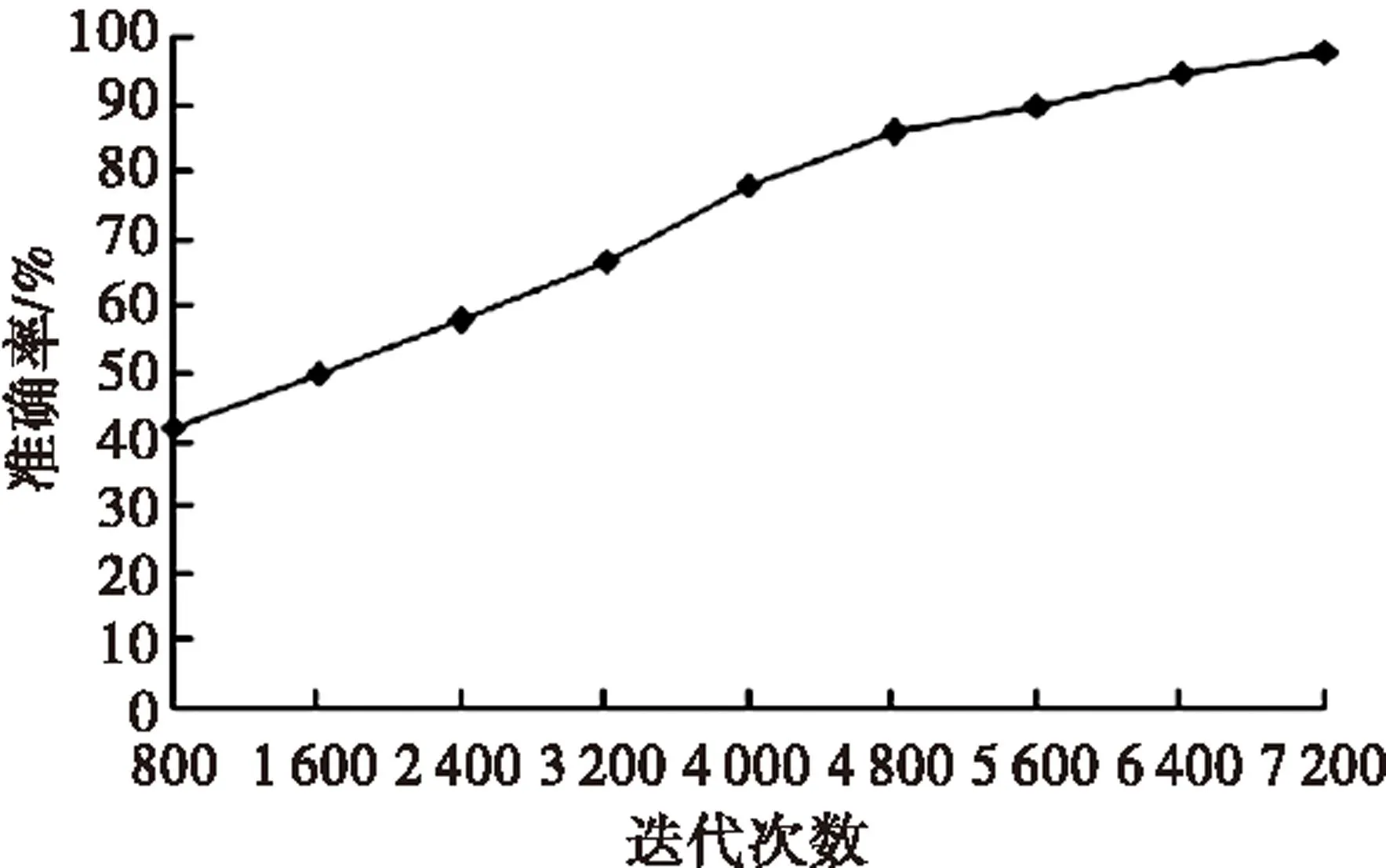
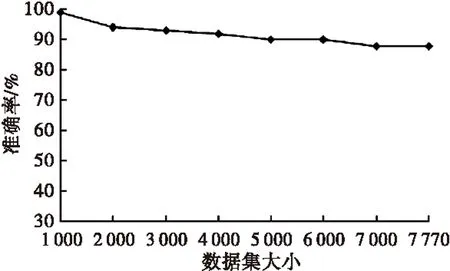
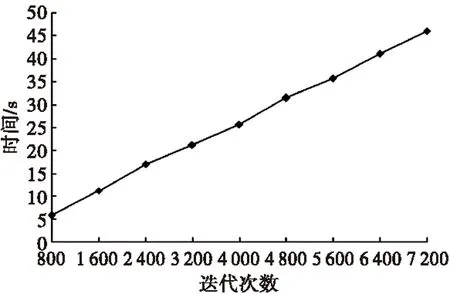
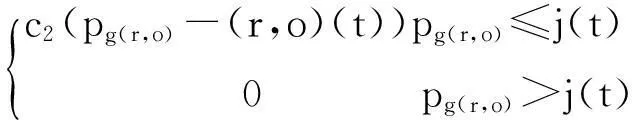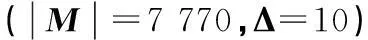基于微粒群算法的上下文离群数据挖掘算法
2015-12-25王也,张继福,赵旭俊
基于微粒群算法的上下文离群数据挖掘算法
王也,张继福,赵旭俊
(太原科技大学计算机科学与技术学院,太原 030024)
摘要:现有的离群检测方法大多都忽视离群数据的上下文信息,使得离群数据难以理解。从离群数据的可解释性角度,采用微粒群算法(PSO),给出了一种上下文有关的离群数据挖掘算法(COM-PSO)。该算法将数据属性作为上文有关信息,且将离群数据看作微粒;根据数据对象相对全局数据的频数,采用带有变异算子的PSO算法来搜索离群数据;最后UCI数据,实验结果验证了该算法的有效性,并具有效率高、可解释性强等特点。
关键词:离群数据;上下文有关;微粒群;可解释性;频数
收稿日期:2014-11-24
基金项目:山西省青年科学
作者简介:王也(1991-),男,主要研究方向为数据挖掘及应用、并行计算。
中图分类号:TP311文献标志码:A
离群数据(outlier)是显著不同于其它数据,不满足数据的一般行为或模式,与存在的其它数据不一致[1]。离群数据挖掘有着广阔的应用前景,如医疗处理,传感器/视频网络监视和入侵等。
目前,离群数据挖掘方法主要有:(1)基于统计学的方法[2],其核心思想是对数据的正常性做出假设,假设数据集服从某种分布或概率模型,通过不一致检验把那些严重偏离分布曲线的数据对象视为离群数据,但问题是:许多情况下,用户不了解数据集的分布,实际数据集往往并不符合理想数学分布。(2)基于距离的方法,该方法的基本思想是对给定的数据集,使用距离来量化数据对象之间的相似性。远离其他数据对象的数据将被视为离群数据。该方法的缺陷是:由于数据集不同,往往不容易设定距离阈值Dmin.(3)基于密度的方法[3-4],其核心思想是把数据对象周围的密度与其邻域周围的密度进行比较,将密度显著不同于其邻域周围的密度的数据对象定义为离群数据。该方法的问题在于其计算量非常大。
尽管大量的离群数据挖掘方法已经被提出[5-6],但是对于离群数据产生的原因进行分析和解释的工作相对较少。离群数据挖掘算法只是离群数据挖掘的第一步,更重要也是更具有挑战性的是要对离群数据产生的来源、含义及特征进行分析。Guanting Tang,Jian Pei等人在2013年SSDBM会议上提出了一个带有上下文信息的离群数据模型[7],并给出一种上下文有关的离群数据挖掘算法,但由于该算法先采用剪枝的方法缩小范围,再采用枚举的方法搜索离群数据,其挖掘效率低,且该模型缺少离群数据与正常数据的相似性。本文利用微粒群算法(Particle SwarmOptimization,PSO)具有简单容易实现,且没有许多参数需要调整等优势,采用带有变异算子的微粒群算法[8-10]来搜索上下文有关离群数据,不仅保存了上下文有关的信息,即:离群数据的可解释性信息,同时也提高了离群数据挖掘的效率。
1离群数据与上下文信息
设数据集R中有M个数据对象,数据属性的维数为N,数据对象为g(A1,A2,…,An),其中Ai作为维属性,A1,A2,…,An是数据对象g的属性值,表示为g.Ai,若属性值为空,则表示为all.参照文献[7],相关概念描述如下:
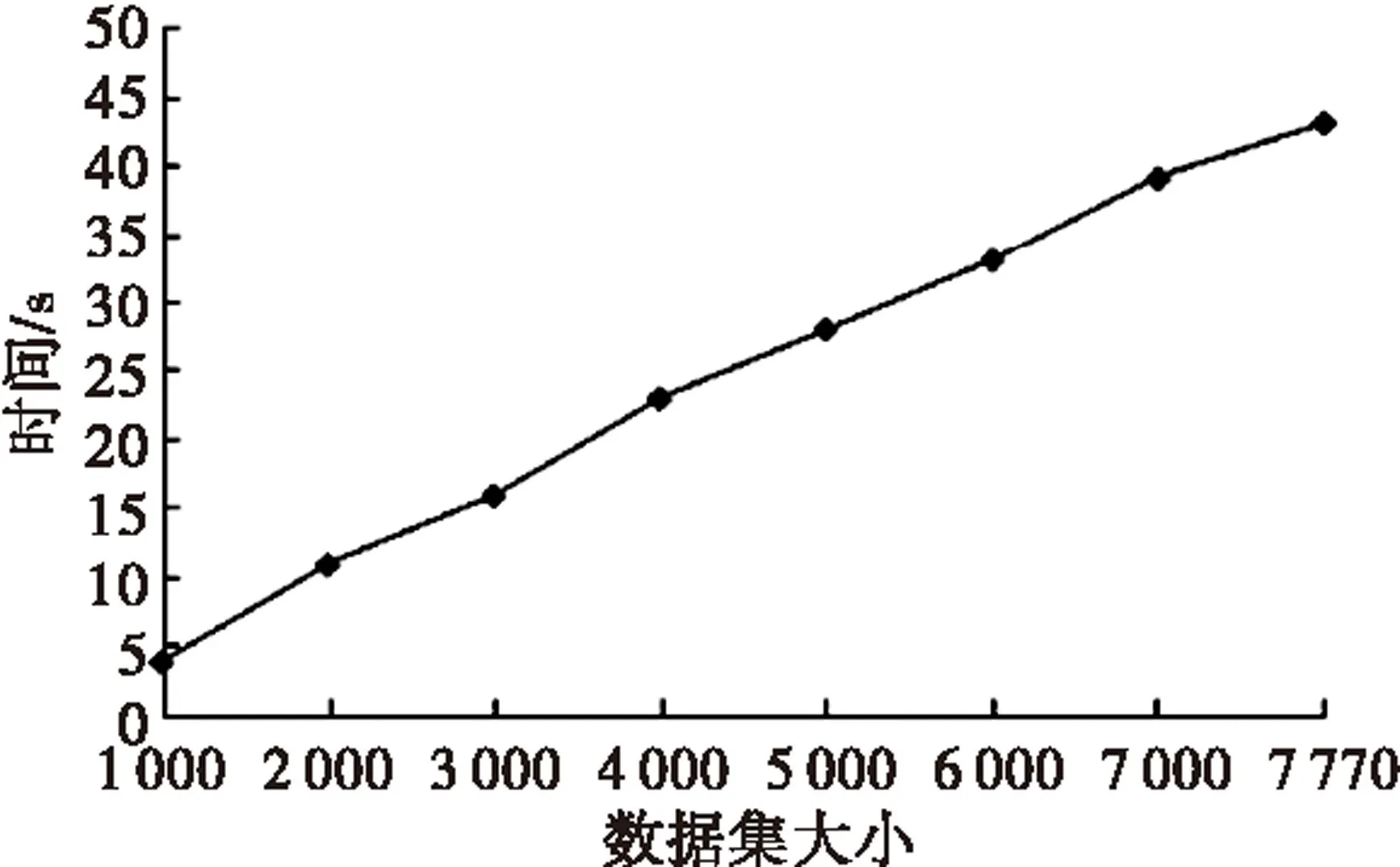
(1)
在公式(1)中,deg(r,o)衡量了数据对象o的离群程度,deg(r,o)越大,数据对象o相对r的离群程度也就越大。
对于数据集R中的两个数据对象g1g2,当g1.Ai≠All时,对于任意的属性Ai(1≤ i ≤ n),都有g1.Ai=g2.Ai,则称g1是g2的祖先,g2是g1的后代。表示为g1 离群数据的上下文信息包含:(1)离群数据的参考数据(r,o);(2)离群属性out(r,o);(3)离群数据数目;(4)离群程度deg(r,o).参考数据r表明离群数据o相比于哪些正常数据是离群的。离群属性out(r,o)=space(r)-space(cond(r,o))表明相比参考数据,离群数据在哪些属性上离群。共同属性值集也称离群数据与参考数据关系集合cond(r,o)=avs(r)∩avs(o)表明离群数据o和参考数据r相似关系,离群数据o在一些属性上与参考数据r有着共同的值,如果cond(r,o),则离群数据o和参考数据r没有共同特征。 2利用微粒群算法搜索上下文有关离群数据 2.1上下文有关离群数据 上下文信息是离群数据的组成部分之一,能够对离群数据的含义做出很好的解释,例如:“在X学校计算机专业学生中,未参加数据结构课程的3名学生相对于参加数据结构课程的128名学生就是离群数据。”,在该离群数据中,上下文信息包括:1)参考数据:参加数据结构课程的128名计算机专业学生;2)离群属性:未参加数据结构课程;3)离群数据数目:3;4)离群数据与参考数据的关系:均为计算机专业的学生;5)离群程度:128/3.由此可以看出,上下文信息很好的解释了该离群数据:相对于参加数据结构的128名计算机专业学生(参考数据),未参加数据结构课程的3名计算机专业学生(离群数据)在未参加数据结构课程的属性(离群属性)上,出现了异常,同时,他们都是计算机专业的学生(离群数据与参考数据的关系)。由此可见,离群数据的上下文有关信息,有效地解释了离群数据,对于离群数据的理解具有较大帮助。 设(r,o)为离群数据,其参考数据为r,离群属性为out(r,o),共同属性值集为cond(r,o),离群程度系数为deg(r,o),则称r、deg(r,o)、out(r,o)和cond(r,o)为(r,o)的上下文有关信息,具有上下文有关信息的离群数据(r,o)称之为上下文有关离群数据。对于数据集R中的任意两个上下文有关离群数据(r1,o1)和(r2,o2),如果r1>r2,o2>o2,cov(r1)=cov(r2),cov(o1)=cov(o2),那么deg(r1,o1)=deg(r2,o2).由此对比可以看出,(r2,o2)比(r1,o1)包含更多的属性,(r2,o2)更适合作为上下文有关离群数据。若上下文有关离群数据(r1,o1),不存在其他的上下文有关离群数据(r2,o2),r2 2.2利用微粒群算法搜索上下文有关离群数据 微粒群算法(Particle Swarm Optimization,PSO)是Kennedy和Eberhart受到鸟类群体行为的启发而提出的。该算法采用“群体”探索问题的空间[9,13],每个粒子按照一定的自适应速度在空间随机搜索,同时,每一粒子记忆自己所在空间的最优解,并以一定的加速度向自己所经历最好位置和群体中所有个体所经历的最好位置飞行。由于PSO算法具有实现容易、精度高,局部和全局搜索能力强等优点,从而对解决复杂环境中的优化问题非常有效[10-11]。 搜索上下文有关离群数据是根据参考数据与离群数据在数据集中出现频数之比为基础,通过计算参考数据(cov(r))与离群数据(cov(o))的频数之比,根据与给定的离群程度系数阈值△的关系来判断是否是离群数据。根据这一模型,将数据集中的任意两条数据看作为数据空间中的微粒i(r,o).两条数据对象分别定义为参考数据和离群数据,同时他们的属性值和标识符代表微粒的位置。数据对象每一次迭代的变化定义为微粒位置变化的速度。因此,微粒的位置可描述为:Xi(r,o)=(r,(Xr1,Xr2,…,Xrn)o,(Xo1,Xo2,…,Xon)),其中r,o为数据对象的标识符,Xr1,Xr2,…,Xrn,Xo1,Xo2,…,Xon为微粒i(r,o)中数据对象r,o属性值。由于微粒的位置由标识符r,o来确定,微粒位置的变化也就意味着标识符r,o的变化,因此微粒位置变化的速度,定义为:Vi(r,o)=(r,(Vr1,Vr2,…,Vrn)o,(Vo1,Vo2,…,Von)),VirVio分别对应为数据对象r,o的速度。由于把离群程度系数deg(r,o)大于阈值△的数据对象作为搜索结果,因此,把离群程度公式(1)定义为目标适应值函数。 根据数据对象的标识符r,o及其属性值是用整数表示的,则可采用整数规划问题的微粒群算法[14]。位置和速度的数值运算与整数的运算相同,相应计算公式如下: vin(t+1)=wvin(t)+c1r1[pij(t)-xin(t)]+ c2r2[pgn(t)-xin(t)] (2) xin(t+1)=xin(t)+vin(t+1) (3) 其中:rand(i)表示取随机数运算: 其中pi(r,o)表示微粒i(r,o)所经历过的离群程度最大数据对象,pg(r,o)表示所有微粒中离群程度最大数据对象。 3基于PSO的上下文有关离群数据挖掘算法 由于每一个封闭的上下文有关离群数据中的参考数据和离群数据必须是封闭的,所以,对于给定的数据集R,采用ClosedCube算法找出所有的封闭数据[8]。 根据以上所述,基于微粒群算法的上下文有关离群数据挖掘算法(Contextual Outlier Mining-Particle Swarm Optimization,COM-PSO)步骤如下: Algorithm COM-PSO 输入:数据集R,离群程度阈值Δ 输出:上下文有关离群数据 步骤1:初始化群体位置、速度、适应值、Pbest和Gbest,跳转至步骤7; 步骤2:按公式(2)(3)计算位置和速度; 步骤3:生成随机数r3,若r3 步骤4:根据公式(1)计算适应值; 步骤5:若存在某个微粒的适应值优于该微粒经历的最好位置Pbest,则用该微粒位置替换Pbest,反之Pbest保持不变; 步骤6:若存在某个微粒的适应值优于全局最好位置Gbest,则用该微粒位置替换Gbest,反之Gbest保持不变; 步骤7:若全局最优Gbest大于离群程度阈值Δ,则输出Gbest离群数据及离群程度系数deg(r,o),并重新初始化。 步骤8:若小于预定进化次数,则返回步骤2. 将输出的Gbest中的两条数据,作为参考数据和离群数据。Gbest的值作为离群程度系数。由此,可以更好的分析的上下文有关离群数据。 4实验分析 在Intel CoreTMi7-820M CPU,8G内存,Windows 8.1操作系统,用Microsoft Visual Studio 2013实现了COM-PSO和COD算法。采用UCI数据库中Solar-flare和Hayes-roth数据集,作为实验数据集。表1为寻找封闭数据时的一些统计数据。 表1 ClosedCube算法所用时间 4.1可理解性 在Hayes-roth数据集中,含有160条数据,每一条数据代表一个人的若干信息,包含5维属性。分别为姓名,爱好,年龄,教育水平,婚姻状况。首先,由于姓名和爱好是随机产生,在分析中我们将其忽略,姓名处理为标识符,爱好用All代替。年龄将其处理为{30,40,50},教育水平取值处理为{初中,高中,大专,本科},婚姻状况取值处理为{单身,已婚,离异,丧偶}。在离群程度阈值Δ=5的情况下,COM-PSO算法挖掘结果如表2所示,其中:“*”代表All. 表2 上下文有关离群数据 从表2中我们可以看到,上下文离群数据o1=(*,*,高中,离异)包含以下上下文信息:参考数据r1{*,*,高中,单身},离群属性out(r1,o1)={婚姻状况},离群数据与参考数据关系集cond(r1,o1)={高中},离群数目6和离群程度deg(r1,o1)=5.7.根据上下文信息,可以很好的理解离群数据o1:在教育水平为高中的群体中,6个婚姻状况为离异的人相比34个婚姻状况为单身的人是离群的,离群程度为5.7.同理,上下文有关离群数据o5也可以解释为:在30岁的群体中,4个丧偶的人相对于34个已婚的人是离群的,离群程度为8.5. 4.2性能分析 在Solar-flare数据集中,含有7 770条数据,每条数据表示在拍摄的功能有源区,包含13维属性。分别为光斑种类,最大光斑尺寸,光斑分布,光斑状态,光斑是否演化,24 h内光斑活跃状态,历史状态,历史上是否是复杂,区域,最大光斑区域,C级耀斑产量数,M级耀斑产量数,X级耀斑产量数。 设群体规模N=80,参数c1=c2=0.5,w=0.8,变异概率mp=0.4,将预设进化代数作为算法终止条件,实验结果如下所示。 由图1可以看出,COM-PSO算法随着迭代次数的增加,其挖掘精度也在增加,特别是当迭代次数超过7200代时,COM-PSO算法的精度达96%以上,其原因是COM-PSO 算法开始时,在给定一个非常大的Vmax(速度极大值)条件下,则能到达数据集中任何地点,但不能在一次迭代之内找到离群程度最高的数据对象;在迭代次数足够的情况下,则可能达到任何数据对象的位置,而且一旦搜索到大于离群程度系数阈值的离群数据,便重新初始化种群位置,避免了种群凝聚。图2表明,随着数据集的增大,在迭代次数一定时,COM-PSO算法的精度下降,其主要原因是随着数据规模变大,所包含的离群数据个数可能增加,同时由于迭代次数不变,所搜索到离群数据数目大致相同,因此可能导致挖掘精度降低。 图1 不同迭代次数的精度 图2 不同数据集的精度(△=10,次数=5 600 ) 由图3、4可知,随着数据集和迭代次数的增长,COM-PSO算法挖掘耗时也在增加,其主要原因是数据集增长导致每次迭代计算数据对象频数的时间增多,从而总体时间增大,而迭代次数的增多也就意味着计算数据对象频数的次数增多,耗时也增大。 图3 不同迭代次数的效率 图4 不同数据集的效率(△=10,次数=5 600) 由图5可看出,当数据集M和迭代次数不变时,离群程度阈值Δ对COM-PSO算法的挖掘效率影响较小,其主要原因是由于离群程度系数阈值在COM-PSO算法中,仅仅作为是否为离群数据的判断条件,而离群程度系数阈值在COD算法中,不仅作为离群数据的判断条件,而且还在剪枝步骤中,作为剪枝判断条件的一部分,从而导致COD算法效率受离群程度系数阈值影响较大。在离群程度阈值较小(Δ<25)时,COM-PSO算法的挖掘效率比COD算法效率高,其主要原因是COM-PSO算法在搜索迭代过程中,由于Vmax,每一次的迭代都是合理的,而在COD算法中,当离群程度系数阈值较小时,剪枝效率低,从而使得挖掘效率较低。 图5 不同程度系数的效率 ,次数=5 600) 5结束语 大多数传统的离群挖掘算法缺少对离群数据的解释,使得离群数据难以理解。将数据属性作为上文有关信息,并采用微粒群算法(PSO),给出了一种上下文有关的离群数据挖掘算法,从而有效地提高离群数据的可解释性。 参考文献: [1]KNNOR E,NG R.Algorithms for mining distance-based outliers in large datasets[C]∥Proc Of the 24thVLDB Conference.New York,USA:Morgan Kaufmann,1998:392-403. [2]BARNETT V,LEWIS T.Outliers in statistical data[M].New York,USA:John Wiley &Sons,1994. [3]SARAWAGI S,AGRNWAL K,MEGIDDO N.Discovery-driven exploration of olap data cubes[C]∥Valencia:Proc of IntConf Extending Database Technology (EDBT’98).LNCS 1377,Springer-Verlag,1998:168-182. [4]BREUNIG M,KRIEGEL H P,NG R,et al.LOF:Identifying density-based local outlier[C]∥Zytkow J M Rauch.Proc of the 3rd European Conference on Principles and Practice of knowledge Discovery in Databases.LNCS 1704,Prague,Czech:Springer,1999:262-270. [5]HAN J W,KAMBER M.数据挖掘:概念与技术[M].范明,孟小峰,译.2版.北京:机械工业出版社,2007. [6]楼巍,曹家麟.面向大数据的高维数据挖掘技术研究[D].上海:上海大学,2013.9. [7]GUANTING TANG,JIAN PEI.Mining multidimensional contextual outliers from categorical relational data[C]∥Scientific and Statistical Database Management’13,July 29 - 31 2013,Baltimore,MD,USA. [8]李盛恩,王珊.封闭数据立方体技术研究[J].软件学报,2004,15(6)1165-1171. [9]葛凌云,张继福,蔡江辉.基于微粒群算法和子空间的离群数据挖掘算法研究[J].系统仿真学报,2009,21(7):1897-1903. [10]仇晨晔,方滨兴.多目标微粒群算法研究及其在交通事故分析中的应用[D].北京:北京邮电大学,2013. [11]J KENNEDY,R EBERHART.Particle swarm optimization[C]∥Proceedingsof IEEE International Conference on Neural networks,NJ,WAAustralia.USA:IEEE Service Center,1995,IV:1942-1948. [12]屈向红,郭靖,夏桂梅,等.求解约束优化问题的改进微粒群算法[J].太原科技大学学报,2012,33(5):406-409. [13]孙超利,谭英,潘正祥,等.一种求解约束优化问题的微粒群算法[J].2010,31(6),453-457. [14]谭瑛,高慧敏,曾建潮.求解整数规划问题的微粒群算法[J].系统工程理论与实践,2004,24(5):126-129. Contextual Outlier Mining Algorithm Based on Particle Swarm Optimization WANG Ye,ZHANG Ji-fu,ZHAO Xu-jun (School of Computer Science and Technology,Taiyuan University of Science and Technology, Taiyuan 030024,China) Abstract:Most methods of outlier mining focus on outlier data objects and give little or no attention to contextual information.To enhance the interpretability of outliers,a contextual outlier mining algorithm (COM-PSO)was proposed by using particle swarm optimization.The attributes of data were considered as contextual information of outliers,and outliers were considered as particle swarm.Contextual outliers were searched with mutational PSO algorithm according to the frequency of data object relative to global data set.At last,the experiment results verified the effectiveness of the algorithm by using UCI machine learning repository. Key words:outliers,context,particle swarm optimization,interpretability,frequency