基于数据挖掘的电力设备状态诊断系统建模
2016-01-20朱付保,霍晓齐,徐显景
基于数据挖掘的电力设备状态诊断系统建模
朱付保, 霍晓齐, 徐显景
(郑州轻工业学院 计算机与通信工程学院, 郑州 450001)
摘要:以电力公司的业务需求为背景,为实现电力设备的状态诊断,以数据挖掘技术中的粗糙集和决策树算法为依据,采用粗糙集和决策树相结合的数据处理模型对电力设备的各属性数据进行了分析处理。综合运用粗糙集和决策树两种数据挖掘算法,通过粗糙集技术进行属性约简,并运用决策树的ID3算法对约简后的数据进行分枝、减枝得到规则集,实现对电力设备工作状态的快速、高效诊断,并根据其工作状态提供决策支持。
关键词:粗糙集;ID3算法;知识库;模型库
中图分类号:TP391
文献标志码:A
DOI:10.3969/j.issn.1671-6906.2015.03.020
Abstract:The system uses the business needs of a power company as the background. For the realization of the state testing of electrical equipment, rough sets and decision tree algorithm belonging to data mining technology is used as the basis. The paper proposes a data processing model combining rough sets with decision tree to realize for power each attribute the data analysis and processing equipment for power each attribute of electrical equipment. Rough sets and decision tree are used in this paper synthetically. Through rough set technology attribute reduction can be realized in this paper. Data which has been reduced is branched and cut branches by the use of the ID3 decision tree algorithm, and then rules in order can be got. At last, the working status of electrical equipment can be diagnosed rapidly and efficiently and the decision support is provided according to their work status.
收稿日期:2014-06-11
基金项目:国家自然科学基金项目(41171341)
作者简介:何渊淘(1983-), 男,河南郑州人,硕士。
文章编号:1671-6906(2015)03-0090-05
随着社会进步和经济的不断发展,工业在人们的日常生活、生产中起到的作用越来越大。迫于各行业对电力能源的巨大需求,电力系统的规模越来越大,并且不断朝着超高压、跨地区的趋势发展。与此同时,当变压器、断路器等电力设备出现故障时,给人们的生活和工业生产带来的影响也日益增大,这必然对电力设备安全、稳定、可靠的运行提出越来越高的要求。
然而,电力行业传统的状态检测效率并不高。计划检修作为常规的检测方法机械地按固定周期对所有电力设备进行检测诊断,工作十分繁琐,且存在工作量大、维修滞后、检修过剩等问题。引起这些问题的主要原因是没有对电力设备状态进行充分的分析和评估,在不同的工作环境下通过已有的检测诊断标准和检修日志对设备进行诊断并做出决策并不容易。怎样根据以往的真实数据通过删除不重要的属性、得到判断规则集、对数据进行高效分析,从而实现对电力设备的状态诊断、异常报警、决策分析,成为目前亟待解决的问题。
数据挖掘能够实现从海量的、无规则的、有干扰以及随机的训练数据中提取出隐含的、人们原先并不知道的有用信息和规则[1]。当前主要使用数据挖掘技术的属性约简、分类和预测等功能。常用的数据挖掘方法有粗糙集、神经网络、决策树和聚类分析等[2]。
本文利用数据挖掘中的粗糙集和决策树建立数据处理模型,使用粗糙集算法对集合属性进行约简,并使用决策树的ID3算法将简约后的结果进行规则提取,实现对电力设备状态的高效、快捷判断。
1粗糙集算法
粗糙集理论是一种新的处理模糊和不确定知识的数学工具,最早起源于波兰数学家Pawlak Z于1982年提出的数学分析理论[3]。粗糙集理论的主要任务是近似分类、知识约简、属性相依性分析、根据决策表产生最优或次优决策控制算法等。粗糙集理论的主要思想是在保持分类能力不变的条件下,通过知识约简,导出问题的决策或分类规则。
1.1知识的含义
在粗糙集理论体系中,知识用来表示一种分类的能力。日常生活中,人们的各种行为其实就是辨别现实和抽象的对象的能力。假使起初已经掌握了论域研究对象的必要的信息和知识,就可以通过这些已有的知识将其划分到不同的类别当中。假如两个对象具有完全相同的信息,那么它们是不可区分的,也就是说当前已有的信息并不能够将其分开。
粗糙集的核心理论是等价关系,一般可以用等价关系来代替分类,根据已有的等价关系将样本集合划分为等价类。从知识库的观点来看,每一个等价类可以被称为一个概念,也就是一条知识或规则。每个等价类可以唯一地用来表示一个概念,归属于同一个等价类的不同对象对于给定概念不能进行区分。
1.2粗糙集的定义
定义1知识表达系统
一个知识表达系统A可以表示为有序四元组:A={U,R,V,f},具体说明如表1。

表1 知识表达系统说明
定义2不可分辨关系
在粗糙集中,可以用多种信息来描述论域中的对象。如果两个不同的对象是被完全相同的属性所描述,则这两个对象在信息系统中被归为同一类,两个对象之间的关系被称为不可分辨关系。也就是对任意属性子集B∈R,假若对象xi、xj∈U,∀r∈B,只有当f(xi,r)=f(xj,r)时,xi与xj为不可分辨对象,也简记作Ind(B)。不可分辨关系亦被称作等价关系。
定义3上近似集和下近似集
上近似集:根据已有的知识R,判别论域U中一定属于和可能属于集合X的对象所组成的集合,公式表示如下:
R-(X)={x∈U,[x]R ∩X≠Ø}
(1)
式中,[x]R为等级关系R中的包含x元素的等价类。
下近似集:根据现存的知识R,判别论域U中全部一定属于集合X的对象所组成的集合,公式表示如下:
R_(X)={x∈U,[x]R∈X}
(2)
式中,[x]R为等级关系R中的包含x元素的等价类。
通过上述上近似集和下近似集的定义可知,对于一个给定的知识表达系统S={U,R,V,f},X∈U表示一个样本子集,R表示等价关系,那么一切包含于X的基本集合的并集即为R_(X),一切与X的交集不为空的基本集合的并集即为R-(X)。
定义4粗糙度
在论域U中,对于知识R,所选样本子集X的不确定性可用粗糙度来度量,公式表示如下:
(3)
aR(X)通常也被称为近似精确度,Card为集合的基数,即集合中元素的个数。易知,0≤aR(X)≤1,当aR(X)取值为1时,则集合X对于R为确定的;假如aR(X)≤1,则集合X对于R是粗糙的。
定义5假设Q∈P,若Q为独立,并且Ind(Q)=Ind(R),那么称Q为等价关系族P的一个约简,简记作Red(P)。在P中所有不可省略关系的集合称为等价关系P的核,记作Core(P)。属性约简和核之间的关系为:属性约简集合Red(P)的交集就是P的核,即Core=∩Red(P)。核不仅是所有约简的计算基础,是知识库的最重要的组成部分,也是知识约简时不能删掉的属性[4]。
2决策树
2.1分类的概念
分类是找出描述并区分数据类或概念的模型(或函数),以便能够使用模型来预测类标记未知的对象类[5]。分类的目的是构造一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。
常用的分类方法有贝叶斯算法、粗糙集算法、神经网络算法、决策树算法等。基于决策树算法不需要繁琐的先验知识,就能够分析处理复杂的海量高维数据,获得规则的方法简单快捷。因此,诊断模型选用决策树作为分类方法。
2.2决策树的介绍
决策树是一种简单高效的分类算法,能够从海量的随机样本中经过分析推断出可以用树状形式表示的规则集。与流程图中树的结构特别相像,决策树的最高层为根节点;最底层的节点为叶子节点,代表一种分类;根节点与叶子节点之间为内部节点,在内部节点上进行特定属性的训练检测,特定属性通过ID3算法中的信息增益标准来确定,各个分支表示检测输出。其中,通过构建的决策树来检测随机样本的各个属性值,检测路径由根节点到叶子节点,得到分类结果进而形成分类模型。分类模型形成后,通过测试数据集对模型的准确率进行估量,经测试完全符合标准的模型才能够用来进行样本分类预测,其原理如图1所示。

图1 决策树工作原理
2.3ID3算法
定义6信息熵
已知随机样本集合T中样本个数为a,类别属性有n个互不相同的值,可以得出n个类别Mi(i=1,2,…,n)。假设类别值为Mi的样本个数为ai,则对某一样本进行分类需要的期望信息[6]如式(4)所示:
(4)
式中,pi为样本集合中Mi的概率值,可以用ai/a进行计算。由于信息需用二进制进行编码,上述公式中的对数底数值取2。
定义7信息增益
假定{b1,b2,…,be}是属性B的e个不相同的值,按照属性B可以将T划分成e个子集合{a1,a2,…,ae};aj表示样本T中在属性B上取值为bj的子集,假若选属性B作为决策树的测试属性,则以上的子集即与由节点生成的分枝相对应,并且由属性B对集合进行划分的期望信息可以由式(5)求出:
(5)
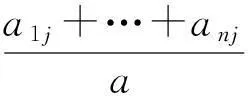
Gain(B)=L(a1,a2,…,an)-E(B)
(6)
在构造决策树的过程中,通过比较各个属性的信息增益的大小,选择信息增益值最大的属性作为随机样本的测试属性。
ID3算法就是通过各个属性的信息增益来选择测试属性构造决策树的,其构造过程如图2所示。
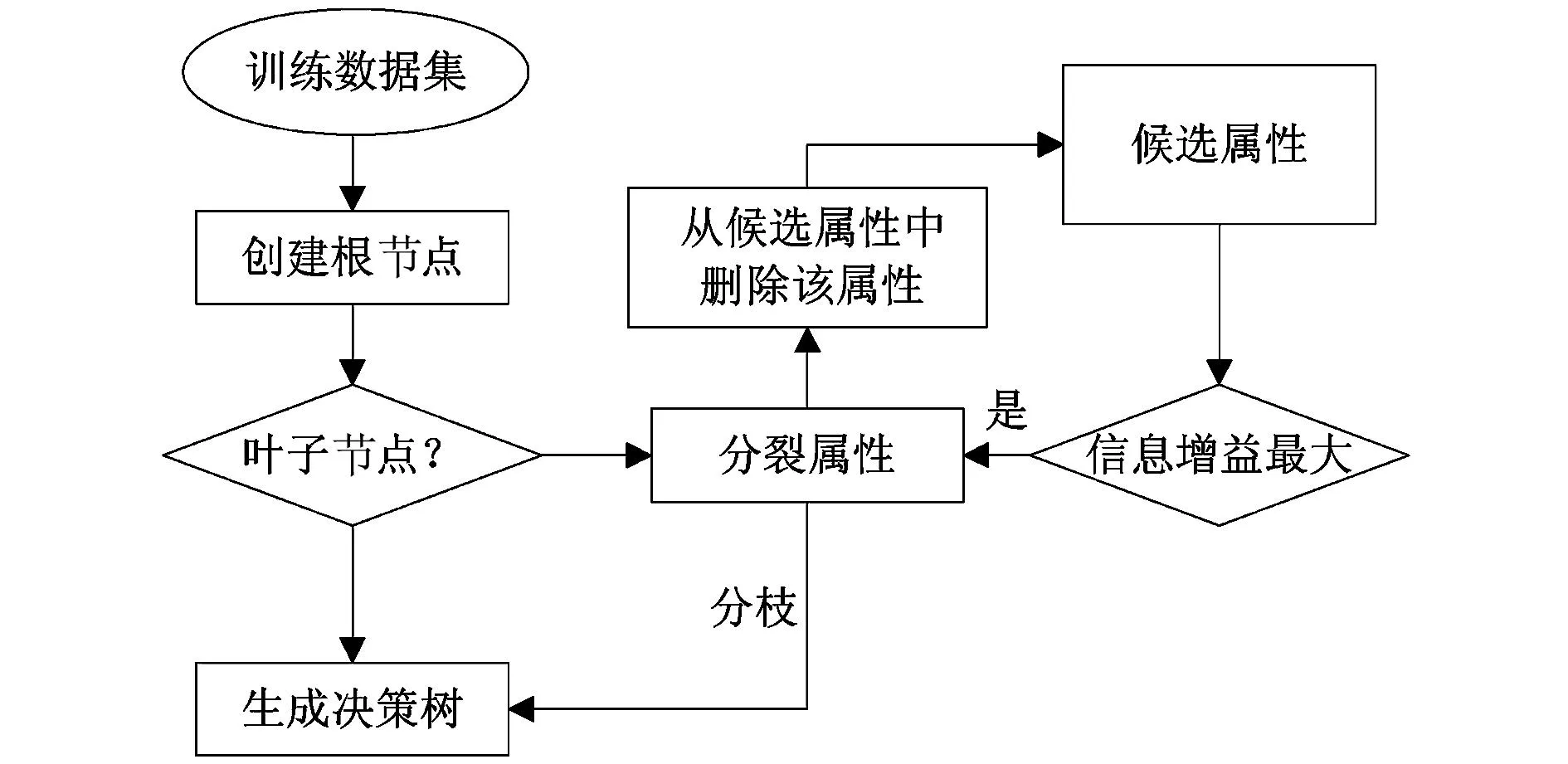
图2 ID3算法构造决策树的流程图
在决策树的构建过程中,通过信息增益值来选择内部节点的测试属性。将信息增益值最大的属性选作特定节点的测试属性[7],确保选中的测试属性在对随机样本数据进行分类时所需要的信息量最小,且反映出划分的最小随机性。使用ID3算法可以保证对样本对象进行分类时期望检测次数达到最少,而且方便计算出一棵简单的决策树。
3粗糙集和决策树相结合的算法模型
粗糙集方法和其他一些不确定方法一样,都能够处理含糊的和不确定的数学问题,然而粗糙集理论自身并没有处理不确定和不准确数据的机制。决策树技术虽然也有很多优点,却不能删除不相关和有干扰性的属性。此外,当前在构造决策树的过程中,通常选择单个属性作为测试属性。
根据粗糙集和决策树各自的优缺点,本文将二者结合起来,取长补短,建立粗糙集-决策树数据处理模型,如图3所示。
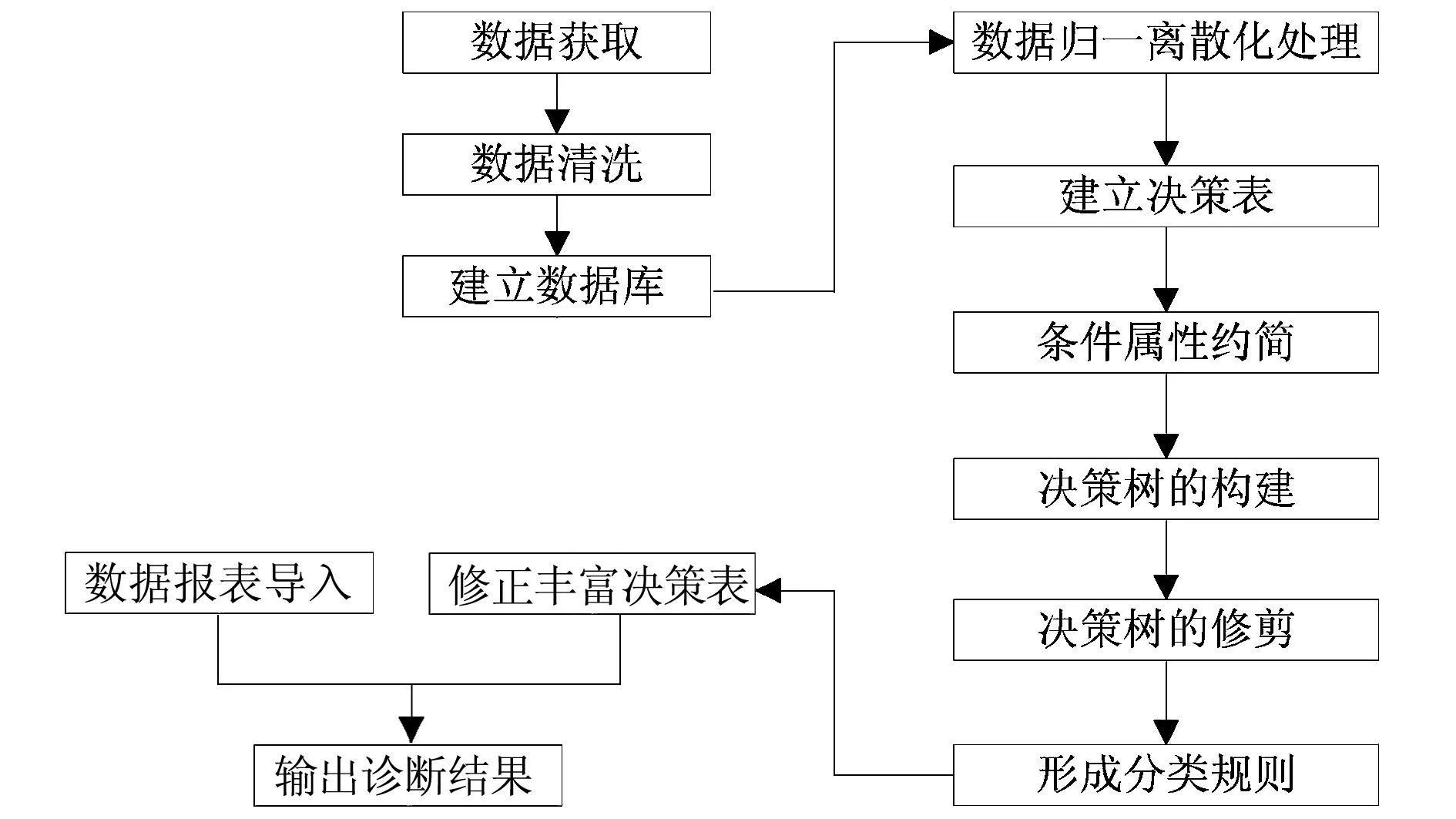
图3 粗糙集-决策树数据处理模型
在数据处理模型中用到的数据主要有两类,一类用作训练测试,一类用作对训练结果进行验证。根据属性判断指标对训练数据集进行离散化处理[8],将处理过的数据中重复的数据予以删除,从而实现对训练数据集的清洗;根据已经预处理过的样本对象建立决策表,决策表中的数据是建立数据处理模型的数据分析来源。根据决策表生成分辨矩阵,由分辨函数得出样本数据集的核,进而根据核值计算出约简集,得出约简后的决策表,利用ID3算法生成简单的决策树。
通常情况下,由简单的决策树得到的规则集形式并不是最简的,需采用后剪枝算法对生成的决策树进行剪枝,通过删除内部节点的分枝,剪掉树节点。对于树中每一个非树叶节点,计算该节点上的子树被剪枝可能出现的期望错误率。然后,使用每个分枝的错误率,结合沿每个分枝观察的权重评估,计算出对该节点剪枝后的期望错误率。如果剪去该节点导致较高的期望错误率,则保留该子树;否则,剪去该子树。产生一组逐渐被剪枝的树之后,使用一个独立的测试集评估每棵树的准确率,得到具有最小期望错误率的决策树,根据剪枝后的决策树生成相应规则。运用验证数据集对生成的规则进行验证,若生成规则不符合,或未达到预期标准,则重新进行计算,直至生成规则符合要求。
4系统实现
4.1逻辑结构
根据电力设备状态诊断系统的需求,电力设备状态检测系统的逻辑体系结构设计如图4所示。
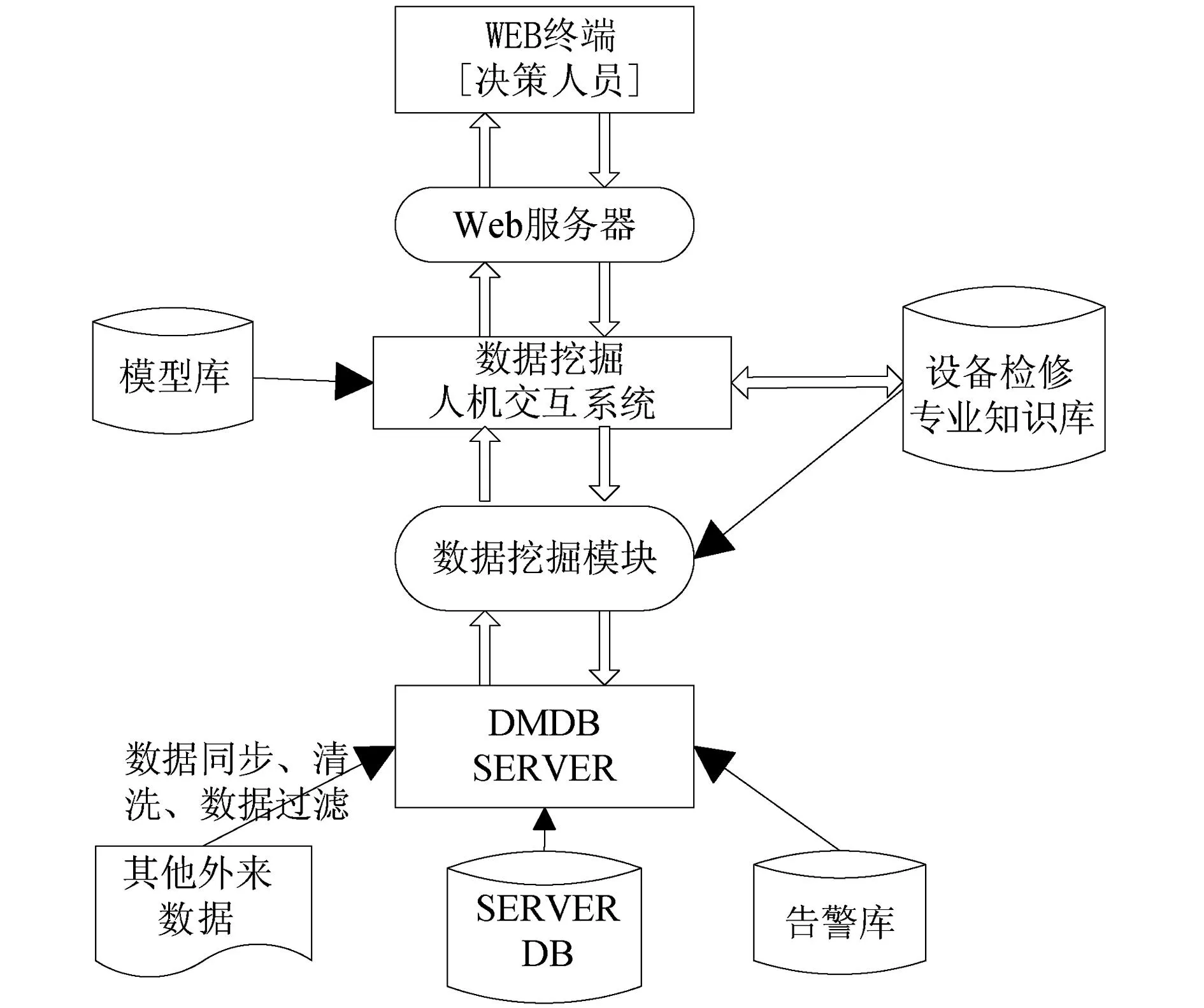
图4 系统逻辑结构图
Web终端是客户端部分,用户可以通过终端对系统进行操作,并将请求向服务器提交。Web服务器将用户请求传递给诊断系统的控制模块部分,最终将处理结果以图、树等多种形式返回给客户端。根据服务器返回的数据形式,Web服务器负责生成相应的图表,终端部分将最终的结果予以呈现。
设备状态检修专业知识库中存放着大量的业务经验数据。通过数据挖掘模块得到的结果可以通过知识库中存放的数据进行修正。部分经过数据挖掘得到的规则[9]和信息也会被存放到知识库当中,为下次同样分析做参考使用。
告警库是状态诊断系统中的另一个独立的数据库系统,电力设备的告警信息就存放在其中。通过对告警信息进行处理,可以更加准确地对数据进行分析处理[10]。
数据库是关系到数据诊断系统正常工作的最基本的组成部分,是整个系统的基本数据来源,其主要组成部分包括整个电力公司的设备运行时的真实数据和部分历史数据。数据挖掘模块中用到的数据都来源于数据库。从其他库中抽取的经过处理的数据也存放在该数据库中。系统对数据库最多的操作是数据提取、变换、集成等。
模型库中存储着系统的业务处理方法和接口,数据处理方法、挖掘方法等的实现程序都存放在模型库中。通过在方法管理模块进行注册,能够对外提供统一的接口,在方法库中所有遵循模型库接口规范的方法都可以被使用。各个模型自身并不存在业务背景,每个模型关心的只是数据输入的个数以及类型,各个模型都严格执行相应的数据处理,而与数据涉及的业务逻辑无关。只需在方法库中设置一个包装程序,并将标准形式的参数进行输入,就能够得到用户需要的结果。
4.2系统架构
系统使用了JavaEE中的Struts2、Spring、AJAX等技术,使用Struts2实现MVC开发模式的设计,运用Spring的分层架构灵活选择所需组件,利用AJAX技术高效实现用户与前台页面的动态交互。通过这些开发技术,有效实现了功能模块和系统代码间的松耦合,并且使系统的工作效率得到极大提高。
开发平台选用Myeclipse,采用Java作为编码语言。客户端通过采用JSP+CSS+JavaScript技术,高效实现页面的交互性。通过点击界面左侧的级联菜单,可以方便地选择需要查看的电力设备。导入设备的数据报表,通过后台的算法处理,即可便捷地查看设备的工作状态。
5结语
系统运用数据挖掘中粗糙集和决策树相结合的数据分析模型对变压器等电力设备的属性数据进行分析和处理,根据最后生成的规则集构建知识库,为电力设备工作状态的诊断提供了依据。通过采用Web开发中的Struts2、Spring、 AJAX等技术,降低了代码之间的耦合性,不仅提高了工作效率,也便于系统的扩展开发。
通过构造粗糙集和决策树的数据挖掘模型,将变压器等电力设备的状态诊断技术与数据挖掘技术相结合,提高了对系统数据库中用到的海量数据的处理能力。通过对生成的规则集和状态指标进行分析,实现了电力设备工作状态的预测、评估、检修等功能,为电力设备正常、稳定地运行提供了可靠的保障。
参考文献:
[1]徐晓,翟敬梅,刘海涛,等.制造决策的知识融合粗糙集模型[J].华南理工大学学报(自然科学版),2011,39(8):36-40.
[2]胡燕,王慧琴,秦薇薇. 基于粗糙集的火灾图像特征选择与识别[J].计算机应用,2013,33(3):704-707.
[3]刘兴文,王典洪,陈分雄. 一种基于变精度粗糙集的C4.5决策树改进算法[J].计算机应用研究,2011,28(10):3649-3651.
[4]费洪晓,胡琳. 一种粗糙集-决策树结合的入侵检测方法[J]. 计算机工程与应用,2012,48(22):124-128.
[5]张军,李鹏. 动态粗集理论在决策树算法中的应用研究[J].计算机应用与软件,2013,30(8):99-101.
[6]张明,唐振民,杨习贝.基于粗糙集的拒绝决策规则获取和约简[J].计算机工程,2011,37(3):22-24.
[7]王飞,王卓,曾姚.基于变精度粗糙集的决策树构造改进算法[J].计算机与数字工程,2013(3):337-339.
[8]翟俊海,翟梦尧,李胜杰.基于相容粗糙集技术的连续值属性决策树归纳[J].计算机科学,2012,39(11):183-186.
[9]王永梅,胡学钢. 决策树中ID3算法的研究[J]. 安徽大学学报(自然科学版),2011,35(3):71-75.
[10]卢铮松.研究生奖学金的决策树分类数据挖掘研究[J].计算机工程与应用,2012,48(26):139-144.
(责任编辑:席艳君)
The Modeling of the Power Equipment Condition Diagnostic
System Based on Data Mining
ZHU Fu-bao, HUO Xiao-qi, XU Xian-jing
(Zhengzhou University of Light Industry, Zhengzhou 450002, China)
Key words:rough sets; ID3 algorithm; knowledge base; model library

