基于聚类分析算法的图书推荐系统的研究
2016-01-19孙彦超北京信息科技大学教务处北京100192
●孙彦超(北京信息科技大学教务处,北京 100192)
基于聚类分析算法的图书推荐系统的研究
●孙彦超(北京信息科技大学教务处,北京100192)
[关键词]协同过滤;聚类;最近邻居;推荐系统;评价矩阵
[摘要]针对协同过滤算法通过用户评分矩阵生成推荐时会遇到“冷启动”、“数据稀疏性”问题,以及忽略用户兴趣实时变化及多样性的特点,笔者在传统协同过滤算法的基础上引入聚类算法,对协同过滤算法进行改进,解决了传统算法的“冷启动”及“数据稀疏性”问题。改进后的算法利用北京信息科技大学图书管理系统中的数据进行实验分析,结果证明新的算法比传统协同过滤算法平均绝对误差小,从而证明改进后的算法具有较高的推荐质量。
随着高校图书馆信息化建设的不断推进,图书管理系统建设的重点已经由读者“查找”图书转变为向读者“推荐”图书,如何更好地为读者推荐图书,如何采集读者对图书的评价信息,如何有效实现每本图书的最大价值,已成为图书管理系统建设的一个重要环节。协同过滤算法凭借算法简单容易实现、对数据对象依赖性低及推荐准确率高等特性,被图书推荐系统广泛采用。协同过滤算法的基本原理是:根据用户对项目的评价信息构建用户评价矩阵,[1]分析用户评价矩阵生成目标用户的最近邻居集合,然后根据最近邻居集对物品评分形成对推荐。但是,该算法忽略了读者的特征信息,比如,读者的爱好跟其年龄、性别、专业、教育背景等特征信息有着紧密联系。通常说,有着相似特征的读者也具有相似的兴趣。协同过滤算法把目标读者跟全体读者作对比,分析其最相似用户集,这种比较方式对推荐结果的准确性和推荐效率都会产生巨大影响。本文在协同过滤算法的基础上进行改进,在产生相似读者集之前,根据读者的特征信息对读者进行聚类,然后对每一类读者生成评价矩阵,对目标读者根据该类评价矩阵计算相似度,从而生成最近邻居集,依据最近邻居集为目标读者预测对待评价图书的评分,从而产生推荐。因为经过聚类后的读者集合具有类内较高相似度,不同类之间的读者具有较低相似度,所以经过改进后的推荐算法从理论上能够为读者提供较高质量的推荐服务。
1 传统协同过滤算法
推荐算法是推荐系统的核心,其算法的好坏直接决定系统推荐的质量。协同过滤算法可以对视频、音频等结构复杂的目标产生推荐,[2]也可以利用评分数据挖掘其隐含的爱好,并且可以产生高质量的推荐,因而被业界广泛采用。协同过滤算法主要思想为:收集用户评价信息,将其整理并转化为评分矩阵,利用评分矩阵计算目标用户相似度最高的邻居集,依据最近邻居生成推荐。[3]主要步骤可以分为四步:①建立用户评价矩阵;②计算用户间相似度,查找最近邻居;③根据最近邻居为目标用户预测评分;④产生推荐。算法具体过程如下。
(1)建立用户评分矩阵。首先,采集用户信息,对评价信息整理形成m行n列的评分矩阵。如图1所示,其中,m表示用户数,n表示项目数,rij表示用户i对项目j的评分。
(2)计算用户间相似度,查找最近邻居。利用用
户评价数据,构建评分矩阵,进而计算用户对物品评价的相似性,根据评价相似性找到相似度最高的邻居。通常计算利用评分矩阵计算相似度的方法有:使用余弦公式计算法、相关系数计算法及修正后的余弦公式计算法。[4]

图1 用户评分矩阵
①余弦公式法,用户u的所有评分为向量,用户u和v的相似度通过计算和余弦夹角值得到,余弦值越大表示相似度越高。该算法忽略了不同用户评分尺度不同对相似度造成的影响。
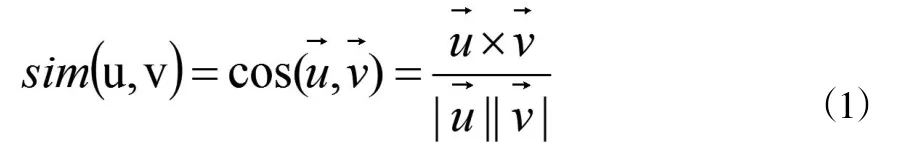
②相关系数法,通过计算用户评分相关性,公式如(2),通过对评分尺度归一化处理,避免了余弦公式法的问题,提高了计算结果的准确性;为用户u和v评分的平均分,Ru,j为u对项目I的评分。
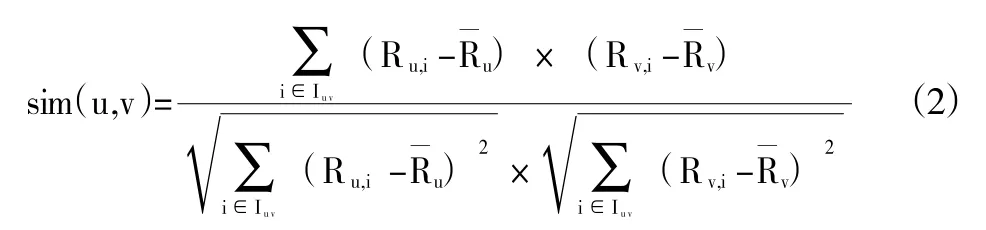
③修正余弦公式法。通过对用户对项目评价的评分进行归一化处理,对经过处理后的评价矩阵分析计算,提高算法得出相似度的准确性。
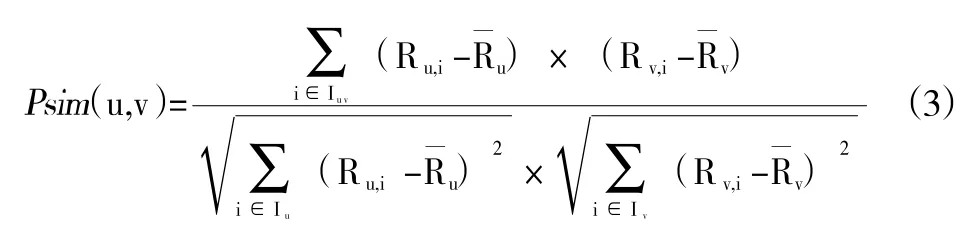
(3)预测目标用户的评分。依据最相似邻居对待评价对象的评分,计算目标用户对其的评分,如计算公式(4),其中,N为用户i的最近邻居集,Rj,d表示i的最近邻居j对项目d的评分,表示邻居j的所有评分的平均值。
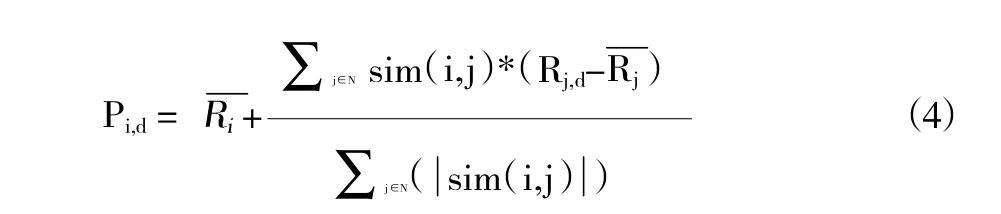
(4)产生推荐。为目标用户对待评价项目预测评分,根据预测值进行降序排列,取相似度最大的若干个进行推荐。在协同过滤算法产生推荐结果过程中,计算用户相似度和生成最近邻居集合是算法中最关键的两步,同时也是最耗时的步骤。随着用户和对象规模的增长,评价数据占整个矩阵的比例迅速下降,从而使得用户评分数据在整个矩阵中极为稀疏,造成依据该评分矩阵产生推荐质量下降。另外,对于新用户和新项目,没有任何评分信息,算法就无法依据历史评分为新用户产生推荐,也无法把新项目推荐给用户。这就是协同过滤算法通常会遇到的“数据稀疏性”和“冷启动”问题。
2 改进后协同过滤算法
由于传统协同过滤算法利用用户的评分矩阵产生计算相似度,产生推荐时会遇到“冷启动”和“数据稀疏性”问题。[5]本文提出了在协同过滤算法基础上引入聚类算法对其进行改进,进而应用到个性化图书管理系统中。改进后的算法工作原理为:首先采集并整理读者信息,根据读者自身特征对其聚类并生成聚类后读者对图书评分矩阵,该矩阵更加精准地反映每类读者的评分相似程度,依据每类读者特征可以分析其特征相似程度,根据同类读者评分矩阵计算读者兴趣相似度。同时,考虑读者特征相似度和兴趣相似度所占权重,根据权重大小计算读者整体相似度,以及整体相似度寻找目标读者的邻居集,从而生成推荐。
(1)采集并整理读者信息。为了给读者产生最佳推荐服务,需要采集读者的特征及评分数据,如特征数据包括读者的年龄、性别、所学专业、教育背景等,[6]这些特征信息主要为了对读者进行聚类,同时为计算聚类用户的特征相似度服务。另外,需要收集读者的借阅图书信息和对图书的评分信息,这部分信息主要是为了形成读者对图书的评分矩阵,利用评分矩阵可以计算出读者的偏好相似度。[7]
(2)读者聚类和生成聚类读者评分矩阵。根据读者的特征信息,本文采用K-Means算法对读者聚类,可以极大地减少数据的维度,生成最近邻居时,只用在目标读者的同一聚类的用户中计算,计算的数据量明显减小,同时,提高了推荐的准确性和实时性;[8]在改进的算法中,为了对读者产生高相似度的聚类,主要选取读者的性别、年龄、专业、教育背景作为特
征属性,[9]生成读者特征矩阵如图3。

图3 读者特征矩阵
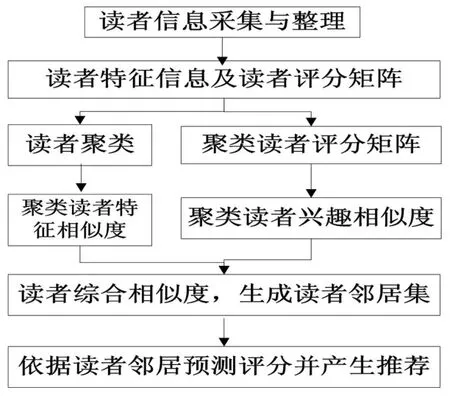
图2 改进后算法流程
其中,m为读者数量,n为读者特征数量,umn为用户m对应的特征n的值。通过对读者特征信息整理,生成读者特征矩阵后,利用K-Means聚类算法对其聚类,算法步骤如下:①任意选择k个读者作为聚类对象中心点;②利用欧式距离公式(5)计算其他读者与中心点读者的特征相似度,根据相似度对读者聚类。[10]
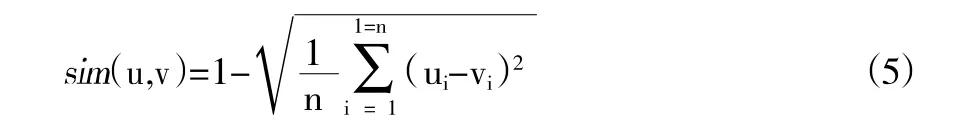
③利用公式(6)更新读者聚类中心,采用每类读者相似度的平均值作为新的中心。利用新的中心点,跳转到第2步,重新聚类。[11]
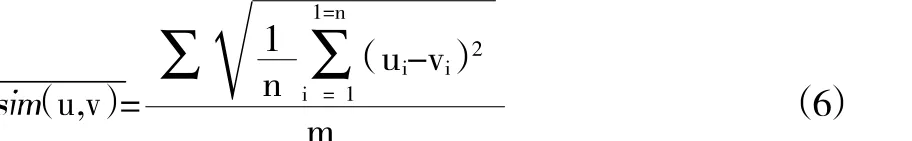
(3)计算读者特征相似度及兴趣相似度。
①计算读者特征相似度。在图书管理系统中,所有读者均有个人特征,通过对读者分析,按照性别、年龄、专业及教育背景进行分类,读者之间的相似度可以用特征相似函数表示,[12]如公式(7):
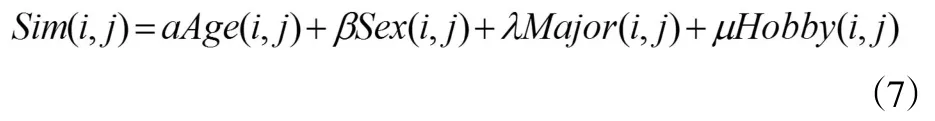
其中,Sim(i,j)读者i和j的特征相似度,Age(i,j)、Sex(i,j)、Major(i,j)及Hobby(i,j)分别表示读者间年龄、性别、专业及爱好相似度。
②计算读者兴趣相似度。根据聚类后的读者评分矩阵,利用修正余弦公式(3)计算读者兴趣相似度。
(4)计算读者综合相似度,生成读者最近邻居集。读者综合相似度的计算方式是将读者的特征相似度和兴趣相似度结合起来,如算法公式(8)。该计算方式既考虑了读者的客观特征相似度,同时兼顾了读者的主观兴趣相似度。比传统协同过滤算法更能全面地考虑读者的相似度。[13]利用公式(8)计算读者综合相似度后,可以利用阈值法生成目标读者的最近邻居集。
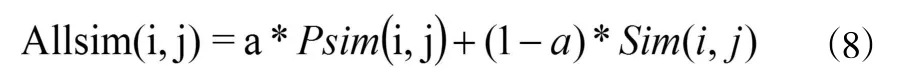
(5)预测目标读者评分,生成推荐结果。根据目标读者的最近邻居,利用公式(4)预测其对待评价图书的评分,得到对图书的预测评分后,对图书评分值进行降序排序,取评分最大的若干图书作为
推荐结果。[14]
3 改进后算法分析与实验
为了测试改进后算法推荐结果的效果,采用北京信息科技大学图书馆系统中的数据进行实验,其中,选取1000名读者基本信息以及对1500个图书的评价数据,分别从推荐算法的准确性(MAE)、“冷启动”问题的解决及“数据稀疏性”问题的解决三方面比较改进前后算法。
(1)推荐算法的准确性。实验选用平均绝对误差比较改进前后算法,[15]如公式(8),其中,n表示图书的个数,P表示读者对图书的预测评分,ri表示读者对图书的实际评分。计算出来的平均绝对误差(MAE)越小,表示推荐质量越高。[16]

使用公式(8)计算出来的结果如图4所示。
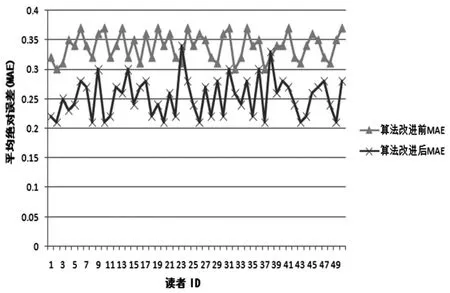
图4 改进前后算法平均绝对误差比较
s
由分析结果可见,改进后算法的推荐结果整体上平均绝对误差均比改进前低,反映了改进后的算法能够提供较好的推荐质量。[17]
(2)“冷启动”及“数据稀疏性”问题。“冷启动”问题最典型的是系统新加入新的读者用户,重点分析改进前后算法对新的读者推荐预测效果。[18]随机从系统中选取10名新读者,通过对其推荐预测结果见表。
从表中可见,改进前算法对新读者不能产生推荐,改进后的算法可以向新读者提供推荐服务,而且准确
率较高。因而,新的算法能够解决推荐算法常见的“冷启动”问题。[19]
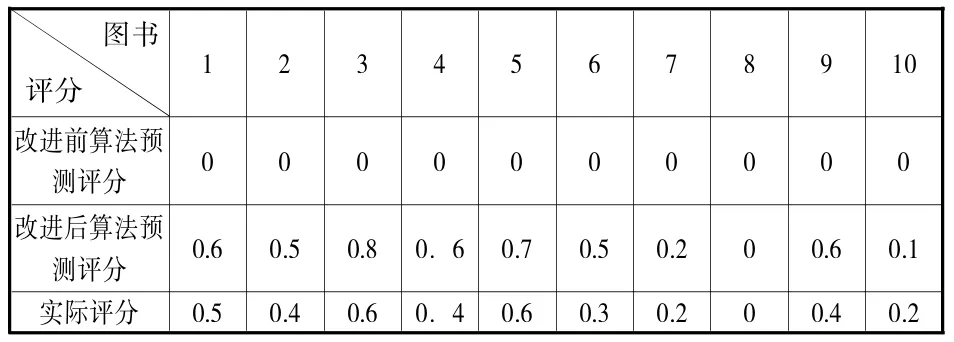
表 改进前后算法对新读者预测结果比较
改进后的算法,利用聚类算法将相似特征的读者进行聚类,根据每类读者生成评分矩阵,从而降低了数据的纬度,减少了系统的计算量,进而提高了算法推荐的准确性和实时性,间接地解决了改进前算法遇到的“数据稀疏性”问题。
4 结论
协同过滤算法凭借算法简单容易实现、对数据对象依赖性低及推荐准确率高等特性,被图书推荐系统广泛采用。针对传统协同过滤算法会遇到“冷启动”及“数据稀疏性”问题,同时忽略了用户兴趣实时变化及多样性的特点。本文在传统协同过滤算法的基础上引入聚类算法,利用读者的特征信息对其进行聚类,并将聚类后的读者对图书的评价转化为评分矩阵,分别计算每类读者的特征相似度和兴趣相似度,通过分析读者整体相似性,在同类读者评分矩阵中找出相似度高的邻居,依据邻居推测其对待评价图书的评分,根据评分结果生成推荐结果,改进后算法缩小了查找最近邻居的范围,提高了算法的运算效率。同时兼顾了读者主观兴趣和读者自身的客观特征属性,一定程度上提高了算法的准确率,也解决了传统算法的“冷启动”及“数据稀疏性”问题。进而利用北京信息科技大学图书管理系统中的数据进行实验分析,结果证明新的算法比传统算法误差小,说明改进后的算法能够产生较高的推荐质量。
[参考文献]
[1]蒋鹏.上下文感知推荐系统的研究与应用[D].广州:华南理工大学,2013:1-3.
[2]靳立忠.基于用户兴趣聚类的协同过滤推荐技术的研究[D].沈阳:东北大学,2007:7-8.
[3]纪良浩.协作过滤信息推荐技术研究[J].重庆邮电大学学报(自然科学版),2012(1):78-82.
[4]程飞.基于用户相似性的协同过滤推荐算法研究[D].北京:北京交通大学,2012:5-6.
[5]任磊.推荐系统关键技术研究[D].上海:华东师范大学,2012:10-17.
[6]李军平.基于社会网络分析的协同过滤推荐方法研究[D].沈阳:辽宁大学,2013:1-6.
[7]孙歆.基于协同过滤技术的SCORM数字化教学资源库研究[D].杭州:浙江工业大学,2013:2-3.
[8]程淑玉.基于协同过滤算法的个性化推荐系统的研究[D].合肥:合肥工业大学, 2010:8-13.
[9]冯鑫.基于内容的自适应博客推荐方法的研究[D].包头:内蒙古科技大学,2012:7-9.
[10]王均波.协同过滤推荐算法及其改进研究[D].重庆:重庆大学,2010:4-6.
[11]王栋针.对网络热点事件观点漂移检测技术的研究与实现[D].沈阳:东北大学, 2012:6-10.
[12]吕振山.基于RBF神经网络的文本过滤技术研究[D].广州:暨南大学, 2008:23-30.
[13]杨春喜.Web文本内容过滤关键技术的分析与研究[D].广州:暨南大学,2007:15-24.
[14]袁新成.基于向量空间模型的自适应文本过滤研究[D].哈尔滨:哈尔滨工业大学,2006:6-9.
[15]杜娟.基于内容的网络信息过滤模型的应用研究[D].大庆:大庆石油学院,2009:8-11.
[16]古丽拜天·卡米尔.基于Web数据挖掘的智能推荐研究[D].长沙:中南大学,2010:16-20.
[17]Fu He-gang.Improvement of Item-Based CF Algorithm[J].Journal of Chongqing University of Techonology,2011(9):69-74.
[18]Shi Hua.Item-Basedand User-Baseddoubleclustering Collaborative Filtering Recommendation Algorithm [D].Changchun:Dongbei Normal Univesity,2009:20.
[19]Wu Yue-ping,Zheng Jian-guo.Improvedcollaborative filtering recommendation algorithm[J].Computer EngineeringandDesign,2011(9):3019-3021.
[收稿日期]2014-09-12 [责任编辑]邵晋蓉
[作者简介]孙彦超(1978-),男,河南南阳人,信息系统项目管理师,研究生学历,主要研究数据库与信息系统、数据挖掘等。
[基金项目]本文系北京信息科技大学2015年度教学改革立项“基于大数据的学籍状态检测与预警方法研究”(项目编号:2015JGZD06)资助成果之一。
[文章编号]1005-8214(2015)05-0076-04
[文献标志码]A
[中图分类号]G252.1
