基于连通域的扭曲中文文本图像快速校正方法
2015-12-23曾凡锋郭正东王战东
曾凡锋,郭正东,王战东
(北方工业大学 信息工程学院,北京100144)
0 引 言
近年来,图像的扭曲校正技术获得迅速发展,主要分为:①基于3D 的模型重建技术校正[1-3],这类方法都能获得较好的校正效果,但是由于需要特定外设及特殊实验参数才能完成,难以将其产品化推广。②基于2D 图像校正,该方向又分为:基于连通域处理[4-6],这类方法具有逻辑清晰,校正粒度小等特点,一直以来都是该研究领域主流,不过由于处理较为细致,也导致了其速度亟待提高;基于文本线处理[7,8],这类方法的主要优势在于较大的校正粒度提高了处理速度,但因为是以行为最小校正单位进行处理,所以对校正效果的精准度有一定损减;基于区域信息校正[9],这类方法能够达到快速而且较好的校正效果,只是通常对原始图像拍摄方式有特殊要求,适用范围受限。
通过上述分析,目前基于2D 的扭曲校正方法各有优缺点。然而许多成熟的2D 校正方法是针对英文文本图像的,应用到中文图像上不易获得理想效果,难以照搬套用。主要原因在于字符组合式的英文单词能够通过迭代地横向合并相邻连通域切分出来,而汉字结构复杂多样,使得切分文字的难度大大提高。另外,由于相机拍摄的图像不能像扫描图像一样可以利用图像仅一侧存在扭曲的特点通过水平投影直方图分析提取出文本行,因此需要研究适应性更强的方法。本文针对拍摄图像提出了一种基于连通域的扭曲校正方法,实现了快速精准的文字切分算法,并针对拍摄图像提出了一种就近聚合文字的方法定位文本行,最后基于文字逐行校正获得最终图像,该方法克服了传统连通域校正方法耗时长的问题,并保证了高精度校正的效果。
1 扭曲图像特征及校正分析
由于书本被拍摄时的摆放和相机位置都可能使得获得图像出现扭曲,如图1所示。

图1 图像扭曲
图像扭曲一般分两种:文本行扭曲和文字变形。从识别的角度来看,扭曲文档识别率主要受前者影响。从校正效率的角度看,文本行扭曲校正作用范围更大,其效率明显高于变形文字的校正效率,而对变形文字的校正范围较小,单位面积校正耗费的代价更大,并且有些变形严重的文字校正后依然不能识别,变形较弱的文字不进行校正也能被识别,所以对识别率的提升不如扭曲文本行校正效果明显。因此,多数校正文献都是对文本行扭曲进行校正,本文也将沿用这种校正思想。
2 基于连通域的扭曲文本图像校正算法
针对中文文本图像的扭曲校正重点在于文字切分,本文就此提出一种基于连通域的校正方法,流程如图2所示。
2.1 二值化
二值化是图像处理的一个重要步骤,处理效果直接关系到后续步骤的顺利完成,特别是文字切分部分就对二值化效果要求较高。

图2 本文算法流程
图像二值化方法很多,传统的方法有双峰法、大津法、最优迭代法、Niblack法等,然而由于文本图像比较注重二值化后文字细节信息的保留,且连通域对笔画连接比较敏感,本文采用的是一种改进的迭代法,即先对统计图像的灰度概率分布F [0…255],按式 (1)计算图像的全局灰度期望作为初始阈值T0

传统的迭代法是不断计算阈值两边 (即前景和背景)的灰度平均值ZL和ZR,然后求其平均值TN,直到TN恒定不变为止,本方法将其改为计算阈值左右部分的灰度标定量E 均值作为新的阈值TN
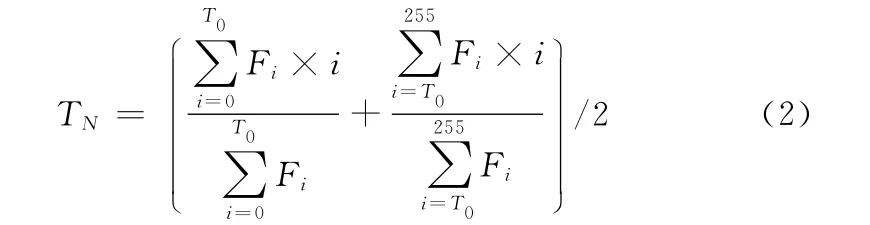
同样当TN=TN-1时,以此恒定阈值来对图像二值化。实验结果表明该方法耗时较少,并且能够很好地保留文字的笔画,如图3所示。

图3 二值化效果
2.2 连通域搜索
连通域搜索的方法有很多,根据扫描方法分为像素扫描即点标记法和线段扫描即线标记法,各算法都能准确标记目标连通域,主要区别在于对等价标号的处理。本文方法参考的是一种优化的快速连通域标记法[10],具体算法:基于4邻域进行搜索,首先用一个二维数组merge记录各像素连通域标号,由于无法一次正确标记所有连通域,还要设置一个共同连通域标号数组common,按下标记录各等价连通域标号所属的连通域。遍历结束后,common 数组中存在下标与值不一致的等价标号,而且实际连通域标号不是连续的,因此需要设置temp 数组做出调整,再次遍历merge数组,统一各连通域标号,完成连通域搜索。
2.3 文字切分
文字切分一直以来都是中文图像识别技术研究的难点,由于汉字的多样性结构,包括左右、上下、包围、半包围和独立结构等,使得汉字的切分不能像英文那样只需横向合并连通域。在中文图像中存在着标点符号、英文字母和数字等元素同样增加了汉字分割的难度。大部分关于文字切分文献的方法中,有些方法[4,6]没能提供绝对的切分参数说明该方法的通用性,也有方法[11]能够获得较高的切分正确率,但多数耗时较长。本文结合以上方法提出了一种优化的快速切分方法,先为标记的连通域添加包围边框,然后按给出规则合并边框,从而切分文字。
2.3.1 添加基本连通域包围边框
创建连通域边框数组R,上下左右值初始化为-1,遍历连通域标号数组merge,比较同一连通域各点坐标 (记为p.x 和p.y)和R[merge[x,y]]的上、下、左、右4个属性值 (记为R[p].l,同理于t,r,b),按下列公式更新rectFrame数组取值,即

要注意的是,计算边框时是根据视图的窗口坐标,原点在左上角,而图像的数据起点是从图片的左下角,因此需要如式 (3)进行变换。另外,由遍历顺序可知,边框下界R[p].b不可能出现更大值,初始赋值为 (height-p.y)即可,其中height代表图片的高度。对于独立结构的文字,即不含偏旁部首的文字 (如工、女、王等),和结构紧凑的文字 (如左、器、暑等)都包含于一个连通域中,所以到此处理阶段多数文字已能正确划分。
2.3.2 合并边框
合并边框是本文算法的难点部分,也是本次课题研究的主要创新点之一。因为非独立结构文字和分布不紧凑的文字一般是由多个连通域组成 (如三、非、晶等),为了将同一文字的各结构归并到同一连通域当中,这里用到了重叠合并和近邻合并两种方法连续处理,算法如下:
(1)统计连通域边框的宽高。
(2)计算图像中字体的标准宽高。先从高度统计数组中寻找概率最大的高度Hm,因为多数文字已经被正确分割出来,且一般的印刷设计版面中大部分的文字高度相差无几,所以可将Hm作为标准高度HS,考虑到字体变化和英文字母等干扰因素,标准高度的估计从最大高度的1/3处开始寻找更加准确。标准宽度的确定不能照用确定HS的方法,因为文档中英文单词、标点符号、数字等非汉字元素的宽度变化较大,另外,当前处理的是扭曲图像,扭曲部分文字的宽度也会缩小,这些原因导致了宽度分布复杂。观察发现,利用印刷版面的特征发现,通常具有固定的宽高比例标准,通过标准高度来计算标准宽度WS。
(3)将合并范围窗口化。为了提高算法的速度,在遍历各连通域时作两次优化,其一,每次仅处理宽高相加大于2的连通域,此做法有一定的逻辑去噪作用,其二,参照局部阈值二值化的思想,为待处理的连通域Ci设置一个合并窗口,仅考虑合并窗口内的连通域。窗口的设置规则是当前连通域边框中心左右扩展WS,向上扩展HS,因为遍历顺序是从图片的下方向上遍历,故没有向下扩展。
(4)遍历窗口内像素点,如果发现不同标号的连通域Cj,首先判断是否与当前连通域Ci发生重叠,定义下列标记:
连通域的外接矩形坐标:(Ci_l,Ci_t)和(Ci_r,Ci_b);
连通域的宽和高:Wi和Hi按式 (6)、式 (7)计算两个连通域合并宽度Wcom和合并高度Hcom。然后根据式 (8)判断是否合并
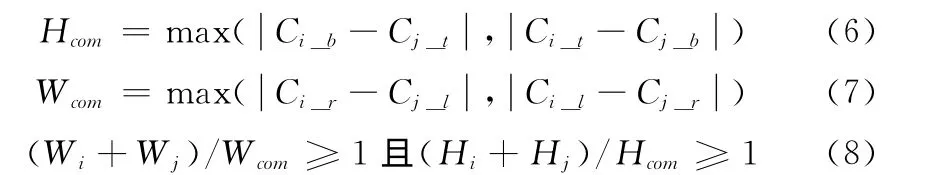
若重叠则进行合并,否则,将其编号Cj记录到相邻连通域集合S 中,待下一步处理。
(5)遍历完窗口后,如果相邻连通域集合S 不为空,则遍历S 中所有连通域,逐一进行重叠判断,若重叠就与Ci合并,并从S 中删除Cj。连通域Ci可能因第一轮重叠合并而扩大区域,与之前并不重叠的连通域开始发生重叠。
(6)如果相邻连通域集合S 还不为空,则进行近邻合并,当两个连通域Ci和Cj满足式 (9)、式 (10)

ρ是限定合并条件的重要参数,若ρ过大会导致合并不完整使得同一个文字的偏旁部首不能并入同一个连通域,ρ过小则又可能导致合并过度,使得多个文字或标点符号等非文字元素被并入一个连通域中。经过多次实验测试,当ρ1=0.845 和ρ2=0.28 时有很好的文字切分效果,如图4所示。
根据统计,在正常光照下拍摄的扭曲图像中,文字切分正确率达90.3%左右,其中非扭曲区域的文字切分正确率达到95.6%左右。
2.4 定位文本行

图4 文字切分效果
文本行搜索是本课题研究的另一创新点,由于拍摄图像扭曲文本线的走向随意,不宜采用水平投影分析来判断文本行,本文采用的是基于文献 [5]提出的就近聚合文字的方法定位文本行,具体算法如下:
(1)计算各个文字的中心坐标 (Cm_x,Cm_y);
(2)就近连接左右邻居。依据中心坐标,计算Ci与左右两侧文字的中心间距,并分左右两边的各取一个间距最小的文字Ci_l和Ci_r,从印刷版面分析可以发现各字块(包含文字和如标点符号、字母和数字等独立字符)与左右字块的间距最小,因此,Ci_l和Ci_r,为Ci的左右邻居字块。为提高效率,通过公式计算中还跳过明显不在一行的字块,对Ci和Cj而言,Ci的上边界小于Cj的下边界,或Ci的下边界大于Cj的上边界时,认为Ci和Cj不在同一行。
(3)将文字聚合成行。先通过遍历各个连通域,寻找出各行的行首文字,没有左邻居的就是行首文字。再从行首文字开始,迭代查找右邻居直至找到没有右邻居的文字完成一行。
实验效果如图5所示,通过连接各行文字的中心来验证文本行定位的正确性。

图5 文本行定位
2.5 扭曲校正
许多文献的方法里需要将单词旋转位移或者重构整个文本行区域来进行校正,这样的处理一般方法是曲线拟合文本行,再进行几何变换采样点的位置。本文利用已确定的文本行和文字位置信息,仅移动单个文字即可完成校正,相比完全的文本行重构很好地减少了运算量。
前面已经确定了各行之间及行内文字之间的逻辑位置,并获得了各文字的实际坐标区间,由于各个汉字的所占面积相接近,那么按行将所有文字移到合理位置即可达到扭曲校正的目的。具体操作是:对图像由上到下逐行遍历,以第i行Li(i>0)为例,先寻找Li上沿最高的文字作为标记文字Cm,然后遍历其它文字Cn(n>0),按式 (11)计算校正位移d

最后将Cn按校正位移d 对文字垂直移动,值得注意的是d 的正负值对应于上移和下移,从而使得各行文字保持在同一水平线上,完成扭曲文档图像的文本行扭曲校正。效果如图6所示。

图6 校正效果
3 实验结果比对
实验条件:图像样张取自16开普通中文书本,共拍摄了200张。摄像头是500 w 像素,主机配置中CPU 是Pentium(R)D 频率2.80GHz,内存2 G,本方法是通过VC++实现,使用汉王OCR 文字识别软件进行文字识别。为了检验效果,同时选取了两种近年来2D 扭曲校正方向有一定成果的方法进行对比。实验结果见表1。

表1 各算法实验结果比较分析
实验结果分析,通过比较3种方法的校正耗时和不同扭曲程度样张的校正后识别率作为评判依据,并根据校正前样张的识别率将样张扭曲程度分为3类作为比较。可以得到,从耗时角度上看,本文方法大大缩短了校正时间。从校正效果上看,对于扭曲程度较高即识别率不足50%的图像,文献 [4]方法提取文本行时局限于假设了页边区域文本行水平进行处理,因而提取文本行不准确导致识别率偏低,但其它情况都有较好的校正效果,而本文的校正效果能够得到稳定的保证。
以上分析结果表明,本文方法对文字处理细致,速度更快且仍能保证较高的识别率。
4 结束语
本文针对中文文本扭曲图像进行研究,提出的基于连通域的校正算法,通过分析汉字结构特点提出了精准的文字切分算法,在其基础上提出了一种就近聚合文字的方法快速定位文本行,最后按行逐字进行校正,简化了传统的按行处理方法。通过实验数据可看出,该方法对严重扭曲的中文文本图像也能取得较好的校正效果,校正后的图像OCR 识别率有比较明显的提高,并且耗时较少,适合推广到实时的文字图像识别系统中进行应用。
[1]HE Yuan,PAN Pan,XIE Shufu,et al.A book dewarping system by boundary-based 3D surface reconstruction [C]//12th International Conference on Document Analysis and Recognition,2013:403-407.
[2]LI Zhang,Andy M Yip,Michael S Brown,et al.A unified framework for document restoration using inpainting and shapefrom-shading [J].Pattern Recognit J,2009,42 (11):2961-2978.
[3]MENG Gaofeng,PAN Chunhong,XIANG Shiming,et al.Metric rectification of curved document images [J].Pattern Analysis and Machine Intelligence,2012,34 (4):707-722.
[4]LIU Hong,YE Lu.A method to restore Chinese warped document images based on binding characters and building curved lines[C]//International Conference on Systems,Man and Cybernetics,2009:984-990.
[5]Gatos B,Pratikakis I,Ntirogiannis K.Segmentation based recovery of arbitrarily warped document images[C]//9th International Conference on Document Analysis and Recognition,2007:989-993.
[6]SONG Lili,WU Yadong,SUN Bo.Improved document image distortion correction method [J].Computer Engineering,2011,37 (1):204-206 (in Chinese).[宋丽丽,吴亚东,孙波.改进的文档图像扭曲校正方法 [J].计算机工程,2011,37 (1):204-206.]
[7]ZHANG Weiye,ZHAO Qunfei.Algorithm for layout analysis and document image preprocessing of reading robot [J].Microcomputer Applications,2011,27 (1):58-61 (in Chinese).[张伟业,赵群飞.读书机器人的版面分析及文字图像预处理算法 [J].微型电脑应用,2011,27 (1):58-61.]
[8]LIU Hong,DING Runwei.Restoring Chinese warped document images based on text boundary lines[C]//International Conference on Systems,Man and Cybernetics,2009:571-576.
[9]TONG Lijing,ZHAN Guoliang,PENG Quanyao,et al.Warped document image mosaicing method based on inflection point detection and registration[C]//International Conference on Multimedia Information Networking and Security,2012:306-310.
[10]LUO Zhizao,ZHOU Yingwu,ZHENG Zhongkai.An optimized algorithm of binary image connected component labeling[J].Journal of Anqing Teachers College (Natural Science Edition),2010,16 (4):34-39 (in Chinese). [罗志灶,周赢武,郑忠楷.二值图像连通域标记优化算法 [J].安庆师范学院院报 (自然科学版),2010,16 (4):34-39.]
[11]FU Lujing,QIAN Junhao,ZHONG Yunfei.Printed image layout segmentation method based on Chinese character connected component[J/OL].Computer Engineering and Applications,2013.http://www.cnki.net/kcms/detail/11.2127.TP.20130731.1817.001.html(in Chinese).[付芦静,钱军浩,钟云飞.基于汉字连通分量的印刷图像版面分割方法[J/OL].计算机工程与应用,2013.http://www.cnki.net/kcms/detail/11.2127.TP.20130731.1817.001.html.]
