几种并行编程框架在数据挖掘领域的比较
2016-01-20何渊淘,齐兵辉
几种并行编程框架在数据挖掘领域的比较
何渊淘, 齐兵辉
(郑州航空工业管理学院, 郑州 450000)
摘要:将机器学习并行化是进行海量数据挖掘的重要方式,但由于并行计算框架、机器学习算法的多样性,导致计算框架的选取及算法并行化存在着困难。本文对几种常见的并行计算框架的模型结构和工作机理进行了分析,根据算法中变量的依存关系将其分类,并将这几类算法进行了实验对比。实验结果表明,算法中变量的依存关系对其在并行化后的性能有巨大的影响。
关键词:MapReduce; Pregel; Hama; GraphLab; MPI; 数据挖掘
中图分类号:TP3
文献标志码:A
DOI:10.3969/j.issn.1671-6906.2015.03.021
Abstract:To slove the date mining on large dataset, the parallelizaion of algorithm is the most important solution. Due to the diversity of the parallel frameworks and the machine learning algorithms, it is difficult to choose a framework and algorithm parallelizaion. In this paper, the models and mechanism of the parallel framework are analyzed, and it is classified based on the parameter relations. In the end, the experiments are conducted and the results show that the relation of the algorithm parameters have great impact on the performance
由于传感技术和通信网络的发展,数据收集和存储的规模在飞速增大,如何从海量数据中挖掘出有效的信息是当前的研究热点。目前较为普遍的方案是采用机群系统和分布式框架来提高数据处理的效率[1-2]。由于数据挖掘算法本身的差异,导致其在不同的并行框架下有着显著的性能差异。本文在常见的并行框架下比较了几种数据挖掘算法,并根据实验结果分析了不同算法在并行计算框架下的适用性,为机器学习算法的并行化提供了实验依据。
1常见的并行计算框架
海量数据处理的关键在于把问题分解为“映射”和“规约”两种操作,“映射”将数据集进行分割和处理,而“规约”则将“映射”后的结果进行整理和归纳。并行计算框架将并行节点中复杂的“通讯”“同步”工作进行了封装,极大降低了数据处理的难度。并行框架的模型分为三类:基于消息传递的模型、基于数据流的模型、基于图的模型[2]。常见的并行计算框架和其特征见表1,其中MPI属于基于消息传递的模型,MapReduce、Twister、Haloop属于基于数据流的模型,Pregel、Hama、GraphLab属于基于图的模型。
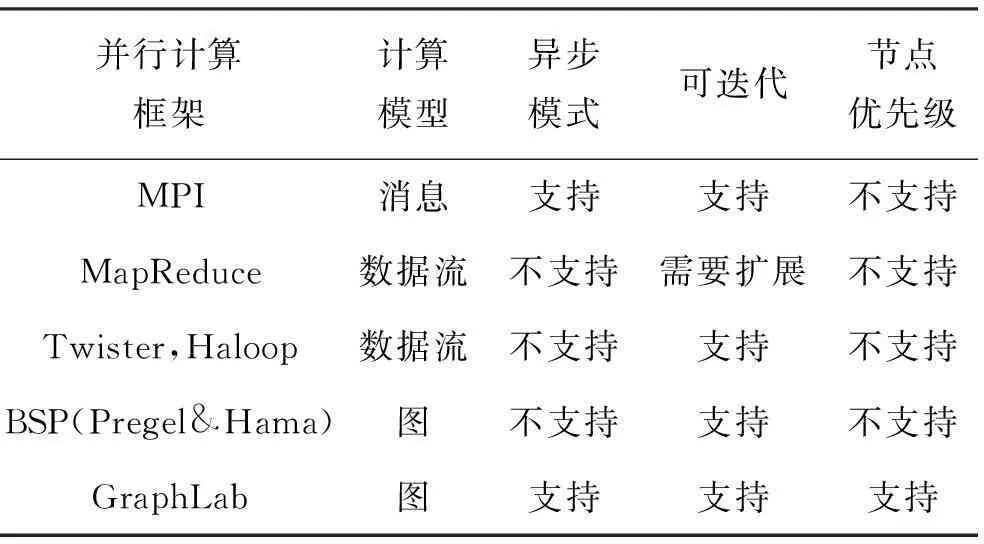
表1 几种分布式计算框架的对比
1.1MPI
MPI(Message Passing Interface)是消息传递接口的标准规范,最初由MPI论坛发布,支持C和Fortran语言。严格来说,MPI是一个函数库,仅提供了对并行计算最基础的支持。MPI的一个极大优势是使用MPI编写的程序具有较好的移植性,同时也有着最高的分布式计算效率。当前基于MPI实现的函数库主要有OpenMPI和MPICH。
基于MPI的应用通常由多个并发进程组成,每个进程位于机群系统的某台主机上,并由唯一的标示符来标记。每个MPI进程完成整个分布式计算任务的一部分,并通过消息机制完成并行进程间数据的交换。使用MPI框架可以实现最高效的算法,但是在并行计算的过程中会遇到数据存储、切分等问题,同时也要解决并发进程间的同步、竞争等一系列问题,属于细粒度的并行开发。这种特征使得基于MPI的数据挖掘对人的要求较高,算法实现周期长。同时MPI的应用与机群规模关系紧密,当机群规模发生变化后,还需要重新调整原有的程序,这不适合弹性变化的云环境。
1.2MapReduce和迭代式MapReduce
MapReduce是谷歌公司为了解决海量数据挖掘问题而设计的并行计算框架, 该框架通过Map和Reduce两个步骤[2]完成分布式计算的“映射”和“规约”操作。海量数据通常存储在分布式文件系统上,该框架将其分割后交给若干个Map来处理,每个并发的Map进行本地计算后将结果输出为<键/值>[1-2]的形式。Map处理完成后,系统会将这些二元组序列进行排序。具有相同“键”的元组被汇总后交由Reduce汇总,最终数据被输出并保存在分布式文件系统上。
MapReduce框架的计算流程如图1所示。从图可以看出,该框架适合数据集内数据关联性弱,数据挖掘算法较为简单,但数据量较为庞大的一类问题[3]。这些问题在自然语言处理、生物信息学等领域较为普遍。数据分析人员仅需要将注意力集中在Map和Reduce的设计上,而数据存储、分割和计算的同步则由框架本身的实现去完成。当前谷歌和雅虎的MapReduce及微软的Dryad都是针对该框架的,其中谷歌使用该框架重新实现了搜索引擎业务,使得程序的结构更为简洁,性能更为稳定[2]。
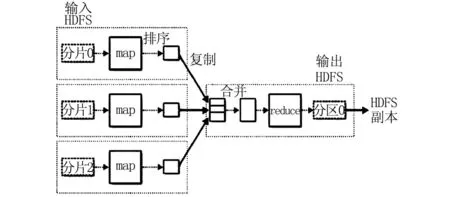
图1 MapReduce处理流程
然而在统计类数据挖掘领域中,MapReduce对数据间独立性假设的条件难以保证[3],这类问题的求解需要进行多次的Map和Reduce操作,即迭代式MapReduce。而Mahout[3]就是针对迭代式MapReduce设计的框架。
1.3改进的迭代式MapReduce
迭代式MapReduce在海量数据挖掘领域中有较多的应用,例如商品推荐系统[3]。然而在迭代过程中,Map和Reduce会频繁进行序列化和反序列化操作,这些操作导致了较高的输入、输出开销。基于Mahout框架的数据挖掘应用就面临了类似的问题[3]。Ekanayake J等指出,当前很多数据集规模小于机群环境中的内存总量[3],因此可以将全部数据存放在内存中以避免序列化和反序列化操作。由此产生了对迭代式MapReduce的改进,其代表为Twister和Haloop[4-7]。
Twister和Haloop将迭代过程中的数据分为静态和动态两种类型。静态数据持久存放在机群的内存中,而少量动态数据采用NarradaBrokering[3-4]消息总线进行传输。这两种策略极大减少了序列化和反序列化的开销,显著提升了算法的运行效率。图2和图3为Twister与其他几种并行框架在商品推荐算法和K-means算法上的性能对比。从图中可以看出,两种算法在Twister下的开销比在Hadoop和Dryad下低几个数量级,与在MPI下的开销较为接近。
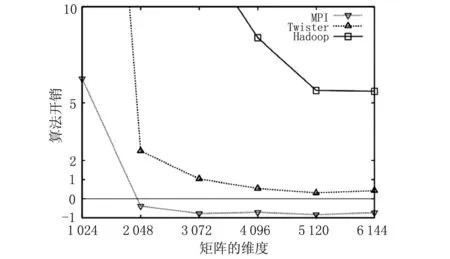
图2 商品推荐算法在3种并行框架下的性能对比
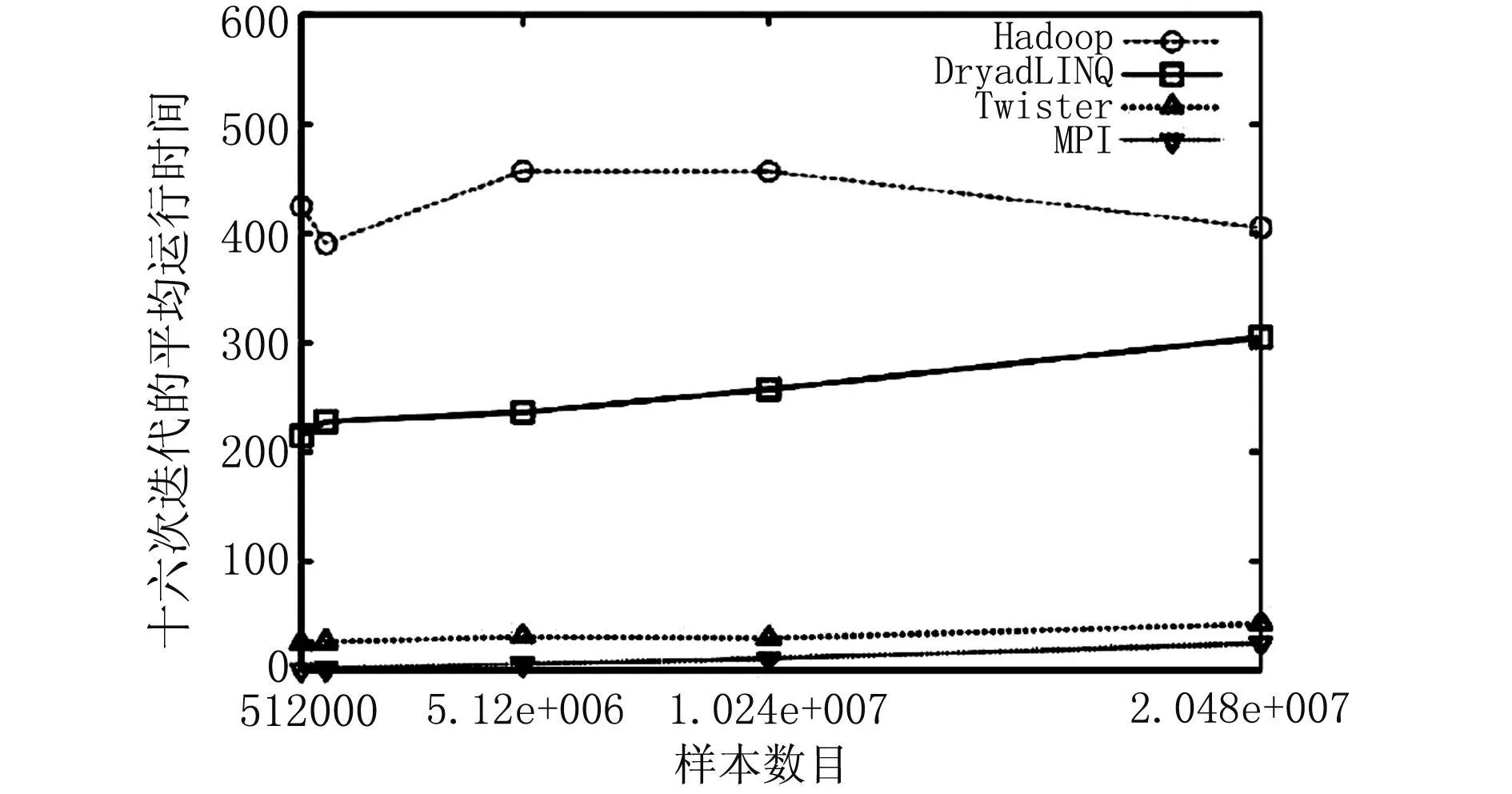
图3 K-means算法在4种并行框架下的性能对比
然而Twister和Haloop对输入数据有特殊要求,即用户需要提前进行数据的切分。同时Twister和Haloop没有提供任何的容错机制,一旦某个分布式计算进程出现错误,整个计算任务就必须重新开始。这种问题在使用廉价计算机搭建的云环境下更为致命。
1.4基于BSP的Pregel和Hama
Pregel和Hama是基于BSP的图计算框架,其中Pregel是谷歌针对大数据下的图遍历、最小生成树、最短路径等而设计的[8-9]。这类框架的典型应用是网页排名和社交网络中的人际关系数据挖掘。
当前大部分数据挖掘算法可以转换为图的结构。以图4中多元素相加为例,算法中的变量可以转变为图中的点,而变量之间的运算关系可以转变为图中的边。用上述方式可以将大部分统计机器学习算法用图来描述,进而在Pregel和Hama[9]下进行实现。图5为K-means算法在Mahout和Hama两种并行框架下的性能对比。从图5可以看出,由于K-means需要进行高频率的数据传递,基于Mahout的并行框架时间开销较高。
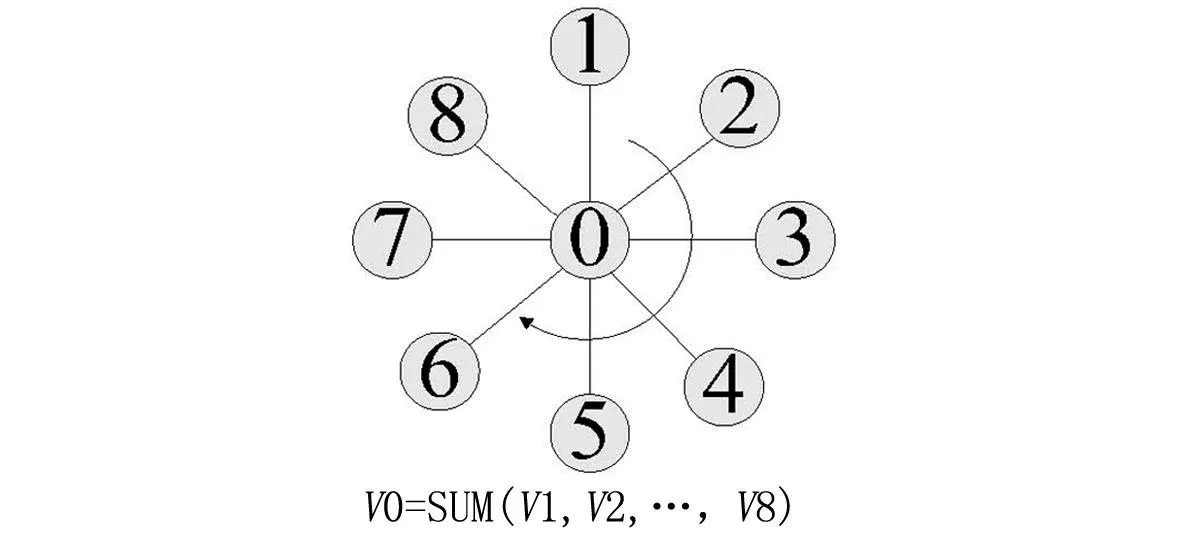
图4 算法内变量依赖关系的图形化表示
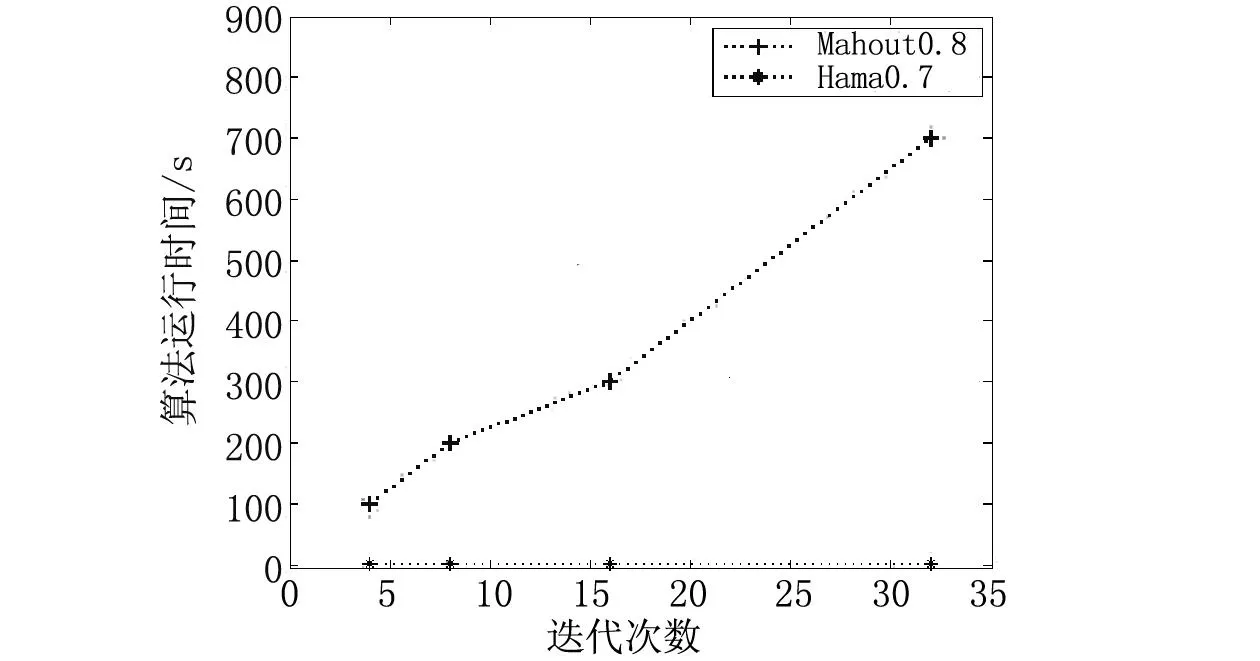
图5 iris数据集上K-means算法的性能对比
从结构来看,Pregel和Hama的基础为BSP(Bulk Synchronous Parallel)[9]。BSP由超步(Superstep)组成,超步的结构如图6所示。每个超步包含了本地计算、节点间通信、同步3个过程。一个超步通常由多个并发的本地计算组成,每个本地计算位于机群中的一个计算机节点上,这些本地计算进程使用机群间的网络完成通信和同步工作。
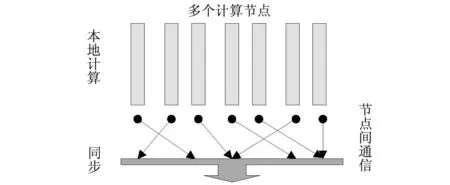
图6 BSP的逻辑结构
由于本地计算进程的数量远大于机群中主机的个数,因此多个本地计算进程共享同一台主机。而超步中每个节点上的本地运算所耗费的时间不等,因此同步机制导致大量节点处于等待状态,这使得基于BSP框架的算法有着较高的时间开销。除此之外,超步内的本地进程需要读入初始数据,而这些初始数据通常存储在主机节点上;如果初始数据在这些计算节点间分配不合理,仅在数据读取这个阶段就会有很长的等待时间,这会造成更为严重的同步等待现象。
1.5GraphLab的异步图计算
GraphLab是CMU[10]针对大数据环境下的图数据挖掘提出的框架,该框架扩展了BSP对异步的支持,同时也更适合统计类数据挖掘算法[10-13]。由于GraphLab使用共享内存的方式在节点间进行被动的信息传递,这种方式避免了在Hama等框架下无效的数据传输[10],为高效的异步计算和通讯提供了支持。
GraphLab使用了基于图的模型,因此可以将统计类算法转变为有向无环图来求解[11]。该框架用节点代表算法中的变量和数据,用边来表示数据的依赖关系,将并行算法执行过程中的数据传递动作抽象成Gather、Apply、Scatter[10]3个操作。为了避免本地计算进程在数据读写上的“竞争条件”和“同步问题”,GraphLab使用了3种一致性模型:“节点一致”模型、“边一致”模型和“完全一致”模型[10]。3种一致性模型按数据的读写顺序将整个图分割成若干子图,并在不同的子图上执行并行计算,这种策略避免了数据一致性问题。3种一致性模型的差别在于所划分子图中边和节点的数量,以及对并行计算的支持度[10]。
图7和图8为GraphLab和其他几种并行框架下Netflix电影推荐算法和名称实体算法的性能对比。从图7和图8可以看出,GraphLab对异步计算的支持和共享内存的消息传递方式使得其对节点数量的依赖性较低,其与其他两种框架相比具有极低的时间复杂度。
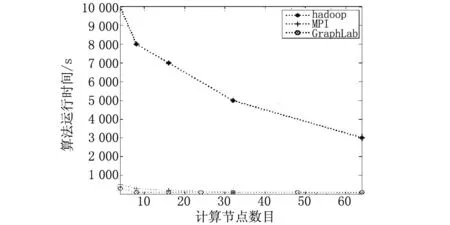
图7 Netflix电影推荐算法在3种并行框架下的性能对比
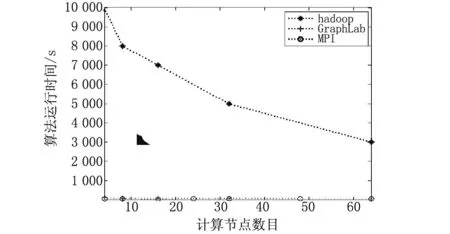
图8 名称实体识别算法在3种并行框架下的性能对比
2几种框架的比较和性能分析
2.1MPI与其他几种编程框架的对比
MPI使用消息传递函数实现不同计算节点间的数据传递。与其他几类分布式框架相比,其抽象程度最低,因而数据分析人员面临的开发难度最大。使用MPI可以完成在其他并行框架下实现的任何算法,理论上来说基于MPI的算法有着最高的性能。然而由于人的因素,MPI绝非任何场景下的最优选择。从图2、图3、图7、图8可得出,尽管MapReduce、BSP、GraphLab抽象程度较高,但算法的性能依然接近MPI下的性能表现。
2.2MapReduce和BSP的差别
MapReduce的抽象程度要高于BSP,因而在该框架下算法的实现难度小于BSP。Low Y等指出,任何在MapReduce下实现的算法都可以在BSP框架下实现,而且有着相近或者是更高的运行效率[10]。对数据集内数据依赖性强、数据处理需要迭代求解的问题,MapReduce性能较差。而BSP避免了序列化和反序列化操作,相比于MapReduce时间开销较低。从图7、图8可以看出,基于BSP的GraphLab相比于MapReduce(hadoop)有着极低的运算开销。Gonzalez J E等也指出,基于BSP的框架更适合图遍历和最短路径树等算法[12]。
当前统计类数据挖掘算法在大数据领域有较多应用,而大部分统计类机器学习算法可以抽象为算法中变量的依存关系,这种关系可以转化为有向无环图,从而在基于BSP的框架下实现。
2.3GraphLab和BSP的差别
基于BSP的Pregel和Hama仅支持同步计算,然而超步中的等待机制导致大量节点处于等待状态,从而造成计算资源的浪费。Corbett J C等指出,大部分统计类的数据挖掘算法具有较强的数据依赖性和变量依赖性[13],如果使用Hama等框架来进行处理会出现超步过多和同步时间过长的现象。GraphLab不仅支持异步计算,也支持节点上的动态调度。同时其采用了节点动态优先级调度和共享内存方式传递数据,这些策略降低了超步的个数和同步时的等待时间。以PageRank为例,仅当某节点所代表的页面权重发生变化时才使得周围的节点进入计算状态,这样,大量节点的权重不需要重新计算[10]。被动的信息传递方式,使得当前节点读取周围节点数据时不需要邻接节点进入运行状态,避免了无效的重复计算。
3结语
从数据挖掘算法的理论效率来看,并行数据挖掘应当尽可能使用抽象程度较低的框架,然而实验数据表明,一些抽象度较高的分布式计算框架在众多算法上有着与MPI相近的性能。除此之外,这些抽象程度较高的框架提供了数据切分、计算任务调度和容灾等能力,从而可以提升数据挖掘的效率,而这些是MPI所不能提供的。
从实验结果可以得出,并行框架与数据集和算法之间存在着密切的关系。以Mahout为代表的迭代式MapReduce适合数据量极大,数据之间关联度小,算法中各变量关联度也较小的一类问题。而Twister和Haloop类型的迭代式MapReduce适合数据量适中,数据之间关联度小,算法中各变量关联度也小的问题。Hama、Pregel和GraphLab适合数据集内关联度大,算法中变量依赖性强,并行节点间通讯较为密集的一类问题,其中GraphLab对异步计算和通讯的支持使得其适合对计算序列要求不严格的一类算法。
参考文献:
[1]Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[2]Ranger C, Raghuraman R, Penmetsa A, et al. Evaluating Mapreduce for Multi-core and Multiprocessor Systems[C]//Proceedings of the 13th Symposiu on High Performance Computer Architecture(HPCA). Washington: IEEE Computer Society, 2007: 13-24.
[3]Ekanayake J, Li H, Zhang B J, et al. Twister: A Runtime for Iterative Mapreduce[C]//Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing. New York: ACM, 2010: 810-818.
[4]Ekanayake J. Architecture and Performance of Runtime Environments for Data Intensive Scalable Computing[D]. Bloomington: Indiana University, 2010.
[5]Ekanayake J, Gunarathne T, Fox G, et al. Dryadlinq for Scientific Analyses[C]//Fifth IEEE International Conference on E-Science. Oxford: IEEE, 2009.
[6]Bu Y, Howe B, Balazinska M, et al. HaLoop: Efficient Iterative Data Processing on Large Clusters[J]. Proceedings of the VLDB Endowment, 2010, 3(1-2): 285-296.
[7]Bu Y, Howe B, Balazinska M, et al. The HaLoop Approach to Large-scale Iterative Data Analysis[J]. The VLDB Journal-The International Journal on Very Large Data Bases, 2012, 21(2): 169-190.
[8]Pace M F. BSP vs MapReduce[J]. Procedia Computer Science, 2012(9): 246-255.
[9]Seo S, Yoon E J, Kim J, et al. Hama: An Efficient Matrix Computation with the Mapreduce Framework[C]//Proceedings of The IEEE 2nd International Conference Cloud Computing Technology and Science. Singapore: IEEE, 2010: 721-726.
[10]Low Y, Bickson D, Gonzalez J, et al. Distributed GraphLab: A Framework for Machine Learning and Data Mining in the Cloud[J]. Proceedings of the VLDB Endowment, 2012, 5(8): 716-727.
[11]Low Y, Gonzalez J, Kyrola A, et al. Graphlab: A New Framework for Parallel Machine Learning[EB/OL]. [2014-05-20]. http://www.docin.com/p-661735882.html.
[12]Gonzalez J E, Low Y, Gu H, et al. PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs[C]. Hollywood:The 10th USENIX Symposium on Operating Systems Designand Implementation,2012.
[13]Corbett J C, Dean J, Epstein M, et al. Spanner: Google’s Globally Distributed Database[J]. ACM Transactions on Computer Systems (TOCS), 2013, 31(3): 8.
(责任编辑:张同学)
The Comparison of Several Parallel Model in the Data Dining Fields
HE Yuan-tao, QI Bing-hui
(Zhengzhou Institute of Aeronautical Industry Management, Zhengzhou 450100, China)
key words:MapReduce; Pregel; Hama; GraphLab; MPI; data mining
