利用概率的位置匿名算法
2015-12-22闫玉双谭示崇赵大为
闫玉双,谭示崇,赵大为
(西安电子科技大学综合业务网理论及关键技术国家重点实验室,陕西西安 710071)
利用概率的位置匿名算法
闫玉双,谭示崇,赵大为
(西安电子科技大学综合业务网理论及关键技术国家重点实验室,陕西西安 710071)
k匿名模型是一种有效的位置隐私保护技术,通过构造包含需要保护的用户在内的k个正在发送请求的用户的匿名区域,达到保护用户位置的目的.但是现有的k匿名模型仅能利用当前正在发送请求的用户,当同时发送请求用户较少时,就会导致匿名区域过大.为此,提出一种利用概率的位置匿名算法来保护路网中的移动用户的位置,利用当前时刻的不活跃用户的历史位置轨迹,计算出进入匿名路段的概率,可明显减小匿名路段长度.实验结果证明,基于概率的位置匿名算法与一般的k匿名模型相比较,提高了匿名效率.
k匿名;不活跃用户;概率;基于概率的位置匿名算法
利用位置的服务(Location-Based Service,LBS)给人们提供各种服务的同时也不可避免地产生了位置隐私泄露的问题.近年来,人们提出了很多利用位置服务的方法来保护移动用户的位置隐私方法.它大体可分为两类:一类是利用策略的[1]位置隐私方法,另一类是利用匿名的[2].其中利用匿名的位置隐私方法应用更为广泛.
k匿名模型是一种有效的位置隐私保护技术[3],它要求发布的数据中至少有k-1个个体与需要隐私保护的个体具有完全相同的准标识属性,从攻击者看来这些个体完全相同而无法区分,从而达到保护个体隐私信息的目的.文献[4]提出了位置匿名的概念,通过匿名的方法保护用户的隐私信息.直观上,很容易想到用假名来代替用户的真实身份[5].随着技术的不断发展,人们逐渐转移到对用户的轨迹信息的研究上来,发现移动用户的位置在时间上具有相关性[6-8].于是,如何有效地保护用户的轨迹信息成为人们关注的焦点.虽然如何把握位置与时间的相关性具有一定的难度,但是利用轨迹的启发式隐私度量方法仍然得到了人们的青睐,例如位置数据随机化[9-10]和对空间[11]或时间[12]数据的模糊化等方法.
在位置隐私的k匿名中,匿名区域的大小是衡量服务质量和通信开销的一个重要指标.现在的技术大多是借助于用户的位置更新来达到匿名隐私的目的,而不关心这些用户是否正在发送位置请求.这些没有发送请求的用户没有义务向服务器提交并更新他们的位置信息,所以这些用户不能得到很好的利用.文中将用户划分为活跃用户和不活跃用户.当前时刻向服务器发出请求的用户就是活跃用户,而不活跃用户是指当前时刻没有向服务器发送请求,但是之前发送过请求并且服务器有其请求记录的用户.匿名服务器仅仅知道活跃用户的当前位置信息,而不能获知不活跃用户的当前位置信息,这样就起到了保护不活跃用户隐私的目的.在k匿名中,若匿名值k比较大或者活跃用户的位置比较分散,那么匿名区也会比较大,从而增加了经济开销,同时降低了服务质量.之前的研究主要利用的是活跃用户,不活跃用户没有得到充分利用.若是可以利用不活跃用户,那么匿名区肯定会明显减小.在路网中,用户只能沿着道路移动,所以匿名区域就是路段的长度.例如图1所示,匿名值k=4,当仅仅利用活跃用户时,匿名的路段长度是dAB,而利用不活跃用户后,匿名路段长度变为dCD,显然比dAB小得多.可见,利用不活跃用户可以显著减小匿名路段长度.
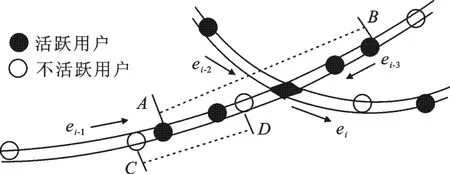
图1 利用不活跃用户进行匿名的示意图
系统模型如图2所示.当匿名服务器接收到移动用户的位置请求时,匿名服务器生成一个用户匿名来代替用户的真实身份,也就是路段长度.接着匿名服务器生成匿名化的位置请求集合R,ri=(ui,RLi,ci,t,k),表示单个用户的请求,其中ui代表用户的匿名身份,RLi代表用户在时刻t的匿名路段,ci代表当前时刻用户的请求内容,t代表用户请求的时刻,k代表匿名值.所有用户的请求都被存储在匿名服务器的数据库F中.然后匿名服务器将请求r′i=(ui,RLi,ci,t)发送给LBS位置服务器,LBS位置服务器接收到信息后就会查询,并且返回所有的结果候选集给匿名服务器.最终匿名服务器会根据用户的精确位置信息挑选最合适的结果,并发送给用户.其中匿名服务器是可信的,而位置服务器是半可信的.

图2 系统模型
1 算法模型
文中提出了一种利用概率的位置匿名(Probability-based Location Anonymity,PLA)算法,充分利用不活跃用户使匿名路段的长度减小,从而达到节省通信开销和提高通信质量的目的.通过研究在路网中的移动用户的行驶路径,发现移动用户的位置具有马尔科夫的特性,也就是说移动用户当前时刻的位置仅与前一时刻的位置有关.不活跃用户的分布特性可以根据匿名服务器所记录的这些用户的历史位置信息得到.根据历史数据和马尔科夫特性进一步计算概率,推知不活跃用户在某一路段的可能性大小,适当地选择匿名路段.
1.1 PLA算法流程
PLA算法的流程如下:
步骤1 可信服务器将整个路网进行划分直到最小的路段小于某一值,生成S,同时设置阈值vth0.
步骤2 在每个路网的交叉点处,匿名服务器通过F计算出相关的矩阵H(v,t)和C(v,t-1).
步骤3 匿名服务器不断更新F并根据用户请求找到一个初始目标路段ei,则,表示用户位于若ei满足隐私要求,则将ei二等分,此时用户位于,判断用户所在的小路段是否满足隐私要求;满足就继续分割,不满足就以大路段Lgi作为匿名路段.最终匿名路段用表示,对用户进行定位.
步骤4 在k匿名下,将初始匿名路段ei中活跃用户的数目与k值进行比较,匿名服务器决定是否进行定位的扩展运算.当活跃用户的数目不能满足隐私要求时,接着进行步骤5;否则,直接跳到步骤6.
步骤5 概率位置扩展匿名(Probability-based Location Extension Anonymity,PLEA)算法:当匿名服务器根据请求找到的初始目标路段ei却不能满足隐私要求时,路段需要进行扩展.这里在原路段的终端随机选取一条路段进行扩展.
随机选取的路段作为ei+1,使得路段ei+ei+1满足隐私要求,则,表示用户位于大路段然后将ei+1划分,选取前半段,也就是路段ei+ei+1-0并且,表示用户位于小路段,判断是否满足隐私要求.若满足就继续分割,不满足就以大路段作为匿名路段.选取最短路段作为最终的匿名路段,并且用RLi表示.
步骤6 服务器用RLi代替用户的位置将请求发送给LBS位置服务器.当匿名服务器收到请求结果时,会从中选择最优的结果,即最接近用户的位置发送给用户.
1.2 PLA算法具体过程
1.2.1 初始化过程
(1)路段的划分和表示方法.用S={E,V},表示整个路网的集合,其中E和V分别是边和顶点的集合,边表示路段,顶点表示路的交叉点,其中E={e1,e2,e3,…},v={v1,v2,v3,…}.采用二叉树的方法将路段进行划分.首先将目标路段进行二等分,前半段用0表示,后半段用1表示;然后再将前半段和后半段分别二等分,分别用00、01、10、11表示.以此类推,将路段继续划分直到长度小于某一阈值.用2表示整条路段.假设路段未划分时设为Grade 0,第1次划分过程为Grade 1,则第g次划分为Grade g,用Lgi表示用户处于Grade g时的一个单元路段.
用起点和终点坐标以及相应的二进制数来表示一条具体路段.将路段ei进行划分,若起点和终点坐标分别是(x1,y1)和(x2,y2),那么段路ei可以由它两端的交叉点和二进制数表示,例如((x1,y1),(x2,y2))-2、((x1,y1),(x2,y2))-0和((x1,y1),(x2,y2))-11.
(2)设置vth0.设在t时刻路段ei上除目标用户uk之外还有kt个活跃用户,则在k匿名下,此路段还需要包括k-1个活跃或不活跃用户.为了满足k匿名要求,则

其中,d为活跃用户的个数,mia会在式(3)中介绍.安全系数(PS)表示用RLj进行用户请求定位的安全程度.
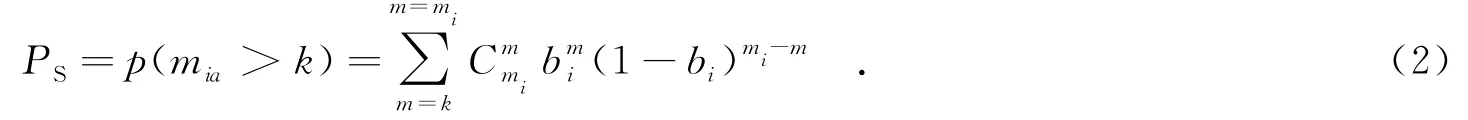
当vth0<PS时,说明用RLj进行用户请求匿名不会暴露用户的位置隐私.
1.2.2 计算不活跃用户进入路段ei的概率
定义两个矩阵,分别是行为预测概率矩阵C(v,t-1)[13]和历史行为矩阵H(v,t-1).
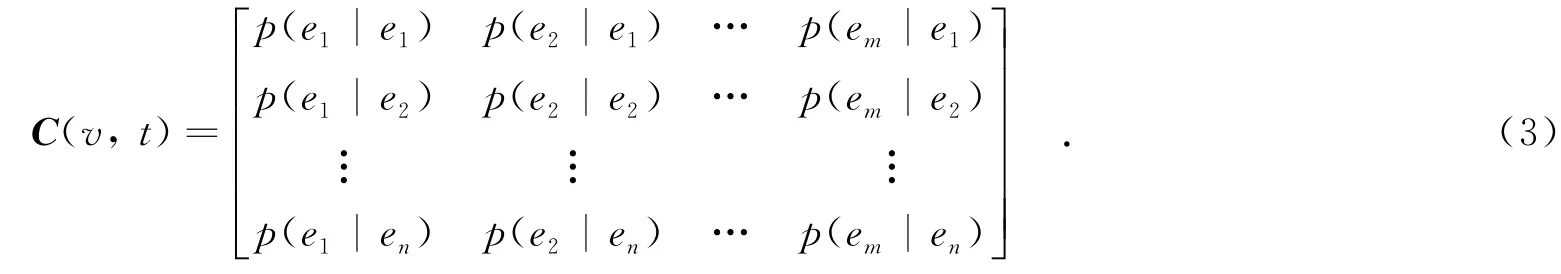
C(v,t-1)表示用户从路段ei转到路段ej的概率分布,其中t-1表示时刻,v表示交叉点的速率,e1,e2,…,em表示与此交叉点直接相连的路段,p(e2|e1)表示用户在路段e1上转到e2上的概率.
匿名服务器会记录发送过请求的用户的所有历史行为信息形成矩阵H(v,t-1),也就是路段行驶的次数以及转向的情况.

1.2.3 计算过程
当路段ei上的活跃用户数目小于k值时,可以利用ei上的不活跃用户来完成k匿名.如图3所示,与路段ei直接相连的其他路段(ei-3,ei-2,ei-1)上的用户在t-1时刻发出请求,而在t时刻未发出请求定义为不活跃用户,这部分用户的集合用Una表示,t时刻在路段ei上的不活跃用户用Uia来表示,mi和mia分别表示集合Una和Uia的用户数量.容易得出Uia⊆Una,且mia≤mi.
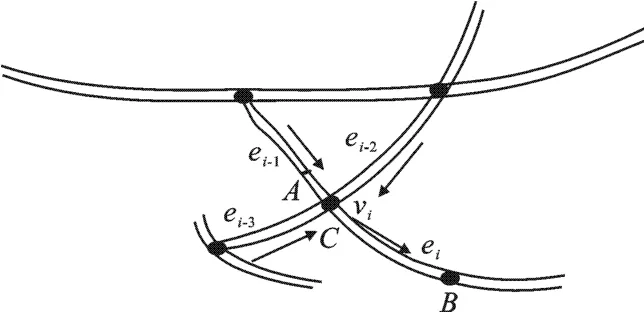
图3 用户进入路段
(1)计算单个不活跃用户进入路段ei的概率.若用户uk∈Una,根据历史行为矩阵H(v,t-1),服务器会找到所有可能进入路段ei的路径.
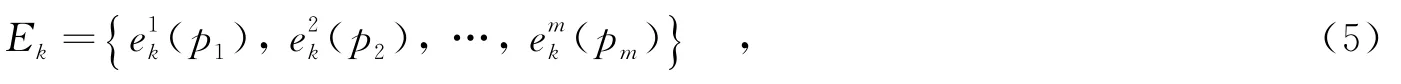
在PLA算法中,不需要知道在时刻t用户uk的位置是否活跃,但是需要关心是否在路段ei上或者行驶进ei的可能性.即使知道用户在哪条路段上,也不能确定用户是否在ei上.对于用户uk∈Una,服务器会计算出此用户的速率范围表示在时刻t-1到时刻t的速率范围,即

其中,D(·)表示路段上两点的距离.
如图3所示,在时刻t用户在点A处,点C和B表示路段ei的起点和终点,若用户能够进入路段ei,则在时刻t,要求
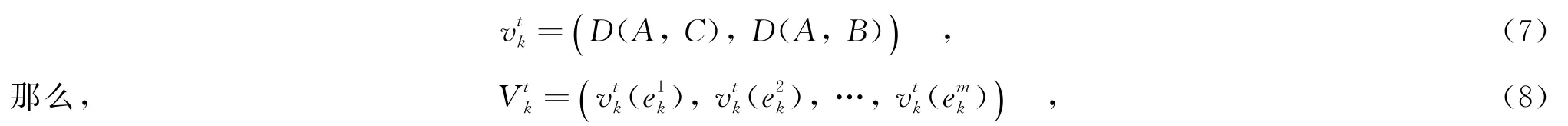
则表示当用户uk在t时刻选择路段emk时,能够进入路段ei时的速率范围.
所以,计算出速度的变化量为

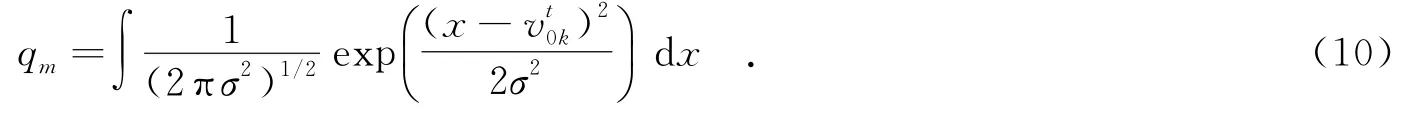
为了方便计算,将Ek变换为E

则用户uk能够进入路段ei的概率为
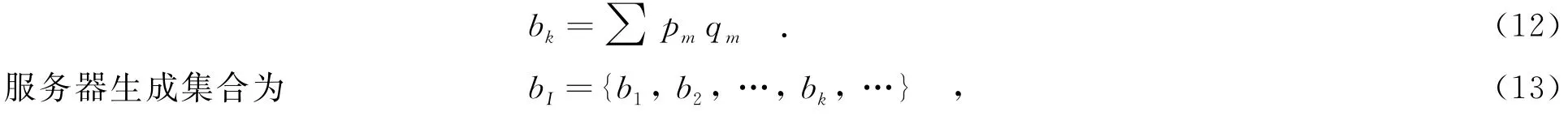
表示每个用户进入路段ei中的概率.
(2)计算m个不活跃用户uk∈Una进入路段ei的概率

其中,bk∈bI,mi是bI中元素的个数,注意m并不是幂指数,指的是m个形式为bk的数相乘,mi-m的意义与m相同,表示mi-m个形式的1-bk相乘.
例如 bI={b1,b2,b3},则
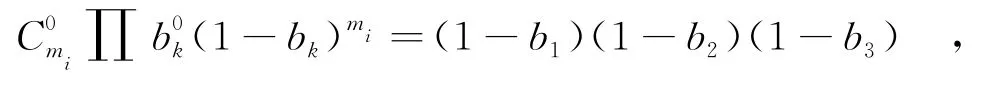

如图1所示,路段e3上仅有2个活跃用户,采用PLA算法则还需要选取两个不活跃用户,若p=大于某一概率值如0.9时,就可以将dCD作为匿名路段.
2 实验仿真
2.1 实验数据及参数
(1)实验环境.假设每个移动用户在结点处的初始速度是30 km/h,且只能沿着道路行驶,他的主要属性包括速率、转向和加速度(本实验中即速率的变化量).移动用户在一个时间戳内会改变速率也就是加速度,加速度符合正态分布,设均值和方差分别是0 km/h和15 km/h.
使用基于网络的移动对象发生器[14]产生移动点,并且模拟它们在15 km×15 km德国的奥尔登堡的4种道路上的行驶状况,包括高速公路、国道、一般公路和街道.路网仿真器产生随机分布的5 000个移动用户,将这些用户的历史信息存入数据库F,并且生成一个请求集合,包括移动用户的ID、地理位置、请求内容和请求时刻t以及匿名值k.
(2)实验参数.本实验通过与没有用预测矩阵的利用路网的k匿名方法做比较,根据路段长度的平均减少率dm来评估PLA算法的性能.
2.2 实验分析
路段长度的减少率用来评价PLA算法的服务质量.假设未使用PLA算法时得到用户请求定位的路段长度为,而PLA算法得到的路段长度为RL,则路段长度的减少率可定义为.分别选取不活跃用户数量与活跃用户数量比例为1∶1或2∶1进行实验.每个活跃用户的匿名值k范围选取3~7.所有请求用户在不同的匿名值下取平均减少率dm.设置不同的时刻t和匿名值k来验证匿名路段长度的平均减少率dm的变化趋势.
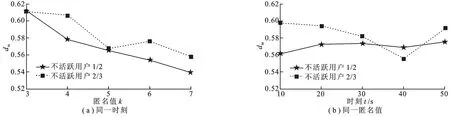
图4 实验结果示意图
由图4(a)可知,使用PLA算法后,在相同时刻t,用户匿名路段的平均减少率dm在不同匿名值k下可高达0.5以上,并且k值越大,匿名路段的dm值越小,这是因为随着匿名值k的增大,增大了不活跃用户满足k匿名的难度.由图4(b)同样可看出用户在相同匿名值k的情况下,其匿名路段的平均减少率dm在不同时刻t的条件下同样可达到0.5左右,而50 s处相比40 s的dm值出现了较大的增长,可能是50 s时不活跃用户在此路段上比较密集,所以较容易满足k匿名,使得匿名路段较短.从图4还可看出,当不活跃用户增多时,路段长度的平均减少率dm就越大,因为不活跃用户越多,其分布会越密集,就越容易满足用户的隐私需求,匿名路段长度的平均减少率dm也就越小,PLA算法也就越精确.实验证明,PLA算法可以在一般的k匿名算法的基础上很大程度地减小匿名路段长度,从而更好地保护用户的隐私,减小通信开销.
3 结束语
针对位置隐私保护的需求,文中提出了一种在路网中利用概率的位置匿名PLA算法.该方法可充分利用不活跃用户,通过计算不活跃用户进入匿名路段的概率,达到提高匿名区域用户数量的目的.实验证明,PLA算法可以在一般的k匿名算法的基础上很大程度地减小匿名路段长度,从而更好地保护用户的隐私,减小通信开销.
[1]Duri S,Gruteser M,Liu X,et al.Framework for Security and Privacy in Automotive Telematics[C]//Proceedings of the 2nd International Workshop on Mobile Commerce.New York:ACM,2002:25-32.
[2]Wang Y,Xu D,He X.L2P2:Location-aware Location Privacy Protection for Location-based Services[C]//Proceedings of IEEE INFOCOM.Piscataway:IEEE,2012:1996-2004.
[3]Wang Q,Xu Z,Qu S.An Enhanced K-Anonymity Model Against Homogeneity Attack[J].Journal of Software,2011,6(10):1945-1952.
[4]Gruteser M,Grunwald D.Anonymous Usage of Location-based Services through Spatial and Temporal Cloaking[C]// Proceedings of the 1st International Conference on Mobile Systems,Applications and Services.New York:ACM,2003: 31-42.
[5]Beresford A R,Stajano F.Location Privacy in Pervasive Computing[J].IEEE Pervasive Computing,2003,2(1):46-55.
[6]Kim M,Fielding J J,Kotz D.Risks of Using AP Locations Discovered through War Driving in Pervasive Computing [M].Berlin:Springer,2006:67-82.
[7]Xu T,Cai Y.Exploring Historical Location Data for Anonymity Preservation in Location-based Services[C]// Proceedings of the 27th IEEE Communications Society Conference on Computer Communications.Piscataway:IEEE,2008:1220-1228.
[8]Chow C Y,Mokbel M F.Trajectory Privacy in Location-based Services and Data Publication[J].ACM SIGKDD Explorations Newsletter,2011,13(1):19-29.
[9]Suzuki A,Iwata M,Arase Y,et al.A User Location Anonymization Method for Location Based Services in a Real Environment[C]//Proceedings of the 18th ACM International Symposium on Advances in Geographic Information Systems.New York:ACM,2010:398-401.
[10]Kato R,Iwata M,Hara T,et al.A Dummy-based Anonymization Method Based on User Trajectory with Pauses[C]// Proceedings of the 20th ACM International Symposium on Advances in Geographic Information Systems.New York: ACM,2012:249-258.
[11]Yigitoglu E,Damiani M L,Abul O.Privacy-preserving Sharing of Sensitive Semantic Locations under Road-network Constraints[C]//Proceedings of the 13th IEEE International Conference on Mobile Data Management.Washington: IEEE Computer Society,2012:186-195.
[12]Pan X,Xu J,Meng X.Protecting Location Privacy against Location-dependent Attacks in Mobile Services[J].IEEE Transactions on Knowledge and Data Engineering,2012,24(8):1506-1519.
[13]Karimi H A,Liu X.A Predictive Location Model for Location-based Services[C]//Proceedings of the 11th ACM International Symposium on Advances in Geographic Information Systems.New York:ACM,2003:126-133.
[14]Thomas Brinkhoff:Network-based Generator of Moving Objects[EB/OL].[2014-05-20].http://iapg.jade-hs.de/ personen/brinkhoff/generator/.
(编辑:李恩科)
Probability-based location anonymity algorithm
YAN Yushuang,TAN Shichong,ZHAO Dawei
(State Key Lab.of Integrated Service Networks,Xidian Univ.,Xi’an 710071,China)
As one of the most effective location privacy preservation technologies,the k-anonymity model provides safeguards for location privacy of the mobile client against vulnerabilities for abuse by constructing an anonymous area of k users including the protected one.However,most existing k-anonymity models only utilize the users who are sending requests at recent time.If there are not enough requesting users,the generated anonymous area of the k-anonymity model will be larger than expected.In this paper,a Probability-based Location Anonymity(PLA)algorithm is proposed for protecting location privacy of the mobile users in a road network.The PLA model takes advantage of the historical path track of the users who are not sending the request currently,and then computes the probability into the anonymous section so that it can greatly reduce the size of the anonymous area.Experimental results show that the PLA algorithm is superior to the k-anonymity and it increases its anonymous efficiency enormously.
k-anonymity;inactive users;probability;PLA algorithm
TP918.91
A
1001-2400(2015)06-0075-06
10.3969/j.issn.1001-2400.2015.06.014
2014-07-13
时间:2015-03-13
中央高校基本科研业务费专项资金资助项目(K5051201027);高等学校学科创新引智计划资助项目(B08038)
闫玉双(1987-),女,西安电子科技大学博士研究生,E-mail:yushuangy15@163.com.
谭示崇(1979-),男,副教授,E-mail:sctan@mail.xidian.edu.cn.
http://www.cnki.net/kcms/detail/61.1076.TN.20150313.1719.014.html
