基于生理振动分析的手机用户身份识别
2015-12-23兰少峰
刘 升,兰少峰
(上海工程技术大学 管理学院,上海201620)
0 引 言
作为身份识别方法的一种,生物特征识别[1]具备安全性高、特征稳定[2]等特点。目前,较常用的识别方法为指纹、人脸识别等,虽然具有可唯一识别的性能,但难以抵抗伪造指纹膜、伪造脸型的攻击[3],也难以用于植入移动设备来保护个人信息。基于此,本文采用一种生物识别技术——生理振动信息,其更加具有不可伪造、难以破解、识别率高的特性。本文采用这种身份识别方法,利用用户的生物信息,通过智能手机内置传感器,采集用户的生理振动数据,进行数据去重力分析、特征提取、数据标准化化处理等。采用模式识别方法进行分类器设计,评价分类器优劣,得出查准率、误检率等评价指标,实现用户身份识别。
1 相关技术理论
1.1 智能手机内置加速度传感器
手机中的加速度传感器是手机中一个非常重要的传感器,主要作用是感应手机的运动状态。并且能够转换成可用的输出信号,它将获取手机的3个参数。
如图1所示,手机加速度传感器的三维坐标系是以屏幕左下方为原点,X 轴沿着屏幕向右,Y 轴沿着屏幕向上,Z轴垂直屏幕向上。
1.2 访问及获取传感器数据
在Android智能手机中,要想访问手机传感器并获取传感器数据,必须先获取传感器管理,然后注册传感器,传感器数值变化时,调用onSensorChanged (),最后保存传感器数据。
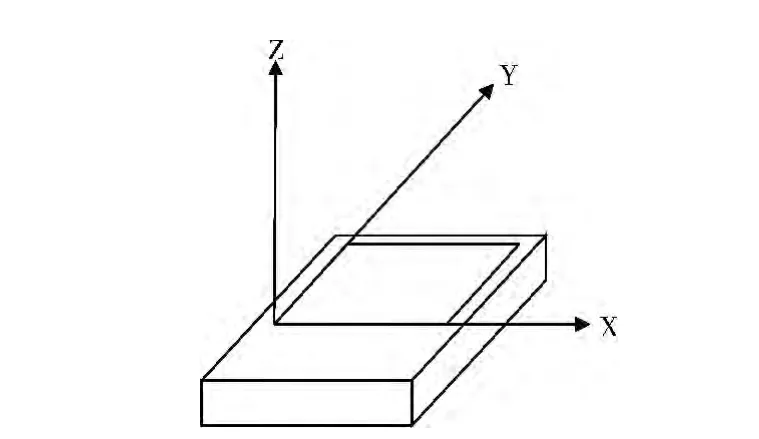
图1 手机内置加速度传感器三维坐标系[4]
SensorManager是传感器的一个综合管理类,包括对传感器的种类、采样频率、精确度等管理。要与传感器交互,应用程序必须注册一个监听器以检测一个或多个传感器相关的活动,可以使用registerListener()[5]注册一个传感器监听器。
SensorEventListener是传感器的监听接口,通常用on-SensorChanged (SensorEvnet)方法。监视传感器值的改变,该方法的参数是一个SensorEvent对象,该对象具有对象、精度、新值、事件4 个描述传感器的属性[6]。感应检测主要依靠该方法检测到环境的改变事件而确定,因为感应检测Sensor设备组件不同,所检测的事件也不同。SensorEvent类中的values 属性非常重要。加速度传感器的values变量的3个元素值分别表示X、Y、Z轴的加速度值。
在访问传感器之后,需要对传感器的数据进行提取。所有传感器的数值保存在SensorEvent。数值的长度和意义取决于当前的传感器类型。其包含三列值,分别表示加速度在立体坐标系X、Y、Z方向上的分量。
实验中,要采集不同用户的多组加速度传感器的数据。读取时,产生传感器的英文名称命名的txt文本文档,每个文本文档里包含四列数据信息:第一列是一个不小于0的数值,相当于一个计数器的功能;第二列是X 轴的数据;第三列是Y 轴的数据;第四列是Z轴的数据。
实验采集了多组样本,除了获取10组手机机主的传感器数据以外,还要获取50位手机机主以外的人的传感器数据作为测试数据,以此进行对比。按照上述方法重复操作,得到50组测试数据,其中,前10组为自己的数据,后50组为别人的数据。
1.3 数据处理
数据处理是对数据的采集、存储、检索、加工、变换和传输,是从大量的、杂乱无章的、难以理解的数据中抽取并推导出对于某些特定的人来说是有价值、有意义的数据的过程[7]。实验中,使用Matlab软件进行数据处理,首先从txt文本文档中读取从传感器获取的原始数据,然后提取其数据特征,如均值、方差、能量、偏度和峰度等,分析数据特征,最后对数据特征进行标准化处理。
1.3.1 数据预处理及特征提取
实验中,进行数据处理的是加速度传感器采集的数据,逐个读取60组样本数据。
原始数据是传感器X 轴、Y 轴和Z轴三维数据,以一组样本数据为例,图2是三轴的变化情况,其中横坐标是数据文件中第一列的数据,纵坐标为加速度传感器的3个轴的数值,即数据文件中第二、三、四列的数据。
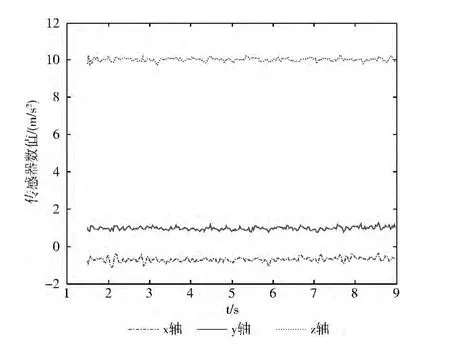
图2 原始数据
有图2以看出,Z轴的数值在9.8 m/s2上下徘徊,这是因为提取的原始数据中受到重力加速度的影响。重力加速度的影响要求在样本的训练和识别过程中都必须让手机在空间中处于相同的位置,这将很大程度上会影响身份识别的精确度。因此要测量设备的实际加速度,重力作用的影响必须要从加速度传感器数据中去除。

那么只要分别计算出3个轴所承受的重力,从原始加速度中减去就可以了,这样就可以得到需要的净加速度值。
设原始加速度样本xi,迭代控制参数为α(0<α<1),则重力g 可以近似表示为
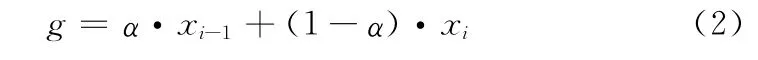
α越趋近于1,g 趋近于当前的x 的速度就越慢,由于样本数据前后变化不明显,重力加速度g 对它们的影响力相当,因此在实验中,选取α=0.5。以Y 轴为例,图3显示了去除重力加速度影响前后的对比效果。
对原始数据去重力影响后,就可以对数据进行特征提取了。特征提取是寻找某些信号特征来区别一种信号于另一种信号的不同,实验中,我们采用以下特征来进行讨论:
均值:计算每一列数据的平均值,均值的计算公式为

标准差:计算每一列数据的方差,标准差计算公式为
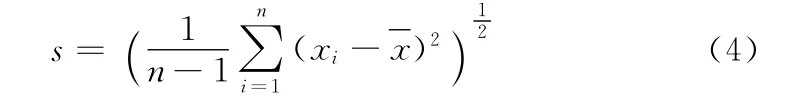
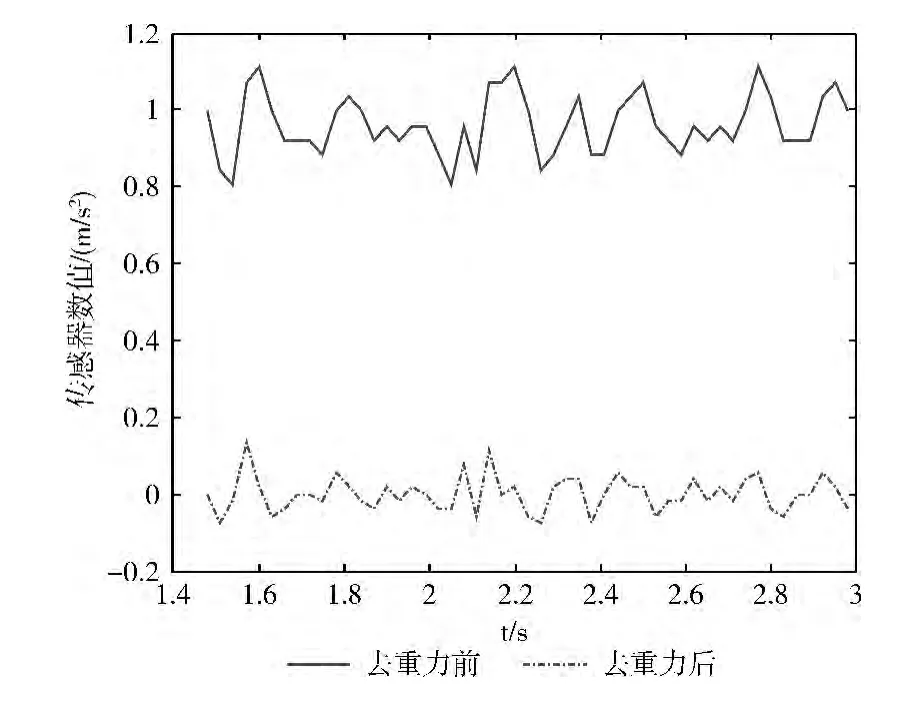
图3 去除重力加速度影响
能量:计算每一列数据的能量,计算能量的公式为

峰度:峰度又叫峰态系数,是描述分布形态的陡缓程度。有时两组数据的算术平均数、标准差都相同,但他们分布曲线顶端的高耸程度却可能不同,峰度的计算公式为

偏度:偏度用于衡量x的对称性。若偏度为负,则x均值左侧的离散度比右侧强;相反,则x均值左侧的离散度比右侧弱。偏度的计算公式为

提取到每一列的数据特征后,每一组样本数据都产生一个15行1列的向量,将其保存在指定数组中,其中1到5为X 轴的5个特征值 (依次为均值、方差、能量、峰度和偏度),5到10为Y 轴的5个特征值,11到15为Z轴的5个特征值。至此,特征提取结束。
1.3.2 数据标准化处理
由于不同变量常常具有不同的单位和不同的变异程度,这使得数据之间相互比较非常困难。比如第一列是均值,第二列是方差,第三列是能量等,在进行对比时,相互之间的关系系数具有很大的差异,那么直接对此矩阵进行处理有很多会出现问题。因此,为了消除数值大小和变量自身变异大小和量纲影响的影响,使得数据之间具有可比性,必须对数据进行标准化处理。
z-score标准化方法在统计学中是一种无因次值,是借由从单一 (原始)数据中减去母体的平均值,再依照母体(母集合)的标准差分割成不同的差距。实验中采用z-score标准化,计算公式[8]为

其中,σ≠0,x 是需要被标准化的原始数据,μ是样本的平均值,σ是样本的标准差。
标准化的结果是没有单位的纯数值,大小在零上下徘徊,标准差为1,这就消除了变量自身变异和单位的不同对实验结果的影响。
2 分类器的设计
2.1 分类器
设计分类器目的是为了在通过一定的学习和训练之后,能够将未知数据分类到已知类别。实验将设计合适的分类器,以便将机主身份与机主以外的人身份分离开来,从而进行用户身份的识别。近邻分类法,是最成熟的分类器设计方法之一,也是最简单的机器学习算法之一,在进行类别的判别时,只与有限个相邻的训练样本有关,在进行分类时,主要根据周围有限个邻近的训练样本的属性,这就是与传统的依靠判别类域的方法来确定属性的不同之处。文献 [9]表明,如果待分类集的类域有较多的重合或交叉,那么近邻分类法是最好的方法之一。
2.2 利用k-近邻算法进行分类器设计
k-近邻算法可简单描述为:取未知样本x 最近的k 个训练样本点,看这k 个训练样本点中多数属于哪一类,就即可将x 归于该类。具体地说,已知N 个训练样本,找出距离x 最近的k 个。在这N 个样本中,分为w1类、w2类、…、wc类共c 个类别,若k1,k2,…,kc,分别为k个近邻中属于w1,w2,…,wc类的样本数,则可以定义判别函数[10]为
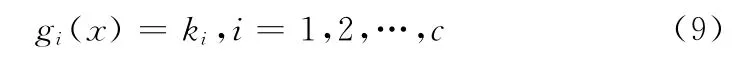
决策规则为:若gj(x)=则决策x ∈wj。
利用k-近邻算法进行分类器设计,实验通过Matlab软件来实现,首先读取样本特征数据,然后设定训练样本和测试样本个数及其类别,运用距离函数计算测试样本与训练样本的距离,来对测试样本进行分类。详细处理时,需要解决寻找适当的训练集、确定距离函数、决定k的取值、综合k个邻居的类别等问题。
2.2.1 寻找适当的训练数据集和距离函数
训练数据集是对历史数据的一个很好的覆盖,这样才能保证最近邻有利于预测,实验中,选取样本的前10组作为第一类的训练数据,第11组到第35组作为第二类的训练数据,选取的各类训练样本的数量不同,这是考虑到第一类(即自己本人)的样本数据之间的相似程度较大,而第二类(即别的不同的几个人)的样本数据之间的相似度较小,为了增加分类的正确率,设置第二类的训练集相对较大。
本文选用欧氏距离作为距离函数进行度量,空间中欧式距离的计算方法如下:n维欧氏空间是一个点集,它的每个点X 可以表示为(X[1],X[2],…,X[n]),其中X[i](i=1,2,…,n)是实数,称为X 的第i 个坐标,两个点A =(a[1],a[2],…,a[n])和B =(b[1],b[2],…,b[n])之间的距离d(A,B)定义为下面的公式
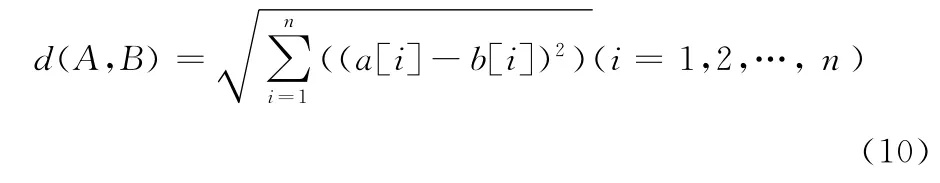
2.2.2 k的取值
k的取值大小,会对分类的结果有一定影响。如果选择较小的k值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,导致的问题是 “学习”的估计误差会增大;如果选择较大的k 值,相当于用较大领域中的训练实例进行预测,其优点是可以减少 “学习”的估计误差,但缺点是 “学习”的近似误差会增大。因此,一般先对k确定一个初始值,再进行调整,直到找到合适的值为止。实验中,由于采集的数据样本较少,k的取值也相对较小,分别取k=1,3,5,7,9进行分析比较。
3 分类结果分析
3.1 分类结果
本实验在MATLAB6.0环境下进行编程实现,硬件平台处理器为Intel Core i5CPU2.0GHZ,内存2.00G,操作系统环境为Windows 7,32位。k 值分别取1、3、5、7、9等值进行比较分析,分别将第1至第10组和第11至第45组作为第1和第2类的训练样本,然后选取样本的总体作为测试组。结果返回这类的类别。
利用k-近邻法进行模式分类后,实验结果见表1,其中类别1为自己的样本数据,类别2为别人的样本数据。
3.2 结果分析
为了能够清晰的看出取不同值时识别率的高低,结果见表2,k分别取1,3,5,7,9时的不同类别的正确识别率、错误拒绝率和总的识别率和错误率。由此表可以看出,k取1时的识别率最高,达到了98.33%,基本达到了实验要求的识别率,因此,选取k=1进行分类器的设计,可以用此方法进行手机用户身份识别。
4 结束语
利用生物特征识别技术,采用用户生理振动进行身份认证,是一种高效的身份识别方法。实验通过采集60 组不同用户的生理振动信息,最高达到了98.33%的识别率,识别结果表明该生物识别技术具有强有力的研究前景。实验也显示一些问题:样本容量较小、特征的选取基于低维的统计量、模式识别方法有待对比改进等。未来更大范围的扩展样本容量、采用高阶统计量更为丰富的特征、更为有效的模式识别方法将会进一步提升用户身份识别的效果。
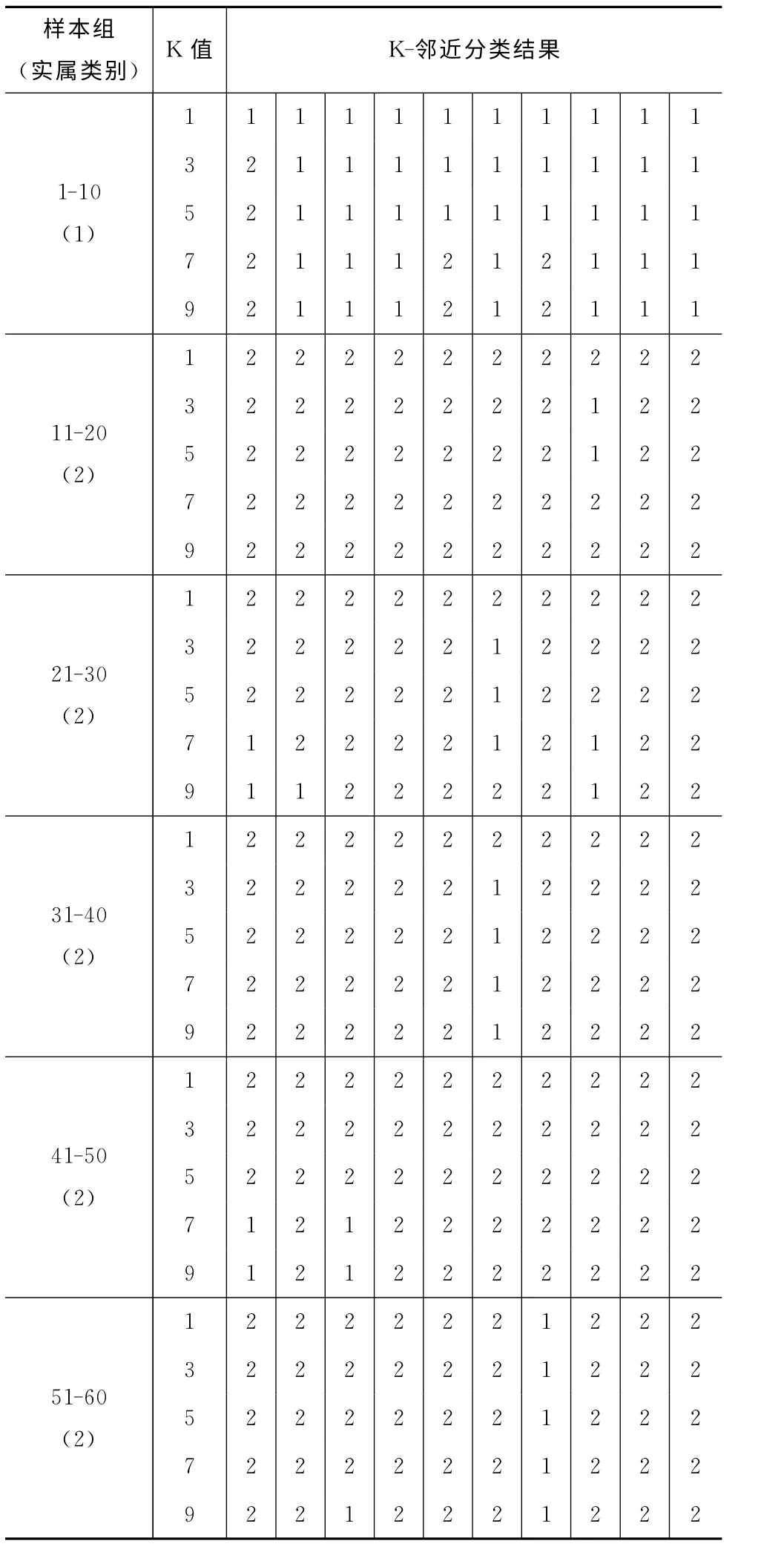
表1 实验结果
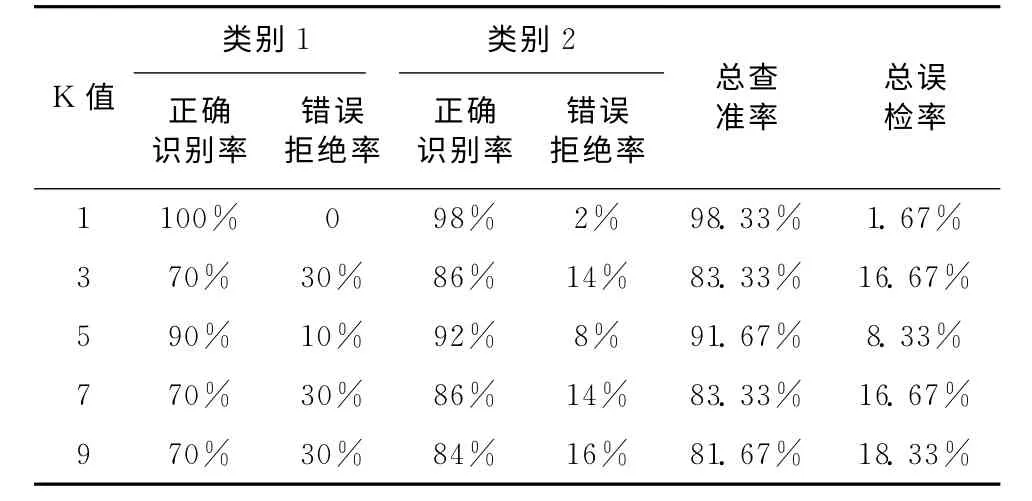
表2 不同k值的实验结果分析
[1]Wayman J.Biometrics in identity management systems [J].Security &Privacy,IEEE,2008,6 (2):30-37.
[2]Mordini E.Body,biometrics and identity [J].Bioethics,2008,22 (9):488-498.
[3]Wang S.Cloud computing lightweight authentication protocol[J]. Applied Mechanics and Materials, 2013, 284:3502-3506.
[4]Bartolini.Mobile sensor deployment in unknown fields[C]//Proceedings IEEE INFOCOM,2010:1-5.
[5]Allen G.Managing and accessing local databases[M].Begin-ning Android 4,2011:367-379.
[6]Zechner M.An Android game development framework [M].Beginning Android Games,2012:193-236.
[7]Romero C.A survey on pre-processing educational data [M].Mining.Springer International Publishing,2014:29-64.
[8]Peguero A.Latino/a student misbehavior and school punishment[J].Hispanic Journal of Behavioral Sciences,2011,33(1):54-70.
[9]Liu Z.A new belief-based K-nearest neighbor classification method [J].Pattern Recognition,2013,46 (3):834-844.
[10]Loperfido N.Skewness and the linear discriminant function[J].Statistics &Probability Letters,2013,83 (1):93-99.
