一种1 GHz多端口低功耗寄存器堆设计*
2016-01-26李娇,王良华,毕卓等
一种1 GHz多端口低功耗寄存器堆设计*
修回日期:2015-03-31
通信地址:上海市延长路149号上海大学电机楼415A室Address:Room 415A,Dianji Building,Shanghai University,149 Yanchang Rd,Shanghai 200072,P.R.China
李娇1,2,王良华1,毕卓1,3,刘鹏1
(1.上海大学微电子研究与开发中心,上海 200072;
2.上海大学新型显示技术及应用集成教育部重点实验室,上海200072;
3.上海大学机电工程与自动化学院自动化系,上海 200072)
摘要:超标量处理器中的寄存器堆通常采用多端口结构以支持宽发射,这种结构对寄存器堆的速度、功耗和面积提出了很大的挑战。设计了一个64*64 bit多端口寄存器堆,该寄存器堆能够在同一个时钟周期内完成8次读操作和4次写操作,通过对传统单端读写结构的存储单元进行改进,提出了电源门控与位线悬空技术相结合的单端读写结构的存储单元,12个读写端口全部采用传输门以加快访问速度。采用PTM 90 nm、65 nm、45 nm和32 nm仿真模型,在Hspice上进行仿真,与传统单端读写结构相比较,所提出的方法能够显著提升寄存器堆的性能,其中写1操作延时降低超过32%,总功耗降低超过45%,而且存储单元的稳定性也得到明显改善。
关键词:寄存器堆;单端结构;电源门控;位线悬空
1引言
寄存器堆是微处理器的重要组成部分[1,2],用于存放微处理器运行时所需要的指令、数据以及运算产生的数据,它的性能直接决定着微处理器的性能。微处理器已由过去的单指令发射发展到现今的多指令发射,多指令发射要求寄存器堆具有多个端口以同时完成多次读操作和写操作,以此提高微处理器的并行处理能力[2]。然而,随着端口数的增多,寄存器堆的访问速度会变慢,功耗和面积会增加,性能随之下降。已有多种技术用于提高多端口寄存器堆的性能:在速度方面,文献[3,4]将动态电路应用于寄存器堆中以加快访问速度,但使用动态电路会大幅增加功耗,也降低了电路的鲁棒性;文献[5,6]从改变晶体管的阈值电压着手,在非关键路径上使用高阈值晶体管以减小电流泄漏,在关键路径上使用低阈值晶体管以加快访问速度,但这些文献中使用的双阈值晶体管、体偏置技术需要特殊工艺的支持,通用性不强;文献[7,8]采用分体技术以减少每个存储体的端口数,这种技术能够明显降低寄存器堆的功耗和面积,但是需要非常复杂的控制逻辑来解决访问时的地址冲突;文献[9,10]通过在存储单元的存储核心与读操作端口之间添加隔离反相器,使得存储核心的抗噪声能力免受读操作的影响,大大提高了存储单元的稳定性。
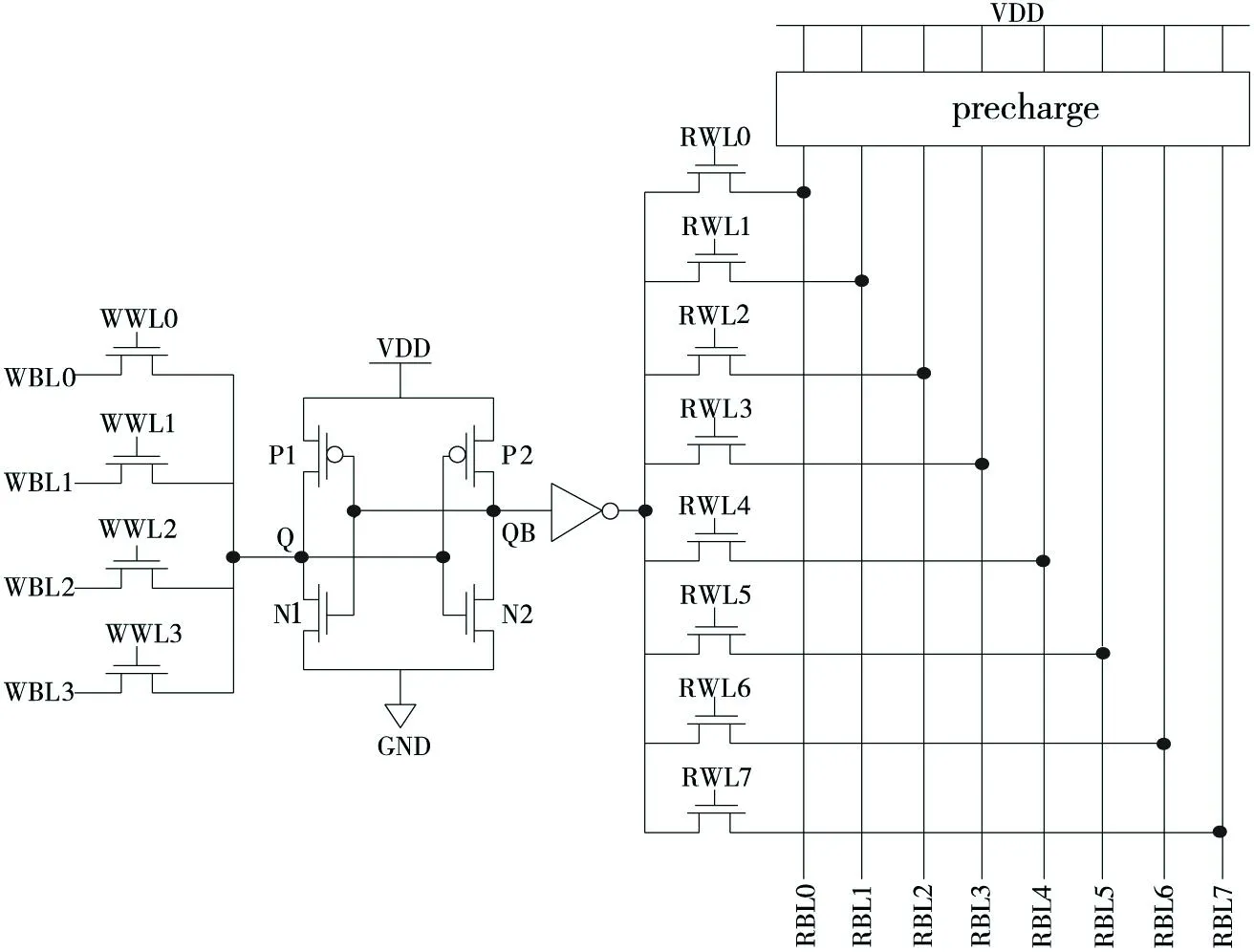
Figure 1 Conventional single-ended memory cell circuit of register files图1 寄存器堆传统单端读写结构单元电路
本文基于一款4发射的超标量处理器设计了一个64*64 bit寄存器堆,含有8个读端口和4个写端口,能够同时实现8次读操作和4次写操作,通过改进寄存器堆存储单元结构实现了性能提升。
2传统单端读写结构
寄存器堆主要由存储阵列、地址译码器和读写控制逻辑三大部分组成,其中存储阵列是功耗、面积最大的部分。存储阵列的基础单元是存储单元,存储单元的结构对寄存器堆的访问速度、面积、功耗和可靠性有着重要影响。
多端口寄存器堆通常采用单端读写结构[11],传统单端读写结构的存储单元电路图如图1所示。存储单元的核心是一对交叉耦合的反相器,在写操作时,四条写位线通过四个传输管将数据写入存储单元,由四条写字线控制具体从哪一个写端口将数据写入存储单元;在读操作时,节点QB通过反相器再经八个传输管将存储值读出,由八条读字线控制具体从哪一个读端口将数据读出。在读操作前,预充电电路会对读位线充电,当读0时,已经被预充为高电平的位线会通过传输管放电使得位线电压下降,再经由灵敏放大器检测位线电平变化将数据读出;当读1时,位线保持高电平,可以即时将数据读出。
相较于双端读写结构,采用单端读写结构能使位线数量减半,面积和功耗大幅降低,适合应用于多端口寄存器堆设计。然而,传统单端读写结构也存在一些缺点:(1)由于写端口是利用NMOS管将数据写入存储单元,NMOS管在传输1电平时存在阈值损失,节点Q电压取决于耦合反相器中N1管与传输管的电阻值之比,如果节点Q电压值小于MOS管阈值电压,写1操作将会失败。因此,往往通过增大传输管的宽度来减小其电阻值,但这会导致功耗和写字线负载增加。(2)在读操作之前需要将读位线预充到高电平,这一过程会消耗很大一部分功耗,并且当节点Q电压为0时,位线电压会经过传输管发生亚阈值泄漏导致位线电压降低,给灵敏放大器检测位线电压变化带来不便。(3)传统单端读写结构的读操作对时序要求较高,为避免工艺偏差和串扰对时序造成的影响,读操作中不同时序信号之间需要预留充足的裕量,这也就增大了读操作延时。另外,灵敏放大器作为模拟电路,受干扰影响较大,对版图设计有较高的要求。鉴于传统单端读写结构存在的缺点,本文对寄存器堆存储单元进行改进,提出了新的存储单元电路。
3一种改进的寄存器堆设计方案
3.1 存储单元改进
新的存储单元电路如图2所示,结构上做了如下改进:(1)去掉了预充电电路和灵敏放大器,改由节点QB经反相器直接驱动位线将数据读出,这样做可以省掉对位线预充电和灵敏放大器读数据时的功耗,这一功耗占总功耗的比重很大。同时,由于精简读操作电路,使得读操作时序更加简单,受工艺偏差的影响更小。(2)去掉预充电电路,使得读位线处于悬空状态,位线泄漏也会大幅降低。(3)对存储单元核心使用了电源门控技术,在电源VDD与P1、P2管,电源GND和N1、N2管之间分别添加一对NMOS管和PMOS管,这四个MOS管构成电源门控电路。当对存储单元写0时,节点Q电压变为0,节点QB电压变为1,同时P4管和N4管关断,耦合反相器与GND断开,P3管和N3管导通,节点QB通过P3管直接与VDD连接,使得节点QB电压恒为1;当对存储单元写1时,节点Q电压变为1,节点QB电压变为0,同时P3管和N3管关断,耦合反相器与VDD断开,P4管和N4管导通,节点QB通过N4管直接与GND相连,使得节点QB电压恒为0。由于单端读写结构的读操作只依靠节点QB的电压将数据读出,所以只要保证节点QB电压稳定即可,节点Q的电压由于受电源门控的影响会处于悬空状态,但这不会影响到读出数据的准确性,因为读出数据值只由节点QB电压决定。当节点Q处于悬空状态时,P3管和N4管的亚阈值泄漏会增加,在纳米工艺下亚阈值泄漏会变得非常严重,为此将P3管和N4管的沟道长度增加20%,通过沟长调制效应来提高P3管和N4管的阈值电压,从而降低亚阈值泄漏。(4)将所有读写端口的传输管改由传输门代替,传输管由于存在阈值损失会影响到读写速度和电压全摆幅性,传输门不存在阈值损失,可以快速进行读写操作,并且读操作时位线电压是全摆幅变化。(5)由于电源门控的作用,节点Q电压为0时,GND与耦合反相器断开,节点Q电压为1时,VDD与耦合反相器断开,这有助于降低存储器核心的功耗,尤其是短路功耗。在反相器翻转的过程中,PMOS管和NMOS管会同时导通,使得在VDD与GND之间形成一条短路通路,造成很大的短路电流,使用电源门控后,短路通路将会被截断,短路电流显著降低。(6)电源门控技术的使用,使得节点QB通过P3、N4管与VDD或GND相连接,增强了节点QB的抗噪声能力,提高了存储单元的稳定性。

Figure 2 Improved memory cell circuit of register files图2 改进后的寄存器堆存储单元电路
3.2 寄存器堆顶层结构设计
为了加快读操作速度和降低功耗,寄存器堆顶层设计采用分体结构,将整个寄存器堆分成八个存储体,每个存储体容量为8*64 bit,这样每条局部位线上只连接八个存储单元,位线负载大大降低,提高了读操作速度。每个存储体都有各自的读写地址译码器和时钟产生电路,最后使用多路选择器将数据读出。寄存器堆顶层结构如图3所示。
4仿真结果比较
4.1 存储单元稳定性
存储单元的稳定性可以用静态噪声容限SNM(Static Noise Margin)来衡量[12],SNM是指允许加在两个耦合反相器输入端上的最大直流信号的幅值,如果噪声信号幅值大于这一值,耦合反相器会发生翻转致使产生错误的状态值。本文所采用的电源门控技术,使得在写入0后节点QB与VDD直接相连,电压值恒为1;在写入1后节点QB与GND相连,电压值恒为0,由于读操作读出的数据直接由节点QB的电压决定,节点QB直接与VDD或GND相连大大提高了存储单元的抗噪声能力。在PTM 45 nm工艺下仿真,得到传统单端读写结构和改进后单端读写结构的读写噪声容限曲线,其中读操作噪声容限RNM(Read Noise Margin)两者相同,写操作噪声容限WNM(Write Noise Margin)后者较前者有明显改善,图4和图5所示为WNM性能对比。
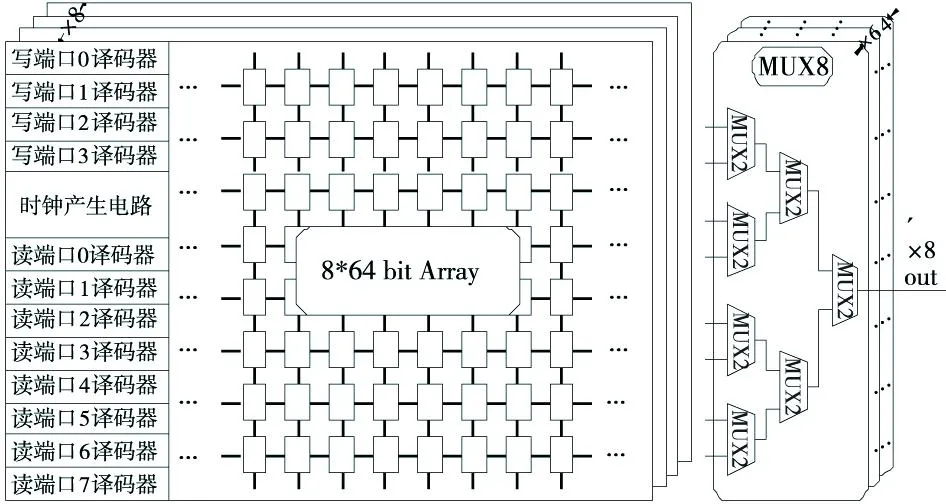
Figure 3 Top architecture of register files图3 寄存器堆顶层结构图
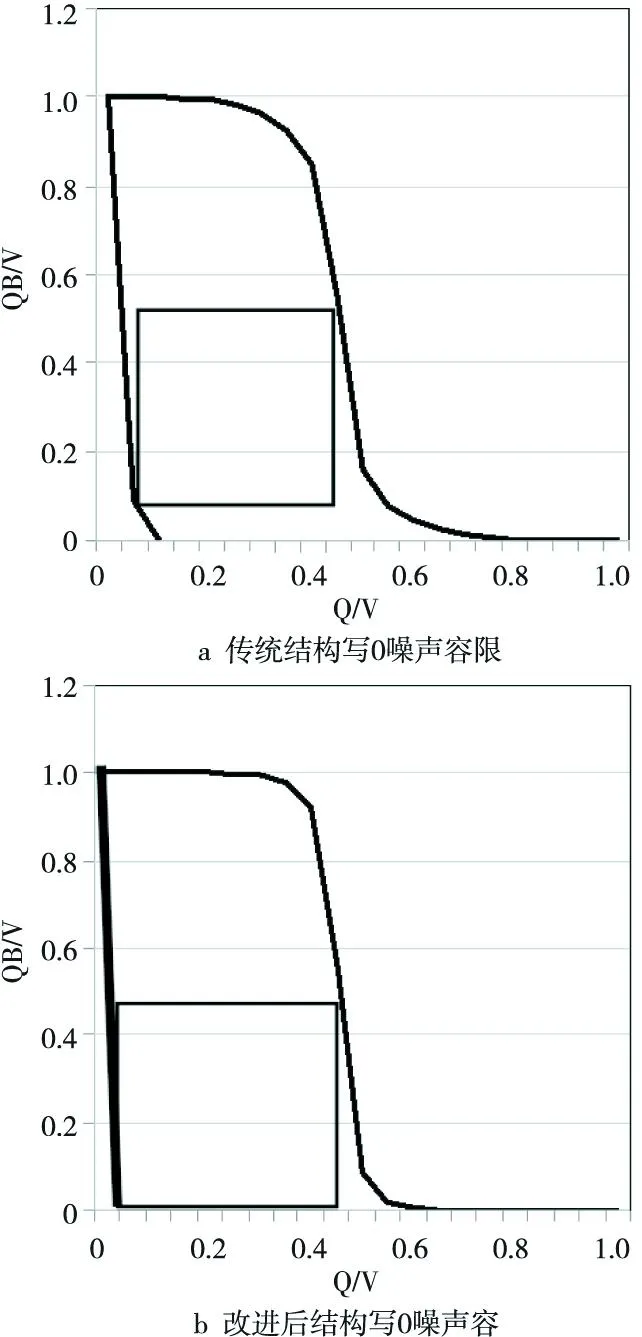
Figure 4 Write 0 noise margin in the conventional structure and the improved structure图4 传统结构与改进结构的写0噪声容限
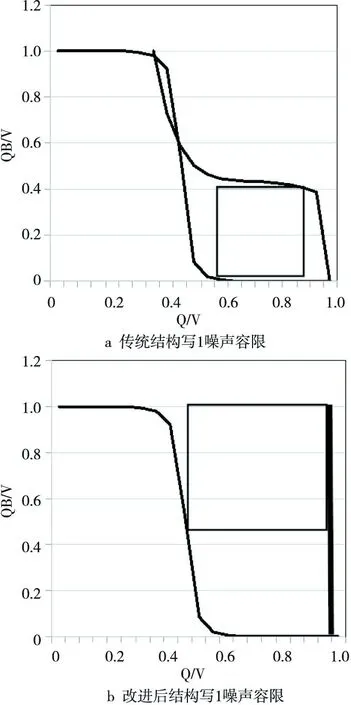
Figure 5 Write 1 noise margin in the conventional structure and the improved structure图5 传统结构与改进结构的写1噪声容限
4.2 关键路径仿真
寄存器堆的读操作是关键路径。如图6所示,系统时钟GlobalCLK经由时钟产生电路产生读操作时钟R0_clk,再与译码器产生的读字线信号相与,再经过反相器增强读字线驱动力。当读操作到来时,读字线信号将传输门开启,存储单元通过反相器再经由传输门对读位线充电或放电将数据读出。在PTM 45 nm工艺下,对寄存器堆关键路径仿真,得到读0延时191 ps,读1延时227 ps,如图7所示为关键路径仿真波形。
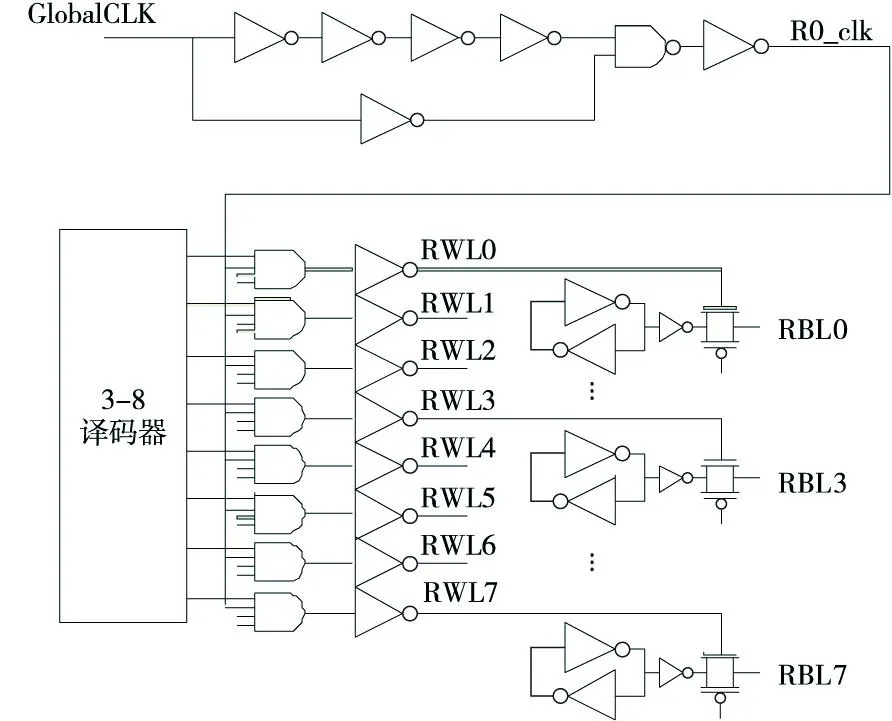
Figure 6 Critical paths of register files图6 寄存器堆关键路径

Figure 7 Simulation results of the critical pathsof register files 图7 寄存器堆关键路径仿真波形
4.3 性能比较
在Cadence Virtuoso下完成寄存器堆原理图设计,采用PTM 90 nm、65 nm、45 nm、32 nm四种不同的仿真模型,在Hspice上分别对传统单端读写结构和本文提出的结构进行仿真验证。寄存器堆系统时钟频率确定为1 GHz,仿真环境是在最坏的情况下进行的,即同一周期内进行八次读操作和四次写操作,并且八个读端口同时读同一个字。如表1所示是四种工艺下的写操作延时、读操作延时、写操作噪声容限、读操作噪声容限和总功耗仿真数据对比。
在面积方面,本文提出的存储单元结构的晶体管数量多于传统单端结构的存储单元,导致存储阵列的面积会增加,分别是90 112和155 648个晶体管;由于省掉了预充电电路和灵敏放大器输出电路,时序上的精简也降低了读写控制逻辑的开销,存储阵列的外围逻辑的面积较传统方法有所减小,分别是81 752和45 736个晶体管。采用传统单端读写结构设计的寄存器堆一共使用了171 864个晶体管,采用本文提出的方法设计的寄存器堆一共使用了201 384个晶体管,面积增加了17.2%。
在访问速度方面,从表1的对比数据来看,改进后的结构在写1操作延时降低了32%以上,是因为采用传输门代替NMOS传输管后避免了阈值损失,加快了写1时的速度。值得注意的是,表1中的传统结构读1操作的延时为0 ps,这主要是由其特殊的结构决定的。传统结构在读操作之前会将读位线预充电为高电平,当读1时,读位线已经是高电平,因此可以即时将数据读出,而改进后的结构的读操作是通过节点QB对读位线进行充电或放电将数据读出,读1操作是一个对读位线充电的过程,需要一段时间才能将数据读出。
在功耗方面,总功耗降低了45%以上,改进后的结构去掉了读位线预充电电路,不再需要对读位线预充电使得功耗大幅下降,并且位线悬空也降低了位线泄漏。
在噪声容限方面,采用电源门控技术增强了节点QB的抗噪声能力,写操作噪声容限显著提升,受反相器隔离作用的影响,读操作噪声容限保持不变。
5结束语
针对传统单端读写结构寄存器堆存在的缺点,本文对寄存器堆存储单元进行改进,采用了电源门控和位线悬空技术,并设计了一个64*64 bit八读四写的寄存器堆。在PTM 90 nm、65 nm、45 nm、32 nm四种仿真模型下仿真,结果表明本文提出的方法能够显著提升寄存器堆在写操作、总功耗等方面的性能,还能提高存储单元的稳定性。
参考文献:附中文
[1]Patwary A R,Greub H,Feng Zhong. Bit-line organization in register files for low-power and high-performance application[C]∥Proc of Electrical and Computer Engineering,2006:505-508.
[2]Roy S,Ranganathan N. State-retentive power gating of register files in multicore processors featuring multithreaded in-or-der cores[J].Transactions on Computers,2011,60(11):1547-1560.

Table 1 Register file performance comparison under four technique models
[3]Li Sheng-long,Li Zhao-lin,Wang Fang. Design of a high-speed low-power multiport register file[C]∥Proc of Microeletronics &Electronics,2009:408-411.
[4]Wang Fang,Ji Li-jiu. Design of high speed 2Write/6Read eight-port register file[C]∥Proc of ICASIC,2003:498-501.
[5]Sarfraz K,Chan M. A low-noise local bitline technique for dual-Vt register files[C]∥Proc of Faible Tension Faible Consommation,2014:1-4.
[6]Gong N,Wang J,Sridhar R. Clock-biased local bit line for high performance register files[J].Electronics Letters,2012,48(18):1104-1105.
[7]Tseng J H,Asanovic K. Banked multiported register files for high-frequency superscalar microprocessors[C]∥Proc of Computer Architecture,2003:62-71.
[8]Wang Dao-ping,Lin Hon-Jarn,Hwang Wei. Low-power multiport SRAM with cross-point write word-lines,shared write bit-lines,and shared write row-access transistors[J].Circuits and Systems II,2014,61(3):188-192.
[9]Xiong Bao-yu. High performance low power multi-port register file research and full custom implementation[D].Shanghai:Fudan University,2011.(in Chinese)
[10]He Peng. Full custom design and realization of large-scale multi-port high speed register File[D].Changsha:National University of Defense Technology,2005.(in Chinese)
[11]Konstadinidis G K,Tremblay M,Chaudhry S. Architecture and physical implementation of a third generation 65nm,16Core,32Thread chip-multithreading SPARC processor[J].JSSC,2009,44(1):7-17.
[12]Hassanzadeh S,Zamani M,Hajsadeghi K. A 32kb 90nm 10T-cell subthreshold SRAM with improved read and write SNM[C]∥Proc of Eletrical Engineering,2013:1-5.
[9]熊保玉. 高性能低功耗多端口寄存器文件研究与全定制实现[D].上海:复旦大学,2011.
[10]贺鹏. 大规模多端口高速寄存器文件全定制设计与实现[D].长沙:国防科学技术大学,2005.

李娇(1975-),女,山西运城人,博士,讲师,研究方向为高性能数字电路设计及集成电路可测试性设计。E-mail:lijiao@staff.shu.edu.cn
Li Jiao,born in 1975,PhD,lecturer,her research interests include high performance digital circuit design, and integrated circuit design for testability.
王良华(1989-),男,湖北黄冈人,硕士生,研究方向为数字电路全定制设计。E-mail:gggyvwxf@163.com
Wang Liang-hua,born in 1989,MS candidate,his research interests include digital circuit full custom design.

毕卓(1979-),男,吉林敦化人,博士,副教授,CCF会员(E200010117M),研究方向为微处理器设计及高性能数字电路设计。E-mail:Zhuo.bi@shu.edu.cn
Bi Zhuo,born in 1979,PhD,associate professor,CCF member(E200010117M),his research interests include microprocessor design, and high performance digital circuit design.

刘鹏(1992-),男,江西赣州人,硕士生,研究方向为数字电路全定制设计。E-mail:1182762405@qq.com
Liu Peng,born in 1992,MS candidate,his research interest includes digital circuit full custom design.
A 1 GHz multi-port low-power register file design
LI Jiao1,2,WANG Liang-hua1,BI Zhuo1,3,LIU Peng1
(1.Microelectronics R&D Center,Shanghai University,Shanghai 200072;
2.Key Laboratory of Advanced Display and System Application,Shanghai University,Shanghai 200072;
3.School of Mechatronic Engineering and Automation,Shanghai University,Shanghai 200072,China)
Abstract:Register files in superscalar processors usually adopt the multi-port structure to support the wide issue, however, this structure brings in problems such as prolonging access speed, increasing in silicon areas and higher power consumption.We design a 64*64 bit multi-port register file which can concurrently accomplish 8 read operations and 4 write operations in one single clock cycle.We improve the conventional single-ended memory cell structure and purpose a new structure, which combines the power-gating and the bit-line floating techniques, and the transmission gate is used in all ports to accelerate the access speed.Simulations are conducted on Hspice with PTM 90 nm, 65 nm, 45 nm and 32 nm technology models compared with the conventional single-ended structure, the proposed method can significantly improve the performance of register files, the delay of write logic 1 decreases more than 32%, and the total power consumption decreases more than 45%; the stability of memory cells is also improved.
Key words:register file;single-ended;power-gating;bit-line floating
作者简介:
doi:10.3969/j.issn.1007-130X.2015.12.005
中图分类号:TP333
文献标志码:A
收稿日期:*2014-12-15;
文章编号:1007-130X(2015)12-2222-06
