面向Open GL的图形加速器设计与实现
2015-12-22邓军勇韩俊刚沈绪榜
邓军勇,李 涛,蒋 林,韩俊刚,沈绪榜
(1.西安邮电大学电子工程学院,陕西西安 710121;2.西安电子科技大学微电子学院,陕西西安 710071)
面向Open GL的图形加速器设计与实现
邓军勇1,李 涛1,蒋 林1,韩俊刚1,沈绪榜2
(1.西安邮电大学电子工程学院,陕西西安 710121;2.西安电子科技大学微电子学院,陕西西安 710071)
为了探索图形处理器的自主开发,设计了一款基于经典流水线结构、支持OpenGL核心函数的图形加速器,并对其中几何变换、投影变换和视窗变换的关键操作——矩阵运算、图元装配以及光栅化等单元进行了优化设计以提高效率,支持Gouraud着色、光照、全屏抗锯齿、纹理贴图等效果.为保证电路功能的正确性,构建了基于C/C++的软件仿真平台和基于System Verilog的硬件仿真平台,并采用Altera公司的EP2C70F896C6搭建原型系统,电路规模约占FPGA总资源的83%,工作频率可达100 MHz.经过大量实例测试,图形加速器具备基本的图形渲染能力.
图形加速器;矩阵运算;图元装配;全屏抗锯齿;原型系统
当前,种类繁多的电子智能设备已经深入到人类生活的众多领域,无论通用计算机领域或嵌入式应用领域,对多媒体和图形图像技术的需求都在日益增加[1].图形处理需要巨大的计算能力,传统的图形处理往往依赖于中央处理器(Central Processing Unit,CPU)的处理能力,很大程度上已经不能满足用户的需求.笔者基于经典流水线结构设计了一款面向开放性图形库(Open Graphics Library,OpenGL)核心函数的图形加速器,并对其中几何变换、投影变换和视窗变换的关键操作——矩阵运算、图元装配以及光栅化等单元进行了优化设计,构建了基于C/C++的软件仿真平台和基于System Verilog的硬件仿真平台,以保证电路功能的正确性,并基于Altera公司的现场可编程门阵列(Field Programmable Gate Array,FPGA)EP2C70F896C6完成硬件电路,实现了由Nios II核、流水线图形加速器、命令输入与显示、渲染结果显示等模块构成的图形处理原型系统,电路规模约占FPGA总资源的83%,工作频率可达100 MHz.
1 体系结构设计
Open GL独立于硬件和窗口系统[2].文中选取与物体的外形描述、变换、光照、着色、纹理、像素操作、抗锯齿等密切相关的核心应用程序接口(Application Program Interface,API)命令设计了一款图形加速器,每条命令由18个字节(144位)组成,包括8位操作码、8位控制字、128位数据字.
1.1 流水线型图形加速器
Open GL规定了明确的图形渲染流程:首先将对象由模型坐标经模型视图变换得到视觉坐标;经投影变换得到裁剪坐标;经坐标齐次化得到规范化的设备坐标;最后经视口变换得到窗口坐标.这种流式数据处理体现为一条由几何变换、图元装配、投影变换、坐标齐次化、视窗变换、背面剔除、光栅化、片元处理等流水级构成的宏观流水线[3].
1.2 电路设计
1.2.1 总体设计
流水线各级之间的数据交互通常采用先进先出队列(First In First Out,FIFO)完成,但片内静态随机访问存储器(Static Random Access Memory,SRAM)资源宝贵,图形加速器采用双轨握手协议实现数据传输.各级输入和输出采用控制信号valid和ready,其中valid表示数据线上有数据;ready表示本单元可以接收数据.当数据信号到达时,valid是1;当没有数据信号时,valid为0.当输入ready信号是1时,数据和valid存入;当输入ready信号是0时,整个流水线冻结.
对于不同功能单元的设计,重点优化了几何变换、投影变换和视窗变换等单元的关键操作——矩阵运算,并对传统的图元装配算法进行了改进,同时对光栅化进行了分析和优化,提高了电路工作效率.
1.2.2 矩阵运算
图形变换是计算机图形学的一个重要研究内容[4],矩阵运算是图形变换的基础.顶点的平移、缩放、旋转、剪切等几何变换依靠顶点的齐次坐标与变换矩阵的左乘/右乘实现,由于应用程序指定的变换可能是一种或多种,因此变换矩阵可能是应用程序直接输入的矩阵,也可能是多种变换矩阵的级联相乘;投影变换和视窗变换同样涉及矩阵运算[5].矩阵运算的性能高低直接影响图形渲染的效率,通常使用更快速的处理器,利用并行性和专门的硬件结构等来提高运算速度;基于脉动阵列的矩阵乘法器充分利用了矩阵乘法运算中数据间关系的局部性与规则性,完成整个矩阵运算需7个时钟周期,16个处理单元(Processing Element,PE)[6].基于Open GL命令的处理方法设计矩阵运算电路,文中思路如下:
(1)几何变换、投影变换、视窗变换等流水级需要处理的命令包括矩阵向量运算类命令、矩阵矩阵运算类命令以及非本级处理而需要透传的命令,因此矩阵运算器需要支持运算、存储与传输.
(2)矩阵与矩阵/向量相乘,可以转换为一系列向量点积运算,基于数据相关性,至少需要1个乘法器、1个加法器和至少5个时钟周期.
(3)为提高运算效率,考虑数据并行处理:要实现利用1个乘法器和1个加法器在5个时钟周期完成向量点积运算,需要采用流水结构;要使整个运算在5个时钟周期内完成,则需要采用阵列结构.
矩阵运算器如图1所示,由4个并行点积运算单元(Dot Product Element,DPE)和1个控制器组成,Din为输入数据,CMD代表输入命令,Rin、Vin和Rout、Vout是双轨握手信号,分别为输入就绪、输入有效、输出就绪和输出有效,Dout为运算结果或直接透传的输入数据.DPE由寄存器组、乘法器、累加器、选择器、寄存器等组成.每个DPE包含8个寄存器,分为A、B两组,每组4个,以乒乓形式工作,用于存放当前矩阵:如果处理矩阵向量运算或透传数据,则当前矩阵不变;如果处理矩阵操作,A、B两组寄存器一组用来做当前运算,另一组用来存放矩阵相乘的结果,每次执行完毕则切换一次当前矩阵.数据寄存器R0、R1、R2分别用来存放乘法结果、累加结果与最终输出.
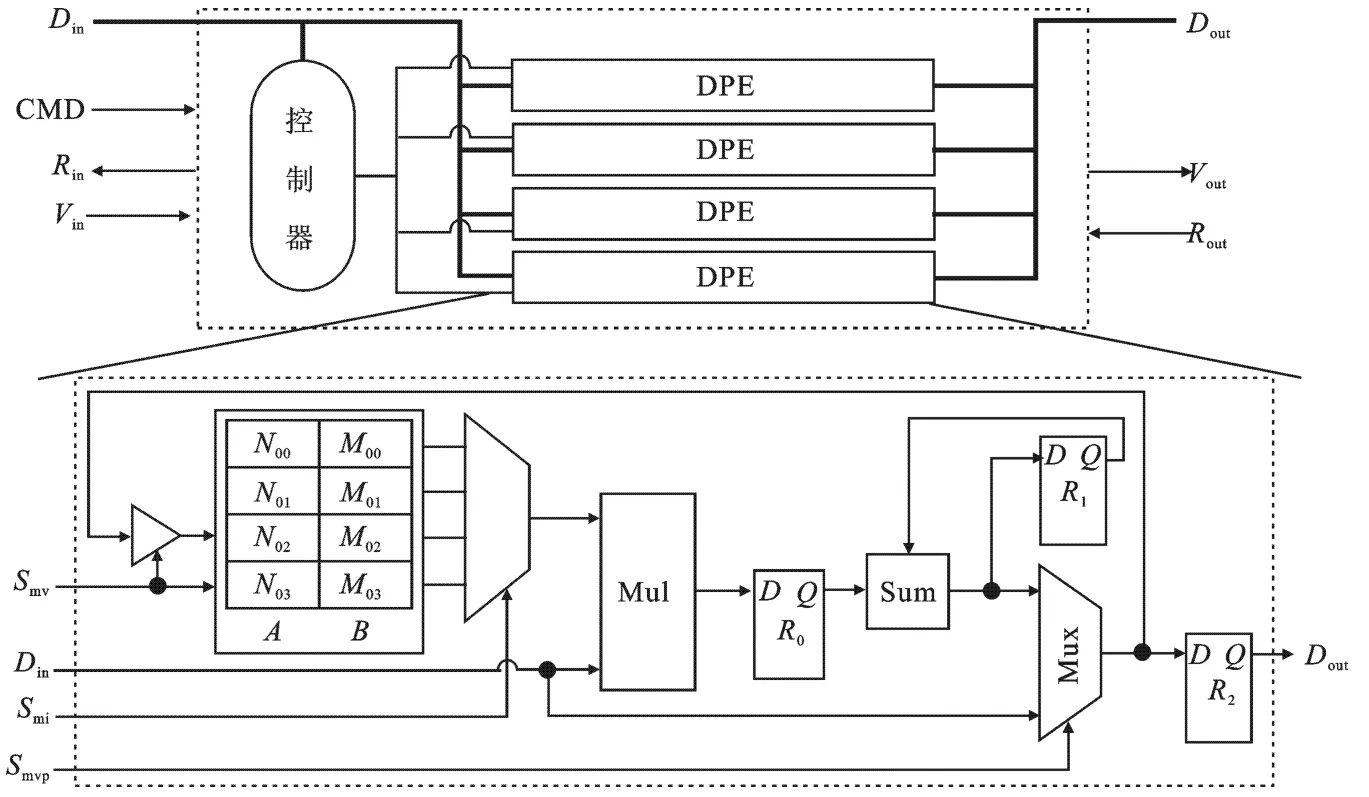
图1 矩阵运算器结构图
图1中,Smv用于控制乒乓寄存器组的切换和矩阵操作结果的存储,Smi是矩阵元素的索引,Smvp用于选择透传输入和累加结果.控制器用于协调整个矩阵运算器的工作,可以采用微程序式或硬连接式设计.鉴于运算类型相对单一,采用硬连接形式的自动机实现以提高效率.
1.2.3 图元装配
图元装配单元根据Open GL命令将绘图对象装配成具有一系列特定属性信息的点、线、三角形等基本图元.加速器设计中对图元装配单元常见的凹多边形支持、裁剪后图元的着色等问题综合考虑解决.
OpenGL规范指定了点、线、三角形、多边形等10种图元,其中多边形仅指凸多边形.对于凹多边形,多采用软件方法拆成三角形图元并辅以边界边标志处理[2],但效率较低,且客户端/服务器之间数据传输量大.目前的设计依实际需求或者仅支持到三角形扇,或者仅支持凸多边形.针对凹多边形,加速器增加了第11种图元GL_POLYGON_CONCAVE,并采用改进的区域填充扫描线算法完成光栅化[7].
图元渲染过程中被剪裁的图元在重新装配过程中常面临着色模式问题.这是由于图元渲染包括单调着色和平滑着色两种模式,裁剪后图元由于属性保持模式使得重新装配的图元在单调着色模式下渲染颜色与OpenGL规范不一致.对于该问题,专利[8]依靠反馈通路将剪裁后且位于视口内的图元重新送回图元装配的前级,对新产生的顶点进行变换、光照等操作.然而深亚微米工艺中,线的延迟比门的延迟更重要[9],因此为避免片上大量走线,将渲染模式的判断隐式地提到图元装配处理以消除反馈通路;对每个图元的每个顶点按保留模式传递颜色属性.
图形加速器将高阶图元,如串、扇、多边形等细分为三角形进行装配.顶点数据从客户端到服务器只需传输一次,但在图元装配过程中可能会多次用于不同图元.每个图元的每个顶点在装配过程中设置了最多16种属性信息以保证装配结果与光栅化结果的正确,用C代表颜色(Color)、FFPC代表正面主颜色(Front Face Primary Color)、FFAC代表正面辅助颜色(Front Face Auxiliary Color)、BFPC代表背面主颜色(Back Face Primary Color)、BFAC代表背面辅助颜色(Back Face Auxiliary Color)、TC0~TC5代表6个纹理坐标(Texture Coordinate)、NV代表法向量(Normal Vector)、EF代表边界边标志(Edge Flag)、PM代表多边形填充模式(Polygon Mode)、CP代表是否凹多边形(Concave Polygon)、V代表顶点坐标(Vertex coordinate).根据支持图元的类型,共设置4个存储单元BUF0~BUF3暂存属性信息,比专利[8]中要暂存当前顶点、后续若干顶点、复用顶点、顶点标签、控制标签、装配后图元、装配后待发送图元等信息需要的存储要少,降低了片内集成大量存储的压力.
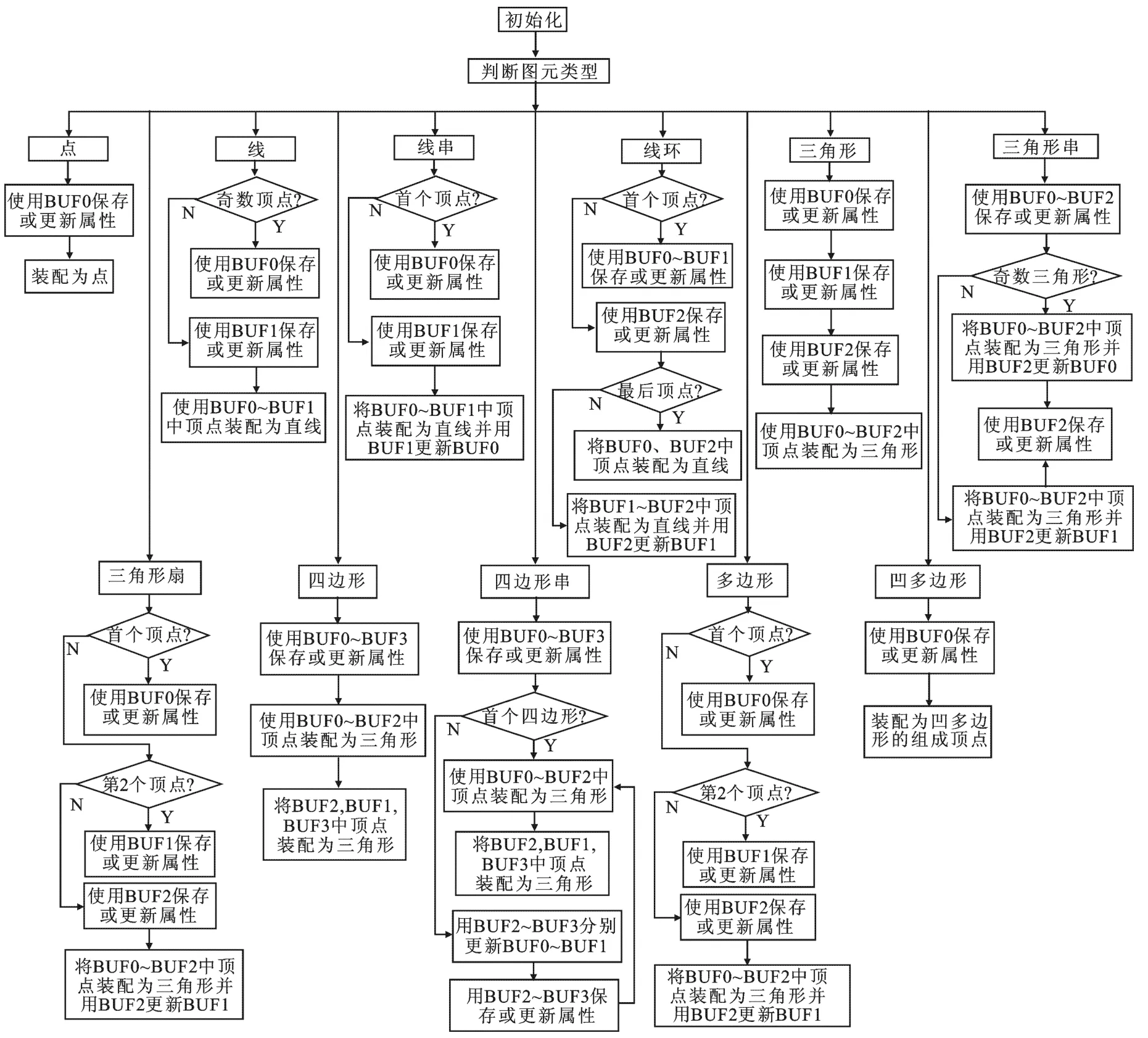
图2 图元装配流程图
图元装配流程图如图2所示.初始化阶段将各个属性设为默认值,继而等待glBegin命令,根据图元类型启动相应过程完成图元装配和信息输出.装配过程中,需要注意:
(1)对于所有图元,在没有启用光照时,不需装配属性FFPC、FFAC、BFPC、BFAC、NV;在没有启用纹理时,不需要装配属性TC0~TC5;
(2)对于点、线、线串、线环,不需要装配属性EF、PM、CP;
(3)对于三角形、三角形串、三角形扇、四边形、四边形串,不需要装配属性CP;
(4)对于四边形、四边形串、多边形的装配,应注意EF属性的正确使用;
(5)对于凹多边形,应注意CP属性的正确设置.
鉴于加速器是一个软硬协同的图形渲染系统,为降低硬件电路的设计压力,软件部分对于应用程序的编译包括了对无效顶点的处理,保证送入加速器的顶点数目为构成对应图元的合理值,比如,对于点图元,保证顶点个数不少于1;对于三角形图元,保证顶点个数为3的正整数倍,多余的1个或2个顶点忽略.
1.2.4 光栅化
光栅化完成点、线、三角形等基本图元向二维图像空间像素点的转换.关于点、线、三角形等基本图元的光栅化有着成熟的算法;凹多边形采用改进的区域填充扫描线算法完成光栅化.为了创建具有真实感效果的三维场景并表现物体表面的细节,对渲染场景进行光照和纹理贴图.光照模型是生成真实感图形的基础,经典的Phong模型[10]易于用软件或硬件高效实现,几乎是所有实时图形渲染系统选用的模型;加速器采用Phong模型并支持多达8盏灯.鉴于纹理贴图是个大主题,又受限于可编程逻辑器件的片上资源,加速器实现了基本的纹理操作,并支持纹理组合器,可以对纹理、片断以及常量颜色进行数学运算.
光照与纹理处理的流程如图3所示.图中虚线代表GL_LIGHT2~GL_LIGHT6的处理流程,由于8盏灯的处理流程相同,限于篇幅,图中从略.一般情况下,光照先于纹理处理,而设定光照模型的GL_SEPARATE_ COLOR为TRUE时,镜面亮点要放在纹理之后处理,因此加速器设计时设置片元主颜色和辅助颜色的寄存器,并在GL_LIGHT0~GL_LIGHT7的使能判断与计算过程中,依次累加以得到全部光源对片元主颜色和辅助颜色的贡献;继而处理纹理时则依据镜面光是否分离决定镜面亮点的计算,纹理处理过程中支持纹理组合器,包括GL_REPLACE、GL_MODULATE、GL_DECAL、GL_ADD和GL_BLEND等功能[11].

图3 光照和纹理处理流程图
由于渲染画质同运算速度都是图形加速器优化的重点,随着应用对画质需求的提高,全屏抗锯齿技术(Full-Screen Anti-Aliasing,FSAA)逐渐成为图形加速器的必备功能.FSAA技术不同于光栅化的抗锯齿(Anti-Aliasing,AA)技术仅对alpha分量根据片元的像素占有率处理,而对RGBA这4个分量都根据应用程序要求进行处理并把结果添加到累积缓冲区.因此,加速器的帧缓冲区包含颜色缓冲区和累积缓冲区以支持FSAA.渲染过程中首先清除累积缓冲区,并启用颜色缓冲区用于像素读取和写入;使用累积缓冲区对图像微移,完成渲染结果的超采样并求均值,实现对所有渲染图元的抗锯齿处理.
2 仿真平台
大规模集成电路的仿真验证约占电路开发消耗的70%.为保证功能的正确性与完整性,首先从系统级构建了基于C/C++的软件仿真平台,用于验证系统方案与实现算法的可行性;同时基于System Verilog语言搭建了周期精准的硬件模型与硬件仿真平台,并采用Synopsys公司的VCS进行仿真与代码覆盖率统计.
2.1 软件仿真平台
为验证图形加速器的系统方案与实现算法,按照第1部分的体系结构设计,基于C/C++建立了软件仿真平台GAU(Graphics Accelerator Unit),由线程client、server和display组成:①client是server与用户相交互的接口,负责读取渲染命令并解析;②server负责完成应用程序的渲染,其处理流程基于前述的体系结构,是仿真平台的核心;③display负责对所生成的图形进行绘制.
2.2 硬件仿真平台
硬件电路的仿真验证,从工程实践上一般包括系统集成前基于测试向量的单元电路验证、系统集成后基于应用程序的单元电路验证、系统集成后基于应用程序的系统级验证以及系统应用验证4个阶段,然而随着系统规模的增加,测试向量、应用程序的规模将非常巨大,难以维护,而且有时几乎是不可能的.加速器的仿真基于System Verilog验证方法学搭建了一种分层的测试平台,包括测试层、场景层、功能层、命令层、信号层,其中:①测试层是顶层,包含了测试和功能覆盖率.②场景层用于驱动相应的命令送往功能层.③功能层接收上层事务,并将之分解为独立的命令送往用于预测事务结果的记分板.④命令层驱动待测设计的输入,并将待测设计的输出与监视器相连,监视器负责检测信号的变化;使用断言监视穿越信号变化.⑤底部的信号层连接待测设计与测试平台.
3 原型系统与测试
对经过充分仿真验证的图形加速器电路开发原型系统实测[12],选择Altera公司的EP2C70F896C6进行测试平台开发,总体结构如图4所示,其中NiosII软核将经键盘输入的OpenGL命令进行初步解析并送入图形加速器,同时完成液晶显示屏(Liquid Crystal Display,LCD)上的输入回显;图形加速器电路完成OpenGL图形程序的渲染,并将结果存入帧缓冲区,输出显示控制器从中读出数据后以标准时序发给显示器.根据软件QuartusII运行结果,电路规模约占FPGA总资源的83%,工作频率可达100 MHz.
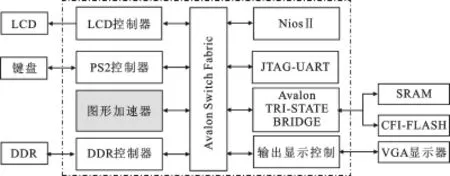
图4 图形加速器的原型系统框图

图5 图形加速器的部分渲染结果
采用典型的Open GL渲染程序对原型系统进行测试,结果表明系统可完成渲染要求.图5(a)所示为经过平移、缩放等几何变换、填充模式为GL_LINE的正方体;图5(b)所示为计算机图形学中的经典图形——Sierpinski镂垫;图5(c)所示为带凹多边形的旗帜;图5(d)所示为纹理组合器效果,依次是GL_REPLACE、GL_MODULATE、GL_DECAL、GL_ADD、GL_BLEND;图5(e)所示为带有光照、全屏抗锯齿前后的效果对比,左侧两幅图为全屏抗锯齿前的全图以及立方体、球体和圆环体交界处的细节图,右侧两幅图则为微移5次后全屏抗锯齿效果,从细节图对比中可以看出抗锯齿效果明显;图5(f)所示为像素操作的渲染结果,根据“像素颜色=像素颜色原值*缩放值+偏移值”,依次为缩放值为1.0,偏移值为0.0;R缩放值为0.0,偏移值为0.0;G缩放值为0.0,偏移值为0.0;B缩放值为0.0,偏移值为0.0;R偏移值为1.0;G偏移值为1.0; B偏移值为1.0;B缩放值为0.5,G偏移值为0.9.
4 结束语
根据多媒体以及图形图像处理能力的应用需求,基于经典流水线结构,笔者设计了一款面向OpenGL核心函数的图形加速器,并对其中几何变换、投影变换和视窗变换的关键操作——矩阵运算、图元装配以及光栅化等单元进行了优化设计.其支持基本的光照、全屏抗锯齿、纹理贴图以及纹理组合器等效果.为保证电路功能的正确性,构建了基于C/C++的软件仿真平台和基于System Verilog的硬件仿真平台;最后采用Altera公司的FPGA EP2C70F896C6搭建原型系统,电路规模约占FPGA总资源的83%,工作频率可达100 MHz.经过大量实例测试,图形加速器具备基本的图形渲染能力.
[1]Deng J,Li T,Jiang L,et al.Design and Optimization for Multiprocessor Interactive GPU[J].The Journal of China Universities of Posts and Telecommunications,2014,21(3):85-97.
[2]Shreiner D,Sellers G,Kessenich J M,et al.OpenGL Programming Guide:the Official Guide to Learning OpenGL,Version 4.3[M].Boston:Addison-Wesley Professional,2013.
[3]Tong T C,Chang Y N.Efficient Vector Graphics Rasterization Accelerator Using Optimized Scan-line Buffer[J].IEEE Transactions on Very Large Scale Integration Systems,2013,21(7):1246-1259.
[4] 许社教.三维图形系统中两种坐标系之间的坐标变换[J].西安电子科技大学学报,1996,23(3):429-432. Xu Shejiao.The Coordinate Transformation between the Two Coordinate Systems of 3D Graphic Systems[J].Journal of Xidian University,1996,23(3):429-432.
[5]Deng J R,Chang L B,Huang G X,et al.The Design and Prototype Implementation of a Pipelined Heterogeneous Multicore GPU[C]//High Performance Computing.Berlin:Springer,2013:66-74.
[6]Amira A,Bensaali F.An FPGA Based Parameterizable Systems for Matrix Product Implementation[C]//IEEE Workshop on Signal Processing Systems.Piscataway:IEEE,2002:75-79.
[7] 李平,韩俊刚,李自迪,等.区域填充扫描线算法的硬件设计与实现[J].微计算机信息,2011,27(6):124-125. Li Ping,Han Jungang,Li Zidi,et al.The Hardware Design and Implementation of Area Filling Scanline Algorithm[J]. Microcomputer Information,2011,27(6):124-125.
[8]Lavelle M G,Pan H,Ramirez A S.Vertex Assembly Buffer AND Primitive Launch Buffer:U.S.Patent 6,816,161 [P].2004-11-9.
[9]Shen X B.Evolution of MPP SoC Architecture Techniques[J].Science in China Series F:Information Sciences,2008,51(6):756-764.
[10]Phong B T.Illumination for Computer Generated Pictures[J].Communications of the ACM,1975,18(6):311-317.
[11]Sellers G,Wright R S,Haemel N.OpenGL Superbible:Comprehensive Tutorial and Reference[M].Boston:Addison-Wesley,2013.
[12]Guo F,Wan W G,Zhang X M,et al.Design of Test Platform for 3D Graphics Pipeline Based on Micro Blaze[C]// International Conference on Audio,Language and Image Processing.Washington:IEEE Computer Society,2012:392-396.
(编辑:王 瑞)
Design and implementation of the graphics accelerator oriented to OpenGL
DENG Junyong1,LI Tao1,JIANG Lin1,HAN Jungang1,SHEN Xubang2
(1.School of Electronic Engineering,Xi’an Univ.of Posts&Telecommunications,Xi’an 710121,China;2.School of Microelectronic,Xidian Univ.,Xi’an 710071,China)
In order to explore the self-development of the graphics processing unit,this paper presents the design of a graphics accelerator which utilizes the classical pipelined structure and supports OpenGL primary commands.The matrix computational unit,which is the critical operation of geometric transformation,projection transformation and viewport transformation,primitive assembly unit and rasterization unit have been optimized to improve the efficiency.The accelerator realizes the rendering effects of Gouraud shading,lighting,full-screen anti-aliasing and texture mapping.In order to verify the circuit,the software and hardware simulation workbench based on C/C++and System Verilog respectively have been established. The prototype system is implemented on EP2C70F896C6 of Altera which takes up to 83%of the FPGA resource,with the speed being up to 100 MHz.The test results of plenty of rendering applications show that the accelerator possesses the capability of graphics rendering.
graphics accelerator;matrix computation;primitive assembly;full-screen anti-aliasing; prototype system
TP302
A
1001-2400(2015)06-0124-07
10.3969/j.issn.1001-2400.2015.06.022
2014-09-18
时间:2015-03-13
国家自然科学基金重点资助项目(61136002);国家自然科学基金资助项目(61272120);陕西省自然科学基金资助项目(2013JC2-32,2015JM6326);西安邮电大学青年教师科研基金资助项目(ZL2014-21)
邓军勇(1981-),男,副教授,博士,E-mail:djy@xupt.edu.cn.
http://www.cnki.net/kcms/detail/61.1076.TN.20150313.1719.022.html
