基于MapReduce分布式连接算法优化技术研究
2015-12-11李素若
李素若
(荆楚理工学院,湖北 荆门 448000)
基于MapReduce分布式连接算法优化技术研究
李素若
(荆楚理工学院,湖北 荆门 448000)
为了解决大规模数据集的并行运算问题,采用以映射与归约为主体思想的编程模型MapReduce,以分布式QR-树索引结构与分布式并行编程模型MapReduce为组合进行连接算法设计。研究结果表明:采用该算法使得数据分布式并行编程计算更加便捷,也解决了传统单机集群系统无法满足海量数据时空开销的迫切需求。在云计算背景下研究MapReduce分布式空间连接算法有很大的意义和价值。
MapReduce;集群技术;QR-树索引;分布式空间连接;算法;优化
MapReduce是诞生于Google所设计的并行编程模型和分布式计算框架,它是云计算中的关键技术,它是开源的,所以能为分布式空间连接计算提供实践平台[1]。在业界,基于MapReduce的分布式并行计算模型已经掀起了一场“集群革命”,专门针对于大规模数据集的分析和处理,完全代替了原有的高性能节点计算模式,证明了其极高的可用性、可伸缩性和高容错性。因此MapReduce分布式连接并行算法在各个领域获得广泛认可和应用也就成为必然。
一、基于MapReduce分布式连接算法的相关理论
基于MapReduce理论的分布式连接算法就是要在偌大的数据库空间中快速链接索引相关数据并获取,所以其算法过程具有化解其庞大性与复杂性的特征。本文也基于此介绍了与分布式连接算法相关的几个理论,为后来的算法优化技术研究打好基础。
1.QR-树索引
QR-树索引基于R-树索引展开,它的基本思想是要对一定的实际地理空间范围进行合理的四叉树规划。换言之就是把二维空间范围内的常规四象限划分为多个子索引空间,随后通过R-树构建方式,借助GIS等系统软件技术为数据库系统应用扩容。如果当索引数据量不断增加,R-树与四叉树不能解决数据存储量空间交叠区域快速扩容问题时,就可以利用QR-树来解决该问题。QR-树所表现的是一棵具有深度d的四叉树Qt和n棵R-树所构成的共同整体。在QR-树中遵循以k为空间维度的公式即:
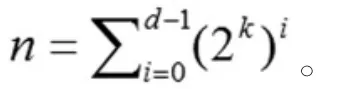
n所表示的就是Qt节点的数量,如果依据广度便历次序为它们编号,就可以表示为:Qt0,Qt1……Qtn-1。Qt在这里将全部空间数据区域都进行了划分,共分割为n个d级别子空间数据区域,最后为他们依次编号记录为S0,S1……,Sn-1(S0=S)。在这里每个级别的数据区域之间都不能发生交叠,而根据R-树可以将数据空间区域表示为Rt0,Rt1……,Rtn-1这些数据分别与Qt中的n个节点及n个子数据空余区域之间紧密相联系在一起。综上所述,QR-树数据空间的结构就应该如图1。
如图1所示,QR-树中包括了2棵四叉树和5棵子R-树所组成,所以它的空间数据区域也被划分为2个级别5个子空间。在这其中,S0~S4以及Rt0~Rt4这两大数据集合之间呈紧密联系状态[2]。
2.并行计算技术
在处理海量空间数据方面,并行计算技术显然要优于串行计算。并行计算技术主要涵盖两大类型:空间并行与时间并行。空间并行用到了多个处理器进行并发式的计算方式。时间并行则是典型的流水线技术。而并行计算根据其工作流程又分为两类:数据并行和任务并行。数据并行会将一个大任务划分为诸多子任务,并映射到不同的处理器或计算节点上同步处理,这样可以大大提升对并行任务的完成效率。而管理和运作这些计算节点的支配者就是集群系统,集群系统将离散的计算机网络重新组合起来,保证网络中各个子系统能够紧密协作。大企业会利用集群系统将高性能的计算机网络集合起来形成计算机集群,这种数据密集型的应用对企业的集群技术发展很有帮助。尤其是在开源云平台Hadoop问世以后,集群系统的可扩展功能也越来越多,比如在低端商用计算机上也能构建平台,让并行计算技术与集群技术更加紧密的结合,从而保证对海量空间数据的稳定管理和随时获取[3]。
目前企业所应用的集群技术主要有两种,MPI和MapReduce,本文重点介绍MapReduce集群技术。MapReduce是典型的分布式计算软件构架,它的特点优势明显,能够合理有效的屏蔽底层实现更多细节,这就为程序员的编程工作降低了难度,让并行程序编写更加高效化。由于Hadoop平台的出现,所以MapReduce也真正实现了开源,它在任务调度、实现机制和性能调优三方面都有提升。
(1)MapReduce的实现机制
首先说实现机制,MapReduce分布式并行计算框架是由一个JobTracker和众多个TaskTracker所组成的[4-6]。这其中JobTracker主要负责调度组成某个作业所涉及到的所有分布于集群TaskTracker中的子任务。而JobTracker则负责监控这些任务的实际执行状况,当有任务分配失败,它会对其进行重新分配。当客户提交Job时,JobTracker就会接收和处理Job信息并进行信息配置,然后将配置信息发送给各个Task-Tracker,对其进行调度组成处理,这样就构成了一个完整的MapReduce分布式计算模型,它的程序运作流程如图2。
图2描述了MapReduce集群技术程序的整体运作流程。基本上,当客户提供Job任务时,JobTracker就会负责调度任务,通过执行Map函数和Reduce函数来监控Map和Reduce两阶段过程。而在数据输入阶段,用户会通过ImputFormat来实现RecordReader接口,并将接口中的功能分片解析转化为键值对,提供给Map函数继续操作。当Map函数阶段操作完毕后,就会进入Reduce阶段,它一般要经历混洗、排序和Reduce三个过程。混洗阶段主要负责为MapReduce计算框架生成key,并将相关结果传输给Reduce进行key区间内节点值的获取;而排序阶段则与混洗阶段同步展开,它为数据形成key键值的集合;最后是Reduce阶段,此时数据集合已经形成,利用Reduce方法对数据进行最终处理,然后再借助Output-Format将处理好的数据结果传输到HDFS上。

图2 MapReduce集群技术程序运作流程示意图
(2)MapReduce的任务调度
MapReduce的任务调度受限要保证数据分布的均匀性,这样Map任务才能在本地顺利执行。另外,也要考虑到MapReduce任务调度策略的公平性,注意JobTracker在为Worker分配任务时可能存在的冲突性。而为了最大限度降低响应时间,MapReduce并行计算框架也采用了预测执行机制。它的思路是如果某个所获取的节点性能较差,就将该节点作为备份任务转移到其它节点上辅助运行。
(3)MapReduce的性能调优
利用MapReduce进行并行编程模型编写中并行程序的性能调优可以帮助其快速达到预期效果。用户可以自定义Map和Reduce任务数量及系统参数。近些年来,MapReduce并行编程模型在执行性能方面也得到了优化,它的具体优化主要体现在以下几大方面。
第一,对集群参数的合理配置,对MapReduce中所使用的存储设备进行mount到noatime选项的设
置,就可以提高磁盘的I/O性能,减少配置文件中内存分配的mapred.child.java.opts属性,从而提高分布式连接算法的性能。
第二,可以为基于MapReduce的并行编程模型添加combiner,因为在并行计算程序要涉及到一些分类聚合函数,所以添加combiner可以完成数据到达reduce端的初始聚合工作,这样就能大量降低写入磁盘的数据量与通过网络途径传输reduce的数据量,由此一来整体并行计算的性能也会随之提高。
第三,也要考虑选择合适的二进制Writable来进一步维护编程模型性能。一般来说,二进制Writable能够做到对文件转换时消耗的降低,从而降低中间数据结果所占用的空间,而减少中间结果空间也能够为并行计算带来更高的性能[7]。
二、基于MapReduce分布式空间连接算法的设计与优化
1.分布式空间连接算法的设计
基于QR-树和MapReduce的空间连接算法要依靠作业Job和MapReduce共同完成。它的具体操作步骤主要有对并行连接任务的生成;对空间连接查询的计算。
(1)生成并行连接任务
若要生成并行连接任务要行使以下三个步骤,初始任务生成——初始任务分发——并行连接任务生成。这三个步骤都要通过MapReduce并行计算框架中的工作机制和作业Job进行预处理。
首先是初始任务生成,它主要是在编程模型的主节点上提交job作业前执行,它的具体任务生成描述如下:为空间数据假设两层空间关系R和S,为它们分别构建QR-树索引,并将它们重新标记为A与B。在扫描它们的根节点时就会产生初始任务,初始任务以一个三元组T={Ai,Bj,BBoxij}。考虑到初始任务的生成仅仅对AB根节点进行扫描,所以空间复杂度很低,可以在job作业提交之前就快速高效完成。
其次是初始任务分发。初始任务分发是将初始任务集发布给Reduce任务开展并行处理工作,它需要Map任务配合共同完成。Map任务的介入可以为初始任务生成任务集{Ai,Bj,BBoxij}。
最后是并行连接任务生成,它需要P个Reduce任务同时处理,而P也代表了并行连接任务所生成的同步并行度。当并行连接任务生成并经过Reduce任务处理之后,就会和上文中所提到的A/B子R-树级别共同计算出交叠的子R-树元组,它们就是并行连接任务的结果集[8]。
(2)分布空间连接计算
分布空间连接计算也可以分为两个步骤,并行连接任务分发和执行,它们都是基于MapReduce并行计算框架工作机制中的Map阶段任务分配及Reduce阶段的任务执行所对应完成的。在连接计算过程中,MapReduce函数输入输出键值如下表1所示。

表1 分布式空间连接计算的MapReduce函数输入输出情况表格
2.分布式空间连接算法的优化
在实际的应用中,我们发现分布式空间连接算法是存在连接和访问问题的,而且算法性能也有待提升。本文主要基于实时缓存的方法优化该算法。它得益于Hadoop分布式缓存机制所带来的启示。它的原理就是在提交Job作业之前,就对集群系统中的所有节点进行共享数据的复制和分发。而在算法方面,它会以并行连接任务生成与空间连接计算来解决存在的并发访问问题。它的具体优化步骤如下:
当并行连接任务生成过程中,要访问QR-树根节点,并且检查本地数据空间是否存在缓存的分布式QR-树子树索引文件。如果不存在,则将索引文件恢复到本地磁盘上,再访问本地磁盘数据空间;如果存在,则直接访问本地磁盘上的缓存索引文件。分布式空间连接计算阶段和并行连接任务生成过程同理。
总之,要考虑在优化算法时空间数据库中可能出现的实时缓存为本地磁盘所带来的存储负载问题,所以有效的优化可以大幅度提升算法的性能,提升对大规模数据分析及处理的有效性[9]。
三、结论
基于MapReduce的分布式空间连接算法是空间数据库中一种极为复杂的操作过程,它对空间数据库领域的发展具有较为深远的现实影响。所以随着企业空间数据规模的与日俱增,利用MapReduce这样的云计算技术来提高海量空间数据连接、计算和查询已经逐渐成为趋势,这也证明了在云计算背景下研究MapReduce分布式空间连接算法的意义和价值。
[1]Jeffrey Dean,Sanjay Ghemawat.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[2]张常淳.基于MapReduce的大数据连接算法的设计与优化[D].合肥:中国科学技术大学,2014.16-23.
[3]霍树民.基于Hadoop的海量影像数据管理关键技术研究[D].长沙:国防科学技术大学,2010.[4]G.Dan.Development of Massive Astronomy Data Federation System and Research of Data Mining Algorithms–Tool Development and Algorithm Research[J].Publications of the Astronomical Society of the Pacific,2008,120(874):1357.
[5]Y.-W.Huang,N.Jing,and E.A.Rundensteiner,“Spatial Joins Using R-trees:Breadth-First Traversal with Global Optimizations[Z].in Proceedings of the 23rd International Conference on Very Large Data Bases,San Francisco,CA,USA, 1997.396-405.
[6]P.Mishra and M.H.Eich.Join processing in relational databases[J].ACM Comput.Surv.,1992,24(1):63-113.
[7]刘杰.基于MapReduce的分布式空间连接查询研究[D].赣州:江西理工大学,2013.28-40.
[8]陈勇旭,陈梦杰,刘雪冰,等.基于MapReduce的连接聚集查询算法研究[J].计算机研究与发展,2013,50(z1):306-311.
[9]郑启龙,房明,汪胜,等.基于MapReduce模型的并行科学计算[J].微电子学与计算机,2009,26(8):13-17.
Research on the Optimization Technology of Distributed Connection Algorithm Based on MapReduce
Li Su-ruo
(Jingchu University of Technology,Jingmen Hubei 448000,China)
To solve the problem of parallel computing with large data sets,using the mapping and reduction to the Juche idea about programming model MapReduce,distributed QR-tree index structure MapReduce distributed parallel programming model is a combination of the connection algorithm.The results show that the algorithm so that the data distributed computing parallel programming easier.The traditional single cluster system can not meet the urgent needs of massive data time and space overhead.In cloud computing,MapReduce distributed spatial join algorithm has great significance and value.
MapReduce;cluster;QR-tree;distributed spatical join;algorithm;optimization
TP311.13
A
1672-0547(2015)05-0107-03
2015-09-23
李素若(1969-),男,湖北荆门人,荆楚理工学院计算机工程学院副教授,硕士,研究方向:计算机网络、软件工程。
2015年湖北省教育厅科学研究项目“基于Mapreducn分布式连接算法优化技术研究”(B2015241);荆楚理工学院校级科研项目“面向大规模科学数据的基于Mapreducn分布式连接算法优化技术研究”(ZR201405)。
