个重要体现。计算机技术的飞速发展在不断改变着海洋环境信息业务化处理的方法,各种新技术和新方法被应用到海洋信息的处理当中来。在十一五期间,数字海洋的建设已经初步搭建起基本的框架结构,相关典型应用也已经初见雏形,为十二五海洋规划的发展奠定良好的基础。十二五海洋规划纲要中指出,要进一步地加强数字海洋的建设,用数字海洋的计算结果来指导决策,建立起完善的海洋信息基础服务体系,开发和设计一系列高质量的业务化系统。
海洋环境信息数据[2]具有一系列显著的特点,数据类型是多样的,数据量巨大,具有典型的时空特性。海洋环境信息的处理主要包括海洋遥感影像处理[3]、数值模式计算[4]和海洋数据挖掘[5]。经过一段时间的发展和探索,如今已初步建立了大批海洋业务方面的应用系统。这些系统能够在一定程度上满足海洋业务处理的需求,但是随着海洋业务处理要求不断的提高,出现了越来越多的问题,比如系统资源占用率多、运行成本高、系统规划缺乏和系统维护困难等问题。基于此种现状,国家相关部门打算采用云计算的技术,对现有的海洋环境业务处理系统进行升级改造,充分利用云计算技术在数据处理和任务调度上的优势,逐步搭建起一个具有强大功能和业务处理能力的新型海洋环境信息处理平台。
乘潮水位数值计算,作为一个海洋环境信息处理的重要组成部分[6],目前大多采用FVCOM(Finite-Volume Coastal Ocean Model)数值计算模型[7],部署到高性能集群上进行计算。在研究传统业务乘潮水位业务计算模式后,本文提出并实现了云计算框架Spark下对乘潮水位计算和可视化平台,实现了对乘潮水位任务的调度控制,并将计算结果可视化呈现给用户。在提高任务调度合理性和科学性、节省乘潮水位计算时间的同时,提高了计算的可交互性、灵活性和可扩展性。
2关键技术
Spark是一个快速的、通用的、伸缩性强的数据处理平台[8],它沿用了 Hadoop MapReduce[9]优点,不同点在于 Spark程序执行过程的中间输出结果可以保存在内存中,不再需要与 HDFS(Hadoop Distribute File System)[10]进行输入输出,即 Spark是一种实现了内存计算的分布式计算框架。与MapReduce框架相比,Spark不但能够处理传统的MapReduce程序,同时也适用于需要多次操作特定数据集的应用场合。测试结果表明,Spark任务通常能够在运行速度方面高出MapReduce几倍到几十倍[11]。
Spark的核心设计思想是弹性分布式数据集—RDD(Resilient Distributed Datasets)[12]。它是MapReduce模型的扩展和延伸,实现了高效的数据共享。RDD除了支持工作集的应用,还具有数据流模型的特点,可以实现计算的伸缩性,对数据进行感知调度,并且实现了自动容错。RDD完整包装了Spark应用程序数据的输入和数据的处理,类似于面向对象编程中类(Class)的概念。RDD的操作分成两种,一种是Transformation,另一种是Action。Transformation是领取任务的过程,Action是任务真正被触发执行的过程。Action是以job的形式提交给计算引擎,由计算引擎将其转换成多个task,分发到各个计算节点上,进行逻辑处理。本文所研究的乘潮水位任务控制模式就是基于此种模式。
乘潮水位计算是一个典型的潮汐潮流数值模拟,目前流行的数值计算模式是采用基于有限体积海洋数值模式FVCOM进行数值模拟。FVCOM代表了海洋数值模式的研究方向,也是近期研究的热点,它能把河流、河口、海湾、大陆架和大洋作为一个整体来研究,根据需要可以在任意地方进行无限加密,不再像以往先分不同区域随后再嵌套的方法。
3系统设计及其实现
3.1 云平台海洋环境信息处理框架体系
基于Spark框架的乘潮水位计算与可视化平台,是海洋公益项目“海洋环境信息云计算与云服务体系框架应用研究”的组成部分之一[13],项目主要研究海洋环境信息在云计算环境中框架体系的问题。图1为海洋环境信息处理总体框架图,用户在Web交互界面中选择要计算的区域,并将任务提交到可视化平台的Web门户服务器上,由Web门户服务器将乘潮水位任务计算请求转发到Spark集群上,进而由Spark框架下的乘潮水位计算和可视化平台进行调度管理和大规模并行计算,计算完成后,生成可视化结果,并将结果通过Web服务器返回给用户。

Figure 1 Architecture of ocean environment information processing图1 海洋环境信息处理框架图
3.2 基于Spark框架的乘潮水位计算与可视化平台处理机制
目前乘潮水位业务计算模式,大多依赖高性能集群完成,该计算模式通过提交shell命令到集群中,进行数值计算模式计算。与该模式相比,Spark框架下的乘潮水位计算与可视化平台有四个方面的优势:(1)改变了传统业务计算模式,将计算迁移到云平台框架下执行,减少对硬件配置的依赖,降低了计算成本。(2)交互性、灵活性和可伸缩性好。平台采用Web交互的方式,界面化操作更加方便,可以通过地图点选的方式选择计算区域,降低了用户使用的难度,计算结果可视化呈现,有更好的可读性。(3)细化局部区域计算精度。根据计算需要,提高某些乘潮水位港口的计算精度。(4)计算任务合理调度,提高计算效率。通过对Spark框架下原生调度算法的计算测试,以及对Spark任务调度策略的研究,设计和实现了一种基于节点计算能力的任务调度方法。乘潮水位计算与可视化分为乘潮水位数据组织、任务选择、生成任务列表、提交到Spark上进行计算、生成可视化结果等过程,具体流程如图2所示。数据组织是指将乘潮水位数值计算的相关数据存储到HDFS分布式文件系统中;任务选择和生成任务列表是指在乘潮水位计算平台的Web界面上,选择乘潮水位计算的区域、精度、计算方式等;Spark计算过程是将计算任务作为一个应用(application)提交给Spark。Spark框架收到任务之后,根据任务调度算法,将计算任务分配到Spark集群中的各个节点,保证每个计算节点的计算任务均衡,任务分配完成后,在Spark计算节点上启动FVCOM进行乘潮水位数值计算。可视化结果展示分为两部分,海域计算结果采用生成BMP图像的方式展示,根据比例尺规定的颜色映射关系,可以直观地看出整个海域内的水位情况。各港口的计算结果以表格和变化曲线展示,可以查看计算时间开始后48小时内的乘潮水位的变化情况。
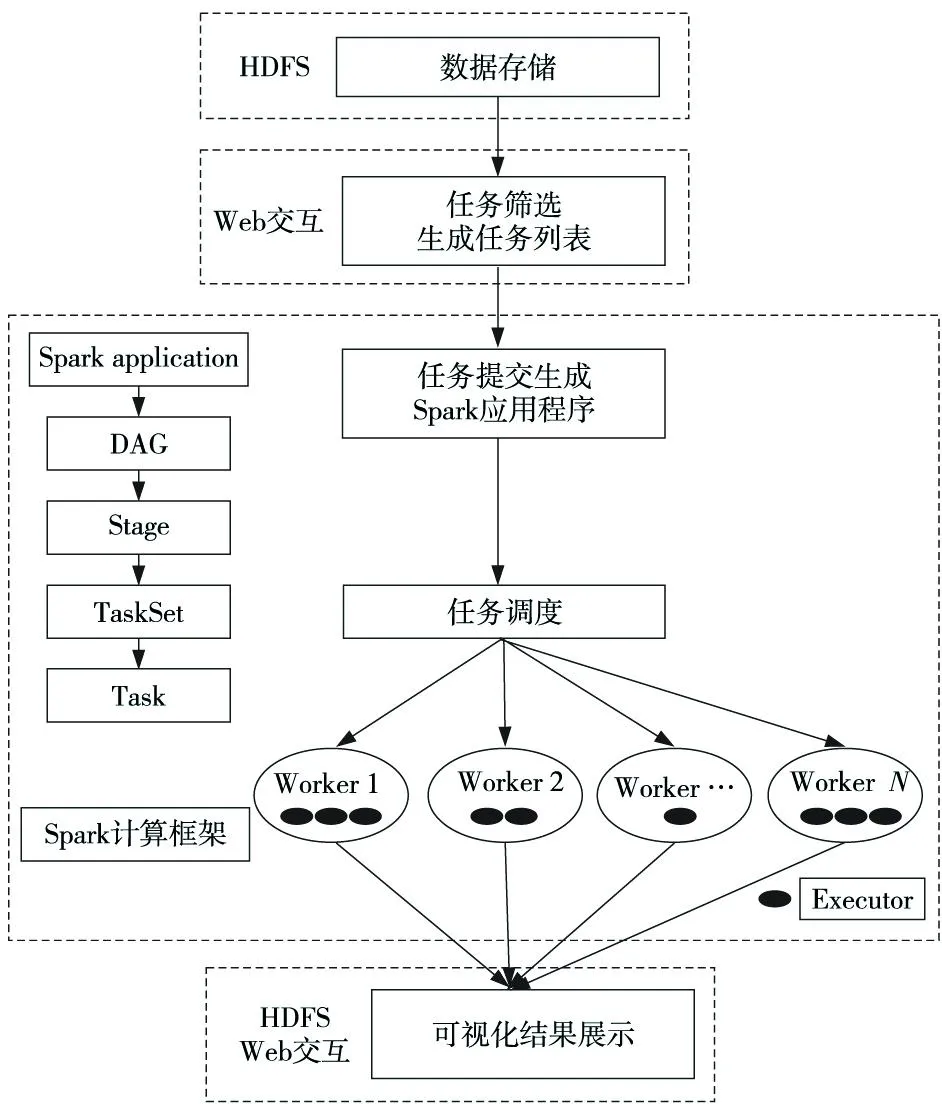
Figure 2 Flow chart of tide-bound water level computing and visualization图2 乘潮水位计算与可视化处理流程
3.3 Spark框架下乘潮水位计算与可视化存在的问题
虽然RDD模型非常灵活地支持细粒度任务的调度,并且RDD已被用于实现一些调度机制,如公平共享调度,但是在用这种模型编写的应用中找到一个适合乘潮水位计算的调度策略仍然是一个难题。在乘潮水位计算中,会产生多个可运行(没有依赖关系)的任务集,这些任务集的调度由调度池的调度方法实现。Spark有两种任务调度方法,对应了两种不同类型的任务调度模式:FIFO模式和FAIR模式。先进先出(FIFO)模式直接管理TaskSetManager,任务执行的过程会根据StageID的顺序来调度TaskSetManager;公平调度FAIR模式,基本原则是根据所管理的正在运行中的任务数量来判断优先级,并通过任务权重(weight)来调整任务集执行的优先程度,权值越高,越优先执行。
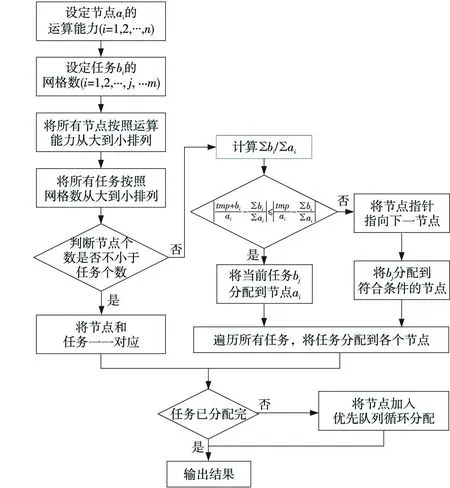
采用以上两种调度模式进行乘潮水位计算,虽然能够一定程度上提高乘潮水位计算的效率,但是我们发现由于不同的计算港口(海域)的网格数量不同,计算复杂度差别较大,计算时间差距较大,无论使用先进先出调度还是公平模式调度,都可能出现由于个别节点计算任务太大,使得整个乘潮水位计算过程的时间变长。本文所研究的基于节点计算能力的算法优化,通过设计合理的调度算法,使计算复杂度高的计算任务优先分配到计算能力强的节点上,使节点计算能力达到充分发挥,避免出现长时间等待其他任务结束的情况,避免Spark随机任务分配过程出现的任务节点分配不合理的情况。具体调度算法优化实现在第四节中具体介绍。
4基于节点计算能力的算法优化
4.1 算法分析和设计
本算法通过研究任务调度算法来提高Spark框架下乘潮水位任务调度效率。为方便介绍,我们将问题抽象为一个简单的数学模型。
名词解释:计算能力是指综合考虑Spark平台中节点的物理参数(CPU型号、CPU主频、内存),设定的一个表达任务处理能力的一个值。
模型假设:首先,假设在Spark集群中有n台计算机,各节点配置不同,将节点计算能力的大小分别设定为a1,a2,…,an。之后,假设有m个港口计算任务,每个任务有一定的大小(网格数),将这m个任务的大小设定为 b1,b2,…,bm。
目标:假设第i个计算节点分配到的任务大小为ci,则目标函数为f=min{max{ci/ai}}。
模型分析:在数学上这是一个NP Hard 问题,因此不能在多项式时间内求解,所以采用近似法求解。
算法过程:
第一步,将{a}和{b}分别从大到小排序。
第二步,判断节点数n和任务数m的关系。
(1)若n≥m,即节点数比要处理的任务数多,则将节点和任务一一对应,使用运算能力强的节点计算网格数大的任务。
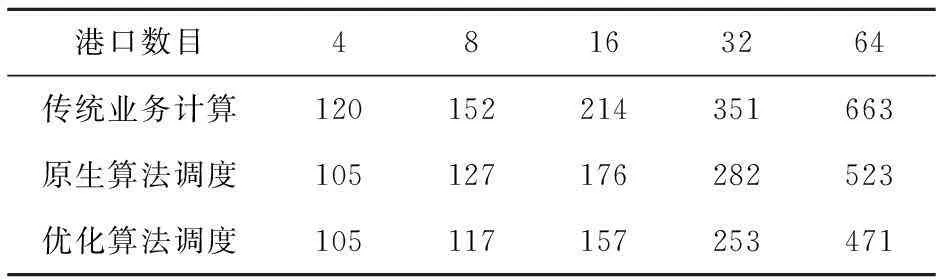
(2)若n 首先计算所有任务的网格数之和与所有节点运算能力之和的比值,设为A,即: 然后以A为基准判断是否能将某个任务bi分配给某个指定节点ai。假设节点ai当前的任务大小为tmp,计算该节点当前任务网格数之和与该节点运算能力的比值,设为B,即B=tmp/a;再计算比值C,C=(tmp+b)/a。 最后,比较|B-A|和|C-A|的大小。若公式|C-A|≤|B-A|成立,则将任务bi分配给节点ai;若不成立,则任务bi不能分配给节点ai,再用上述方法判断任务bi是否能分配给下一个节点ai+1。 任务的分配顺序为从两边向中间靠拢,例如若按任务网格数从大到小排序后的任务序列为t1、t2、ti、tm,则分配顺序为t1、tm、t2、tm-1、ti、tm+1-i(i≤m/2),使得任务能够均匀分配。节点分配按照顺序分配。 按照这种算法可能会出现任务分配不完的情况,在这种情况下,把所有已分配的节点和任务加入优先队列中,每次从优先队列中取出一个当前任务值和节点运算能力比值最小的节点进行任务的二次分配,重复上述分配过程,直到所有任务和节点都加到优先队列中,输出分配结果。 Figure 3 Flow chart of the optimization algorithm图3 优化算法流程图 根据上述优化算法,设计和实现基于Spark的乘潮水位计算优化调度方案,具体技术实现方法如下: (1)建立Spark集群节点计算能力表,根据Spark集群实际计算能力添加信息,包括CPU计算能力、CPU核心数、内存大小。在启动Spark集群之前创建好该表,并将该表的配置信息放到SparkConf中或者在Spark启动时候由Master进程读取。 (2)建立乘潮水位计算港口任务表,该表的主要作用是对乘潮水位计算港口的计算量进行定量表示,通过港口计算的网格数目来定量表示计算的复杂度,网格数目越多,计算越复杂。 (3)描述表转化。根据节点计算能力描述表和计算任务描述表进行转化,转化成我们需要的数据结构,进而调用优化后的任务调度算法。 (4)应用层读取任务分配结果: ①读取生成的xml,以host为key,以所有host相同的taskId及其描述信息构成的列表为value生成一个二元元组为元素的数组。 ②将生成的数组通过parallelize方法生成一个rdd,并设置该rdd的partition为当前需要执行的taskId的总数。 ③对该rdd进行foreach操作,获取当前处理二元元组的第二个元素,可得到在该节点上需要执行的任务列表。 ④改写Spark中TaskSchedulerImpl中的resourceOffers函数,将任务分配部分代码改写为按workerOffer中的host绑定task,此时遍历任务列表将对应host的task绑定到对应的host上的executor即可。 通过以上步骤,我们可以把具体任务分发下去,使任务能够根据元组的host值将任务分发到对应节点,完成调度。 5系统性能 乘潮水位计算与可视化实验平台硬件是Spark集群中的各节点,为了更好地测试优化后的任务调度算法的性能,体现Spark框架下乘潮水位任务控制模式的特点,我们选择了5个Spark节点,其中节点1为主节点,负责乘潮水位任务的控制调度,Spark2~Spark5节点为计算节点,详细节点配置描述表见表1。 Table 1 Spark configuration information 软件配置方面,每个节点安装的集群计算框架为Spark1.0.2、Hadoop 2.3.0,Java版本:jdk-1.7.0_60,Scala版本:Scala-2.10.4,FVCOM版本:FVCOM-2.6。 实验数据为中国海区各港口乘潮水位计算区域数据,各港口区域计算网格数目不同,计算复杂度不同,计算时间不同。所有乘潮水位数据存放在HDFS分布式文件系统中,Spark程序运行过程中,HDFS作为数据的输入。 测试目的:分别使用Spark框架下乘潮水位原生调度模式和优化控制模式对相同计算量的乘潮水位进行计算。为了实验结果的可信性和科学性,实验结果均记录10次并计算平均值。 测试用例:分别选择2N(N=1,2,…,7)个港口进行测试。 Table 2 Elapsed time of the three mission 测试结果如图4所示。 Figure 4 test results图4 测试结果 通过实验结果可以看出,与传统业务计算模式相比,原生调度模式提升效率在15%左右,而使用优化后的调度算法提升计算效率在26%~30%。以64个港口为例,优化后的调度算法相对于传统业务模式节约计算时间192 min,能够有效提高乘潮水位的计算效率。由此可见,使用Spark框架下的乘潮水位任务控制模式可以减少相同计算量的乘潮水位计算的时间,计算数据量越大,加速效果越明显,这主要是因为无论使用传统计算模式还是Spark框架进行乘潮水位计算,由于大区的计算结果是初始条件和边界值,所以都无法避免这段时间(89 min),而这部分时间占到了计算时间的大部分。 总之,本文研究的基于Spark的乘潮水位计算和可视化平台,可以改变乘潮水位原有的业务计算模式,增加了计算的灵活性、交互性和可伸缩性,可以根据需要计算不同的港口,提高局部区域的计算精度。更重要的是,通过优化后的任务调度算法,实现对计算任务的合理调度,提高乘潮水位计算的效率。实验表明,Spark乘潮水位计算和可视化平台的任务调度模式的加速效果,已经基本达到了对乘潮水位计算加速的预期。 6结束语 本文针对乘潮水位长时间序列下乘潮水位海量数据计算的特点,提出一种基于Spark框架的乘潮水位计算和可视化平台,并对任务调度算法进行了优化,提高了计算的交互性、灵活性和可伸缩性,达到了提高计算效率的目的。由于目前设置的节点计算能力为根据机器相关配置参数,多次测试后手动设置,如何采用算法的方式动态地计算出节点的计算能力,将是未来工作的重点。 参考文献:附中文 [1]Xin Zhang, Wen Dong, Li Si-hai, et al. China digital ocean prototype system[J]. International Journal of Digital Earth,2011,4(3):211-222. [2]Liu Jian,Jiang Xiao-yi,Fan Xiang-tao. Review on the marine environment information visualization[J]. Marine Science Bulletin,2014,33(2):235-240.(in Chinese) [3]Martin S. An introduction to ocean remote sensing[M]. Cambridge:Cambridge University Press,2014. [4]Kantha L H,Clayson C A. Numerical models of oceans and oceanic processes[M]. New York:Academic Press,2000. [5]Wooley B,Bridges S,Hodges J,et al. Scaling the data mining step in knowledge discovery using oceanographic data[C]∥Proc of the 13th International Conference on Industrial and Engineering Application of Artificial Intelligence and Expert System,2000:85-92. [6]Tsai C P,Lee T L. Back-propagation neural network in tidal-level forecasting[J]. Journal of Waterway,Port,Coastal,and Ocean Engineering,1999,125(4):195-202. [7]Chen C,Cowles G,Beardsley R C. An unstructured grid,finite-volume coastal ocean model:FVCOM user manual[R]. Technology Report 0620602.New Bedford:SMAST/UMASSD,2006. [8]Zaharia M,Chowdhury M,Franklin M J,et al. Spark:cluster computing with working sets[C]∥Proc of the 2nd USENIX Conference on Hot Topics in Cloud Computing,2010,10. [9]Dean J,Ghemawat S. MapReduce:Simplified data processing on large clusters[J]. Operating Systems Design & Implementation,2004,51(1):147-152. [10]Shvachko K,Kuang H,Radia S,et al. The Hadoop distributed file system[C]∥Proc of 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST),2010:1-10. [11]Lee M,Jung H,Cho M. On a Hadoop-based analytics service system[J]. International Journal of Advances in Soft Computing & Its Applications,2015,7(1):1-8. [12]Zaharia M,Chowdhury M,Das T,et al. Resilient distributed datasets:A fault-tolerant abstraction for in-memory cluster computing[C]∥Proc of the 9th USENIX Conference on Networked Systems Design and Implementation,2012:141-146. [13]Wang Jia-liang,Qin Bo,Liu Jian-jian,et al. Interactive visualization platform based on MapReduce[J].Telecommunications Science,2012,28(9):22-27.(in Chinese) [2]刘健,姜晓轶,范湘涛.海洋环境信息可视化研究进展[J].海洋通报,2014,33(2):235-240. [13]王加亮,秦勃,刘健健,等. 基于MapReduce的交互可视化平台[J]. 电信科学,2012,28(9):22-27. 秦勃(1964-),男,山东青岛人 ,博士,教授,研究方向为计算机图形图像处理、并行处理和云计算。E-mail:qinbo@ouc.edu.cn QIN Bo,born in 1964,PhD,professor,his research interests include computer graphics and image processing,parallel processing,and cloud computing. Tide-bound water level computing and visualization platform based on Spark QIN Bo1,ZHU Yong1,QIN Xue2 (1.College of Information Science and Engineering,Ocean University of China,Qingdao 266100; 2.National Marine Data & Information Service,Tianjin 300171,China) Abstract:Tide-bound water level computing is an important part of ocean environment information processing, which features huge amount of data, high complexity, and prolonged computing time. The traditional computing model implemented by HPC has a number of problems, such as high computation cost, poor scalability and interactivity. Aiming at all these problems, we propose an interactive computing and visualization platform based on the Spark scheduling algorithm. We design a computing capacity scheduling algorithm, realize the parallel processing of large-scale tide-bound water level data, such as data retrieval, data extraction, numerical calculation, feature-based visualization, and achieve the purpose of parallel processing and visualization of large-scale ocean environmental data on Spark. Experimental results show that the computing and visualization platform based on Spark can improve the traditional computing model, lessen the dependence of tidal level calculation on high performance cluster and reduce computation cost. In addition, the newly-developed task scheduling algorithm can make task allocation more rational and scientific, and therefore further enhance its efficiency. In conclusion, the proposed platform provides a new method for tide-bound water level computing. Key words:Spark; tide-bound water level;task scheduling algorithm;parallel processing;ocean environmental information 作者简介: doi:10.3969/j.issn.1007-130X.2015.12.004 中图分类号:TP311 文献标志码:A 基金项目:海洋公益性行业科研专项经费资助项目(201105033) 收稿日期:修回日期:2015-10-26 文章编号:1007-130X(2015)12-2216-06
4.2 具体技术实现
5.1 乘潮水位计算与可视化平台构建

5.2 实验结果

5.3 结果分析与测试结论

