基于MapReduce的约束频繁项集挖掘算法
2015-12-23钱雪忠
施 亮,钱雪忠
(江南大学 物联网工程学院,江苏 无锡214122)
0 引 言
本文结合MapReduce[1]云计算编程模型提出一种基于MapReduce的约束频繁项集挖掘算法DCFIBMR (discover constrained frequent itemsets based on MapReduce)。该算法可以将一个完整的挖掘任务分成若干个相对独立的子任务,然后通过Hadoop[2]框架的MapReduce并行编程模型实现FP-Growth算法的并行化,其原理是DCFIBMR 算法将一个挖掘任务分成若干个相对独立的子任务,然后利用Hadoop框架将子任务分发给各个子节点进行处理,该算法在数千机器组成的集群中处理数据挖掘,因此DCFIBMR 算法可以有效地处理海量的数据挖掘任务。
1 相关概念
1.1 约束频繁项
本文中讨论的约束是有项约束,即挖掘包含某些项目(或同时包含几个项目)的频繁项目集合,设布尔表达式B是I上的项约束条件,将B 转换为析取范式 (disjunctive normal form,DNF)的形式,如:B1∨B2∨B3…∨Bn,如果把B写成集合的形式,形如:set-of-B= {B1,B2,B3…Bn},其中集合B中的任意两个组成元素均不相等[3]。
1.2 FP-tree的构建
在FP-tree[4]中每个节点包含有5个属性:该节点的名称 (NodeName),该节点在数据库中出现的次数 (Node-Count),指向下一个同名节点的指针 (NodeSlider),指向该节点的父节点的指针 (ParentNode)及该节点的子节点所构成的节点集合 (ChildrenNode)。而该频繁项按计数降序排列组成的头表集合 (HTable)中,每个元素包含3个子对象:频繁项名称ItemName,频繁项计数ItemCount及指向FP-tree中同名节点的指针ItemHead。FP-tree[5]的构造过程如下:
(1)扫描一次事务数据库DB,构造频繁项和其支持数组成集合L,将集合L 中不满足最小支持度的频繁项删除并按支持数降序排列,生成支持数降序排列的频繁项集合F。
(2)构造FP-tree树的根节点T,并标记为 “NULL”,再次扫描事务数据库DB,遍历每条事务Trans,并执行如下过程:
1)根据频繁项集在F中的顺序,对事务Trans中频繁项按其支持数降序排列,构造 [p|P]结构,其中p是事务Trans中第一个项,P是剩余项。
2)调用insert_tree([p|P,T])函数,该函数执行过程如下:
如果T 存在一个子节点N,并满足N.NodeName,=p.NodeName,那么使节点N 的计数NodeCount加1;否则,创建一个新的子节点N,并且设置节点N.NodeName=p.NodeName、N.NodeCount=1、p.ParentNode=T。如果P非空,递归调用insert_tree(P,N)。
1.3 MapReduce编程模型
MapReduce是Apache下开源云计算框架Hadoop中一种并行计算编程模型,利用MapReduce编程模型Hadoop可以并行处理数据量巨大的任务,该框架可以极大的简化分布式任务的处理。而MapReduce编程模型主要有Map和Reduce两个部分组成,其主要原理是利用一个输入键值对集合,通过处理产生一个输出键值对集合[6]。
用户需要重写两个函数:mapper和reducer,MapReduce首先将数据分片输入到mapper函数中,根据指定的处理过程产生键值对集合并将相同键的键值对输出给同一个reducer函数进行处理,reducer函数根据用户的自定义的处理流程处理后将结果输出[7]。
2 约束频繁项集挖掘DCFIBMR算法
给定一个事务数据库、最小支持度及约束规则B,DCFIBMR 算法需要执行两次MapReduce过程。
2.1 第一次MapReduce过程
使用一个MapReduce任务来统计整个事务数据库中的频繁项的支持数。每个mapper实例处理一个事务数据库的数据块。mapper实例接收的数据是一种键值对的形式,如<key,value=Ti>,其中Ti是事务数据库 (DB)中的每条记录,对于每个频繁项,mapperper实例将处理好的数据以一种键值对的形式输出,如<key’=aj,value’=1>。对于每个mapperper实例的输出,用一个对应的combiner实例进行局部的整合,将相同键的值进行求和,通过此步可有效地减少节点之间的数据通信量。
在所有的mapperper实例执行完毕后,Hadoop框架会将具有相同键的键值对分发给同一个reducer实例进行处理,reducer实例对具有相同键 (key’)的值进行求和运算,处理结束后同样以键值对的形式输出,如<key’,sum(values’)>[8]。该阶段处理完成后可获得一个由频繁项及按支持度降序排列的列表,F。
2.2 第二次MapReduce过程
首先,在Map阶段,事务数据库中的数据被处理成组内依赖的数据块。然后在Reduce阶段每个reducer实例根据获取到的数据块构建子频繁模式树 (SubFP-tree),并在构建的子频繁模式树上递归进行频繁模式的挖掘任务。在mapper实例的开始阶段,它会加载第一次MapReduce过程生成的F[9]。在本文的实现中,F被构建成一个Hash映射表,将其包含的每一项映射到相应的组的编号(group-id)上。
(1)mapper的输入参数是事务数据库中的数据切片,每个数据切片以键值对,如<key,Value=Ti>,的形式传递。对于每个Ti,mapper将会按照如下步骤进行:
1)按照F中频繁项的顺序对Ti进行降序排列;
2)对于Ti中的每一项i,定位该项左边的项集,记录为L;
3)输出一个键值对,形如<key’=group-id,value={Ti[1],Ti[2],…Ti[L-1],Ti[L]},其中group-id为i在F中的下坐标。
(2)reducer实例开始执行时同样会加载F。在这个阶段,reducer实例会接受<key’,Value=DB (group-id)>键值对,DB (group-id)包含了同一组内的所有事务数据块[10]。针对DB (group-id),reducer实例会递归地构建和挖掘子频繁模式树 (SubFP-tree)。详细描述如下:
1)首先设置前缀项prefix=F[group-id];
2)扫描一次DB(group-id),产生由频繁项按支持数降序排列的头表subHTable;
3)再次扫描DB(group-id)构建局部子频繁模式树subFPtree;
4)判断由prefix和subHTable中的各个频繁项构成的项集是否满足约束规则B,如果满足则输出该频繁项;
5)遍历subHTable集合,对于集合中的每个频繁项p,从subFPtree中找到含有p的路径,并构造p的条件模式基集合。然后将prefix=prefix+p.NodeName,p的条件模式基集合,约束规则B 及F 作为输入参数从步骤2)开始迭代执行。
算法的具体执行过程如下:
输入:事务数据库DB,最小支持度minsup,约束规则B;
第一次MapReduce:


第二次MapReduce:

3 DCFIBMR 算法实例讲解
为了对DCFIBMR 算法的详细挖掘流程进行讲解,设事务数据库DB,其数据见表1,约束规则为B=(f∧c∧p)∨ (b∧i)及最小支持度为30%,从该事物数据库DB中挖掘出满足约束条件B的所有频繁项目集合。
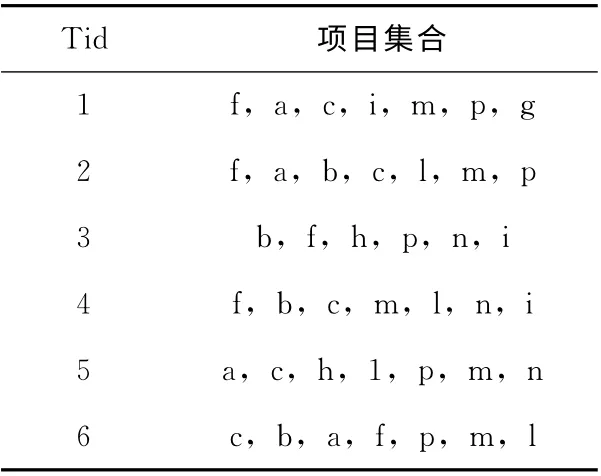
表1 事务数据库D
首先,执行一次MapReduce统计事务数据库中的所有频繁项及其出现的次数,产生形如L= [{f:5},{c:5},{p:5},{m:5},{b:4},{a:4},{n:3},{h:2},{i:3}, {l:4}, {g:1}],从中剔除支持数小于1.8 (6×30%)的频繁项,可以看出g出现次数小于1.8,将其从L中删除。然后对L按照支持数降序排列,组成F集合,F=[f,c,p,m,b,a,l,n,i,h]。
再执行一次MapReduce,在本次执行中将事务数据库D,约束规则B,最小支持度30%及F集合作为输入,通过相关的挖掘处理,输出满足要求的频繁项集合。
Map阶段:
本阶段主要是对事务数据库D 的分组及数据的分发,以便于后续的并行计算。以D 中第一行Tid-1为例,首先对Tid-1中的项集按照频繁项在F中的位置进行降序排序,并删除F中没有的项集,得到T={f,c,p,m,a,i}。然后对T 进行分组,形式如:{{f,c,p,m,a}|i}、{{f,c,p,m}|a}、{{f,c,p}|m}、{{f,c}|p}、{{f}|c}。在F中i的下标为8,则将 {{f,c,p,m,a}|i}放入第8组中,并输出:output<8, {f,c,p,m,a}>的键值对,其中8为组编号,{f,c,p,m,a}为i的条件模式基,其余几项的分组同理i。
Reduce阶段:
在Map阶段,事务数据库被进行了分组及输出,而在Reduce阶段,会接收到被分到同一组内的数据集合,形如<group-id,Values>,其中group-id为组的编号,Values为同一组内的数据集合;以频繁项i为例,将会获取到group-id=8,Values= ({f,c,p,m,a},{f,p,b,n},{f,c,m,b,l,n})。设定DB (8)= [{f,c,p,m,a},{f,p,b,n},{f,c,m,b,l,n}]。那么基于该局部数据库构建subFPtree,可构建出如图1 所示的头表subHTable及子频繁模式树subFPtree。
设置前缀项prefix=F [8]=i,并判断由subHTable中的各个频繁项和prefix 组成的项集pattern= {{i,f},{i,c},{i,p},{i,m},{i,b},{i,n}}是否满足约束规则B,从中可以看到频繁集 {i,b}满足要求。因此将{i,b}输出。
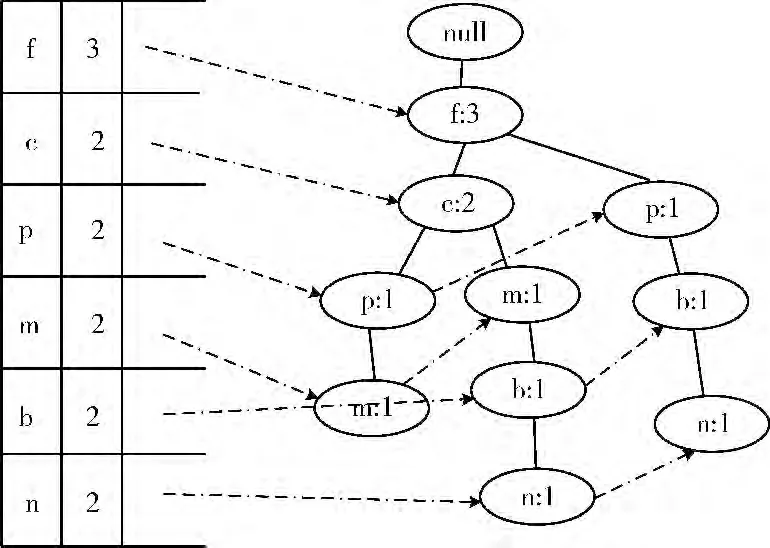
图1 头表及子频繁模式树
然后遍历subHTable,在本例中对于频繁项n,从sub-FPtree中可以找到以n为前缀的条件模式基集合cbase-n={{f,c,m,b},{f,p,b}},然后设置prefix=prefix+n,在集合cbase-n上建立头表及频繁模式树,挖掘过程同理i。最终,通过上述执行步骤可挖掘出满足约束规则B 的所有频繁项集。
4 算法性能比较与分析
Direct*算法[11]是一种串行的基于频繁模式树的约束频繁项集挖掘算法,在本次实验中将DCFIBMR 算法与Direct*算法进行比较,可以得出如下结论:
(1)Direct*算法主要是基于Apriori思想,即不断地由频繁K 项集产生K+1候选项集,因此在算法执行期间会产生大量的候选项集,并需要多次扫描数据库[11],而DCFIBMR 算法在执行过程中仅需要扫描两次数据库,因此算法的执行效率有显著的提升。
(2)Direct*算法是一种典型的单任务执行的算法,即一次只能执行一个任务,因此在处理海量数据挖掘任务时,用户需要等待很长时间才会看到结果,而DCFIBMR 算法的主要优势在于可以将一个任务分成多个相对独立的子任务在多台计算机中进行处理,因此可显著降低用户等待的时间。
为了进一步验证本文算法的有效性,实验设计如下:
实验环境是4台机器组成的集群,其中一台作为主节点,其余机器作为子节点。4 台机器具有相同的硬件及软件配置,每台机器有两个2.4GHz Intel处理器和360G 内存,Ubuntu13.10系统,Jdk1.7,以及0.20.2 版本的Hadoop,数据集是由IBM 的数据模拟生成器[12]所生成,数据集含有2113个数据项,事务平均长度64,事务最长73。
图2给出了在不同最小支持度 (40%,30%,20%,10%,5%,3%,1%)下随机选择几个频繁项组成约束条件B时,Direct*算法与DCFIBMR 算法的执行效率对比。从图中的数据对比可知,在约束条件B 相同的条件下DC-FIBMR 算法的执行效率远远高于Direct*算法,且随着支持度的变小,DCFIBMR 算法相对于Direct*算法的效率显著提升,因此该实验验证了DCFIBMR 算法的有效性。
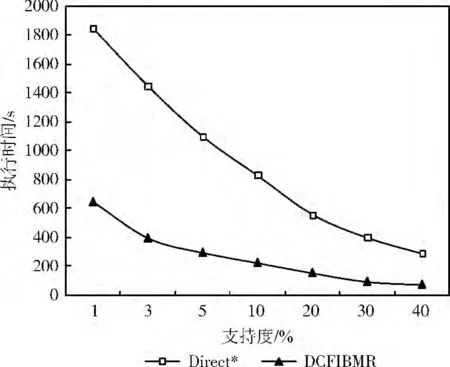
图2 两种算法在不同支持度下的执行时间对比
5 结束语
从海量的数据中挖掘出满足用户指定约束条件的频繁项集,使用传统的串行算法是很难完成的任务。针对此类问题并结合目前流行的开源框架MapReduce,提出一种并行的约束频繁项集挖掘算法DCFIBMR,该算法由用户来指定约束规则,利用MapReduce框架将一个完整任务拆分为若干个相对独立的子任务,由这些子任务根据约束规则从待处理的数据中挖掘出符合要求的频繁项集,将从各个子任务中处理的结果进行汇总整合,得到最终的处理结果。通过理论分析及实验验证了DCFIBMR 算法的有效性。
[1]Hai Duong,Tin Truong,Bac Le.An efficient algorithm for mining frequent itemsets with single constraint[J].Advanced Computational Methods for Knowledge Engineering,2013,479:367-378.
[2]Mohammad El-hajj,Osmar R Zaiane.Parallel leap:Largescale maximal pattern mining in a distributed environment[C]//12th International Conference on Parallel and Distributed Systems,2006:230-232.
[3]HUA Hongjuan,ZHANG Jian,CHEN Shaohua.Miningalgorithm for constrained maximum frequent itemsets based on frequent pattern tree [J].Computer Engineering,2011,37(9):78-80 (in Chinese).[花红娟,张健,陈少华.基于频繁模式树的约束最大频繁项集挖掘算法 [J].计算机工程,2011,37 (9):78-80.]
[4]XU Xiaoyong,PAN Yu,LING Chen.Energy saving and scheduling resources under the cloud computing environment[J].Journal of Computer Applications,2012,32 (7):421-426 (in Chinese).[徐骁勇,潘郁,凌晨.云计算环境下资源的节能调度 [J].计算机应用,2012,32 (7):421-426.]
[5]LI Tao,XIAO Nanfeng.Suitable large data sets of weighted frequent itemsets mining algorithm [J].Computer Engineering and Design,2014,35 (6):2114-2118 (in Chinese).[李涛,肖南峰.适用大数据集的带权频繁项集挖掘算法 [J].计算机工程与设计,2014,35 (6):2114-2118.]
[6]Yang C,Yen C,Tan C,et al.Osprey:Implementing Map-Reducer-style fault tolerance in a shared-nothing distributed database[C]//International Conference on Data Engineering,2010:657-668.
[7]Dean J,Ghemawat S.MapReduce:A flexible data processing tool[J].Commun ACM,2011,53 (1):72-77.
[8]LIU Yi,ZHANG Kan.Workflow task assignmen strategy based on load balance and experiential value [J].Computer Engineering,2009,35 (21):232-234 (in Chinese). [刘怡,张戡.基于负载平衡和经验值的工作流任务分配策略 [J].计算机工程,2009,35 (21):232-234.]
[9]LV Xueji,LI Longshu.Research on the algorithm of MapRe-duce FP-Growth [J].Computer Technology and Development,2012 (11):123-126 (in Chinese). [吕雪骥,李龙澍.FPGrowth算法MapReduce 化研究 [J].计算机技术与发展,2012 (11):123-126.]
[10]ZUO Liyun,ZUO Lifeng.Cloud computing scheduling optimization algorithm based on reservation category [J].Computer Engineering and Design,2012,33 (4):1357-1361 (in Chinese).[左利云,左利锋.云计算中基于预先分类的调度优化算法[J].计算机工程与设计,2012,33 (4):1357-1361.]
[11]LI Yingjie.New item constraint method for mining frequent itemsets[J].Computer Engineering and Applications,2009,45 (3):161-164 (in Chinese). [李英杰.项约束频繁项集挖掘的新方法 [J].计算机工程与应用,2009,45 (3):161-164.]
[12]IBM.IBM quest synthetic data generation code [EB/OL].http://www.almaden.ibm.com/,2009.
