协同仿真中的精确异常保证技术
2015-12-23蒋烈辉李轶民王飞龙
庄 宽,蒋烈辉,李轶民,王飞龙
(1.数学工程与先进计算国家重点实验室,河南 郑州450001;2.成都军区政治部,四川 成都751104)
0 引 言
系统仿真器在支持精确异常机制上一般是通过定位基本块、发现异常、回滚、重新翻译执行的方法,给仿真带来一定的性能开销[1-6]。支持精确异常一般分为在软件层实现和硬件层实现,QEMU[7]对精确异常的处理在软件层实现,采用定位基本块块首EIP,保存块首处理器状态,当异常在基本块中发生时,通过定位的EIP回滚到块首位置,恢复块首位置处理器状态,然后再进行逐条翻译执行,可以定位到异常发生的位置,这种支持精确异常的方式由于需要回滚、解释执行,因而降低系统仿真的效率。Code Morphing Software(CMS)[8,9]通过使用影子寄存器 (shadow register)和可撤销写缓存硬件支持来实现精确异常,CMS将基本块作为一个事物 (transaction)来执行,用影子寄存器和可撤销写缓存来保存执行过程中机器状态变化以及对内存的修改,只有当没有异常发生时,才将机器状态更新并将可撤销写缓存写入内存,当异常发生时,恢复监测点机器状态,并进行逐条的翻译执行以确保精确异常。CMS通过硬件的支持来实现精确异常,节省了其在精确异常方面的时间,从而提高了性能,由于CMS需要在处理器中使用大量的影子寄存器,因而此方法的多平台通用性不强。
本文依托全系统仿真软件AB (architecture bridge),其支持精确异常采用软件层实现,下文将用软硬件协同优化设计的方式来实现AB 的精确异常机制,最终使其对异常能快速准确定位。
1 简介
如图1 所示,AB 主要对CPU、I/O、内存等进行仿真,通过循环的译码、翻译、执行来实现对系统的仿真。
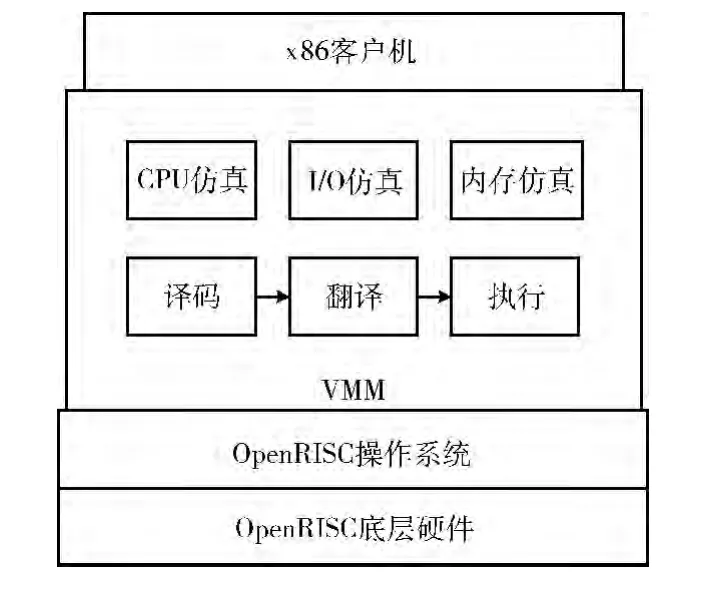
图1 AB整体结构框架
AB的结构包括由初始化、动态二进制翻译器、内存虚拟化、I/O 仿真4部分组成,如图2所示。
初始化阶段主要包括:解析用户提交的虚拟机配置相关的命令行参数、为虚拟机建立物理内存并建立映射关系、初始化二进制翻译器、初始化虚拟CPU、初始化I/O 子系统等。当初始化结束后,启动动态二进制翻译器,后者将根据当前PC值从虚拟机内存中取指、译码、翻译并执行,开始虚拟机的运行。
动态二进制翻译器:动态二进制翻译器目前的主要特性是:以基本块为翻译单位,支持翻译缓存,采用C 代码仿真x86的复杂操作 (如访存操作、涉及保护检查的指令、可能引发异常的指令等),基于指令操作原语的翻译。主要循环的进行以下工作:异常检测与派发、外部中断检测与派发、TB-CACHE查找、译码、翻译、I-CACHE 刷新、上下文切换(prologue)、TB执行、上下文切换(epilogue)。
内存虚拟化:AB内存虚拟化包括两大模块:一是物理内存虚拟化,即使用宿主机的虚拟内存来模拟客户机的物理内存,二是MMU 虚拟化,即仿真x86 的MMU。主要完成虚拟TLB 的查找,GVA (guest virtual address)到GPA (guest physical address)的转化,GPA 到 HVA(host virtual address)的转化。
I/O 仿真:虚拟化I/O 设备的方法一般有3 种:设备仿真、直接设备访问和虚拟设备模型,AB目前以软件方式实现了与P6处理器配套的典型I/O 接口和设备的仿真,包括芯片组 (i440fx/piix3)、PIC (i8259)、PIT (i8254)、键盘接口 (i8042)、IDE、标准VGA、UART 等。
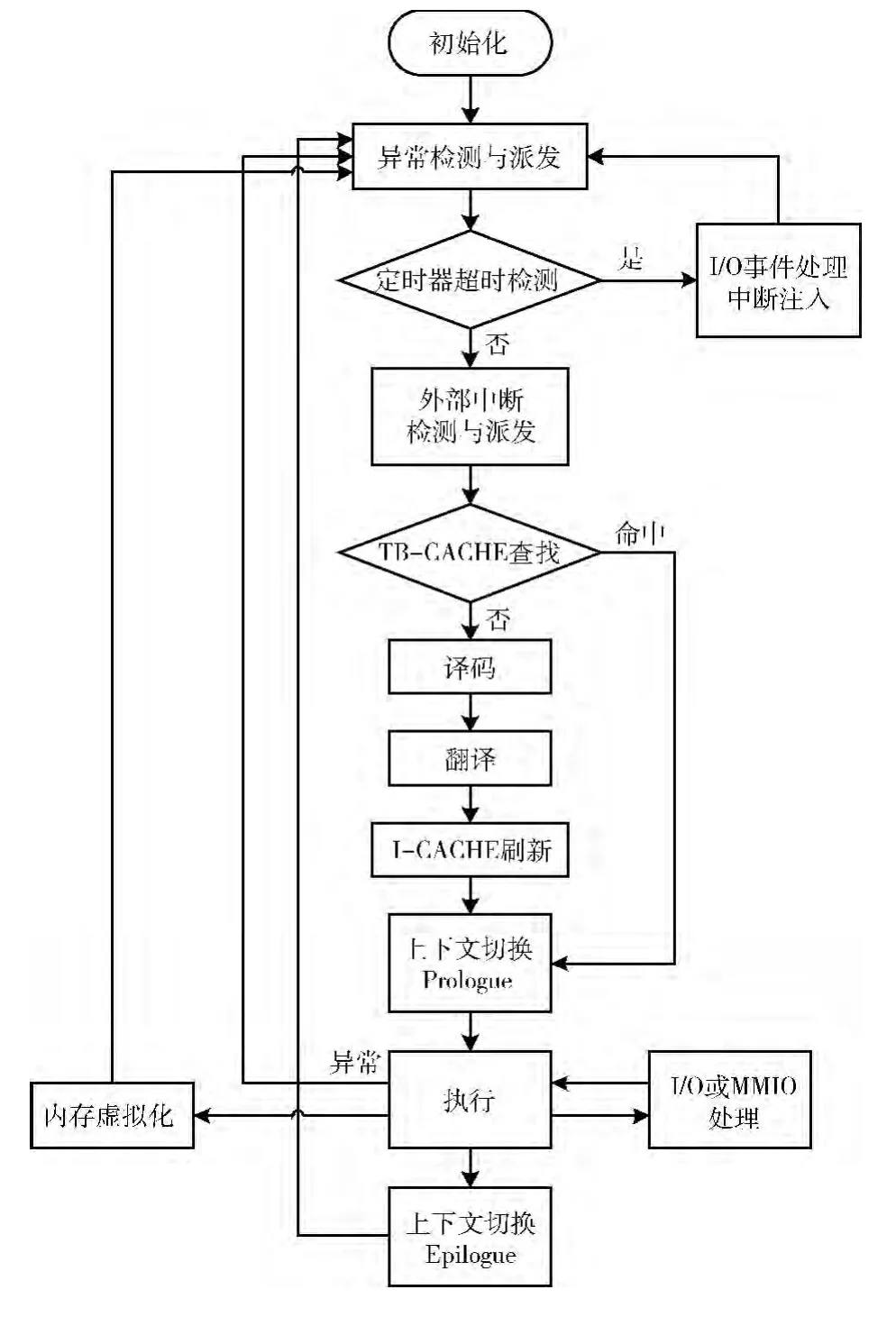
图2 AB的执行
2 AB对精确异常的处理
精确异常是指当异常发生之前所有的指令都正确的执行完毕[10,11],之后的所有指令都没有执行。满足精确异常的处理器,在软件层看来,指令是顺序执行的。
在翻译x86指令时,AB仅在确保不会有异常发生时才会修改虚拟机的状态,因此当异常发生时,可以确保有正确的机器状态。唯一的例外是EIP 的值,出于效率方面的考虑,AB在翻译每条指令时,并不生成指令来更新EIP的值,因此当发生异常时,应该恢复EIP的值。
有3种情景需要考虑EIP的恢复:
(1)取指 (译码)时发生异常 (#PF 或#GP)。取指时,异常仅会发生在取基本块的第一条指令时 (如指令的第一个字节所在的页不在内存中),或发生在指令跨页时(指令的尾部所在的页不在内存中)。对于第一种情况,由于处于块边界,因此EIP 的值可满足精确异常的需要。对于第二种情况,AB在翻译时会识别指令跨页的情况 (返回DCDR_RIDE_PG),若该跨页的指令不是基本块的第一条指令,则结束基本块。下次翻译时,跨页指令将是基本块的第一条指令,若发生异常,EIP的值可确保精确异常。
(2)TB执行过程中发生异常。若指令非访存指令 (如LJMP等)且可能引发异常,AB在翻译x86指令时会生成OpenRisc指令来保存当前EIP的值,以便异常发生时有正确的EIP值可用。若指令为普通访存指令(如MOV等),当发生异常时,mmu_rd/wt()会根据翻译基本块时生成的EIP到HOST_PC 的对应关系调用restore_eip ()来恢复EIP的值。由于restore_eip()实现上的限制 (利用__builtin_return_address(0)返回的HOST_PC,并判断HOST_PC是否在TB范围内),要求在TB中直接调用mmu_rd/wt(),而不能在helper_xxx()中调用mmu_rd/wt()。
某些特殊的指令使用helper_xxx ()实现且需使用mmu_rd/wt()进行隐含的访存操作,如MOV DS,AX指令会访问描述符表,可能发生#PF 异常,由于是在helper_xxx ()上下文中调用mmu_rd/wt(),因此restore_eip ()无法恢复出正确的EIP。对于这种指令,AB也应在翻译指令时将加入OpenRisc指令来保持当前EIP的值,此时即使restore_eip ()无法恢复出正确的EIP,也可确保异常发生时有正确的EIP可用。
(3)中断或异常处理过程中的异常。中断或异常的递交在cpu_exec()上下文中进行,隐含着访存操作 (访问各种描述符表),并且可能引发各种保护异常 (包括#PF异常)。中断总是在基本块的边界处理,因此可确保EIP的值满足精确异常的要求。由于 (1)、 (2)的保证,可确保异常处理时EIP的值满足精确异常的要求。若中断或异常的递交过程中再次发生异常,EIP的值仍是精确的。
AB在对客户机指令翻译完执行之前,每次都要进行异常检测,在进行异常检测前,都不会对机器的状态进行任何修改,这样在一定程度上能支持精确异常,但其由于是严格按照程序顺序的执行,并且在每条指令尾部提交机器的状态,这种保守的机制对虚拟机的性能有一定的影响,然后对于一些指令重排、死代码删除等等的优化工作受到了很多的限制。本文采用协同处理的方式,将软件层面的精确异常支持由硬件部分维护与完成,降低AB 在精确异常方面的开销,并且能给后期的软件优化工作带来方便。
3 实现
3.1 依托平台
本文所使用处理器平台为开源组织OpenCore组织维护与发展的处理器OpenRisc,OpenRisc处理器采用五级流水线和哈佛结构 (Harvard architecture),支持内存管理单元(MMU),Cache,带有基本的DSP功能,外部数据和地址总线采用Wishbone片上总线标准,实现了基本指令集和向量指令,并支持指令扩展,可以增加8 个自定义指令。具有完整的工具链,包括开源的软件开发工具、C语言实现的cpu仿真模型、操作系统,以及软件应用所需的函数库等。其处理器Verilog HDL代码开源,可供个人与企业开发使用。由于其诸多优势,使得OpenRisc得到了广泛的关注。
3.2 精确异常
对精确异常的支持,是处理器的基本特性,因此,系统仿真中对异常的仿真不可避免。AB对异常仿真时,每次更改处理器状态都需要对异常进行检测,只有在没有任何异常产生时,才会改变处理器状态,每次的异常检测需要耗费一定的时间,降低了仿真的效率。并且AB 在修改宿主机EIP时采用了 “懒惰算法”,即在翻译后基本块执行过程中不更改宿主机EIP,当一个基本块执行完毕时才修改宿主机EIP,当异常发生时,只需要恢复宿主机EIP。在恢复宿主机EIP时,需要根据基本块生成时的EIP和HOST_PC的关系,通过restore_eip (),进行恢复。在恢复宿主机EIP时,需要调用mmu_wd/rd查找对应关系,然后恢复出宿主机EIP,需要相当多的时钟周期完成。因而,异常的检测与恢复宿主机EIP 都对性能有一定的影响。鉴于AB在异常仿真方面对性能的影响,采用建立翻译前EIP与翻译后HOST _PC 对应关系表,通过反向查表,定位EIP。
在系统仿真中,翻译前的基本块BB (Basic Block)中一条指令B1 可能对应于T1、T2、…、Tn多条OpenRisc指令,当翻译的指令块TB (Translation Block)执行时,如果在T2处发生异常,则需要通过异常的发生位置T2,查找到源指令B1,这样才能定位异常,考虑到翻译前的基本块BB 与翻译后的基本块TB的对应关系B1-> (T1,Tn),如图3所示。
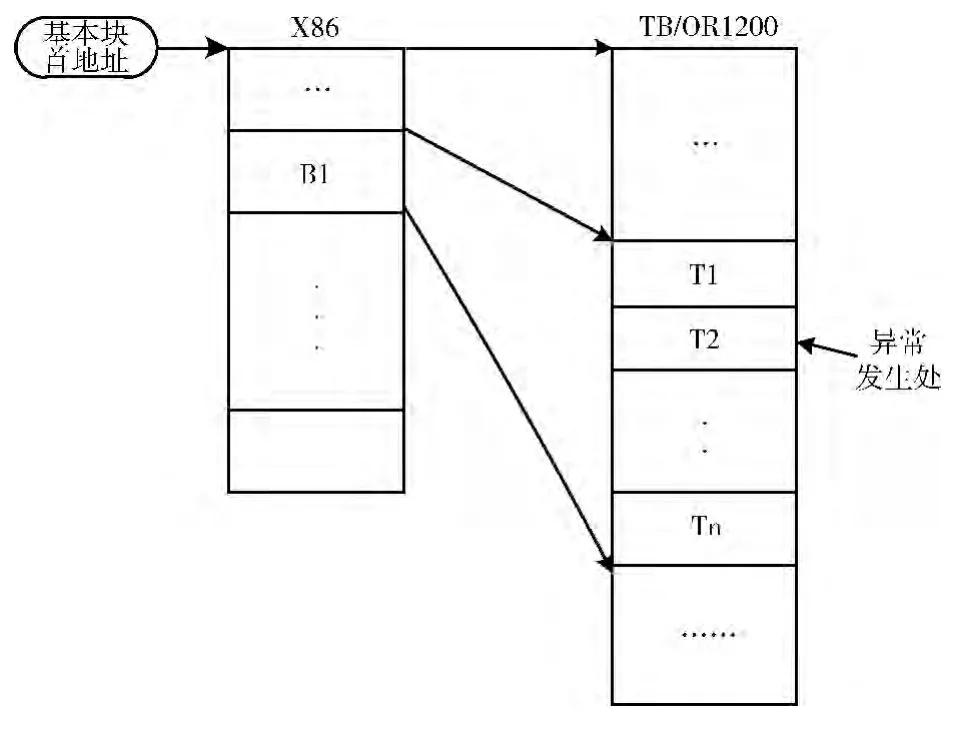
图3 异常对应关系
可以建立BTMT (basic block to translated block mapping table)表记录翻译前基本块BB 的EIP 与翻译后基本块TB的HOST_PC对应关系,见表1。
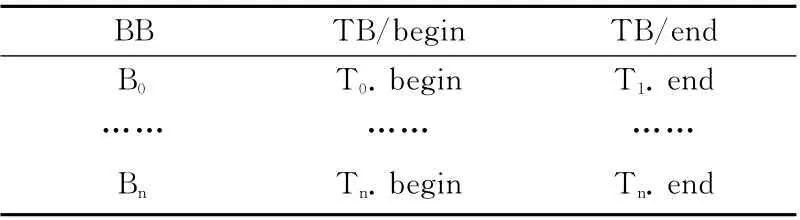
表1 EIP与HOST_PC关系
当异常发生的位置Ti.begin≤Ti.except≤Ti.end 时,则对应的宿主机基本块中异常发生位置指令Bi即可定位。因此,在异常发生位置Ti.except被定位时,通过两者的对应关系表就能顺利找到宿主机eip。
3.3 设计与实现
3.3.1 BTMT 表的实现
软硬件协同处理方式大致分为两种:一是,增加硬件电路协处理器单元,通过增加的硬件电路协处理单元,协同处理器完成相应工作,以提高处理器的性能,但是这种方式带来硬件协处理单元与处理器之间的通信开销,并且这种硬件协处理器设计难度较大,不易实现。二是,修改处理器Verilog HDL 硬件描述语言,以增加特定的功能。这种只需要修改处理器Verilog HDL 硬件描述语言,改动较少代码就能实现相应功能,便于实现,但是很多处理器受到专利等保护,不提供处理器Verilog HDL 代码,造成了在实现上的难度。因此,结合OpenRisc开源的特性,我们用第二种方法,采用自定义指令的方式,使其增加特定的查找BTMT 表的功能。
BTMT 表的实现在翻译时生成,在动态二进制翻译器翻译引擎translate()函数中实现记录Basic Block的EIP与Translated Block的HOST_PC之间的BTMT,见表2。

表2 BTMT
翻译前基本块BB,对应EIP 为B1、…、Bi、…、Bn,分别与翻译后的TB建立一一对应关系,T1、…、Ti、…、Tn分别为每个翻译后指令块的块首,此种关系表格可以简化比对时间以及底层Verilog HDL 的复杂度,当出现异常指令Ti≤Tii<Ti+1时,即可定位Bi。
建立的BTMT 表在每次随着基本块翻译生成时生成,当基本块执行完毕,修改机器状态,将此基本块对应的BTMT 表无效,下一块基本块在翻译之时,置新生成的BTMT 有效。每次生成的BTMT 表放在OpenRisc处理器的高速缓存中,以在异常发生时,由新定义指令调用,并返回比对结果。
3.3.2 自定义指令
所用平台处理器OR1200为新指令的定义预留了8 个指令槽,这些指令槽有两种格式,如图4所示。
图4 (a)指令格式的预留操作码有0x1c、0x1d、0x1e、0x1f,图4 (b)指令格式的预留操作码有0x3c、0x3d、0x3e、0x3f,由于需要通过翻译基本块的HOST_PC查找到客户机EIP,因此选择第二种格式作为新增加指令的格式。

图4 OR1200自定义指令格式
添加指令包括两方面工作:一是,硬件层修改。修改OR1200 Verilog HDL 的处理器源码文件or1200 _defines.v、or1200_cpu.v、or1200_ctrl.v等文件中分别增加相应修改:①对or1200_defines.v的修改:添加对应指令操作码:`define OR1200_OR32_hte 6'b111110//l.the。②对or1200_ctrl.v的修改:增加BTMT 表控制比对逻辑单元以及新指令取指译码的控制单元,并输出到ALU 模块的比对信号,使得新指令能够对建立的BTMT 表进行比对,产生比对结果。③对or1200_alu.v的修改:添加运算控制逻辑,并控制返回输出。新指令l.hte定义l.hte操作码为0x3c,机器码为0xf1e10000,RD 寄存器位置为保存宿主机EIP的寄存器r15,寄存器RA 位置为保存HOST_PC 寄存器r16,寄存器RB 位置保留,L、K 相应位置均保留机器。二是,软件层修改。新定义的指令不能被交叉编译器识别,让新定义的指令在机器上执行,还需修改相关部分。具体做法有两种:一是,修改编译器,增加对新指令的支持,这种做法较为复杂,而且会影响生成代码的质量。二是,修改汇编器,增加内嵌机器码以及定义新指令到二进制编码的映射等实现新指令。本次实现采取第二种方式,首先在交叉编译工具文件binutils/opcodes/or32-opc.c 加入: {"l.hte","rD,rA","11 0xC DDDDD AAAAA----------------",EF (l_hte),0,it_unknown},然后用内联汇编_asm_ _volatile_(“l.hte”)调用新定义指令。
4 测试分析
实验硬件平台利用以OR1200处理器所搭建的协同处理仿真平台,系统平台为OpenRisc linux,内核版本为linux 3.4,软件平台为AB 系统仿真器、fast-tty-linux.img系统镜像,以及SPEC 2006测试集的部分子测试程序。
由于OR1200处理器性能的限制以及平台部分资源的不足,实验选取SPEC 2006 测试集的4 个测试程序400.perlbench、445.gobmk、458.sjeng、462.libquantum对系统在精确异常方面的开销进行测试,结果如图5所示。
通过对增加精确异常的协处理部分前后的程序运行时间进行比较,发现增加精确异常协处理部分后,测试程序的运行时间比没有加入协处理部分分别有9.16%、14.32%、13.56%、10.48%降低,由于测试程序400.perlbench 和462.libquantum 程序没有太多的异常发生,性能提升相对较小,而测试程序458.sjeng和445.gobmk 异常发生相对较多,对性能提升比前两个有较为明显。
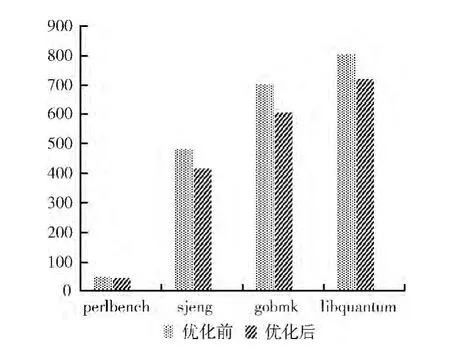
图5 优化前后执行时间
因此,对于触发异常较少程序,此方法对性能的提升相对较小,而对于一些局部性不好或者容易触发异常的程序,此方法对性能的提升比较明显。
5 结束语
本文分析了AB 系统仿真器在支持精确异常方面的不足,以及在纯软件实现上的性能损耗,结合开源处理器OR1200,通过更改其Verilog HDL硬件描述语言,增加新定义指令,以完成HOST_PC到宿主机EIP的转换,经过SPEC2006测试集测试,性能比优化前提高了9.16%~14.32%,根据其测试集程序的不同,优化的效果也不尽想同。由于系统仿真器AB 在优化过程中增加了TB-cache、块链等机制,给精确异常带来困难,此方法有助于今后在软件层面的深度优化。因本文所述方式需改动底层硬件描述语言以及交叉编译工具链,其移植性不高。
以上方法虽然在实践上比较困难,但对于一些国产处理器的系统仿真器优化,有一定的借鉴意义。
[1]DONG Weiyu,WANG Lixin,JIANG Liehui,et al.Accelerate X86system emulation with protection cache [J].Computer Engineering and Design,2013,34 (2):606-610 (in Chinese).[董卫宇,王立新,蒋烈辉,等.基于保护缓存的X86系统仿真优化[J].计算机工程与设计,2013,34(2):606-610.]
[2]Jair Fajaido Junior,Mateus B Rutzig,Antonio CS Beck,et al.Towards an adaptable multiple-ISA Re-configurable processor[G].Lecture Notes in Computer Science 6578:7th International Symposium on Applied Reconfigurable Computing,2011:157-168.
[3]HU Wei,WANG Jian,GAO Xiang,et al.GODSON-3:A scalable multicore RISC processor with emulation [J].IEEE Micro,2009,29 (2):17-29.
[4]Fan DR,Li XW,Li GJ,et al.New methodologies for parallel architecture[J].Journal of Computer Science and Technology,2011,26 (4):578-587.
[5]DENG Haipeng.Reorganization and optimization of the backend code in dynamic binary translation [D].Shanghai:Shanghai Jiao Tong University,2011 (in Chinese).[邓海鹏.动态二进制翻译后端代码热路径的重组优化 [D].上海:上海交通大学,2011.]
[6]SUN Tingtao.Branch analysis and optimization in dynamic binary translation [D].Shanghai:Shanghai Jiao Tong University,2010 (in Chinese). [孙廷韬.动态二进制翻译中跳转分析与优化 [D].上海:上海交通大学,2010.]
[7]QEMU.Change Log/1.2[EB/OL].[2012-09-05].http://wiki.qemu.org/ChangeLog/1.2.
[8]YU Lu.Research on improving mechanism of precise exception of QEMU [D].Wuhan:Huazhong University of Science &Technology,2008 (in Chinese).[余璐.一种改进QEMU 精确异常处理机制的研究 [D].武汉:华中科技大学,2008.]
[9]CHEN Wei.Research on dynamic binary translation based on Co-designed virtual machine[D].Changsha:National University of Defense Technology,2010 (in Chinese).[陈微.基于动态二进制翻译的协同设计虚拟机关键技术研究 [D].长沙:国防科学技术大学,2010.]
[10]CHEN Haifeng.Research on ISA mapping of Co-design X86 emulation [D].Zhengzhou:Information Engineering University,2012 (in Chinese).[陈海峰.协同设计X86仿真指令集映射技术研究 [D].郑州:信息工程大学,2012.]
[11]CHEN Qiao,JIANG Liehui,DONG Weiyu,et al.Simulator research based on dynamic binary translation technology [J].Computer Engineering,2011,37 (20):277-279 (in Chinese).[陈乔,蒋烈辉,董卫宇,等.基于动态二进制翻译技术的仿真器研究[J].计算机工程,2011,37 (20):277-279.]
