基于FVQMM的说话人识别方法*
2015-12-26杨彦赵力
杨 彦 赵 力
(1. 江苏盐城工业职业技术学院汽车工程学院,盐城,224005; 2. 东南大学信息科学与工程学院,南京,210096)
基于FVQMM的说话人识别方法*
杨 彦1赵 力2
(1. 江苏盐城工业职业技术学院汽车工程学院,盐城,224005; 2. 东南大学信息科学与工程学院,南京,210096)
为了进一步提高基于高斯混合模型的与文本无关说话人识别系统的识别性能,本文针对高斯混合模型在建模时需要较多的训练数据的缺陷,提出了一种新的应用于小样本说话人识别系统的与文本无关说话人识别方法,该方法综合考虑了模糊集理论、矢量量化和高斯混合模型的优点,通过用模糊矢量量化误差尺度取代传统高斯混合模型的输出概率函数,减少了建模时对训练数据量的要求,提高了模型精度和识别速度。同时由于模糊集理论起到了“数据整形”的作用,所以增强了目标说话人数据的相似性。实验结果表明该方法针对小样本数据的说话人识别系统,识别性能优于传统的基于高斯混合模型的说话人识别系统。
说话人识别;模糊集理论;矢量量化;高斯混合模型
引 言
自动说话人识别(Automatic speaker recognition, ASR)很久以来就是一个既有吸引力又有相当困难的课题。说话人识别技术按其最终完成的任务可以分为两类:自动说活人确认(Automatic speaker verification,ASV)和自动说话人辨认(Automatic speaker identification, ASI)。本质上它们都是根据说话人所说的测试语句或关键词,从中提取与说话人本人特征有关的信息,再与存储的参考模型比较后做出正确的判断[1]。另外,说话人识别按其被输入的测试语音来分可以分为与文本有关的说话人识别和与文本无关的说话人识别,而与文本无关的说话人识别在今天无疑有着更广泛的应用前景。
对于与文本无关的说话人识别,由于说话人的个性特征具有长时变动性,而且其发音常常与环境、说话人情绪和说话人健康有密切关系,并且实际过程中还可能引入背景噪声等干扰,这些都是与文本无关说话人识别的识别率得不到进一步提高的主要因素。通常说话人识别的经典方法是基于高斯混合模型(Gaussian mixed model, GMM)的识别方法,由于它作为统计模型能够吸收由不同说话人引起的说话人个性特征的变化,可以得到较好的识别性能。但是由于GMM作为统计模型对模型训练数据量有一定的依赖性,所以对于小样本的与文本无关说话人识别系统,要使GMM完全吸收由不同说话人引起的语音特征的变化去除话者差别非常困难,所以在实际应用中通常采用话者适应的方法使未知说话人的语音去适应已知标准说话人的语音模型。因此,近年来在说话人识别方法方面,基于高斯混合背景模型(Gaussian mixed model-universal background model, GMM-UBM)方法已成为主流的识别方法[2-3]。基于GMM超向量的支持向量机和因子分析方法[4-5]则代表GMM-UBM方法的新成果。尽管GMM-UBM方法作为目前主流的方法已得到共识,但同时一些局部的改进方法和针对不同应用的改进方法也非常有意义[6-10]。几乎所有成功的语音信号处理方法都是基于统计的、概率的或信息理论的方法。其中较具代表性的方法有矢量量化法(Vector quantization, VQ)和隐马尔可夫模型法(Hidden Markov modeling, HMM),而GMM是HMM中的一种。VQ方法是由Shore和Burton首先提出,并应用于特定人数码识别[11],其主要优点是无需时间规正或进行动态时间伸缩,同时对于模型训练数据依赖较小。但是,该方法对于由话者差别引起的语音特征变化的模型优化能力较弱。模糊集理论通过隶属度函数引入不确定性思想[12],实现对硬聚类算法的有效扩展,可以较好地吸收特征参数的变化,起到“数据整形”的作用,对于由话者差别引起的语音特征的变化,模糊集理论可以较好地起到模型优化的作用。模糊矢量量化采用模糊C均值聚类算法来实现矢量量化,在同样码本尺寸的情况下,通过模糊C均值聚类分析可以减少码本的量化误差,在实际应用中取得过较好的效果。
本文对于GMM在建模时需要较多的训练数据的缺陷,针对小样本的说话人识别系统,提出了一种基于模糊矢量量化混合模型(Fuzzy VQ mixed model, FVQMM)与文本无关的说话人识别方法,它综合考虑了VQ,GMM方法以及模糊集理论的优点。通过用模糊矢量量化误差尺度取代传统高斯混合模型的输出概率函数,减少了建模时对训练数据量的要求,提高了模型精度和识别速度。同时由于模糊集理论起到了“数据整形”的作用,所以增强了目标说话人数据的相似性。实验结果表明该方法针对小样本数据的说话人识别系统,识别性能优于传统的基于高斯混合模型的说话人识别系统。
1 基于GMM的说话人识别方法
为了说明基于FVQMM的说话人识别方法,首先必须介绍一下传统的基于GMM的说话人识别方法。GMM是M个成员的高斯概率密度的加权和,可以用下式表示
(1)
式中:x为D维随机向量;bi(x) (i=1,2,…,M)为每个成员的高斯概率密度函数;ai(i=1,2,…,M)是混合权值。完整的GMM可表示为λi={ai,μi,Σi}(i=1,2,…,M)。每个成员密度函数是一个D维变量的高斯分布函数,形式如下
(2)
对于一个长度为T的测试语音时间序列X=(x1,x2,…,xT),其GMM似然概率可以写作
(3)
或用对数域表示为
(4)
识别时运用贝叶斯定理,在N个未知话者的模型中,得到的似然概率最大的模型对应的话者即为识别结果
(5)
2 基于FVQMM的说话人识别方法
从式(1)可知,在基于GMM的说话人识别方法中,每一帧语音的得分值是通过每个成员的输出概率函数计算出的输出概率值。正确的输出概率函数的估计需要一定数量的训练数据训练得到。在说话人识别系统中,用于各说话人GMM训练的语料较少,给GMM的学习带来一定困难。而本文提出的基于FVQMM的说话人识别方法中,每一帧语音的得分值是每个成员通过用FVQ误差尺度取代传统GMM的输出概率函数,利用矢量量化误差值取代传统GMM的输出概率值得到的。即它的模型参数由混合权值和每个成员的码本组成,对于某个类别的模型,每一帧语音的得分值就是该帧语音与每个成员码本的量化误差值的加权和。识别系统对每个类别都预备一个相应的模型,利用各成员的码本逐帧计算输入序列的量化误差值,并计算所有输入帧的累积误差值。在N个未知话者的模型中,得到的累积量化误差值最小的模型对应的话者即为识别结果。
最小累积误差的计算可以通过维特比算法实现。其计算公式为
(6)
式中:x1,x2,…,xT表示输入时间序列;ai(i=1,2,…,M)是混合权值;Ci表示与成员i相对应的码本;d(xt,Ci) 表示xt和Ci间的距离, 该距离定义如下
(7)
可以通过维特比算法求取最小累积误差距离
(8)
式中:g(t) 表示输入时间部分序列x1,x2…,xt与模型间的最小累积距离;t=1,2,…,T;i=1,2,…,M。
对于一个给定的输入时间序列,识别系统将利用各类别模型逐帧计算该序列的量化误差值,得到最小累积量化误差值的模型所对应的类别即为识别结果。式(7)采用最近邻准则计算误差,也可以采用其他误差准则,如K最近邻准则,即
(9)
式中dk表示xt和Ci中所有码字的第k个最小距离。也可以采用概率形式
(10)
3 FVQMM模型参数的估计
在训练FVQMM之前,必须首先确定混合模型的成员数M,然后利用有效方法把训练数据集对成员数M进行分段,再利用归属成员M的训练数据集来训练第M个成员的FVQ码本。本文采用时间规整神经网络来分割训练数据集。整个FVQMM模型参数估计过程可以描述如下。
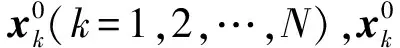
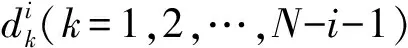

(11)
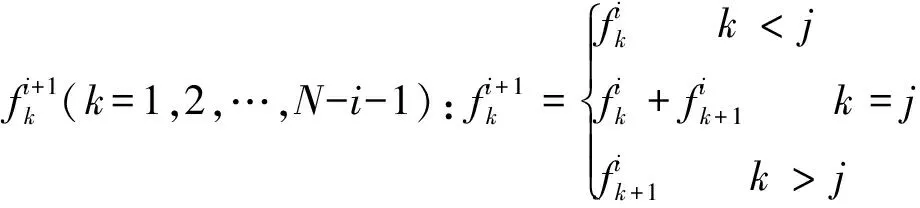
(12)
时间规整网络从语音信号的局部入手,依次合并具有最小帧距离的语音分析帧,合并过程有效地将语音过渡段融入各音素段,从而保证了最后的识别率不受说话人发音特点的影响,使得整个识别系统呈现出更强的鲁棒性[13]。
(2)每个成员的混合权值等于一个成员划分内的特征矢量数与训练数据集特征总数之比。
(3)每个成员的码本由成员划分内的特征矢量通过模糊C均值聚类算法(Fuzzy c-means algorithm FCM)聚类算法得到。FCM聚类是在引入模糊C划分后,对传统K均值聚类算法的模糊推广,它通过隶属度函数引入不确定性思想,实现对硬聚类算法的有效扩展,在实际应用中取得了非常优良的效果[14]。 首先定义FCM聚类算法目标函数为
(13)
(14)
FCM算法的收敛性在文献[14]中给出了证明。在迭代计算聚类中心ak及隶属度函数uk直到收敛后,由新的聚类中心组成重估后的新码本。
4 实验结果与分析
实验中采用的语音数据取自在实验室环境下录取10个人(5男、5女)的语音,其中每人对10,20,30,40 s左右时间长度的一段语音各说3遍作为训练数据,通过用这些数据进行训练得到每个人的模型参数。另外每人对30个不同的字词各说3遍共900个语音作为测试数据进行测试。
输入语音信号经12 kHz采样,1-0.98z-1的预加重,窗长21.33 ms(256点),窗移10 ms的汉明窗后,进行14阶线性预测编码(Linear prediction coding,LPC)分析,然后从14阶LPC系数中求出12阶的倒谱系数和倒谱的12阶线性回归1次系数,这些语音参数用于说话人识别实验。实验对FVQMM方法和GMM方法进行了比较,结果如表1和表2所示。
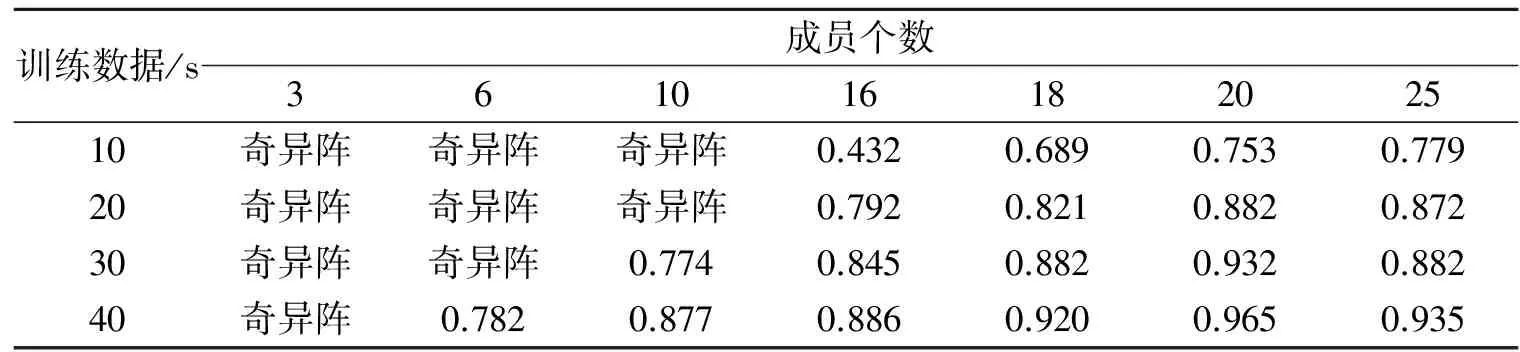
表1 GMM方法的说话人平均辨识率

表2 FVQMM方法的说话人平均辨识率(码本尺寸为32)
从表1和表2中可以看出,虽然最优结果出现在GMM,在训练数据为40s ,成员函数总数为20时,识别率为96.5%。而FVQMM的最好结果为95%,没有超过GMM的最好结果,但是,当训练数据较少时,FVQMM的结果明显好于GMM。而且,当训练数据较少时成员函数混合总数为3,6和10时,GMM训练会出现奇异阵,所以这是基于EM算法的GMM 方法存在的重大缺陷。为了找到最优的FVQMM各成员码本的码本尺寸,在成员个数一定的条件下(即取最好识别结果的成员个数为16,见表2),测量不同的码本尺寸的识别结果。实验结果如表3所示。
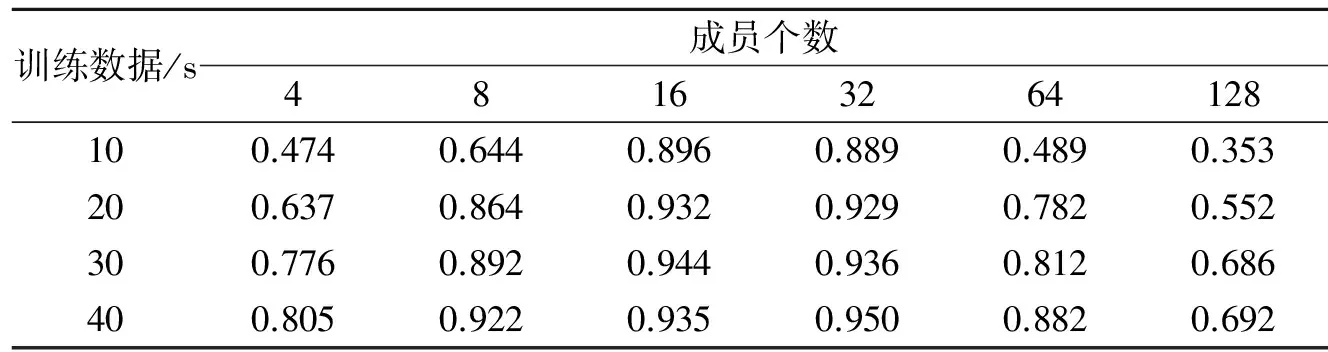
表3 不同码本尺寸时FVQMM方法的说话人平均辨识率
从表3可以发现,码本尺寸为16时识别结果比较好。这是因为在训练数据有限的情况下,码本分的太细反而会使代表码字的误差变大。从表1~3中可知,本文提出的FVQMM的识别性能一般优于传统的GMM,从而证明了这种新方法的有效性。
从另一个角度来分析,在一定的条件下,例如学习数据有限时,过多的模型参数往往不能得到好的学习精度。同时过多的模型参数也会给学习和识别增加运算成本,不利于实时的识别处理。为了分析比较提出的FVQMM和传统的GMM的参数数量,表4计算了取得最好结果时各模型所具有的参数总数。表中L表示码本尺寸,P=24表示语音特征矢量唯数,M表示成员混合数。从表中可知FVQMM参数总数比GMM要少的多。所以,虽然FVQMM是传统GMM的特殊形式,由于模型参数较少,在实验中取得了较好的识别结果。另外,本文提出的方法在FVQMM参数估计中,通过FCM聚类分析进一步减少了码本的量化误差,提高了码本的精度。

表4 各模型具有的参数总数
5 结束语
本文提出了基于FVQMM的说话人识别新方法,作为GMM的改进形式,它综合考虑了VQ和GMM方法的优点。该方法既可以弥补传统VQ方法对于由说话人个性特征长时变动性等引起的语音特征的变化吸收能力较弱的缺点,又可以弥补传统GMM 在建模时需要较多的训练数据的缺点。由于其模型参数数量较传统GMM少,模型学习对训练数据量要求不高,所以具有学习收敛速度快、识别速度快、适于实时自适应学习和小样本数据的说话人识别系统等特点。实验证明该方法在模型训练数据较少的情况下可以取得比传统GMM和VQ 方法更好的识别性能。下一步的工作是实验验证FVQMM方法是否可以应用到现在主流的GMM-UBM说话人识别方法中,并通过主流的NIST评测来进行实验验证。
[1] 赵力.语音信号处理[M]. 北京:机械工业出版社:2009,236-253.
[2] Soonil K, Shrikanth N.Robust speaker identification based on selective use of feature vectors[J]. Pattern Recognition Letters, 2007 (28): 85-89.
[3] Dehak N, Dehak R, Kenny P.et al. Comparison between factor analysis and GMM support vector machines for speaker verification[C]// The Speaker and Language Recognition Workshop (Odyssey 2008). Stellenbosch, South Africa: ISCA Archive, 2008: 21-25.
[4] Campbell W M, Sturim D E, Reynolds D A, et al. SVM based speaker verification using a GMM supervector kernel and NAP variability compensation[C]// Acoustics, Speech and Signal Processing of ICASSP 2006, IEEE International Conference on. Toulouse, France: IEEE, 2006: 97-100.
[5] Yin Shou-Chun, Richard R, Patrick K, A joint factor analysis approach to progressive model adaptation in text-independent speaker verification[J]. IEEE Trans on Audio Speech and Language Processing, 2007, 15:1999-2110.
[6] 何勇军, 孙广路, 付茂国,等. 基于稀疏编码的鲁棒说话人识别 [J]. 数据采集与处理, 2014, 29(2):198-203.
He Yongjun, Sun Guanglu, Fu Maoguo, et al. Robust speaker recognition based on sparse coding [J]. Journal of Data Acquisition and Processing, 2014, 29(2):198-203.
[7] 花城, 李辉. 小训练语料下基于均值超矢量聚类的说话人确认方法 [J]. 数据采集与处理, 2014, 29(2):238-242.
Hua Cheng, Li Hui. Speaker verification based on supervector clustering with poor corpus [J]. Journal of Data Acquisition and Processing, 2014, 29(2): 238-242.
[8] 王华朋, 杨军, 许勇. 应用似然比框架的法庭说话人识别[J]. 数据采集与处理, 2013, 28(2):240-243.
Wang Huapeng, Yang Jun, Xu Yong. Forensic speaker recognition in likelihood ratio framework [J]. Journal of Data Acquisition and Processing, 2013, 28(2):240-243.
[9] 王敏, 赵鹤鸣, 张庆芳. 基于瞬时频率估计和特征映射的汉语耳语音话者识别[J]. 数据采集与处理, 2011, 26(2):687-690.
Wang Min, Zhao Heming, Zhang Qingfang. Speaker identification with Chinese whispered speech based on instantaneous frequency estimation and feature mapping[J]. Journal of Data Acquisition and Processing, 2011, 26(2):687-690.
[10]奚吉, 赵力, 左加阔. 基于改进多核学习的语音情感识别算法[J]. 数据采集与处理, 2014, 29(5): 730-734.
Xi Ji, Zhao Li, Zuo Jiakuo. Speech emotion recognition based on modified multiple kernel learning algorithm [J]. Journal of Data Acquisition and Processing, 2014, 29(5): 730-734.
[11]Shore J E, Burton D K Discrete utterance speech recognition without time alignment[J]. IEEE Trans, 1983,29(4):473-491.
[12]李忠国, 侯杰, 王凯, 等. 模糊支持向量机在路面识别中的应用[J]. 数据采集与处理, 2014, 29(1): 146-151.
Li Zhongguo, Hou Jie, Wang Kai, et al. Application of fuzzy support vector machine on road type recognition[J]. Journal of Data Acquisition and Processing, 2014, 29(1): 146-151.
[13]Chen Sin Horng, Chen Wen Yuan. Generalized minimal distortion segmentation for ANN-based speech recognition[J].IEEE Trans on Speech and Audio Processing, 1995,3(2):141-145
[14]Bezdek J C. A convergence theorem for the fuzzy ISODATA clustering algorithms[J]. IEEE Trans,1990(2):1-8.
Speaker Recognition Based on FVQMM
Yang Yan1, Zhao Li2
(1.School of Automobile Engineering, Yancheng Institute of Industry Technology, Yancheng, 224005,China; 2.School of Information Science and Engineering, Southeast University, Nanjing, 210096, China)
In order to further improve the performance of speaker recognition system based on the GMM independent of text, a new speaker recognition method is applied to the speaker recognition system with small samples and text independent. Aiming at the large quantity demanded of training data during the modeling of the GMM, the advantages of the fuzzy-set theory, vector quantization and the GMM are considered. Then through replacing the output probability function in the traditional GMM with the error scale of the fuzzy VQ, the requirements of the training data amount are reduced while improving the accuracy and recognition speed of the model. Meanwhile as a result of the fuzzy-set theory playing a role of "plastic date", the similarity in the data of the target speakers is enhanced. Experimental results exhibit that the speaker recognition system of the method for the small sample data, achieves a superior recognition performance than the traditional speaker recognition system based on the GMM.
speaker recognition; fuzzy-set theory; vector quantization; Gaussian mixed model
国家自然科学基金(61273266)资助项目;教育部博士点专项基金(20110092130004)资助项目;2014年江苏省青蓝工程资助项目。
2014-11-09;
2015-11-05
TN912.34
A

杨彦(1974-),女,副教授,研究方向:信号处理,电子与通讯,E-mail:yfyangyan@126.com。

赵力(1958年-),男,教授,研究方向:信号处理。
