基于Swiftstack的云存储关键技术研究
2015-12-07严晔王欢苏伟秦雪吴玉宁
严晔,王欢,苏伟,秦雪,吴玉宁
(1.长春理工大学 计算机科学技术学院,长春 130022;2.长春理工大学 信息化中心,长春 130022)
云存储的到来,让用户可以在有网络服务的地方随时访问云端存储的数据,避免了随身携带存储设备的麻烦。云存储是指通过分布式文件系统、网络技术、集群应用等功能,将网络中各种类型的存储设备,通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的系统,所以云存储可以认为是一个以数据存储管理为核心的云计算系统[1]。IDC(International Data Corporation)根据2013年全球数据量分析预测,到2017年全球的数据存储量将达到7235EB[2],虽然数据量在爆炸式的增长,但云计算发展至今仍没有一个较统一的行业标准,Amazon、Google、IBM、Microsoft、Swiftstack 等提供的云存储服务在应对不同客户要求时各有各的优缺点。针对开源云计算、云存储发展中系统架构和负载均衡问题,本文提出负载均衡设置策略以及数据处理过程,并进行了实验测试。
1 基于Swiftstacak的云存储架构
Swiftstack通过账户(account)、容器(container)、对象(object)[3]三层的逻辑结构来对存储数据进行抽象并将其映射到物理存储硬件中。云存储使用这样的逻辑结构可以为存储的数据创建独一无二的存储路径。在这里,账户(account)不是用户ID而是存储的区域(storage location)。云存储逻辑结构如图1所示。
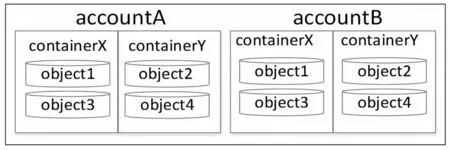
图1 云存储逻辑结构
Swiftstack通过集群(cluster)、区域(region)、带(zone)、节点(node)来划分和定义其存储体系结构,相当于平常所说的“点、线、面”,它们之间的相互关系如图2所示。
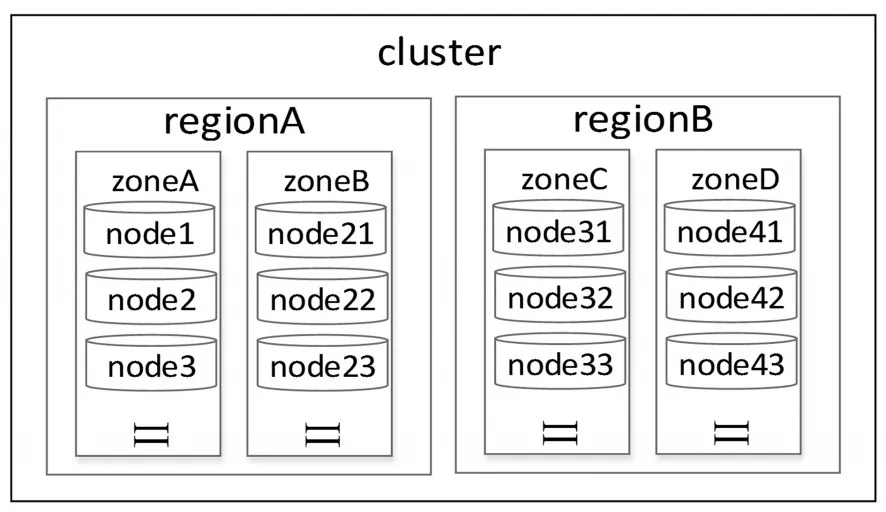
图2 云存储体系结构
2 负载均衡设置
Swiftstack数据请求的主要过程是在接收到HTTP请求后,先通过proxy server进程来确定数据要存储的路径,再由proxy server通过改进的一致性哈希算法将请求指向它要到达的存储位置。proxy server在大规模部署时常与storage server分开部署(如图3),数据的读写请求到达proxy server的机会是均等的。实际经验证明,在大规模部署时将proxy server与storage server分开部署,不用在proxy server前进行负载均衡,可以完全由独立部署的proxy server来处理数据的读写请求。
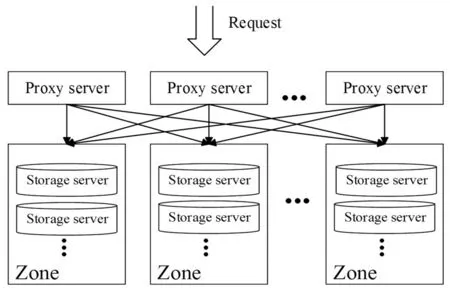
图3 大规模部署结构
而在中规模部署的情况下,proxy server与storage server都部署在同一节点内(如图4),proxy server只负责该节点内的数据存储与读取,其保存的哈希环信息也只有该节点内各个存储点的位置信息。在中规模部署的情况下,在节点外进行负载均衡,可有效地控制数据请求到达各节点的均衡性,不会出现一些节点过载,一些节点空载的情况。现在较流行的负载均衡算法大都是从SHA(Secure Hash Algorithm)算法演化而来,其基本结构都是哈希算法,在应对不同部署要求时,可对算法进行相应调整。中规模部署下通过load balance和proxy server作两次哈希均衡,将更好地控制数据访问和存储性能。

图4 中规模部署结构
3 基于Swiftstack的数据处理
3.1 一致性哈希环
存储节点先通过取它的存储路径哈希值,然后将他们都映射到一个哈希环上。为确保数据存储时可以较均匀的分布在各个物理存储器内,Swiftstack采用了哈希环虚拟分区的办法,例如:实际存储节点A,为其建立5个存储路径指向A的虚拟分区A-1,A-2,A-3,A-4,A-5,然后将这六个节点分别映射到哈希环上,此时的哈希环上将会较均匀的分布有这些节点。虚拟分区的数量是根据各个存储器容量大小来决定,容量大则权重(weight)较大,所设的分区数就高。但在实际应用中,容量较大的存储器不一定有高的接入速度,如果仅仅只考虑容量大小来确定权重,往往会导致部署完成后,该节点的读写性能不佳。所以在确定虚拟分区数量时除了考虑存储容量大小外,还要考虑存储器的接入速度和读写性能。
3.2 数据备份
云存储,就一定会涉及到数据备份的问题[4]。传统的数据备份都是在数据完成传输后再进行相应的数据拷贝和保存。Swiftstack在数据备份方面采用的方法是设置数据备份数,最小的备份数为2,在默认情况下为3,可以根据存储数据重要程度的差异设定备份数目。与传统的备份方式不同的是,Swiftstack在完成数据存储的同时对数据进行备份。以默认情况下的3个备份为例,数据X通过一致性哈希环被定位存储到dev1,在这同时,X的备份X-1,X-2,X-3也分别被映射到别的存储点,在这一过程中,如果X和X-1先完成存储,则X-2、X-3的存储进程则会被移到后台,待存储节点处理数据请求空闲时再继续进行,这样可以确保存储节点在处理数据请求繁忙时有足够的读写性能。除此以外,Swiftstack还有备份数据锁死机制,当某一分区发生改变时,位于该分区内的备份数据则会被锁死,直到位于该分区内的数据确认被改动后才解除锁死,这一锁死机制时间的长短可以在min_part_hours文件内进行设置。
3.3 数据完整性
为保证存储数据的完整性,Swiftstack在每个节点的后台都运行有审计监听进程,该进程会不间断的对存储节点内各个账户内的容器和存储对象进行扫描,确保所保存的数据不会因存储设备故障而损坏,如果扫描到损坏的数据,该进程会将损坏的数据放入隔离区再进一步处理。若是无效的数据或者过期的数据,那么会将它删除,若是有备份的数据,则会通过其该数据的其他备份来恢复。存储节点内每个账户、容器保存有各自的哈希列表,这些列表也会在后台不断地被扫描并及时更新,确保数据路径的准确及时性。
3.4 误删除恢复
Swiftstack在应对数据的误删除方面,有其相应的策略。通过Account reaper进程设置延迟删除的时间,在收到用户的删除请求后只是将该账户内的数据全部标记成已删除,待到达预设的删除时间后再对该账户及内容进行彻底删除。在这之前,用户都可以通过各备份点重新恢复数据。
4 Swiftstack的性能测试
在测试环境下对Swiftstack进行安装部署[5]。测试环境如表1所示。

表1 测试环境
测试环境下,设置了三个存储节点,proxy server和storage server都部署在各节点内,采用小规模部署下的结构。对Swiftstack分别进行了5GB非结构化数据的大文件和1.5GB非结构化数据的小文件的写入性能测试,测试结果如图5和图6所示。

图5 大文件写入性能
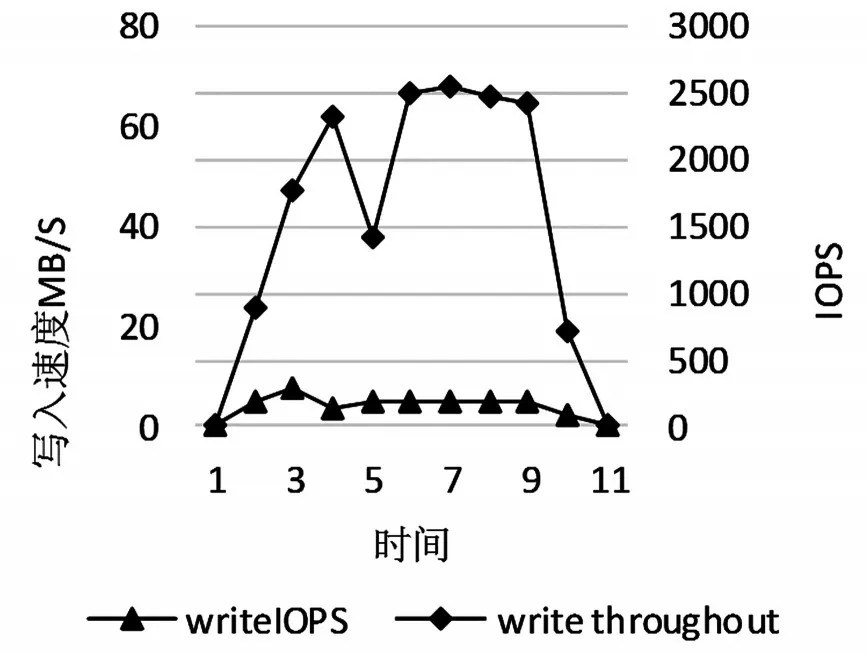
图6 小文件写入性能
从测试结果可以看出,在大文件写入过程中,数据的写入速度最高能达到16MB/s,写入的IOPS可以达到近180,写入速度的稳定性不高,达到峰值后就开始下降,磁盘的写入性能没有完全发挥出来,从而可以看出Swiftstack在对大文件的写入性能一般。在小文件写入过程中,数据的最高速度能达到70MB/s,而且在达到峰值后能较好的维持在较高速度,而且其写入时的IOPS也较稳定的维持在350左右,无论是写入的速度还是稳定性,相对较大文件来说,Swiftstack在小文件的写入性能方面较好。
5 结论
本文提出了大、中型云存储部署架构的设计方法和负载均衡的设置策略。研究分析了云存储架构、云存储数据处理过程,通过实验测试证明Swiftstack的存储性能能够满足用户对云存储的使用要求,而大文件存储方面的性能有待在后续的研究中对其改进。
[1]陈冬冬.云计算以及数字图书馆发展探析[J].长春理工大学学报:自然科学版,2012,35(11):265-266.
[2]NatalyaYezhkova.IDC'sOutlook fordatabyte density acrossthe globe hasbig implicationsfor the future[J/OL].IDC.21 Oct 2013,http://www.idc.com/getdoc.jsp?containerId=prUS24398613.
[3]Joe Arnold and members of the Swiftstack team.OpenStack Swift[M].United States of America:O’Reilly Media,October 2014:21-23.
[4]邓红,王东兴.基于开源云平台OpenStack的存储分析[J].黑龙江科技信息,2012(32):134.
[5]张瑞杰,李战怀,张晓,等.基于私有云的虚拟实验平台的设计与实现[J].计算机与现代化,2013(8):159-164.
