基于数据挖掘技术的高校图书馆个性化书目推荐服务研究
2015-12-27陶硕马鞍山职业技术学院安徽马鞍山243000
陶硕(马鞍山职业技术学院 安徽马鞍山 243000)
基于数据挖掘技术的高校图书馆个性化书目推荐服务研究
陶硕
(马鞍山职业技术学院 安徽马鞍山 243000)
数据挖掘技术在高校图书馆个性化书目推荐服务中的应用很有必要,阐述个性化书目推荐服务系统的设计目的和设计思路,设计了个性化书目推荐系统的整体构架、功能模块和工作流程,最后指出了数据挖掘的主要实施过程,数据源的选取和借阅信息处理等。
数据挖掘技术;个性化服务;书目推荐;高校图书馆
数据挖掘又可以认为是从数据库中发现知识,是一个对大量数据进行分析的复杂过程,通过这一过程可以把未知的、有价值的模式等知识抽取挖掘出来。数据挖掘设计的学科领域很多,是一个交叉学科领域,使用的方法也很多,包括数据库技术、神经网络、可视化等等。
一、数据挖掘技术应用在高校图书馆个性化书目推荐服务中的必要性
(一)高校图书馆信息资源极大丰富化的需要。图书馆经过这么多年的积累和沉淀不仅有浓厚的文化氛围,更有系统的专业知识和丰富的馆藏资源是互联网资源无法可比的。伴随着人们对与数字图书馆相关的多媒体大数据信息的研究,图书馆与网络技术的结合也逐渐成为一种趋势。现在,人们对馆藏资源可视化的研究主要包括可视化检索的研究和可视化检索结果的研究。数字图书馆信息资源可视化当前突出的问题,不只是数据资源的丰富和可视化效果要好,馆藏资源的数字化过程也是个大问题,有些资源的保存介质是很久以前的纸质,这些信息数据的数据库录入工作就不是件容易事,这在很大程度影响到数字图书馆的馆藏资源的可视化过程。
(二)高校图书馆用户信息需求的多样化的要求。在高校图书馆中,用户信息需求有其多样化的特点[1],主要表现在三个方面:首先是用户信息需求主体的多样化,需求主体多样化导致信息用户不断增多,不断增多的用户群体之间又存在不同的信息需求;其次是信息需求内容的多样化,需求内容多样化使得用户有了更多可选择的信息源,不同的用户可以获取不同的信息内容;最后是用户信息需求方式的多样化,需求方式的多样化提供了更多的途径方便用户获取信息。不同的用户可以根据自己本身的阅读需求,从高校图书馆中可以自由选择信息获取的方式和内容。
二、数据挖掘在高校图书馆中的应用
(一)图书文献推荐工作中的应用。高校图书馆中最主要、最基础的就是图书文献资源,图书馆中文献资源的利用率是评价图书馆各项服务质量高低的最主要因素之一,特别是个性化服务质量的评价所占比重更大。所以,在高校图书馆中,个性化书目推荐工作是整个图书馆服务的重点。
采用聚类分析或者关联分析的方法研究读者的历史借阅数据时,数据挖掘技术的利用有利于关联规则的发现,对于读者在图书馆中图书文献的借阅提供理论支持,简单理解也就是不同的读者借阅的图书类型不同,而且同一读者也可能会借阅不同类型的图书,通过计算类型相关图书文献之间的关联规则,可以分析得到置信度和支持度,进而可以构建得出读者的借阅模式,形成图书馆馆藏资源基础上的图书推荐数据库,通过对读者借阅行为的分析从数据库中推荐相对有用的图书西苑给读者。例如,通过关联分析读者的借阅行为,关联性较强的有计算机编程和数据库类型的文献,那么当读者有意向对计算机编程语言图书进行借阅时,就可以个性化的向读者推荐数据库类别的资源,不仅节省了读者的查找时间,还能帮助读者更好的学习,图书馆服务的质量得到提高。
(二)文献检索中的应用。在高校图书馆提供的个性化信息推荐服务中,其中的重要一环无疑就是文献检索。在传统的文献检索中,图书馆仅能把一些简单的馆藏文献资源提供给读者,而不是进行个性化推荐服务,更遑论参考读者的阅读喜好和规律。
图书馆在对读者提供个性化推荐服务时,在目标的实现过程中应用数据挖掘技术可以减轻工作强度。首先是数据准备阶段,数据信息是数据的基础,所以数据的收集对应的也是数据挖掘技术应用的基础,收集的数据主要是读者历史借阅行为,这种类型的数据收集本身就是一项巨大的工程,在图书馆后台数据库中,数据资源是海量的,数据的收集不仅要收集读者的历史借阅激励,还要把相关的读者预约和续借等信息都收集起来。其次,是数据筛选和处理阶段,该阶段的数据筛选主要是处理上阶段收集到的数据,包括噪声和重复数据的消除等。然后把处理后的数据进行预处理和转换,至此构建完成结构化的数据库,有助于数据挖掘算法的进一步实施。第三,是数据挖掘阶段,该阶段是运用关联分析和聚类分析等方法研究建立的数据库,把不同类型读者阅读的喜好和借阅书目信息分析出来。最后,结合可视化技术,利用以上分析结果,把个性化的文献推荐服务提供给读者,当读者进行文献的检索时,通过推荐集把与读者搜索文献相关的其他文献自动推荐给读者,同时根据读者喜好进行相关优秀文献的推荐,不仅能有效的进行读者的导读推荐,还能以可视化的方式把有用的数据信息呈现给读者。
(三)馆藏书架管理的优化。在高校中,师生教研工作的开展进程中,作为一个重要的辅助部门,高校图书馆的馆藏文献资源十分丰富,其包含的内容不仅囊括了本所高校设置的专业领域资源,还涉及了其他相关的研究领域,能极其有效的帮助全校师生的教学和科研,并能提供给师生个性化的推荐服务。高校图书馆有着种类繁多的馆藏资源,正是因为如此,在高校图书馆科学发展中,馆藏书架管理工作的优化极为重要,而其中的一个重点方向就是图书文献变化趋势预估,在书架上给预测出的最新文献预留出位置,尽量减少书架上图书的倒架次数,做到旧文献的及时剔除,新文献的迅速上架。
上面所述馆藏书架的优化管理,可以通过数据挖掘技术的引入来实现,首先针对图书馆的历史图书文献借阅日志,选择预测分析技术进行数据分析,选用的方法为回归与时序分析方法,可以得出文献被借阅的周期变化,之后对整理好的图书流通日志进行具体分类,并采用统计方法对其进行统计分析,把借阅增幅较大和借阅频繁的馆藏资源挑选出来,并根据这些数据按照排架规则进行图书的上架管理,在容易查找的书架位置放置借阅量较大的馆藏资源,并预留位置给那些借阅增幅较大的馆藏文献,使图书的倒架次数减小。最后,要及时剔除陈旧文献,实时更新上架新文献,要对馆藏文献资源中的图书进行分类分析,统计出来已印刷新版的旧版图书、拥有过多副本的馆藏图书、残缺破损的图书以及规定时间已到不予以流通的图书,按照以上图书分类分别统计各类图书的数量及其具体所在书架位置,然后对整理好的图书做到及时的下架,并将下架信息反馈给相关管理单位,使图书馆馆藏文献资源的及时更新得到保障。
四、基于数据挖掘技术的高校图书馆个性化书目推荐服务系统设计
(一)系统结构设计。针对高校图书馆设计出的个性化服务模型图1可知,其基本流程从第一步的用户注册直至个性化服务的提供图中已经有详细的示意,首先是采集用户信息,然后根据信息数据对整体用户利用相关技术进行建模,最后匹配规则库与针对用户多构建的模型提供给用户个性化的信息服务。
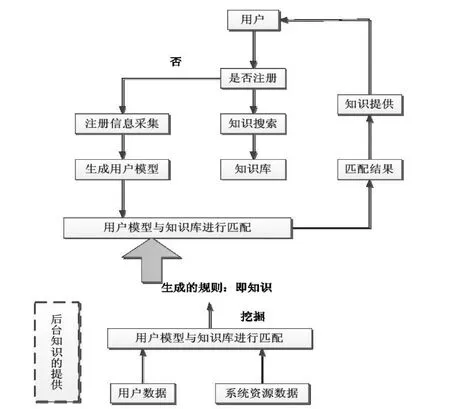
图1 切其于数据挖掘的个性化系统结构图
由上图所示,该个性化系统主要包括在线推荐模块和离线挖掘模块两大模块,分别表示为实线图和虚线图,而在知识库中,分别由资源的采集、存储、加工处理以及最后服务的提供一起构成了知识的获得。其中前三层提供数据基础给第四层的资源服务层进行知识的推送。在该模型中,数据采集阶段主要是对一些比较零散的数字信息进行采集,一般情况下包括图书馆的馆藏资源信息,读者基本信息、借阅记录以及检索记录,最后资源处理阶段要对采集到的信息进行加工处理,保证能实时进行数据库信息的更新,资源数据的时效性才能得到有效的保证。其知识资源获取结构如图2所示。
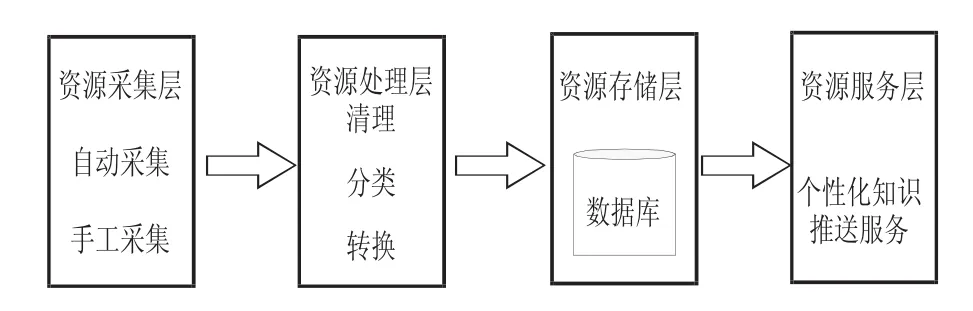
图2 知识资源获取结构
在资源采集层中,主要由两种信息采集方式:一种是自动采集方式,读者在图书馆进行借阅时,系统提取借书证中的读者个人信息并在读者信息库中进行存储;一种是对读者信息进行手工采集,这主要是在读者借书证中存在不完全的个人信息记录的情况下才会采用,这部分信息不全的读者在借书时,工作人员需要对读者遗缺的信息进行手工的补充。在资源处理层中,要清理不规范的数据并进行适当的格式转化,使数字信息可被数据挖掘识别,最后通过数据挖掘,存储转换后的知识并提供给读者个性化的服务。
(二)系统功能描述。
首先是收集用户信息模块,该模块还有两个子模块,分别为图书信息采集和读者信息采集模块。在前一个模块中主要是准备全面的图书信息提供给后期的数据处理过程,这些采集的主要内容包括书名、索书号、出版社信息以及作者,有些还包括图书馆分类号,在读者进行图书的借阅以及个性化推荐图书时就可以提供给用户以上详细的书籍信息,方便用户的使用。后一个子模块不仅要收集用户的注册信息,还要更全面的对能体现用户个性的各类信息进行详细的收集。
其次是用户模型分析模块,在这个阶段是针对用户生成具体模型的,也即是分析上述采集到的信息,将读者按照数据背后隐藏的规律进行分类,进而把读者借阅模型构建出来。
最后是个性化推荐模块,该模块也是最核心的内容所在,推荐算法的不同决定着推荐系统的差异,其具体划分如下所示:系统过滤[2];基于内容的推荐系统[3];混合推荐系统[4]及基于规则的推荐系统[5]。
个性化服务系统通过以上三个模块的分析,就可以实现个性化服务的提供,不仅展示了图书馆个性化服务个性化的一面,还可以看出图书馆个性化服务提供的主动性。在读者对资源没有明确的需要时,这种功能根据读者的以往借阅记录,参考与其相似读者的属性对读者的借阅行为进行预测,从而提供给读者个性化的服务。
(三)系统工作流程。总的工作流程,将从读者和图书馆的后台数据库两方面同时开展。首先,从读者的角度来说,根据网站的注册信息在首页输入账号和密码就可以选择进入个性化界面,实现人机交互,对各类书籍信息进行查询,同时可以参考系统提供的个性化推荐。另外,从图书馆的后台数据方面来说,个性化系统对读者的个人信息和特点进行后台的调取,然后把以上进行分类再分析,把具体的读者借阅模型构建出来,再利用数据挖掘技术中的关联分析把其中关联关系最好的资源推荐给读者。其工作流程如图3所示。
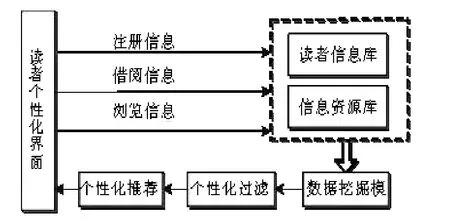
图3 系统工作流程
五、结论
数据挖掘技术在高校图书馆个性化书目推荐服务中应用的优势很明显。在网络时代背景下图书馆在数字化进程中馆藏文献资源愈加丰富,在数字化进程中应用数据挖掘技术能更好的发挥出高校图书馆信息服务的作用,对提高图书馆的服务质量具有重要意义。
[1]杨雪霞.数据挖掘技术在高校图书馆管理系统中的应用研究[J].软件,2012(6).
[2]杨芳.数据挖掘在高校图书馆个性化信息服务中的应用[J].科技情报开发与经济,2012(1).
[3]李静.数据挖掘技术在高校图书馆个性化服务中的应用研究[D].天津大学,2012(5).
[4]刘显显.基于数据挖掘的高校图书馆个性化信息推荐方法研究[D].辽宁大学,2013(5).
[5]王斌.数据挖掘在高校图书馆服务中的应用研究[D].西安理工大学,2010(5).
[责任编辑 郑丽娟]
G252
A
2095-0438(2015)11-0138-03
2015-06-27
陶硕(1973-),女,安徽枞阳人,马鞍山职业技术学院讲师,研究方向:数据挖掘。
